1. Introduction
The Direction of Arrival (DOA) estimation technique is widely used in radar, sonar, and other fields, and is an important research direction in array signal processing [
1,
2]. Typical DOA estimation methods include MUSIC (Multiple Signal Classification) [
3] and ESPRIT (Estimation of Signal Parameters via Rotational Invariance Technique) [
4]. Thanks to the successful application of 1D DOA estimation problems, the subspace super-resolution algorithms are successfully extended to 2D DOA estimation problems, such as 2D unitary estimation of signal parameters via rotational invariance techniques (U-ESPRIT) [
5] and the 2D multiple signal classification (2D MUSIC) algorithm [
6]. These algorithms can obtain high
angular resolution under the requirement of multiple snapshot reception data and known coherent signal sources, but any of the conditions not satisfied will cause its estimation performance to degrade or even fail.
In recent years, effective alternative algorithms based on compressive sensing techniques have been introduced into the field of DOA estimation, and fruitful research results have been achieved. The traditional compressed sensing algorithms, for example, orthogonal matching pursuit (OMP) [
7], sparse Bayesian learning (SBL) [
8], and other algorithms, divide the possible space of the signal source into a finite number of grid points by dimension. It shows excellent estimation performance when the target angle falls exactly on the established grid, which can be applied to complex scenarios such as single snapshot, signal coherence, and missing data. On the contrary, if the real signal source does not fall on the established grid, it will cause a grid mismatch problem, and the estimation performance will be degraded or even fail. In addition, traditional compressed sensing algorithms must satisfy the pairwise isometry property (PIP) [
9] and high-density gridding.
A gridless continuous compressive sensing technique based on the atomic norm theory and the Vandermonde decomposition theorem is proposed to overcome these problems, called atomic norm minimization (ANM) [
10,
11,
12,
13,
14]. ANM projects the Vandermonde structure of the steering matrix from the observed data to the corresponding semi-definite programming (SDP) model using the Toeplitz matrix and obtains the recovered signal by solving the SDP optimization model to achieve super-resolution. Compared with the conventional compressed sensing algorithm, it does not need to mesh the space domain, and effectively avoids the grid mismatch problem and the PIP limitation. By solving the SDP optimization model using the SDPT3-based CVX/alternating direction method of multipliers (ADMM), the ANM-based method can obtain the recovered signal to achieve super-resolution 1D DOA estimation. However, computational budgets of the CVX solver SDPT3-based method increase with the scale of the problem. The performance of the model-driven ADMM method also depends on the selected regularization parameters, and improper initial values of the parameters affect its convergence speed and accuracy.
According to Caratheodory’s theory, the Vandermonde decomposition of the Toeplitz matrix does not hold in higher dimensional spaces, so the 1D ANM cannot be directly extended to the 2D DOA estimation problem. Fortunately, Chi et al. successfully apply vectorized ANM (VANM) to 2D DOA estimation with a dual Toeplitz matrix with a 2-dimensional Vandermonde structure [
15]. However, the vectorization operations increase computational complexity. They cannot be applied to real-world scenarios. The dual 2D ANM starts from the dual problem of the VANM, but does not reduce the high computational costs of the VANM [
16]. Luckily, Tian et al. proposed a new decoupled atomic norm minimization algorithm (DANM) [
17,
18,
19] to reduce the heavy computational burden. DANM first replaces the vector atomic set in VANM with the matrix atomic set and then derives the corresponding SDP model, which naturally decouples the dual Toeplitz matrix in VANM into two Toeplitz matrices containing one-dimensional Vandermonde structures. Thereby, the 2D DOA estimation problem is converted to two 1D DOA estimation problems. This algorithm significantly reduces the computational complexity and is several orders of magnitude lower than VANM, which can also be solved by SDPT3-based CVX and ADMM algorithms [
20,
21]. However, ADMM algorithms are suffering from difficulties of parameter setting in practical applications. Meanwhile, inappropriate parameter settings will decrease the convergence speed and accuracy of the ADMM algorithm, thus adding to the computing complexity and degrading the DOA estimation performance. Even if the proper parameters can be chosen by theoretical analysis and cross-validation method, the fixed parameter settings fail to guarantee optimal convergence.
