1. Introduction
Due to the increasing intensity of military applications and marine resource development, the research on underwater acoustic communication technology has attracted more and more attention [
1,
2]. In recent years, underwater acoustic communication networks (UACNs) have become more and more widely used in marine data collection, pollution monitoring, disaster prevention, and marine rescue [
3,
4,
5]. However, because of the characteristics of the underwater environment, there are many disadvantages, such as limited bandwidth, limited energy supply, and prolonged propagation factors, which seriously restrict the development of underwater acoustic communication networks [
6,
7,
8].
Similar to terrestrial wireless communication, resource allocation is also a key issue for UACNs to solve. Compared with radio communication, resource allocation of UACNs undoubtedly faces more challenges [
9,
10]. (a) The bandwidth is narrow. The available bandwidth of the underwater acoustic channel is only a few kHz to several tens of kHz; (b) the energy limitation. Most acoustic modems are battery-powered, but in the underwater environment, the replacement and charging of the battery is extremely difficult. From the perspective of overhead, the energy problem of UACNs is more valuable than RF communication on land; (c) long time delay. The propagation speed of sound waves in water is about 1500 m/s [
11], which is much lower than that of electromagnetic waves in air, which makes it difficult to obtain real-time channel information in UACNs.
Moreover, only a single transmitter–receiver pair was required in the initial underwater applications, but as application requirements become more complex, multiple devices are required for simultaneous acoustic communication in the same area [
12]. When there are many underwater communication users, the communication environment is more crowded, and many users have to conduct communication activities in similar frequency bands, and the communication users will form confrontations and interfere with each other, thus affecting the communication quality of underwater communication users. Therefore, it is still a challenge for UACNs to design a resource allocation method with high efficiency and low overhead for the complex underwater acoustic communication environment.
In recent years, scholars from home and abroad have made some achievements in the research of resource allocation methods. The studies reported in [
13,
14] regard the power allocation problem as a resource optimization problem. However, the schemes proposed in the above studies are all applied in a centralized manner. The underwater communication environment is complex, and it is difficult to deploy a centralized control center underwater. Therefore, UACNs have strong distributed requirements. Game theory with distributed characteristics is an effective means to solve the problem of multi-user resource allocation in a strong adversarial environment. In [
15], game theory is used to maximize the throughput of UACNs, which improves the channel capacity and energy efficiency, but does not consider the problem of interference control between nodes in the network, so the communication service quality is relatively low, and the energy efficiency improvement is limited. In [
16], an environment-friendly power allocation method is proposed, which considers the impact of transmission power on marine organisms in the power allocation algorithm based on game theory and reduces the interference of underwater communication equipment on marine organisms.
However, all the above algorithms rely on the assumption that all users can perceive the channel gain information in time. In a complex underwater network environment, channel information and interference information may not be acquired by users in a timely manner. The time delay and time variability in underwater acoustic channels will eventually lead to the result that the feedback information obtained by the transmitter cannot reflect the real-time channel environment, which seriously affects the adaptive communication system’s inability to select the transmission power suitable for the real-time communication environment [
17]. Therefore, the unknown channel information makes it more difficult to solve the complex multi-user joint resource allocation problem, and traditional optimization methods cannot be easily applied to UACNs.
Reinforcement learning is widely used to solve the problems of policy optimization and policy selection. In other words, communicating nodes in UACNs can interact to adapt to changes in the environment, update optimized policies, and select appropriate actions. In general, reinforcement learning can realize the self-organizing network of UACNs, that is, improve the intelligence and autonomous adaptability of communication nodes, try to minimize human intervention, and perform self-configuration, self-optimization and self-healing [
18]. Multi-armed bandit (MAB) is a reinforcement learning decision theory that has shown strong applicability in dealing with problems involving unknown factors. Refs. [
19] and [
20], respectively, construct the routing problem and spectrum access problem in wireless networks as a MAB decision problem and use MAB theory to solve the game problem containing unknown information. However, the learning time of existing MAB-based wireless network algorithms is relatively long. According to literature statistics, it takes more than 10,000 learning times to reach the expected goal. Due to the limited energy, UACNs are not suitable for processing expensive learning algorithms [
21]. Based on this, this study proposes a MAB-based resource allocation algorithm with high learning efficiency for UACNs.
In this work, we study the resource allocation problem under interference constraints for an underwater acoustic communication system consisting of multiple pairs of transmitter and receiver nodes. In the literature, some works use MAB algorithms in reinforcement learning to solve the problem of resource allocation in wireless communication systems (this will be briefly introduced later in
Section 2), but the premise is that nodes must know all perfect channel gain and other policy information for the node. It is well-known that these assumptions will lead to a large amount of information exchange, and it is difficult to obtain information in real-time in complex underwater acoustic communication environments with time delays. Based on this, this paper studies the joint resource allocation problem of multi-users in the case of unknown channel information in UACNs and proposes a distributed, low-complexity, high-learning-efficiency learning game algorithm that does not rely on any prior channel information. The main contributions of this work include the following three aspects:
We construct a multi-agent MAB game model to characterize the joint resource allocation problem. To be more specific, the node is regarded as an agent, and the multi-node network is regarded as a multi-agent network, the multi-agent action space and reward function are constructed, and the optimal response strategy of each node is solved.
We propose a learning algorithm based on a Greedy-Softmax action selection strategy to solve this game problem. To be more specific, the proposed learning algorithm can be performed in a fully distributed manner, where nodes only need to record their own local information, without any prior information and direct information exchange, thus reducing the cost of resource allocation.
Furthermore, in order to improve the learning efficiency and reduce the learning cost, we propose a learning algorithm based on the two-layer HGL strategy. To be more specific, the historical reward information is named virtual learning information, and the introduction of virtual learning information into the algorithm can enrich the learning information of players, thereby improving their learning ability.
The rest of this paper is organized as follows.
Section 2 reviews the related work, and
Section 3 expounds the UACNs model and the construction method of the multi-node MAB game model.
Section 4 demonstrates the effectiveness of the constructed model. The multi-node MAB game learning algorithm is analyzed in
Section 5.
Section 6 verifies the effectiveness of the designed scheme from multiple perspectives, and
Section 7 presents the conclusion.
2. Related Work
Power allocation plays an important role in underwater acoustic communication networks. In [
22,
23], the resource allocation problem in the wireless network is constructed as a goal optimization problem, and the traditional optimization algorithm is used to solve the goal. However, traditional optimization algorithms are centralized optimization algorithms. When applied in actual wireless networks, a central information processor is a must, yet it is difficult to build a CPU in an underwater environment. The centralized algorithm requires a very large information exchange overhead, which can not be borne by underwater acoustic communication.
