
Accessing the Impact of Meteorological Variables on Machine Learning Flood Susceptibility Mapping


Abstract
:1. Introduction
2. Materials and Methods
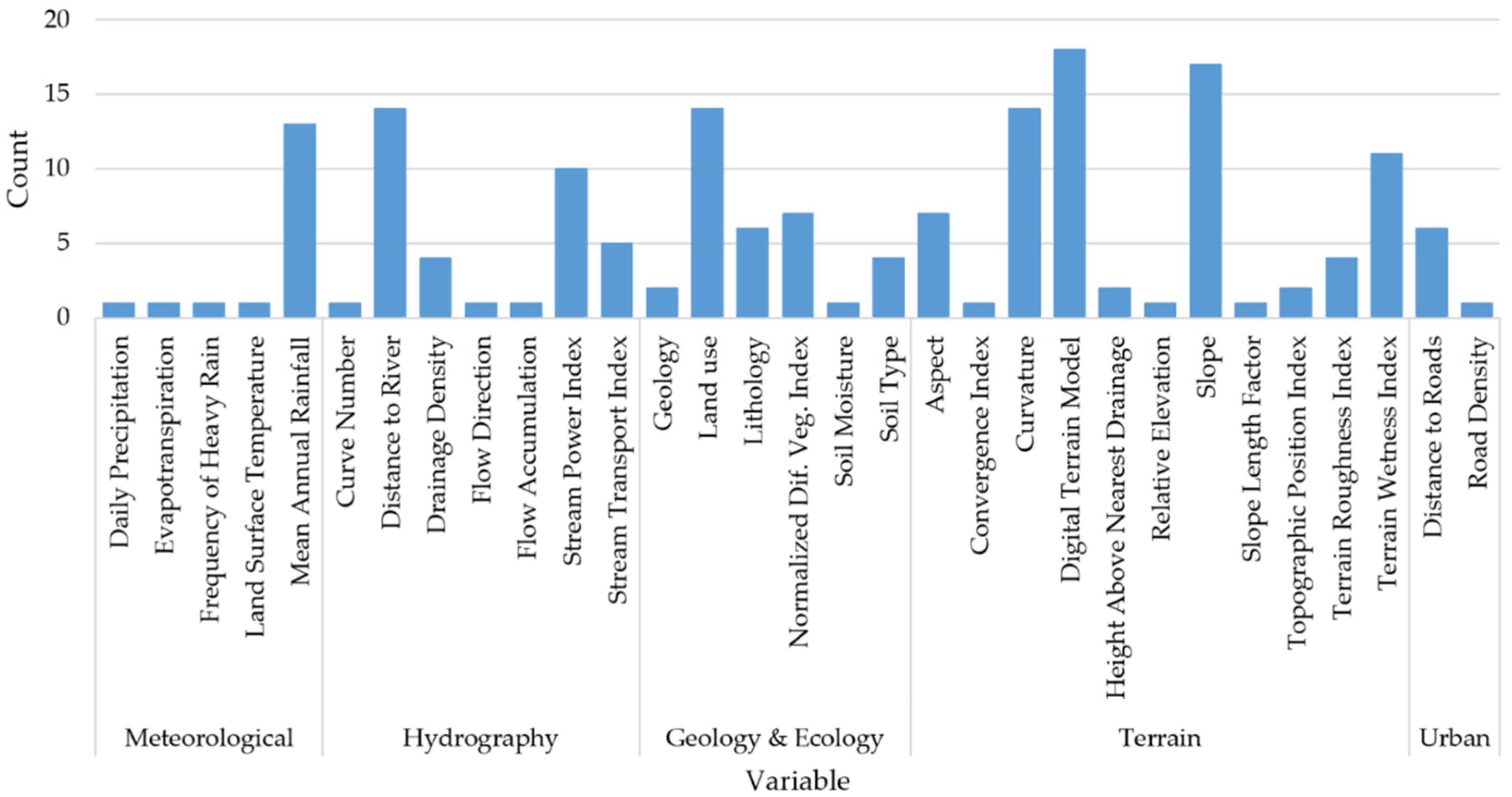
2.1. Exploratory Variables
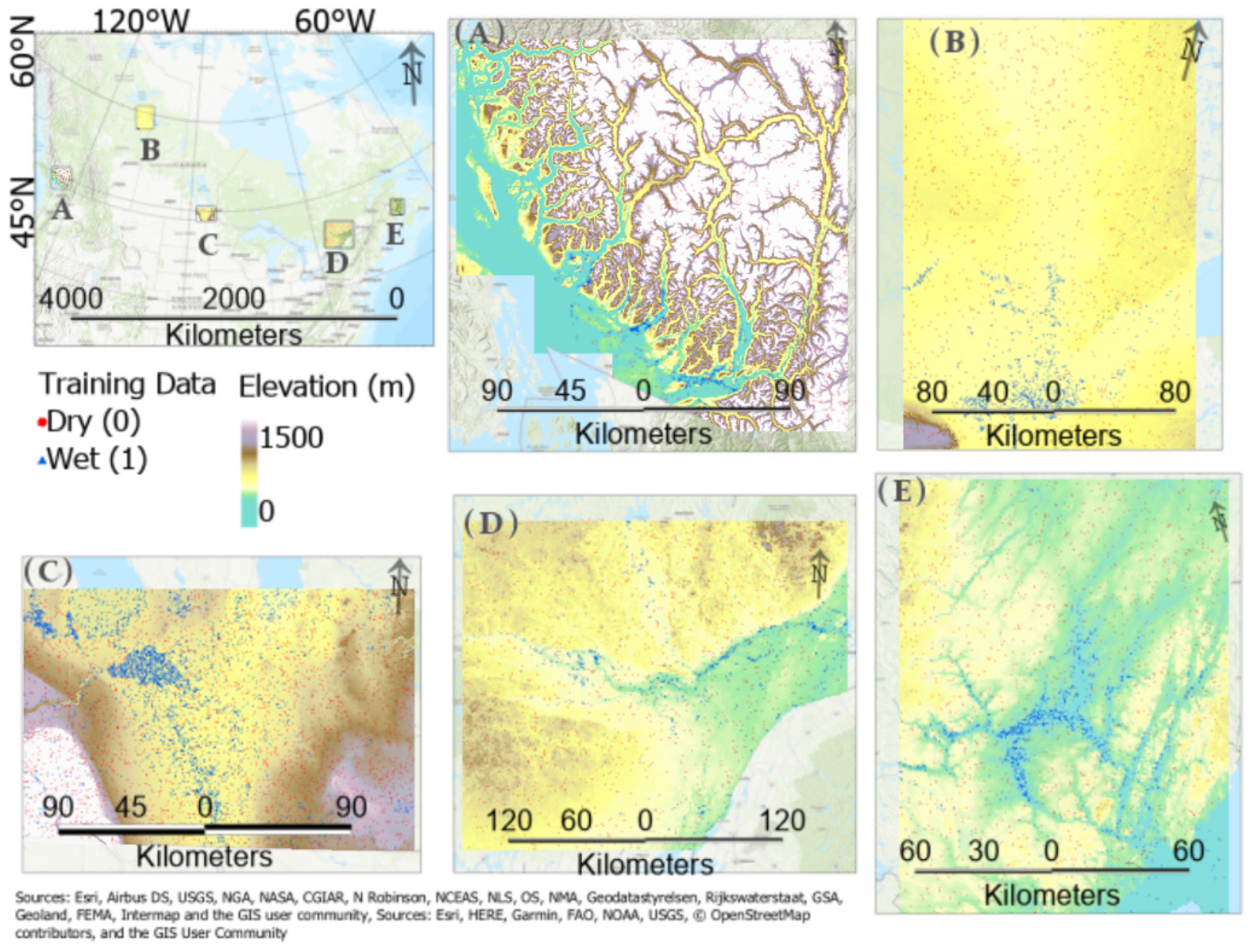
2.2. Training Data
2.3. Machine Learning
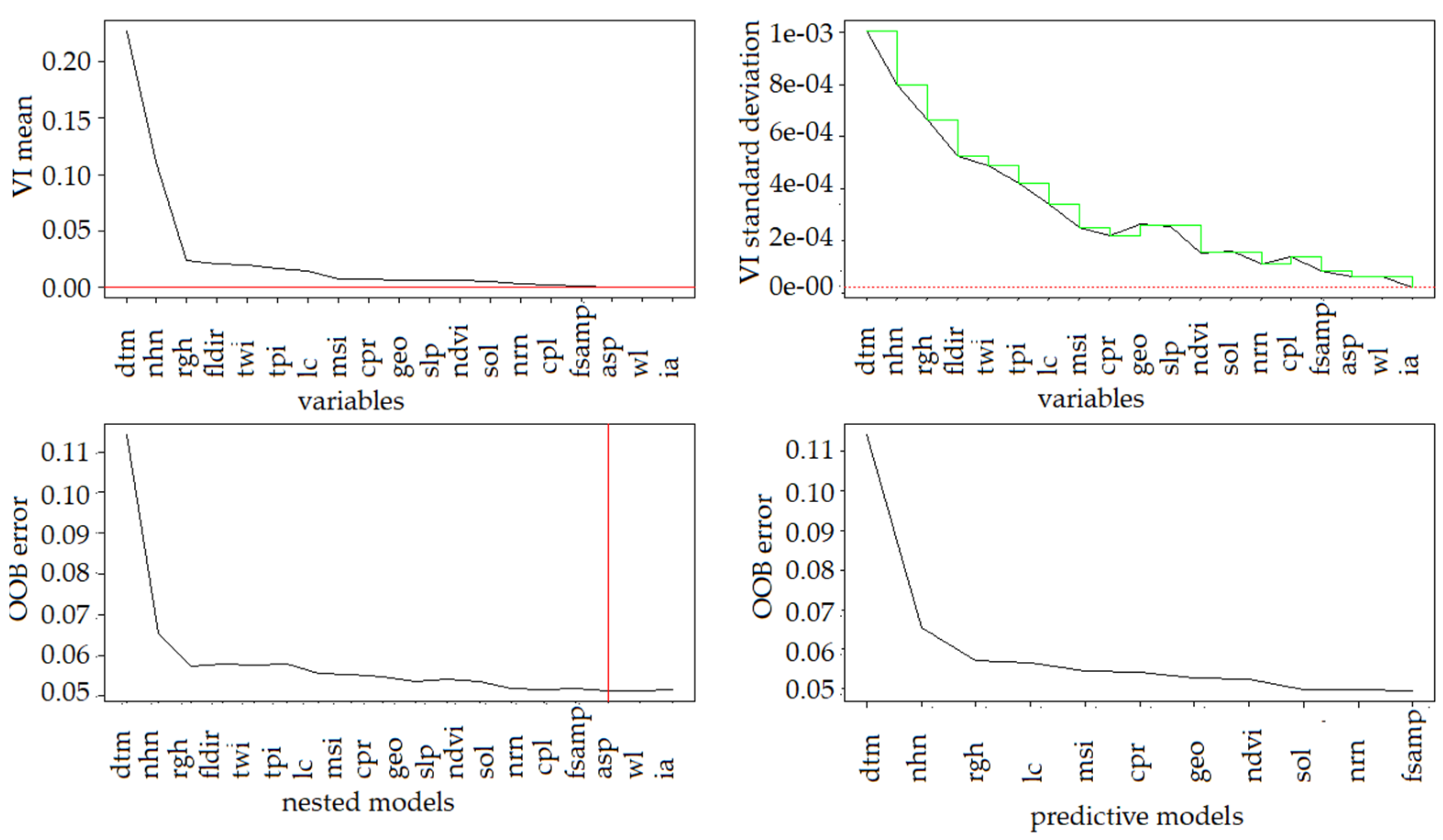
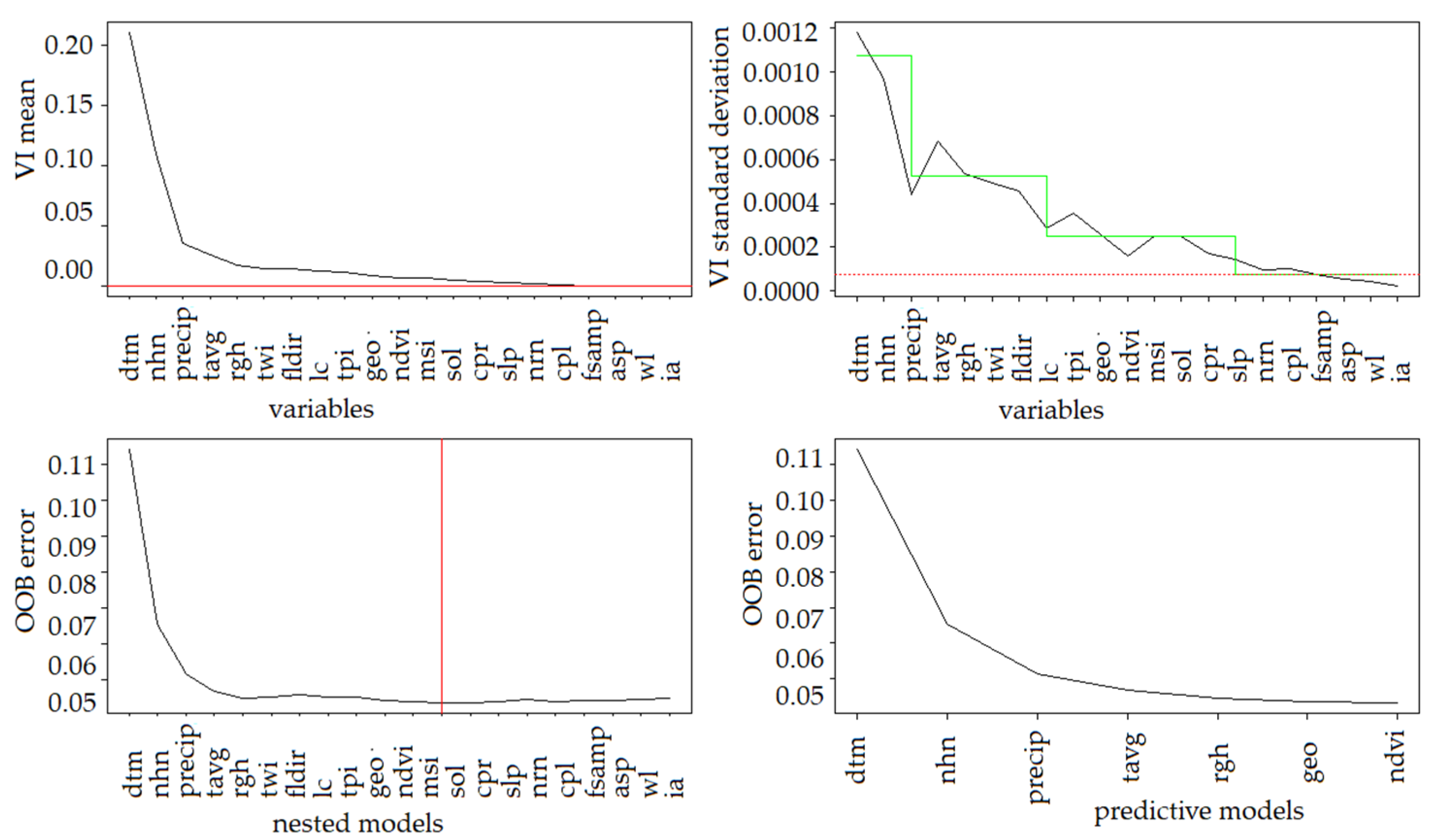
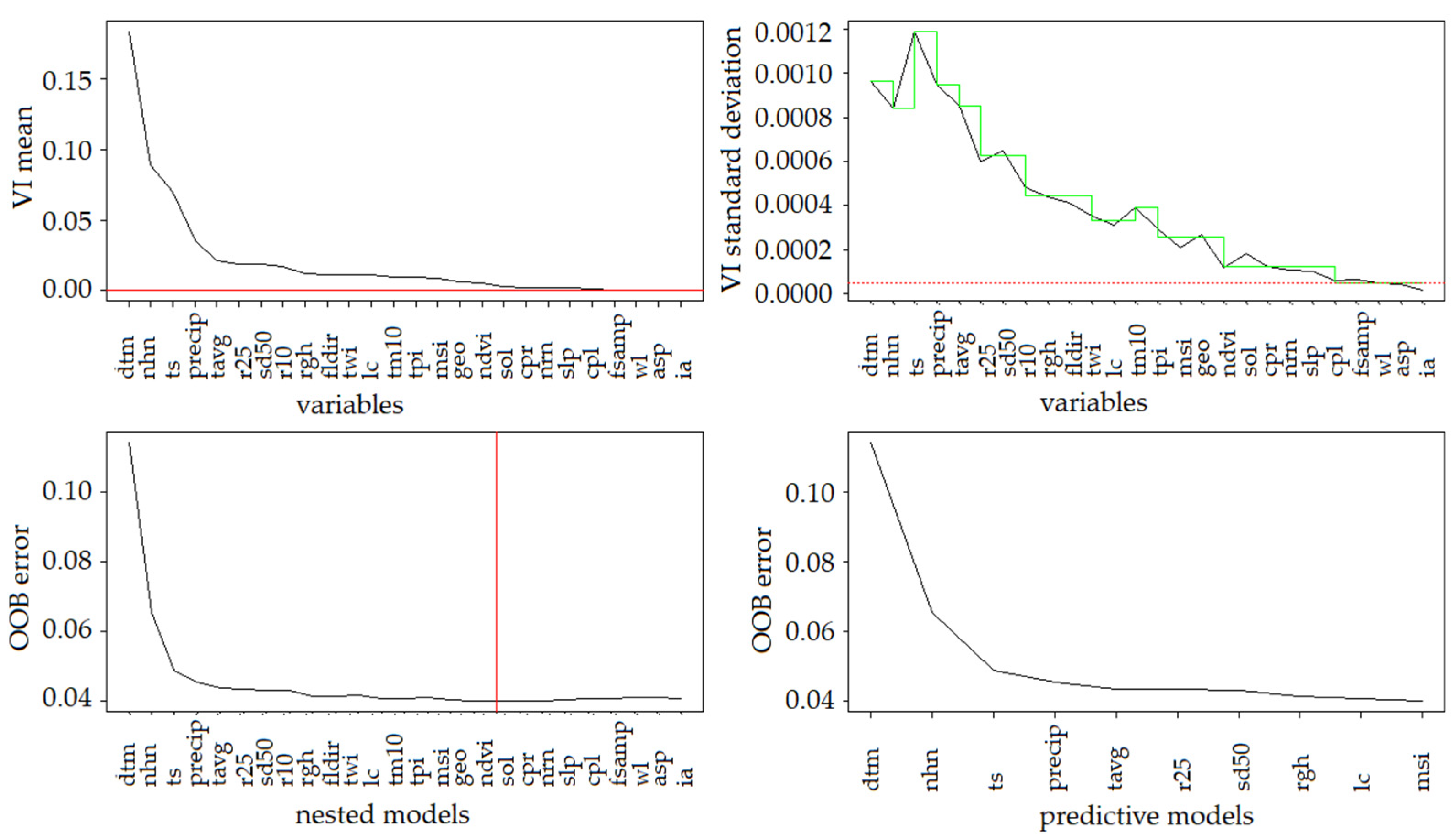
2.3.1. Evaluation of Important Factors
2.3.2. Selected Model
Random Forest
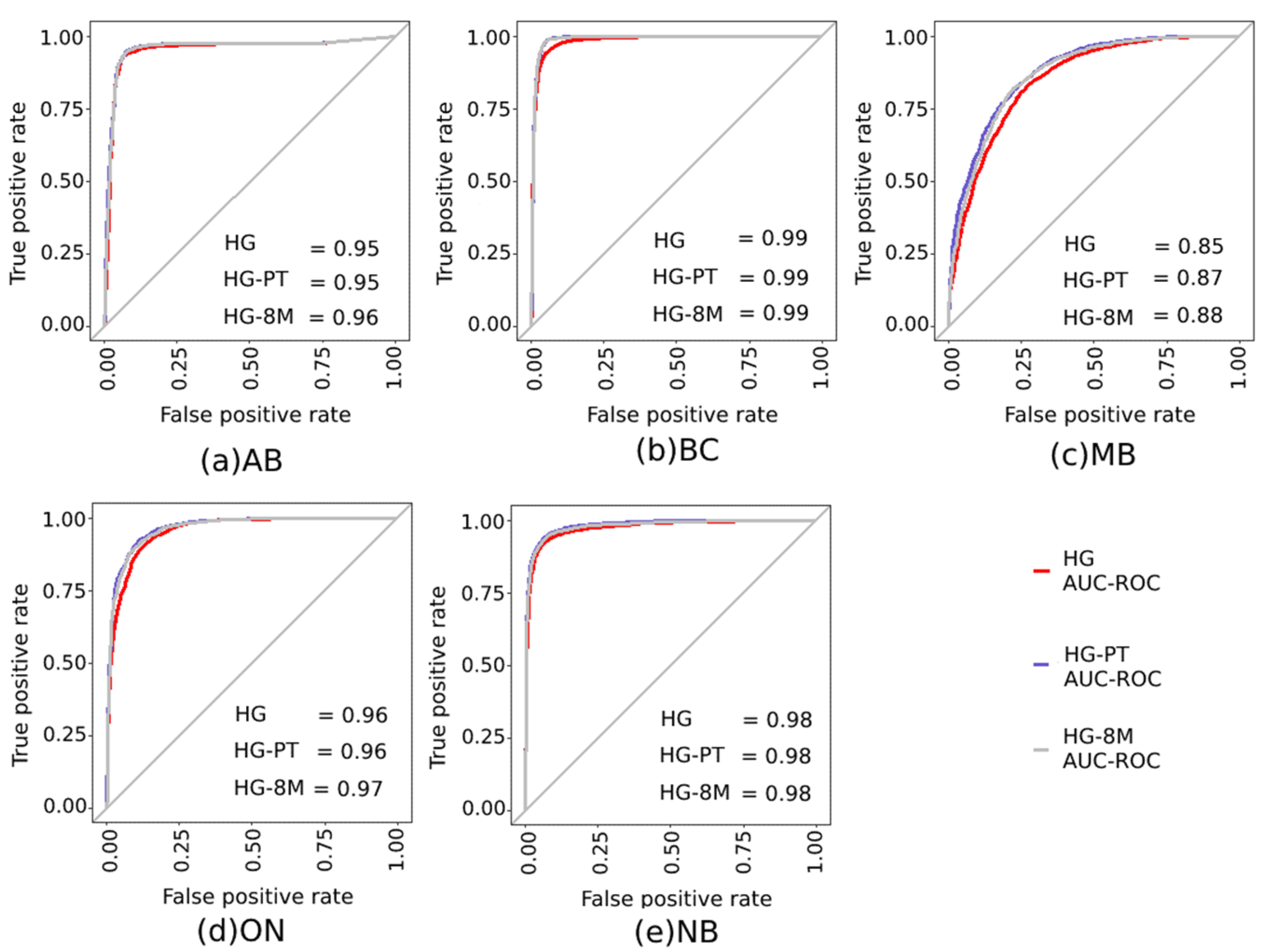
2.3.3. Analysis Metrics
3. Study Areas
4. Results
4.1. Exploratory Variables
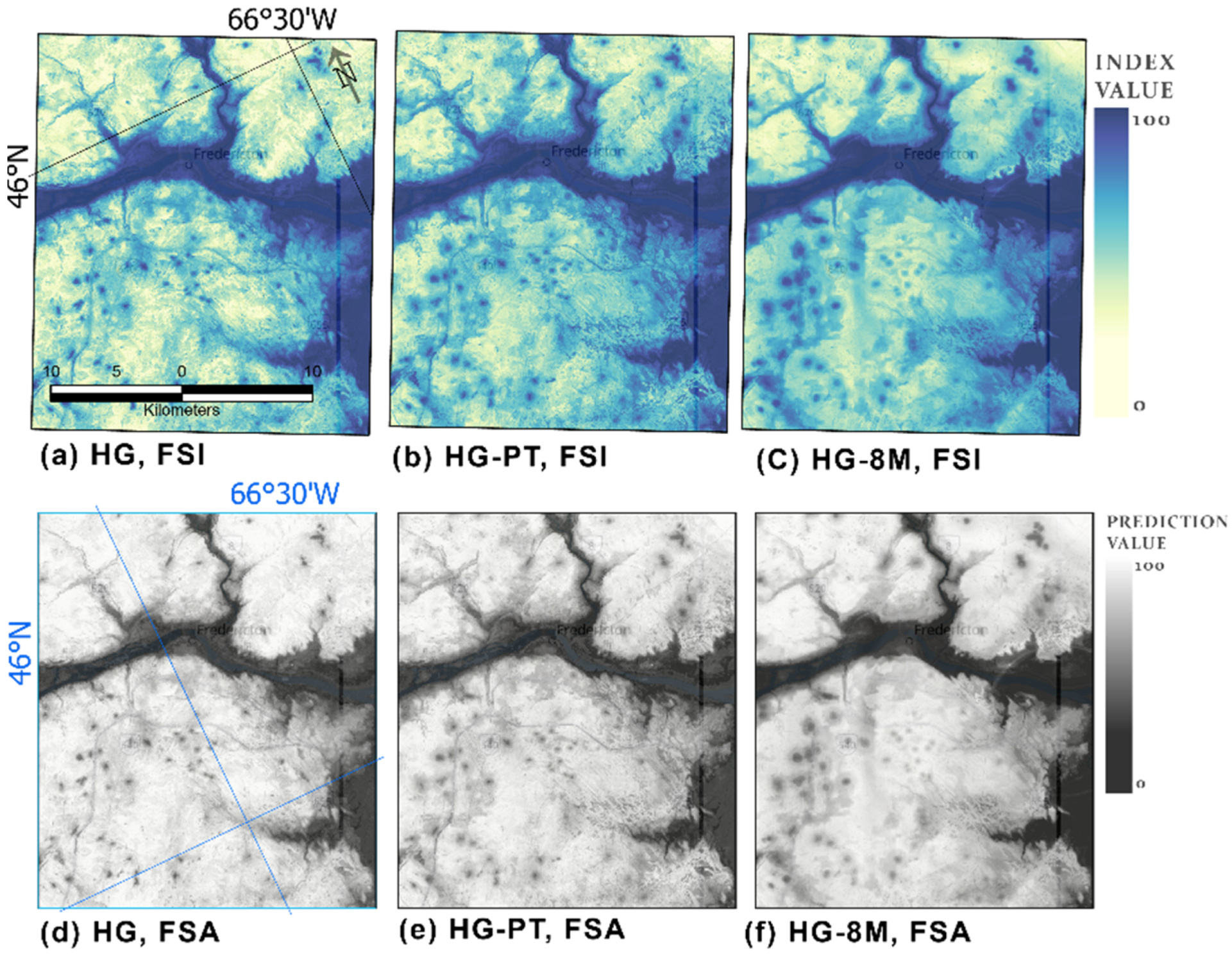
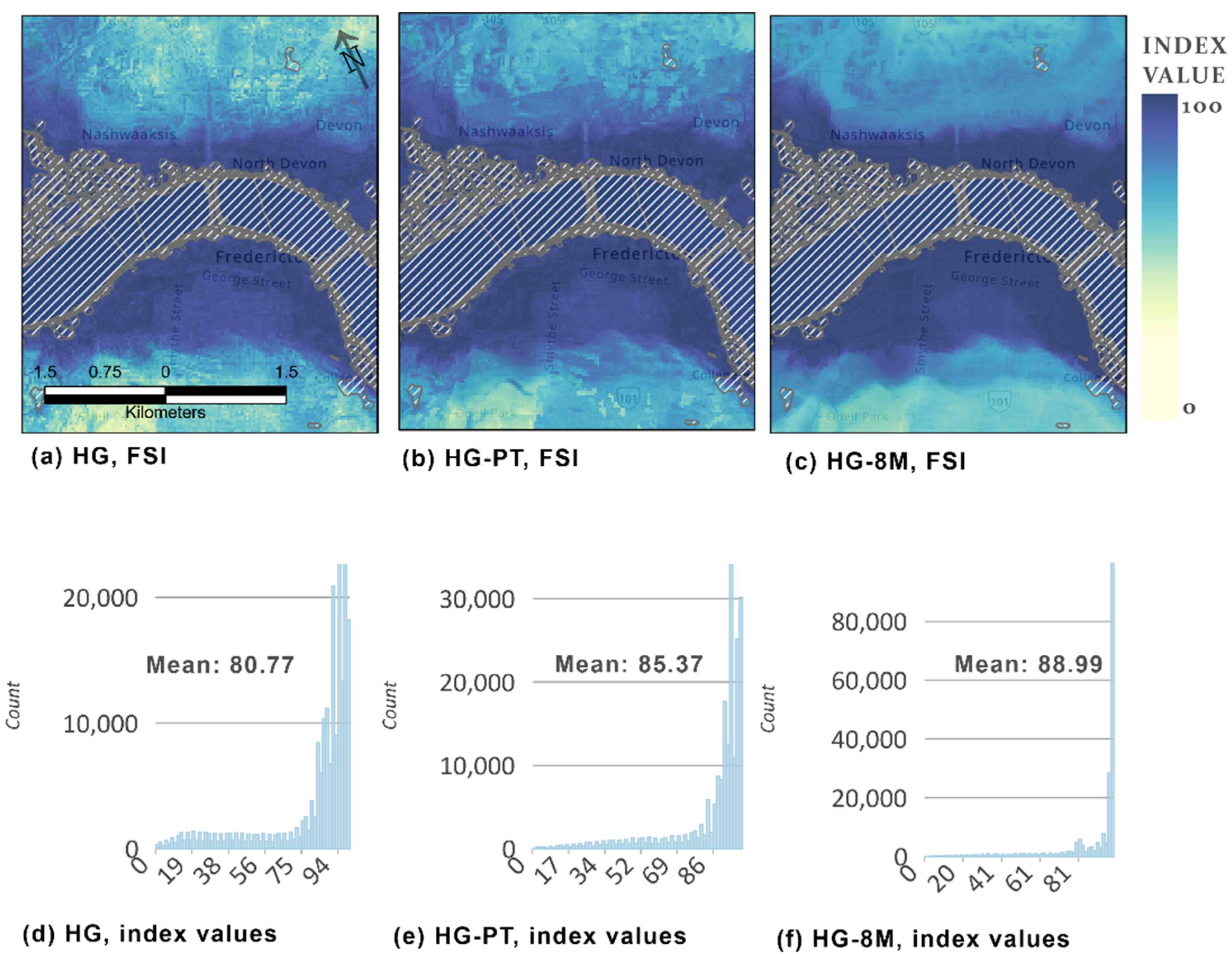
4.2. Model Results
5. Discussion
5.1. Important Factors
5.2. Model Results
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Natural Resources Canada and Public Safety Canada. Federal Flood Mapping Framework, Technical Report. version 2.0; Government of Canada: Ottawa, ON, Canada, 2018. [Google Scholar]
- Coulson, C. Manual of Operational Hydrology in British Columbia; Ministry of Environment, Water Management Division, Hydrology Section: Victoria, BC, Canada, 1991.
