1. Introduction
Extracting buildings is of great significance for applications such as urban planning, land use change, and environmental monitoring [
1,
2], particularly for buildings in emergency shelters. This process helps improve disaster prevention and mitigation and other management capabilities [
3]. An emergency shelter is a safe place for emergency evacuation and temporary dwelling for residents in response to sudden disasters such as earthquakes [
4]. These temporary facilities mainly include open spaces, such as parks, green spaces, stadiums, playgrounds, and squares [
5]. When disasters occur, buildings are prone to collapse and can injure people [
6]. Some areas cannot be used for evacuation. Therefore, extracting buildings from emergency shelters has important guiding relevance in evaluating the emergency evacuation capabilities of shelters.
In the early days, the building footprint in emergency shelters was mainly obtained by manual measurement. The spatial resolution of satellite remote sensing images has reached the submeter level with the development of Earth observation technology. High-resolution remote sensing images have the advantages of rich ground object information, multiple imaging spectral bands, and short revisit time [
7,
8,
9]. Thus, these images can accurately show the details of urban areas, providing critical support for extracting buildings. Despite the detailed information that these images provide, spectral errors, such as “intra-class spectral heterogeneity” and “inter-class spectral homogeneity”, exist [
10]. These errors increase the difficulty of building extraction. Moreover, buildings have various features, such as shapes, materials, and colors, complicating the quick and accurate extraction of buildings from high-resolution remote sensing images [
11,
12].
The traditional methods of extracting buildings based on remote sensing images mainly include image classification based on pixel features and object-oriented classification. The extraction methods based on pixel features mainly rely on the information of a single pixel for classification; these methods include support vector machine and morphological building index, which are relatively simple and efficient to use [
13]. However, they ignore the relationship between adjacent pixels and lack the use of spatial information of ground objects. They are prone to “salt and pepper noise”, resulting in the blurred boundaries of the extracted buildings [
14]. Based on object-oriented extraction methods, pixels are clustered according to relative homogeneity to form objects for classification, utilizing spatial relationships or context information to obtain good classification accuracy [
15]. However, classification accuracy largely depends on image segmentation results, and the segmentation scale is difficult to determine; thus, problems such as oversegmentation or undersegmentation are prone to occur [
16], resulting in complex object-oriented classification methods.
Deep learning has a strong generalization ability and efficient feature expression ability [
17]. It bridges the semantic gap, integrates feature extraction and image classification, and avoids preprocessing, such as image segmentation, through the hierarchical end-to-end construction method. It can also automatically perform hierarchical feature extraction on massive raw data, reduce the definition of feature rules by humans, lessen labor costs, and solve problems such as the inaccurate representation of ground objects caused by artificially designed features [
18,
19]. With the rapid development of artificial intelligence technology in recent years, deep learning has played a prominent role in image processing, change detection, and information extraction. It has been widely used in building extraction, and the extraction method has been continuously improved.
Convolutional neural network (CNN) is the most widely used method for structural image classification and change detection [
20]. CNN can solve the problems caused by inaccurate empirically designed features by eliminating the gap between different semantics; it can also learn feature representations from the data in the hierarchical structure itself [
21], improving the accuracy of building extraction. Tang et al. [
22] proposed to use the vector “capsule” to store building features. The encoder extracts the “capsule” from the remote sensing image, and the decoder calculates the target building, which not only realizes the effective extraction of buildings, but also has good generalization. Li et al. [
23] used the improved faster regions with a convolutional neural network (R-CNN) detector; the spectral residual method is embedded into the deep learning network model to extract the rural built-up area. Chen et al. [
24] used a multi-scale feature learning module in CNN to achieve better results in extracting buildings from remote sensing images. However, CNN requires ample storage space, and repeated calculations lead to low computational efficiency. Moreover, only some local features can be extracted, limiting the classification performance.
Fully convolutional neural network (FCN) is an improvement based on CNN. It uses a convolutional layer to replace the fully connected layer after CNN; it also realizes end-to-end semantic segmentation for the first time [
25]. FCN fuses deep and shallow features of the same resolution to recover the spatial information lost during feature extraction [
26]. It is widely used in image semantic segmentation. Bittner et al. [
27] proposed an end-to-end FCN method based on the automatic extraction of relevant features and dense image classification. Their proposed method effectively combines spectral and height information from different data sources (high-resolution imagery and digital surface model, DSM). Moreover, the network increases additional connections, providing access to high-frequency information for the top-level classification layers and improving the spatial resolution of building outline outputs. Xu et al. [
28] pointed out that the FCN model can detect different classes of objects on the ground, such as buildings, curves of roads, and trees, and predict their shapes. Wei et al. [
29] introduced multiscale aggregation and two postprocessing strategies in FCN to achieve accurate binary segmentation. They also proposed a specific, robust, and effective polygon regularization algorithm to convert segmented building boundaries into structured footprints for high building extraction accuracy. Although FCN has achieved good results in building extraction, it does not consider the relationship between pixels. It also focuses mainly on global features and ignores local features, resulting in poor prediction results and a lack of edge information. However, FCN is symbolic in the field of image semantic segmentation, and most of the later deep learning network models are improved and innovated based on it.