In [
15], a MAC protocol is proposed, and a distributed method is adopted to adjust the transmission power to maximize the throughput of the underwater communication network. In [
13], a distributed power allocation algorithm is proposed, which considers power allocation schemes of different available power levels for different network densities to reduce energy consumption. Although the power allocation methods in the above literature are distributed, there must be an assumption that the channel information is ideal. The underwater acoustic channel is extremely complex. In different environments, the state information of the channel will change at any time. The underwater communication environment is constantly changing due to the influence of ocean currents and other factors. Communication nodes will move with the current, and the channel state information is constantly changing. The channel state information has strong uncertainty [
24,
25]. However, the performance of the algorithm based on ideal channel information will inevitably decline when it is applied to the underwater acoustic communication network with strong uncertainty. Therefore, it is necessary to propose a robust optimization algorithm to reduce the impact of uncertainties on resource allocation.
The nodes in the underwater acoustic communication network are independent individuals, which are very rational and selfish [
26]. Game theory means that both sides of the game can maximize their own benefits in the game and can also play a great role in the resource allocation problem of wireless sensor networks. Based on the game theory, in [
27], an adaptive distributed power allocation scheme is proposed to solve the power allocation problem of multiple nodes. A distributed game power allocation algorithm considering node residual energy is proposed in [
28] to improve the channel capacity of network communication. Meanwhile, a robust game spectrum allocation algorithm is proposed in [
29] to maximize the utility function of nodes and improve the communication quality of nodes. Although the game theory algorithm proposed in the above literature can solve the distributed optimization problem, it requires accurate channel state information for resource allocation.
When the underwater communication environment is greatly affected by ship, sunlight and other factors, the underwater acoustic communication environment is harsh, the channel state information is extremely difficult to determine, and the channel state information and interference information cannot be directly obtained. On the one hand, the traditional optimization methods can not be effectively applied to the actual communication scenarios where users vary. On the other hand, the traditional learning methods have too little learning information, resulting in very low learning efficiency. Therefore, efficient and adaptable reinforcement learning algorithms are urgently needed to solve the joint resource allocation problem in complex communication networks [
30,
31]. Next, we further outline the resource allocation method based on MAB theory.
In recent years, MAB has been gradually applied to solve various resource allocation problems in complex cognitive radio communication environments [
32,
33]. In terms of power allocation, a low-cost UCB1-based water-filling algorithm is proposed in [
34] for single-user multi-channel models; in [
35], a joint resource allocation method based on MAB theory is proposed for multi-channel multi-user networks. However, the problem of interference control between users in the network is not considered in its model. The above algorithms based on MAB theory all effectively overcome the unknown prior information of the channel and improve the performance of the network. However, the existing MAB-based algorithms have very long learning times due to their unique learning methods and less learning information. In general, it takes up to 10,000 learning times to reach the desired policy [
36]. Undoubtedly, for a wireless network with heavy traffic, such a large learning time is unacceptable.
Inspired by the above research, this work applies the idea of MAB to the resource allocation problem of UACNs and proposes a learning algorithm based on a two-layer HGL policy to implement interference control among communication nodes in the network, so as to improve the overall service quality of the network and reduce the level of network interference.
4. Problem Formulation
In the multi-agent MAB game problem, the goal of each agent is to maximize its own utility (return value). In [
15], the utility function constructed for agent
is described as follows
where
denotes the price factor, which is set to
, which represents the maximum transmit power of the node. Obviously, the benefit part of the utility function described by Equation (
5) is the node channel capacity, and the cost part is the product of the unit power price and the node transmit power. However, this utility function does not take the level of interference in the network into consideration. Since the optimal transmit powers of nodes all affect each other, if only its own power cost is considered in the utility function, while the mutual interference between nodes is not considered, then each transmitting node will try to transmit data at a higher power level. This will not only make the interference in the network more serious and reduce the quality of network service but also shorten the node’s survival time.
To address the shortcomings of the above algorithm and to improve the quality of network services, this study makes the following improvements to the utility function:
where the first term represents the channel capacity when the node power is
and the second term is the network interference level penalty term.
indicates that node
is subject to interference from other transmitting nodes and environmental noise.
is the adjustment coefficient. Through the above analysis, in the multi-agent MAB game problem in this work, the optimization problem for each agent
i can be expressed as
The purpose of the game is to seek an optimal combination of strategies, i.e., a Nash equilibrium, which can make the strategy of each agent be the optimal response to the strategies of other agents [
40]. Next, the existence and uniqueness of the newly constructed game model Nash equilibrium will be proved.
Definition 1 (Nash Equilibrium [
41]).
Let be a strategy combination of a game , if all is true for each player i: , then strategy combination is a Nash equilibrium of the game. represents the strategy chosen by player i that is different from , and represents the combination chosen by all participants except i in all agents. At the Nash equilibrium point, the power value of other users is constant, and no user can improve its utility by simply changing its power value. The Nash equilibrium point is an equilibrium point obtained in the competition that each participant is unwilling to deviate from. The following proves the existence and uniqueness of the Nash equilibrium point in the MAB game model [
15,
40,
41].
Theorem 1. There is a Nash Equilibrium in .
Proof. According to Nash’s theorem, has a Nash equilibrium if the following conditions are met.
- (a)
is a non-empty, closed and bounded convex set of Euclidean space ;
- (b)
is continuous on and quasi-concave on .
Since the policy space of each node is defined in , the first condition is obviously satisfied. For condition (b), it is obvious that is continuous on , so it is only necessary to prove that is quasi-concave on .
The first-order partial derivative of the utility function
with respect to
is:
The second-order partial derivative of the utility function
with respect to
is:
Since , is concave in , a concave function is also a proposed concave function, so there is a Nash equilibrium in .
The optimal solution of
is
. For continuously differentiable functions, the necessary condition for first-order optimization is
, which can be obtained from Equation (
11)
Therefore, Equation (
13) is the pricing function of the power policy
, where
indicates that the transmission power is non-negative. Further, the value range of
can be obtained
That is, if the price per unit of power exceeds this range, no user can benefit from the system. The optimal solution of
is
□
Theorem 2. The Nash equilibrium of is unique.
