
Lite-YOLOv5: A Lightweight Deep Learning Detector for On-Board Ship Detection in Large-Scene Sentinel-1 SAR Images




Abstract
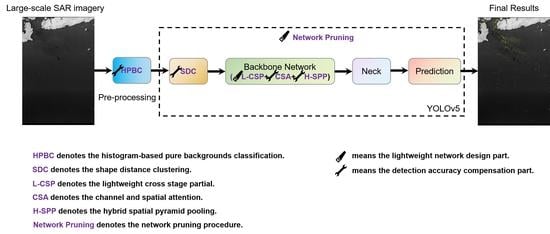
:
1. Introduction
- In order to obtain a lightweight network, we (1) design a lightweight cross stage partial (L-CSP) module for reducing the amount of calculation and (2) apply network pruning for a more compact detector.
- In order to ensure the detection performance, we (1) propose a histogram-based pure backgrounds classification (HPBC) module for excluding pure background samples to effectively suppress false alarms; (2) propose a shape distance clustering (SDC) model for generating superior priori anchors to match ship shape better; (3) apply a channel and spatial attention (CSA) model for paying more attention to regions of interest to enhance ships feature extraction capacity; and (4) propose a hybrid spatial pyramid pooling (H-SPP) model for increasing the context information of the receptive field to attach importance to key small ships.
