
A SLAM System with Direct Velocity Estimation for Mechanical and Solid-State LiDARs


Abstract
:1. Introduction
- The point cloud generated by the various LiDARs is represented as a spherical image by spherical projection for further processing. In contrast to most scan line-based feature extraction methods, our method classifies feature points based on a more precise point-to-plane or point-to-line distance. In addition, the features are grouped into higher-level clusters to prevent inaccurate data associations.
- We estimate the velocities while estimating the poses during the odometry stage. With a small bundle adjustment, we can perform a 12-degree-of-freedom estimation for multiple scans simultaneously, allowing us to directly obtain accurate velocities.
- We present an efficient method for computing the covariance matrix of the feature points, which significantly reduces the computational complexity of bundle adjustment during the mapping stage.
- We test the performance of our algorithm on four types of LiDARs, including two rotor-based mechanical LiDARs and two solid-state LiDARs. The experimental results show that the proposed method can be applied successfully to these LiDARs and that it achieves higher precision than existing state-of-the-art SLAM methods.
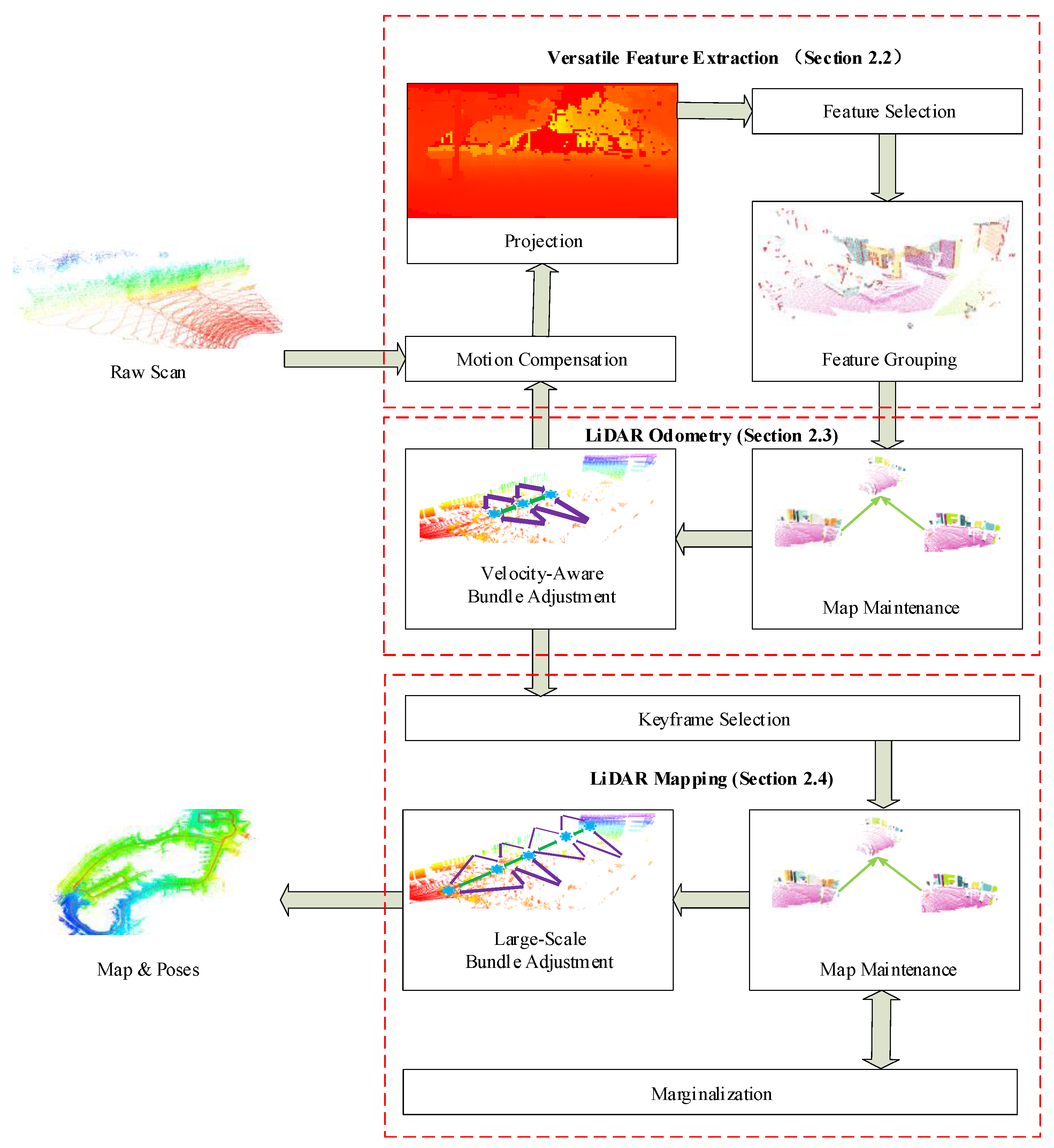
2. Method
2.1. System Overview
2.2. Versatile Feature Extraction
2.2.1. Motion Prediction and Point Cloud Compensation
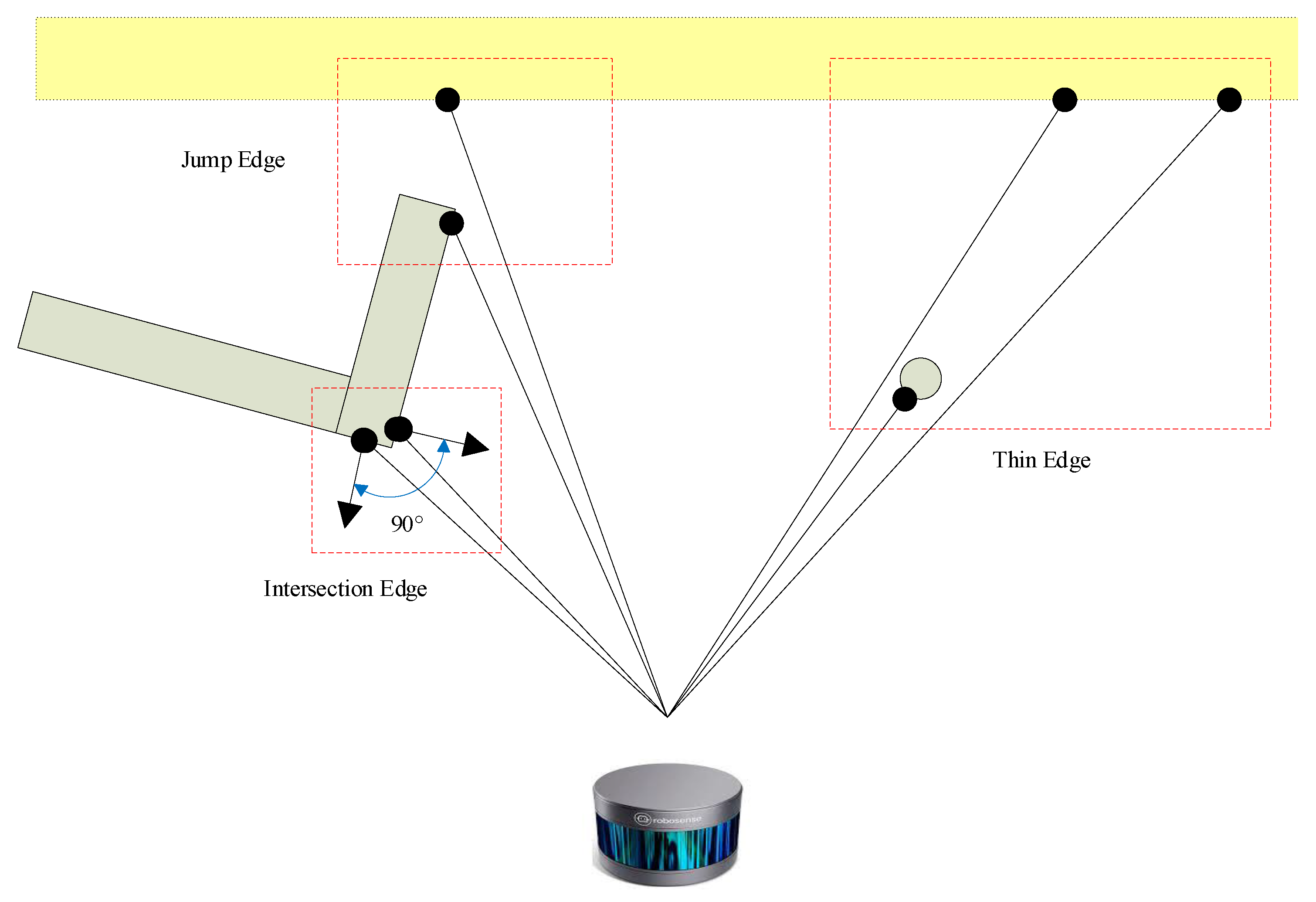
2.2.2. Classification of Planar Features
2.2.3. Classification of Edge Features
- A point i is selected as an intersection edge feature if it and its neighboring point j are planar features with different planar feature IDs. Moreover, the position and normal of i and j must satisfy the conditions:
- A point i is selected as a jump edge feature if it is a planar feature with a significantly different depth than its neighboring point j:
- A point i is selected as a thin edge feature if its two adjacent points j and k in the same row or column satisfy the conditions:
2.3. LiDAR Odometry
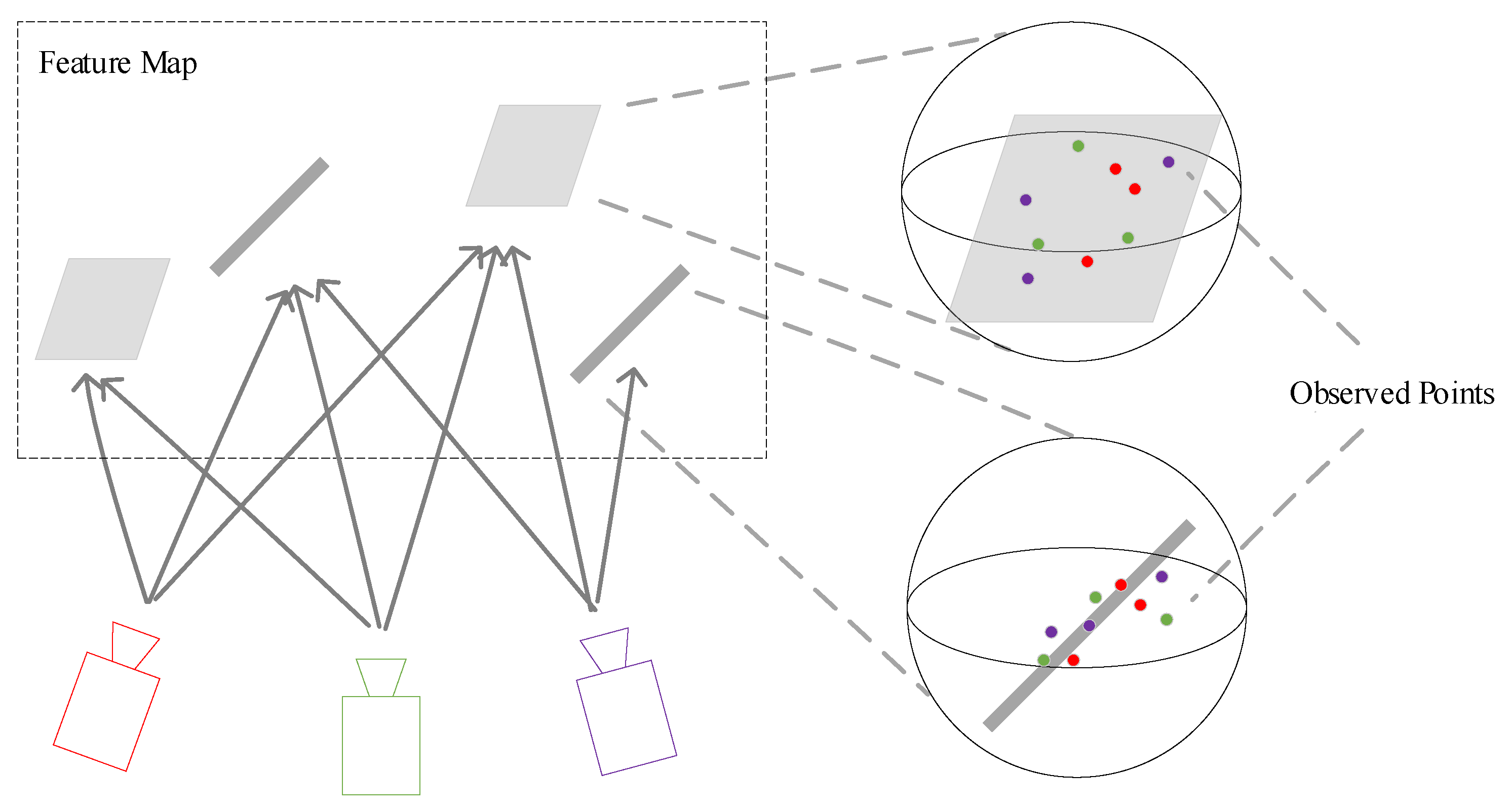
2.3.1. Map Maintenance
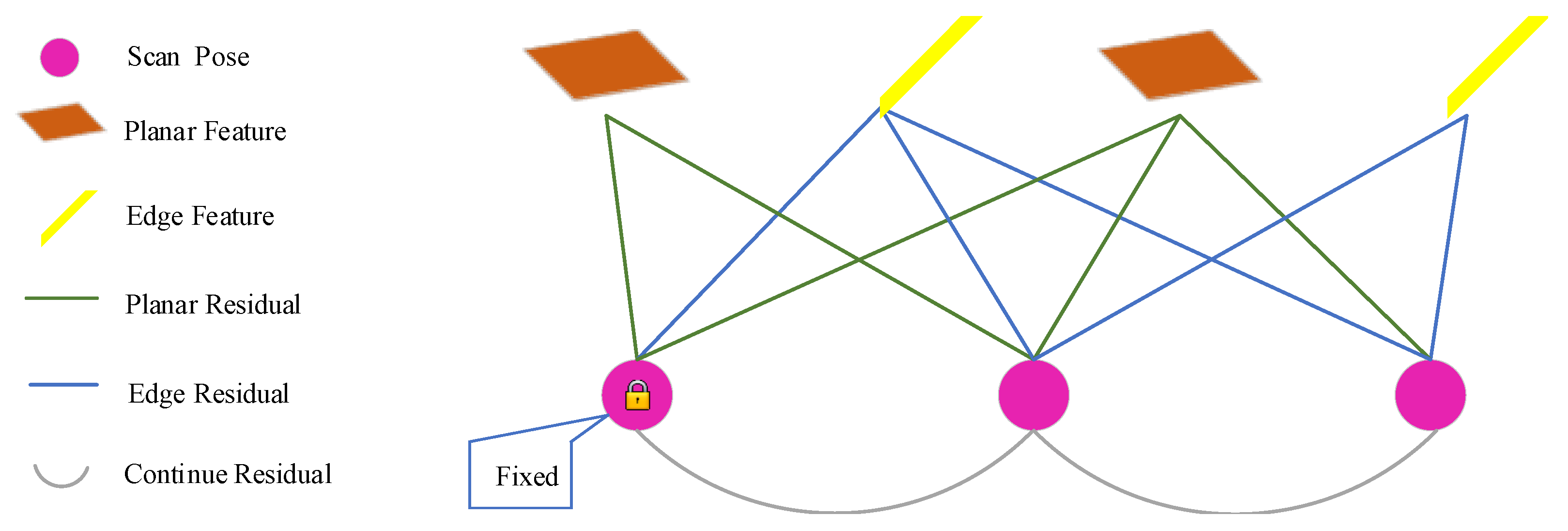
2.3.2. Bundle Adjustment with Direct Velocity Estimation
2.4. LiDAR Mapping
- The number of scans within the sliding window has not reached a preset value.
