
NDSRGAN: A Novel Dense Generative Adversarial Network for Real Aerial Imagery Super-Resolution Reconstruction


Abstract
:1. Introduction
- We produce a new image dataset with paired high- and low-resolution real aerial remote sensing images, which are both obtained by actual photography.
- We propose a novel dense generative adversarial network for real aerial imagery super-resolution reconstruction (NDSRGAN). In the generative network, we use a multilevel dense network to connect the dense connections in a residual dense block. In the discriminative network, we use a matrix mean discriminator that can discriminate the generated images locally. We also use loss to accelerate the model convergence and reach the global optimum faster.
2. Related Work
2.1. Interpolation-Based Methods
2.2. Reconstruction-Based Methods
2.3. Learning-Based Methods
2.3.1. CNN-Based SR Reconstruction Methods
2.3.2. GAN-Based SR Reconstruction Methods
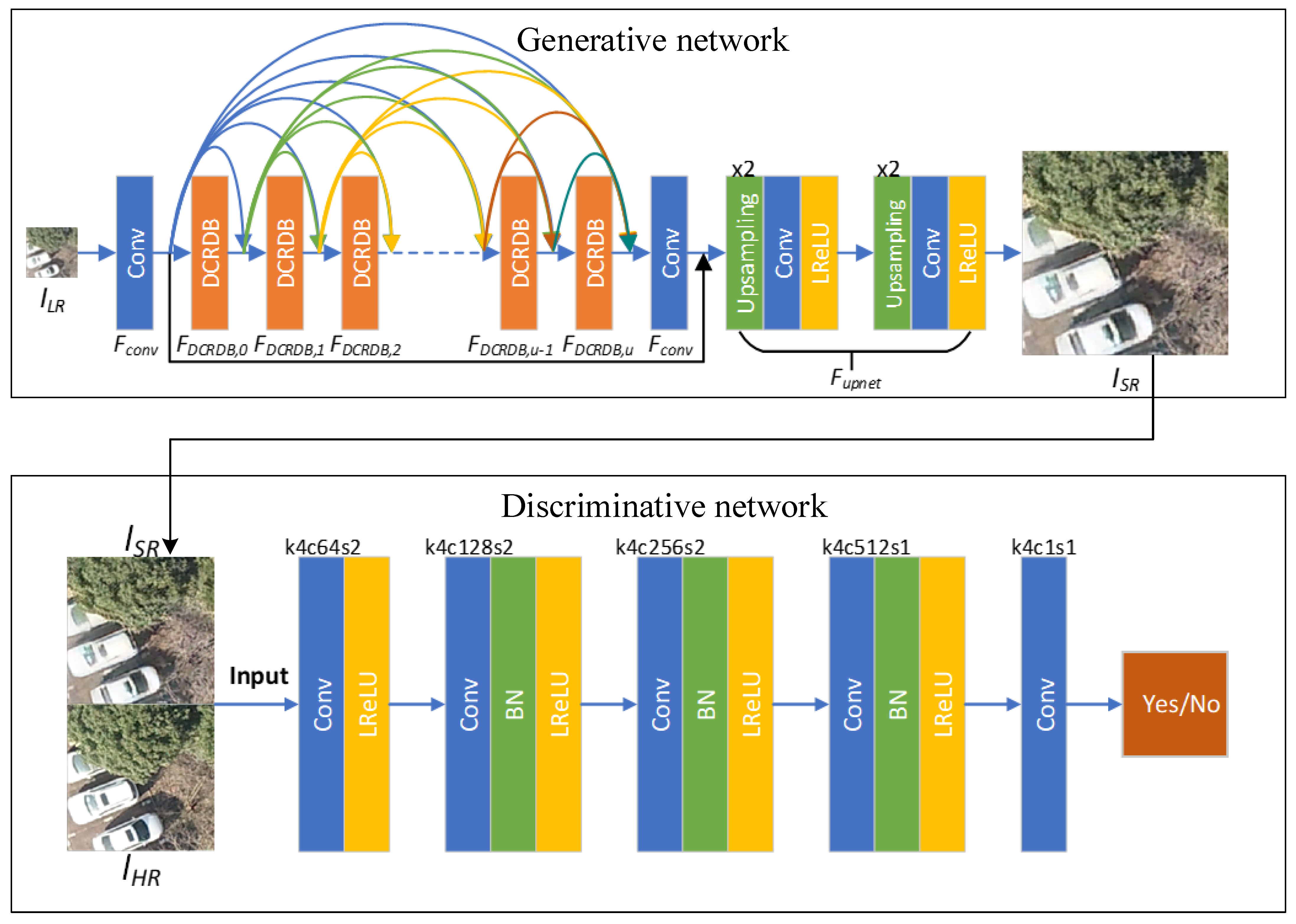
3. Method
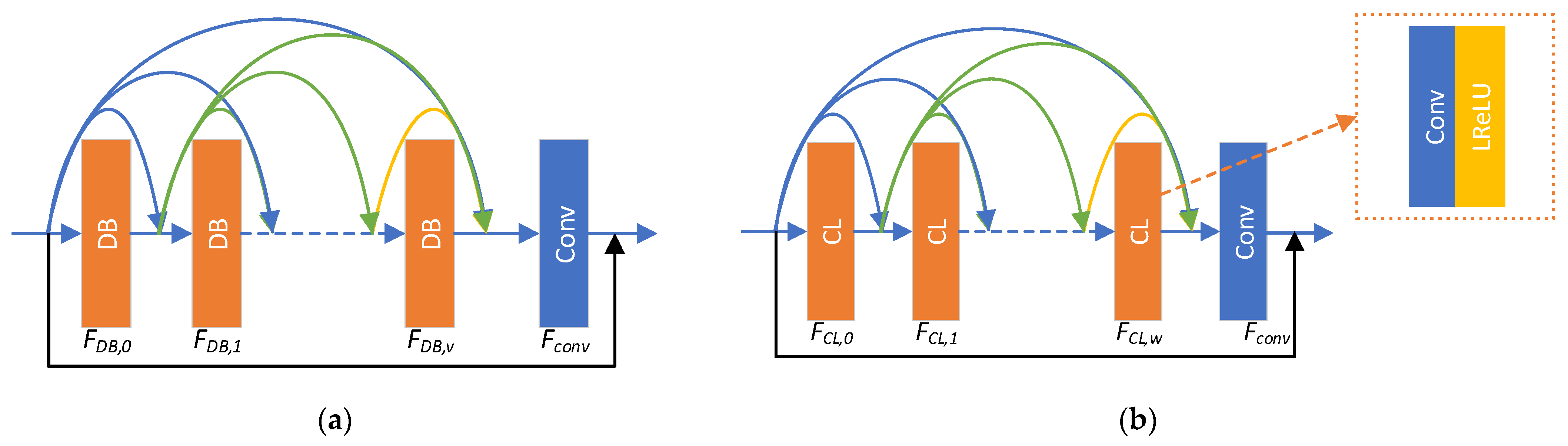
3.1. Generative Network
3.2. Discriminative Network
3.3. Loss Function Design
4. Experiments and Results
4.1. RHLAI Dataset
4.2. Training Details
4.3. Cross-Validation
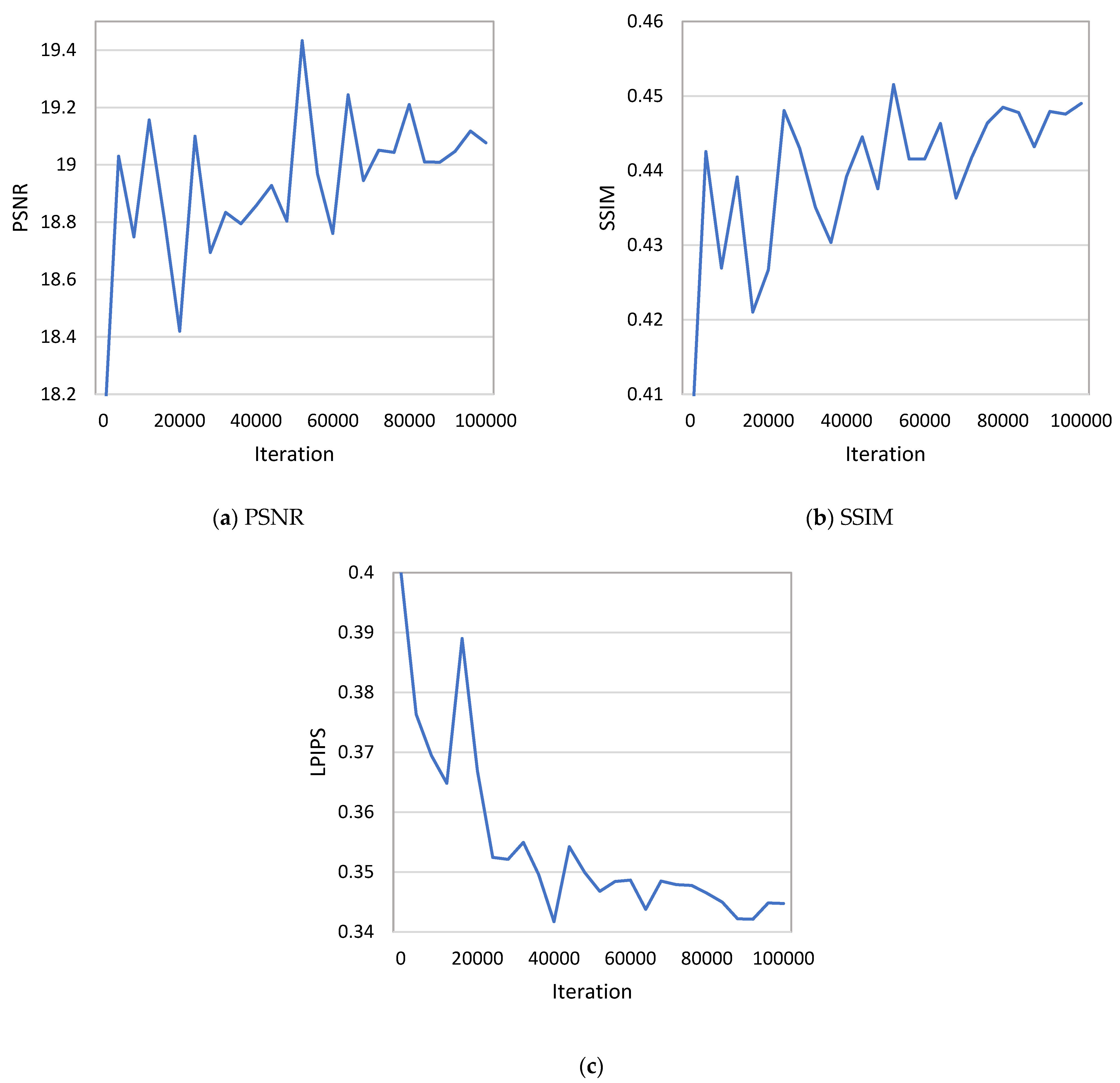
4.4. Image Quality Metrics Analysis during NDSRGAN Training
4.5. Reconstruction Results Analysis of RHLAI Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Ablation Study

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | |
|---|---|
| Base | |
| Base + MDC | |
| Base + MDC+ MMD | |
| Base + MDC + MMD + |

Appendix A.2. Residual Scaling Factor

Appendix A.3. Discriminative Matrix Size

Appendix A.4. Random Crop Size of Training Input Images
| . | |

References
- Walter, V. Automated GIS data collection and update. In Proceedings of the Photogrammetric Week′ 99, Heidelberg, Germany, 22–26 September 1999; pp. 267–280. [Google Scholar]