Proof. According to Theorem 2, there is a Nash equilibrium in
, and its Nash equilibrium solution is assumed to be
. According to Equation (
15), the interference equation is
, where
. The interference equation
is said to be standard if the following properties are satisfied for all non-negative power vectors, (a) positive,
> 0, (b) monotonic, (c) scalability,
. The standard equation converges to a unique point. Therefore, to prove the uniqueness of the Nash equilibrium, it is only necessary to prove that
is a standard function, that is, it satisfies positivity, monotonicity and measurability.
Positivity. According to the value range of the pricing function, it can be guaranteed that there must be a node whose power level > 0, then > 0.
Monotonicity. For
, let
,
It can be seen from Equation (
16) that when
,
. Therefore,
is a single decreasing function, and it takes the equal sign when
.
For the above formula, we only need to prove
when discussing
in the previous section, we obtain
From the positive condition, we can obtain , and it is easy to obtain . Hence .
In summary, the interference equation is a standard function, so has a unique Nash equilibrium solution. □
6. Scheme Analysis and Evaluation
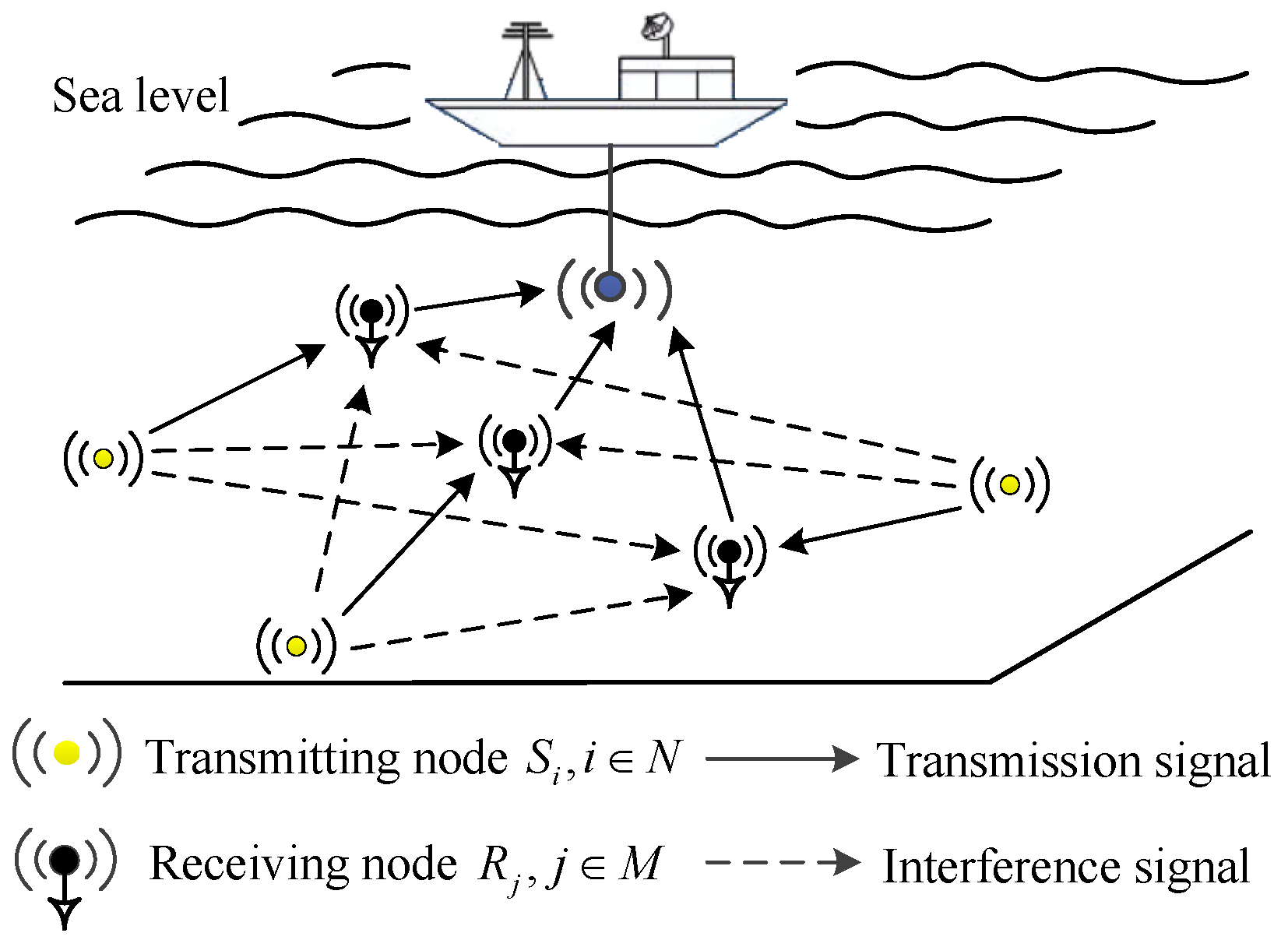
This section verifies the superiority of the proposed algorithm by comparing five learning strategies (HGL, Softmax-greedy,
-greedy, Greedy, Random). In the simulation, we assume that there are six nodes in which three transmitting nodes and three receiving nodes are randomly distributed in an area 2 km deep, 3 km long and 2 km wide. For the above scenario, we will analyze the following four aspects: a. the impact of different parameters
in softmax-greedy on the algorithm. b. Comparison of four strategies such as softmax-greedy and
–greedy. c. Comparison of improved HGL and softmax-greedy in terms of convergence and SINR. d. The proposed HGL is compared with the other four learning strategies in dynamic environments. Note that the size of the underwater target area is not limited when considering a dynamic environment. As shown in
Figure 2, the circle indicates the transmitting node, the diamond indicates the receiving node, and the coordinate information of the nodes is shown in
Table 1. During the operation of the network, the transmitting node
and the corresponding receiving node
perform information transmission. Considering the random and non-stationary characteristics of underwater signals, the influence of underwater uncertain factors on the underwater acoustic channel is reflected by the variable
, where
, and
obeys the Rayleigh distribution with a mean of 0.1. Therefore, in the simulation, the underwater acoustic channel gain adopts
. Meanwhile, set the carrier frequency to be 20 kHz, the propagation coefficient to be 1.5, the signal bandwidth to be 10 kHz, the gain per unit rate to be 0.05, and the maximum transmit power of the node to be 10 W. In addition, in order to facilitate the display of experimental results, we add a coefficient
before the first term of Equation (
6), so that
is equal to ln2, and at the same time,
takes the value 0.01.