- Henry, S.; Laroche, A.-M.; Hentati, A.; Boisvert, J. Prioritizing Flood-Prone Areas Using Spatial Data in the Province of New Brunswick, Canada. Geosciences 2020, 10, 478. [Google Scholar] [CrossRef]
- Carvalho, A.C.P.; Pejon, O.J.; Collares, E.G. Integration of morphometric attributes and the HAND model for the identification of Flood-Prone Area. Environ. Earth Sci. 2020, 79, 367. [Google Scholar] [CrossRef]
- De Lollo, J.A.; Marteli, A.N.; Lorandi, R. Flooding Susceptibility Identification Using the HAND Algorithm Tool Supported by Land Use/Land Cover Data. IAEG/AEG Annu. Meet. Proc. 2018, 2, 107–112. [Google Scholar] [CrossRef]
- Echogdali, F.Z.; Boutaleb, S.; Elmouden, A.; Ouchchen, M. Assessing Flood Hazard at River Basin Scale: Comparison between HECRAS-WMS and Flood Hazard Index (FHI) Methods Applied to El Maleh Basin, Morocco. J. Water Resour. Prot. 2018, 10, 957–977. [Google Scholar] [CrossRef] [Green Version]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.-B.; Gróf, G.; Ho, H.L.; et al. A comparative assessment of flood susceptibility modeling using Multi-Criteria Decision-Making Analysis and Machine Learning Methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Montani, I.; Marquis, R.; Anthonioz, N.E.; Champod, C. Resolving differing expert opinions. Sci. Justice 2019, 59, 1–8. [Google Scholar] [CrossRef]
