1. Introduction
Papaver somniferum (opium poppy) is an annual herb cultivated in many parts of Asia. On the one hand, the
Papaver somniferum seed is an important food product, which contains amino acids such as glycine, alanine, tyrosine, phenylalanine, and aspartic acid, which are beneficial to health. It is widely used in making all kinds of baked foods and salads. On the other hand,
Papaver somniferum fruit extracts are the source of a variety of sedatives, such as morphine, thebaine, codeine, papaverine, and noscapine [
1]. In particular,
Papaver somniferum fruit is the major raw material for the production of opium. Thus, it is stipulated by law in many countries and regions that the cultivation and sales of
Papaver somniferum must be authorized by the government and are subject to official supervision throughout the entire industry chain.
Despite stringent legal constraints, there are still people who cultivate
Papaver somniferum in private fields or yards without authorization, and then sell and eat
Papaver somniferum illegally in certain countries and regions. Illicit
Papaver somniferum cultivation causes potential harm to the social order. Once
Papaver somniferum related products are out of regulation and flow into the market, they pose a serious threat to people’s physical and mental health. Hence, it has become an urgent issue for local regulatory authorities to investigate illicit
Papaver somniferum cultivation. In view of this, the rapid and accurate detection of illicit
Papaver somniferum cultivation sites is an important means of combating such crimes. Nakazawa et al. [
2] identified the differences in spectral characteristics between opium poppy and other crops by utilizing hyperspectral imaging and developed a method to detect illicit opium poppy fields based on hyperspectral data. However, hyperspectral instruments are generally expensive, so the rapid detection of opium poppy from remote-sensing images is not the first choice for researchers. At present, the use of unmanned aerial vehicle (UAV) equipped with high-definition cameras to inspect illicit
Papaver somniferum cultivation is deemed an accurate and effective approach. Zhou et al. [
3] and Wang et al. [
4] realized the detection of low-altitude remote sensing opium poppy images by applying a target detection algorithm. Nevertheless, in large-scale high-resolution remote sensing images, the accurate detection of opium poppy is actually a very challenging task due to a variety of problems (e.g., blurred images due to natural shooting conditions; existence of easily-confused objects such as green onion, white flowers, wine bottle, plastic toy, green plastic film, etc.; complex backgrounds; etc.) Currently, the complete process of opium poppy screening and elimination is as follows: (1) after the UAV captures the images, anti-drug experts will conduct a naked eye search on a large number of collected images to label and record the suspicious targets in the images; (2) the relevant government departments will collect coordinate points for the suspicious targets and then visit the sites to uproot the
Papaver somniferum plants. Although this method can accurately locate opium poppy cultivation sites, it has many obvious shortcomings. For example, the number of images collected by UAV can be incredibly huge, which is often counted on the order of terabytes. Screening of these images relying on the naked eye is extremely laborious and time-consuming, and the accuracy of the results is highly dependent on the proficiency and skills of the inspectors.
With the rapid development of artificial intelligence, target detection algorithms have been successfully applied to various fields such as medicine [
5], agriculture [
6], forestry [
7], physics [
8], and remote sensing communities [
9].The target detection algorithm can be traced back to the cascade classifier framework proposed by in 2001 [
10], which brought target detection into reality for the first time. In 2005, Dalal N. and Triggs B [
11] achieved human detection using Histogram of Gradients (HOG) and Support Vector Machines (SVM). Early scholars mainly relied on expert experience to describe and extract the shape, color, texture, and other features of objects and then to implement target detection using artificial feature extraction algorithms. Until 2012, Krizhevsky [
12] innovatively applied AlexNet to the field of image classification [
13]. Since then, researchers have turned their attention from artificial feature extraction methods to deep learning methods. The core of deep learning lies in the fact that the feature extraction network can realize automatic target feature extraction, which greatly reduces the difficulty and improves the accuracy and efficiency of target detection.
Target detection methods based on deep learning can be generally divided into one-stage methods and two-stage methods. The two-stage method is implemented in the following steps: (1) select region proposals from the input images that may contain the target object; (2) classify and perform location regression on the region proposals to obtain the detection results. The one-stage method omits the step of generating region proposals and directly computes anchor boxes of different sizes and aspect ratios in the input images. The commonly used two-stage detectors include R-CNN [
14], Fast R-CNN [
15], Faster R-CNN [
16], Mask R-CNN [
17], R-FCN [
18], and Cascade R-CNN [
19]. The one-stage target detection algorithms mainly include the SSD [
20,
21,
22,
23,
24] series and the YOLO series [
25,
26,
27,
28]. Compared with two-stage detectors, the inference speed of one-stage detectors is generally faster.
