In this section, we will first introduce the proposed residual activity factor, then explain the overall network framework in detail, and finally analyse the working principle of the fully connected beta network.
2.1. Residual Activity Factor
Residual learning has proven its effectiveness in image feature extraction and fusion [
47,
49]. Although fusion networks that include residual blocks have achieved good results, their workings and operational speed still deserve more attention. In fact, using the cross-layer connection strategy used by Dense Block in SpeNet with good performance leads to the increase of network data buffer, which not only increases the computation, but also consumes a large amount of memory in the GPU. Therefore, we first consider the ResNet [
55] structure instead of Dense Block to improve the synthesis speed.
Residual learning is one of the most used network structures in deep learning networks, relying on ‘shortcut connections’ to achieve a very good fit. Formally, denoting the desired underlying mapping as
(an underlying mapping to be fit by a few stacked layers), with
x denoting the inputs to the first of these layers. Multiple nonlinear layers can asymptotically approximate a residual function
. So the desired underlying mapping
can be expressed as Equation (
1).
We suppose that the residual mapping
F to be learned is independent of the number of layers rather considering it as a function
with
is the weight matrix layers for a given block. In general, the residual connection directly outputs the input feature
x to
, and
learns the tiny residual feature between
x and
. Compared with the network structure of the VGG [
56] tiled convolutional layer, residual learning can better transfer the features extracted by the previous network layer to the subsequent network layers. Unlike extracting features from a single natural image, the core process of hyperspectral image fusion is the spatial-spectral fusion of a three-dimensional data cube stitched together from upsampled multichannel hyperspectral images and multispectral images (RGB images). Therefore, the problem we are dealing with can be transformed into: extracting the features of the data block formed by the connection of the LR-HSI upsampled with the HR-MSI. The traditional CS-based and MRA-based methods accomplish the task by extracting the spatial information of the multispectral image (HR-MSI) and adding it to the blurred hyperspectral image (LR-HSI). Inspired by this, we analogize the form of residual network, assuming that the upsampled LR-HSI represents
x and HR-MSI represents
. It is worth noting that HR-MSI is no longer the meaning of residuals. This is a fusion problem of fusing data from two different distributions. Further, we hope that the two kinds of data are in the same order of magnitude as possible as shown Equation (
2).
where
is
norm of a vector, to quantitatively analyze the performance of the residual learning block, we define
to denote the activity of residual learning as Equation (
3).
This can be understood as a restriction on LR-HSI and HR-MSI data in the process of feature extraction. Indirectly, it is also possible to determine whether the input and output of the residual block are of one magnitude. As shown in
Figure 1, when
, the structure of the network is similar to the residual module, which extracts hyperspectral information from x and spatial information of the same magnitude from F(x), respectively. When
, the learning ability of the residual decreases sharply. For the residual module, the network will degenerate into the VGG-Net structure, which is equivalent to considering more spatial information in HR-MSI while ignoring the hyperspectral information in LR-HSI. When
, the residual learning block degenerates to a constant mapping with infinite learning activity, and the residual fraction does not learn any knowledge and has a learning capacity of 0. At this point, the fusion process did not learn any spatial information from HR-MSI.
According to our definition of the residual activity factor, the residual learning block has an activity value of approximately 1.0 when the magnitudes of the extracted spatial information and inter-spectral information are not particularly significant. In order to verify the effectiveness of the residual activity factor, we use the HARVARD dataset to test three networks with residual modules, DBIN+, MHF-Net and SpeNet, and record the
and the corresponding PSNR at different stages in the training process.
Figure 2 shows the corresponding PSNR under different
by adjusting the distribution of LR-HSI and HR-MSI. At the same time, we also compare the SAM and ERGAS of the three methods as shown in
Table 1. An intuitive conclusion is that the closer the residual activity factor is to 1, the better the performance of the network. Therefore, when evaluating the performance of the residual block in the fusion network, the proposed
can be used to evaluate whether the currently used residual block can achieve the desired effect. It is worth noting that
is not suitable for evaluating the residual activity in the extraction process of a single natural image, because this is different from the principle that the spectral information and spatial information need to be extracted in the fusion process as close as possible in order of magnitude.