- Band, S.; Janizadeh, S.; Pal, S.C.; Saha, A.; Chakrabortty, R.; Melesse, A.; Mosavi, A. Flash Flood Susceptibility Modeling Using New Approaches of Hybrid and Ensemble Tree-Based Machine Learning Algorithms. Remote Sens. 2020, 12, 3568. [Google Scholar] [CrossRef]
- Alipour, A.; Ahmadalipour, A.; Abbaszadeh, P.; Moradkhani, H. Leveraging machine learning for predicting flash flood damage in the Southeast US. Environ. Res. Lett. 2020, 15, 024011. [Google Scholar] [CrossRef]
- Mai, J.; Tolson, B.A.; Shen, H.; Gaborit, É; Fortin, V.; Gasset, N.; Awoye, H.; Stadnyk, T.A.; Fry, L.M.; Bradley, E.A.; et al. Great Lakes Runoff Intercomparison Project Phase 3: Lake Erie (GRIP-E). J. Hydrol. Eng. 2021, 26, 05021020. [Google Scholar] [CrossRef]
- Li, X.; Yan, D.; Wang, K.; Weng, B.; Qin, T.; Liu, S. Flood Risk Assessment of Global Watersheds Based on Multiple Machine Learning Models. Water 2019, 11, 1654. [Google Scholar] [CrossRef] [Green Version]
- Zhao, G.; Pang, B.; Xu, Z.; Yue, J.; Tu, T. Mapping flood susceptibility in mountainous areas on a national scale in China. Sci. Total Environ. 2018, 615, 1133–1142. [Google Scholar] [CrossRef] [PubMed]