- We conduct extensive ablation studies to confirm the effectiveness of each above contribution. The experimental results on the Large-Scale SAR Ship Detection Dataset-v1.0 (LS-SSDD-v1.0) reveal the state-of-the-art on-board SAR ship detection performance of Lite-YOLOv5 compared with eight other competitive methods. In addition, we also transplant Lite-YOLOv5 on the embedded platform NVIDIA Jetson TX2 to evaluate its on-board SAR ship detection ability.
2. Methodology
2.1. Network Structure of YOLOv5
2.2. Network Structure of Lite-YOLOv5
2.3. Lightweight Network Design
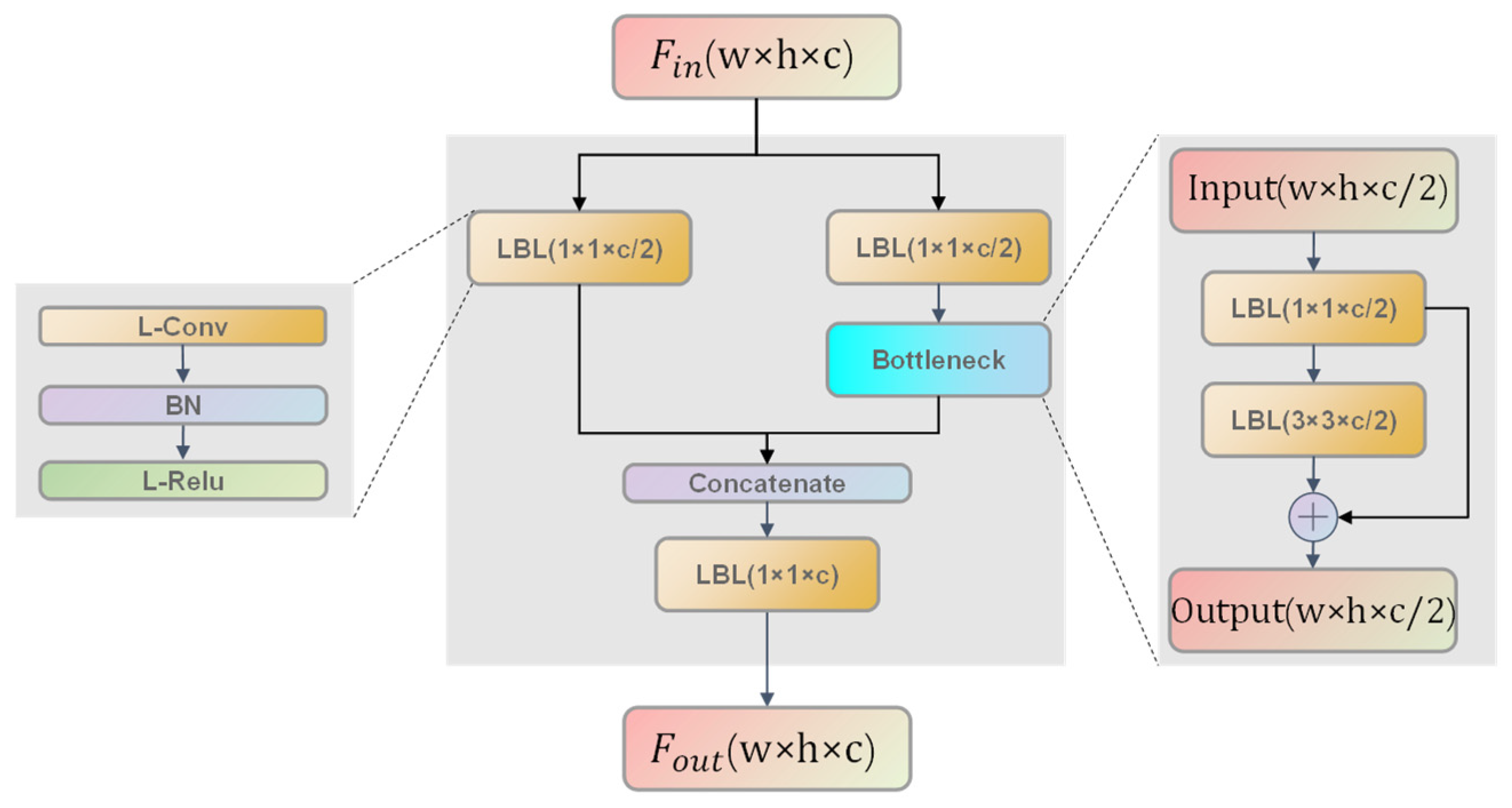
2.3.1. L-CSP Module
2.3.2. Network Pruning
2.4. Detection Accuracy Compensation
2.4.1. HPBC Module
2.4.2. SDC Module
2.4.3. CSA Module
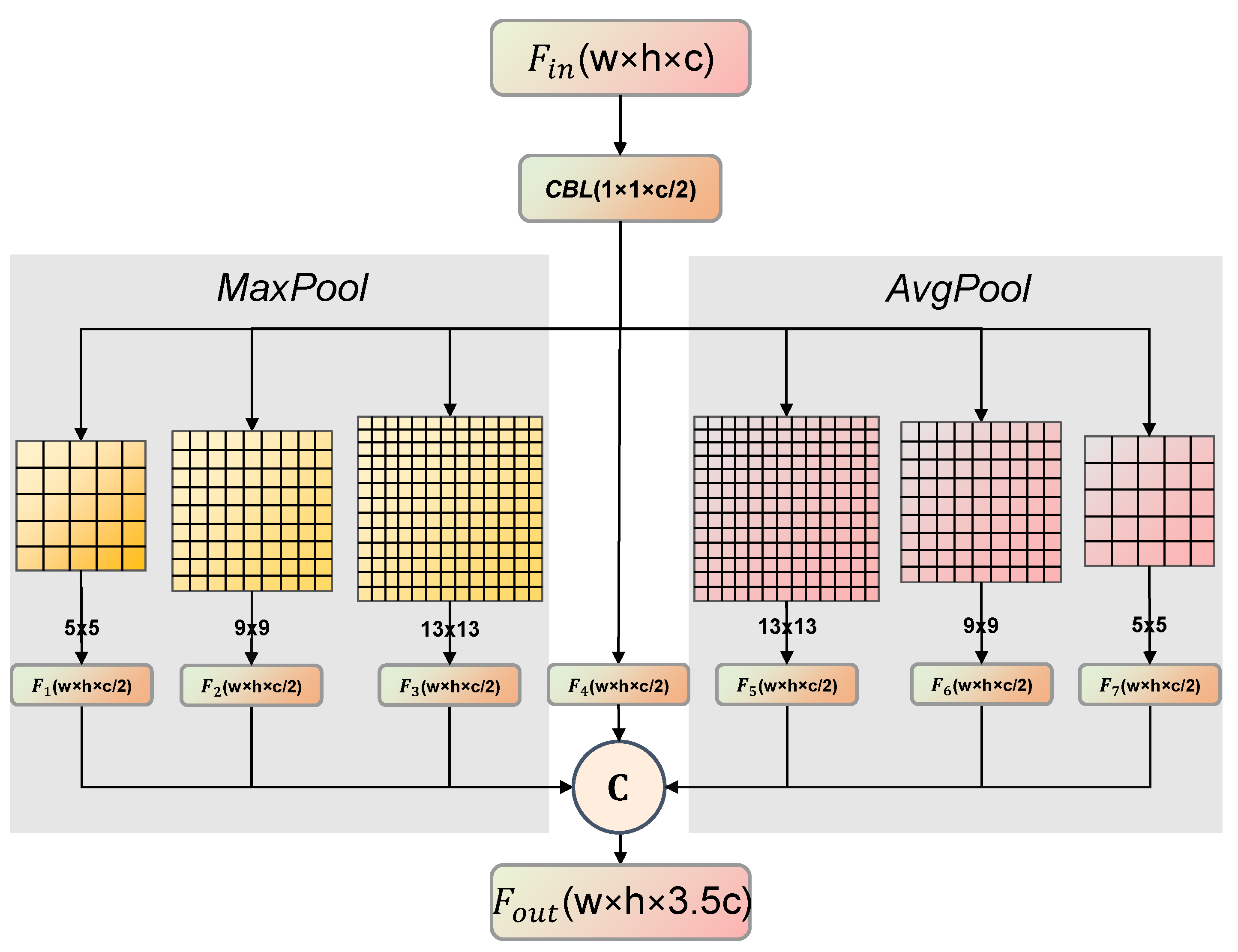
2.4.4. H-SPP Module
3. Experiments
3.1. Experimental Platform
3.1.1. Training Experimental Platform
3.1.2. Testing Experimental Platform
3.2. Dataset
3.3. Experimental Details
3.4. Evaluation Indices
4. Results
4.1. Quantitative Results
- Compared with YOLOv5, our Lite-YOLOv5 can guarantee the model is lightweight and realize the slight improvement of detection performance at the same time.