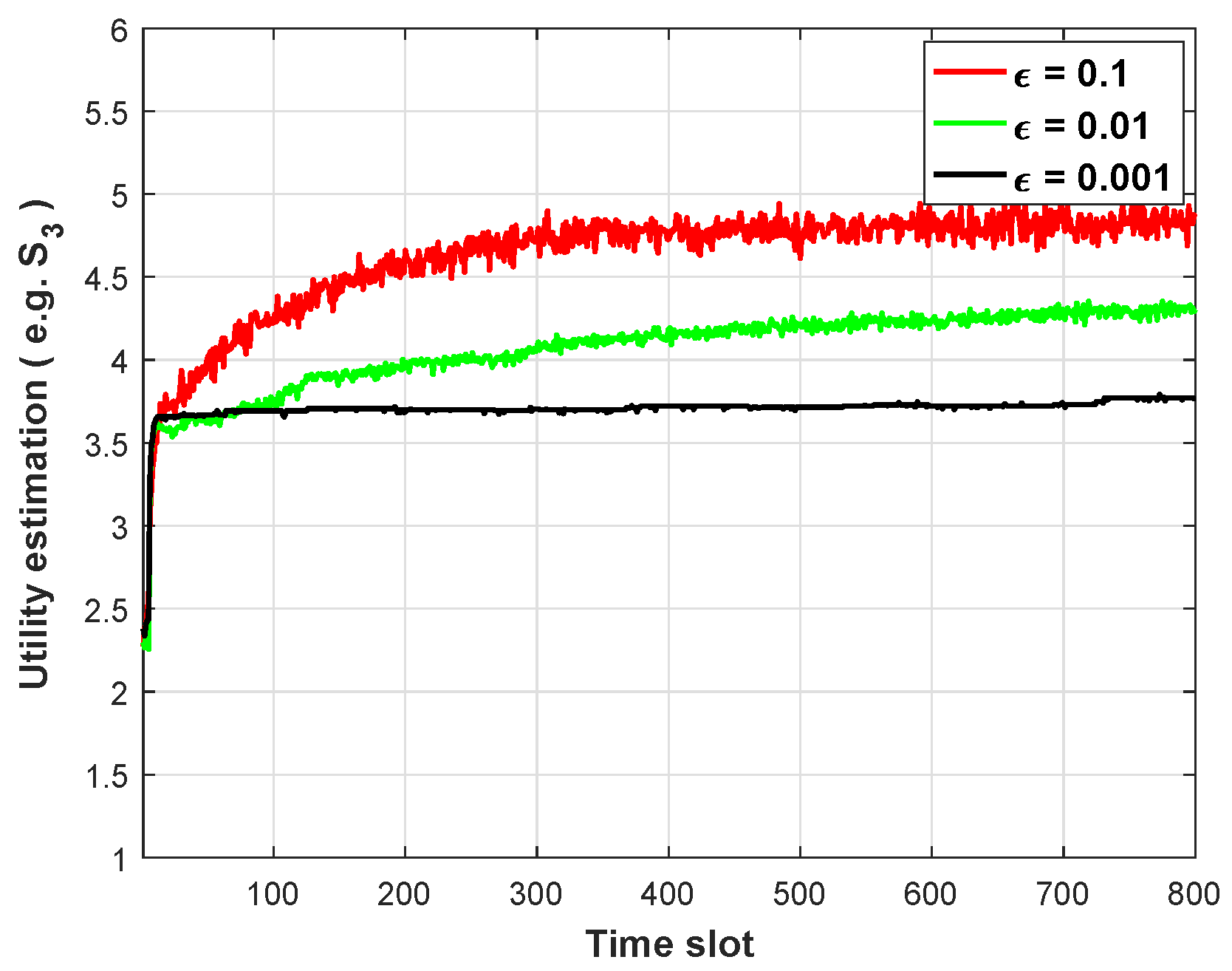
Figure 3 describes the impact of different
on the softmax-greedy algorithm convergence when softmax-greedy action selection strategy is adopted. In this section, the values of
are taken as 0.1, 0.01 and 0.001, respectively. As can be seen from the above discussion, the MAB algorithm has two stages: exploration and utilization. When the agent is in an unfamiliar environment, it needs to explore the environment more, and agents can change the proportion of exploration and exploitation by adjusting
. In the exploration phase, the softmax-greedy strategy estimates the
Q value corresponding to each action. From
Figure 3, we can observe that within a reasonable range of values, the smaller the
, the slower the convergence speed of the algorithm. The reason is that when the value of
is small, the agent has a greater probability of selecting an action through the Greedy strategy, that is, it tends to select the power with the largest
Q value. This ignores other actions with more value, resulting in incomplete exploration. In order to ensure the convergence of the algorithm, we make
= 0.1 in the next simulation experiments.
