

AQE-Net: A Deep Learning Model for Estimating Air Quality of Karachi City from Mobile Images

 and
and 
Abstract
:
1. Introduction
2. Materials and Methods
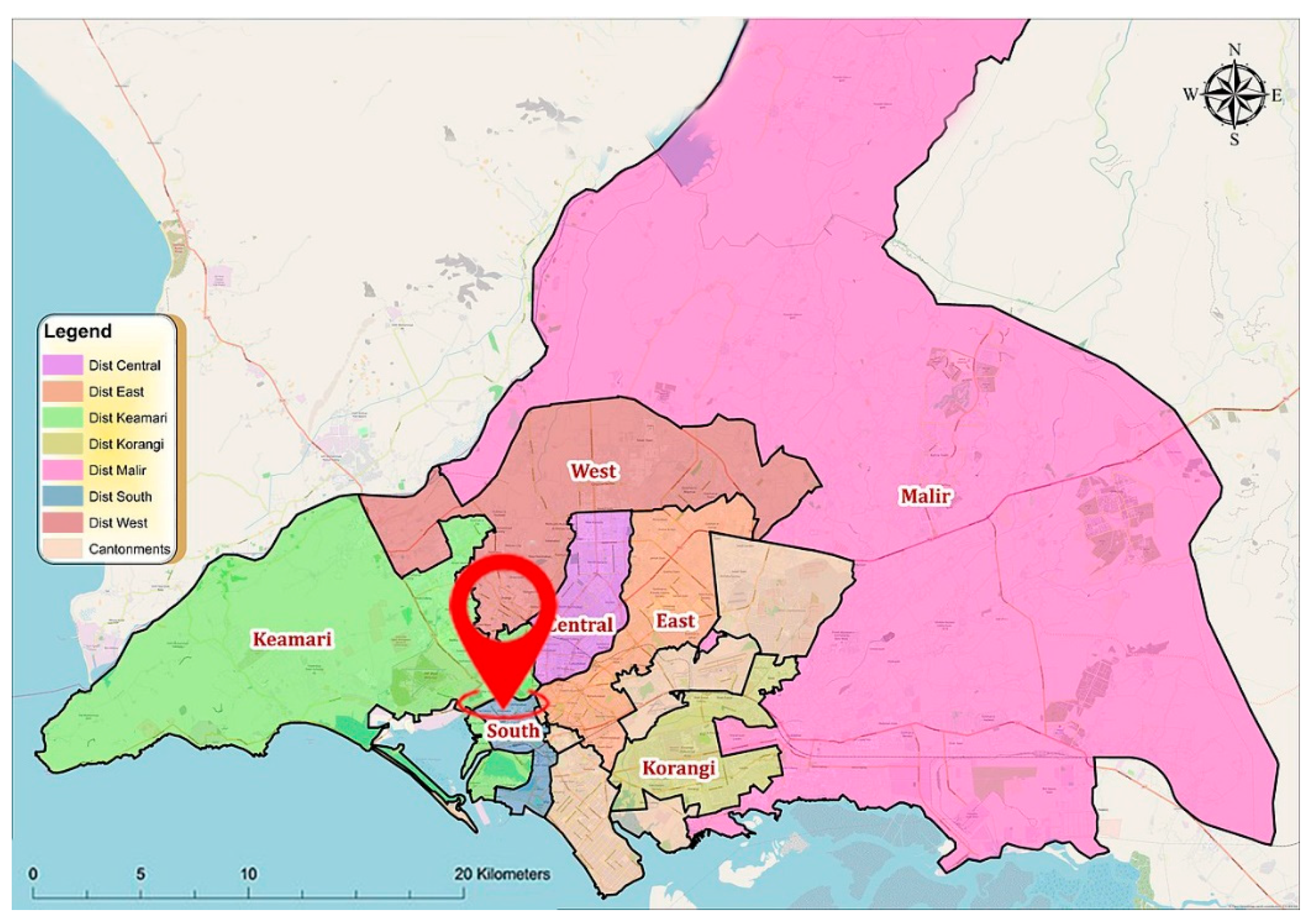
2.1. Study Area
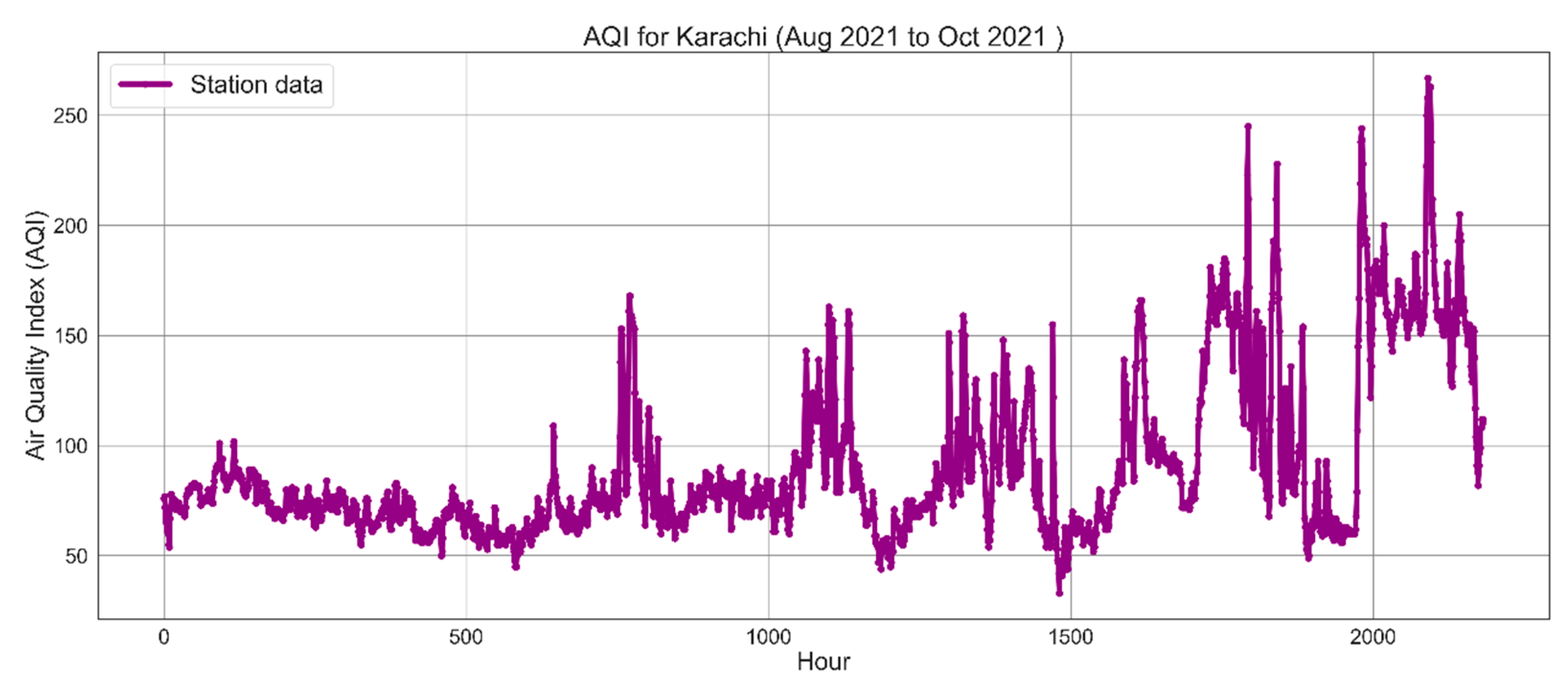
2.2. Dataset
2.3. Convolutional Neural Network (CNN)
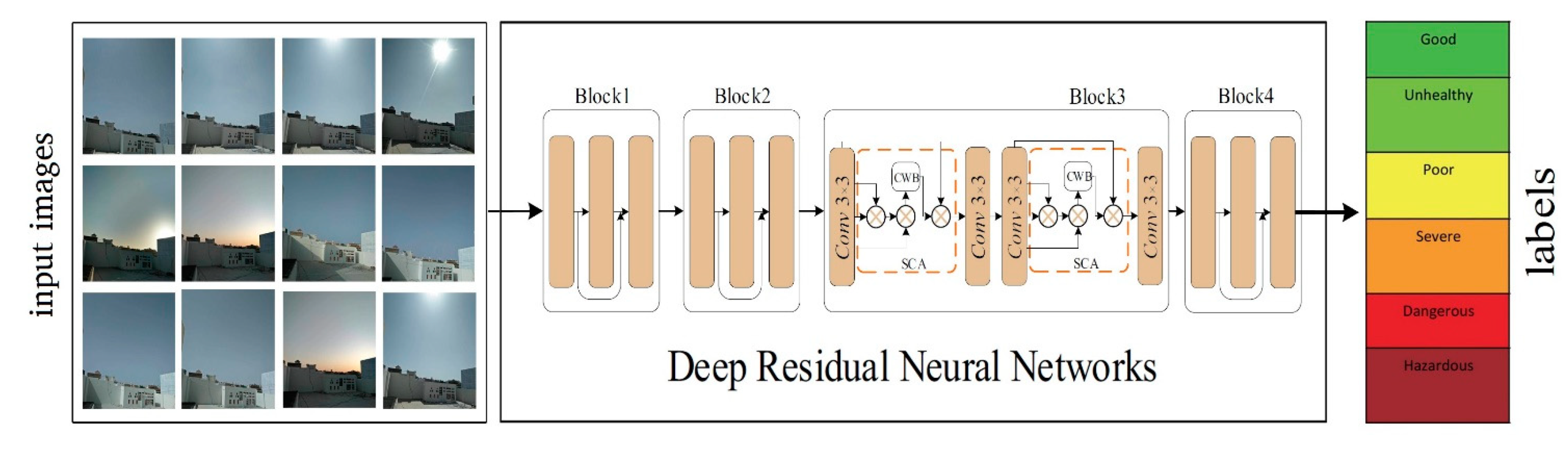
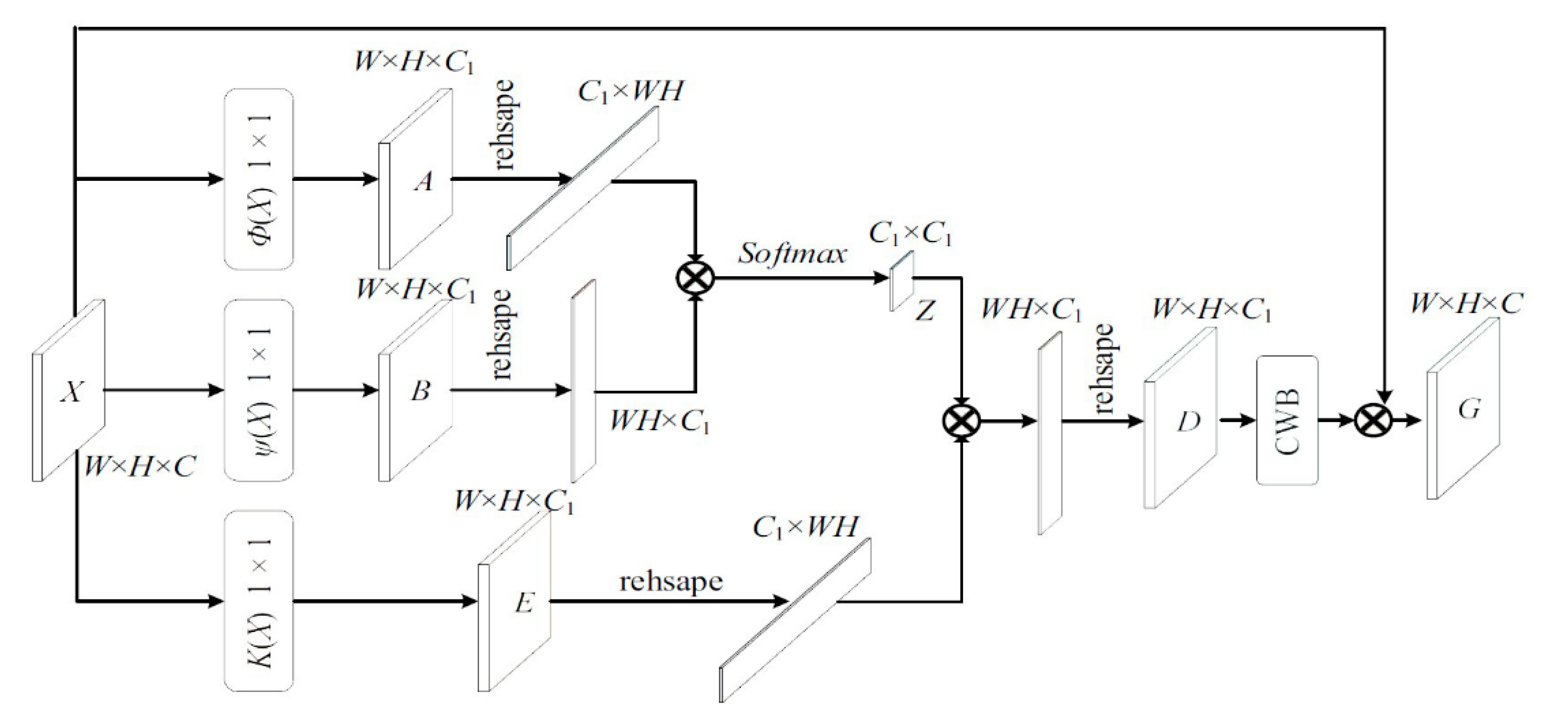
2.4. AQE-NET Model
2.5. Model Training
2.6. Model Selection Criteria
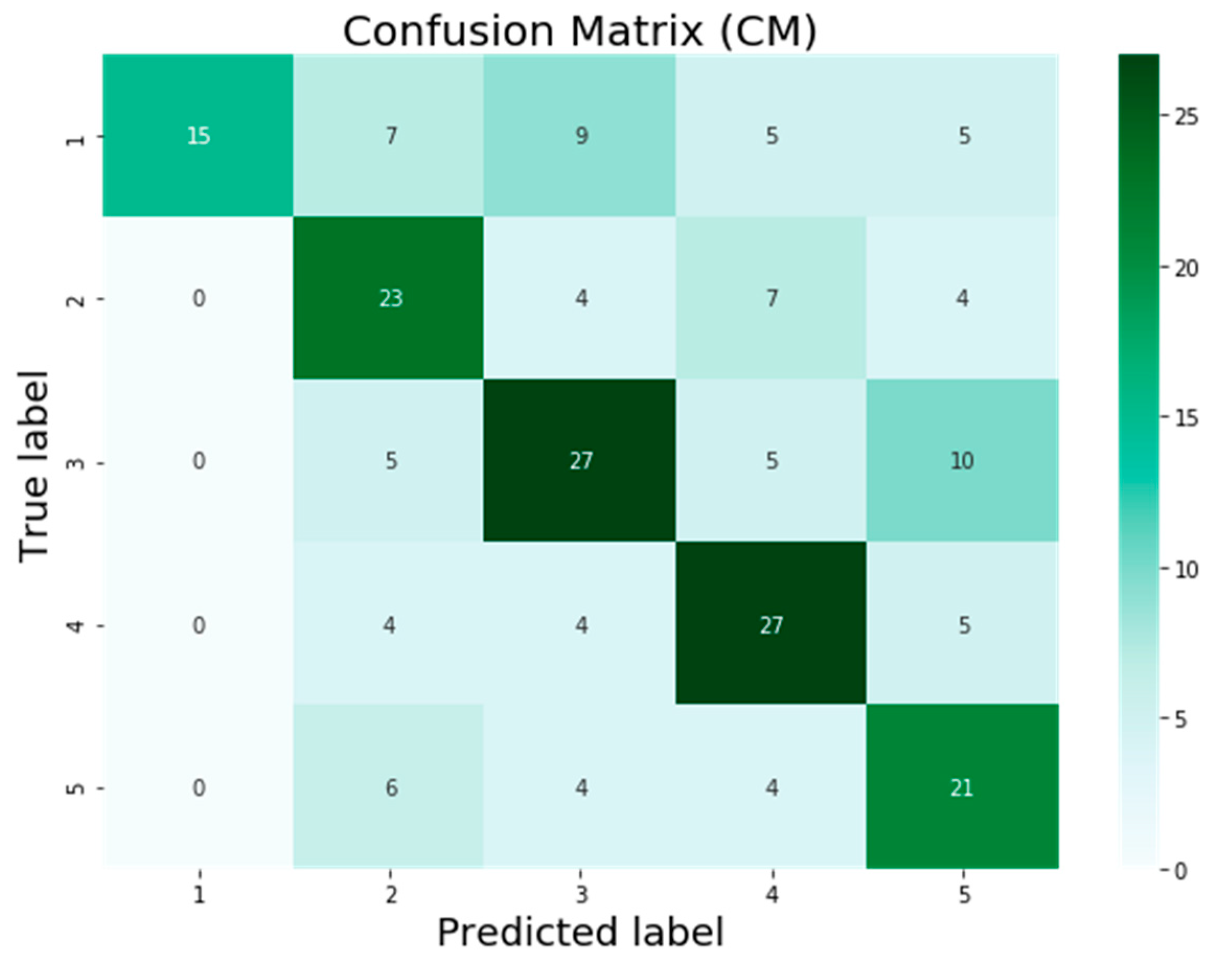
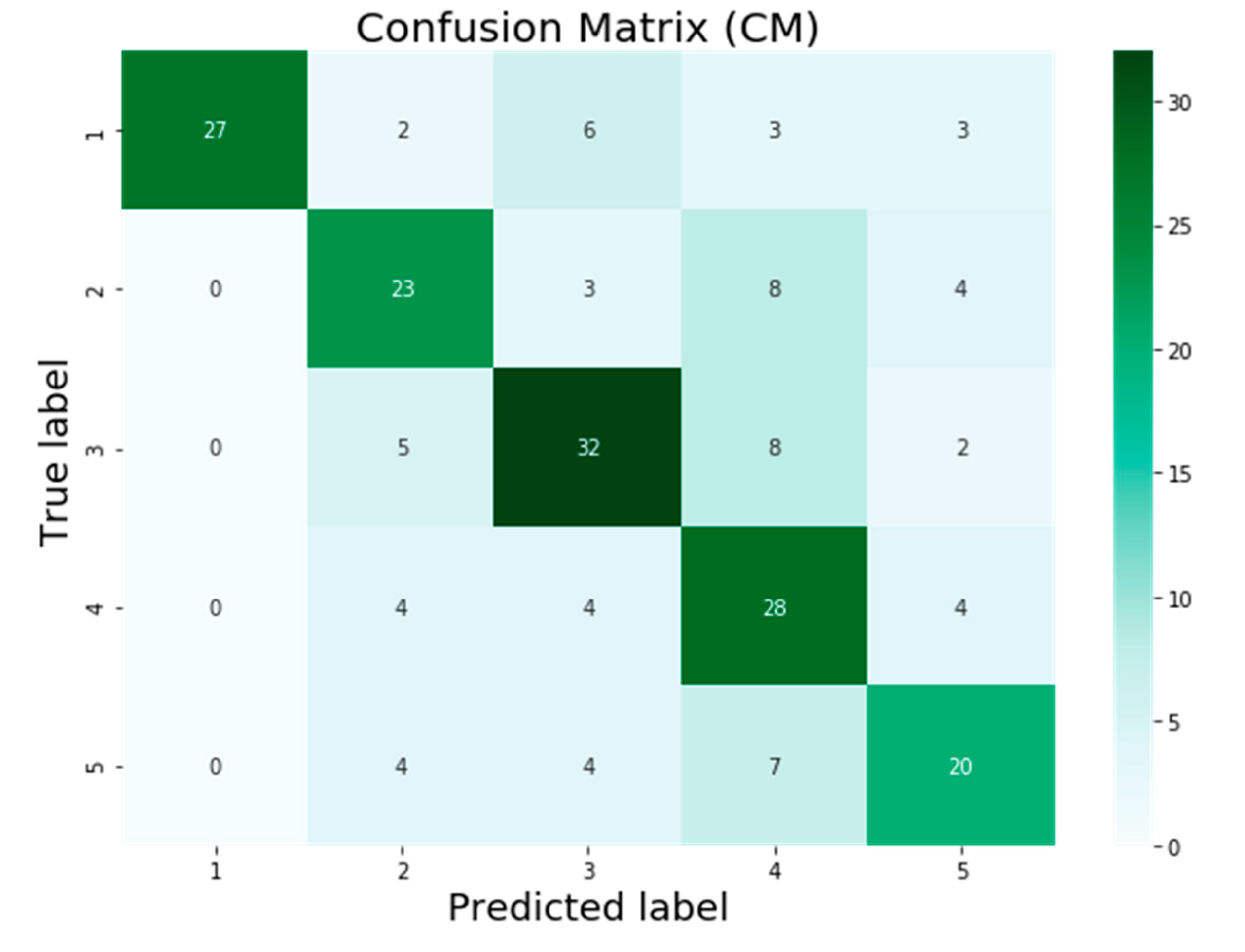
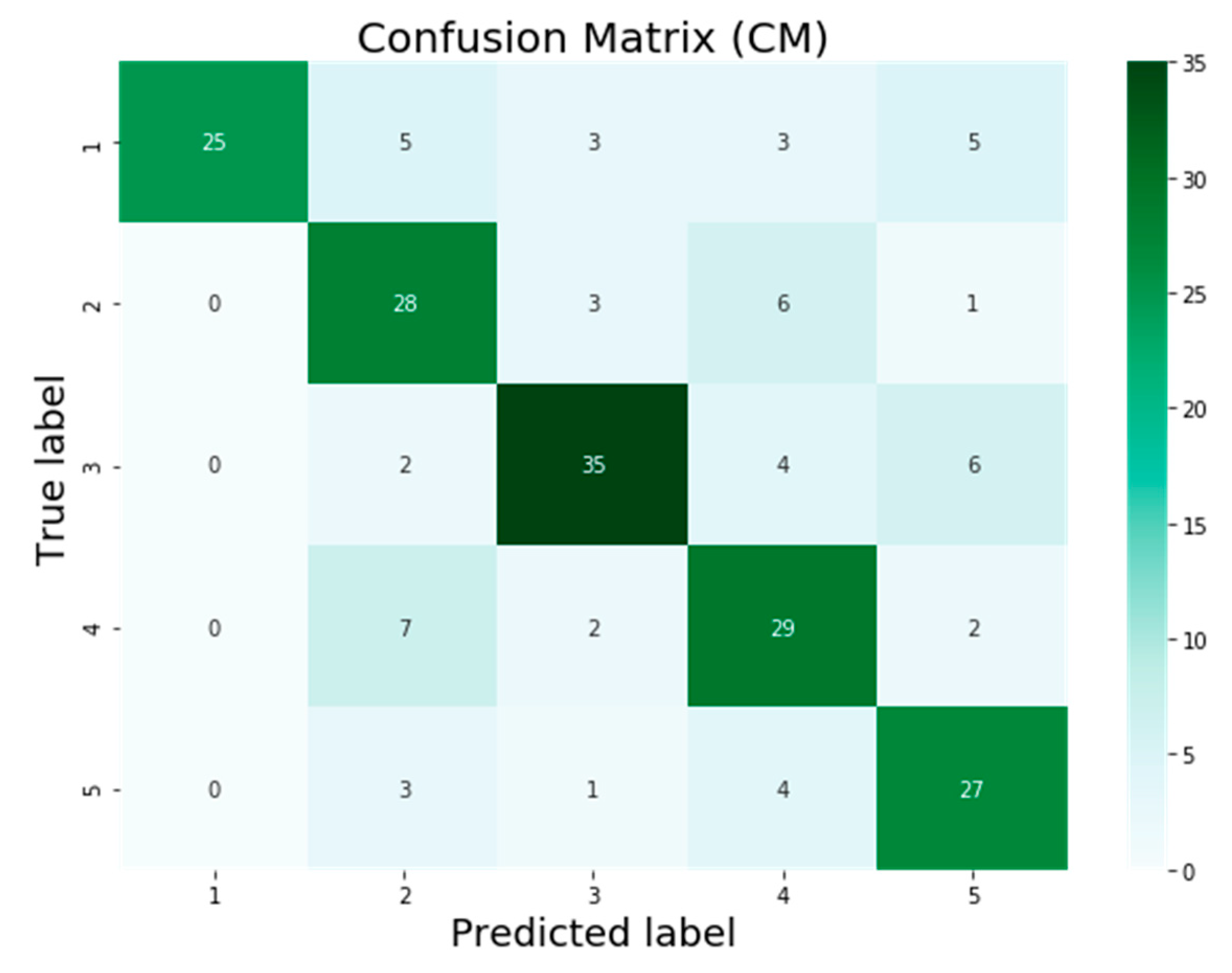
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ruggieri, M.; Plaia, A. An Aggregate AQI: Comparing Different Standardizations and Introducing a Variability Index. Sci. Total Environ. 2012, 420, 263–272. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Goyal, P. Forecasting of Daily Air Quality Index in Delhi. Sci. Total Environ. 2011, 409, 5517–5523. [Google Scholar] [CrossRef]
- Ahmed, M.; Xiao, Z.; Shen, Y. Estimation of Ground PM2.5 Concentrations in Pakistan Using Convolutional Neural Network and Multi-Pollutant Satellite Images. Remote Sens. 2022, 14, 1735. [Google Scholar] [CrossRef]
- Shi, J.; Wang, X.; Chen, Z. Polluted Humanity: Air Pollution Leads to the Dehumanization of Oneself and Others. J. Environ. Psychol. 2022, 83, 101873. [Google Scholar] [CrossRef]
