



Improved One-Stage Detectors with Neck Attention Block for Object Detection in Remote Sensing

 ,
,
Abstract
:
1. Introduction
2. Related Work
2.1. One-Stage Detector
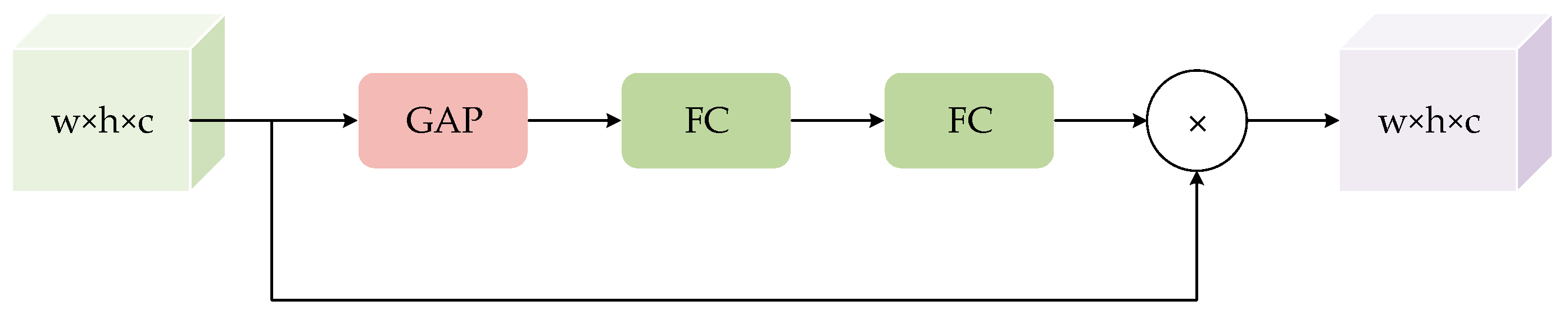
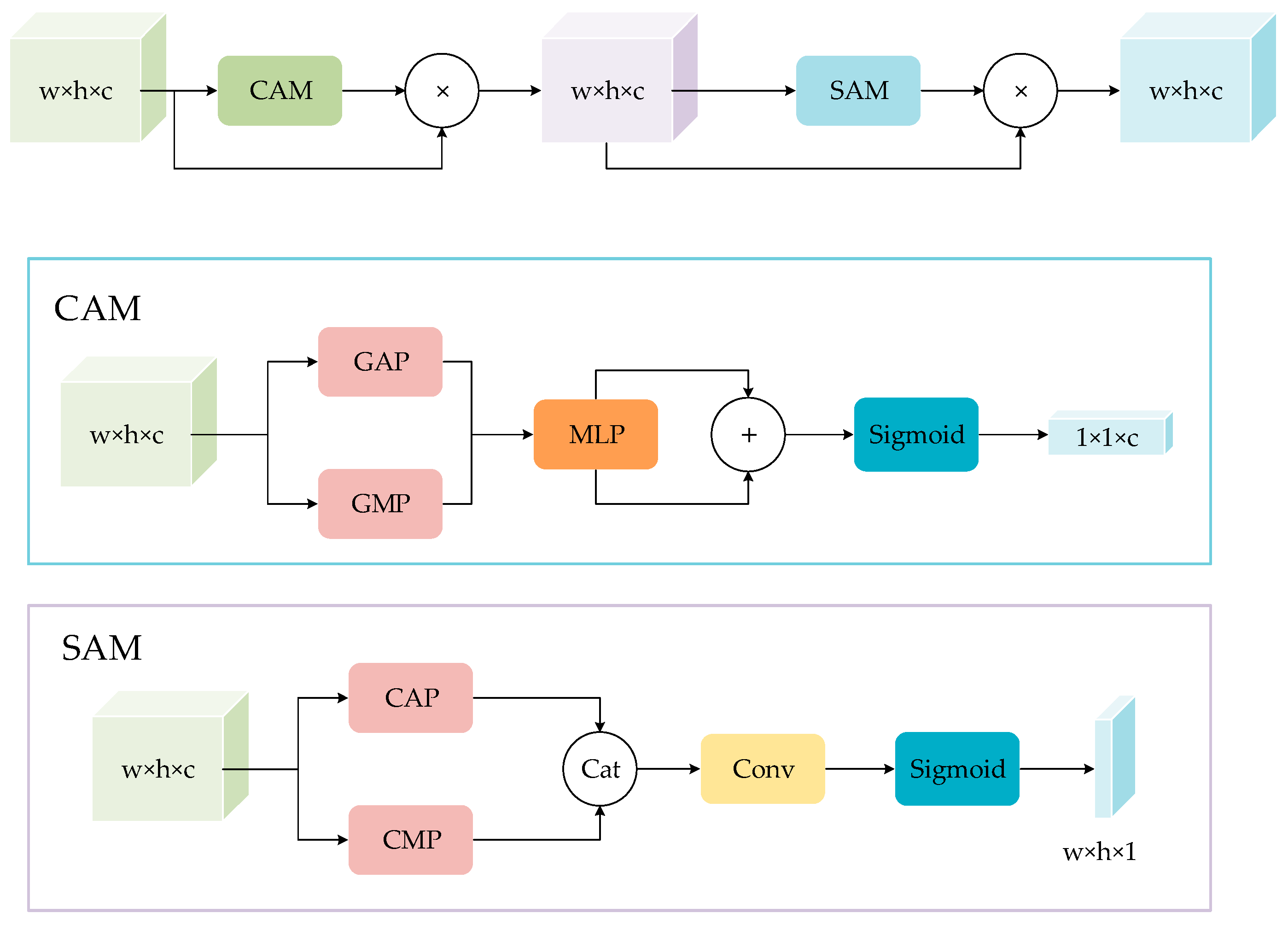
2.2. Attention Mechanism
2.3. Small Object Detection
3. Materials and Methods
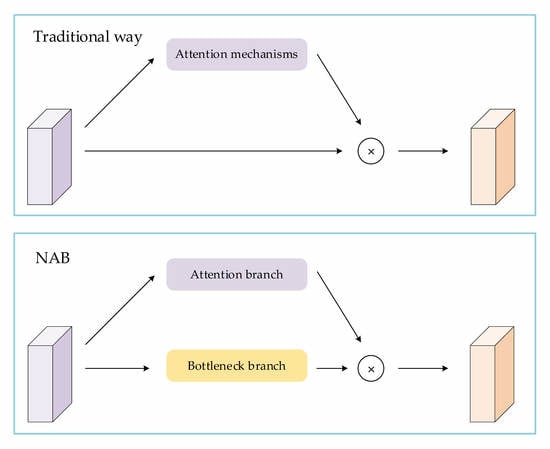
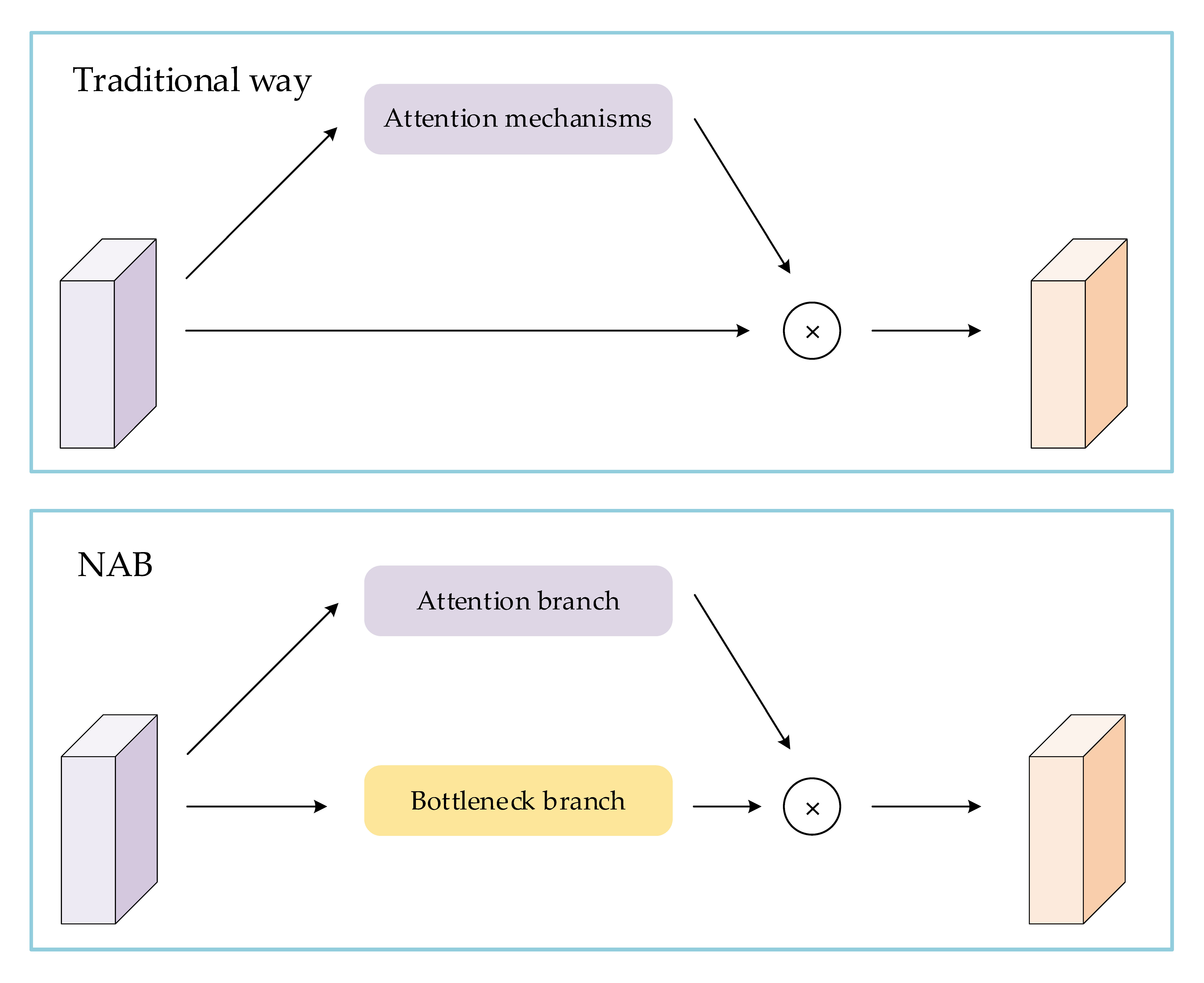
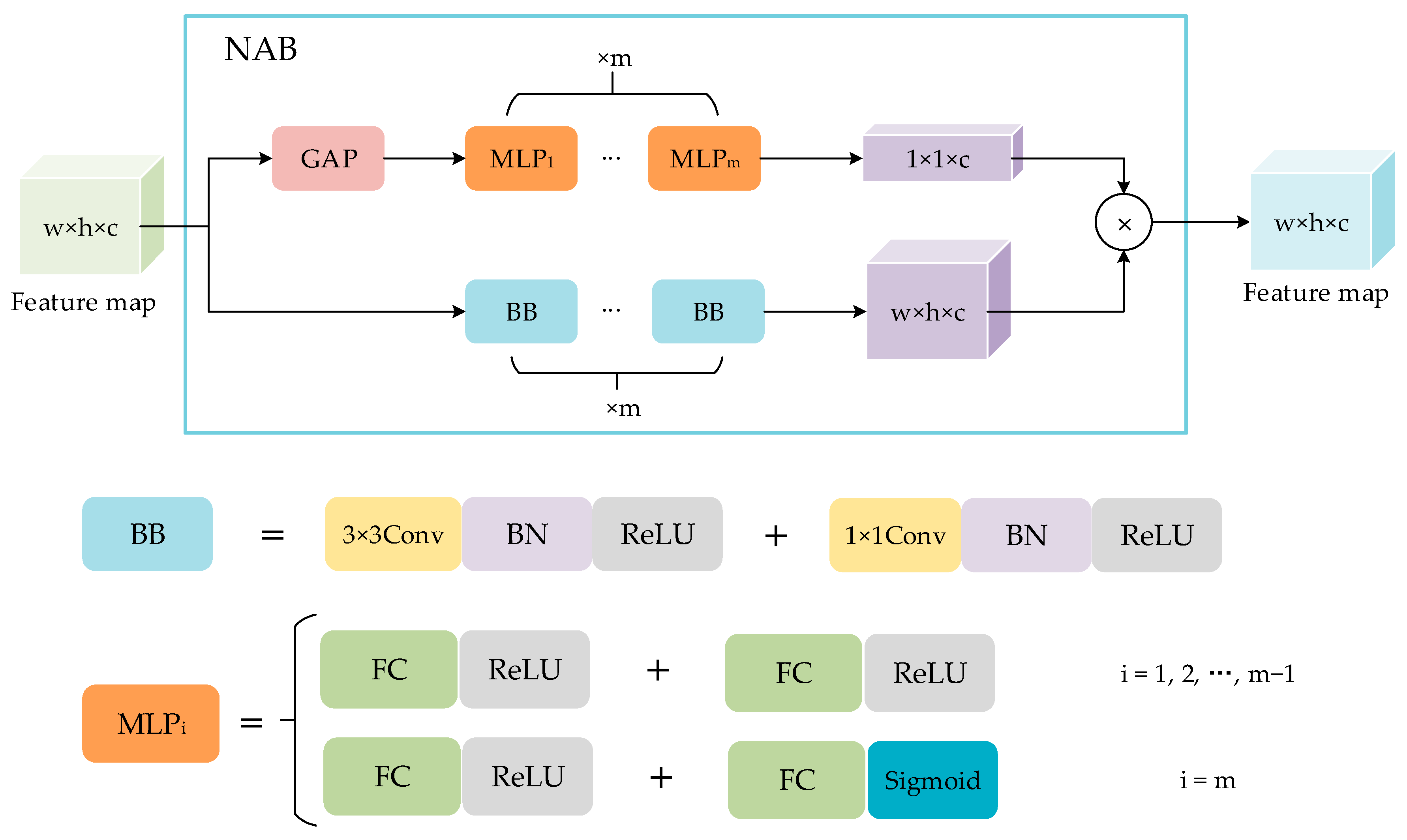
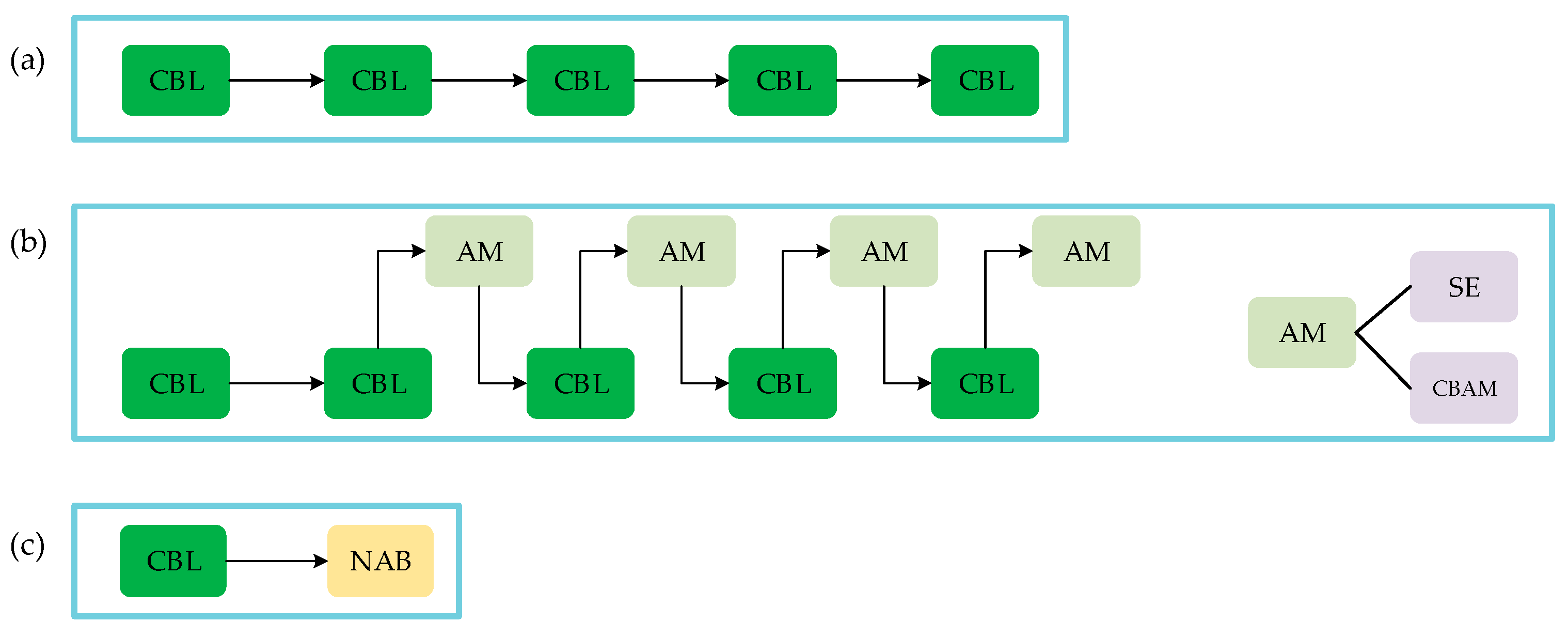
3.1. NAB
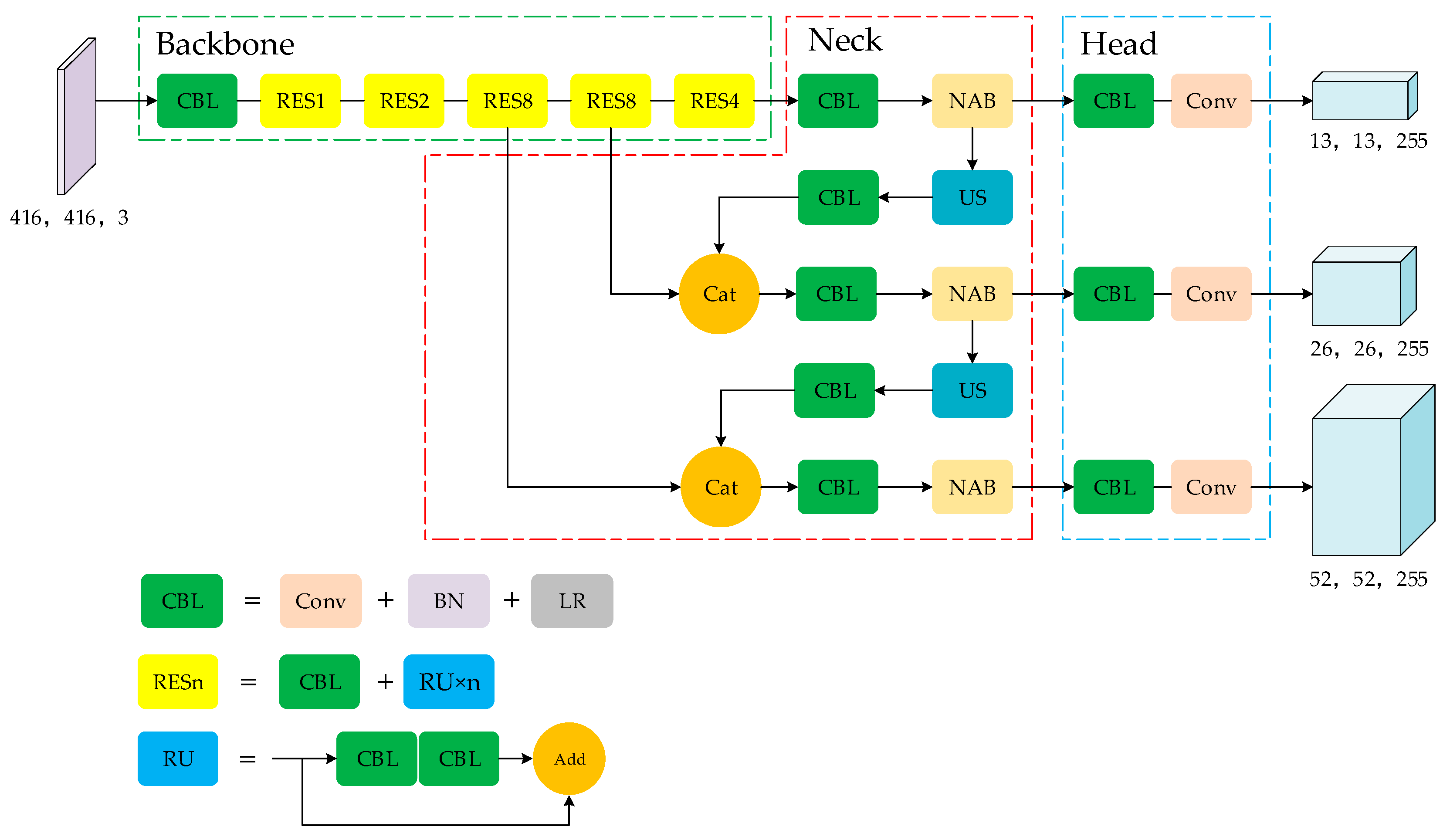
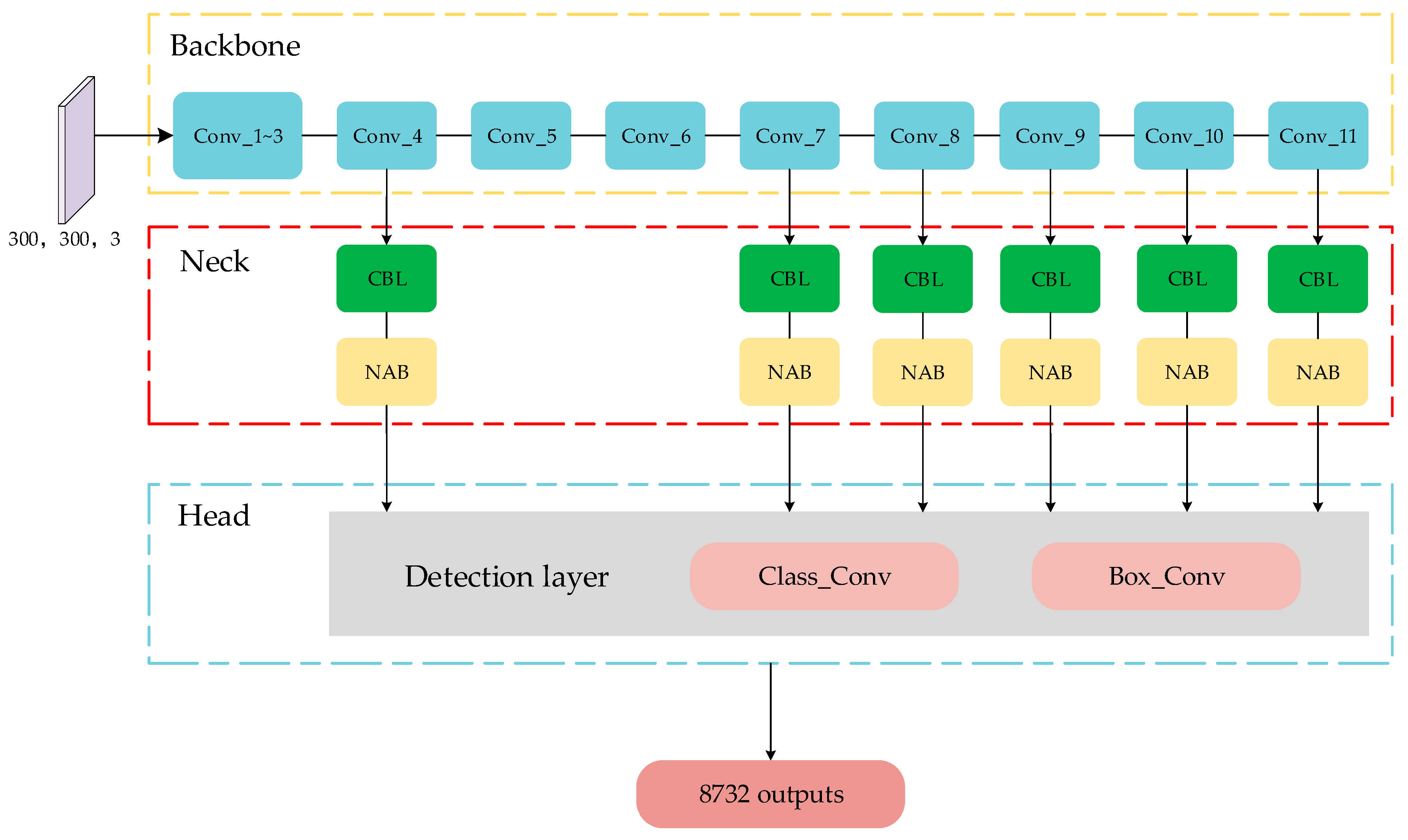