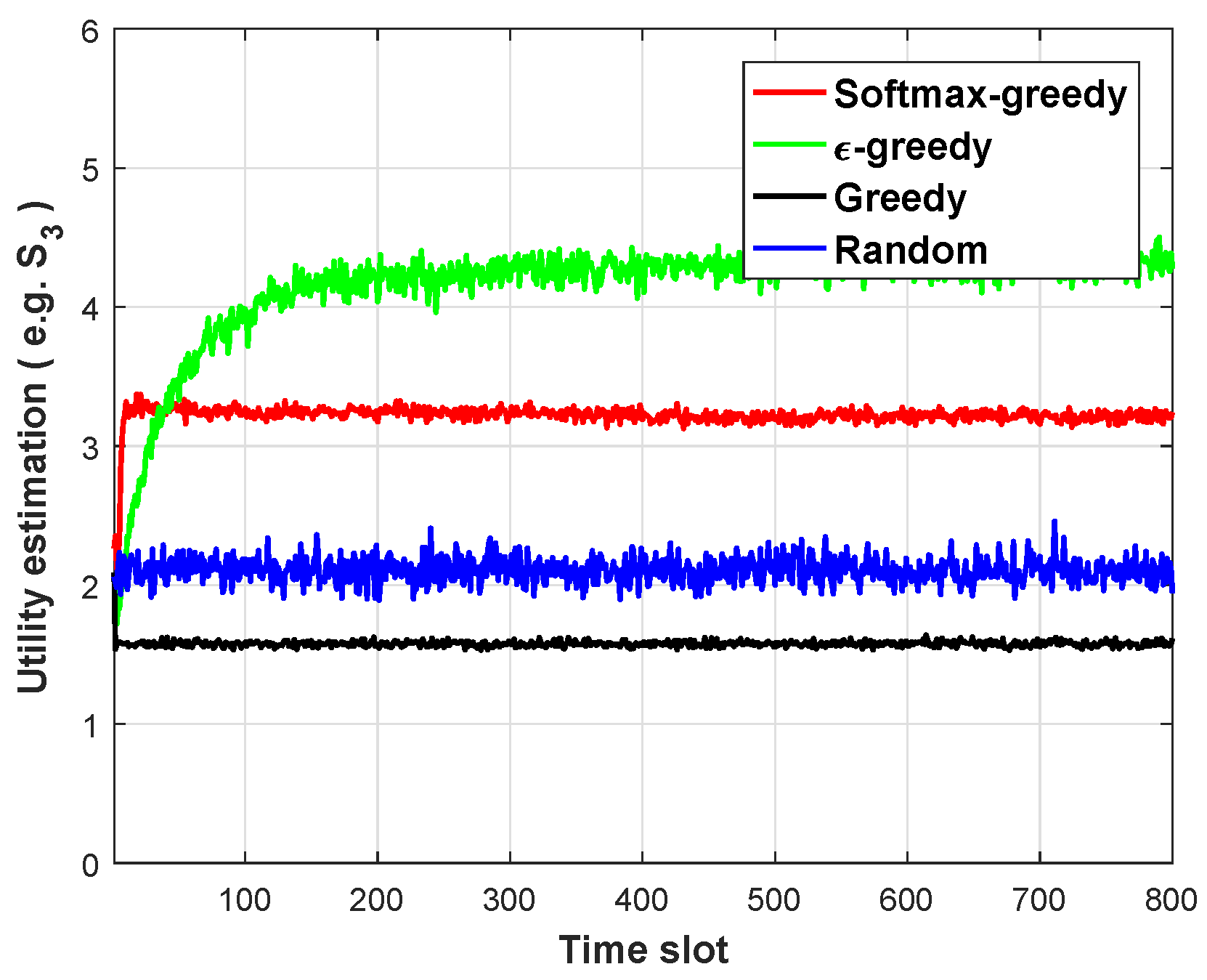
Further, this section verifies the superiority of the softmax-greedy algorithm by comparing the performance of four learning algorithms (softmax-greedy,
-greedy, Greedy, Random).
Figure 4 compares the performance of four algorithms, softmax-greedy,
-greedy, greedy and random, demonstrating the effectiveness of the proposed algorithm. The key to learning algorithms is to maintain an explore–exploit balance. The greedy strategy only emphasizes “exploitation”, that is, the agent tends to choose the strategy that seems to have the greatest utility at present, while the random strategy only emphasizes “exploration”, which always chooses an action randomly and uniformly with the same probability. The
-greedy strategy balances “exploration” and “exploitation” with the help of
, but during “exploitation”, it still randomly selects an action with the same small probability (
). In contrast, the softmax-greedy strategy will make the action with more utility have a greater probability of being selected, i.e., not forgetting to take advantage of it during exploration. Therefore, from
Figure 4, we can observe that in terms of stability, greedy > softmax-greedy >
-greedy > random, and in terms of performance,
-greedy > softmax-greedy > random > greedy. Overall, the softmax-greedy strategy has the best overall performance.
It can be seen from
Figure 4 that softmax-greedy is slightly lower than
-greedy in terms of performance, mainly because the softmax-greedy strategy is more inclined to select actions with higher returns in exploration, and a very small amount of learning information limits the degree of exploration. Subsequently,
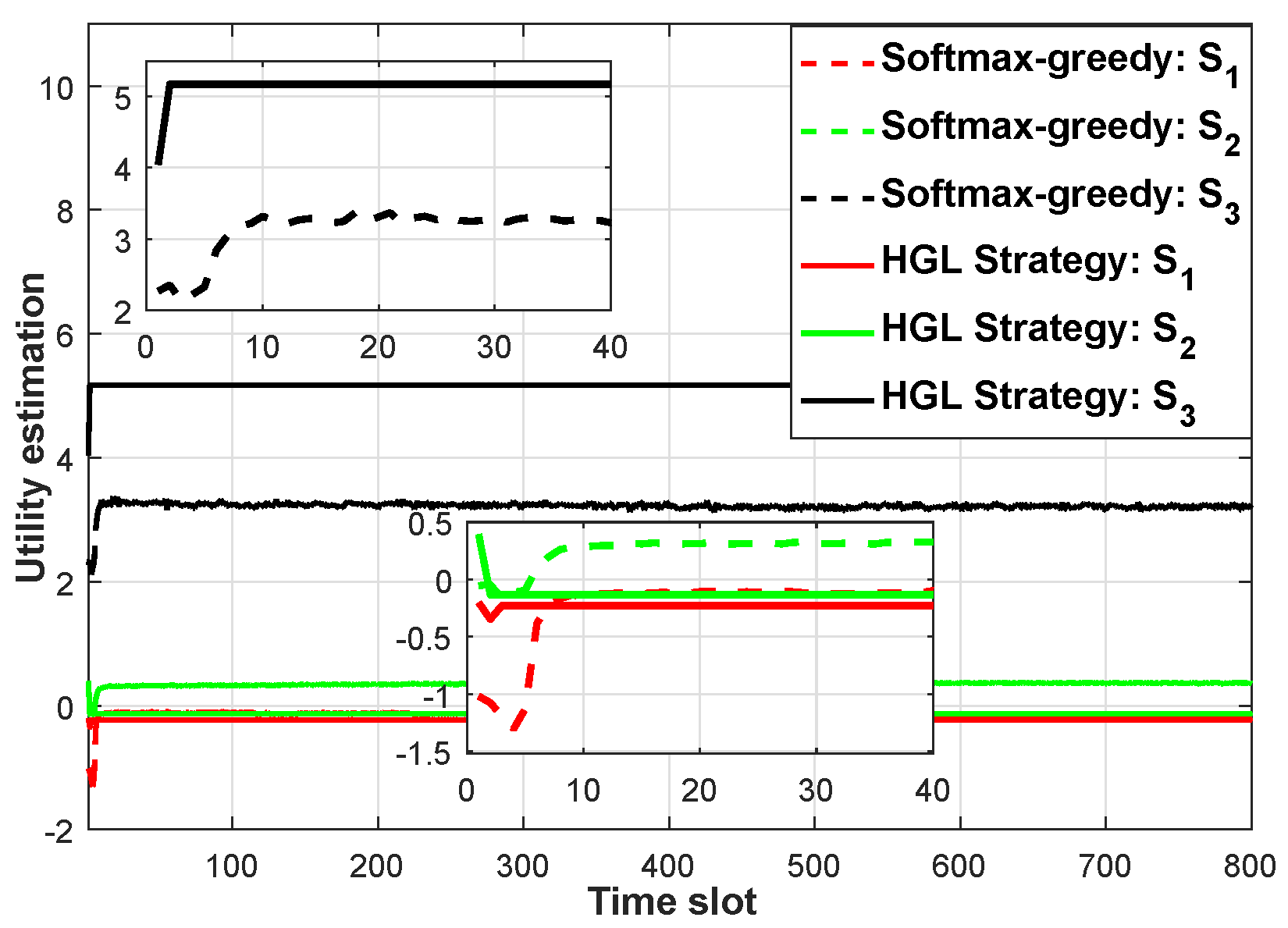
Figure 5 shows the variation of the utility of the three nodes with time slots under the guidance of the softmax-greedy strategy and HGL strategy, respectively. Obviously, compared with the softmax-greedy strategy, the HGL strategy can make the three nodes quickly reach the convergence state after a short fluctuation. Therefore, based on the softmax-greedy strategy, the proposed HGL strategy can enrich the learning information of the agent by mining historical reward information, improve the learning efficiency and reduce the learning cost of the algorithm.
