
Multi-Branch Adaptive Hard Region Mining Network for Urban Scene Parsing of High-Resolution Remote-Sensing Images


Abstract
:1. Introduction
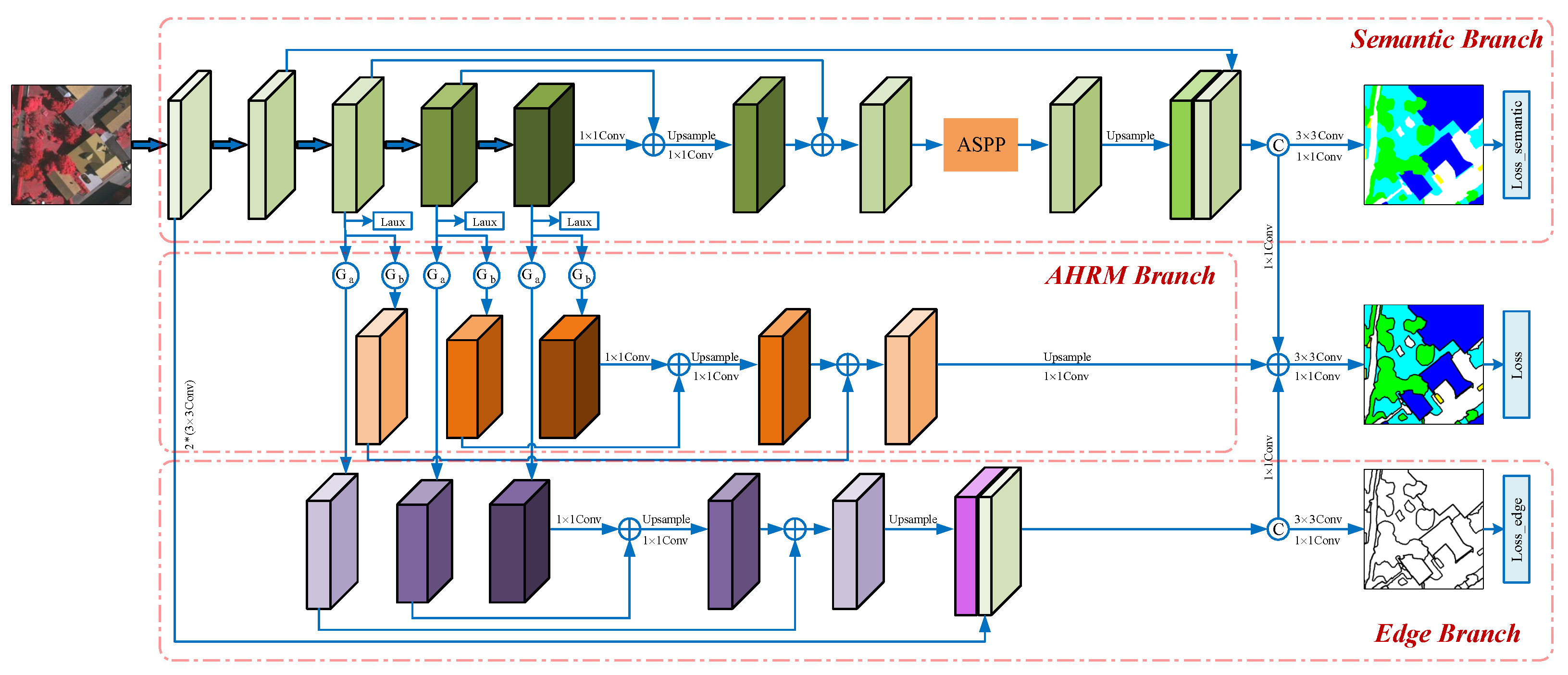
- A multi-branch adaptive hard region mining network is proposed to perform urban scene parsing of HRRSIs. It consists of a multi-scale semantic branch, an AHRM branch, and an edge-extraction branch. We performed experimental validation on two HRRSI datasets from ISPRS and obtained SOTA performance;
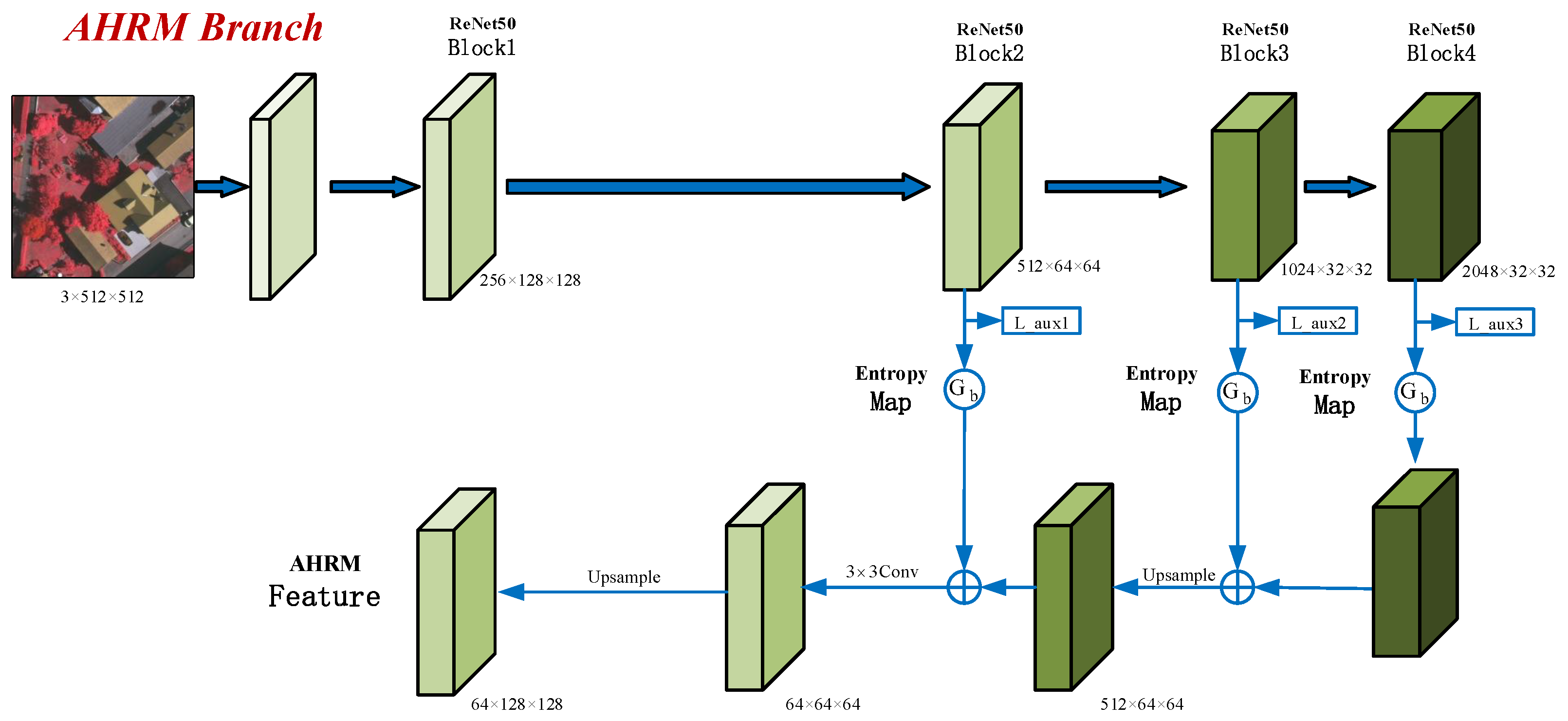
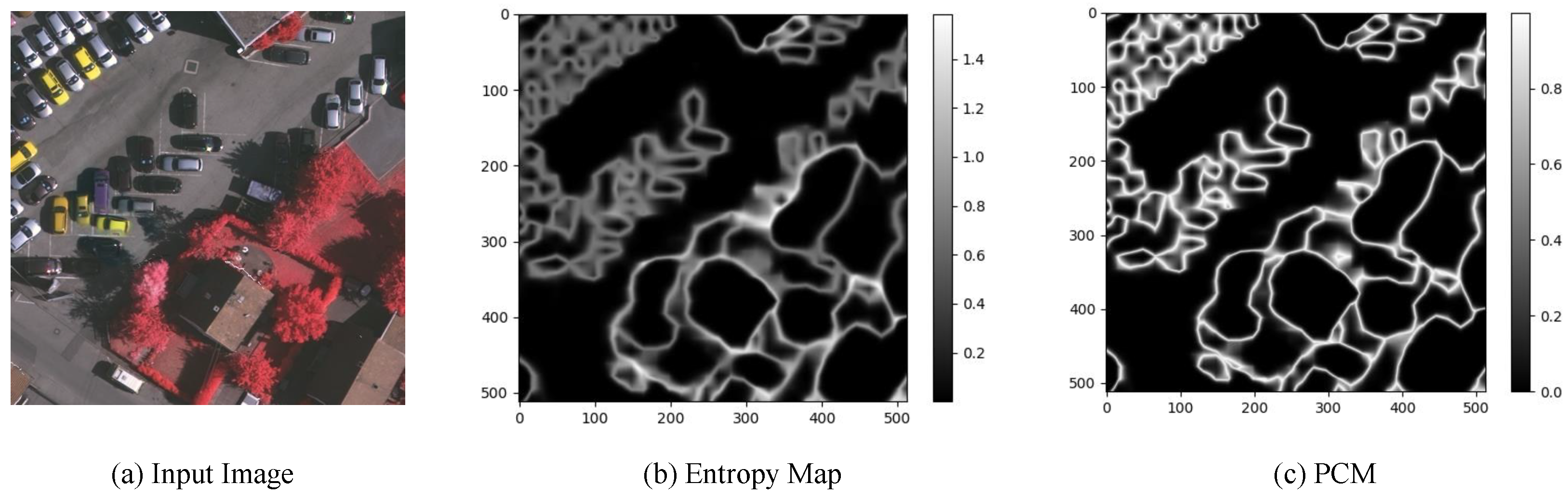
- A prediction uncertainty gating mechanism based on an entropy map is proposed. Then, an adaptive hard region mining branch is constructed based on this gating unit to adaptively mine hard regions in the images and extract their informative features;
- An edge-extraction branch is constructed using the gating unit based on the predicted confusion map to filter out most of the redundant information except edge features in the output of each block of ResNet, thereby qualitatively screening edge features. Finally, an edge loss is used to supervise its training explicitly.
2. Related Work
2.1. Multi-Scale Feature Extraction
2.2. Hard Region Mining
2.3. Edge Extraction
3. Methodology
3.1. The Framework of MBANet
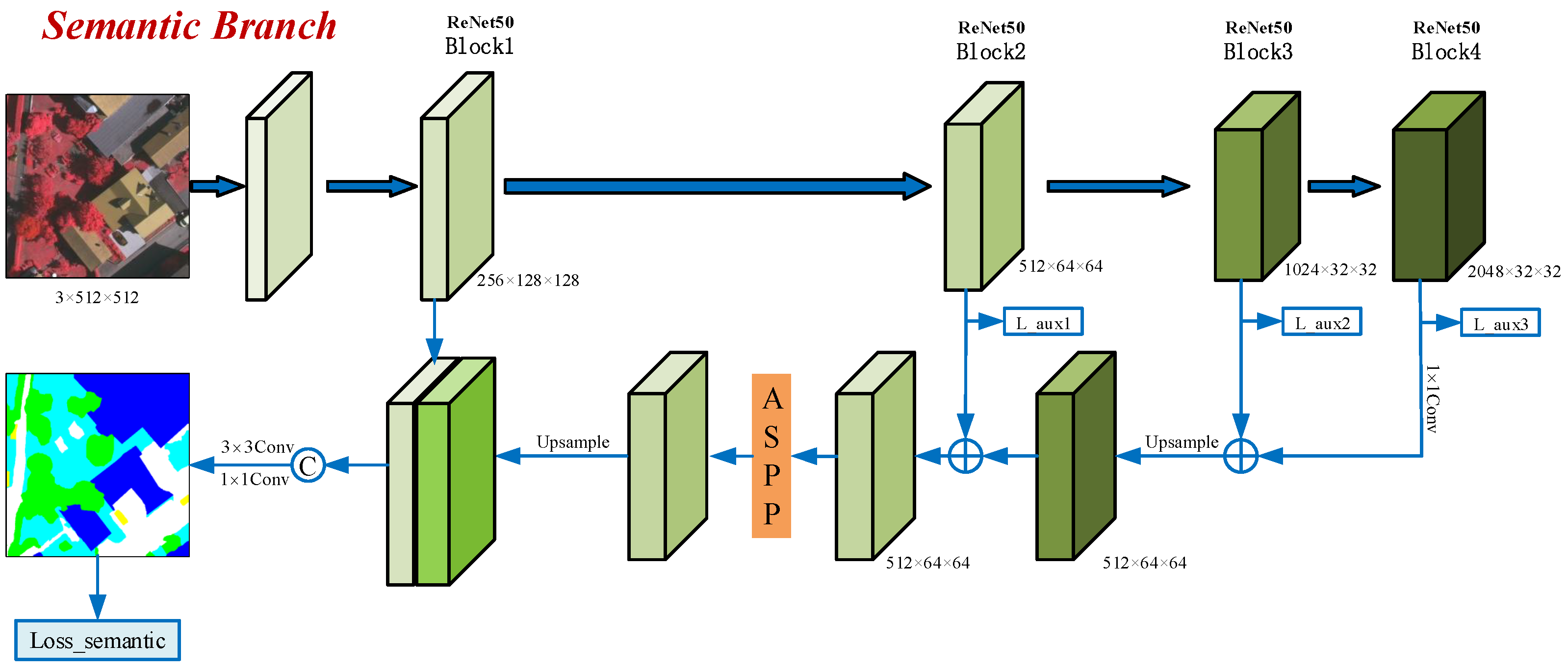
3.2. Semantic Branch
3.3. AHRM Branch
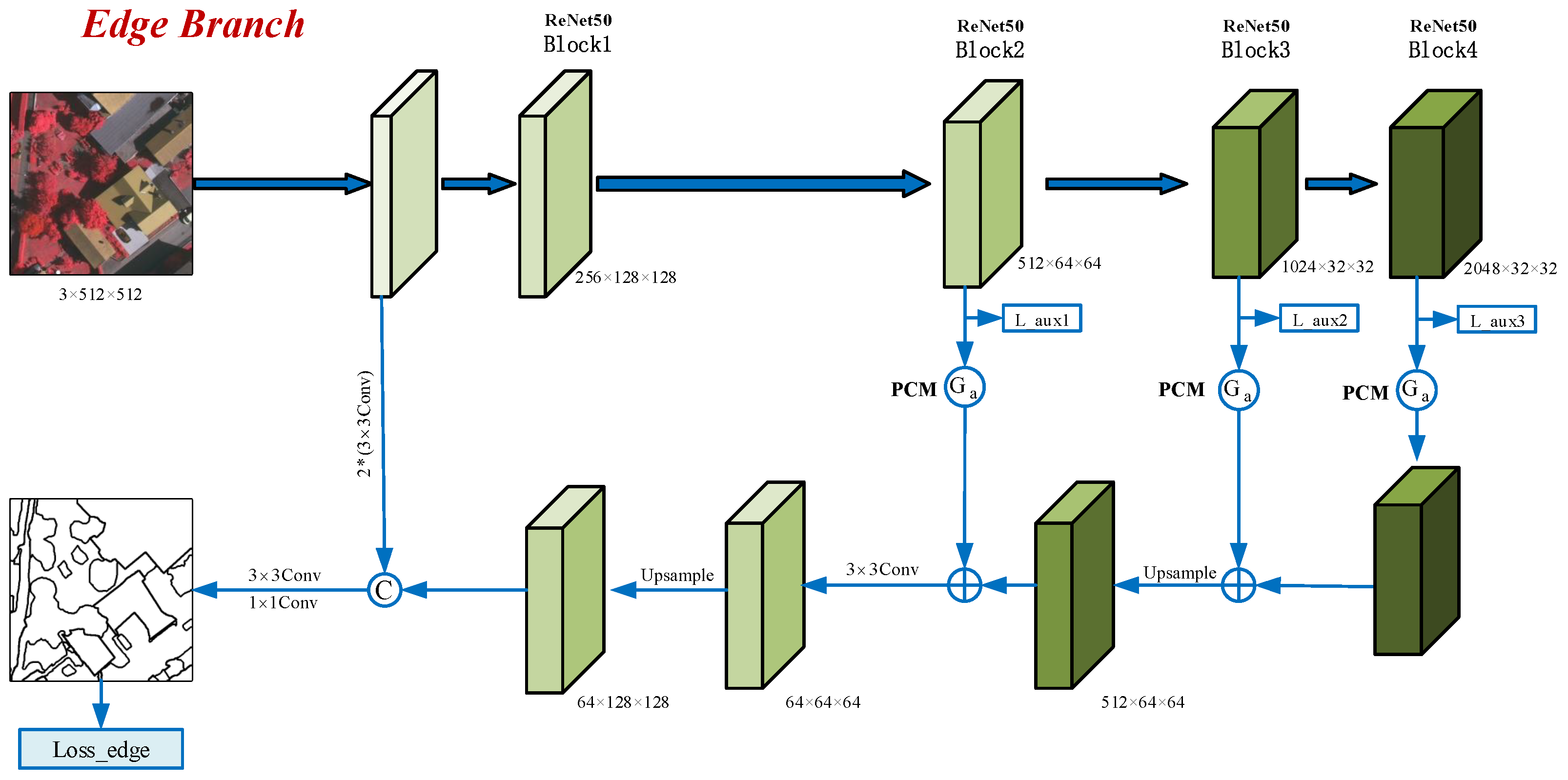
3.4. Edge Branch
3.5. Loss Function
4. Experiments and Results
4.1. Datasets
4.2. Experiment Setup
4.3. Ablation Study
4.3.1. Ablation Study for the Semantic Branch
4.3.2. Ablation Study for the AHRM Branch
4.3.3. Ablation Study for the Edge Branch
4.3.4. Integration of the Three Branches
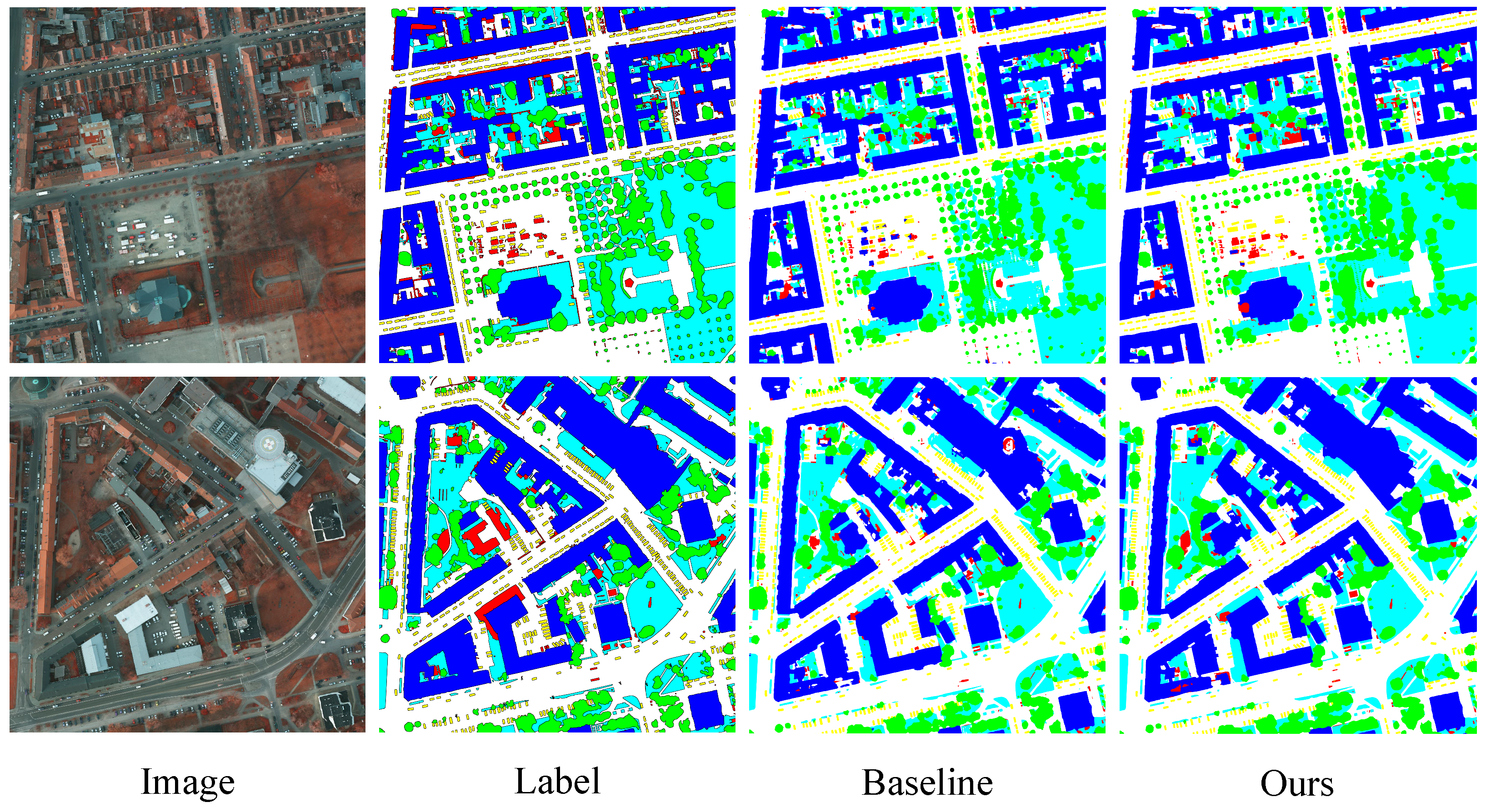
4.4. Comparison with Other SOTA Methods
4.5. Model Complexity Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Peng, D.; Zhang, Y.; Guan, H. End-to-end change detection for high resolution satellite images using improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef] [Green Version]
- Fang, B.; Pan, L.; Kou, R. Dual learning-based siamese framework for change detection using bi-temporal VHR optical remote sensing images. Remote Sens. 2019, 11, 1292. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Wu, C.; Du, B.; Zhang, L.; Wang, L. Change detection in multisource VHR images via deep siamese convolutional multiple-layers recurrent neural network. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2848–2864. [Google Scholar] [CrossRef]
- Willis, K. Remote sensing change detection for ecological monitoring in United States protected areas. Biol. Conserv. 2015, 182, 233–242. [Google Scholar] [CrossRef]
- Shan, W.; Jin, X.; Ren, J.; Wang, Y.; Xu, Z.; Fan, Y.; Gu, Z.; Hong, C.; Lin, J.; Zhou, Y. Ecological environment quality assessment based on remote sensing data for land consolidation. J. Clean. Prod. 2019, 239, 118126. [Google Scholar] [CrossRef]