- The ratio of the number of successfully tracked planar map features to the number of newly created features is less than 2.
- The ratio of the number of successfully tracked edge map features to the number of newly created features is less than 1.5.
- The time difference between the most recent frame and the last keyframe is greater than a specified value.
2.4.1. Fast Computing for
3. Experimental Results
3.1. Evaluation Metrics
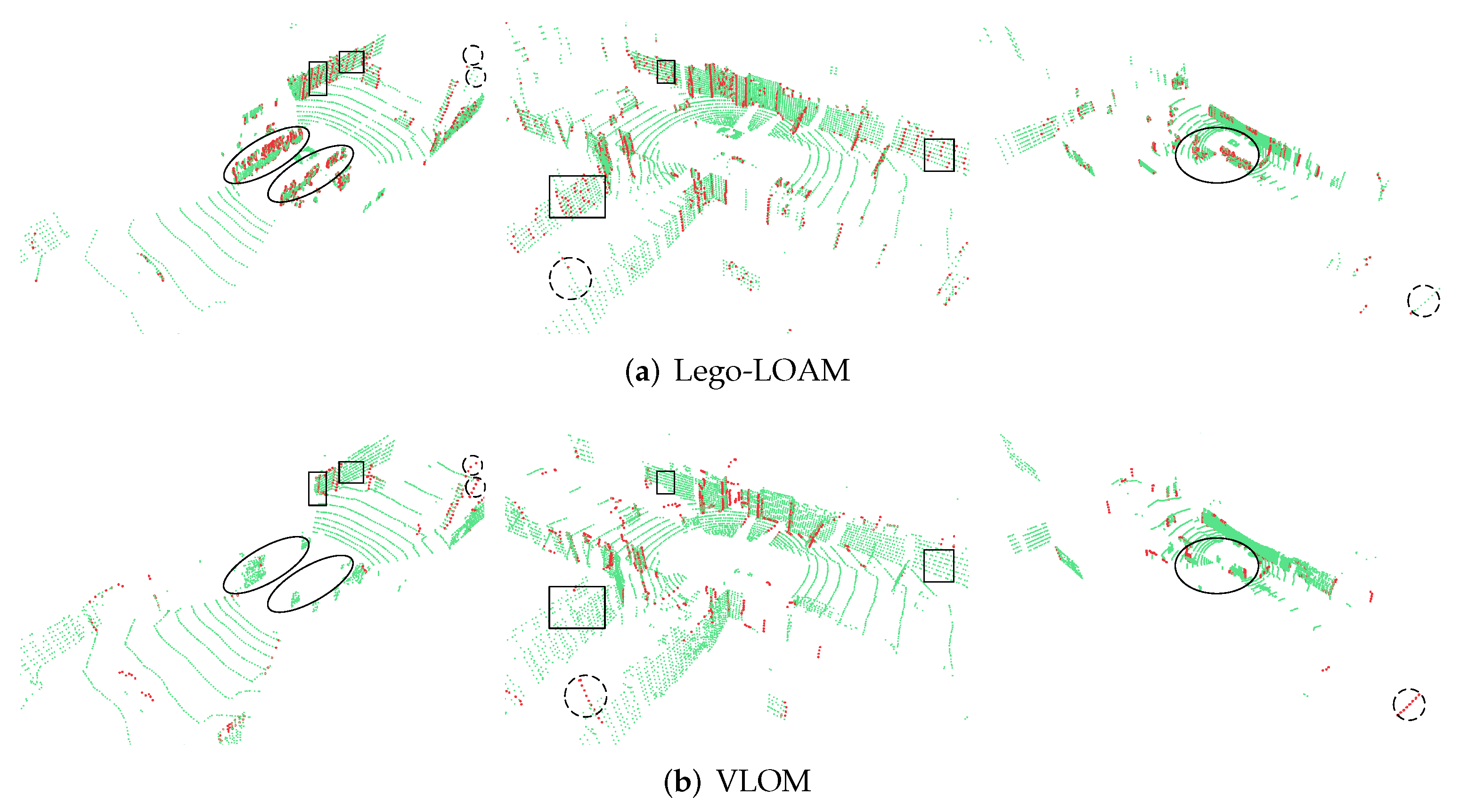
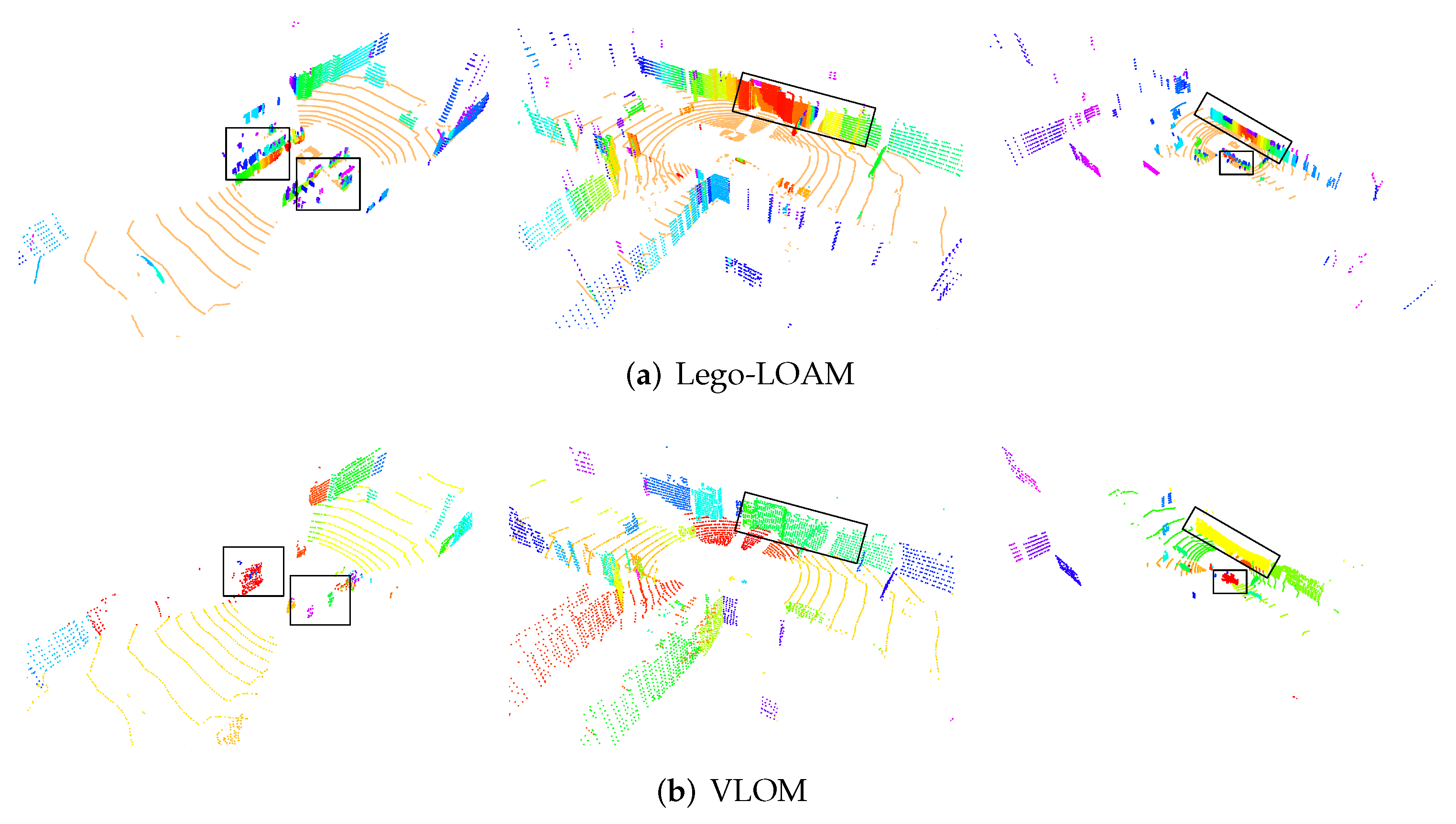
3.2. Feature Extraction Results
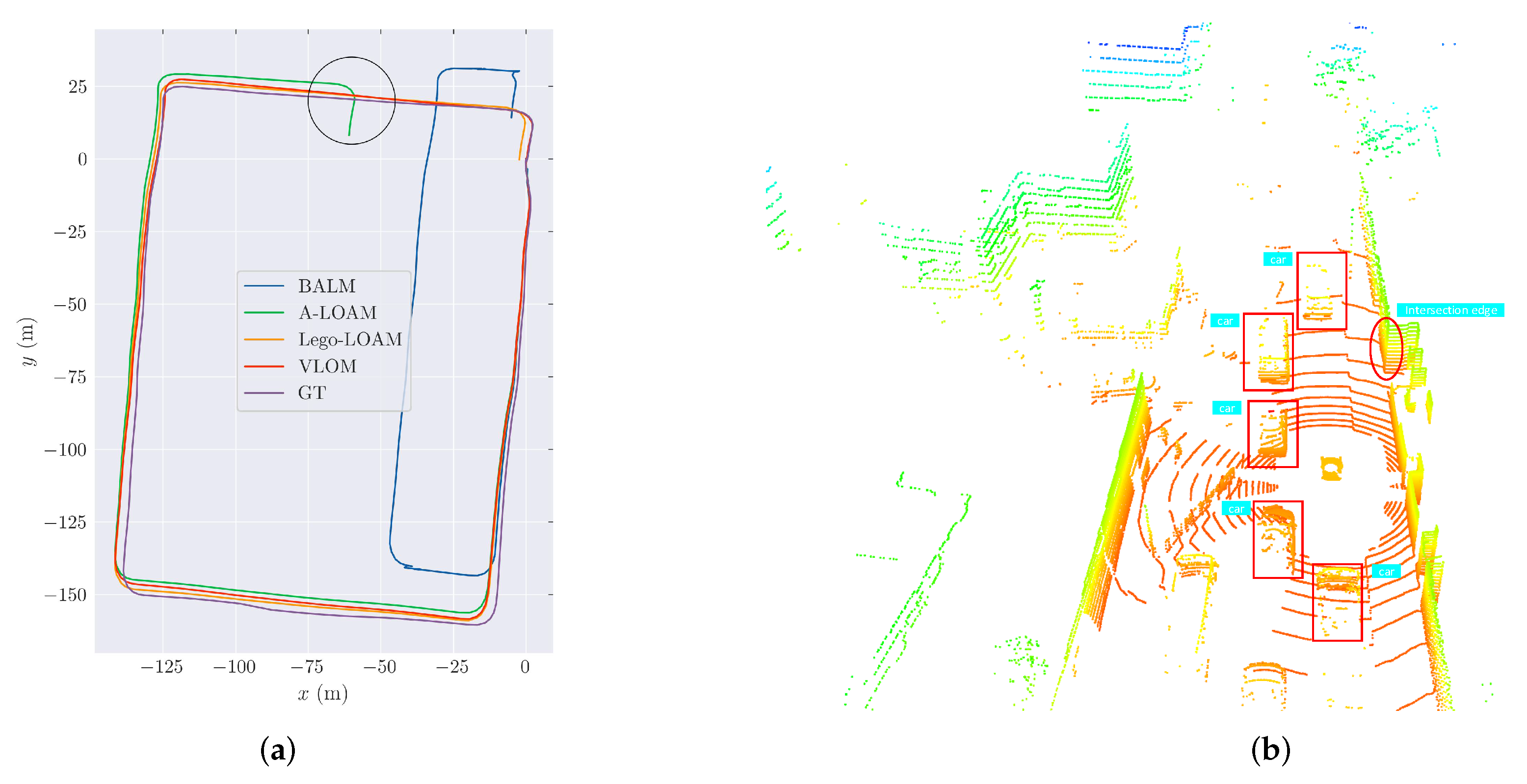
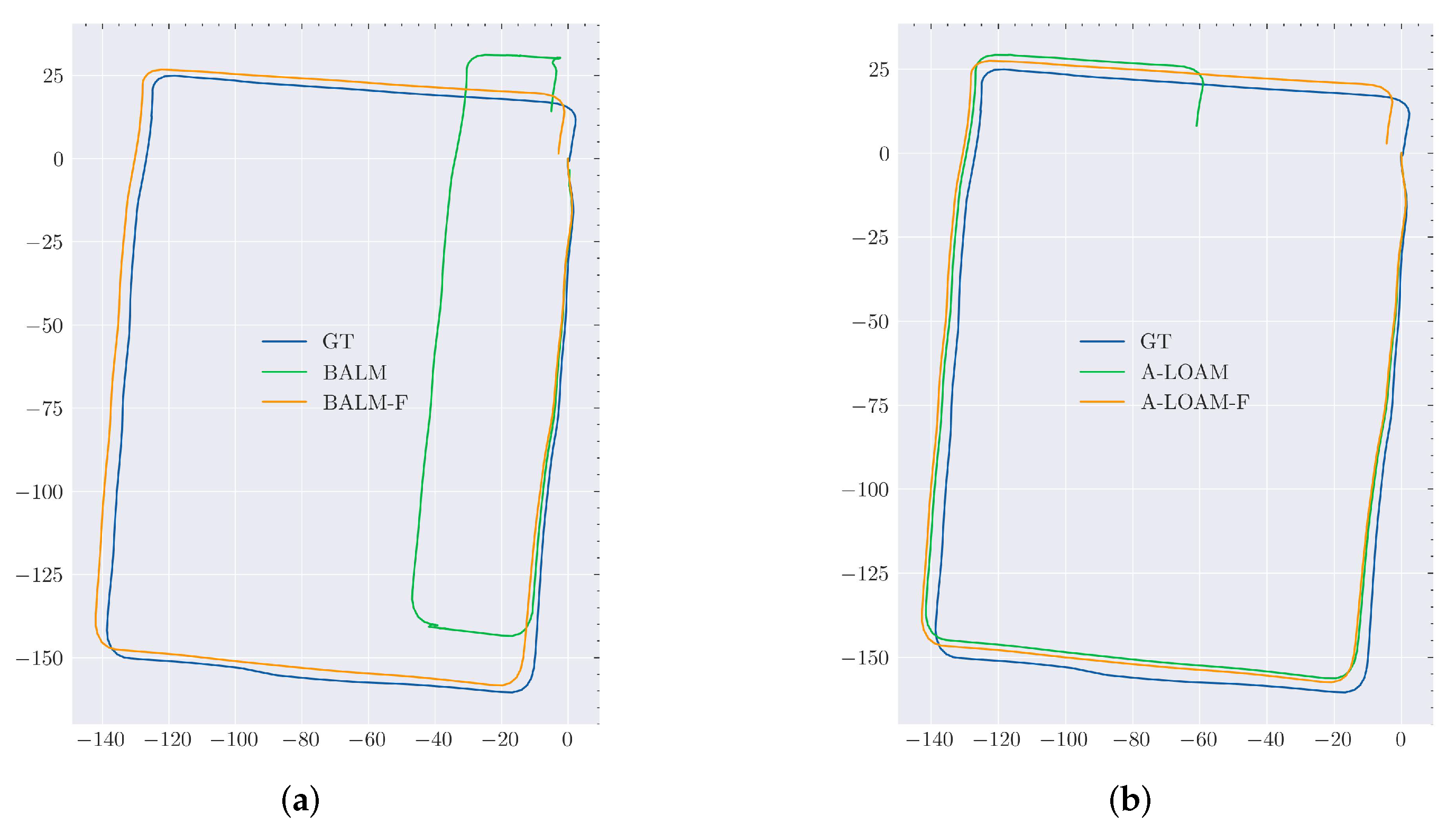
3.3. Evaluation on Velodyne HDL-32E
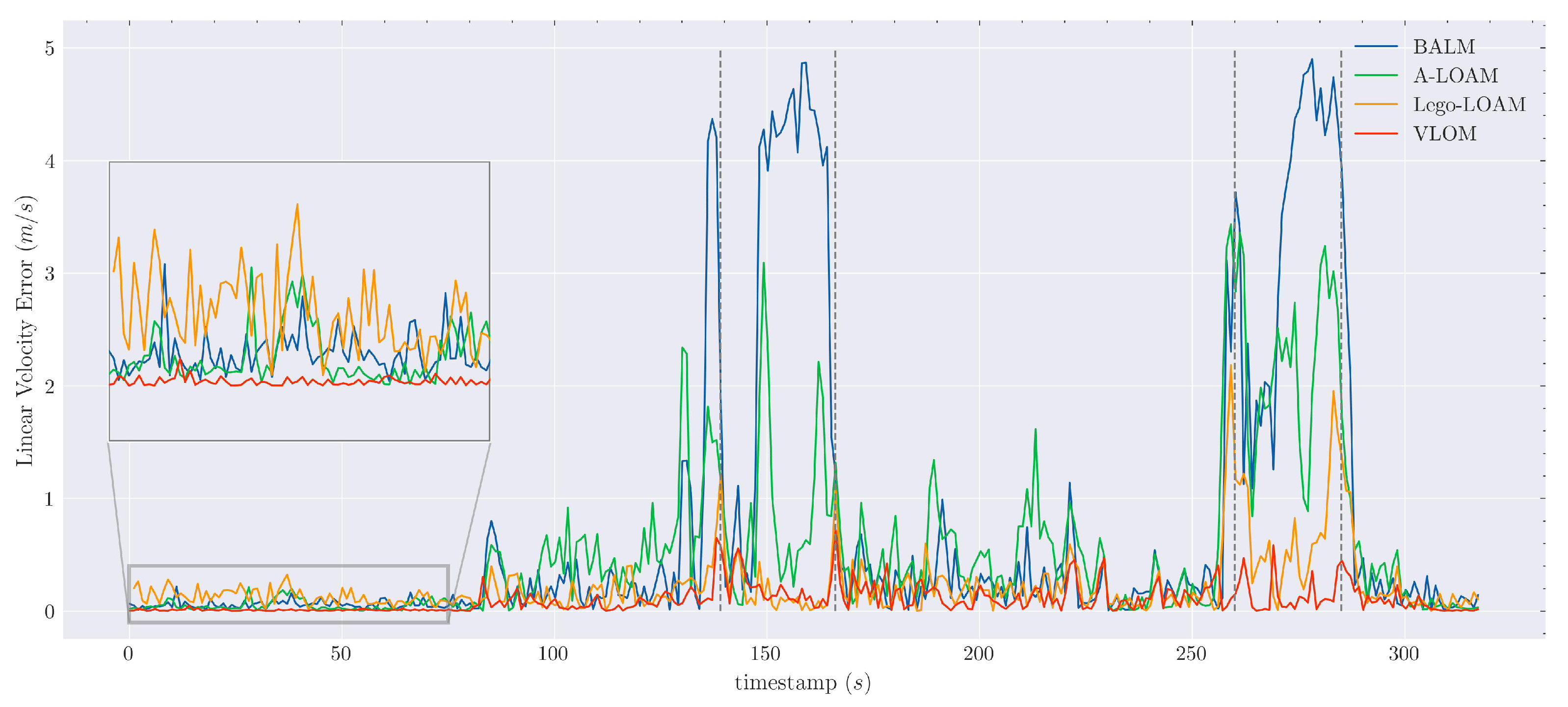
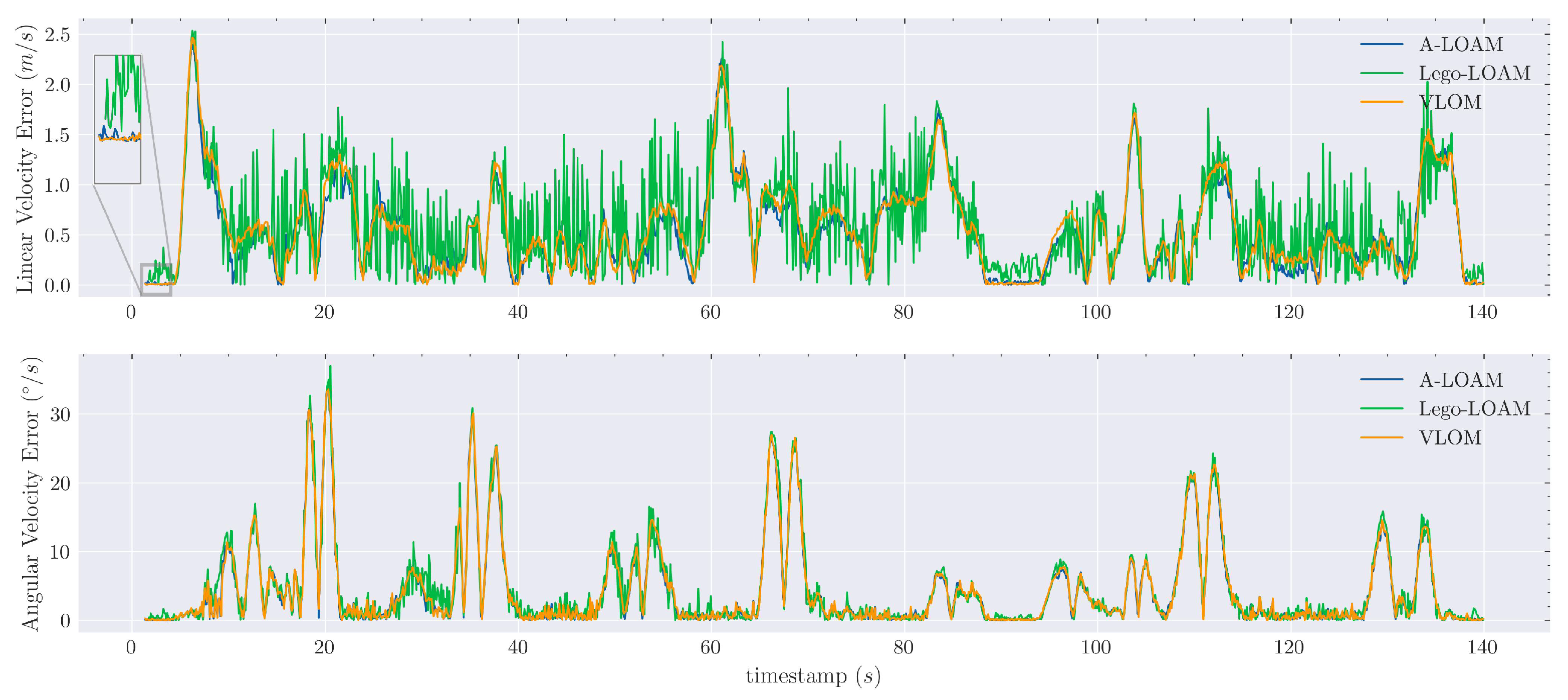
3.3.1. Evaluation of the Velocity Estimate
3.4. Evaluation on Livox Horizon
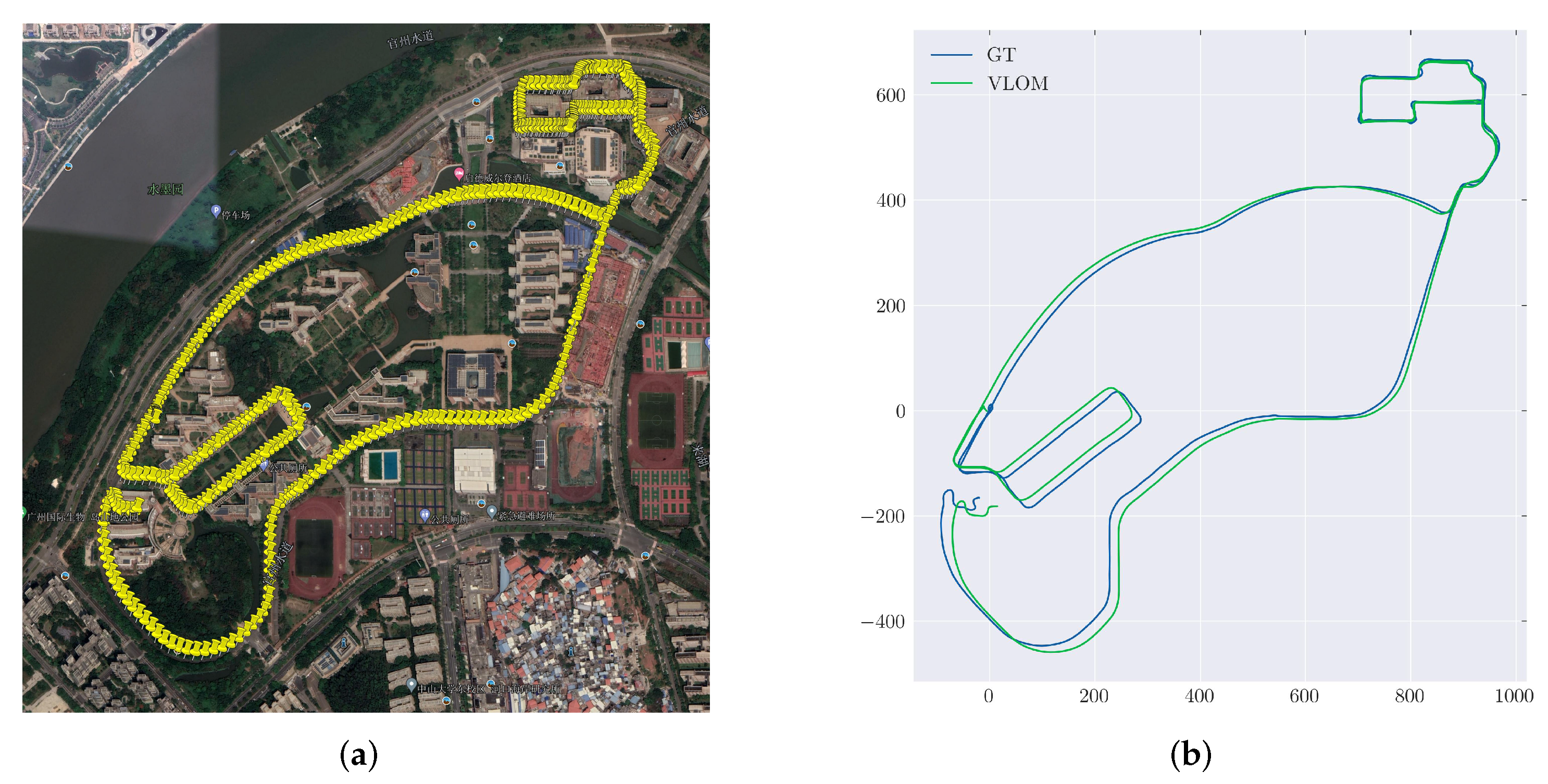
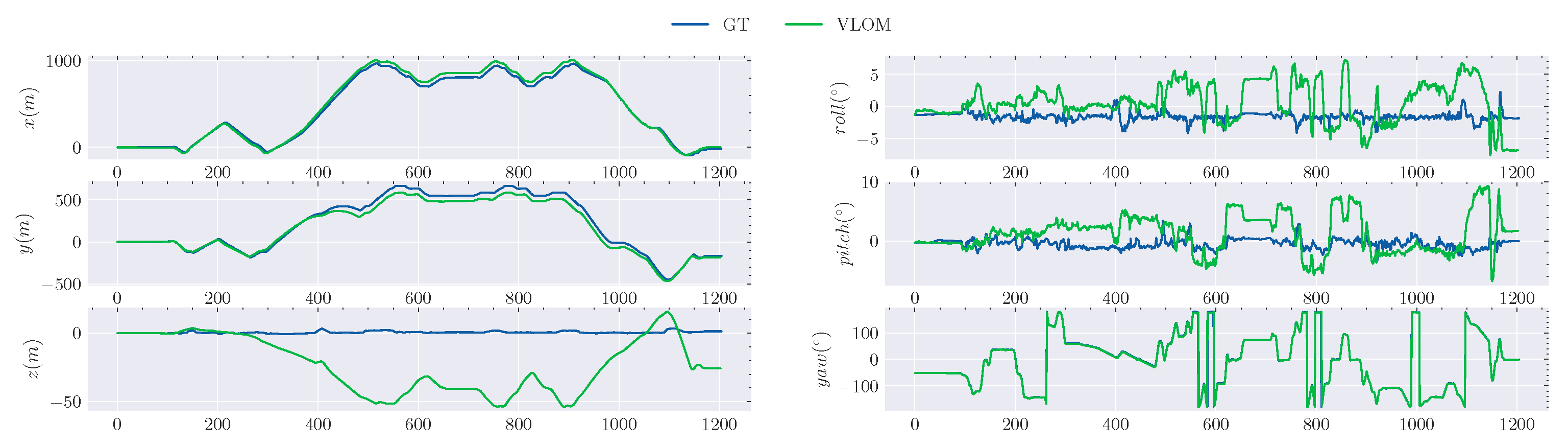
3.5. Evaluation on Our Campus Dataset
Evaluation of the Velocity Estimate
3.6. Evaluation of Runtime
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Barsan, I.A.; Liu, P.; Pollefeys, M.; Geiger, A. Robust Dense Mapping for Large-Scale Dynamic Environments. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, ICRA 2018, Brisbane, Australia, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7510–7517. [Google Scholar]
- Xu, C.; Liu, Z.; Li, Z. Robust Visual-Inertial Navigation System for Low Precision Sensors under Indoor and Outdoor Environments. Remote Sens. 2021, 13, 772. [Google Scholar] [CrossRef]
- Ji, K.; Chen, H.; Di, H.; Gong, J.; Xiong, G.; Qi, J.; Yi, T. CPFG-SLAM: A Robust Simultaneous Localization and Mapping based on LIDAR in Off-Road Environment. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium—IV 2018, Changshu, China, 26–30 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 650–655. [Google Scholar]
- Wang, W.; Liu, J.; Wang, C.; Luo, B.; Zhang, C. DV-LOAM: Direct Visual LiDAR Odometry and Mapping. Remote Sens. 2021, 13, 3340. [Google Scholar] [CrossRef]
