
Infrared and Visible Image Fusion Based on Co-Occurrence Analysis Shearlet Transform

Abstract
:1. Introduction
2. Related Work
2.1. Co-Occurrence Filter
2.2. Directional Localization
- (1)
- Coordinate mapping: from the pseudo-polar coordinates to the Cartesian coordinates;
- (2)
- Based on the “Meyer” equation, construct the small-size shearlet filter;
- (3)
- The k band-pass detail-layer images and the “Meyer” equation are processed by convolution operation [26].
2.3. Latent Low Rank Representation
2.4. Counting the Zero Crossings in Difference
2.4.1. Proximity Operator of the Number of Zero Crossings
- (1)
- The number of non-zero elements in each segment is one at least.
- (2)
- None-zero elements’ signs in the same segment are the same.
- (3)
- None-zero elements’ signs in adjacent segments are opposite.
| Algorithm 1. Evaluating the proximity operator of |
| Input: Vector , smoothing parameter λ, weight parameter β. |
| Output: The result u, namely is the proximity operator of . |
| 1 Find a MSSP from vector g. |
| 2 Initialize relative parameter . |
| 3 Calculate e, then we can get and . |
| 4 If M ≥ 2 then |
| 5 For j = 3 to M |
| 6 solve for in Equation (11) to compute the minimum loss. |
| 7 End for |
| 8 Update the parameter j ← M + 1 |
| 9 While j ≥ 2 do |
| 10 |
| 11 |
| 12 End while |
| 13 End if |
2.4.2. Image Smoothing with Zero-Crossing Count Regularization
| Algorithm 2. Image smoothing via counting zero crossings |
| Input: Source image I, smoothing weight λ, parameters β, and rate k. |
| Output: Processed image S. |
| 1 Initialization: , . |
| 2 Calculate the vertical difference V via Equation (20) based on Algorithm 1. |
| 3 Calculate the horizontal difference H via Equation(21) based on Algorithm 1. |
| 4 Repeat |
| 5 Calculate S by Equation(18). |
| 6 Calculate and by Equation(19). |
| 7 Update the weight parameter . |
| 8 Until stop condition: the weight parameter . |
| 9 End |
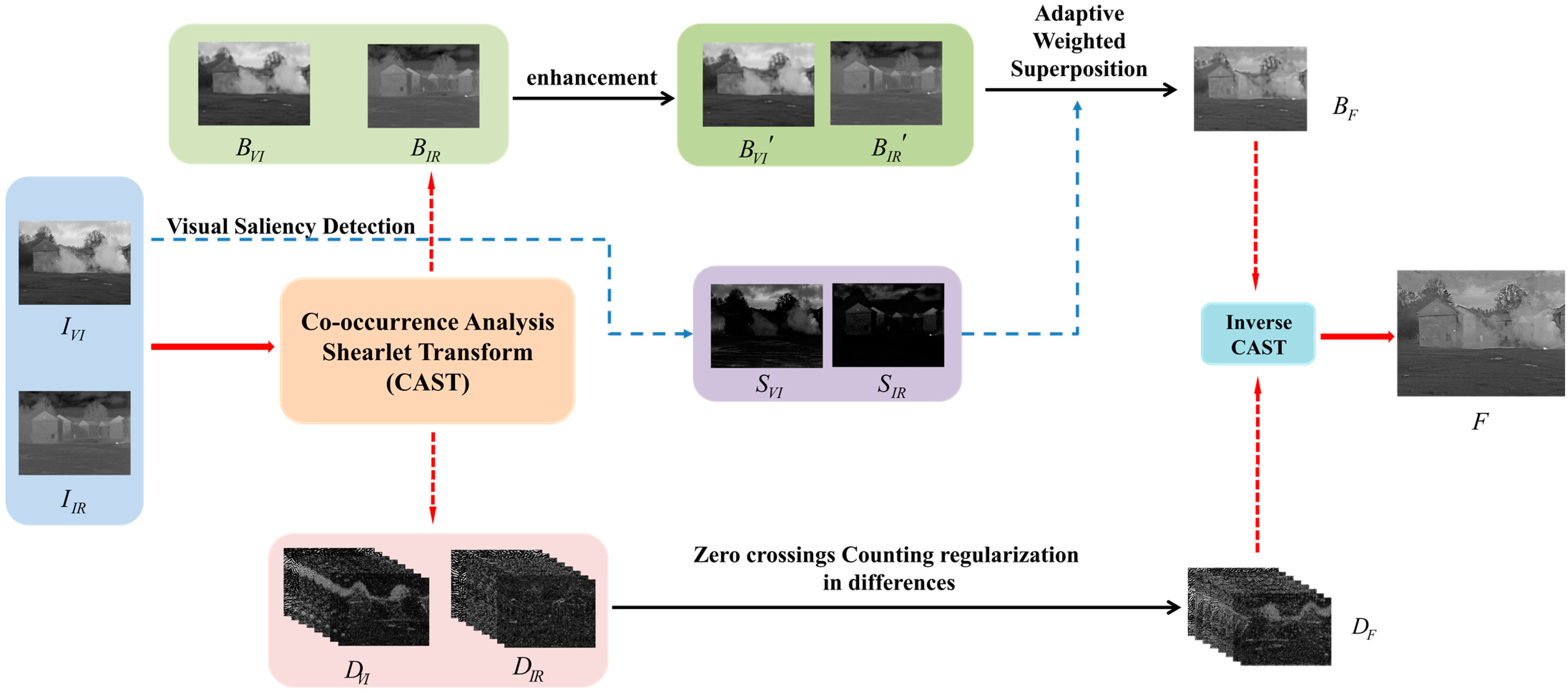
3. The Proposed Method
3.1. Image Decomposition by CAST
3.1.1. The Multi-Scale Decomposition Steps of COF
3.1.2. Multi-Directional Decomposition by Using Discrete Tight Support Shearlet Transform
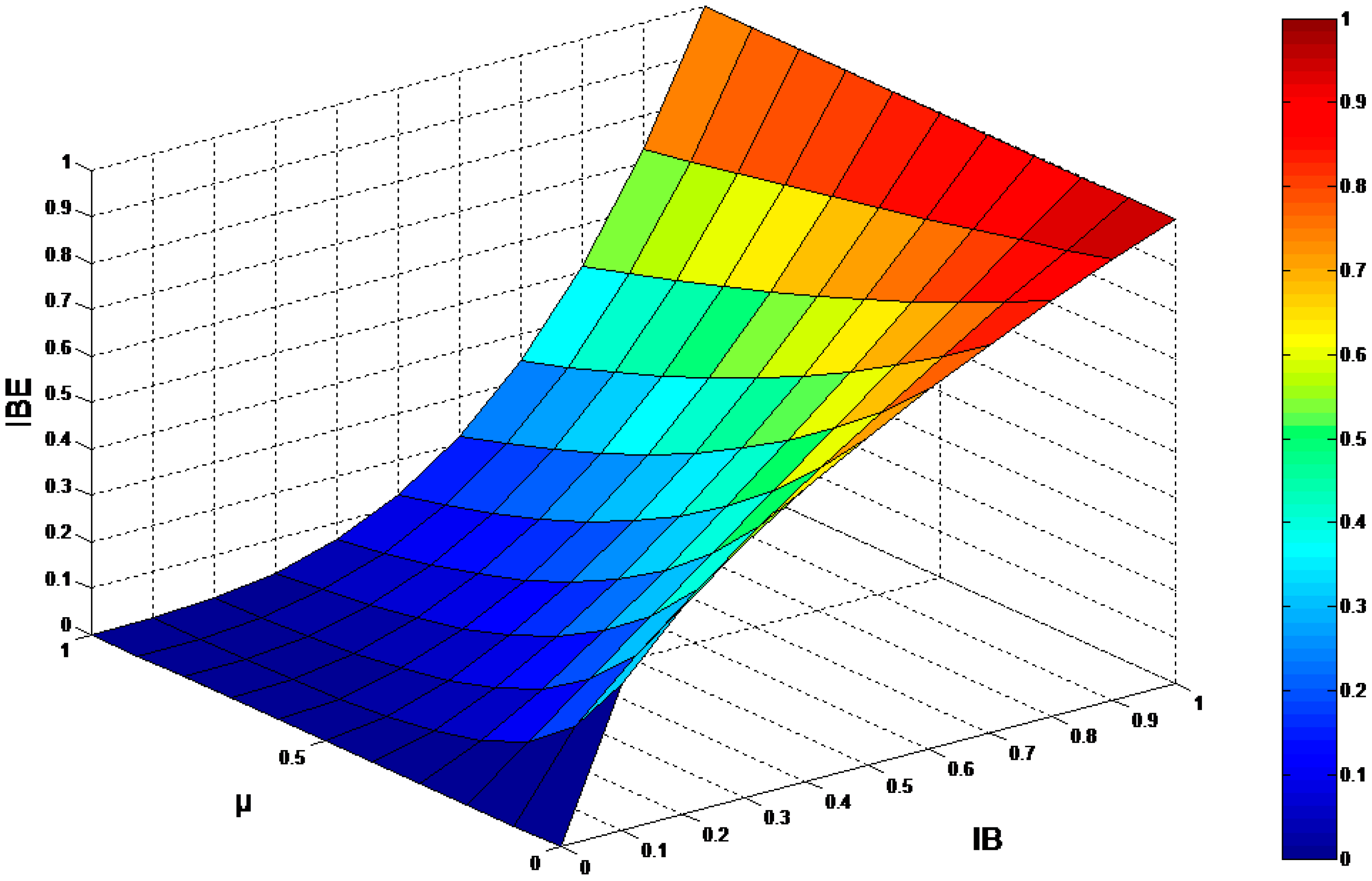
3.2. The Brightness Correction of Based-Layer Image
3.3. Fusion Rule of Base-Layer Image
3.4. Fusion Rule of Detail-Layer Image
4. Experimental Results and Analysis
4.1. Experimental Settings
4.2. Subjective Evaluation