The target detection technology based on deep learning has increasingly wide applications in the field of remote sensing. Xu et al. [
29] proposed an improved YOLOv3 algorithm by using DenseNet (Densely Connected Network) to enhance the network performance. On the basis of the original YOLOv3 network, the improved method increased the detection scale to 4 and thereby improved the mAP from 77.10% to 88.73% on the RSOD remote sensing dataset. Especially, for the detection of small targets such as aircrafts, the mAP was increased by 12.12%, suggesting that large-scale detection mechanism can help improve the accuracy of small target detection to a certain extent. By comparing the detection performance between one-stage and two-stage detectors on a single UAS-based image, Ezzy et al. [
30] concluded that the self-trained YOLOv3 detector could achieve accurate small target detection of rodent caves. In view of the difficulty in small target detection, researchers have made consistent efforts to improve the network structure from different perspectives so as to increase the accuracy of small target detection [
31]. Miura et al. [
32] utilized an improved CNN network and the post-earthquake aerial images in Japan to detect collapsed buildings, non-collapsed buildings, and buildings covered with blue tarps. Shi et al. [
33] proposed to use the improved classic YOLOv4 model to quickly detect collapsed buildings from aerial images after the Wenchuan and Beichuan earthquakes in China and used the K-means algorithm to cluster the optimal anchor boxes from the images. By improving the CSPDarkNet53 module and the loss function in the original network, the proposed method effectively increased the average precision of collapsed building detection. Zhu et al. [
34] improved the YOLOv5 algorithm based on the attention mechanism and designed a pyramid-based method for boulder detection in planetary images. The proposed network was equipped with the Convolutional Block Attention Module (CBAM) and the Efficient Channel Attention Network (ECA-Net) to improve the overall detection performance. Yan et al. [
35] proposed to use the improved YOLOv5s model to distinguish apples that can be grasped from those that cannot be grasped. Specifically, the authors upgraded the CSP module to CSP-2 module and inserted the SE module in the attention mechanism network into the modified backbone network. The improved model was more accurate, faster, and lighter than the original YOLOv5s and other detection models. Mehdi et al. [
36] improved yolov3 to detect of hazardous and noxious substances of vital transportation by sea. It can be seen from the research status described above that, in the field of remote sensing image detection, the one-stage YOLO series is more in line with the real-time and accurate detection requirements at the current stage.
YOLOv5 is the latest version of the YOLO series of networks and is also the most advanced network of the one-stage method. YOLOv5 treats target detection as a regression problem so as to perform localization and classification concurrently to achieve fast and accurate detection. Wang et al. [
4] proposed an improved YOLOv3 algorithm, which realized fast and accurate low-altitude remote sensing opium poppy image detection. Their algorithm effectively improved the accuracy of opium poppy detection and reduced the parameter size of the model, but they did not provide a good solution for distinguishing easily confused plants and objects and for the accurate detection of opium poppy cultivation. Hu et al. [
37] relied on the two-stage idea to realize the identification of individual cows. First, the YOLO algorithm was used to locate the parts of each cow of interest, and then the segmented parts were sent to three convolutional neural networks for feature extraction. After the fusion of parts features, the SVM was used to achieve individual cow identification.
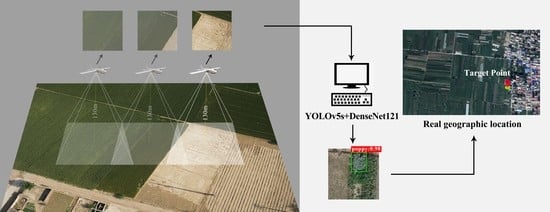
In order to address the problems of labor intensity and time-consuming of manual screening opium poppy inspection images, this paper proposes a two-stage automatic detection method of “detection + classification”. YOLOv5 was chosen as the first-stage detector in our study considering its characteristics of high detection accuracy and real-time performance, for the purpose of improving the recall and detection speed. Then, the detection results from the first stage were input into the second stage network for further classification, so as to improve the overall accuracy of Papaver somniferum detection.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
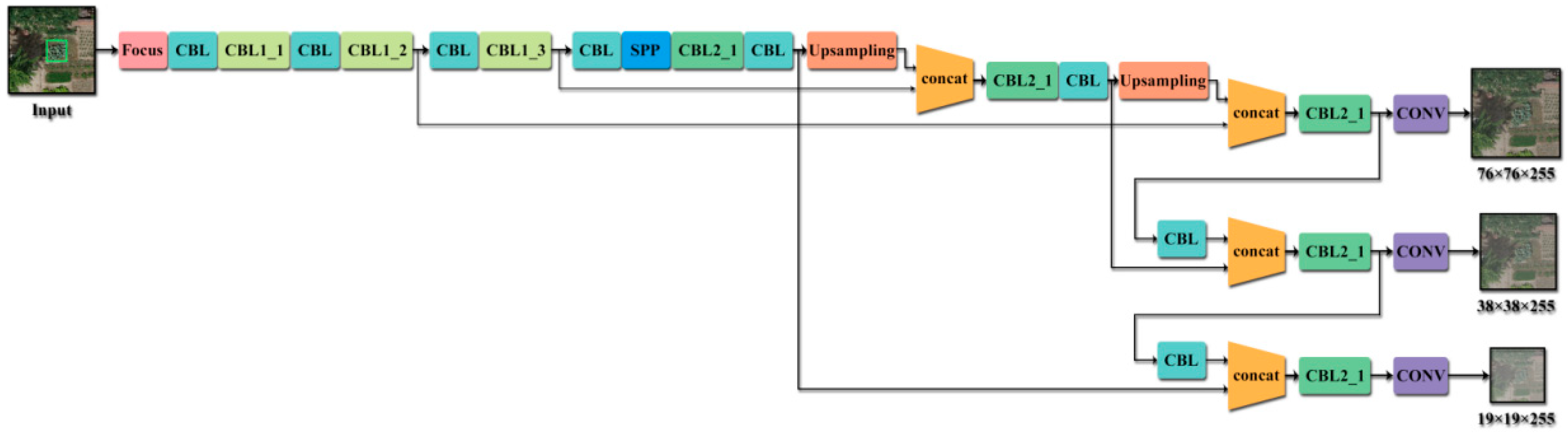{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



