- Besl, P.; McKay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Pomerleau, F.; Colas, F.; Siegwart, R.; Magnenat, S. Comparing ICP variants on real-world data sets. Auton. Robot. 2013, 34, 133–148. [Google Scholar] [CrossRef]
- Chen, Y.; Medioni, G. Object modelling by registration of multiple range images. Image Vis. Comput. 1992, 10, 145–155. [Google Scholar] [CrossRef]
- Park, S.Y.; Subbarao, M. An accurate and fast point-to-plane registration technique. Pattern Recogn. Lett. 2003, 24, 2967–2976. [Google Scholar] [CrossRef]
- Segal, A.; Hähnel, D.; Thrun, S. Generalized-ICP. In Proceedings of the Robotics: Science and Systems V, University of Washington, Seattle, WA, USA, 28 June–1 July 2009; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Deschaud, J.E. IMLS-SLAM: Scan-to-Model Matching Based on 3D Data. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation—ICRA 2018, Brisbane, Australia, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2480–2485. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE Computer Society: Piscataway, NJ, USA, 2012; pp. 3354–3361. [Google Scholar]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohli, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A.W. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the 10th IEEE International Symposium on Mixed and Augmented Reality—ISMAR 2011, Basel, Switzerland, 26–29 October 2011; IEEE Computer Society: Piscataway, NJ, USA, 2011; pp. 127–136. [Google Scholar]
- Qiu, D.; May, S.; Nüchter, A. GPU-Accelerated Nearest Neighbor Search for 3D Registration. In Proceedings of the Computer Vision Systems, 7th International Conference on Computer Vision Systems—ICVS 2009, Liège, Belgium, 13–15 October 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 194–203. [Google Scholar]
- Neumann, D.; Lugauer, F.; Bauer, S.; Wasza, J.; Hornegger, J. Real-time RGB-D mapping and 3-D modeling on the GPU using the random ball cover data structure. In Proceedings of the IEEE International Conference on Computer Vision Workshops—ICCV 2011 Workshops, Barcelona, Spain, 6–13 November 2011; IEEE Computer Society: Piscataway, NJ, USA, 2011; pp. 1161–1167. [Google Scholar]
