
AF-SRNet: Quantitative Precipitation Forecasting Model Based on Attention Fusion Mechanism and Residual Spatiotemporal Feature Extraction


Abstract
:
1. Introduction
2. Related Work
3. Methods
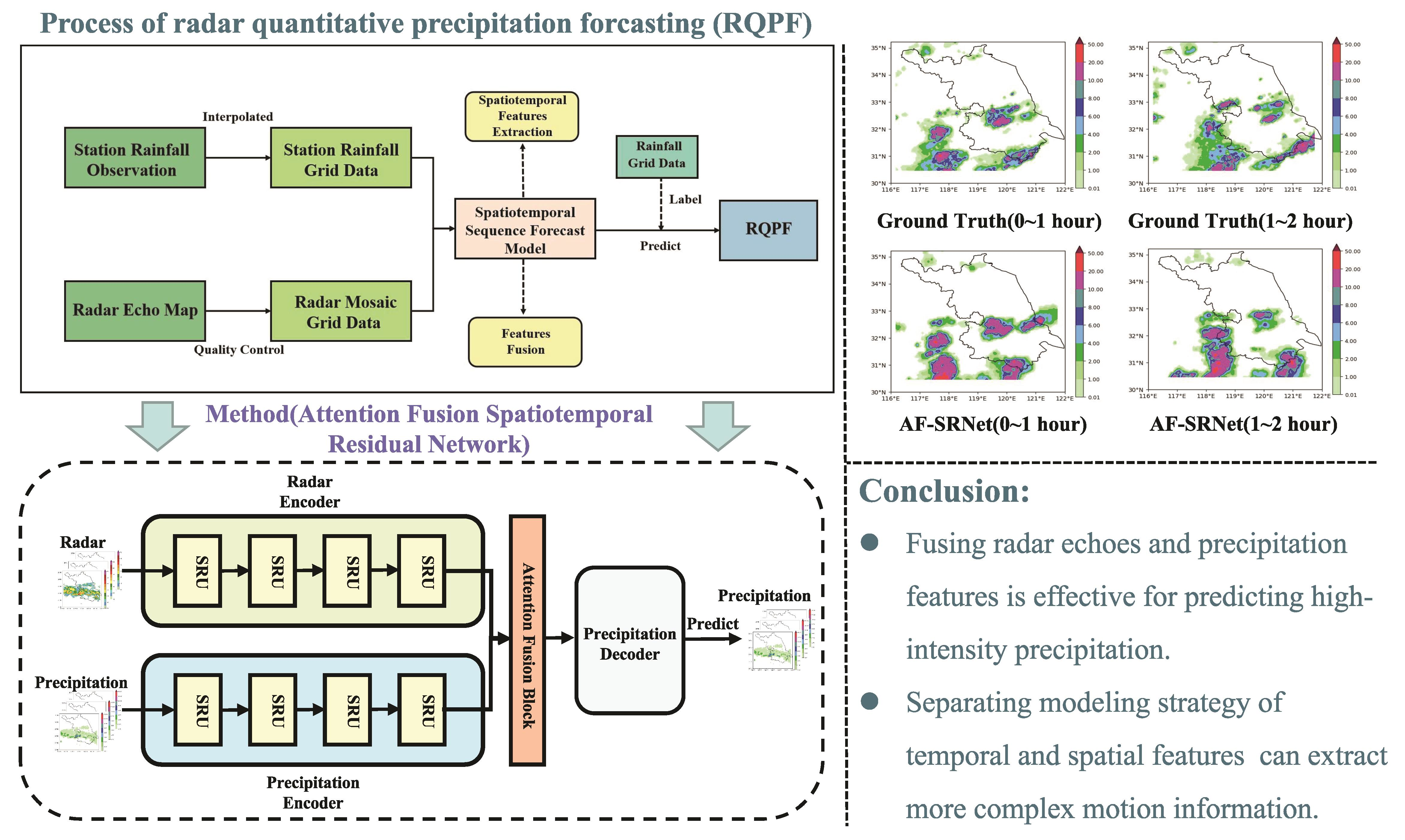
3.1. Problem Definition
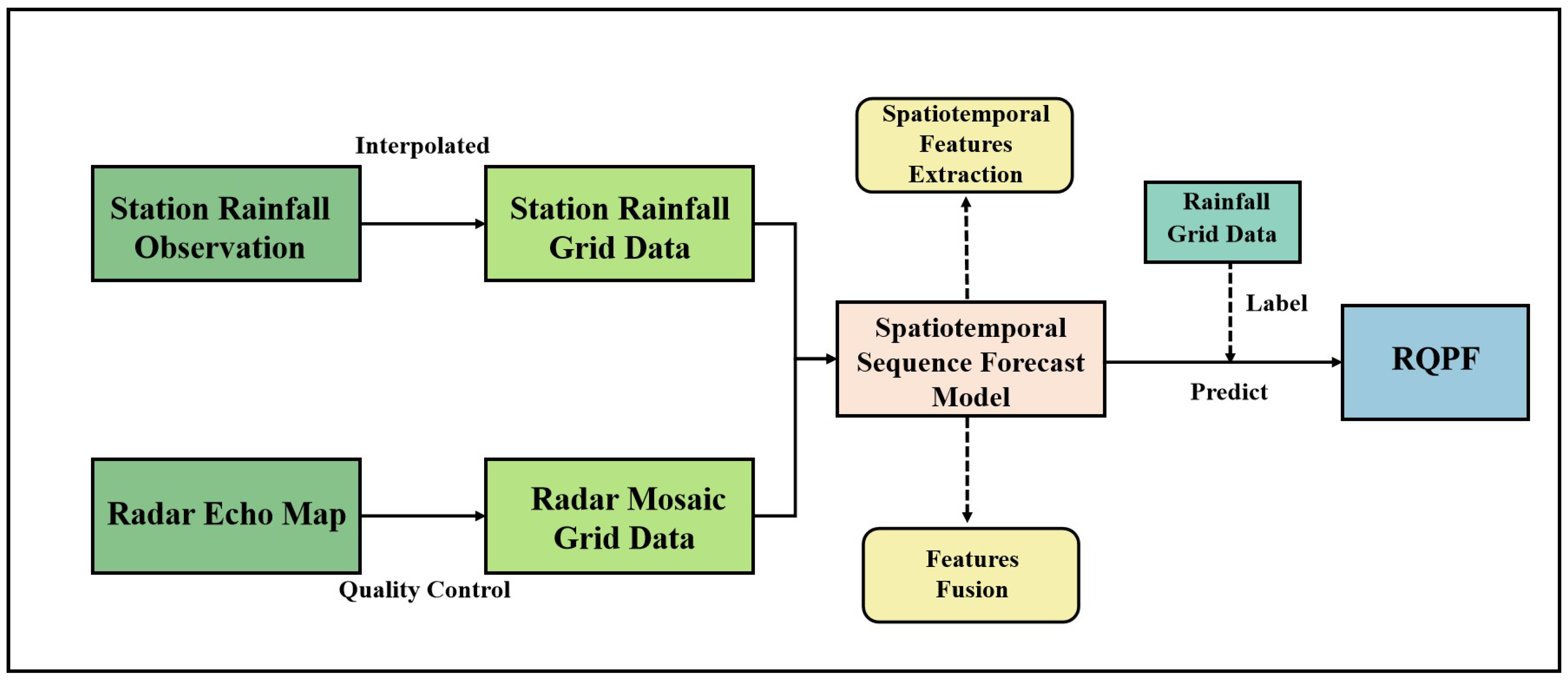
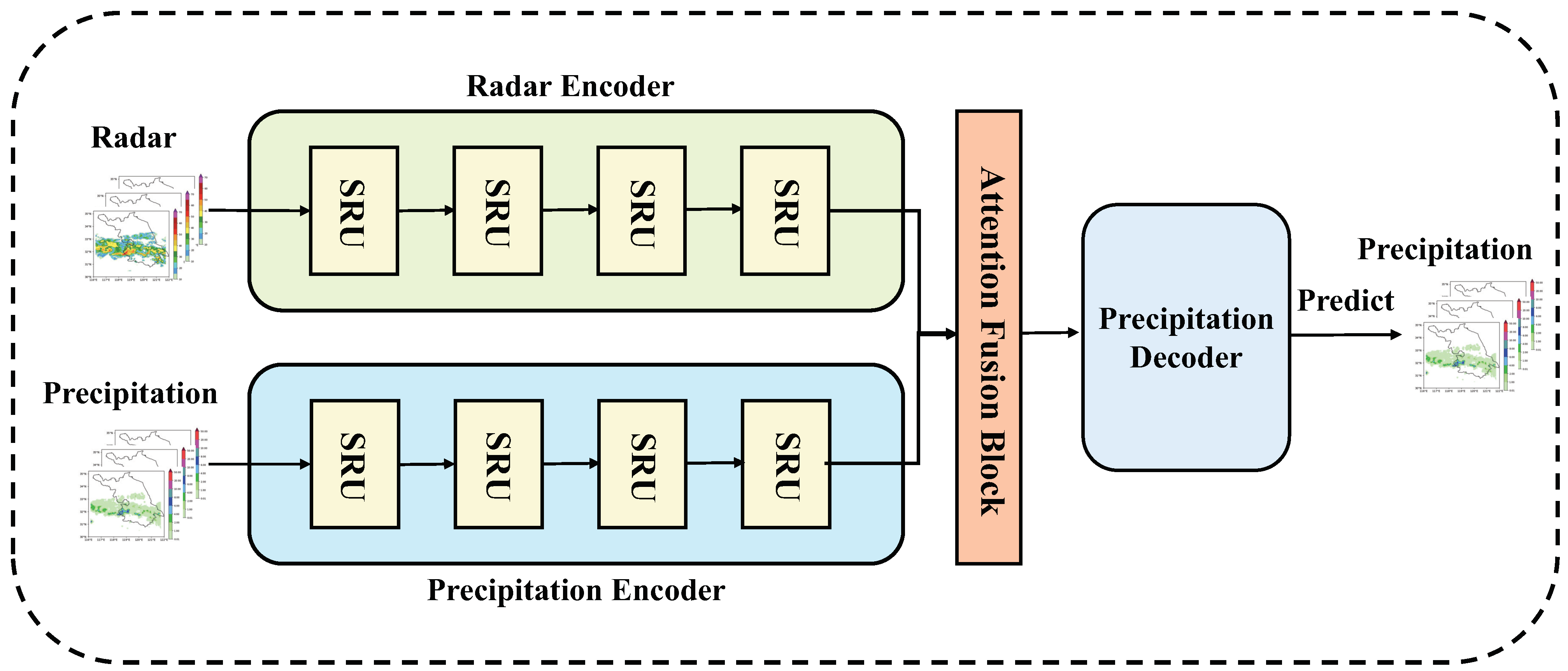
3.2. Model
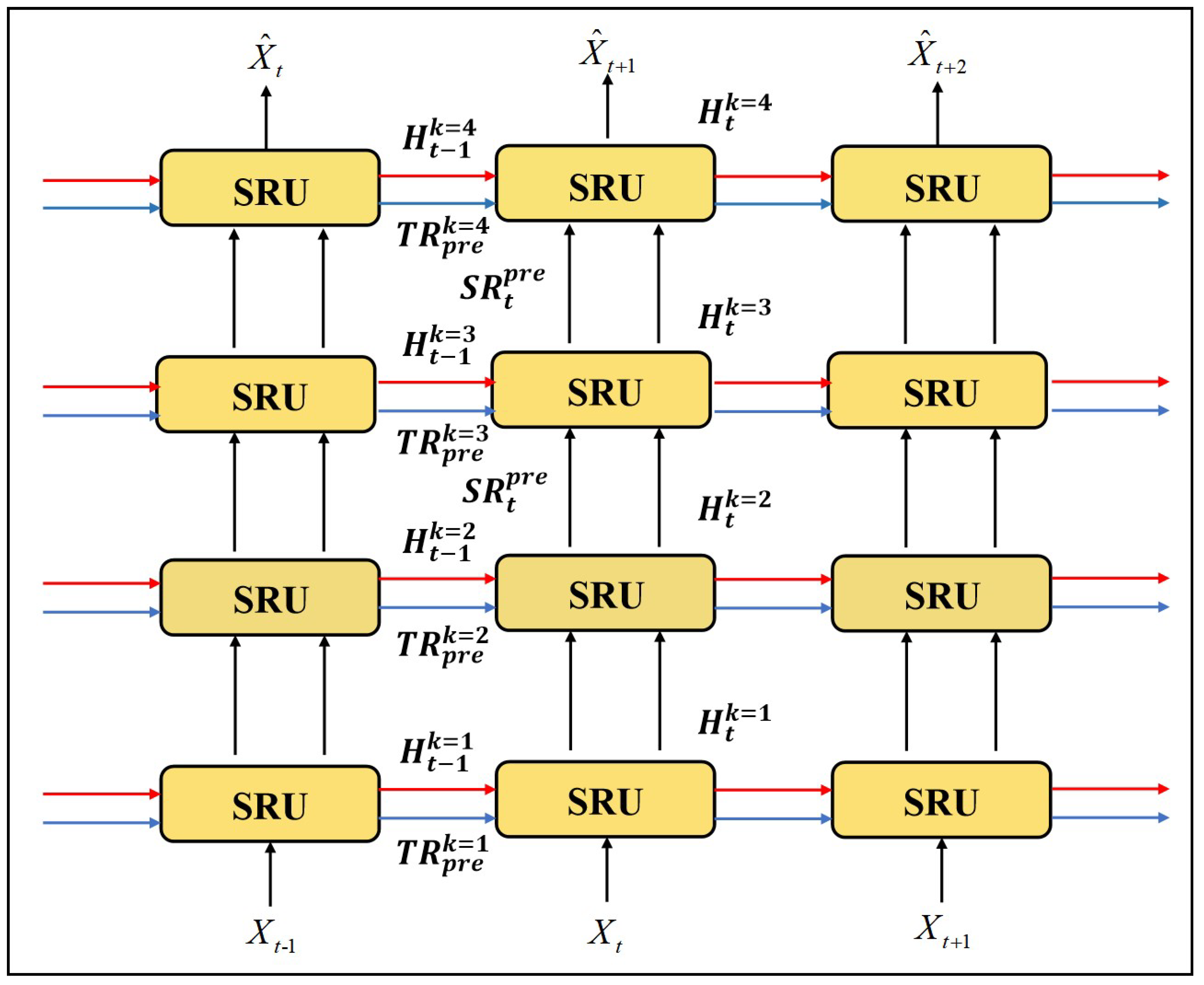
3.2.1. Whole Network
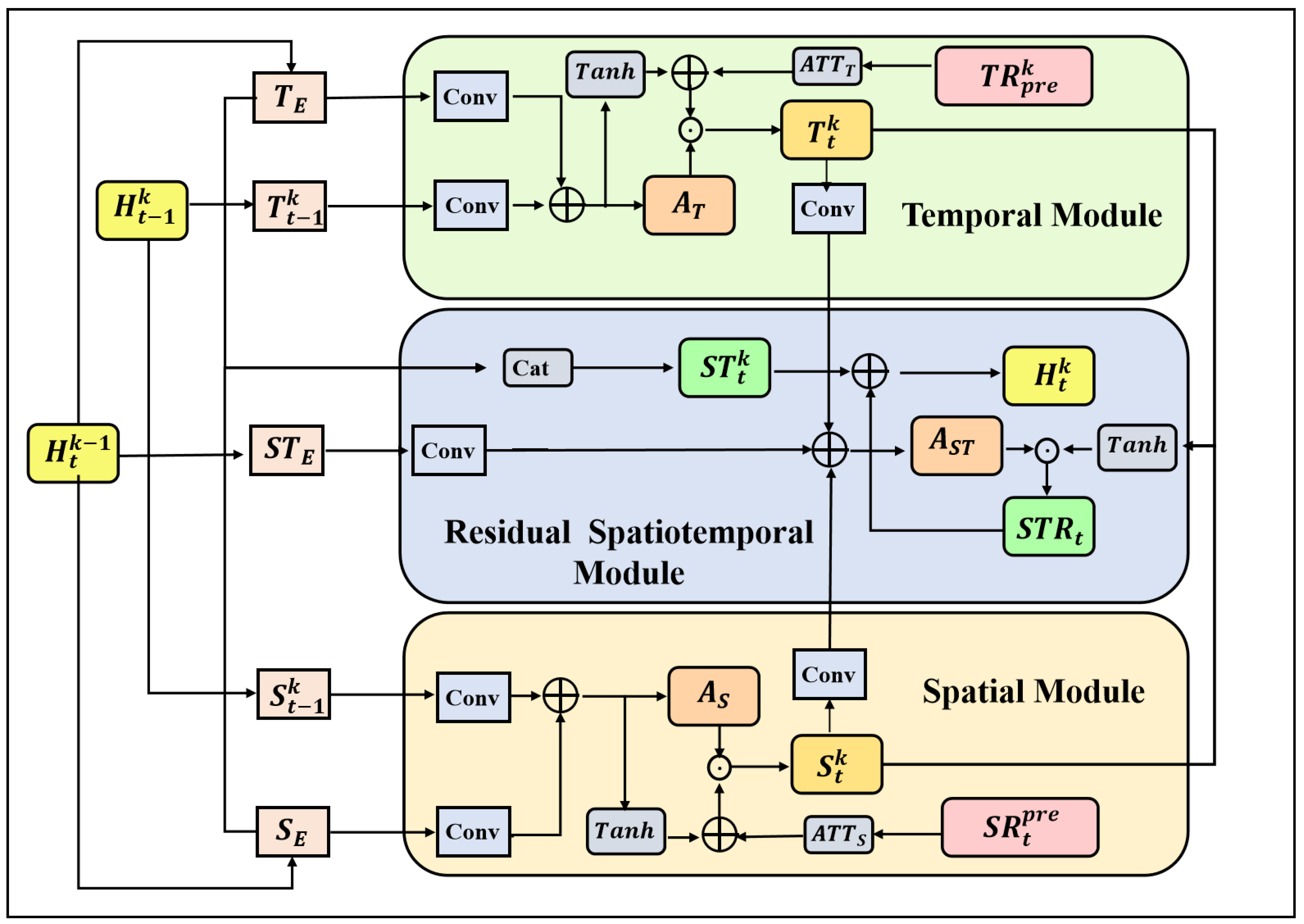
3.2.2. Spatiotemporal Residual Unit
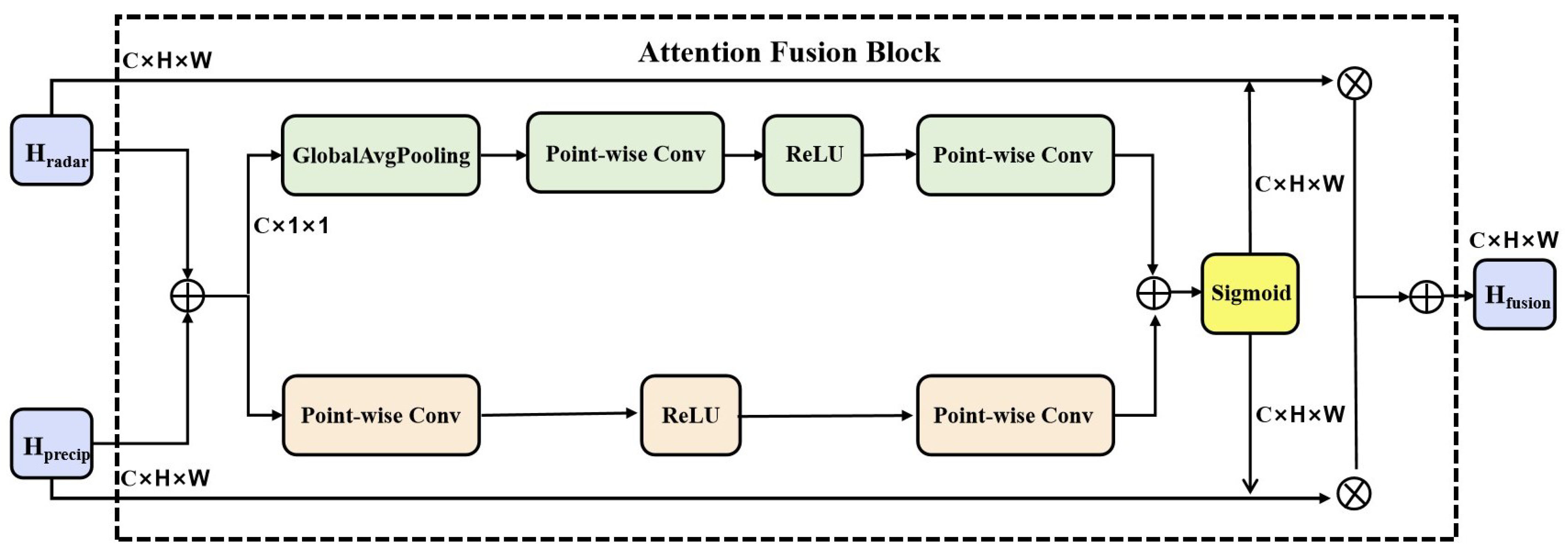
3.2.3. Attention Fusion Block
3.2.4. Decoder
4. Experiments
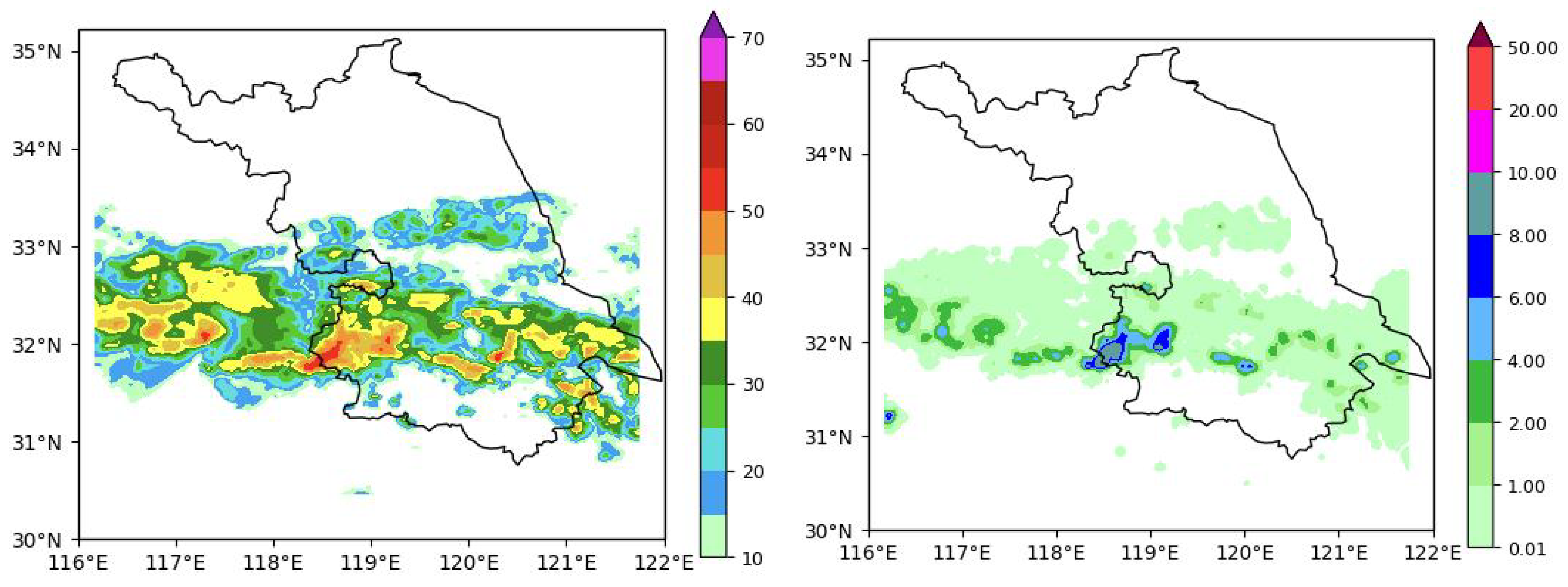
4.1. Dataset
4.2. Loss Fuction
4.3. Implementation Details
4.4. Performance Metric
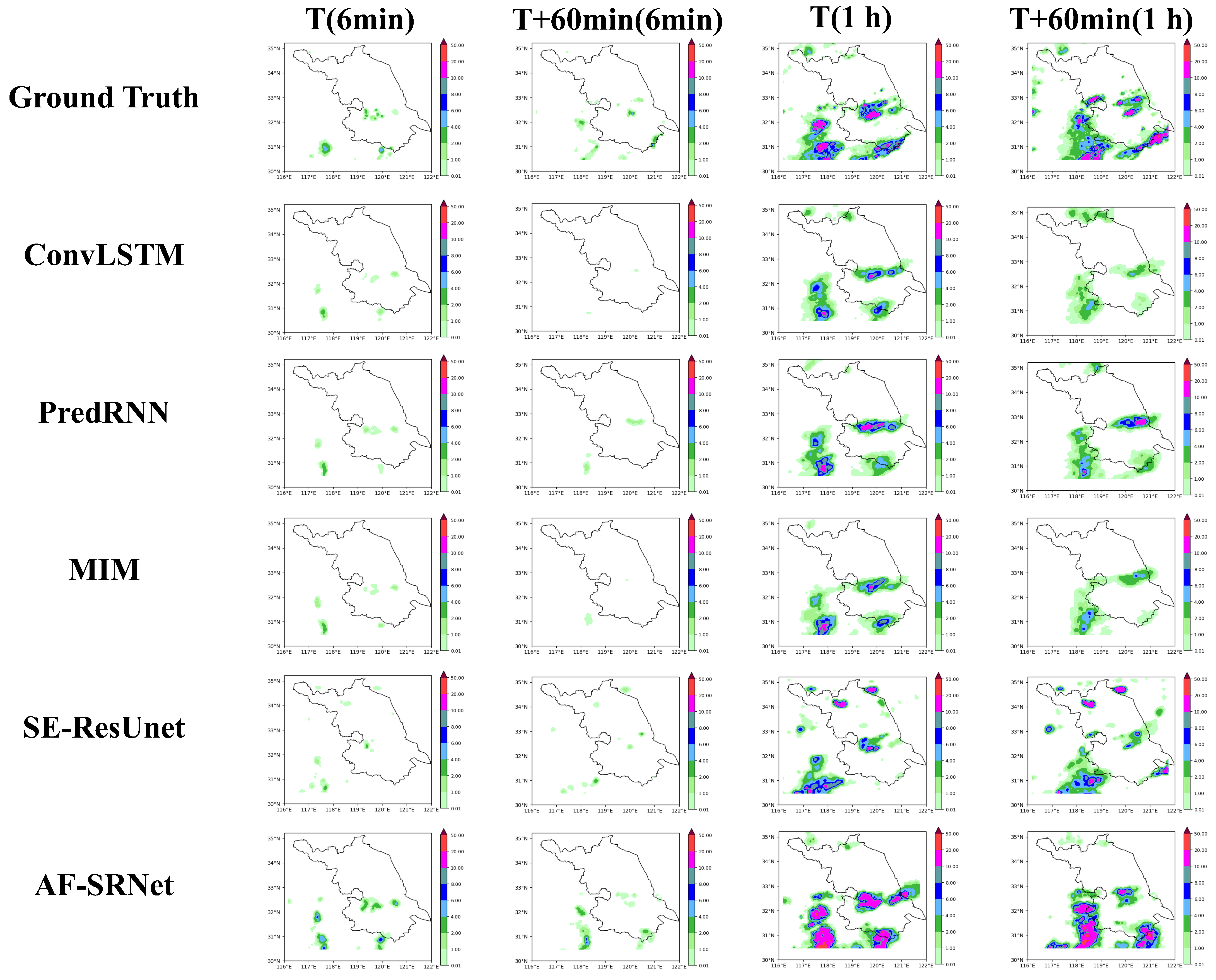
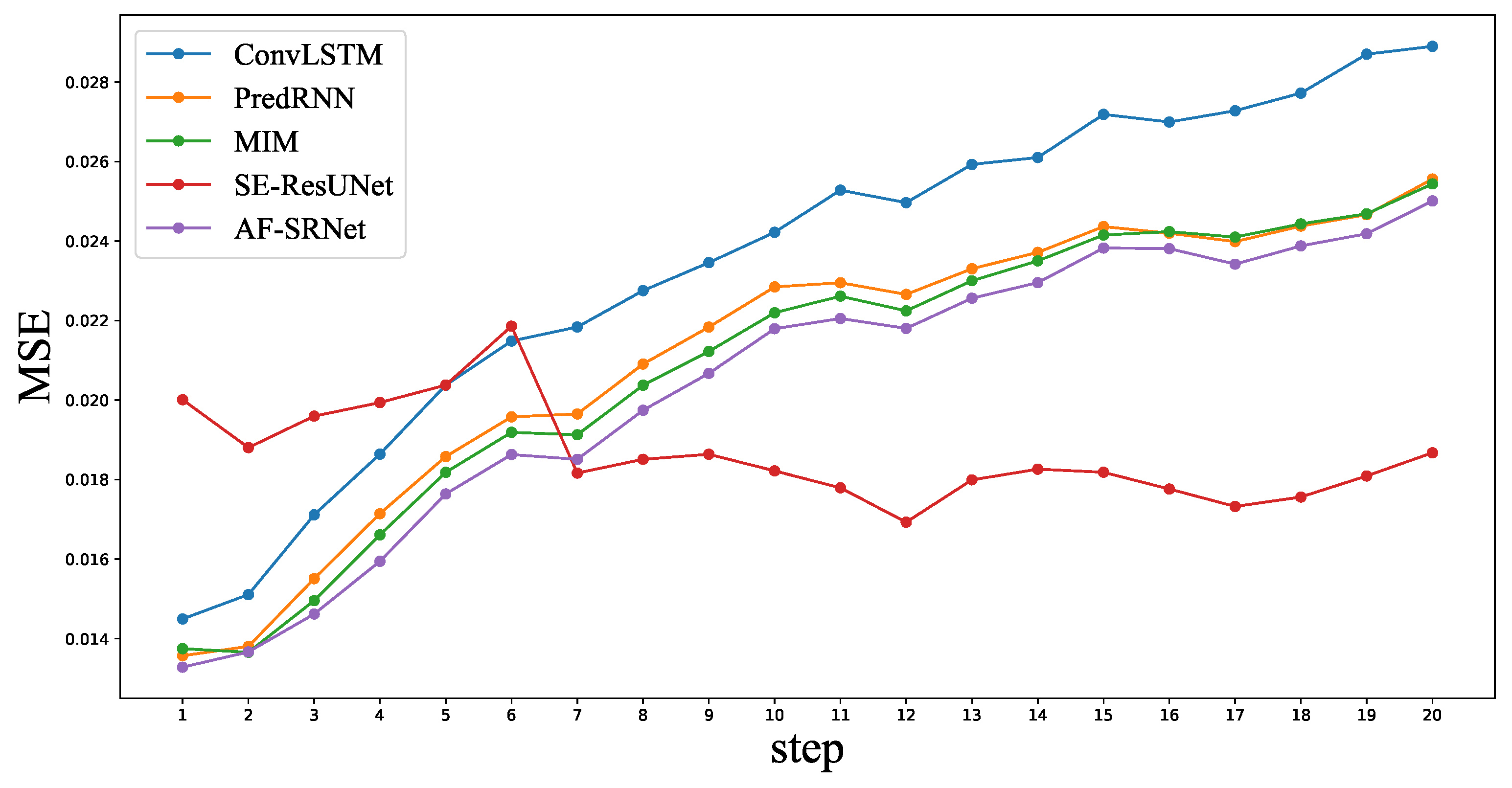
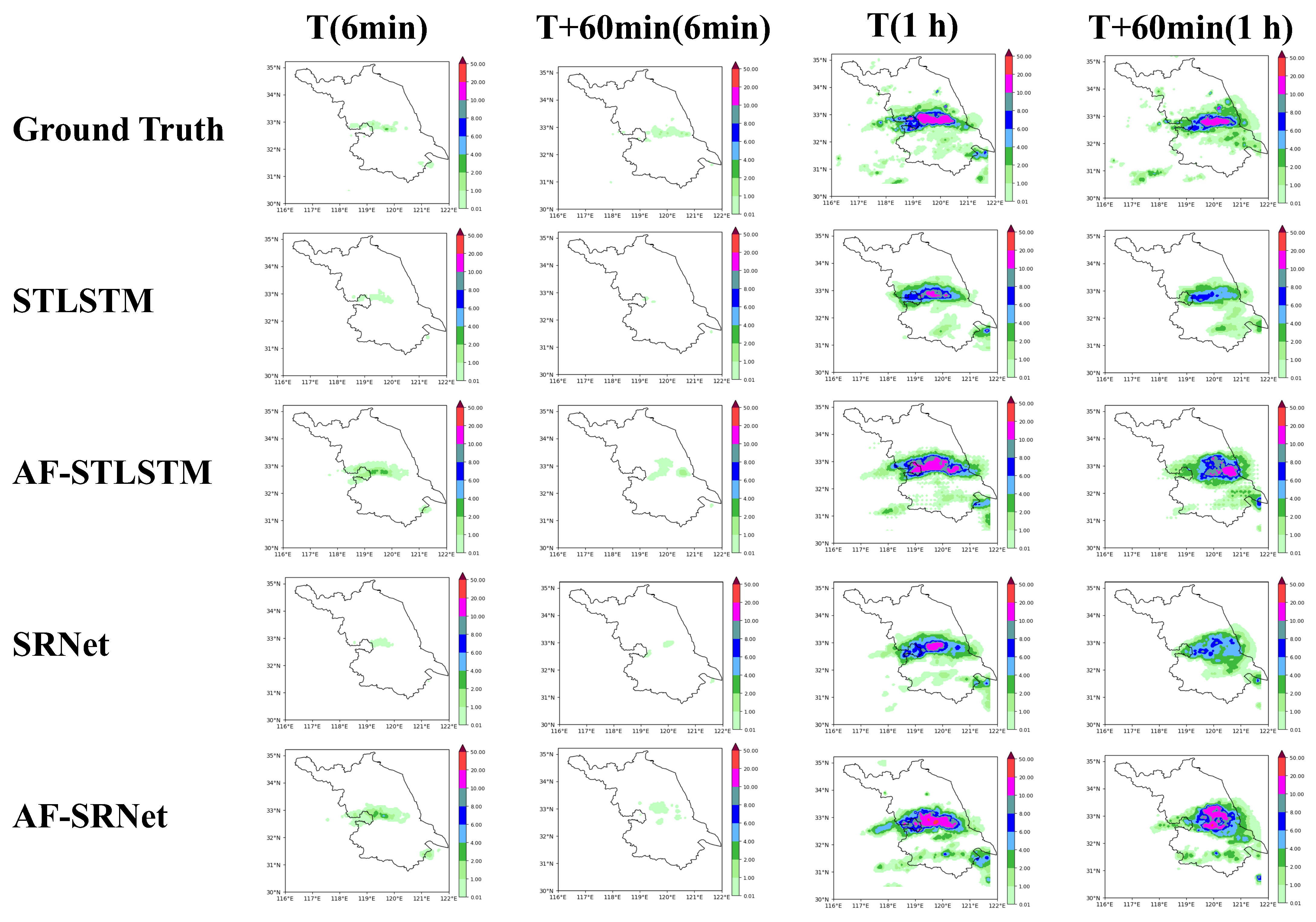
4.5. Experimental Results and Comparisons with SOTAs
4.6. Ablation Experiments and Analyses
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fabry, F.; Seed, A.W. Quantifying and predicting the accuracy of radar-based quantitative precipitation forecasts. Adv. Water Resour. 2009, 32, 1043–1049. [Google Scholar] [CrossRef]
- Shukla, B.P.; Kishtawal, C.M.; Pal, P.K. Prediction of Satellite Image Sequence for Weather Nowcasting Using Cluster-Based Spatiotemporal Regression. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4155–4160. [Google Scholar] [CrossRef]
- Sobolev, G.A. Application of electric method to the tentative short-term forecast of Kamchatka earthquakes. Pure Appl. Geophys. 1975, 113, 229–235. [Google Scholar] [CrossRef]