- Lee, K.; Ryu, H.Y. Automatic circuity and accessibility extraction by road graph network and its application with high-resolution satellite imagery. In Proceedings of the 2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; Volume 5, pp. 3144–3146. [Google Scholar]
- Lim, S.B.; Seo, C.W.; Yun, H.C. Digital map updates with UAV photogrammetric methods. J. Korean Soc. Surv. Geod. Photogramm. Cartogr. 2015, 33, 397–405. [Google Scholar] [CrossRef]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building Extraction Based on U-Net with an Attention Block and Multiple Losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Sun, H.; Sun, X.; Wang, H.; Li, Y.; Li, X. Automatic target detection in high-resolution remote sensing images using spatial sparse coding bag-of-words model. IEEE Geosci. Remote Sens. Lett. 2011, 9, 109–113. [Google Scholar] [CrossRef]
- Wu, F.; Duan, J.; Chen, S.; Ye, Y.; Ai, P.; Yang, Z. Multi-target recognition of bananas and automatic positioning for the inflorescence axis cutting point. Front. Plant Sci. 2021, 12, 705021. [Google Scholar] [CrossRef]
- Tang, Y.; Zhu, M.; Chen, Z.; Wu, C.; Chen, B.; Li, C.; Li, L. Seismic performance evaluation of recycled aggregate concrete-filled steel tubular columns with field strain detected via a novel mark-free vision method. Structures 2022, 37, 426–441. [Google Scholar] [CrossRef]
- Wang, Z.; Jiang, K.; Yi, P.; Han, Z.; He, Z. Ultra-dense GAN for satellite imagery super-resolution. Neurocomputing 2020, 398, 328–337. [Google Scholar] [CrossRef]
- Forsyth, D.; Ponce, J.; Mukherjee, S.; Bhattacharjee, A.K. Computer Vision: A Modern Approach; Prentice Hall: Upper Saddle River, NJ, USA, 2011. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Koester, E.; Sahin, C.S. A comparison of super-resolution and nearest neighbors interpolation applied to object detection on satellite data. arXiv 2019, arXiv:1907.05283. [Google Scholar]
- Zhang, X. A new kind of super-resolution reconstruction algorithm based on the ICM and the bilinear interpolation. In Proceedings of the 2008 International Seminar on Future BioMedical Information Engineering, Wuhan, China, 18 December 2008; pp. 183–186. [Google Scholar]