The UNet network model belongs to one of the FCN variants. It adds skip connections between the encoding and decoding of FCN. The decoder can receive low-level features from the encoder, form outputs, retain boundary information, fuse high- and low-level semantic features of the network, and achieve good extraction results through skip connections [
30]. In recent years, many image segmentation algorithms have used the UNet network as the original segmentation network model, and these algorithms have been fine-tuned and optimized on this basis. Ye et al. [
31] proposed RFN-UNet, which considers the semantic gap between features at different stages. It also uses an attention mechanism to bridge the gap between feature fusions and achieves good building extraction results in public datasets. Qin et al. [
32] proposed a network structure U
2Net with a two-layer nested UNet. This model can capture a large amount of context information and has a remarkable effect on change detection. Peng et al. [
33] used UNet++ as the backbone extraction network and proposed a differentially enhanced dense attention CNN for detecting changes in bitemporal optical remote sensing images. In order to improve the spatial information perception ability of the network, Wang et al. [
34] proposed a building method, B-FGC-Net, with prominent features, global perception, and cross-level information fusion. Wang et al. [
35] combined UNet, residual learning, atrous spatial pyramid pooling, and focal loss, and the ResUNet model was proposed to extract buildings. Based on refined attention pyramid networks (RAPNets), Tian et al. [