4.3. Objective Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Palsson, F.; Sveinsson, J.; Ulfarsson, M. Sentinel-2 Image Fusion Using a Deep Residual Network. Remote Sens. 2018, 18, 1290. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Dong, L.; Chen, Y.; Xu, W. An Efficient Method for Infrared and Visual Images Fusion Based on Visual Attention Technique. Remote Sens. 2020, 12, 781. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Wu, K.; Cheng, Z.; Luo, L. A Saliency-based Multiscale Approach for Infrared and Visible Image Fusion. Signal Process. 2021, 182, 4–19. [Google Scholar] [CrossRef]
- Harbinder, S.; Carlos, S.; Gabriel, C. Construction of Fused Image with Improved Depth-of-field Based on Guided Co-occurrence Filtering. Digit. Signal Process. 2020, 104, 516–529. [Google Scholar]
- Li, H.; Wu, X.; Josef, K. MDLatLRR: A Novel Decomposition Method for Infrared and Visible Image Fusion. IEEE Trans. Image Process. 2020, 29, 4733–4746. [Google Scholar] [CrossRef] [Green Version]
- Shen, D.; Masoumeh, Z.; Yang, J. Infrared and Visible Image Fusion via Global Variable Consensus. Image Vis. Comput. 2020, 104, 153–178. [Google Scholar] [CrossRef]
- Bavirisetti, D.; Xiao, G.; Liu, G. Multi-sensor Image Fusion Based on Fourth Order Partial Differential Equations. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–9. [Google Scholar]
- Zhao, W.; Lu, H.; Dong, W. Multisensor Image Fusion and Enhancement in Spectral Total Variation Domain. IEEE Trans. Image Process. 2018, 20, 866–879. [Google Scholar] [CrossRef]
- Tan, W.; William, T.; Xiang, P.; Zhou, H. Multi-modal Brain Image Fusion Based on Multi-level Edge-preserving Filtering. Biomed. Signal Process. Control 2021, 64, 1882–1886. [Google Scholar] [CrossRef]
- Peter, B.; Edward, A. The Laplacian Pyramid as a Compact Image Code. IEEE Trans. Commun. 1983, 31, 532–540. [Google Scholar]
- Liu, J.; Ding, J.; Ge, X.; Wang, J. Evaluation of Total Nitrogen in Water via Airborne Hyperspectral Data: Potential of Fractional Order Discretization Algorithm and Discrete Wavelet Transform Analysis. Remote Sens. 2021, 13, 4643. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, J.; Jiang, X.; Yan, X. Infrared and Visible Image Fusion via Hybrid Decomposition of NSCT and Morphological Sequential Toggle Operator. Optik 2020, 201, 163497. [Google Scholar] [CrossRef]