- On the one hand, as for accuracy indices, Lite-YOLOv5 can make a 5.97% precision improvement (i.e., from 77.04% to 83.01%), 1.12% AP improvement (i.e., from 72.03% to 73.15%), and 1.51% F1 improvement (i.e., from 72.01% to 73.52%). This fully reveals the effectiveness of the proposed HPCB, SDC, CSA, and H-SPP modules.
- On the other hand, as for other evaluation indices, Lite-YOLOv5 can realize on-board ship detection with 37.51 s per large-scale image (73.29% of the processing time of YOLOv5), a lighter architecture with 4.44 G FLOPs (26.59% of the FLOPs of YOLOv5), and 2.38 M model volume (14.18% of the model size of YOLOv5). This fully reveals the effectiveness of the proposed L-CSP module and network pruning.
- What stands out in this table is the competitive accuracy performance with the greatly reduced model volume of Lite-YOLOv5.
- The AP and F1 of Lite-YOLOv5 cannot reach the best performance at the same time; nevertheless, the excellent performance of the other evaluation indicators can make up for it. More prominently, with the tiny model size of ~2 M and competitive accuracy indicators, Lite-YOLOv5 can ensure a superior on-board detection performance.
- Compared with the experimental baseline YOLOv5, Lite-YOLOv5 offers ~1.1% AP improvement (i.e., from 72.03% to 73.15%) and ~1.5% F1 improvement (i.e., from 72.01% to 73.52%). This fully reveals the effectiveness of the proposed HPBC, SDC, CSA, and H-SPP modules.
- Compared with the experimental baseline YOLOv5, Lite-YOLOv5 offers the most lightweight network architecture with 4.44 G FLOPs (~26.6% of the FLOPs of YOLOv5), 1.04 M parameter size (~14.7% of the parameter size of YOLOv5), and ~ 2 M model volume (~14.2% of the model size of YOLOv5). This fully reveals the effectiveness of the proposed L-CSP module and network pruning.
- Libra R-CNN offers the highest F1 (i.e., 75.93%), but its AP is rather poor to satisfy the basic detection application, i.e., its 62.90% AP << Lite-YOLOv5′s 73.15%. Furthermore, its detection time, FLOPs, parameter size, and model volume are all one or two orders of magnitude than those of Lite-YOLOv5, which is a huge obstacle for on-board detection.
4.2. Qualitative Results
- In the offshore scenes, Lite-YOLOv5 can offer high-quality detection results even under the environment of strong speckle noise. Most other methods always produce the missed alarms caused by speckle noise. Taking the second line of images as an example, there were four missed detections of RetinaNet and three missed detections of YOLOv5, which are both more than that of Lite-YOLOv5 (only one missed ship).
- In the inshore scenes, Lite-YOLOv5 can offer high-quality detection results even under the environment of ship-shaped reefs and buildings near shore. Most other methods always produce the missed alarms caused by them. Taking the fourth line of images as an example, there were two missed detections of RetinaNet and two missed detections of YOLOv5, which are both more than that of Lite-YOLOv5 (only one missed ship).
- Lite-YOLOv5 can offer an advanced on-board ship detection performance compared with other state-of-the-art methods.
5. Ablation Study
5.1. Ablation Study on the L-CSP Module
5.2. Ablation Study on Network Pruning
5.2.1. Experiment 1: Effectiveness of Network Pruning
5.2.2. Experiment 2: Effect of Channel-Wise Pruning
5.3. Ablation Study on the HPBC Module
5.4. Ablation Study on the SDC Module
5.5. Ablation Study on the CSA Module
5.6. Ablation Study on the H-SPP Module
6. Discussion
7. Conclusions
- We will decrease the detection time further.