36] embedded salient multi-scale features into a convolutional block attention module to improve the accuracy of building extraction.
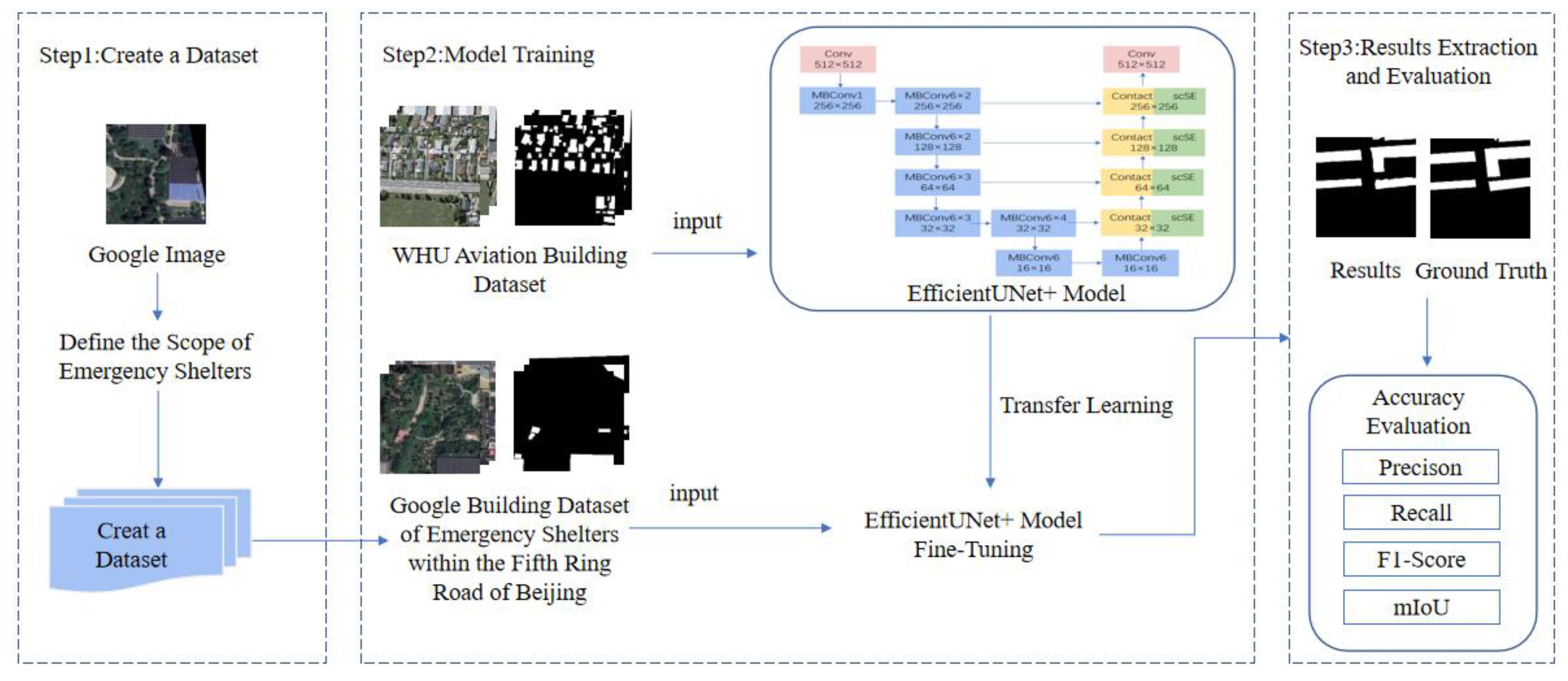
Most of the above methods of extracting buildings are performed on standard public datasets or large-scale building scenarios. They rarely involve buildings in special scenarios, such as emergency shelters. The volume and footprint of buildings in emergency shelters are generally small. For such small buildings, UNet [
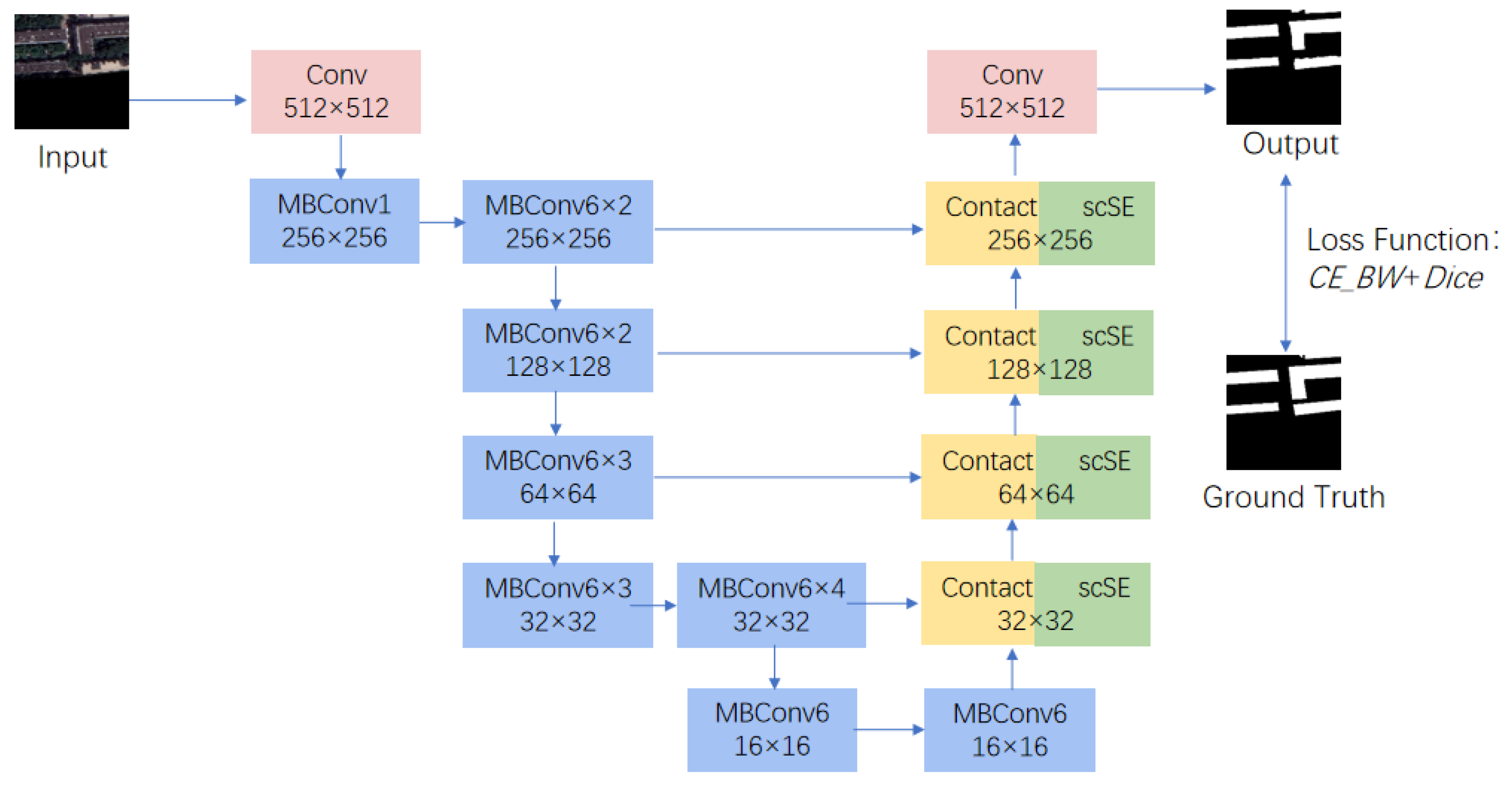
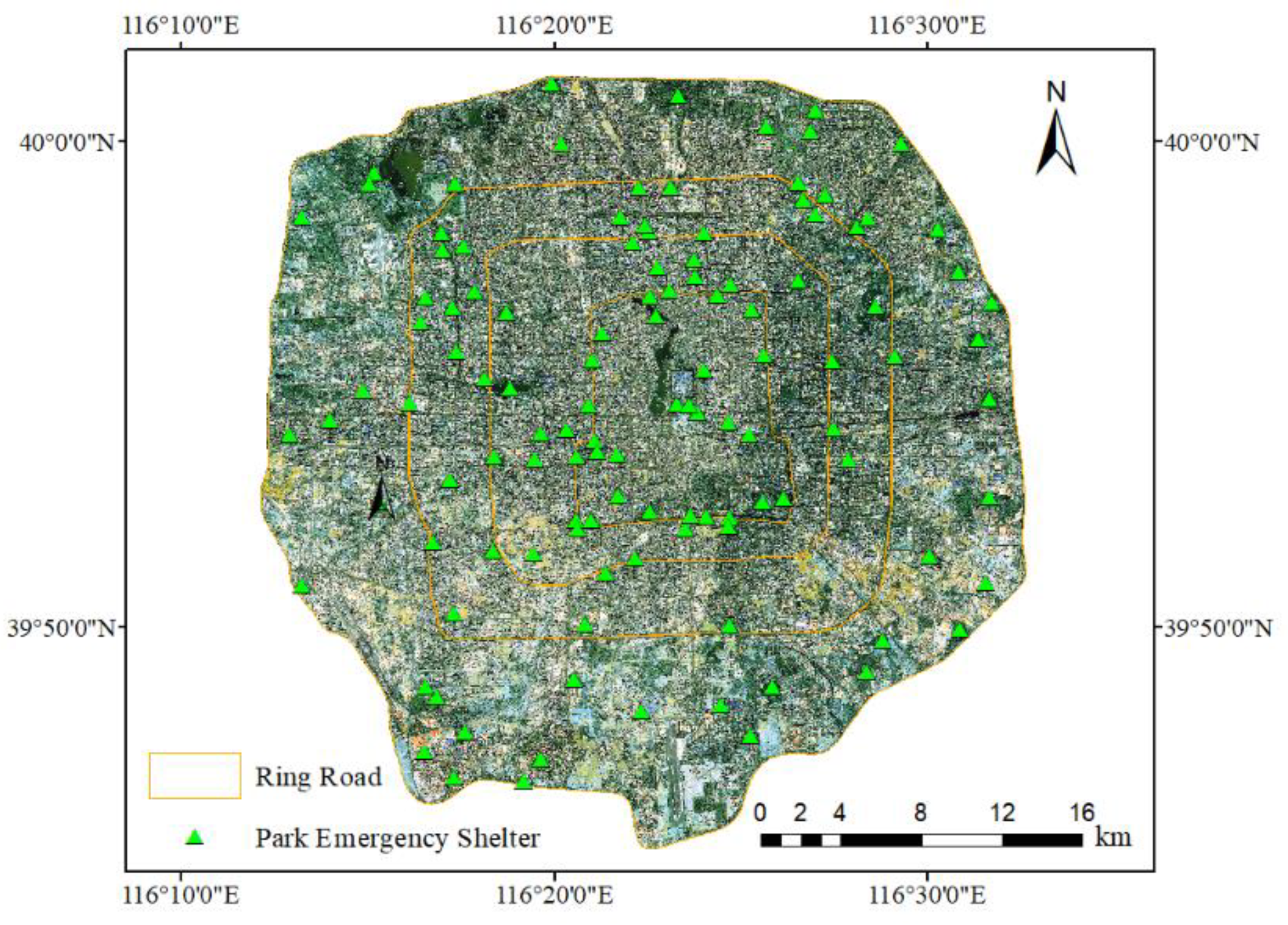