- Dodangeh, E.; Choubin, B.; Eigdir, A.N.; Nabipour, N.; Panahi, M.; Shamshirband, S.; Mosavi, A. Integrated machine learning methods with resampling algorithms for flood susceptibility prediction. Sci. Total Environ. 2019, 705, 135983. [Google Scholar] [CrossRef] [PubMed]
- Shafizadeh-Moghadam, H.; Valavi, R.; Shahabi, H.; Chapi, K.; Shirzadi, A. Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J. Environ. Manag. 2018, 217, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Esfandiari, M.; Abdi, G.; Jabari, S.; McGrath, H.; Coleman, D. Flood Hazard Risk Mapping Using a Pseudo Supervised Random Forest. Remote Sens. 2020, 12, 3206. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Du, J.; Zhang, L.; Song, Y.; Sun, G. Multi-geohazards susceptibility mapping based on machine learning—a case study in Jiuzhaigou, China. Nat. Hazards 2020, 102, 851–871. [Google Scholar] [CrossRef]
- Roopnarine, R.; Opadeyi, J.; Eudoxie, G.; Thongs, G.; Edwards, E. GIS-based flood susceptibility and risk mapping Trinidad using weight factor modeling. Caribb. J. Earth Sci. 2018, 49, 18. [Google Scholar]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz watershed, northern Iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef] [PubMed]