- Boni, G.; De Angeli, S.; Taramasso, A.; Roth, G. Remote sensing-based methodology for the quick update of the assessment of the population exposed to natural hazards. Remote Sens. 2020, 12, 3943. [Google Scholar] [CrossRef]
- Gillespie, T.; Chu, J.; Frankenberg, E.; Thomas, D. Assessment and prediction of natural hazards from satellite imagery. Prog. Phys. Geogr. 2007, 31, 459–470. [Google Scholar] [CrossRef] [Green Version]
- Ehrlich, D.; Melchiorri, M.; Florczyk, A.; Pesaresi, M.; Kemper, T.; Corbane, C.; Freire, S.; Schiavina, M.; Siragusa, A. Remote sensing derived built-up area and population density to quantify global exposure to five natural hazards over time. Remote Sens. 2018, 10, 1378. [Google Scholar] [CrossRef] [Green Version]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic segmentation of urban buildings from VHR remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef] [Green Version]
- Grinias, I.; Panagiotakis, C.; Tziritas, G. MRF-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. Isprs J. Photogramm. Remote Sens. 2016, 122, 145–166. [Google Scholar] [CrossRef]
- Nezami, S.; Khoramshahi, E.; Nevalainen, O.; Pölönen, I.; Honkavaara, E. Tree species classification of drone hyperspectral and RGB imagery with deep learning convolutional neural networks. Remote Sens. 2020, 12, 1070. [Google Scholar] [CrossRef] [Green Version]
- Schiefer, F.; Kattenborn, T.; Frick, A.; Frey, J.; Schall, P.; Koch, B.; Schmidtlein, S. Mapping forest tree species in high resolution UAV-based RGB-imagery by means of convolutional neural networks. Isprs J. Photogramm. Remote Sens. 2020, 170, 205–215. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zheng, X.; Huan, L.; Xia, G.; Gong, J. Parsing very high resolution urban scene images by learning deep ConvNets with edge-aware loss. Isprs J. Photogramm. Remote Sens. 2020, 170, 15–28. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Chen, F.; Liu, H.; Zeng, Z.; Zhou, X.; Tan, X. BES-Net: Boundary Enhancing Semantic Context Network for High-Resolution Image Semantic Segmentation. Remote Sens. 2022, 14, 1638. [Google Scholar] [CrossRef]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. Pointrend: Image segmentation as rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9799–9808. [Google Scholar]
- Kim, S.; Kook, H.; Sun, J.; Kang, M.; Ko, S. Parallel feature pyramid network for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 234–250. [Google Scholar]
- Cao, J.; Chen, Q.; Guo, J.; Shi, R. Attention-guided context feature pyramid network for object detection. arXiv 2020, arXiv:2005.11475. [Google Scholar]
- Li, X.; Lai, T.; Wang, S.; Chen, Q.; Yang, C.; Chen, R.; Lin, J.; Zheng, F. Weighted feature pyramid networks for object detection. In Proceedings of the 2019 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Xiamen, China, 16–18 December 2019; pp. 1500–1504. [Google Scholar]
- Li, X.; Zhao, H.; Han, L.; Tong, Y.; Tan, S.; Yang, K. Gated fully fusion for semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11418–11425. [Google Scholar]