- We will lighten the detector further without sacrificing the accuracy.
- We will explore a reasonable hardware acceleration scheme for on-board SAR ship detection.
- We will explore other viable approaches such as distillation techniques in the following lightweight detector design.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
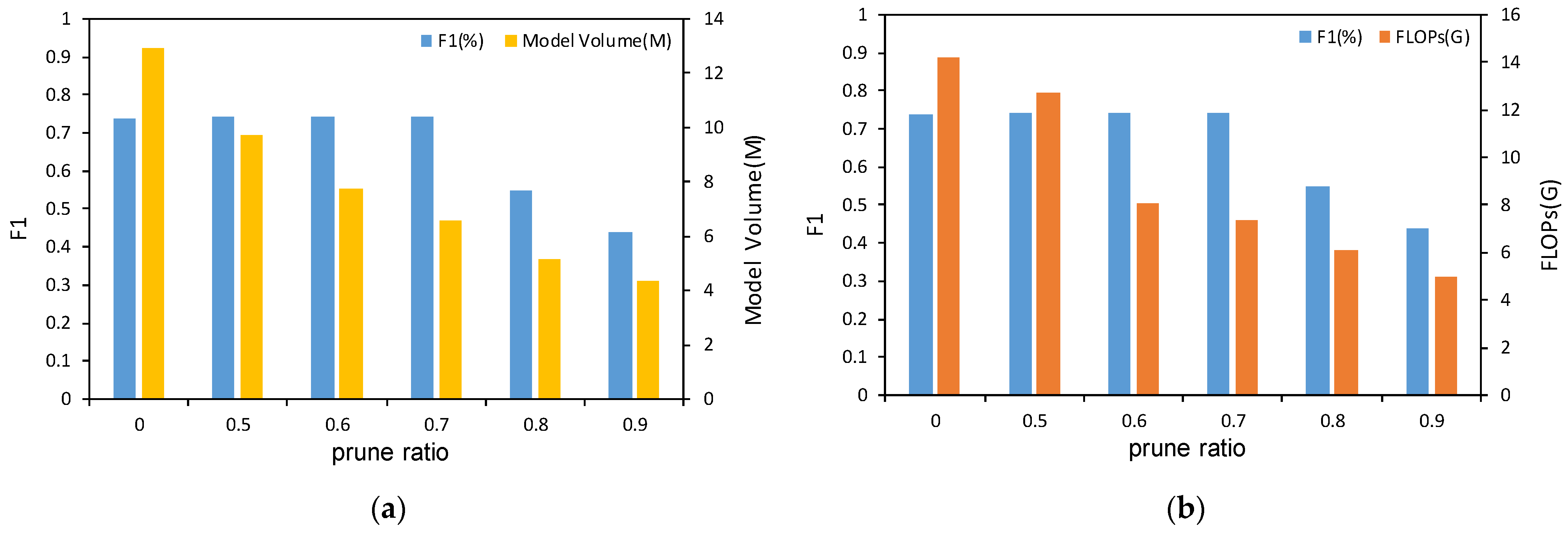{kind=link}
| Abbreviation | Full Name |
|---|---|
| AP | average precision |
| BN | batch normalization |
| Conv | convolution |
| CFAR | constant false alarm rate |
| CNN | convolutional neural network |
| CSA | channel and spatial attention |
| CSP | cross stage partial |
| CV | computer vision |
| DAPN | dense attention pyramid network |
| DL | deep learning |
| DS-CNN | depth-wise separable convolution neural network |
| FFEN | fusion feature extraction network |
| FL | focal loss |
| FLOPs | floating point operations |
| FPN | feature pyramid network |
| GAP | global average pooling |
| GMP | global max pooling |
| HR-SDNet | high-resolution ship detection network |
| HNM | hard negative mining |
| HPBC | histogram-based pure backgrounds classification |
| H-SPP | hybrid spatial pyramid pooling |
| L-Conv | lightweight convolution |
| L-CSP | lightweight cross stage partial |
| LFO-Net | lightweight feature optimization network |
| L-Relu | Leaky_ReLu |
| LS-SSDD-v1.0 | Large-Scale SAR Ship Detection Dataset-v1.0 |
| MLP | multi-layer perceptron |
| NLP | natural language processing |
| PAN | path aggregation network |
| RDN | refined detection network |
| RPN | region proposal network |
| SAR | synthetic aperture radar |
| SDC | shape distance clustering |
| SGD | stochastic gradient descent |
| SPP | spatial pyramid pooling |
| YOLOv5 | You Only Look Once version 5 |
References
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and Excitation Rank Faster R-CNN for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 751–755. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, X.; Zhang, T. Multi-Scale SAR Ship Classification with Convolutional Neural Network. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Online Event, 11–16 July 2021; pp. 4284–4287. [Google Scholar]
- Zhang, T.; Zhang, X.; Ke, X. Quad-FPN: A Novel Quad Feature Pyramid Network for SAR Ship Detection. Remote Sens. 2021, 13, 2771. [Google Scholar] [CrossRef]
- O’Shea, T.; Hoydis, J. An Introduction to Deep Learning for the Physical Layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef] [Green Version]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. Mobile Encrypted Traffic Classification Using Deep Learning: Experimental Evaluation, Lessons Learned, and Challenges. IEEE Trans. Netw. Serv. Manag. 2019, 16, 445–458. [Google Scholar] [CrossRef]
- Liu, G.; Li, L.; Jiao, L.; Dong, Y.; Li, X. Stacked Fisher autoencoder for SAR change detection. Pattern Recognit. 2019, 96, 106971. [Google Scholar] [CrossRef]
- Ciuonzo, D.; Carotenuto, V.; De Maio, A. On Multiple Covariance Equality Testing with Application to SAR Change Detection. IEEE Trans. Signal Process. 2017, 65, 5078–5091. [Google Scholar] [CrossRef]
- Kang, M.; Ji, K.; Leng, X.; Lin, Z. Contextual Region-Based Convolutional Neural Network with Multilayer Fusion for SAR Ship Detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef] [Green Version]