- Arabameri, A.; Saha, S.; Chen, W.; Roy, J.; Pradhan, B.; Bui, D.T. Flash flood susceptibility modelling using functional tree and hybrid ensemble techniques. J. Hydrol. 2020, 587, 125007. [Google Scholar] [CrossRef]
- Islam, A.R.M.T.; Talukdar, S.; Mahato, S.; Kundu, S.; Eibek, K.U.; Pham, Q.B.; Kuriqi, A.; Linh, N.T.T. Flood susceptibility modelling using advanced ensemble machine learning models. Geosci. Front. 2020, 12, 101075. [Google Scholar] [CrossRef]
- Natural Resources Canada. Map Information Branch. Canadian Digital Elevation Model Product Specifications. 2016. Available online: http://ftp.geogratis.gc.ca/pub/nrcan_rncan/elevation/cdem_mnec/doc/CDEM_product_specs.pdf (accessed on 17 September 2021).
- Natural Resources Canada. High Resolution Digital Elevation Model (HRDEM)—CanElevation Series; Product Specifications edition 1.1; Government of Canada: Ottawa, ON, Canada, 2017. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: https://www.R-project.org/ (accessed on 1 December 2021).
- Latifovic, R. Canada’s Land Cover, Tech. Rep. version 2015; Natural Resources: Ottawa, ON, Canada, 2015. [Google Scholar]