- Ye, M.; Ouyang, J.; Chen, G.; Zhang, J.; Yu, X. Enhanced Feature Pyramid Network for Semantic Segmentation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3209–3216. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yu, B.; Yang, L.; Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, C.; Ding, M.; Li, J. Real-time dense semantic labeling with dual-Path framework for high-resolution remote sensing image. Remote Sens. 2019, 11, 3020. [Google Scholar] [CrossRef] [Green Version]
- Bai, Y.; Hu, J.; Su, J.; Liu, X.; Liu, H.; He, X.; Meng, S.; Mas, E.; Koshimura, S. Pyramid pooling module-based semi-siamese network: A benchmark model for assessing building damage from xBD satellite imagery datasets. Remote Sens. 2020, 12, 4055. [Google Scholar] [CrossRef]
- Su, Y.; Cheng, J.; Bai, H.; Liu, H.; He, C. Semantic Segmentation of Very-High-Resolution Remote Sensing Images via Deep Multi-Feature Learning. Remote Sens. 2022, 14, 533. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Online batch selection for faster training of neural networks. arXiv 2015, arXiv:1511.06343. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. OCNet: Object context for semantic segmentation. Int. J. Comput. Vis. 2021, 129, 2375–2398. [Google Scholar] [CrossRef]
- Li, X.; Liu, Z.; Luo, P.; Change Loy, C.; Tang, X. Not all pixels are equal: Difficulty-aware semantic segmentation via deep layer cascade. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3193–3202. [Google Scholar]
- Yin, J.; Xia, P.; He, J. Online hard region mining for semantic segmentation. Neural Process. Lett. 2019, 50, 2665–2679. [Google Scholar] [CrossRef]
- Li, X.; Li, T.; Chen, Z.; Zhang, K.; Xia, R. Attentively Learning Edge Distributions for Semantic Segmentation of Remote Sensing Imagery. Remote Sens. 2021, 14, 102. [Google Scholar] [CrossRef]
- Sun, X.; Xia, M.; Dai, T. Controllable Fused Semantic Segmentation with Adaptive Edge Loss for Remote Sensing Parsing. Remote Sens. 2022, 14, 207. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Song, R.; Wu, C.; Liu, W.; Li, Z.; Li, Y. Edge Guided Context Aggregation Network for Semantic Segmentation of Remote Sensing Imagery. Remote Sens. 2022, 14, 1353. [Google Scholar] [CrossRef]
- Pan, S.; Tao, Y.; Nie, C.; Chong, Y. PEGNet: Progressive edge guidance network for semantic segmentation of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 637–641. [Google Scholar] [CrossRef]
- Nong, Z.; Su, X.; Liu, Y.; Zhan, Z.; Yuan, Q. Boundary-Aware Dual-Stream Network for VHR Remote Sensing Images Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5260–5268. [Google Scholar] [CrossRef]
- Jung, H.; Choi, H.; Kang, M. Boundary enhancement semantic segmentation for building extraction from remote sensed image. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5215512. [Google Scholar] [CrossRef]