- Cheng, B.; Jin, L.; Li, G. A Novel Fusion Framework of Visible Light and Infrared Images Based on Singular Value Decomposition and Adaptive DUALPCNN in NSST Domain. Infrared Phys. Technol. 2018, 91, 153–163. [Google Scholar] [CrossRef]
- Zhuang, P.; Zhu, X.; Ding, X. MRI Reconstruction with an Edge-preserving Filtering Prior. Signal Process. 2019, 155, 346–357. [Google Scholar] [CrossRef]
- Yin, H.; Gong, Y.; Qiu, G. Side Window Guided Filtering. Signal Process. 2019, 165, 315–330. [Google Scholar] [CrossRef]
- Gong, Y.; Sbalzarini, I. Curvature Filters Efficiently Reduce Certain Variational Energies. IEEE Trans. Image Process. 2017, 26, 1786–1798. [Google Scholar] [CrossRef] [Green Version]
- Tomasi, C.; Manduchi, R. Bilateral Filtering for Gray and Color Images. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), Bombay, India, 7 January 1998; IEEE: Piscataway, NJ, USA, 2002; pp. 839–846. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef]
- Yuan, W.; Yuan, X.; Xu, S.; Gong, J.; Shibasaki, R. Dense Image-Matching via Optical Flow Field Estimation and Fast-Guided Filter Refinement. Remote Sens. 2019, 11, 2410. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Zhao, J.; Shi, M. Medical Image Fusion Based on Rolling Guidance Filter and Spiking Cortical Mode. Comput. Math. Methods Med. 2015, 2015, 156043. [Google Scholar]
- Jevnisek, R.; Shai, A. Co-occurrence Filter. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, G.; Yan, S. Latent Low-rank Representation for Subspace Segmentation and Feature Extraction. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1615–1622. [Google Scholar]
- Nie, T.; Huang, L.; Liu, H.; Li, X.; Zhao, Y.; Yuan, H.; Song, X.; He, B. Multi-Exposure Fusion of Gray Images Under Low Illumination Based on Low-Rank Decomposition. Remote Sens. 2021, 13, 204. [Google Scholar] [CrossRef]
- Cheng, B.; Jin, L.; Li, G. General Fusion Method for Infrared and Visual Images via Latent Low-rank Representation and Local Non-subsampled Shearlet Transform. Infrared Phys. Technol. 2018, 92, 68–77. [Google Scholar] [CrossRef]
- Jiang, X.; Yao, H.; Liu, S. How Many Zero Crossings? A Method for Structure-texture Image Decomposition. Comput. Graph. 2017, 68, 129–141. [Google Scholar] [CrossRef]
- Cheng, B.; Jin, L.; Li, G. Infrared and Low-light-level Image Fusion Based on l2-energy Minimization and Mixed-L1-gradient Regularization. Infrared Phys. Technol. 2019, 96, 163–173. [Google Scholar] [CrossRef]