- Khokhlov, V.N.; Glushkov, A.V.; Loboda, N.S.; Bunyakova, Y.Y. Short-range forecast of atmospheric pollutants using non-linear prediction method. Atmos. Environ. 2008, 42, 7284–7292. [Google Scholar] [CrossRef]
- Pan, H.L.; Wu, W.S. Implementing a Mass Flux Convective Parameterization Package for the NMC Medium-Range Forecast Model; National Centers for Environmental Prediction (U.S.): College Park, MD, USA, 1995. [Google Scholar]
- Gowariker, V.; Thapliyal, V.; Kulshrestha, S.M.; Mandal, G.S.; Sikka, D.R. A power regression model for long range forecast of southwest monsoon rainfall over India. Mausam 1991, 42, 125–130. [Google Scholar] [CrossRef]
- Sun, J.; Xue, M.; Wilson, J.W.; Zawadzki, I.; Ballard, S.P.; Onvlee-Hooimeyer, J.; Joe, P.; Barker, D.M.; Li, P.W.; Golding, B.; et al. Use of NWP for Nowcasting Convective Precipitation: Recent Progress and Challenges. Bull. Am. Meteorol. Soc. 2014, 95, 409–426. [Google Scholar] [CrossRef] [Green Version]
- Xiong, A.; Liu, N.; Liu, Y.; Zhi, S.; Wu, L.; Xin, Y.; Shi, Y.; Zhan, Y. QpefBD: A Benchmark Dataset Applied to Machine Learning for Minute-Scale Quantitative Precipitation Estimation and Forecasting. J. Meteorol. Res. 2022, 36, 93–106. [Google Scholar] [CrossRef]
- Chen, H.; Chandrasekar, V. The quantitative precipitation estimation system for Dallas–Fort Worth (DFW) urban remote sensing network. J. Hydrol. 2015, 531, 259–271. [Google Scholar] [CrossRef] [Green Version]
- Fujiwara, M. Raindrop-size Distribution from Individual Storms. J. Atmos. Sci. 1965, 22, 585–591. [Google Scholar] [CrossRef]
- Wang, S.; Yu, X.; Liu, L.; Huang, J.; Ho Wong, T.; Jiang, C. An Approach for Radar Quantitative Precipitation Estimation Based on Spatiotemporal Network. Comput. Mater. Contin. 2020, 65, 459–479. [Google Scholar] [CrossRef]