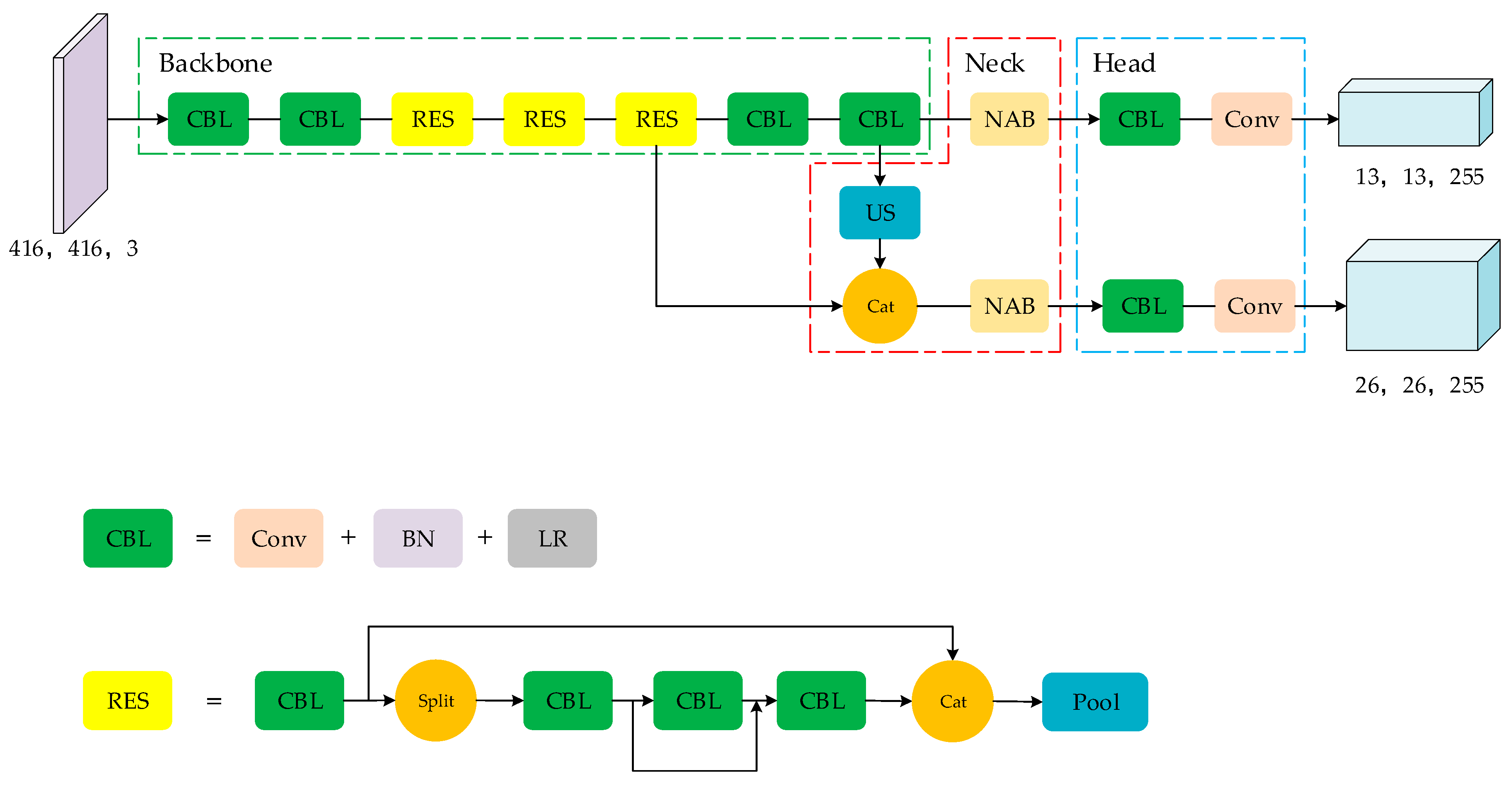
3.2. Improved Models
3.3. Datasets
4. Results
4.1. Evaluation Criteria
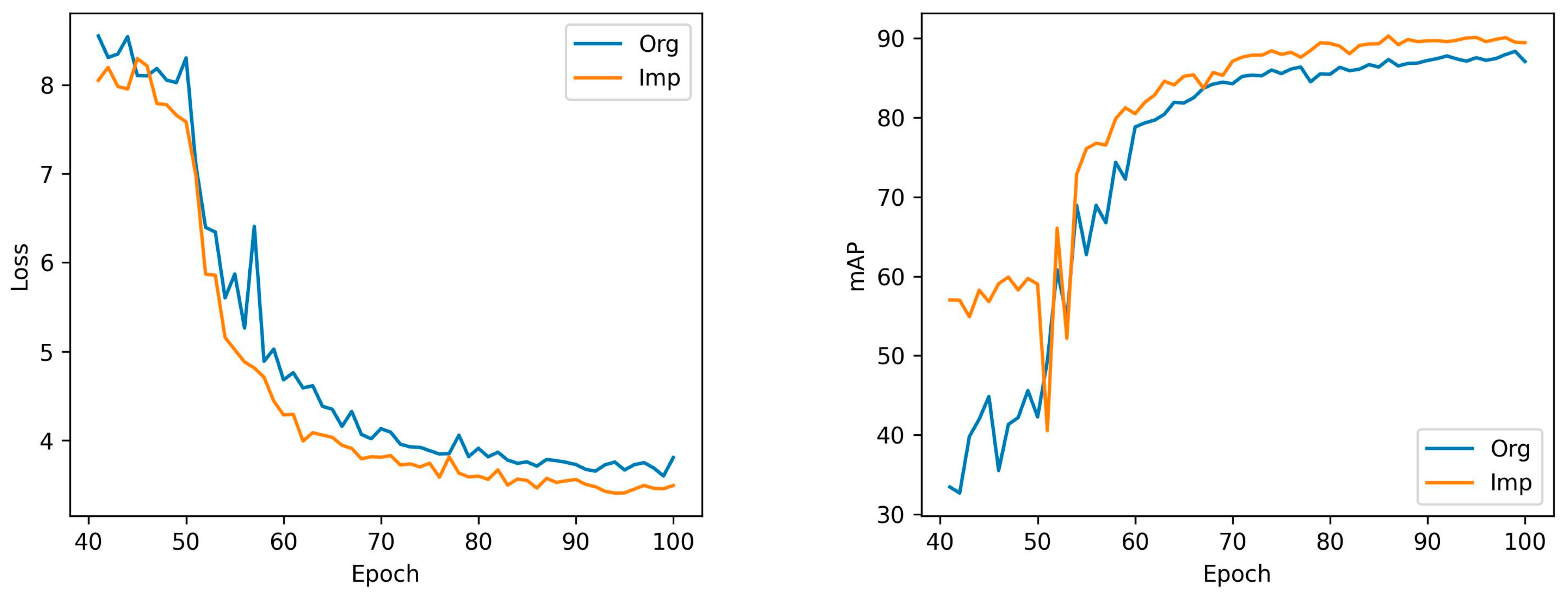
4.2. VHRAI
4.3. TGRS-HRRSD
4.4. PASCAL VOC
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Wei, L.; Yangqing, J.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot MultiBox detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ye, Y.; Ren, X.; Zhu, B.; Tang, T.; Tan, X.; Gui, Y.; Yao, Q. An adaptive attention fusion mechanism convolutional network for object detection in remote sensing images. Remote Sens. 2022, 14, 516. [Google Scholar] [CrossRef]