- Biber, P.; Strasser, W. The normal distributions transform: A new approach to laser scan matching. In Proceedings of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems—IROS 2003, Las Vegas, NV, USA, 27 October–1 November 2003; IEEE: Piscataway, NJ, USA, 2003; pp. 2743–2748. [Google Scholar]
- Zhang, J.; Singh, S. LOAM: Lidar Odometry and Mapping in Real-time. In Proceedings of the Robotics: Science and Systems X, University of California, Berkeley, CA, USA, 12–16 July 2014. [Google Scholar]
- Shan, T.; Englot, B. LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems—IROS 2018, Madrid, Spain, 1–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4758–4765. [Google Scholar]
- Bogoslavskyi, I.; Stachniss, C. Fast range image-based segmentation of sparse 3D laser scans for online operation. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems—IROS 2016, Daejeon, Korea, 9–14 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 163–169. [Google Scholar]
- Zhou, P.; Guo, X.; Pei, X.; Chen, C. T-LOAM: Truncated Least Squares LiDAR-Only Odometry and Mapping in Real Time. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5701013. [Google Scholar] [CrossRef]
- Wang, J.; Li, J.; Shi, Y.; Lai, J.; Tan, X. AM3Net: Adaptive Mutual-learning-based Multimodal Data Fusion Network. IEEE Trans. Circuits Syst. Video Technol. 2022; early access. [Google Scholar] [CrossRef]
- Du, S.; Li, Y.; Li, X.; Wu, M. LiDAR Odometry and Mapping Based on Semantic Information for Outdoor Environment. Remote Sens. 2021, 13, 2864. [Google Scholar] [CrossRef]
- Chen, X.; Milioto, A.; Palazzolo, E.; Giguère, P.; Behley, J.; Stachniss, C. SuMa++: Efficient LiDAR-based Semantic SLAM. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems—IROS 2019, Macau, China, 3–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 4530–4537. [Google Scholar]
- Behley, J.; Stachniss, C. Efficient Surfel-Based SLAM using 3D Laser Range Data in Urban Environments. In Proceedings of the Robotics: Science and Systems XIV, Carnegie Mellon University, Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems—IROS 2019, Macau, China, 3–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 4213–4220. [Google Scholar]