- Bowler, N.; Pierce, C.E.; Seed, A. Development of a precipitation nowcasting algorithm based upon optical flow techniques. J. Hydrol. 2004, 288, 74–91. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, L.; Yang, M.H.; Li, L.J.; Long, M.; Fei-Fei, L. Eidetic 3D Lstm: A Model for Video Prediction and Beyond. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019; p. 14. [Google Scholar]
- Wang, Y.; Long, M. PredRNN: Recurrent Neural Networks for Predictive Learning using Spatiotemporal LSTMs. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; p. 10. [Google Scholar]
- Wang, Y.; Zhang, J.; Zhu, H.; Long, M.; Wang, J.; Yu, P.S. Memory In Memory: A Predictive Neural Network for Learning Higher-Order Non-Stationarity from Spatiotemporal Dynamics. arXiv 2019, arXiv:1811.07490. [Google Scholar]
- Geng, H.; Wang, T.; Zhuang, X.; Xi, D.; Hu, Z.; Geng, L. GAN-rcLSTM: A Deep Learning Model for Radar Echo Extrapolation. Atmosphere 2022, 13, 684. [Google Scholar] [CrossRef]
- Trebing, K.; Stanczyk, T.; Mehrkanoon, S. SmaAt-UNet: Precipitation nowcasting using a small attention-UNet architecture. Pattern Recognit. Lett. 2021, 145, 178–186. [Google Scholar] [CrossRef]
- Song, K.; Yang, G.; Wang, Q.; Xu, C.; Liu, J.; Liu, W.; Shi, C.; Wang, Y.; Zhang, G.; Yu, X.; et al. Deep Learning Prediction of Incoming Rainfalls: An Operational Service for the City of Beijing China. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019; IEEE: Beijing, China, 2019; pp. 180–185. [Google Scholar] [CrossRef]