- Pearthree, P.A.; Young, J.J.; Cook, J.P. Surficial Geology and Flood Hazards on the Western Piedmont of the Maricopa Mountains and the Southern Piedmont of the Buckeye Hills, Maricopa County, Arizona. 2012. Available online: http://repository.azgs.az.gov/uri_gin/azgs/dlio/1456 (accessed on 27 January 2022).
- Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W. Disturbance-Informed Annual Land Cover Classification Maps of Canada’s Forested Ecosystems for a 29-Year Landsat Time Series. Can. J. Remote Sens. 2018, 44, 67–87. [Google Scholar] [CrossRef]
- Government of Canada. Canadian Climate Normals. Available online: https://climate.weather.gc.ca/climate_normals/ (accessed on 26 August 2021).
- Minerva Intelligence and Ebbwater Consulting. National Flood Hazard Data Layer: Schema Design and Implementation Final Report; Minerva Intelligence, Tech. Rep. Project; NRCan—NFHDL: Vancouver, BC, Canada, 2021. [Google Scholar]
- Genuer, R.; Poggi, J.-M.; Tuleau-Malot, C. VSURF: An R Package for Variable Selection Using Random Forests. R J. 2015, 7, 19–33. [Google Scholar] [CrossRef] [Green Version]
- Sanchez-Pinto, L.N.; Venable, L.R.; Fahrenbach, J.; Churpek, M.M. Comparison of variable selection methods for clinical predictive modeling. Int. J. Med. Inform. 2018, 116, 10–17. [Google Scholar] [CrossRef] [PubMed]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Kuhn, M. Caret: Classification and Regression Training; Astrophysics Source Code Library: Leicester, UK, 2021. [Google Scholar]