- Alizadeh, R.; Soltanisehat, L.; Lund, P.D.; Zamanisabzi, H. Improving Renewable Energy Policy Planning and Decision-Making through a Hybrid MCDM Method. Energy Policy 2020, 137, 111174. [Google Scholar] [CrossRef]
- Pan, J.; Xue, Y.; Li, S.; Wang, L.; Mei, J.; Ni, D.; Jiang, J.; Zhang, M.; Yi, S.; Zhang, R. PM2.5 Induces the Distant Metastasis of Lung Adenocarcinoma via Promoting the Stem Cell Properties of Cancer Cells. Environ. Pollut. 2022, 296, 118718. [Google Scholar] [CrossRef]
- Thangavel, P.; Park, D.; Lee, Y.-C. Recent Insights into Particulate Matter (PM2.5)-Mediated Toxicity in Humans: An Overview. Int. J. Environ. Res. Public Health 2022, 19, 7511. [Google Scholar] [CrossRef]
- Rijal, N.; Gutta, R.T.; Cao, T.; Lin, J.; Bo, Q.; Zhang, J. Ensemble of Deep Neural Networks for Estimating Particulate Matter from Images. In Proceedings of the 2018 IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 733–738. [Google Scholar]
- Zhao, K.; He, T.; Wu, S.; Wang, S.; Dai, B.; Yang, Q.; Lei, Y. Research on Video Classification Method of Key Pollution Sources Based on Deep Learning. J. Vis. Commun. Image Represent. 2019, 59, 283–291. [Google Scholar] [CrossRef]