- Bai, C.; Sun, F.; Zhang, J.; Song, Y.; Chen, S. Rainformer: Features Extraction Balanced Network for Radar-Based Precipitation Nowcasting. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, X.; Guan, J.; Wu, M.; Guo, L. RN-Net: A Deep Learning Approach to 0–2 Hour Rainfall Nowcasting Based on Radar and Automatic Weather Station Data. Sensors 2021, 21, 1981. [Google Scholar] [CrossRef]
- Wu, W.; Zou, H.; Shan, J.; Wu, S. A Dynamical Z - R Relationship Precipitation Estimation Based Radar Echo-Top Height Classification. Adv. Meteorol. 2018, 2018, 8202031. [Google Scholar] [CrossRef] [Green Version]
- Pulkkinen, S.; Chandrasekar, V.; Harri, A.M. Fully Spectral Method for Radar-Based Precipitation Nowcasting. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1369–1382. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, X.; Guan, J. A Novel Multi-Input Multi-Output Recurrent Neural Network Based on Multimodal Fusion and Spatiotemporal Prediction for 0–4 Hour Precipitation Nowcasting. Atmosphere 2021, 12, 1596. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. arXiv 2019, arXiv:1709.01507. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. arXiv 2015, arXiv:1506.04214. [Google Scholar]
- Luo, C.; Li, X.; Ye, Y. PFST-LSTM: A SpatioTemporal LSTM Model with Pseudoflow Prediction for Precipitation Nowcasting. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 843–857. [Google Scholar] [CrossRef]
- Bouget, V.; Béréziat, D.; Brajard, J.; Charantonis, A.; Filoche, A. Fusion of Rain Radar Images and Wind Forecasts in a Deep Learning Model Applied to Rain Nowcasting. Remote Sens. 2021, 13, 246. [Google Scholar] [CrossRef]