According to the definition of Equation (
3), the value of
varies as the input to the neural network changes, but the residual activity factor should be a characterising quantity in a uniform sense. Therefore, for each data
i with a sample set of
N, we count the
corresponding to each input and calculate the average residual factor
for sample
N together reflecting the learning activity of the residuals throughout the network as shown in Equation (
4). For the sake of concise representation,
appearing in subsequent comparison trials all denote the average result for the overall dataset.
where
N represents the number of samples. We illustrate the proposed method experimentally in comparison with current hyperspectral super-resolution reconstruction methods in
Section 3.4.
2.2. Lightweight Multi-Level Information Fusion Network
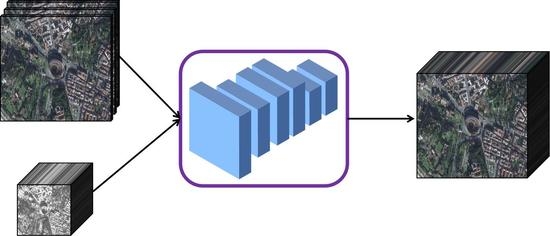
The proposed lightweight multi-level information network (MINet) for multispectral and hyperspectral image fusion framework is displayed in
Figure 3. The network is composed of several residual constraint blocks (orange boxes) based on a global variance fine-tuning (GVF-RCB) module, and a hyperspectral image reconstruction module (green boxes). The input to the network is the LR-HSI
and the HR-MSI
, where
are the reduced height, width, and number of spectral bands, respectively, and
are corresponding high-resolution version (
). First,
is upsampled to
of the same size as
by bilinear interpolation. In order to reduce the amount of computation and improve the running speed, we choose a bilinear interpolation algorithm that is more suitable for large-scale parallel computation and stable for upsampling operations. Then, the GVF-RCB module estimates a residual image from both the input
and
progressively along the spectral dimension. Inspired by the success of the progressive reconstruction strategy in image super-resolution, we progressively embed the spectral bands of upsampled LR-HSI instead of feeding them all into the network at the beginning. The resulting residual image is further superimposed on
to generated a blurred HR-HSI, which is finally fed into the reconstruction module. After further fine-tuning and correction of the reconstruction module, the network outputs the final reconstructed high-resolution hyperspectral image.
The GVF-RCB module is the core module of our proposed multi-level information network, and the flowchart of the network architecture is shown in
Figure 4. Its main function is to fuse the spatial information extracted from HR-MSI and the spectral information extracted from LR-HSI to reconstruct the corresponding HR-HSI. The GVF-RCB module is composed of a global residual connection branch and multiple local residual fusion unit cascade branches. The global residual connection branch can extract and transfer low-frequency information of hyperspectral images quickly and efficiently. The goal of residual branch learning is to fuse the information extracted from LR-HSI and MSI into a map of the detail level of the desired HR-HSI to be reconstructed. Define the output of the fusion network as
, which can be expressed as Equation (
5).
where
represents the mapping of the detailed level of information extracted from LR-HSI and MSI fused into the desired HR-HSI to be reconstructed. The network structure of the proposed GVF-RCB module mainly uses convolution kernels with receptive field sizes of
and
as the basic configuration. The
convolution kernel is used to extract the spatial feature information and build a fusion model for local spatial information features of hyperspectral images, and the
convolution kernel is used to fuse the hyperspectral information for channel compression or dimension enhancement. Inspired by the success of the zero-mean normalization strategy in SpeNet, we also add this constraint to transform the data distribution of feature maps to zero when extracting residual feature information.
The overall network consists of four key steps: (1) concatenate the output of the upper layer with HR-MSI (UP-HSI sampling numbers are 8, 16, 31) and increase the number of channels to be consistent with the up-sampled hyperspectral image (UP-HSI); (2) fuse two kinds of data with different distributions. A fully connected beta network is used to perform mutual induction global spectral information fusion on the output feature map and UP-HSI, adaptively adjust the data distribution of the two inputs, and accelerate the fusion of local spatial information and spectral information in the next stage; (3) use a convolutional layer to fuse the local spatial structure feature information of feature map0 and feature map1, and use a convolutional layer to perform spectral fusion of the channel dimension and reduce the number of channels; (4) use convolution for further fusion, and add it to the feature map and output it.