- Bi, J.-W.; Liu, Y.; Fan, Z.-P.; Zhang, J. Wisdom of crowds: Conducting importance-performance analysis (IPA) through online reviews. Tour. Manag. 2018, 70, 460–478. [Google Scholar] [CrossRef]
- Chen, J.; Li, K.; Tang, Z.; Bilal, K.; Yu, S.; Weng, C.; Li, K. A Parallel Random Forest Algorithm for Big Data in a Spark Cloud Computing Environment. IEEE Trans. Parallel Distrib. Syst. 2016, 28, 919–933. [Google Scholar] [CrossRef] [Green Version]
- Delgado, R.; Tibau, X.-A. Why Cohen’s Kappa should be avoided as performance measure in classification. PLoS ONE 2019, 14, e0222916. [Google Scholar] [CrossRef] [Green Version]
- Fielding, A.H.; Bell, J.F. A review of methods for the assessment of prediction errors in conservation presence/absence models. Environ. Conserv. 1997, 24, 38–49. [Google Scholar] [CrossRef]
- Mann, R. Recalling the 2018 New Brunswick Floods—One of the Worst in Modern History. Available online: https://www.theweathernetwork.com/ca/news/article/this-day-in-weather-history-april-24-2018-new-brunswick-flooding (accessed on 27 January 2022).