- Zhou, K.; Zheng, Y.; Dong, W.; Wang, T. A Deep Learning Network for Cloud-to-Ground Lightning Nowcasting with Multisource Data. J. Atmos. Ocean. Technol. 2020, 37, 927–942. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Gao, Z.; Long, M.; Wang, J.; Yu, P.S. PredRNN++: Towards A Resolution of the Deep-in-Time Dilemma in Spatiotemporal Predictive Learning. arXiv 2018, arXiv:1804.06300. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Geng, Y.A.; Li, Q.; Lin, T.; Jiang, L.; Zhang, Y. LightNet: A Dual Spatiotemporal Encoder Network Model for Lightning Prediction. In Proceedings of the the 25th ACM SIGKDD International Conference, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Chang, Z.; Zhang, X.; Wang, S.; Ma, S.; Gao, W. STRPM: A Spatiotemporal Residual Predictive Model for High-Resolution Video Prediction. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 13926–13935. [Google Scholar]
- Weyn, J.A.; Durran, D.R.; Caruana, R. Improving data-driven global weather prediction using deep convolutional neural networks on a cubed sphere. J. Adv. Model. Earth Syst. 2020, 12, e2020MS002109. [Google Scholar] [CrossRef]
- Pan, X.; Lu, Y.; Zhao, K.; Huang, H.; Wang, M.; Chen, H. Improving Nowcasting of Convective Development by Incorporating Polarimetric Radar Variables Into a Deep-Learning Model. Geophys. Res. Lett. 2021, 48, e2021GL095302. [Google Scholar] [CrossRef]
- Wang, Y.Q. MeteoInfo: GIS software for meteorological data visualization and analysis. Meteorol. Appl. 2014, 21, 360–368. [Google Scholar] [CrossRef]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.Y.; Wong, W.k.; Woo, W.c. Deep Learning for Precipitation Nowcasting: A Benchmark and A New Model. arXiv 2017, arXiv:1706.03458. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Chintala, S. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Hogan, R.J.; Ferro, C.A.T.; Jolliffe, I.T.; Stephenson, D.B. Equitability Revisited: Why the “Equitable Threat Score” Is Not Equitable. Weather Forecast. 2010, 25, 710–726. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Wang, H.; Zeng, J.; Ma, L.; Guan, L. Short-Term Dynamic Radar Quantitative Precipitation Estimation Based on Wavelet Transform and Support Vector Machine. J. Meteorol. Res. 2020, 34, 413–426. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | 6-min Rainfall (mm) |
|---|---|
| Drizzle | [0, 0.1) |
| Light/moderate rain | [0.1, 0.7) |
| Heavy rain | [0.7, 1.5) |
| Rainstorm | [1.5, 4) |
| Downpour | [4, ∝) |
| Rainfall Levels | Rainfall Amount per Hour (mm) |
|---|---|
| No or hardly noticeable | [0, 0.5) |
| Light | [0.5, 2) |
| Light to moderate | [2, 5) |
| Moderate or greater | [5, ∝) |
| Method | r ≥ 0.5 mm/h | r ≥ 2.0 mm/h | r ≥ 5.0 mm/h | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CSI↑ | POD↑ | FAR↓ | HSS↑ | CSI↑ | POD↑ | FAR↓ | HSS↑ | CSI↑ | POD↑ | FAR↓ | HSS↑ | |
| ConvLSTM | 0.4169 | 0.4548 | 0.1570 | 0.2528 | 0.2767 | 0.3285 | 0.2365 | 0.1802 | 0.1210 | 0.1522 | 0.2477 | 0.0865 |
| PredRNN | 0.4140 | 0.4545 | 0.1549 | 0.2517 | 0.2740 | 0.3316 | 0.2758 | 0.1798 | 0.1254 | 0.1623 | 0.2719 | 0.0895 |
| MIM | 0.4328 | 0.4651 | 0.1323 | 0.2629 | 0.2847 | 0.3314 | 0.2534 | 0.1870 | 0.1182 | 0.1387 | 0.2124 | 0.0839 |
| SE-ResUNet | 0.4168 | 0.5536 | 0.3327 | 0.2496 | 0.2619 | 0.4248 | 0.4712 | 0.1720 | 0.1272 | 0.2427 | 0.4951 | 0.0919 |
| AF-SRNet | 0.5159 | 0.6511 | 0.3051 | 0.3071 | 0.3360 | 0.2499 | 0.4643 | 0.2178 | 0.1545 | 0.2499 | 0.4274 | 0.1073 |