- Zhang, P. Infrared and Visible Image Fusion Using Co-occurrence Filter. Infrared Phys. Technol. 2018, 93, 223–231. [Google Scholar] [CrossRef]
- Hu, Y.; He, J.; Xu, L. Infrared and Visible Image Fusion Based on Multiscale Decomposition with Gaussian and Co-Occurrence Filters. In Proceedings of the 4th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Yibin, China, 20–22 August 2021. [Google Scholar]
- Wang, B.; Zeng, J.; Lin, S.; Bai, G. Multi-band Images Synchronous Fusion Based on NSST and Fuzzy Logical Inference. Infrared Phys. Technol. 2019, 98, 94–107. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and Visible Image Fusion Based on Visual Saliency Map and Weighted Least Square Optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Marr, D.; Ullman, S.; Poggio, T. Bandpass Channels, Zero-crossings, and Early Visual Information Processing. J. Opt. Soc. Am. 1979, 69, 914–916. [Google Scholar] [CrossRef]
- Combettes, P.; Pesquet, J. Proximal splitting methods in signal processing. In Fixed-Point Algorithms for Inverse Problems in Science and Engineering; Bauschke, H., Burachik, R., Combettes, P., Elser, V., Luke, D., Wolkowicz, H., Eds.; Springer: New York, NY, USA, 2011; pp. 185–212. [Google Scholar]
- Zakhor, A.; Oppenheim, A. Reconstruction of Two-dimensional Signals from Level Crossings. Proc. IEEE 1990, 78, 31–55. [Google Scholar] [CrossRef]
- Badri, H.; Yahia, H.; Aboutajdine, D. Fast Edge-aware Processing via First Order Proximal Approximation. IEEE Trans. Vis. Comput. Graph. 2015, 21, 743–755. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar]
- Storath, M.; Weinmann, A.; Demaret, L. Jump-sparse and Sparse Recovery Using Potts Functionals. IEEE Trans. Signal Process. 2014, 62, 3654–3666. [Google Scholar] [CrossRef] [Green Version]
- Storath, M.; Weinmann, A. Fast Partitioning of Vector-valued Images. SIAM J. Imaging Sci. 2014, 7, 1826–1852. [Google Scholar] [CrossRef] [Green Version]
- Ono, S. l0 Gradient Projection. IEEE Trans. Image Process. 2017, 26, 1554–1564. [Google Scholar] [CrossRef] [PubMed]
- Ren, L.; Pan, Z.; Cao, J.; Liao, J.; Wang, Y. Infrared and Visible Image Fusion Based on Weighted Variance Guided Filter and Image Contrast Enhancement. Infrared Phys. Technol. 2021, 114, 71–77. [Google Scholar] [CrossRef]
- Toet, A. TNO Image Fusion Dataset. 2014. Available online: https://figshare.com/articles/TN_Image_Fusion_Dataset/1008029 (accessed on 30 November 2021).