- Jiao, J.; Zhang, Y.; Sun, H.; Yang, X.; Gao, X.; Hong, W.; Fu, K.; Sun, X. A Densely Connected End-to-End Neural Network for Multiscale and Multiscene SAR Ship Detection. IEEE Access. 2018, 6, 20881–20892. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense Attention Pyramid Networks for Multi-Scale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Liu, N.; Cao, Z.; Cui, Z.; Pi, Y.; Dang, S. Multi-Scale Proposal Generation for Ship Detection in SAR Images. Remote Sens. 2019, 11, 526. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Lu, C.; Jiang, W. Simultaneous Ship Detection and Orientation Estimation in SAR Images Based on Attention Module and Angle Regression. Sensors 2018, 18, 2851. [Google Scholar] [CrossRef] [Green Version]
- An, Q.; Pan, Z.; Liu, L.; You, H. DRBox-v2: An Improved Detector With Rotatable Boxes for Target Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8333–8349. [Google Scholar] [CrossRef]
- Chen, C.; Hu, C.; He, C.; Pei, H.; Pang, Z.; Zhao, T. SAR Ship Detection Under Complex Background Based on Attention Mechanism. In Image and Graphics Technologies and Applications; Springer: Singapore, 2019; pp. 565–578. [Google Scholar]
- Dai, W.; Mao, Y.; Yuan, R.; Liu, Y.; Pu, X.; Li, C. A Novel Detector Based on Convolution Neural Networks for Multiscale SAR Ship Detection in Complex Background. Sensors 2020, 20, 2547. [Google Scholar] [CrossRef] [PubMed]
- Wei, S.; Su, H.; Ming, J.; Wang, C.; Yan, M.; Kumar, D.; Shi, J.; Zhang, X. Precise and Robust Ship Detection for High-Resolution SAR Imagery Based on HR-SDNet. Remote Sens. 2020, 12, 167. [Google Scholar] [CrossRef] [Green Version]
- Chang, Y.-L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.-Y.; Lee, W.-H. Ship Detection Based on YOLOv2 for SAR Imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. Depthwise Separable Convolution Neural Network for High-Speed SAR Ship Detection. Remote Sens. 2019, 11, 2483. [Google Scholar] [CrossRef] [Green Version]
- Mao, Y.; Yang, Y.; Ma, Z.; Li, M.; Su, H.; Zhang, J. Efficient Low-Cost Ship Detection for SAR Imagery Based on Simplified U-Net. IEEE Access. 2020, 8, 69742–69753. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, H.; Xu, C.; Lv, Y.; Fu, C.; Xiao, H.; He, Y. A Lightweight Feature Optimizing Network for Ship Detection in SAR Image. IEEE Access. 2019, 7, 141662–141678. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. Automatic Ship Detection Based on RetinaNet Using Multi-Resolution Gaofen-3 Imagery. Remote Sens. 2019, 11, 531. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A SAR Dataset of Ship Detection for Deep Learning under Complex Backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Zhang, X.; Ke, X.; Zhan, X.; Shi, J.; Wei, S.; Pan, D.; Li, J.; Su, H.; Zhou, Y.; et al. LS-SSDD-v1.0: A Deep Learning Dataset Dedicated to Small Ship Detection from Large-Scale Sentinel-1 SAR Images. Remote Sens. 2020, 12, 2997. [Google Scholar] [CrossRef]
- Xu, P.; Li, Q.; Zhang, B.; Wu, F.; Zhao, K.; Du, X.; Yang, C.; Zhong, R. On-Board Real-Time Ship Detection in HISEA-1 SAR Images Based on CFAR and Lightweight Deep Learning. Remote Sens. 2021, 13, 1995. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.H.; Tian, Q.; Guo, J.Y.; Xu, C.J.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1577–1586. [Google Scholar]
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 November 2021).