30] structure can integrate high- and low-level features effectively and restore fine edges, thereby reducing the problems of missed and false detection and blurred edges during building extraction. We use UNet as the overall framework to design a fully convolutional neural network, namely, the EfficientUNet+ method. We verify this method by taking an emergency shelter within the Fifth Ring Road of Beijing as an example. The innovations of the EfficientUNet+ method are as follows:
- (1)
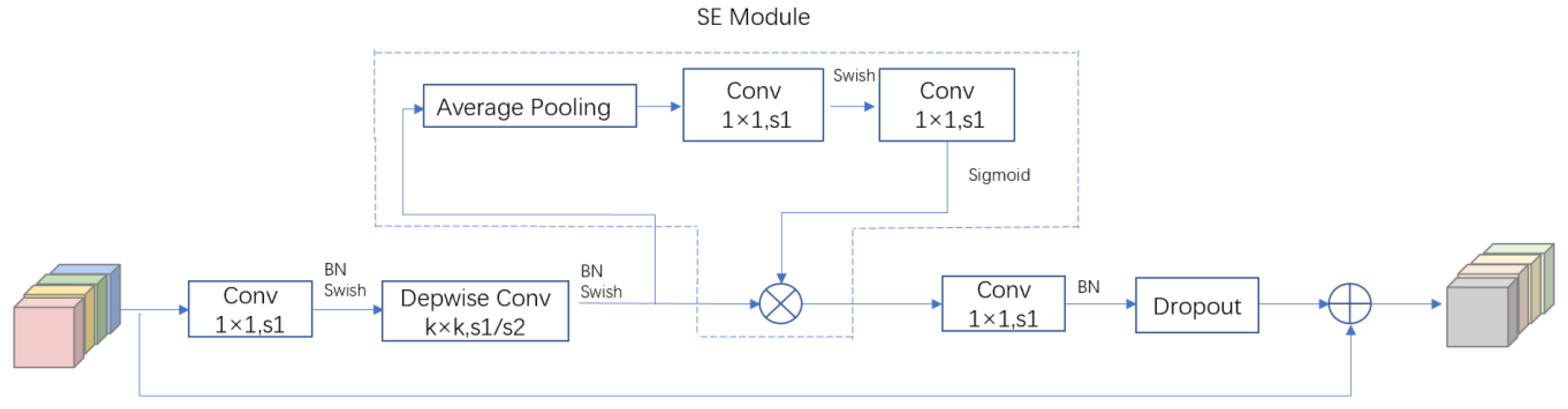
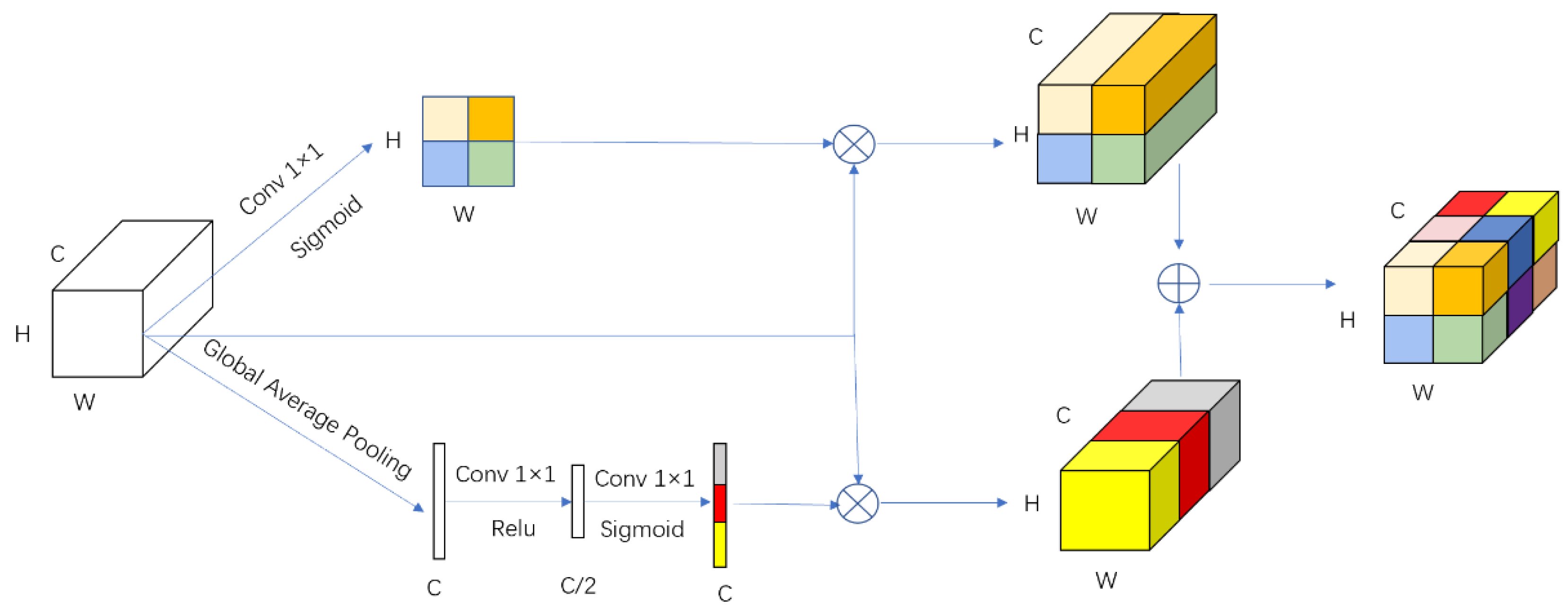
We use EfficientNet-b0 as the encoder to trade off model accuracy and speed. The features extracted by the model are crucial to the segmentation results; we also embed the spatial and channel squeeze and excitation (scSE) in the decoder to achieve positive correction of features.