| Method | r ≥ 0.5 mm/h | r ≥ 2.0 mm/h | r ≥ 5.0 mm/h | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CSI↑ | POD↑ | FAR↓ | HSS↑ | CSI↑ | POD↑ | FAR↓ | HSS↑ | CSI↑ | POD↑ | FAR↓ | HSS↑ | |
| ConvLSTM | 0.3436 | 0.3845 | 0.2324 | 0.2097 | 0.2097 | 0.2580 | 0.3076 | 0.1387 | 0.0803 | 0.1052 | 0.2827 | 0.0582 |
| PredRNN | 0.3436 | 0.3867 | 0.2236 | 0.2104 | 0.2114 | 0.2637 | 0.3249 | 0.1408 | 0.0872 | 0.1151 | 0.2933 | 0.0630 |
| MIM | 0.3531 | 0.3890 | 0.1987 | 0.2165 | 0.2110 | 0.2530 | 0.3023 | 0.1412 | 0.0798 | 0.0961 | 0.2536 | 0.0574 |
| SE-ResUNet | 0.3475 | 0.5395 | 0.4724 | 0.2079 | 0.2235 | 0.3827 | 0.6118 | 0.1577 | 0.1024 | 0.2217 | 0.6819 | 0.0790 |
| AF-SRNet | 0.4196 | 0.5438 | 0.3662 | 0.2507 | 0.2560 | 0.4049 | 0.5039 | 0.1673 | 0.1121 | 0.1944 | 0.4558 | 0.0792 |
| Method | r ≥ 0.5 mm/h | r ≥ 2.0 mm/h | r ≥ 5.0 mm/h | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CSI↑ | POD↑ | FAR↓ | HSS↑ | CSI↑ | POD↑ | FAR↓ | HSS↑ | CSI↑ | POD↑ | FAR↓ | HSS↑ | |
| STLSTM | 0.4140 | 0.4545 | 0.1549 | 0.2517 | 0.2740 | 0.3316 | 0.2758 | 0.1798 | 0.1254 | 0.1623 | 0.2719 | 0.0895 |
| AF-STLSTM | 0.5025 | 0.6143 | 0.2892 | 0.3016 | 0.3300 | 0.4579 | 0.4296 | 0.2156 | 0.1506 | 0.2212 | 0.4123 | 0.1060 |
| SRNet | 0.4957 | 0.5970 | 0.2791 | 0.2985 | 0.3243 | 0.4439 | 0.4364 | 0.2128 | 0.1465 | 0.2156 | 0.4422 | 0.1035 |
| AF-SRNet | 0.5159 | 0.6511 | 0.3051 | 0.3071 | 0.3360 | 0.2499 | 0.4643 | 0.2178 | 0.1545 | 0.2499 | 0.4274 | 0.1073 |
| Method | r ≥ 0.5 mm/h | r ≥ 2.0 mm/h | r ≥ 5.0 mm/h | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CSI↑ | POD↑ | FAR↓ | HSS↑ | CSI↑ | POD↑ | FAR↓ | HSS↑ | CSI↑ | POD↑ | FAR↓ | HSS↑ | |