- Liu, Z.; Li, J.G.; Shen, Z.Q.; Huang, G.; Yan, S.M.; Zhang, C.S. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2755–2763. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 346–361. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A Forest Fire Detection System Based on Ensemble Learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Loffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML), Lile, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Mastromichalakis, S. ALReLU: A different approach on Leaky ReLU activation function to improve Neural Networks Performance. arXiv 2020, arXiv:2012.07564. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Scardapane, S.; Comminiello, D.; Hussain, A.; Uncini, A. Group sparse regularization for deep neural networks. Neurocomputing 2017, 241, 81–89. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Zhan, R.; Wang, W.; Zhang, J. Learning Slimming SAR Ship Object Detector Through Network Pruning and Knowledge Distillation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1267–1282. [Google Scholar] [CrossRef]
- Gao, G. Statistical Modeling of SAR Images: A Survey. Sensors 2010, 10, 775–795. [Google Scholar] [CrossRef]
- Wackerman, C.C.; Friedman, K.S.; Pichel, W.; Clemente-Colón, P.; Li, X. Automatic detection of ships in RADARSAT-1 SAR imagery. Can. J. Remote Sens. 2001, 27, 568–577. [Google Scholar] [CrossRef]
- Ferrara, M.N.; Torre, A. Automatic moving targets detection using a rule-based system: Comparison between different study cases. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Seattle, WA, USA, 6–10 July 1998; pp. 1593–1595. [Google Scholar]
- Gagnon, L.; Oppenheim, H.; Valin, P. R&D activities in airborne SAR image processing/analysis at Lockheed Martin Canada. Proc. SPIE Int. Soc. Opt. Eng. 1998, 3491, 998–1003. [Google Scholar]
- Chen, P.; Li, Y.; Zhou, H.; Liu, B.; Liu, P. Detection of Small Ship Objects Using Anchor Boxes Cluster and Feature Pyramid Network Model for SAR Imagery. J. Mar. Sci. Eng. 2020, 8, 112. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.W.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.C.; Wang, J.L. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef] [Green Version]
- Ketkar, N. Introduction to Pytorch. In Deep Learning with Python: A Hands-On Introduction; Apress: Berkeley, CA, USA, 2017; pp. 195–208. Available online: https://link.springer.com/chapter/10.1007/978-1-4842-2766-4_12 (accessed on 1 December 2021).
- Gao, S.; Liu, J.M.; Miao, Y.H.; He, Z.J. A High-Effective Implementation of Ship Detector for SAR Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, F.; Zhou, Y.; Zhang, F.; Yin, Q.; Ma, F. Small Vessel Detection Based on Adaptive Dual-Polarimetric Sar Feature Fusion and Attention-Enhanced Feature Pyramid Network. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Online Event, 11–16 July 2021; pp. 2218–2221. [Google Scholar]
- Zhang, L.; Liu, Y.; Guo, Q.; Yin, H.; Li, Y.; Du, P. Ship Detection in Large-scale SAR Images Based on Dense Spatial Attention and Multi-level Feature Fusion. In Proceedings of the ACM Turing Award Celebration Conference—China (ACM TURC 2021), Hefei, China, 30 July–1 August 2021; Association for Computing Machinery: Hefei, China, 2021; pp. 77–81. [Google Scholar]
- Zhang, X.; Huo, C.; Xu, N.; Jiang, H.; Cao, Y.; Ni, L.; Pan, C. Multitask Learning for Ship Detection From Synthetic Aperture Radar Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8048–8062. [Google Scholar] [CrossRef]
- Sergios, T. Stochastic gradient descent. Mach. Learn. 2015, 5, 161–231. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. arXiv 2019, arXiv:1904.02701. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. arXiv 2019, arXiv:1911.09070. [Google Scholar]
- Zhang, X.; Wan, F.; Liu, C.; Ye, Q. FreeAnchor: Learning to match anchors for visual object detection. arXiv 2019, arXiv:1909.02466. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. FoveaBox: Beyond anchor-based object detector. arXiv 2019, arXiv:1904.03797. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]

 means the lightweight network design part.