- He, C.; Li, S.; Xiong, D.; Fang, P.; Liao, M. Remote sensing image semantic segmentation based on edge information guidance. Remote Sens. 2020, 12, 1501. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, W.; Zhao, Q. Semantic segmentation of aerial imagery via split-attention networks with disentangled nonlocal and edge supervision. Remote Sens. 2021, 13, 1176. [Google Scholar] [CrossRef]
- Zhuang, C.; Yuan, X.; Wang, W. Boundary enhanced network for improved semantic segmentation. In Proceedings of the International Conference on Urban Intelligence and Applications, Taiyuan, China, 14–16 August2020; pp. 172–184. [Google Scholar]
- Liu, S.; Ding, W.; Liu, C.; Liu, Y.; Wang, Y.; Li, H. ERN: Edge loss reinforced semantic segmentation network for remote sensing images. Remote Sens. 2018, 10, 1339. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Huan, L.; Xiong, H.; Gong, J. ELKPPNet: An edge-aware neural network with large kernel pyramid pooling for learning discriminative features in semantic segmentation. arXiv 2019, arXiv:1906.11428. [Google Scholar]
- Bai, H.; Cheng, J.; Su, Y.; Liu, S.; Liu, X. Calibrated Focal Loss for Semantic Labeling of High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6531–6547. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D. Dense semantic labeling of subdecimeter resolution images with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 55, 881–893. [Google Scholar] [CrossRef] [Green Version]
- Marcos, D.; Volpi, M.; Kellenberger, B.; Tuia, D. Land cover mapping at very high resolution with rotation equivariant CNNs: Towards small yet accurate models. Isprs J. Photogramm. Remote Sens. 2018, 145, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Hua, Y.; Zhu, X. Relation matters: Relational context-aware fully convolutional network for semantic segmentation of high-resolution aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7557–7569. [Google Scholar] [CrossRef]
- Nogueira, K.; Dalla Mura, M.; Chanussot, J.; Schwartz, W.; Dos Santos, J. Dynamic multicontext segmentation of remote sensing images based on convolutional networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7503–7520. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. Isprs J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Schindler, K.; Wegner, J.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. Isprs J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- Yue, K.; Yang, L.; Li, R.; Hu, W.; Zhang, F.; Li, W. TreeUNet: Adaptive tree convolutional neural networks for subdecimeter aerial image segmentation. Isprs J. Photogramm. Remote Sens. 2019, 156, 1–13. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhang, F.; Chen, Y.; Li, Z.; Hong, Z.; Liu, J.; Ma, F.; Han, J.; Ding, E. Acfnet: Attentional class feature network for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6798–6807. [Google Scholar]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. Isprs J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer, Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Ding, L.; Zhang, J.; Bruzzone, L. Semantic segmentation of large-size VHR remote sensing images using a two-stage multiscale training architecture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5367–5376. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, X.; Xin, Q.; Huang, J. Developing a multi-filter convolutional neural network for semantic segmentation using high-resolution aerial imagery and LiDAR data. Isprs J. Photogramm. Remote Sens. 2018, 143, 3–14. [Google Scholar] [CrossRef]
- Sun, Y.; Tian, Y.; Xu, Y. Problems of encoder-decoder frameworks for high-resolution remote sensing image segmentation: Structural stereotype and insufficient learning. Neurocomputing 2019, 330, 297–304. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Vaihingen | Potsdam | ||
|---|---|---|---|---|
| Size | ||||
| GSD | 9 cm | 5 cm | ||
| Wave Bands | NIR, R, G | NIR, R, G, B | ||
| Scenes | Small Village | Large City | ||
| Train | Test | Train | Test | |
| Original Images | 16 | 17 | 24 | 14 |
| Small Patches | 705 | 398 | 7776 | 2016 |
| Operating System | Ubuntu 18.04.5 LTS | GPU | GeForce RTX 3090 (24 G) |
| DeepLearning Framework | Pytorch-1.7 | Batch Size | 8 |
| Training Epoch | 100 | Optimizer | SGD () |
| Vaihingen | Potsdam | ||
| Learning Rate | 0.01 | 0.005 |
| Imp. Surf. | Build | Low Veg. | Tree | Car | Mean | OA | Memory Usage | |
|---|---|---|---|---|---|---|---|---|
| FCN | 91.04 | 94.19 | 81.92 | 88.13 | 79.13 | 86.88 | 88.91 | 16,980 M |
| DeepLab v3+ | 91.37 | 94.18 | 82.79 | 88.75 | 83.67 | 88.15 | 89.39 | 18,696 M |
| Semantic Branch | 92.03 | 95.11 | 83.46 | 89.10 | 82.58 | 88.46 | 90.02 | 10,005 M |
| IoU | mIoU | |||||||
| FCN | 83.56 | 89.02 | 69.38 | 78.77 | 65.47 | 77.87 | 88.91 | - |
| DeepLab v3+ | 84.12 | 89.01 | 70.63 | 79.77 | 71.93 | 79.64 | 89.39 | - |
| Semantic Branch | 85.23 | 90.68 | 71.62 | 80.35 | 70.32 | 80.34 | 90.02 | - |
| Imp. Surf. | Build | Low Veg. | Tree | Car | Mean | OA | |
|---|---|---|---|---|---|---|---|
| Semantic Branch | 92.03 | 95.11 | 83.46 | 89.10 | 82.58 | 88.46 | 90.02 |
| Semantic Branch with Deep Supervision | 92.55 | 95.48 | 83.64 | 88.92 | 82.82 | 88.68 | 90.28 |
| IoU | mIoU | ||||||
| Semantic Branch | 85.23 | 90.68 | 71.62 | 80.35 | 70.32 | 80.34 | 90.02 |
| Semantic Branch with Deep Supervision | 86.12 | 91.36 | 71.88 | 80.05 | 70.67 | 80.64 | 90.28 |
| Imp. Surf. | Build | Low Veg. | Tree | Car | Mean | OA | Memory Usage | |
|---|---|---|---|---|---|---|---|---|
| Semantic Branch | 92.55 | 95.48 | 83.64 | 88.92 | 82.82 | 88.68 | 90.28 | 10,005 M |
| + AHRM without gate | 92.32 | 95.42 | 83.85 | 89.15 | 83.41 | 88.83 | 90.32 | - |
| + AHRM with gate | 92.85 | 95.59 | 84.22 | 89.25 | 83.17 | 89.02 | 90.61 | 10,786 M |
| IoU | mIoU | |||||||
| Semantic Branch | 86.12 | 91.36 | 71.88 | 80.05 | 70.67 | 80.64 | 90.28 | - |
| + AHRM without gate | 85.73 | 91.24 | 72.19 | 80.42 | 71.54 | 80.79 | 90.32 | - |