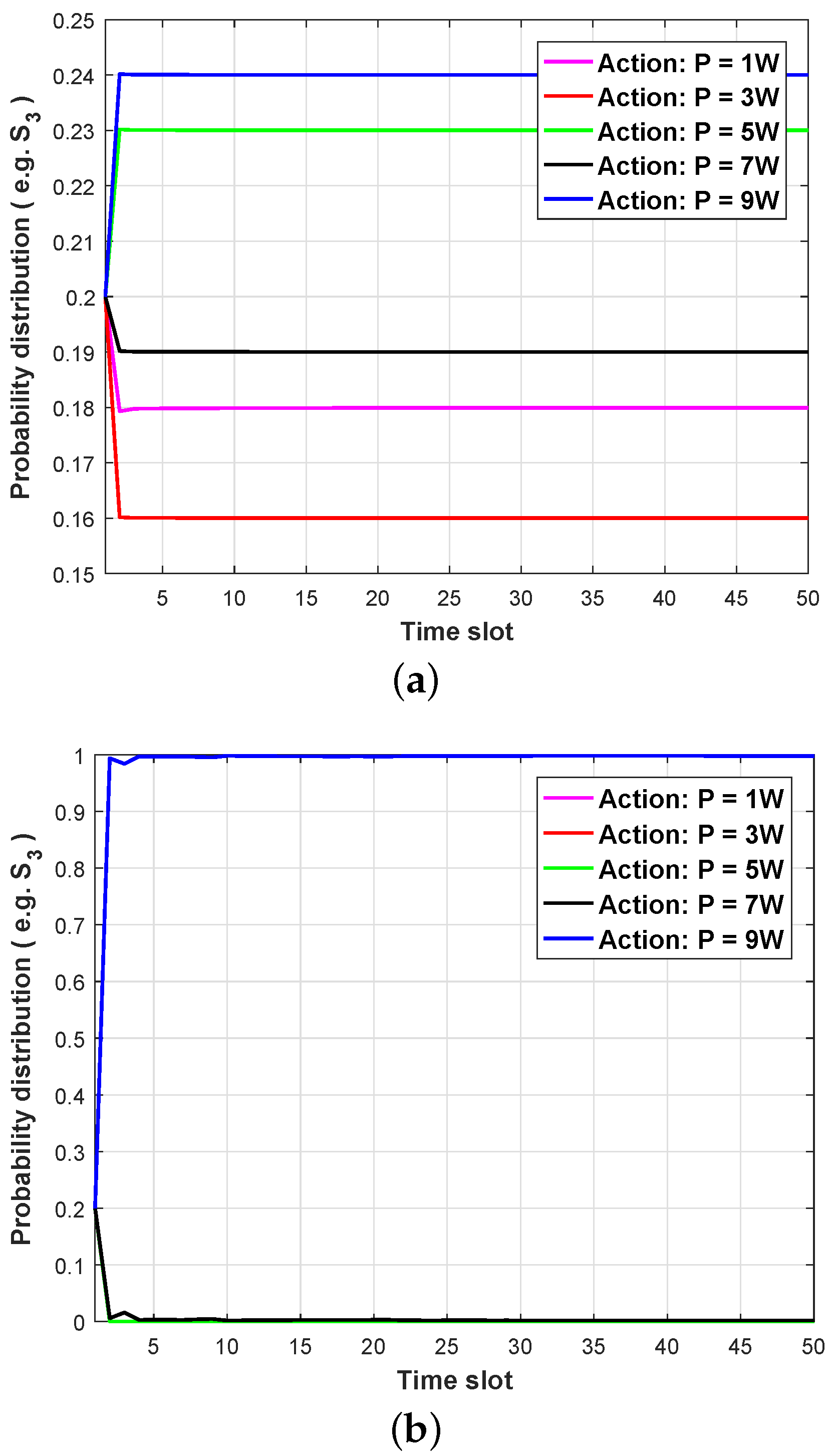
In order to verify the effectiveness of the HGL strategy, we further analyze the strategy probability distribution of node
under the guidance of the two strategies. It can be seen from
Figure 6 that in the initial stage, the probability of each strategy being selected is equal, which is 0.2. As the number of learning increases, the expected utility
corresponding to each action will gradually change. Subsequently, the Boltzmann distribution is used as a random strategy to increase the probability of action with large
being selected and, conversely, to decrease the probability. It can be seen from
Figure 6 that the convergence speed and effect of the HGL strategy are better than those of the softmax-greedy strategy. In the HGL strategy, each discrete strategy can converge to a pure strategy after less iteration, while the softmax-greedy strategy can only converge to a mixed strategy. This is mainly because the number of learning times a node can obtain in one learning of the two-layer HGL strategy is one more than that of the single-layer learning algorithm. More importantly, the added virtual learning information enriches the learning information of nodes, and these virtual pieces of information are optimized information based on the actual execution information, so the two-layer HGL strategy can significantly improve the learning efficiency and reduce the number of learning times.