- Zhang, X. A new kind of super-resolution reconstruction algorithm based on the ICM and the bicubic interpolation. In Proceedings of the 2008 International Symposium on Intelligent Information Technology Application Workshops, Shanghai, China, 21–22 December 2008; pp. 817–820. [Google Scholar]
- Gilman, A.; Bailey, D.G. Near optimal non-uniform interpolation for image super-resolution from multiple images. Image Vis. Comput. N. Z. Great Barrier Isl. N. Z. 2006, 20, 31–35. [Google Scholar]
- Rasti, P.; Demirel, H.; Anbarjafari, G. Iterative back projection based image resolution enhancement. In Proceedings of the 2013 8th Iranian Conference on Machine Vision and Image Processing, Zanjan, Iran, 10–12 September 2013; pp. 237–240. [Google Scholar]
- Tipping, M.E.; Bishop, C.M. Bayesian image super-resolution. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver and Whistler, BC, Canada, 8–13 December 2003; pp. 1303–1310. [Google Scholar]
- Fan, C.; Wu, C.; Li, G.; Ma, J. Projections onto convex sets super-resolution reconstruction based on point spread function estimation of low-resolution remote sensing images. Sensors 2017, 17, 362. [Google Scholar] [CrossRef]
- Xu, J.; Gao, Y.; Xing, J.; Fan, J.; Gao, Q.; Tang, S. Two-direction self-learning super-resolution propagation based on neighbor embedding. Signal Process. 2021, 183, 108033. [Google Scholar] [CrossRef]
- Zhang, J.; Shao, M.; Yu, L.; Li, Y. Image super-resolution reconstruction based on sparse representation and deep learning. Signal Process. Image Commun. 2020, 87, 115925. [Google Scholar] [CrossRef]
- Ooi, Y.K.; Ibrahim, H. Deep Learning Algorithms for Single Image Super-Resolution: A Systematic Review. Electronics 2021, 10, 867. [Google Scholar] [CrossRef]