- Cai, W.; Li, M.; Li, X. Infrared and Visible Image Fusion Scheme Based on Contourlet Transform. In Proceedings of the Fifth International Conference on Image and Graphics (ICIG), Xi’an, China, 20–23 September 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 20–23. [Google Scholar]
- John, J.; Robert, J.; Stavri, G.; David, R.; Nishan, C. Pixel-and Region-based Image Fusion with Complex Wavelets. Inf. Fusion 2007, 8, 119–130. [Google Scholar]
- Liu, Y.; Liu, S.; Wang, Z. A General Framework for Image Fusion Based on Multi-scale Transform and Sparse Representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and Visible Image Fusion via Gradient Transfer and Total Variation Minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Naidu, V. Image Fusion Technique Using Multi-resolution Singular Value Decomposition. Def. Sci. J. 2011, 61, 479–484. [Google Scholar] [CrossRef] [Green Version]
- Jin, H.; Xi, Q.; Wang, Y. Fusion of visible and infrared images using multi objective evolutionary algorithm based on decomposition. Infrared Phys. Technol. 2015, 71, 151–158. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.; Kittler, J. RFN-Nest: An End-to-end Residual Fusion Network for Infrared and Visible Images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Eskicioglu, A.M.; Fisher, P. Image quality measures and their performance. IEEE Trans. Commun. 1995, 43, 2959–2965. [Google Scholar] [CrossRef] [Green Version]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Metrics | CVT | CWT | WLS | LP | ADF | GTF | MSVD | Proposed |
|---|---|---|---|---|---|---|---|---|---|
| AVG | 3.114 | 3.022 | 4.101 | 3.193 | 2.696 | 3.211 | 2.592 | 3.673 | |
| MI | 13.398 | 13.275 | 14.350 | 13.693 | 13.090 | 14.702 | 12.995 | 15.034 | |
| Marne | Qab/f | 0.202 | 0.149 | 0.306 | 0.144 | 0.121 | 0.182 | 0.039 | 0.266 |
| SF | 6.346 | 6.271 | 8.633 | 6.607 | 5.553 | 6.654 | 5.338 | 9.327 | |
| SD | 25.664 | 24.486 | 36.793 | 28.216 | 23.077 | 41.608 | 22.557 | 45.640 | |
| AVG | 5.100 | 5.095 | 5.520 | 5.375 | 4.192 | 4.389 | 4.250 | 6.282 | |
| MI | 13.000 | 12.937 | 13.458 | 13.245 | 12.647 | 13.028 | 12.638 | 12.189 | |
| Umbrella | Qab/f | 0.153 | 0.128 | 0.192 | 0.133 | 0.061 | 0.076 | 0.011 | 0.238 |
| SF | 10.467 | 10.534 | 10.838 | 10.963 | 8.580 | 9.564 | 8.568 | 11.146 | |
| SD | 30.557 | 30.531 | 40.463 | 35.340 | 27.678 | 37.642 | 27.213 | 45.772 | |
| AVG | 4.400 | 4.343 | 5.052 | 4.536 | 3.675 | 3.885 | 3.606 | 6.922 | |
| MI | 13.544 | 13.401 | 13.910 | 13.538 | 13.195 | 14.099 | 13.078 | 14.031 | |
| Kaptein | Qab/f | 0.173 | 0.143 | 0.226 | 0.141 | 0.044 | 0.070 | 0.013 | 0.242 |