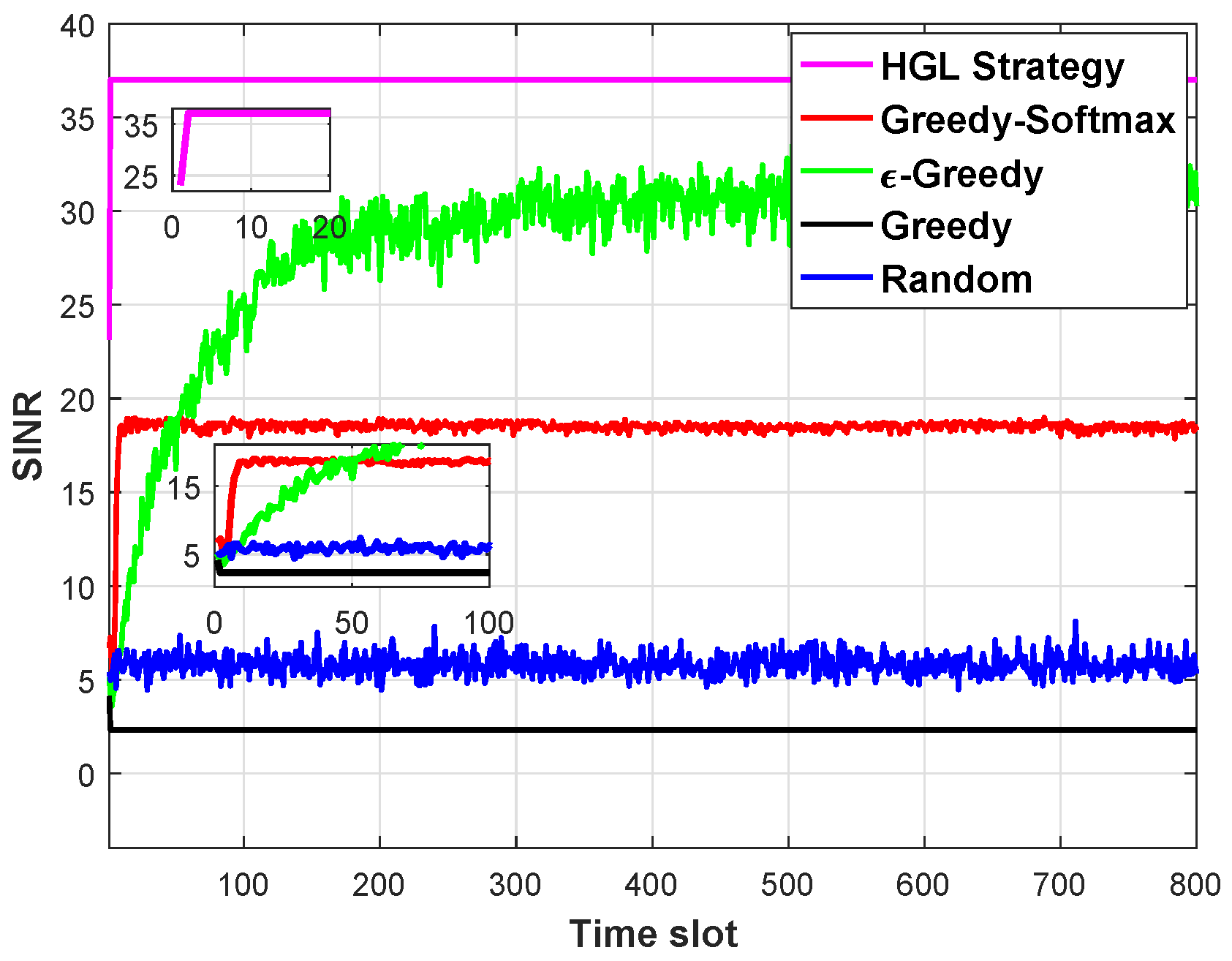
In
Figure 7, we compare the SINR performance of the HGL strategy and other strategies under different time slots. We can observe that the two-layer HGL strategy can obtain the best SINR performance. This is due to the efficient hierarchical learning method that greatly enhances the learning ability of the HGL learning algorithm. Specifically, in the lower-level learning, historical decision information is constructed as virtual information, and the agent learns the virtual information and mines the environmental information, thereby improving the learning efficiency.
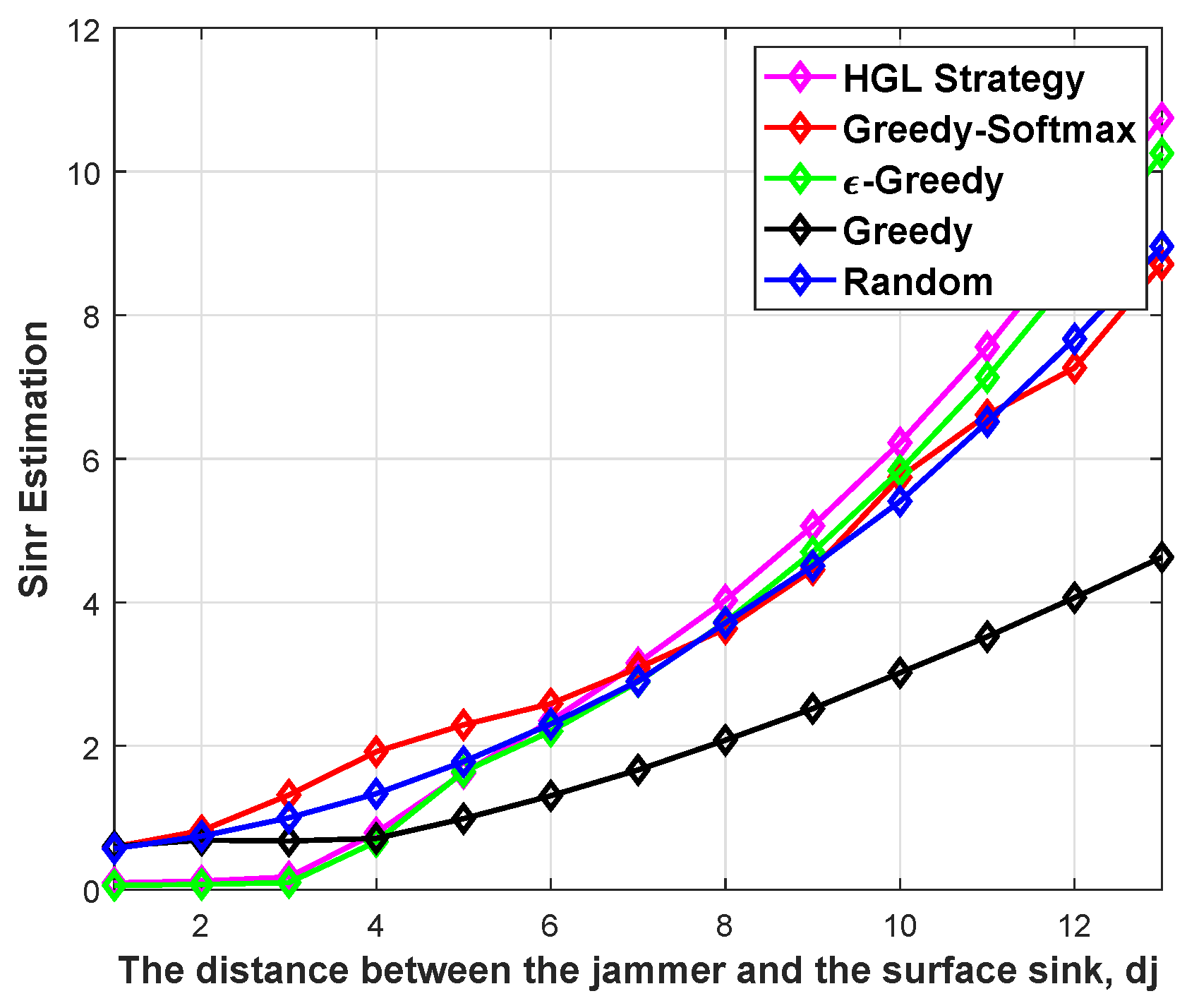
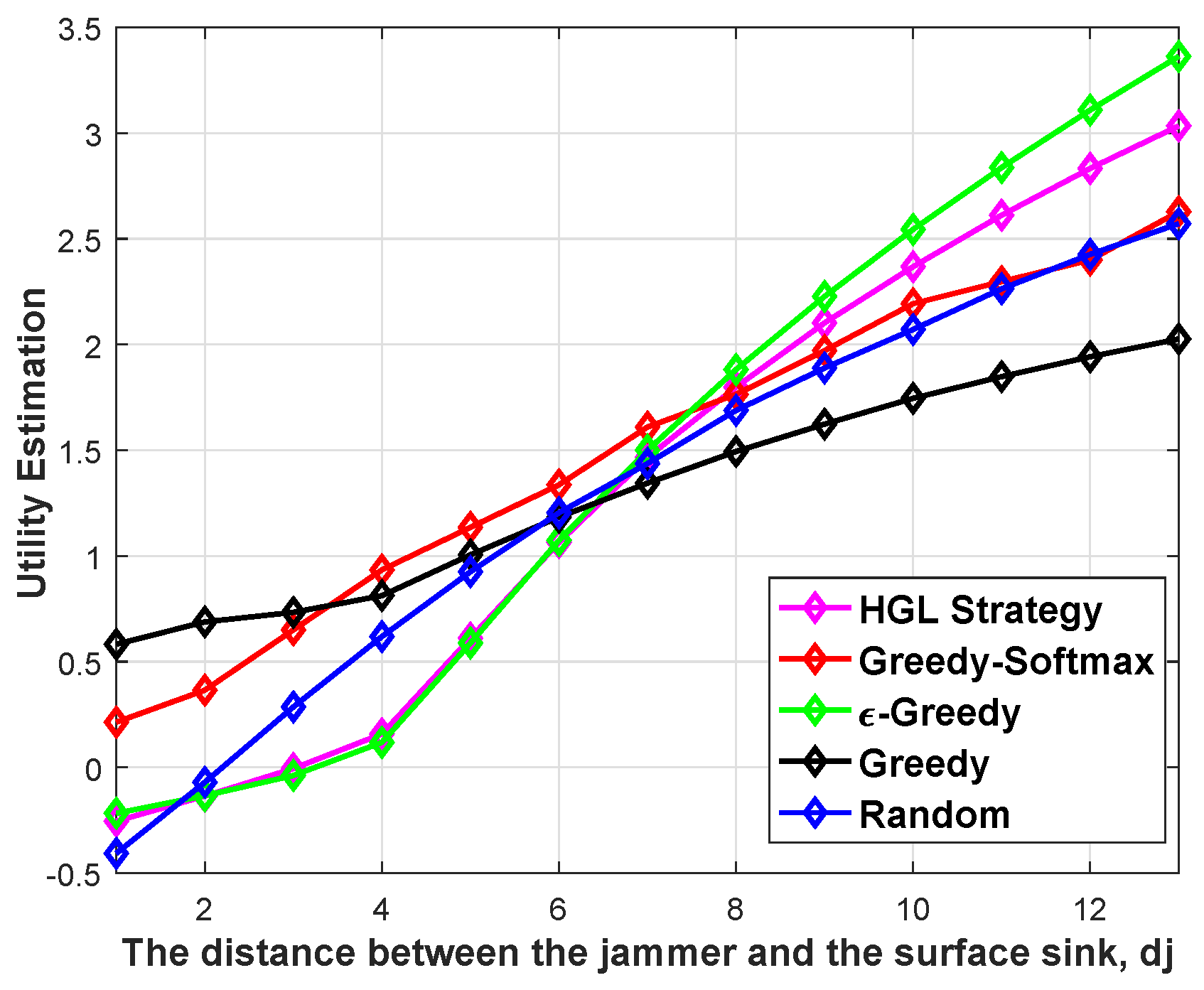
Next, we show how the performance of five strategies varies with distance in a dynamic water environment. Assuming that the transmitter-receiver pair 1 and 3 are in the same position in the target waters, the transmitter-receiver pair 2 moves in a certain direction. In other words, the distance between the transmitter-receiver pair 2 and the transmitter-receiver pair 1 and 3 is becoming farther and farther.
Figure 8 and
Figure 9 show the effect of distance
on the performance of the proposed scheme,
= [0.35, 0.5, 0.65, …, 2.3] km, where
represents the distance from transmitting node
to transmitting node
. Two conclusions can be drawn from
Figure 8. On the one hand, the utility of the node increases with the increase in
. This is mainly because with the increase in
, the interference suffered by node
decreases continuously. On the other hand, the HGL strategy improves the adaptive ability of node
, that is, it can quickly adjust the power according to the changes in the environment. When
is less than 7 km, node
S2 suffers a lot of network interference and has a low utility; on the contrary, when
is greater than 7 km, node
has a high utility. Similarly, it can be seen from
Figure 9 that the SINR of the signal increases with the increase in
. It is further confirmed that the proposed algorithm has strong adaptive ability and can adjust the transmit power of the node according to the changes in the environment.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}