- Wang, W.; You, X.; Zhang, X.; Chen, L.; Zhang, L.; Liu, X. LiDAR-Based SLAM under Semantic Constraints in Dynamic Environments. Remote Sens. 2021, 13, 3651. [Google Scholar] [CrossRef]
- Zhou, L.; Wang, S.; Kaess, M. π-LSAM: LiDAR Smoothing and Mapping With Planes. In Proceedings of the IEEE International Conference on Robotics and Automation—ICRA 2021, Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 5751–5757. [Google Scholar]
- Liu, Z.; Zhang, F. BALM: Bundle Adjustment for Lidar Mapping. IEEE Robot. Autom. Lett. 2021, 6, 3184–3191. [Google Scholar] [CrossRef]
- Hong, S.; Ko, H.; Kim, J. VICP: Velocity updating iterative closest point algorithm. In Proceedings of the IEEE International Conference on Robotics and Automation—ICRA 2010, Anchorage, AK, USA, 3–7 May 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1893–1898. [Google Scholar]
- Wang, H.; Wang, C.; Chen, C.L.; Xie, L. F-LOAM: Fast LiDAR Odometry and Mapping. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems—IROS 2021, Prague, Czech Republic, 27 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4390–4396. [Google Scholar]
- Zhou, L.; Koppel, D.; Kaess, M. LiDAR SLAM With Plane Adjustment for Indoor Environment. IEEE Robot. Autom. Lett. 2021, 6, 7073–7080. [Google Scholar] [CrossRef]
- Roriz, R.; Cabral, J.; Gomes, T. Automotive LiDAR Technology: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 1–16. [Google Scholar] [CrossRef]
- Lin, J.; Zhang, F. Loam livox: A fast, robust, high-precision LiDAR odometry and mapping package for LiDARs of small FoV. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation—ICRA 2020, Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 3126–3131. [Google Scholar]
- Wang, H.; Wang, C.; Xie, L. Lightweight 3-D Localization and Mapping for Solid-State LiDAR. IEEE Robot. Autom. Lett. 2021, 6, 1801–1807. [Google Scholar] [CrossRef]
- Li, K.; Li, M.; Hanebeck, U.D. Towards High-Performance Solid-State-LiDAR-Inertial Odometry and Mapping. IEEE Robot. Autom. Lett. 2021, 6, 5167–5174. [Google Scholar] [CrossRef]