- Demir, G.; Akyurek, Z. The Importance of Precise Digital Elevation Models (DEM) in Modelling Floods. In Geophysical Research Abstracts, EGU General Assembly 2016; EGU General Assembly: Vienna, Austria, 2016. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Test | Variable | Code | Source (UUID from OpenMaps.ca, (Accessed on 17 August 2021)) | Method |
|---|---|---|---|---|---|
| G | HG | Forest Cover (Percent) | fcp | Extracted from LC | |
| G | HG | Impermeable Areas | ia | Extracted from LC | |
| G | HG | Land Cover | lc | 4e615eae-b90c-420b-adee-2ca35896caf6 | |
| G | HG | NDVI | ndvi | 44ced2fa-afcc-47bd-b46e-8596a25e446e | |
| G | HG | Soil | sol | 0b88062f-ebbe-46c6-ab19-54fd226e9aa7 | |
| G | HG | Surficial Geology | geo | cebc283f-bae1-4eae-a91f-a26480cd4e4a | |
| H | HG | Flow Direction | fldir | Derivative DTM | R raster |
| H | HG | Minimum Snow and Ice | msi | 808b84a1-6356-4103-a8e9-db46d5c20fcf | |
| H | HG | Hydrographic network | nhn | a4b190fe-e090-4e6d-881e-b87956c07977 | |
| H | HG | Stream Power Index | spi | Derivative DTM, NHN | ln(CA*tan(slp)) |
| H | HG | Terrain Wetness Index | twi | Derivative DTM | ln(a/tan(slp)) |
| H | HG | Wetland | wl | 02c992bb-9692-4bff-9517-7a92b09676c7 | |
| T | HG | Aspect | asp | Derivative DTM | R gdalUtils |
| T | HG | Curvature-Plan | cpl | Derivative DTM | R spatialEco |
| T | HG | Curvature-Profile | cpr | Derivative DTM | R spatialEco |
| T | HG | Digital Terrain Model | dtm | 957782bf-847c-4644-a757-e383c0057995, 7f245e4d-76c2-4caa-951a-45d1d2051333 | |
| T | HG | Roughness | rgh | Derivative DTM | R gdalUtils |
| T | HG | Slope | slp | Derivative DTM | R gdalUtils |
| T | HG | Terrain Roughness Index | tri | Derivative DTM | R gdalUtils |
| T | HG | Topographic Position Index | tpi | Derivative DTM | R dalUtils |
| C | HG-PT | Average Precipitation | precip | https://climate-change.canada.ca/climate-data/#/climate-normals, (accessed on 26 August 2020) | R gstat::idw |
| C | HG-PT | Average Temperature | tavg | R gstat::idw | |
| C | Days with >10 mm Rainfall | r10 | R gstat::idw | ||
| C | HG-8M | Days with >25 mm Rainfall | r25 | R gstat::idw | |
| C | HG-8M | Days with min temp < −10 °C | tm10 | R gstat::idw | |
| C | HG-8M | Days with Snow Depth. 50 cm | sd50 | R gstat::idw | |
| C | HG-8M | Number of Spring days, min temp > 0 °C | spr | R gstat::idw | |
| C | HG-8M | Total Snow | ts | R gstat::idw | |
| U | HG | Euclidean distance to roads | nrn | 3d282116-e556-400c-9306-ca1a3cada77f |
| parRF | Accuracy | F1 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Site | HG | HG-PT | HG-8M | HG | HG-PT | HG-8M | HG | HG-PT | HG-8M |
| AB | 0.953 | 0.955 | 0.957 | 0.904 | 0.911 | 0.914 | 0.95 | 0.954 | 0.956 |
| BC | 0.963 | 0.971 | 0.971 | 0.927 | 0.94 | 0.94 | 0.963 | 0.969 | 0.969 |
| MB | 0.797 | 0.822 | 0.827 | 0.593 | 0.643 | 0.653 | 0.782 | 0.811 | 0.82 |
| ON | 0.903 | 0.923 | 0.926 | 0.805 | 0.845 | 0.85 | 0.898 | 0.918 | 0.921 |
| NB | 0.939 | 0.943 | 0.954 | 0.877 | 0.885 | 0.908 | 0.935 | 0.939 | 0.951 |
| HG | HG-PT | HG-8M | |||||||
|---|---|---|---|---|---|---|---|---|---|
| HG | Meteo | Total | HG | Meteo | Total | HG | Meteo | Total | |
| AB | 7 | 0 | 7 | 6 | 2 | 8 | 5 | 4 | 9 |
| BC | 9 | 0 | 9 | 6 | 2 | 8 | 6 | 5 | 11 |
| MB | 8 | 0 | 8 | 7 | 2 | 9 | 8 | 4 | 12 |
| ON | 10 | 0 | 10 | 6 | 2 | 8 | 7 | 3 | 10 |
| NB | 12 | 0 | 12 | 7 | 2 | 9 | 7 | 5 | 12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
McGrath, H.; Gohl, P.N. Accessing the Impact of Meteorological Variables on Machine Learning Flood Susceptibility Mapping. Remote Sens. 2022, 14, 1656. https://doi.org/10.3390/rs14071656
McGrath H, Gohl PN. Accessing the Impact of Meteorological Variables on Machine Learning Flood Susceptibility Mapping. Remote Sensing. 2022; 14(7):1656. https://doi.org/10.3390/rs14071656
Chicago/Turabian StyleMcGrath, Heather, and Piper Nora Gohl. 2022. "Accessing the Impact of Meteorological Variables on Machine Learning Flood Susceptibility Mapping" Remote Sensing 14, no. 7: 1656. https://doi.org/10.3390/rs14071656
APA StyleMcGrath, H., & Gohl, P. N. (2022). Accessing the Impact of Meteorological Variables on Machine Learning Flood Susceptibility Mapping. Remote Sensing, 14(7), 1656. https://doi.org/10.3390/rs14071656