- Babari, R.; Hautiere, N.; Dumont, E.; Bremond, R.; Paparoditis, N. A Model-Driven Approach to Estimate Atmospheric Visibility with Ordinary Cameras. Atmos. Environ. 2011, 45, 5316–5324. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Yan, J.; Li, C.; Rui, X.; Liu, L.; Bie, R. On Estimating Air Pollution from Photos Using Convolutional Neural Network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Nederlands, 15–19 October 2016; pp. 297–301. [Google Scholar]
- Chakma, A.; Vizena, B.; Cao, T.; Lin, J.; Zhang, J. Image-Based Air Quality Analysis Using Deep Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3949–3952. [Google Scholar]
- Baklanov, A.; Mestayer, P.G.; Clappier, A.; Zilitinkevich, S.; Joffre, S.; Mahura, A.; Nielsen, N.W. Towards Improving the Simulation of Meteorological Fields in Urban Areas through Updated/Advanced Surface Fluxes Description. Atmos. Chem. Phys. 2008, 8, 523–543. [Google Scholar] [CrossRef]
- Pak, U.; Ma, J.; Ryu, U.; Ryom, K.; Juhyok, U.; Pak, K.; Pak, C. Deep Learning-Based PM2.5 Prediction Considering the Spatiotemporal Correlations: A Case Study of Beijing, China. Sci. Total Environ. 2020, 699, 133561. [Google Scholar] [CrossRef]
- Woody, M.C.; Wong, H.-W.; West, J.J.; Arunachalam, S. Multiscale Predictions of Aviation-Attributable PM2.5 for US Airports Modeled Using CMAQ with Plume-in-Grid and an Aircraft-Specific 1-D Emission Model. Atmos. Environ. 2016, 147, 384–394. [Google Scholar] [CrossRef]