- Xu, D.; Wu, Y. Improved YOLO-V3 with DenseNet for multi-scale remote sensing target detection. Sensors 2020, 20, 4276. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Qu, Z.; Zhu, F.; Qi, C. Remote Sensing Image Target Detection: Improvement of the YOLOv3 Model with Auxiliary Networks. Remote Sens. 2021, 13, 3908. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Jing, Y.; Ren, Y.; Liu, Y.; Wang, D.; Yu, L. Automatic Extraction of Damaged Houses by Earthquake Based on Improved YOLOv5: A Case Study in Yangbi. Remote Sens. 2022, 14, 382. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI 2020 Conference, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:1312.4400. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Sun, C.; Zhang, S.; Qu, P.; Wu, X.; Feng, P.; Tao, Z.; Zhang, J.; Wang, Y. MCA-YOLOV5-Light: A Faster, Stronger and Lighter Algorithm for Helmet-Wearing Detection. Appl. Sci. 2022, 12, 9697. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Yu, X.; Gong, Y.; Jiang, N.; Ye, Q.; Han, Z. Scale match for tiny person detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1246–1254. [Google Scholar]
- Chen, C.; Liu, M.-Y.; Tuzel, O.; Xiao, J. R-CNN for small object detection. In Proceedings of the ACCV 2016—Asian Conference on Computer Vision, Taipei, Taiwan, 21–23 November 2016. [Google Scholar]
- Heitz, G.; Koller, D. Learning spatial context: Using stuff to find things. In Proceedings of the ECCV 2008—10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef] [Green Version]
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A Large contextual dataset for classification, detection and counting of cars with deep learning. In Proceedings of the ECCV—Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship Rotated Bounding Box Space for Ship Extraction From High-Resolution Optical Satellite Images With Complex Backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Pham, M.-T.; Courtrai, L.; Friguet, C.; Lefèvre, S.; Baussard, A. YOLO-Fine: One-Stage Detector of Small Objects Under Various Backgrounds in Remote Sensing Images. Remote Sens. 2020, 12, 2501. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, S.-P.; Thachan, S.; Chen, J.; Qian, Y.-t. Deconv R-CNN for small object detection on remote sensing images. In Proceedings of the IGARSS—IEEE International Geoscience Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2483–2486. [Google Scholar]
- Qin, H.; Li, Y.; Lei, J.; Xie, W.; Wang, Z. A Specially Optimized One-Stage Network for Object Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 401–405. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning—Volume 37, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Tzutalin. LabelImg. Git Code. 2015. Available online: https://github.com/tzutalin/labelImg (accessed on 10 September 2020).