- Minsky, M. Steps toward Artificial Intelligence. Proc. IRE 1961, 49, 8–30. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, X.; Tian, Y.; Wang, W.; Xue, J.; Liao, Q. Deep Learning for Single Image Super-Resolution: A Brief Review. IEEE Trans. Multimed. 2019, 21, 3106–3121. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 391–407. [Google Scholar]
- Xu, L.; Ren, J.S.; Liu, C.; Jia, J. Deep Convolutional Neural Network for Image Deconvolution. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1790–1798. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume abs/1512.03385, pp. 770–778. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Xiaomei, Y.; Chenghu, Z. Analysis of the complexity of remote sensing image and its role on image classification. In Proceedings of the IEEE Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 24–28 July 2000; Volume 5, pp. 2179–2181. [Google Scholar]
- Aumann, R.; Brandenburger, A. Epistemic Conditions for Nash Equilibrium. Econometrica 1995, 63, 1161–1180. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Clements, M.P.; Hendry, D.F. On the limitations of comparing mean square forecast errors. J. Forecast. 1993, 12, 617–637. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Texture synthesis and the controlled generation of natural stimuli using convolutional neural networks. In Proceedings of the Bernstein Conference 2015, Heidelberg, Germany, 15–17 September 2015. [Google Scholar]
- Bruna, J.; Sprechmann, P.; Lecun, Y. Super-Resolution with Deep Convolutional Sufficient Statistics. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–17. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October; pp. 694–711.
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014; pp. 1–14. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision Workshops, Munich, Germany, 8–14 September 2018; pp. 1–16. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–25. [Google Scholar]