| + AHRM with gate | 86.66 | 91.55 | 72.73 | 80.59 | 71.19 | 81.11 | 90.61 | - |
| Imp. Surf. | Build | Low Veg. | Tree | Car | Mean | OA | Memory Usage | |
|---|---|---|---|---|---|---|---|---|
| Semantic Branch | 92.55 | 95.48 | 83.64 | 88.92 | 82.82 | 88.68 | 90.28 | 10,005 M |
| + edge without gate | 92.41 | 95.29 | 84.25 | 88.96 | 83.68 | 88.92 | 90.34 | - |
| + edge with gate | 92.62 | 95.43 | 84.33 | 89.28 | 84.11 | 89.15 | 90.56 | 11,190 M |
| IoU | mIoU | |||||||
| Semantic Branch | 86.12 | 91.36 | 71.88 | 80.05 | 70.67 | 80.64 | 90.28 | - |
| + edge without gate | 85.89 | 91.00 | 72.79 | 80.12 | 71.94 | 80.91 | 90.34 | - |
| + edge with gate | 86.26 | 91.26 | 72.90 | 80.63 | 72.58 | 81.22 | 90.56 | - |
| Imp. Surf. | Build | Low Veg. | Tree | Car | Mean | OA | |
|---|---|---|---|---|---|---|---|
| 92.40 | 95.37 | 83.31 | 88.93 | 82.16 | 88.43 | 90.18 | |
| 92.57 | 95.39 | 84.66 | 89.32 | 83.03 | 89.00 | 90.59 | |
| 92.81 | 95.56 | 84.49 | 89.37 | 82.78 | 89.00 | 90.70 | |
| 93.02 | 95.63 | 84.74 | 89.38 | 84.58 | 89.47 | 90.82 | |
| 92.65 | 95.40 | 84.14 | 89.24 | 84.60 | 89.20 | 90.50 | |
| 92.69 | 95.46 | 83.75 | 89.14 | 84.42 | 89.09 | 90.44 | |
| 92.71 | 95.35 | 83.60 | 88.86 | 82.93 | 88.69 | 90.31 | |
| 89.94 | 92.72 | 82.07 | 88.08 | 63.73 | 83.31 | 88.11 | |
| IoU | mIoU | ||||||
| 85.87 | 91.14 | 71.40 | 80.07 | 69.72 | 80.16 | 90.18 | |
| 86.17 | 91.18 | 73.41 | 80.71 | 70.98 | 80.97 | 90.59 | |
| 86.57 | 91.50 | 73.15 | 80.79 | 70.62 | 81.02 | 90.70 | |
| 86.95 | 91.62 | 73.53 | 80.81 | 73.28 | 81.81 | 90.82 | |
| 86.30 | 91.20 | 72.62 | 80.56 | 73.31 | 81.35 | 90.50 | |
| 86.38 | 91.31 | 72.04 | 80.41 | 73.05 | 81.18 | 90.44 | |
| 86.41 | 91.11 | 71.83 | 79.95 | 70.84 | 80.65 | 90.31 | |
| 81.72 | 86.43 | 69.60 | 78.69 | 46.77 | 73.76 | 88.11 |
| Imp. Surf. | Build | Low Veg. | Tree | Car | Mean | OA | Memory Usage | |
|---|---|---|---|---|---|---|---|---|
| FCN | 91.04 | 94.19 | 81.92 | 88.13 | 79.13 | 86.88 | 88.91 | 16,980 M |
| Semantic Branch | 92.55 | 95.48 | 83.64 | 88.92 | 82.82 | 88.68 | 90.28 | 10,005 M |
| + AHRM | 92.85 | 95.59 | 84.22 | 89.25 | 83.17 | 89.02 | 90.61 | 10,786 M |
| + edge | 92.62 | 95.43 | 84.33 | 89.28 | 84.11 | 89.15 | 90.56 | 11,190 M |
| MBANet | 93.02 | 95.63 | 84.74 | 89.38 | 84.58 | 89.47 | 90.82 | 11,592 M |
| IoU | mIoU | |||||||
| FCN | 83.56 | 89.02 | 69.38 | 78.77 | 65.47 | 77.87 | 88.91 | - |
| Semantic Branch | 86.12 | 91.36 | 71.88 | 80.05 | 70.67 | 80.64 | 90.28 | - |
| + AHRM | 86.66 | 91.55 | 72.73 | 80.59 | 71.19 | 81.11 | 90.61 | - |
| + edge | 86.26 | 91.26 | 72.90 | 80.63 | 72.58 | 81.22 | 90.56 | - |
| MBANet | 86.95 | 91.62 | 73.53 | 80.81 | 73.28 | 81.81 | 90.82 | - |
| Imp. Surf. | Build | Low Veg. | Tree | Car | Mean | OA | ||
|---|---|---|---|---|---|---|---|---|
| Baseline | 92.25 | 95.67 | 85.94 | 87.37 | 94.08 | 57.40 | 85.45 | 89.73 |
| MBANet | 93.20 | 96.78 | 87.12 | 88.36 | 95.64 | 61.78 | 87.15 | 90.87 |