| SF | 8.482 | 8.480 | 9.761 | 8.858 | 6.578 | 7.736 | 6.946 | 11.584 | |
| SD | 34.090 | 33.554 | 48.580 | 36.148 | 31.638 | 47.391 | 31.549 | 54.582 | |
| AVG | 4.977 | 4.990 | 5.109 | 5.146 | 2.948 | 4.419 | 3.948 | 5.321 | |
| MI | 13.813 | 13.797 | 14.020 | 14.227 | 13.187 | 14.142 | 13.298 | 13.950 | |
| Car | Qab/f | 0.593 | 0.621 | 0.549 | 0.691 | 0.444 | 0.654 | 0.464 | 0.508 |
| SF | 14.796 | 14.881 | 15.470 | 15.240 | 8.696 | 13.998 | 11.993 | 16.482 | |
| SD | 34.315 | 34.471 | 47.796 | 40.897 | 28.287 | 48.457 | 29.516 | 52.094 | |
| AVG | 6.620 | 6.455 | 7.405 | 6.975 | 4.895 | 5.876 | 5.711 | 9.321 | |
| MI | 13.660 | 13.567 | 13.861 | 13.920 | 13.196 | 14.049 | 13.151 | 13.253 | |
| Camp | Qab/f | 0.385 | 0.432 | 0.404 | 0.497 | 0.385 | 0.448 | 0.322 | 0.318 |
| SF | 13.413 | 13.315 | 14.418 | 14.038 | 9.610 | 11.922 | 10.914 | 15.493 | |
| SD | 32.424 | 31.595 | 34.416 | 35.148 | 27.858 | 36.659 | 27.836 | 40.387 | |
| AVG | 3.995 | 3.923 | 4.223 | 4.034 | 3.637 | 3.088 | 3.131 | 4.932 | |
| MI | 13.120 | 12.860 | 13.248 | 12.984 | 12.664 | 13.384 | 12.489 | 13.190 | |
| Octec | Qab/f | 0.173 | 0.128 | 0.217 | 0.139 | 0.090 | 0.113 | 0.012 | 0.292 |
| SF | 10.525 | 10.494 | 9.960 | 10.585 | 9.215 | 8.321 | 7.902 | 11.729 | |
| SD | 30.009 | 29.071 | 33.146 | 30.657 | 28.165 | 32.189 | 27.674 | 35.603 | |
| AVG | 10.240 | 10.255 | 10.583 | 10.686 | 8.028 | 9.042 | 8.955 | 11.402 | |
| MI | 14.504 | 14.457 | 14.500 | 14.691 | 14.076 | 14.539 | 13.992 | 12.361 | |
| Road | Qab/f | 0.214 | 0.166 | 0.169 | 0.150 | 0.071 | 0.070 | 0.042 | 0.239 |
| SF | 20.995 | 21.454 | 22.188 | 22.228 | 16.335 | 19.169 | 18.757 | 24.049 | |
| SD | 41.613 | 41.667 | 42.919 | 47.292 | 34.667 | 42.080 | 34.913 | 52.268 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, B.; Jin, L.; Li, G.; Zhang, Y.; Li, Q.; Bi, G.; Wang, W. Infrared and Visible Image Fusion Based on Co-Occurrence Analysis Shearlet Transform. Remote Sens. 2022, 14, 283. https://doi.org/10.3390/rs14020283
Qi B, Jin L, Li G, Zhang Y, Li Q, Bi G, Wang W. Infrared and Visible Image Fusion Based on Co-Occurrence Analysis Shearlet Transform. Remote Sensing. 2022; 14(2):283. https://doi.org/10.3390/rs14020283
Chicago/Turabian StyleQi, Biao, Longxu Jin, Guoning Li, Yu Zhang, Qiang Li, Guoling Bi, and Wenhua Wang. 2022. "Infrared and Visible Image Fusion Based on Co-Occurrence Analysis Shearlet Transform" Remote Sensing 14, no. 2: 283. https://doi.org/10.3390/rs14020283
APA StyleQi, B., Jin, L., Li, G., Zhang, Y., Li, Q., Bi, G., & Wang, W. (2022). Infrared and Visible Image Fusion Based on Co-Occurrence Analysis Shearlet Transform. Remote Sensing, 14(2), 283. https://doi.org/10.3390/rs14020283