- He, L.; Chao, Y.; Suzuki, K.; Wu, K. Fast connected-component labeling. Pattern Recognit. 2009, 42, 1977–1987. [Google Scholar] [CrossRef]
- Li, M.; Mourikis, A.I. Improving the accuracy of EKF-based visual-inertial odometry. In Proceedings of the IEEE International Conference on Robotics and Automation—ICRA 2012, St. Paul, MN, USA, 14–18 May 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 828–835. [Google Scholar]
- Liu, H.; Ye, Q.; Wang, H.; Chen, L.; Yang, J. A Precise and Robust Segmentation-Based Lidar Localization System for Automated Urban Driving. Remote Sens. 2019, 11, 1348. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, S.; Mierle, K. Ceres Solver. Available online: http://ceres-solver.org (accessed on 16 February 2022).
- Forster, C.; Carlone, L.; Dellaert, F.; Scaramuzza, D. On-Manifold Preintegration for Real-Time Visual–Inertial Odometry. IEEE Trans. Robot. 2017, 33, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.; Zhang, F. A fast, complete, point cloud based loop closure for LiDAR odometry and mapping. arXiv 2019, arXiv:1909.11811. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.P.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source robot operating system. In Proceedings of the IEEE International Conference on Robotics and Automation—ICRA 2009 Workshop, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Grupp, M. Evo: Python Package for the Evaluation of Odometry and SLAM. 2017. Available online: https://github.com/MichaelGrupp/evo (accessed on 16 February 2022).
- Wen, W.; Zhou, Y.; Zhang, G.; Fahandezh-Saadi, S.; Bai, X.; Zhan, W.; Tomizuka, M.; Hsu, L.T. UrbanLoco: A Full Sensor Suite Dataset for Mapping and Localization in Urban Scenes. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation—ICRA 2020, Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2310–2316. [Google Scholar]
- Qin, T.; Cao, S. Advanced Implementation of LOAM. Available online: https://github.com/HKUST-Aerial-Robotics/A-LOAM (accessed on 10 February 2022).
- Zhang, J.; Singh, S. Low-drift and Real-time Lidar Odometry and Mapping. Auton. Robot. 2017, 41, 401–416. [Google Scholar] [CrossRef]