- (2)
The accurate boundary segmentation of positive samples in the segmentation results has always been a challenge. We weight the building boundary area with the cross-entropy function and combine the Dice loss to alleviate this problem from the perspective of the loss function.
- (3)
Producing a large number of samples for emergency shelters within the Fifth Ring Road of Beijing is time-consuming and labor-intensive. We use the existing public WHU aerial building dataset for transfer learning to achieve high extraction accuracy using a few samples. It can improve the computational efficiency and robustness of the model.
This paper is organized as follows:
Section 2 “Methods” introduces the EfficientUNet+ model overview, which includes EfficientNet-b0, scSE module, loss function, and transfer learning;
Section 3 “Experimental Results” presents the study area and data, experimental environment and parameter settings, and accuracy evaluation and experimental results of the EfficientUNet+ method;
Section 4 “Discussion” validates the effectiveness of the proposed method through comparative experiments and ablation experiments;
Section 5 “Conclusion” presents the main findings of this study.
5. Conclusions
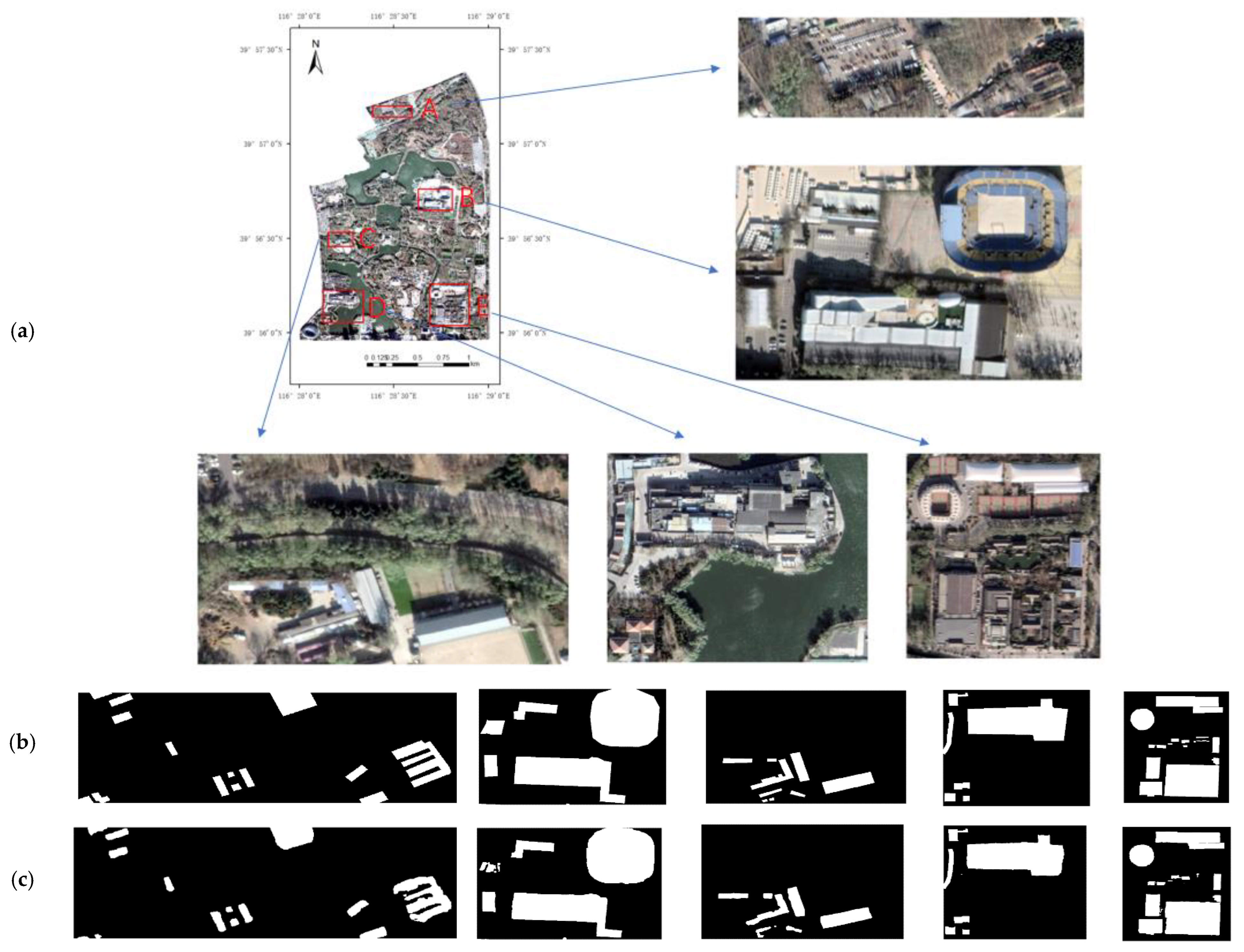
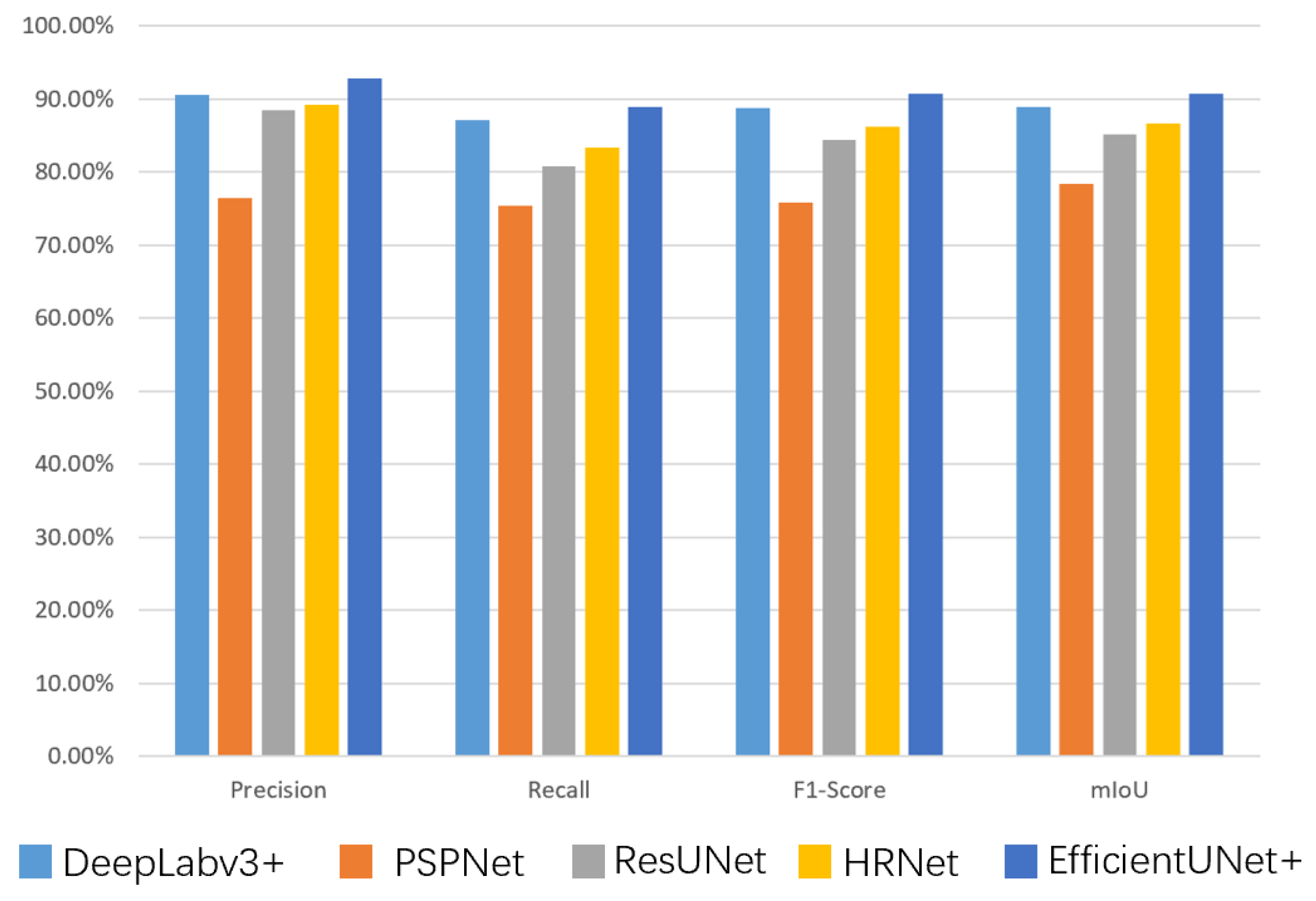
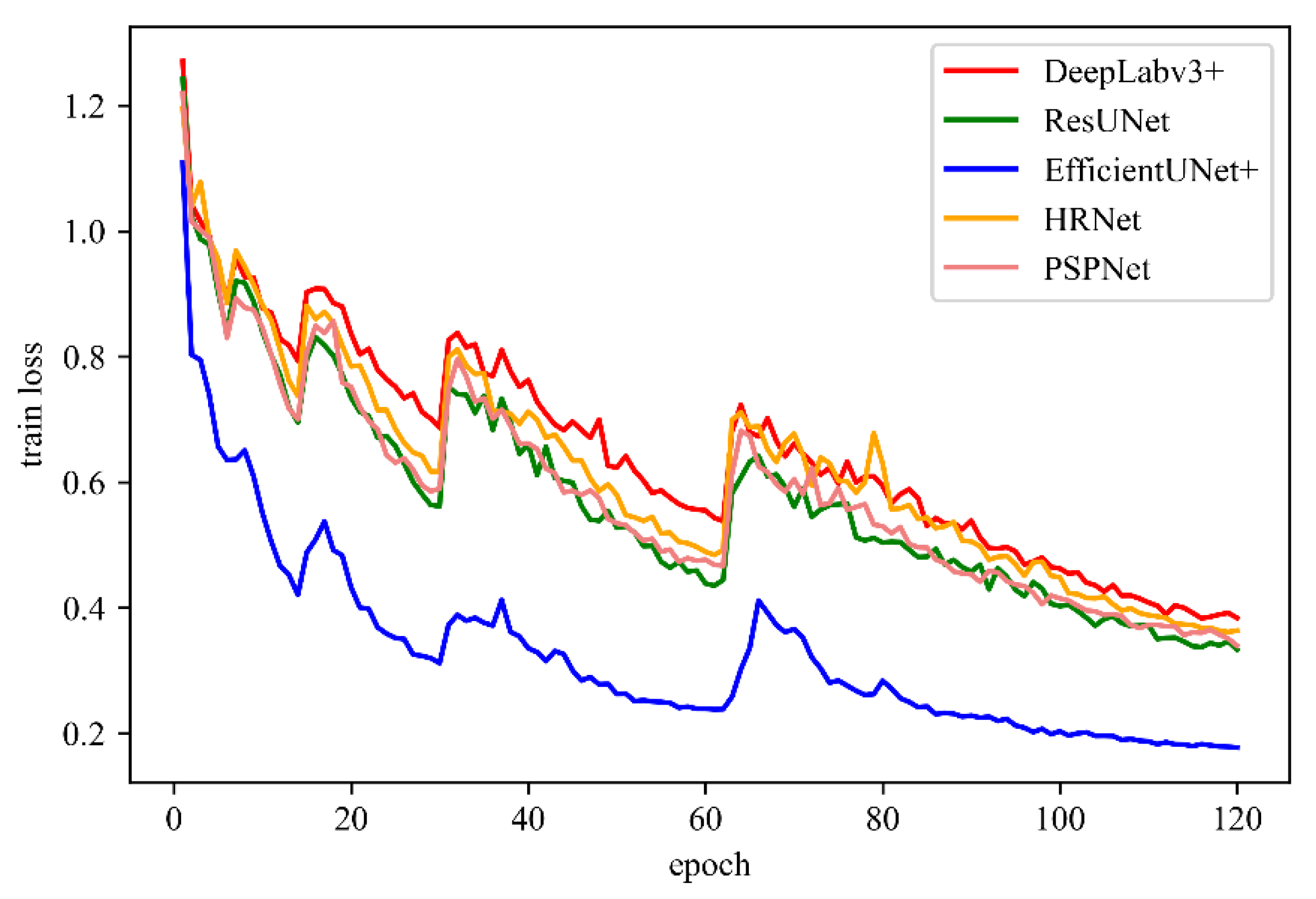
Buildings in special scenes, such as emergency shelters, are generally small. The extraction of such small buildings is prone to problems, such as integrity, misrepresentation and omission, and blurred boundaries. An improved deep learning method, EfficientUNet+, is proposed in this study, taking the emergency shelters within the Fifth Ring Road of Beijing as the research area. The effectiveness of the proposed method to extract buildings is verified. The following are the conclusions: (1) EfficientNet-b0 is used as the encoder, and the scSE is embedded in the decoder, which can accurately correct the feature map. Thus, the features extracted by the model are conducive to building extraction. (2) The joint loss function of building boundary-weighted cross-entropy and Dice loss can enforce constraints on building boundaries, making the building extraction results close to the ground truth. (3) Transfer learning technology can complete the high-precision extraction of buildings with few training samples in a specific scene background and improve the generalization ability of the model. The Precision, Recall, F1-Score, and mIoU of the EfficientUnet+ method are 93.01%, 89.17%, 91.05%, and 90.97%, respectively. Its accuracy is the highest among all evaluation indicators. This finding shows that the EfficientUnet+ method has suitable performance and advantages in extracting buildings in emergency shelters. The extraction results have guiding relevance in improving urban emergency evacuation capabilities and building livable cities.
However, the model sometimes misses extracting buildings that are obscured by trees. In the future, we will continue to optimize and improve the EfficientUNet+ method, try to extract buildings under different phenological conditions in summer and winter, and improve the accuracy and performance of remote sensing image building extraction. The method proposed in this study is suitable for optical remote sensing images. In the future, we will try to apply the proposed method to other datasets, such as side-scan sonar, to further verify the advantages of this method in small building extraction.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}