- Bray, C.D.; Battye, W.; Aneja, V.P.; Tong, D.; Lee, P.; Tang, Y.; Nowak, J.B. Evaluating Ammonia (NH3) Predictions in the NOAA National Air Quality Forecast Capability (NAQFC) Using in-Situ Aircraft and Satellite Measurements from the CalNex2010 Campaign. Atmos. Environ. 2017, 163, 65–76. [Google Scholar] [CrossRef]
- Zhou, G.; Xu, J.; Xie, Y.; Chang, L.; Gao, W.; Gu, Y.; Zhou, J. Numerical Air Quality Forecasting over Eastern China: An Operational Application of WRF-Chem. Atmos. Environ. 2017, 153, 94–108. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep Learning Based Multi-Temporal Crop Classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Giyenko, A.; Palvanov, A.; Cho, Y. Application of Convolutional Neural Networks for Visibility Estimation of CCTV Images. In Proceedings of the 2018 International Conference on Information Networking (ICOIN), Chiang Mai, Thailand, 10–12 January 2018; pp. 875–879. [Google Scholar]
- Zhang, Q.; Fu, F.; Tian, R. A Deep Learning and Image-Based Model for Air Quality Estimation. Sci. Total Environ. 2020, 724, 138178. [Google Scholar] [CrossRef]
- Kopp, M.; Tuo, Y.; Disse, M. Fully Automated Snow Depth Measurements from Time-Lapse Images Applying a Convolutional Neural Network. Sci. Total Environ. 2019, 697, 134213. [Google Scholar] [CrossRef]
- Vahdatpour, M.S.; Sajedi, H.; Ramezani, F. Air Pollution Forecasting from Sky Images with Shallow and Deep Classifiers. Earth Sci. Inform. 2018, 11, 413–422. [Google Scholar] [CrossRef]