| IoU | mIoU | |||||||
| Baseline | 85.61 | 91.71 | 75.35 | 77.57 | 88.82 | 40.25 | 76.55 | 89.73 |
| MBANet | 87.26 | 93.76 | 77.18 | 79.15 | 91.65 | 44.69 | 78.95 | 90.87 |
| SW | MS | Flip | Imp. Surf. | Build | Low Veg. | Tree | Car | Mean | OA | |
|---|---|---|---|---|---|---|---|---|---|---|
| Base | 93.02 | 95.63 | 84.74 | 89.38 | 84.58 | 89.47 | 90.82 | |||
| SW | ✓ | 93.26 | 95.74 | 85.01 | 89.91 | 86.34 | 90.05 | 91.18 | ||
| SW + MS | ✓ | ✓ | 93.56 | 96.02 | 85.75 | 90.34 | 87.95 | 90.72 | 91.59 | |
| SW + Flip | ✓ | ✓ | 93.44 | 95.95 | 85.60 | 90.43 | 87.63 | 90.61 | 91.53 | |
| SW + MS + Flip | ✓ | ✓ | ✓ | 93.60 | 96.14 | 86.19 | 90.77 | 88.33 | 91.01 | 91.82 |
| IoU | mIoU | |||||||||
| Base | 86.95 | 91.62 | 73.53 | 80.81 | 73.28 | 81.81 | 90.82 | |||
| SW | ✓ | 87.37 | 91.83 | 73.93 | 81.67 | 75.97 | 82.15 | 91.18 | ||
| SW + MS | ✓ | ✓ | 87.89 | 92.35 | 75.05 | 82.39 | 78.49 | 83.24 | 91.59 | |
| SW + Flip | ✓ | ✓ | 87.68 | 92.21 | 74.82 | 82.53 | 77.98 | 83.04 | 91.53 | |
| SW + MS + Flip | ✓ | ✓ | ✓ | 87.97 | 92.56 | 75.73 | 83.10 | 79.10 | 83.69 | 91.82 |
| SW | MS | Flip | Imp. Surf. | Build | Low Veg. | Tree | Car | Mean | OA | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Base | 93.20 | 96.78 | 87.12 | 88.36 | 95.64 | 61.78 | 87.15 | 90.87 | |||
| SW | ✓ | 93.57 | 96.97 | 87.72 | 89.00 | 95.88 | 62.87 | 92.63 | 91.31 | ||
| SW + MS | ✓ | ✓ | 93.83 | 97.15 | 88.15 | 89.16 | 96.30 | 64.19 | 92.92 | 91.62 | |
| SW + Flip | ✓ | ✓ | 93.92 | 97.16 | 88.40 | 89.48 | 96.31 | 64.24 | 93.06 | 91.75 | |
| SW + MS + Flip | ✓ | ✓ | ✓ | 94.04 | 97.23 | 88.65 | 89.57 | 96.63 | 64.77 | 93.22 | 91.90 |
| IoU | mIoU | ||||||||||
| Base | 87.26 | 93.76 | 77.18 | 79.15 | 91.65 | 44.69 | 78.95 | 90.87 | |||
| SW | ✓ | 87.92 | 94.12 | 78.12 | 80.18 | 92.09 | 45.85 | 86.49 | 91.31 | ||
| SW + MS | ✓ | ✓ | 88.38 | 94.45 | 78.82 | 80.45 | 92.87 | 47.27 | 86.99 | 91.62 | |
| SW + Flip | ✓ | ✓ | 88.54 | 94.48 | 79.22 | 80.97 | 92.88 | 47.32 | 87.22 | 91.75 | |
| SW + MS + Flip | ✓ | ✓ | ✓ | 88.76 | 94.60 | 79.61 | 81.1 | 93.48 | 47.89 | 87.51 | 91.90 |
| Method | Imp. Surf. | Build | Low Veg. | Tree | Car | Mean | mIoU | OA |
|---|---|---|---|---|---|---|---|---|
| UZ_1 [51] | 89.2 | 92.5 | 81.6 | 86.9 | 57.3 | 81.5 | - | 87.3 |
| RoteEqNet [52] | 89.5 | 94.8 | 77.5 | 86.5 | 72.6 | 84.2 | - | 87.5 |
| S-RA-FCN [53] | 91.5 | 95.0 | 80.6 | 88.6 | 87.1 | 88.5 | 79.8 | 89.2 |
| U-FMG-4 [54] | 91.1 | 94.5 | 82.9 | 88.8 | 81.3 | 87.7 | - | 89.4 |
| V-FuseNet [55] | 92.0 | 94.4 | 84.5 | 89.9 | 86.3 | 89.4 | - | 90.0 |
| DLR_9 [56] | 92.4 | 95.2 | 83.9 | 89.9 | 81.2 | 88.5 | - | 90.3 |
| TreeUNet [57] | 92.5 | 94.9 | 83.6 | 89.6 | 85.9 | 89.3 | - | 90.4 |
| DANet [58] | 91.6 | 95.0 | 83.3 | 88.9 | 87.2 | 89.2 | 81.3 | 90.4 |
| PSPNet [30] | 92.8 | 95.5 | 84.5 | 89.9 | 88.6 | 90.3 | 82.6 | 90.9 |
| ACFNet [59] | 92.9 | 95.3 | 84.5 | 90.1 | 88.6 | 90.3 | 82.7 | 90.9 |