- Livox. Advanced Implementation of LOAM. Available online: https://github.com/Livox-SDK/livox_horizon_loam (accessed on 11 February 2022).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | RRE () | RTE (m) | ||
|---|---|---|---|---|---|
| Mean Value | RMSE | Mean Value | RMSE | ||
| HK-Data20190117 | BALM | 0.894 | 1.586 | 0.801 | 1.740 |
| A-LOAM | 0.708 | 1.426 | 0.346 | 0.714 | |
| Lego-LOAM | 0.866 | 1.840 | 0.407 | 0.552 | |
| VLOM | 0.701 | 1.308 | 0.148 | 0.214 | |
| Dataset | BALM | LiHo | LiLi-OM | VLOM |
|---|---|---|---|---|
| Schloss-2 | 224.7/- | 14.43/8.100 | 5.580/4.410 | 3.012/- |
| Dataset | Method | RRE () | RTE (m) | ||
|---|---|---|---|---|---|
| Mean Value | RMSE | Mean Value | RMSE | ||
| OS | BALM | 1.210 | 2.515 | 16.85 | 435.3 |
| A-LOAM | 1.523 | 2.545 | 0.432 | 0.629 | |
| Lego-LOAM | 2.132 | 3.518 | 0.614 | 0.848 | |
| VLOM | 0.582 | 0.931 | 0.157 | 0.217 | |
| Feature | Odometry | Feature + Odometry | Mapping | ||
|---|---|---|---|---|---|
| Old | New | ||||
| HK-Data20190117 | 22.71 | 20.00 | 42.71 | 73.38 | 53.07 |
| Schloss-2 | 10.07 | 15.15 | 25.22 | 50.71 | 36.05 |
| OS | 42.39 | 28.50 | 70.89 | 48.27 | 44.14 |
| RS | 26.66 | 16.13 | 42.79 | 69.96 | 54.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jie, L.; Jin, Z.; Wang, J.; Zhang, L.; Tan, X. A SLAM System with Direct Velocity Estimation for Mechanical and Solid-State LiDARs. Remote Sens. 2022, 14, 1741. https://doi.org/10.3390/rs14071741
Jie L, Jin Z, Wang J, Zhang L, Tan X. A SLAM System with Direct Velocity Estimation for Mechanical and Solid-State LiDARs. Remote Sensing. 2022; 14(7):1741. https://doi.org/10.3390/rs14071741
Chicago/Turabian StyleJie, Lu, Zhi Jin, Jinping Wang, Letian Zhang, and Xiaojun Tan. 2022. "A SLAM System with Direct Velocity Estimation for Mechanical and Solid-State LiDARs" Remote Sensing 14, no. 7: 1741. https://doi.org/10.3390/rs14071741
APA StyleJie, L., Jin, Z., Wang, J., Zhang, L., & Tan, X. (2022). A SLAM System with Direct Velocity Estimation for Mechanical and Solid-State LiDARs. Remote Sensing, 14(7), 1741. https://doi.org/10.3390/rs14071741