- Soh, P.-W.; Chang, J.-W.; Huang, J.-W. Adaptive Deep Learning-Based Air Quality Prediction Model Using the Most Relevant Spatial-Temporal Relations. IEEE Access 2018, 6, 38186–38199. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J. Deep Learning in Environmental Remote Sensing: Achievements and Challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Wang, B.; Yan, Z.; Lu, J.; Zhang, G.; Li, T. Deep Multi-Task Learning for Air Quality Prediction. In Proceedings of the 25th International Conference on Neural Information Processing, Siem Reap, Cambodia, 13–16 December 2018; pp. 93–103. [Google Scholar]
- Bo, Q.; Yang, W.; Rijal, N.; Xie, Y.; Feng, J.; Zhang, J. Particle Pollution Estimation from Images Using Convolutional Neural Network and Weather Features. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3433–3437. [Google Scholar]
- Chang, F.-J.; Chang, L.-C.; Kang, C.-C.; Wang, Y.-S.; Huang, A. Explore Spatio-Temporal PM2.5 Features in Northern Taiwan Using Machine Learning Techniques. Sci. Total Environ. 2020, 736, 139656. [Google Scholar] [CrossRef]
- Zhou, Y.; Chang, F.-J.; Chang, L.-C.; Kao, I.-F.; Wang, Y.-S. Explore a Deep Learning Multi-Output Neural Network for Regional Multi-Step-Ahead Air Quality Forecasts. J. Clean. Prod. 2019, 209, 134–145. [Google Scholar] [CrossRef]