- Liu, K.; Mattyus, G. Fast Multiclass Vehicle Detection on Aerial Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1938–1942. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and Robust Convolutional Neural Network for Very High-Resolution Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | # Categories | # Images | # Instances | Image Width | Average Area per Instance |
|---|---|---|---|---|---|
| TAS | 1 | 30 | 1319 | 792 | 805 |
| UCAS-AOD | 2 | 1510 | 14,597 | 1280 | 4888 |
| HRSC2016 | 1 | 1070 | 2976 | ~1000 | 56,575 |
| DLR-MVDA | 2 | 10 | 3505 | 5616 | 239 |
| COWC | 1 | 53 | 32,716 | 2000~19,000 | 1024 |
| VEDAI (512) | 9 | 1250 | 3757 | 512 | 3108 |
| VHRAI (ours) | 1 | 900 | 5589 | 960 | 369 |
| Model | # Parameters | Precision (%) | Recall (%) | AP (%) | AP_s (%) |
|---|---|---|---|---|---|
| YOLOv3 | 61.52 M | 83.73 | 83.87 | 88.35 | 41.9 |
| YOLOv3-SE | 63.24 M | 84.44 | 83.5 | 88.15 | 39.5 |
| YOLOv3-CBAM | 63.24 M | 85.88 | 83.76 | 89.09 | 41.4 |
| YOLOv3-NAB (m = 1) | 54.81 M | 86.62 | 84.36 | 90.29 | 42.9 |
| YOLOv3-NAB (m = 2) | 61.87 M | 81.01 | 87.45 | 89.16 | 41.9 |
| YOLOv4-Tiny | 5.87 M | 71.35 | 58.77 | 63.99 | 20.6 |
| YOLOv4-Tiny-NAB | 7.05 M | 72.05 | 60.39 | 65.82 | 21.6 |
| Model | Ship | Bridge | Ground Track Field | Storage Tank | Basketball Court | Tennis Court | Airplane | Baseball Diamond | Harbor | Vehicle | Crossroad | T Junction | Parking Lot | mAP (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 92.65 | 92.04 | 98.40 | 93.99 | 83.17 | 96.06 | 99.57 | 93.05 | 95.02 | 92.69 | 93.92 | 83.62 | 70.09 | 91.10 |
| YOLOv3-SE | 94.37 | 92.72 | 98.31 | 94.47 | 84.05 | 95.81 | 98.73 | 93.62 | 92.79 | 96.91 | 92.31 | 82.86 | 70.67 | 91.35 |
| YOLOv3-CBAM | 94.63 | 92.78 | 98.71 | 96.89 | 82.35 | 95.12 | 99.54 | 93.63 | 97.27 | 97.02 | 92.51 | 84.72 | 72.03 | 92.09 |
| YOLOv3-NAB | 94.59 | 93.33 | 98.33 | 96.12 | 82.84 | 95.83 | 99.02 | 93.34 | 96.79 | 97.05 | 94.08 | 85.03 | 71.79 | 92.16 |
| YOLOv4-Tiny | 86.34 | 73.18 | 92.31 | 97.20 | 69.60 | 93.53 | 98.88 | 89.90 | 84.36 | 90.27 | 87.13 | 68.85 | 53.36 | 83.44 |
| YOLOv4-Tiny-NAB | 89.72 | 85.31 | 95.89 | 97.28 | 71.30 | 93.61 | 98.94 | 91.61 | 92.11 | 93.43 | 89.98 | 73.15 | 60.79 | 87.16 |
| Model | Aero | Bike | Bird | Bottle | Car | Cow | Dog | Horse | Sofa | Train | mAP (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 88.84 | 85.88 | 80.11 | 63.78 | 90.90 | 84.40 | 86.62 | 86.99 | 73.91 | 88.86 | 80.47 |
| YOLOv3-SE | 89.28 | 86.81 | 81.81 | 63.21 | 90.89 | 83.38 | 86.82 | 86.46 | 78.58 | 89.80 | 80.49 |
| YOLOv3-CBAM | 89.18 | 87.26 | 82.68 | 62.37 | 91.32 | 84.31 | 85.54 | 89.97 | 80.94 | 89.86 | 80.78 |
| YOLOv3-NAB | 89.65 | 87.78 | 81.74 | 65.97 | 91.02 | 86.89 | 86.38 | 87.18 | 71.55 | 88.70 | 81.35 |
| YOLOv4-Tiny | 84.06 | 85.29 | 74.35 | 62.55 | 90.54 | 81.41 | 77.86 | 86.55 | 73.10 | 84.39 | 77.08 |
| YOLOv4-Tiny-NAB | 87.21 | 87.09 | 76.97 | 66.72 | 91.77 | 80.75 | 79.52 | 87.67 | 73.18 | 86.75 | 79.06 |
| SSD | 77.81 | 84.93 | 75.35 | 42.32 | 86.50 | 77.35 | 86.99 | 88.60 | 73.52 | 84.93 | 75.8 |
| SSD-NAB | 79.75 | 85.06 | 77.55 | 45.79 | 85.61 | 77.15 | 85.67 | 87.80 | 74.46 | 86.66 | 76.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lang, K.; Yang, M.; Wang, H.; Wang, H.; Wang, Z.; Zhang, J.; Shen, H. Improved One-Stage Detectors with Neck Attention Block for Object Detection in Remote Sensing. Remote Sens. 2022, 14, 5805. https://doi.org/10.3390/rs14225805
Lang K, Yang M, Wang H, Wang H, Wang Z, Zhang J, Shen H. Improved One-Stage Detectors with Neck Attention Block for Object Detection in Remote Sensing. Remote Sensing. 2022; 14(22):5805. https://doi.org/10.3390/rs14225805
Chicago/Turabian StyleLang, Kaiqi, Mingyu Yang, Hao Wang, Hanyu Wang, Zilong Wang, Jingzhong Zhang, and Honghai Shen. 2022. "Improved One-Stage Detectors with Neck Attention Block for Object Detection in Remote Sensing" Remote Sensing 14, no. 22: 5805. https://doi.org/10.3390/rs14225805
APA StyleLang, K., Yang, M., Wang, H., Wang, H., Wang, Z., Zhang, J., & Shen, H. (2022). Improved One-Stage Detectors with Neck Attention Block for Object Detection in Remote Sensing. Remote Sensing, 14(22), 5805. https://doi.org/10.3390/rs14225805