The GVF-RCB module mainly completes two tasks. First, it extracts the spectral feature information of the hyperspectral image and the spatial structure information of the multispectral image, and fuses the two kinds of information into the detailed information of the hyperspectral image to be output. It is responsible for MINet extraction and fusion of complementary information from each input. In addition, as the basic unit of residual branch information fusion, the spatial structure information and spectral information of different levels are gradually fused through the cascade of multiple GVF-RCB modules. The two fused parts have the same spatial resolution, but the number of channels and spectral images are different for each input to the GVF-RCB module, and the gradually increasing number of channels enhances the feature extraction of spectral information. The two different feature vectors rely on the core unit beta network for fusion.
The input of the hyperspectral image reconstruction module is the coarse HR-HSI output by the fusion network, and the reconstructed images in the first stage of the network are fine-tuned and distilled. The network structure of the reconstruction module is relatively simple, the overall structure is a residual block, and the residual branch is mainly composed of and convolutional layers alternately.
2.3. Fully Connected Beta Network
The fully connected beta network is the core unit of the GVF-RCB module, which can be used to adjust the mean and variance of hyperspectral images. Although hyperspectral images and feature maps generated by convolutional neural networks have the same spatial dimension, their data distributions are quite different. We visualized the input and output of the beta network in the fifth GVF-RCB module, and selected three images from the CAVE [
57] and HARVARD [
58] datasets, respectively, as shown in
Figure 5, where blue represents the mean value of each channel of the hyperspectral image and orange represents the mean value of each channel of the feature map. The average value of each channel is calculated as in the average pooling operation. From the mean value of each channel of the hyperspectral image and feature map, and the beta coefficient of each channel (output of the network), it can be seen that the mean value of the hyperspectral image channel is small and densely distributed, while the mean value of each channel of the feature map is large and irregularly distributed. Due to the obvious data gap, directly cascading hyperspectral images and feature maps will result in the ineffective fusion of the spatial feature information of the feature maps and the spectral information of the hyperspectral images. Therefore, it is usually necessary to pass the extracted feature information to convolutional layers using Dense Connection.
Adjusting the internal data distribution of the neural network can often make the network converge quick and stable, and improve the generalization ability of the network. Batch normalization is one of the most commonly used methods to quickly adjust the distribution of feature map data. During training, the local mean and variance of each mini-batch data are used for normalization and to estimate the global value. Finally, in the testing process adjust the data distribution with the global mean and variance instead of the local mean and variance. However, super-resolution reconstruction methods [
59] for natural images point out that batch normalization will introduce huge randomness and cause the network to underfit, so it is not suitable for image reconstruction problems.
To reduce the difficulty of training neural networks, we introduce a coefficient
(
) on the residual learning branch, and the refined residual information is multiplied by
to achieve convergence. Assuming
is a feature map, let
and
be the mean and variance of
, respectively, calculated according to the following equation:
when the output feature map
of the residual branch is multiplied by a small coefficient
, the mean
and variance
of the feature map are calculated according to the following equation:
Therefore, multiplying the residual branch by a small coefficient changes the mean and variance of the feature map data, which essentially adjusts the data distribution of the feature map in the direction where the mean tends to zero, reducing the absolute value of the feature map. Further, the magnitude of the learning parameters in the process of training the network is reduced, so that the variable parameters can better fit the data map. The reduction of variance makes the data distribution more compact, suppresses the fluctuation range of data changes, and at the same time enhances the stability of the data, making the neural network converge towards a more stable direction.
The proposed fully connected beta network is shown in
Figure 6. We used the beta network to make the hyperspectral image and the feature map perceive each other’s feature information, and then adaptively changed the data distribution to an appropriate degree. The selection of the beta value was obtained by adaptive learning of the beta network, for each channel will learn a different beta value, and then the small coefficient beta was multiplied by each feature map. The detailed calculation steps of the beta network algorithm are shown in Algorithm 1.
| Algorithm 1: Data distribution adjustment in fusion network |
| Input: X and Y |
| Output: and |
| STEP1: compute mean vector |
| |
| |
| STEP2: concatenate and to obtain neural input μ |
| STEP3: feed μ into fully connected network and output the coefficient vector β |
| STEP4: split β to and |
| STEP5: compute outputs and |
| |
| |














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}