- Zhou, Y.; Chang, L.-C.; Chang, F.-J. Explore a Multivariate Bayesian Uncertainty Processor Driven by Artificial Neural Networks for Probabilistic PM2.5 Forecasting. Sci. Total Environ. 2020, 711, 134792. [Google Scholar] [CrossRef]
- Li, Y.; Huang, J.; Luo, J. Using User Generated Online Photos to Estimate and Monitor Air Pollution in Major Cities. In Proceedings of the 7th International Conference on Internet Multimedia Computing and Service, Zhangjiajie, China, 19–21 August 2015; pp. 1–5. [Google Scholar]
- Liu, C.; Tsow, F.; Zou, Y.; Tao, N. Particle Pollution Estimation Based on Image Analysis. PLoS ONE 2016, 11, e0145955. [Google Scholar] [CrossRef]
- Ma, J.; Li, K.; Han, Y.; Yang, J. Image-Based Air Pollution Estimation Using Hybrid Convolutional Neural Network. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 471–476. [Google Scholar]
- Yu, Y.; Samali, B.; Rashidi, M.; Mohammadi, M.; Nguyen, T.N.; Zhang, G. Vision-Based Concrete Crack Detection Using a Hybrid Framework Considering Noise Effect. J. Build. Eng. 2022, 61, 105246. [Google Scholar] [CrossRef]
- Yu, Y.; Rashidi, M.; Samali, B.; Mohammadi, M.; Nguyen, T.N.; Zhou, X. Crack Detection of Concrete Structures Using Deep Convolutional Neural Networks Optimized by Enhanced Chicken Swarm Algorithm. Struct. Health Monit. 2022, 21, 2244–2263. [Google Scholar] [CrossRef]