means the lightweight network design part.  means the detection accuracy compensation part. For obtaining a lightweight network, L-CSP and network pruning are inserted. For better feature extraction, HPBC, SDC, CSA, and H-SPP are embedded. L-CSP denotes the lightweight cross stage partial. Network pruning denotes the network pruning procedure. HPBC denotes the histogram-based pure backgrounds classification. SDC denotes the shape distance clustering. CSA denotes the channel and spatial attention. H-SPP denotes the hybrid spatial pyramid pooling.
means the lightweight network design part. means the detection accuracy compensation part. For obtaining a lightweight network, L-CSP and network pruning are inserted. For better feature extraction, HPBC, SDC, CSA, and H-SPP are embedded. L-CSP denotes the lightweight cross stage partial. Network pruning denotes the network pruning procedure. HPBC denotes the histogram-based pure backgrounds classification. SDC denotes the shape distance clustering. CSA denotes the channel and spatial attention. H-SPP denotes the hybrid spatial pyramid pooling.
means the detection accuracy compensation part. For obtaining a lightweight network, L-CSP and network pruning are inserted. For better feature extraction, HPBC, SDC, CSA, and H-SPP are embedded. L-CSP denotes the lightweight cross stage partial. Network pruning denotes the network pruning procedure. HPBC denotes the histogram-based pure backgrounds classification. SDC denotes the shape distance clustering. CSA denotes the channel and spatial attention. H-SPP denotes the hybrid spatial pyramid pooling.
means the lightweight network design part. means the detection accuracy compensation part. For obtaining a lightweight network, L-CSP and network pruning are inserted. For better feature extraction, HPBC, SDC, CSA, and H-SPP are embedded. L-CSP denotes the lightweight cross stage partial. Network pruning denotes the network pruning procedure. HPBC denotes the histogram-based pure backgrounds classification. SDC denotes the shape distance clustering. CSA denotes the channel and spatial attention. H-SPP denotes the hybrid spatial pyramid pooling.












| Category | Related Works | Main Distinctive Characteristics |
|---|---|---|
| DL-based SAR ship detectors | [9,10,11,12,13,14,15,16,17] | Fairish detection performance ✓ Competitive detection speed ✘ Designed for on-board platform ✘ |
| DL-based lightweight SAR ship detectors | [18,19,20,21,22,23,24] | Fairish detection performance ✓ Competitive detection speed ✓ designed for on-board platform ✘ |
| Method | Receptive Field | Prior Boxes (Width, Height) |
|---|---|---|
| K-means | Big Medium Small | (5, 5), (7, 8), (11, 12) (15, 15), (17, 22), (26, 19) (23, 30), (35, 31), (49, 49) |
| SDC Module | Big Medium Small | (5, 5), (7, 8), (9, 11) (13, 14), (14, 19), (22, 19) (21, 31), (32, 22), (36, 38) |
| Key | Value |
|---|---|
| Sensors | Tokyo, Adriatic Sea, etc. |
| Polarization | VV, VH |
| Sensor mode | IW |
| Scene | land, sea |
| Resolution (m) | 5 × 20 |
| Number of images | 15 |
| Image size | 24,000 × 16,000 |
| Cover width (km) | ~250 |
| Method | P (%) | R (%) | AP (%) | F1 (%) | T (s) | FLOPs (G) | Model Volume (M) |
|---|---|---|---|---|---|---|---|
| YOLOv5 | 77.04 | 67.60 | 72.03 | 72.01 | 51.18 | 16.70 | 13.70 |
