
Capsule–Encoder–Decoder: A Method for Generalizable Building Extraction from Remote Sensing Images

 ,
,  , , and
, , and
Abstract
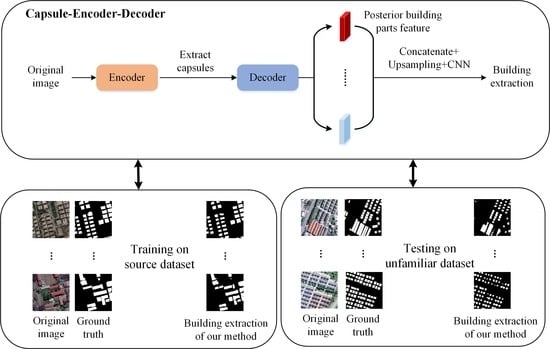
:
1. Introduction
1.1. CNN-Based Method for Building Extraction
1.2. Capsule Networks for Building Extraction
1.3. Research Objectives
- We propose a novel building extraction method: Capsule–Encoder–Decoder. The encoder extracts capsules from remote sensing images. Capsules contain the information of buildings’ parts. Additionally, the decoder calculates the relationship between the target building and its parts. The decoder corrects the buildings’ distribution and up-samples them to extract target buildings.
- Compared with the mainstream deep learning methods on the source dataset, our method will achieve convergence faster and show higher accuracy.
- Capsules in our method have high-level semantic information, which are more explanatory.
- Without fine tuning, our method will reduce the error rates of building extraction results on an almost unfamiliar dataset.
2. Materials and Methods
2.1. An Overview of Capsule–Encoder–Decoder
2.2. Architecture of Our Encoder
- Posture information , which stores posture information such as rotation, translation, scaling, and shearing.
- Texture details , which reflects the color and texture properties of the building parts.
- Attention distribution , which reflects the possible position distribution of the building parts in the original image.
2.3. Architecture of Our Decoder
2.4. Loss Function
- The cross entropy between the semantic segmentation results and ground truth.
- The cross entropy between the posterior part distribution accumulation results and the ground truth.
2.5. Data
- Extract the ground truth from the labeled information, which is a binary gray image.
- Cut the high-resolution remote sensing image from size of 3000 × 3000 to the slices with size of 256 × 256.
- Randomly flip and shift the slice images.
- Standardize images along RGB channels.
3. Results
3.1. Experimental Setup
3.1.1. Evaluation Metrics
3.1.2. Experimental Details
3.2. Ablation Study
3.3. Compared with CNN-Based Methods and Capsule-Based Methods
3.4. Explainability
3.5. Generalization
3.6. Further Experimental Support
4. Discussion
4.1. Discussion of Explainability
4.2. Discussion of Generalization
4.3. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building extraction based on U-Net with an attention block and multiple losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Chen, K.; Fu, K.; Gao, X.; Yan, M.; Sun, X.; Zhang, H. Building extraction from remote sensing images with deep learning in a supervised manner. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 1672–1675. [Google Scholar]
- Chen, M.; Wu, J.; Liu, L.; Zhao, W.; Tian, F.; Shen, Q.; Zhao, B.; Du, R. DR-Net: An improved network for building extraction from high resolution remote sensing image. Remote Sens. 2021, 13, 294. [Google Scholar] [CrossRef]
- Zhang, H.; Liao, Y.; Yang, H.; Yang, G.; Zhang, L. A Local-Global Dual-Stream Network for Building Extraction From Very-High-Resolution Remote Sensing Images. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 1269–1283. [Google Scholar] [CrossRef] [PubMed]
- Deng, W.; Shi, Q.; Li, J. Attention-Gate-Based Encoder–Decoder Network for Automatical Building Extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2611–2620. [Google Scholar] [CrossRef]
- Zhu, Y.; Liang, Z.; Yan, J.; Chen, G.; Wang, X. ED-Net: Automatic Building Extraction From High-Resolution Aerial Images With Boundary Information. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4595–4606. [Google Scholar] [CrossRef]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A fully convolutional neural network for automatic building extraction from high-resolution remote sensing images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef] [Green Version]