- Heydari, A.; Majidi Nezhad, M.; Astiaso Garcia, D.; Keynia, F.; De Santoli, L. Air Pollution Forecasting Application Based on Deep Learning Model and Optimization Algorithm. Clean Technol. Environ. Policy 2022, 24, 607–621. [Google Scholar] [CrossRef]
- Muthukumar, P.; Cocom, E.; Nagrecha, K.; Comer, D.; Burga, I.; Taub, J.; Calvert, C.F.; Holm, J.; Pourhomayoun, M. Predicting PM2.5 Atmospheric Air Pollution Using Deep Learning with Meteorological Data and Ground-Based Observations and Remote-Sensing Satellite Big Data. Air Qual. Atmos. Health 2022, 15, 1221–1234. [Google Scholar] [CrossRef]
- Gilik, A.; Ogrenci, A.S.; Ozmen, A. Air Quality Prediction Using CNN+ LSTM-Based Hybrid Deep Learning Architecture. Environ. Sci. Pollut. Res. 2022, 29, 11920–11938. [Google Scholar] [CrossRef]
- Kurnaz, G.; Demir, A.S. Prediction of SO2 and PM10 Air Pollutants Using a Deep Learning-Based Recurrent Neural Network: Case of Industrial City Sakarya. Urban Clim. 2022, 41, 101051. [Google Scholar] [CrossRef]
- Hu, K.; Guo, X.; Gong, X.; Wang, X.; Liang, J.; Li, D. Air Quality Prediction Using Spatio-Temporal Deep Learning. Atmos. Pollut. Res. 2022, 13, 101543. [Google Scholar] [CrossRef]
- Mengara Mengara, A.G.; Park, E.; Jang, J.; Yoo, Y. Attention-Based Distributed Deep Learning Model for Air Quality Forecasting. Sustainability 2022, 14, 3269. [Google Scholar] [CrossRef]
- AirNow. Available online: https://www.airnow.gov/ (accessed on 10 February 2022).