- Ma, C.; Rao, Y.; Cheng, Y.; Chen, C.; Lu, J.; Zhou, J. Structure-Preserving Super Resolution With Gradient Guidance. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7766–7775. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31, pp. 1–7. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 30, p. 3. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; Volume abs/1611.07004, pp. 1125–1134. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Yang, C.; Ma, C.; Yang, M. Single-Image Super-Resolution: A Benchmark. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 372–386. [Google Scholar]
- Zhou, W.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1905–1914. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; pp. 711–730. [Google Scholar]
- Huang, J.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]




| Network Layers | Calculation Formula | Size of the Output Matrix |
|---|---|---|
| the first layer | ||
| the second layer | ||
| the third layer | ||
| the fourth layer | ||
| the fifth layer |
| PSNR | |||||||||
| SSIM | |||||||||
| LPIPS |
| Metrics | Bicubic | CNN | GAN | |||||
|---|---|---|---|---|---|---|---|---|
| SRCNN | EDSR | SRGAN | ESRGAN | SPSR | Real-ESRGAN | Ours | ||
| PSNR | ||||||||
| SSIM | ||||||||
| LPIPS | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, M.; Zhang, Z.; Liu, H.; Huang, Y. NDSRGAN: A Novel Dense Generative Adversarial Network for Real Aerial Imagery Super-Resolution Reconstruction. Remote Sens. 2022, 14, 1574. https://doi.org/10.3390/rs14071574
Guo M, Zhang Z, Liu H, Huang Y. NDSRGAN: A Novel Dense Generative Adversarial Network for Real Aerial Imagery Super-Resolution Reconstruction. Remote Sensing. 2022; 14(7):1574. https://doi.org/10.3390/rs14071574
Chicago/Turabian StyleGuo, Mingqiang, Zeyuan Zhang, Heng Liu, and Ying Huang. 2022. "NDSRGAN: A Novel Dense Generative Adversarial Network for Real Aerial Imagery Super-Resolution Reconstruction" Remote Sensing 14, no. 7: 1574. https://doi.org/10.3390/rs14071574
APA StyleGuo, M., Zhang, Z., Liu, H., & Huang, Y. (2022). NDSRGAN: A Novel Dense Generative Adversarial Network for Real Aerial Imagery Super-Resolution Reconstruction. Remote Sensing, 14(7), 1574. https://doi.org/10.3390/rs14071574