| STLSTM | 0.3436 | 0.3867 | 0.2236 | 0.2104 | 0.2114 | 0.2637 | 0.3249 | 0.1408 | 0.0872 | 0.1151 | 0.2933 | 0.0630 |
| AF-STLSTM | 0.4113 | 0.5192 | 0.3794 | 0.2485 | 0.2532 | 0.3747 | 0.4903 | 0.1662 | 0.1071 | 0.1679 | 0.4587 | 0.0766 |
| SRNet | 0.3994 | 0.4935 | 0.3713 | 0.2424 | 0.2459 | 0.3541 | 0.4813 | 0.1633 | 0.1038 | 0.1623 | 0.4746 | 0.0745 |
| AF-SRNet | 0.4196 | 0.5438 | 0.3662 | 0.2507 | 0.2560 | 0.4049 | 0.5039 | 0.1673 | 0.1121 | 0.1944 | 0.4558 | 0.0792 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geng, L.; Geng, H.; Min, J.; Zhuang, X.; Zheng, Y. AF-SRNet: Quantitative Precipitation Forecasting Model Based on Attention Fusion Mechanism and Residual Spatiotemporal Feature Extraction. Remote Sens. 2022, 14, 5106. https://doi.org/10.3390/rs14205106
Geng L, Geng H, Min J, Zhuang X, Zheng Y. AF-SRNet: Quantitative Precipitation Forecasting Model Based on Attention Fusion Mechanism and Residual Spatiotemporal Feature Extraction. Remote Sensing. 2022; 14(20):5106. https://doi.org/10.3390/rs14205106
Chicago/Turabian StyleGeng, Liangchao, Huantong Geng, Jinzhong Min, Xiaoran Zhuang, and Yu Zheng. 2022. "AF-SRNet: Quantitative Precipitation Forecasting Model Based on Attention Fusion Mechanism and Residual Spatiotemporal Feature Extraction" Remote Sensing 14, no. 20: 5106. https://doi.org/10.3390/rs14205106
APA StyleGeng, L., Geng, H., Min, J., Zhuang, X., & Zheng, Y. (2022). AF-SRNet: Quantitative Precipitation Forecasting Model Based on Attention Fusion Mechanism and Residual Spatiotemporal Feature Extraction. Remote Sensing, 14(20), 5106. https://doi.org/10.3390/rs14205106