- Fukushima, K.; Miyake, S. Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Visual Pattern Recognition. In Competition and Cooperation in Neural Nets; Springer: Berlin, Germany, 1982; pp. 267–285. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Rivenson, Y.; Liu, T.; Wei, Z.; Zhang, Y.; de Haan, K.; Ozcan, A. PhaseStain: The Digital Staining of Label-Free Quantitative Phase Microscopy Images Using Deep Learning. Light Sci. Appl. 2019, 8, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Y.; Racah, E.; Correa, J.; Khosrowshahi, A.; Lavers, D.; Kunkel, K.; Wehner, M.; Collins, W. Application of Deep Convolutional Neural Networks for Detecting Extreme Weather in Climate Datasets. arXiv 2016, arXiv:1605.01156. [Google Scholar]
- Shen, Y.; He, X.; Gao, J.; Deng, L.; Mesnil, G. Learning Semantic Representations Using Convolutional Neural Networks for Web Search. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Republic of Korea, 7–11 April 2014; pp. 373–374. [Google Scholar]
- Rivenson, Y.; Zhang, Y.; Günaydın, H.; Teng, D.; Ozcan, A. Phase Recovery and Holographic Image Reconstruction Using Deep Learning in Neural Networks. Light Sci. Appl. 2018, 7, 17141. [Google Scholar] [CrossRef] [Green Version]
- Clark, C.; Storkey, A. Training Deep Convolutional Neural Networks to Play Go. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1766–1774. [Google Scholar]
- Rahmani, B.; Loterie, D.; Konstantinou, G.; Psaltis, D.; Moser, C. Multimode Optical Fiber Transmission with a Deep Learning Network. Light Sci. Appl. 2018, 7, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated Recognition, Localization and Detection Using Convolutional Networks. Eprint Arxiv. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Lin, Z.; Feng, M.; dos Santos, C.N.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A Structured Self-Attentive Sentence Embedding. arXiv 2017, arXiv:1703.03130. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on Imagenet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Jmour, N.; Zayen, S.; Abdelkrim, A. Convolutional Neural Networks for Image Classification. In Proceedings of the 2018 International Conference on Advanced Systems and Electric Technologies (IC_ASET), Hammamet, Tunisia, 22–25 March 2018; pp. 397–402. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Collection Point | Clifton Store Karachi |
|---|---|
| Photo pixels (Px) | 1706 × 1280 |
| Shooting time period | 8:00–18:00 |
| Collection interval | Hourly |
| Camera equipment | OppoA37 (Mobile) |
| Total period | 3 months (Aug 2021 to Oct 2021) |
| Capturing Time | Image Name | Air Time | AQI | Classes |
|---|---|---|---|---|
| 2021/1/6 8:00:00 | DSCF0667.JPG | 2021/1/6 8:00:00 | 114 | 3 |
| 2021/1/6 8:00:00 | DSCF0667.JPG | 2021/1/6 8:00:00 | 123 | 3 |
| 2021/1/6 8:00:00 | DSCF0667.JPG | 2021/1/6 8:00:00 | 90 | 2 |
| 2021/1/6 8:00:00 | DSCF0667.JPG | 2021/1/6 8:00:00 | 87 | 2 |
| Method | P-Times(s) | Accuracy | Sensitivity | F1 Score | Error Rate |
|---|---|---|---|---|---|
| SVM | 0.0532 | 56.2% | 0.77 | 0.87 | 0.16 |
| VGG16 | 0.0085 | 59.2% | 0.79 | 0.88 | 0.14 |
| InceptionV3 | 0.0072 | 64.6% | 0.85 | 0.92 | 0.05 |
| AQE-Net | 0.0053 | 70.1% | 0.92 | 0.96 | 0.03 |
| Indicator | SVM | VGG16 | InceptionV3 | AQE-NET |
|---|---|---|---|---|
| MSE | 1.915 | 1.910 | 1.373 | 1.278 |
| MAE | 0.830 | 0.796 | 0.626 | 0.542 |
| MAPE | 0.473 | 0.465 | 0.326 | 0.310 |
| No. of Epochs | Number of Iterations | Training Times (s) | Accuracy |
|---|---|---|---|
| 3 Epochs | 9 | 12,091.69 | 0.4866 |
| 4 Epochs | 12 | 17,611.09 | 0.5089 |
| 5 Epochs | 15 | 39,255.33 | 0.5816 |
| 6 Epochs | 18 | 42,324.30 | 0.6514 |
| No. of Epochs | Number of Iterations | Training Times (s) | Accuracy |
|---|---|---|---|
| 3 Epochs | 54 | 11,589.23 | 0.5866 |
| 4 Epochs | 72 | 15,173.47 | 0.6089 |
| 5 Epochs | 90 | 222.349 | 0.6816 |
| 6 Epochs | 108 | 25,934.44 | 0.7014 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, M.; Shen, Y.; Ahmed, M.; Xiao, Z.; Cheng, P.; Ali, N.; Ghaffar, A.; Ali, S. AQE-Net: A Deep Learning Model for Estimating Air Quality of Karachi City from Mobile Images. Remote Sens. 2022, 14, 5732. https://doi.org/10.3390/rs14225732
Ahmed M, Shen Y, Ahmed M, Xiao Z, Cheng P, Ali N, Ghaffar A, Ali S. AQE-Net: A Deep Learning Model for Estimating Air Quality of Karachi City from Mobile Images. Remote Sensing. 2022; 14(22):5732. https://doi.org/10.3390/rs14225732
Chicago/Turabian StyleAhmed, Maqsood, Yonglin Shen, Mansoor Ahmed, Zemin Xiao, Ping Cheng, Nafees Ali, Abdul Ghaffar, and Sabir Ali. 2022. "AQE-Net: A Deep Learning Model for Estimating Air Quality of Karachi City from Mobile Images" Remote Sensing 14, no. 22: 5732. https://doi.org/10.3390/rs14225732
APA StyleAhmed, M., Shen, Y., Ahmed, M., Xiao, Z., Cheng, P., Ali, N., Ghaffar, A., & Ali, S. (2022). AQE-Net: A Deep Learning Model for Estimating Air Quality of Karachi City from Mobile Images. Remote Sensing, 14(22), 5732. https://doi.org/10.3390/rs14225732