| BKHN11 | 92.9 | 96.0 | 84.6 | 89.9 | 88.6 | 90.4 | - | 91.0 |
| CASIA2 [60] | 93.2 | 96.0 | 84.7 | 89.9 | 86.7 | 90.1 | - | 91.1 |
| CCNet [61] | 93.3 | 95.5 | 85.1 | 90.3 | 88.7 | 90.6 | 82.8 | 91.1 |
| BES-Net [22] | 93.0 | 96.0 | 85.4 | 90.0 | 88.3 | 90.6 | - | 91.2 |
| MBANet | 93.6 | 96.1 | 86.2 | 90.8 | 88.3 | 91.0 | 83.7 | 91.8 |
| Method | Imp. Surf. | Build | Low Veg. | Tree | Car | Mean | mIoU | OA |
|---|---|---|---|---|---|---|---|---|
| UZ_1 [51] | 89.3 | 95.4 | 81.8 | 80.5 | 86.5 | 86.7 | - | 85.8 |
| U-FMG-4 [54] | 90.8 | 95.6 | 84.4 | 84.3 | 92.4 | 89.5 | - | 87.9 |
| S-RA-FCN [53] | 91.3 | 94.7 | 86.8 | 83.5 | 94.5 | 90.2 | 82.4 | 88.6 |
| V-FuseNet [55] | 92.7 | 96.3 | 87.3 | 88.5 | 95.4 | 92.0 | - | 90.6 |
| TSMTA [62] | 92.9 | 97.1 | 87.0 | 87.3 | 95.2 | 91.9 | - | 90.6 |
| Multi-filter CNN [63] | 90.9 | 96.8 | 76.3 | 73.4 | 88.6 | 85.2 | - | 90.7 |
| TreeUNet [57] | 93.1 | 97.3 | 86.6 | 87.1 | 95.8 | 92.0 | - | 90.7 |
| CASIA3 [60] | 93.4 | 96.8 | 87.6 | 88.3 | 96.1 | 92.4 | - | 91.0 |
| PSPNet [30] | 93.4 | 97.0 | 87.8 | 88.5 | 95.4 | 92.4 | 84.9 | 91.1 |
| BKHN3 | 93.3 | 97.2 | 88.0 | 88.5 | 96.0 | 92.6 | - | 91.1 |
| AMA_1 | 93.4 | 96.8 | 87.7 | 88.8 | 96.0 | 92.5 | - | 91.2 |
| BES-Net [22] | 93.9 | 97.3 | 87.9 | 88.5 | 96.5 | 92.8 | - | 91.4 |
| CCNet [61] | 93.6 | 96.8 | 86.9 | 88.6 | 96.2 | 92.4 | 85.7 | 91.5 |
| HUSTW4 [64] | 93.6 | 97.6 | 88.5 | 88.8 | 94.6 | 92.6 | - | 91.6 |
| SWJ_2 | 94.4 | 97.4 | 87.8 | 87.6 | 94.7 | 92.4 | - | 91.7 |
| MBANet | 94.0 | 97.2 | 88.7 | 89.6 | 96.6 | 93.2 | 87.5 | 91.9 |
| Model | Backbone | Params. (M) | Macs (G) |
|---|---|---|---|
| FCN | ResNet50/os = 8 | 28.23 | 119.39 |
| PSPNet | ResNet50/os = 8 | 28.29 | 133.6 |
| DANet | ResNet50/os = 8 | 36.66 | 164.75 |
| DeepLab v3 | ResNet50/os = 8 | 40.23 | 166.39 |
| DeepLab v3+ | ResNet50/os = 8 | 40.35 | 182.94 |
| MBANet | ResNet50/os = 16 | 60.66 | 102.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, H.; Cheng, J.; Su, Y.; Wang, Q.; Han, H.; Zhang, Y. Multi-Branch Adaptive Hard Region Mining Network for Urban Scene Parsing of High-Resolution Remote-Sensing Images. Remote Sens. 2022, 14, 5527. https://doi.org/10.3390/rs14215527
Bai H, Cheng J, Su Y, Wang Q, Han H, Zhang Y. Multi-Branch Adaptive Hard Region Mining Network for Urban Scene Parsing of High-Resolution Remote-Sensing Images. Remote Sensing. 2022; 14(21):5527. https://doi.org/10.3390/rs14215527
Chicago/Turabian StyleBai, Haiwei, Jian Cheng, Yanzhou Su, Qi Wang, Haoran Han, and Yijie Zhang. 2022. "Multi-Branch Adaptive Hard Region Mining Network for Urban Scene Parsing of High-Resolution Remote-Sensing Images" Remote Sensing 14, no. 21: 5527. https://doi.org/10.3390/rs14215527
APA StyleBai, H., Cheng, J., Su, Y., Wang, Q., Han, H., & Zhang, Y. (2022). Multi-Branch Adaptive Hard Region Mining Network for Urban Scene Parsing of High-Resolution Remote-Sensing Images. Remote Sensing, 14(21), 5527. https://doi.org/10.3390/rs14215527