| Lite-YOLOv5(ours) | 83.01 | 65.97 | 73.15 | 73.52 | 37.51 | 4.44 | 2.38 |
| Method | AP (%) | F1 (%) | T (s) | FLOPs (G) | Parameter Size (M) | Model Volume (M) |
|---|---|---|---|---|---|---|
| Libra R-CNN [56] | 62.90 | 75.93 | 62.28 | 162.18 | 41.62 | 532 |
| Faster R-CNN [57] | 63.00 | 69.48 | 124.45 | 134.38 | 33.04 | 320 |
| EfficientDet [58] | 61.35 | 64.70 | 131.33 | 107.52 | 39.40 | 302 |
| Free anchor [59] | 71.04 | 64.60 | 52.32 | 127.82 | 36.33 | 277 |
| FoveaBox [60] | 52.30 | 68.26 | 52.32 | 126.59 | 36.24 | 277 |
| RetinaNet [61] | 54.31 | 70.53 | 52.06 | 127.82 | 36.33 | 277 |
| SSD-512 [62] | 40.60 | 57.65 | 23.09 | 87.72 | 24.39 | 186 |
| YOLOv5 [27] | 72.03 | 72.01 | 1.92 | 16.70 | 7.06 | 14 |
| Lite-YOLOv5 (ours) | 73.15 | 73.52 | 1.41 | 4.44 | 1.04 | 2 |
| L-CSP | P (%) | R (%) | AP (%) | F1 (%) | FLOPs (G) | Model Volume (M) |
|---|---|---|---|---|---|---|
| ✘ | 82.23 | 67.16 | 73.17 | 73.93 | 8.16 | 2.56 |
| ✓ | 83.01 | 65.97 | 73.15 | 73.52 | 4.44 | 2.38 |
| Network Pruning | P (%) | R (%) | AP (%) | F1 (%) | FLOPs (G) | Model Volume (M) |
|---|---|---|---|---|---|---|
| ✘ | 80.93 | 67.75 | 73.84 | 73.76 | 14.16 | 12.90 |
| ✓ | 83.01 | 65.97 | 73.15 | 73.52 | 4.44 | 2.38 |
| HPBC | P (%) | R (%) | AP (%) | F1 (%) | T (s) |
|---|---|---|---|---|---|
| ✘ | 82.45 | 65.97 | 72.96 | 73.30 | 47.88 |
| ✓ | 83.01 | 65.97 | 73.15 | 73.52 | 37.51 |
| εa | #Images | #Ships | P (%) | R (%) | AP (%) | F1 (%) |
|---|---|---|---|---|---|---|
| 0 | 3000 | 2378 | 82.45 | 65.97 | 72.96 | 73.30 |
| 96 | 2566 | 2378 | 82.49 | 65.97 | 73.00 | 73.31 |
| 112 | 2450 | 2378 | 82.62 | 65.97 | 73.07 | 73.36 |
| 128 | 2350 | 2378 | 83.01 | 65.97 | 73.15 | 73.52 |
| 144 | 2271 | 2372 | 82.02 | 66.94 | 73.28 | 73.72 |
| SDC | P (%) | R (%) | AP (%) | F1 (%) | FLOPs (G) | Model Volume (M) |
|---|---|---|---|---|---|---|
| ✘ | 82.37 | 64.89 | 72.53 | 72.59 | 4.33 | 2.33 |
| ✓ | 83.01 | 65.97 | 73.15 | 73.52 | 4.44 | 2.38 |
| CSA | P (%) | R (%) | AP (%) | F1 (%) | FLOPs (G) | Model Volume (M) |
|---|---|---|---|---|---|---|
| ✘ | 80.38 | 64.59 | 70.56 | 71.63 | 4.05 | 2.31 |
| ✓ | 83.01 | 65.97 | 73.15 | 73.52 | 4.44 | 2.38 |
| H-SPP | P (%) | R (%) | AP (%) | F1 (%) | FLOPs (G) | Model Volume (M) |
|---|---|---|---|---|---|---|
| ✘ | 82.34 | 65.14 | 72.61 | 72.74 | 5.19 | 2.35 |
| ✓ | 83.01 | 65.97 | 73.15 | 73.52 | 4.44 | 2.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Zhang, X.; Zhang, T. Lite-YOLOv5: A Lightweight Deep Learning Detector for On-Board Ship Detection in Large-Scene Sentinel-1 SAR Images. Remote Sens. 2022, 14, 1018. https://doi.org/10.3390/rs14041018
Xu X, Zhang X, Zhang T. Lite-YOLOv5: A Lightweight Deep Learning Detector for On-Board Ship Detection in Large-Scene Sentinel-1 SAR Images. Remote Sensing. 2022; 14(4):1018. https://doi.org/10.3390/rs14041018
Chicago/Turabian StyleXu, Xiaowo, Xiaoling Zhang, and Tianwen Zhang. 2022. "Lite-YOLOv5: A Lightweight Deep Learning Detector for On-Board Ship Detection in Large-Scene Sentinel-1 SAR Images" Remote Sensing 14, no. 4: 1018. https://doi.org/10.3390/rs14041018
APA StyleXu, X., Zhang, X., & Zhang, T. (2022). Lite-YOLOv5: A Lightweight Deep Learning Detector for On-Board Ship Detection in Large-Scene Sentinel-1 SAR Images. Remote Sensing, 14(4), 1018. https://doi.org/10.3390/rs14041018