- Zou, Z.; Shi, T.; Li, W.; Zhang, Z.; Shi, Z. Do game data generalize well for remote sensing image segmentation? Remote Sens. 2020, 12, 275. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R. Making convolutional networks shift-invariant again. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 7324–7334. [Google Scholar]
- Yuan, J. Learning building extraction in aerial scenes with convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2793–2798. [Google Scholar] [CrossRef]
- Lunga, D.; Arndt, J.; Gerrand, J.; Stewart, R. ReSFlow: A Remote Sensing Imagery Data-Flow for Improved Model Generalization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10468–10483. [Google Scholar] [CrossRef]
- Sheng, H.; Chen, X.; Su, J.; Rajagopal, R.; Ng, A. Effective data fusion with generalized vegetation index: Evidence from land cover segmentation in agriculture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 60–61. [Google Scholar]
- Yang, B.; Cao, F.; Ye, H. A Novel Method for Hyperspectral Image Classification: Deep Network with Adaptive Graph Structure Integration. IEEE Trans. Geosci. Remote Sens. 2022. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Fu, X.; Qu, H. Research on semantic segmentation of high-resolution remote sensing image based on full convolutional neural network. In Proceedings of the 2018 12th International Symposium on Antennas, Propagation and EM Theory (ISAPE), Hangzhou, China, 3–6 December 2018; pp. 1–4. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zheng, X.; Chen, T. Segmentation of High Spatial Resolution Remote Sensing Image based On U-Net Convolutional Networks. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2571–2574. [Google Scholar]
- Ye, Z.; Fu, Y.; Gan, M.; Deng, J.; Comber, A.; Wang, K. Building extraction from very high resolution aerial imagery using joint attention deep neural network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zuo, Z.; Zhang, W.; Zhang, D. A remote sensing image semantic segmentation method by combining deformable convolution with conditional random fields. Acta Geod. Cartogr. Sin 2019, 48, 718–726. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yu, B.; Yang, L.; Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Lin, Y.; Xu, D.; Wang, N.; Shi, Z.; Chen, Q. Road extraction from very-high-resolution remote sensing images via a nested SE-Deeplab model. Remote Sens. 2020, 12, 2985. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. arXiv 2017, arXiv:1710.09829. [Google Scholar]
- Hinton, G.E.; Sabour, S.; Frosst, N. Matrix capsules with EM routing. In International Conference on Learning Representations; 2018; Available online: https://openreview.net/forum?id=HJWLfGWRb¬eId=rk5MadsMf¬eId=rk5MadsMf (accessed on 15 January 2022).
- Kosiorek, A.R.; Sabour, S.; Teh, Y.W.; Hinton, G.E. Stacked capsule autoencoders. arXiv 2019, arXiv:1906.06818. [Google Scholar]
- Lee, J.; Lee, Y.; Kim, J.; Kosiorek, A.; Choi, S.; Teh, Y.W. Set transformer: A framework for attention-based permutation-invariant neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Nagoya, Japan, 17–19 November 2019; pp. 3744–3753. [Google Scholar]
- Yu, Y.; Ren, Y.; Guan, H.; Li, D.; Yu, C.; Jin, S.; Wang, L. Capsule feature pyramid network for building footprint extraction from high-resolution aerial imagery. IEEE Geosci. Remote Sens. Lett. 2020, 18, 895–899. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, C.; Gao, J.; Jin, S.; Jiang, X.; Jiang, M.; Zhang, H.; Zhang, Y. Building Extraction From Remote Sensing Imagery With a High-Resolution Capsule Network. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Chen, C.; Li, O.; Tao, C.; Barnett, A.J.; Su, J.; Rudin, C. This looks like that: Deep learning for interpretable image recognition. arXiv 2018, arXiv:1806.10574. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto (Canada), Toronto, ON, Canada, 2013. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lee, S.; Kim, J. Land cover classification using sematic image segmentation with deep learning. Korean J. Remote Sens. 2019, 35, 279–288. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Z.; Shen, C.; Hengel, A.v.d. Bridging category-level and instance-level semantic image segmentation. arXiv 2016, arXiv:1605.06885. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Building Parts | Posterior | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| IoU(%) | ✓ | 61.1 | 62.1 | 64.5 | 65.2 | 65.3 |
| PA(%) | ✓ | 79.2 | 82.6 | 83.4 | 84.2 | 84.7 |
| IoU(%) | ✕ | 54.3 | 55.8 | 57.6 | 56.2 | 56.9 |
| PA(%) | ✕ | 69.4 | 72.0 | 76.9 | 74.9 | 75.1 |
| Iterations | ✓ | 2995 | 2708 | 2317 | 2106 | 2212 |
| Loss Weights | 3:7 | 5:5 | 7:3 | 8:2 | 9:1 | 10:0 |
|---|---|---|---|---|---|---|
| IoU(%) | 40.4 | 55.1 | 62.8 | 65.2 | 63.1 | 60.4 |
| PA(%) | 59.6 | 72.3 | 82.1 | 84.2 | 82.7 | 79.8 |
| Method | Capsule-Based | IoU(%) | PA(%) | Iterations |
|---|---|---|---|---|
| CapFPN [35] | ✓ | 65.0 | 84.1 | 3015 |
| HR-CapsNet [36] | ✓ | 65.1 | 84.1 | 2914 |
| FCN-8s [18] | ✕ | 46.9 | 76.8 | 4369 |
| SegNet [21] | ✕ | 61.6 | 81.7 | 3647 |
| SegNet+DeConv [26] | ✕ | 63.4 | 82.1 | 5219 |
| UNet [20] | ✕ | 64.7 | 83.6 | 3985 |
| RFA-UNet [23] | ✕ | 64.9 | 83.5 | 4011 |
| PSPNet [27] | ✕ | 64.9 | 84.1 | 4285 |
| Deeplab-v3 [29] | ✕ | 65.1 | 84.2 | 6013 |
| Ours (parts = 5) | ✓ | 65.2 | 84.2 | 2106 |
| Ours (parts = 6) | ✓ | 65.3 | 84.7 | 2212 |
| Method | IoU’ (%) | PA’ (%) | IoU (%) | PA (%) |
|---|---|---|---|---|
| CapFPN | 31.3 | 50.6 | 33.7 | 33.4 |
| HR-CapsNet | 33.9 | 54.2 | 31.2 | 29.9 |
| FCN-8s | 13.2 | 34.1 | 33.7 | 42.7 |
| SegNet | 29.5 | 48.8 | 32.1 | 32.9 |
| SegNet+DeConv | 47.7 | 67.3 | 16.3 | 14.8 |
| UNet | 26.9 | 44.2 | 37.8 | 39.4 |
| RFA-UNet | 47.2 | 67.4 | 17.8 | 16.1 |
| PSPNet | 35.5 | 54.2 | 29.4 | 29.9 |
| Deeplab-v3 | 46.9 | 65.8 | 19.2 | 18.4 |
| Ours (parts = 5) | 50.7 | 70.4 | 14.5 | 13.8 |
| Ours (parts = 6) | 50.9 | 70.8 | 14.4 | 13.9 |
| Method | IoU’ (%) | PA’ (%) | IoU (%) | PA (%) |
|---|---|---|---|---|
| CapFPN | 26.4 | 44.7 | 38.6 | 39.3 |
| HR-CapsNet | 22.5 | 41.3 | 42.1 | 42.8 |
| SegNet+DeConv | 38.1 | 57.8 | 25.3 | 24.3 |
| RFA-UNet | 24.6 | 43.9 | 40.1 | 39.6 |
| Deeplab-v3 | 31.9 | 50.4 | 33.2 | 33.8 |
| Ours | 51.9 | 70.9 | 13.5 | 13.7 |
| Method | IoU (%) | PA (%) | IoU’ (%) | PA’ (%) | IoU (%) | PA (%) |
|---|---|---|---|---|---|---|
| CapFPN | 67.8 | 85.9 | 36.9 | 55.7 | 30.9 | 30.2 |
| HR-CapsNet | 68.4 | 86.6 | 37.3 | 53.2 | 31.1 | 33.4 |
| SegNet+ DeConv | 63.6 | 81.4 | 40.6 | 54.9 | 23.0 | 26.5 |
| Ours | 68.1 | 86.2 | 59.2 | 76.1 | 8.9 | 10.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Z.; Chen, C.Y.-C.; Jiang, C.; Zhang, D.; Luo, W.; Hong, Z.; Sun, H. Capsule–Encoder–Decoder: A Method for Generalizable Building Extraction from Remote Sensing Images. Remote Sens. 2022, 14, 1235. https://doi.org/10.3390/rs14051235
Tang Z, Chen CY-C, Jiang C, Zhang D, Luo W, Hong Z, Sun H. Capsule–Encoder–Decoder: A Method for Generalizable Building Extraction from Remote Sensing Images. Remote Sensing. 2022; 14(5):1235. https://doi.org/10.3390/rs14051235
Chicago/Turabian StyleTang, Zhenchao, Calvin Yu-Chian Chen, Chengzhen Jiang, Dongying Zhang, Weiran Luo, Zhiming Hong, and Huaiwei Sun. 2022. "Capsule–Encoder–Decoder: A Method for Generalizable Building Extraction from Remote Sensing Images" Remote Sensing 14, no. 5: 1235. https://doi.org/10.3390/rs14051235
APA StyleTang, Z., Chen, C. Y. -C., Jiang, C., Zhang, D., Luo, W., Hong, Z., & Sun, H. (2022). Capsule–Encoder–Decoder: A Method for Generalizable Building Extraction from Remote Sensing Images. Remote Sensing, 14(5), 1235. https://doi.org/10.3390/rs14051235