Recently, the Deep Unfolding/Unrolling (DU) method has been proposed as a solution to the above problems of model-driven SR algorithms inspired by deep learning techniques. With the DU method, a specific SR algorithm is unrolled into a deep neural network by taking the number of iterations of the algorithm as the number of layers and the algorithm’s parameters as the network’s learning parameters. SR-Net is trained on the training data set to determine the optimal parameters, thus improving the convergence speed and accuracy of the SR algorithm [
22,
23,
24,
25,
26,
27,
28,
29,
30,
31]. Some deep unfolding networks have successfully solved different DOA estimation problems. For example, The paper implemented fast DOA estimation under array deficiencies using the learned ISTA (LISTA) algorithm based on the iterative soft thresholding algorithm (ISTA) [
32]; The paper proposed (position-enabled complex Toeplitz learned iterative shrinkage thresholding algorithm) PACT-LISTA algorithm, which integrates the intrinsic Toeplitz structure of the signal into LISTA, ignores the amplitude and phase information of the signal to be recovered and solves the mutual coupling problem between the antenna array elements using data [
33]; In the paper [
34], the iterative fixed-point continuation (FPC) algorithm was expanded into a deep neural network DeepFPC, to achieve single-bit DOA estimation. The paper in [
35] modeled the 2D-DOA estimation problem for unmanned vehicles as a block sparse recovery problem and then used sparse bayesian learning network (SBLNet) to learn nonlinear features from data received by a large-scale (Multi-Input Multi-Output) MIMO multiple-input system or (Reconfigurable Intelligent Surface) RIS to achieve 2D-DOA and polarization parameter estimation at lower computational complexity. Our group extended the smoothed (SL0) algorithm into SL0-Net to achieve super-resolution DOA estimation [
36]. By combining model-driven and data-driven approaches effectively, these DU methods reduce computational complexity dramatically and provide high DOA performance compared with corresponding SR algorithms.
Based on the ideas above, this paper proposes the DU gridless DOA estimation method, and the main ideas and contributions are as follows:
- ➀
The ANM-ADMM and DANM-ADMM algorithms are implemented to solve the 1D ANM and 2D DANM gridless DOA model, respectively, based on sparse optimization theory to reduce the computational burden of the existing SDPT3-based CVX method to a certain extent.
- ➁
Aiming to reduce the high computational cost and tackle the problems of intractable parameter presettings of the algorithms, we unfold the algorithms to the multi-layer deep neural network named ANM-ADMM-Net and DANM-ADMM-Net, respectively, based on the DU method. They include several types of network layers and parameters. Depending on the ANM and DANM estimation models, the complete and reasonable dataset construction methods are proposed to train the network with suitable training methods to achieve fast and accurate 1D and 2D DOA estimation, respectively.
- ➂
Traditional DU methods, such as FISTA and LAMP, are challenging to solve the ANM and DANM models. The proposed ANM-ADMM-Net and DANM-ADMM-Net as the novel DU-DOA framework is the only DU method that can optimize the above models and secure better gridless 1D and 2D DOA estimation performances with lower operational complexity.
The rest of this paper is structured as follows: In
Section 2, the array received signal model and gridless DOA model, including the ANM and DANM models, are established briefly.
Section 3 introduces the 1D ANM-ADMM and 2D DANM-ADMM algorithms first, then, the network structure, datasets construction method, and training methods of ANM-ADMM-Net and DANM-ADMM-Net are provided in detail.
Section 4 verifies the performance and advantages of DU-DOA through simulation experiments compared with the SDPT3-based CVX and ADMM methods. Conclusions are drawn in
Section 5.
3. DU-DOA Estimation
In order to lighten the computational load and enhance the estimation performance efficiently, this paper intends to the DU-DOA method to solve (5) for 1D DOA and (13) for the 2D DOA estimations in this section. According to [
22], the DU approach can be seen as an iterative step based on the SR algorithm for designing the structure and parameters of the deep neural network. DU methods such as LISTA, LAMP, and LePOM [
22,
23,
24] can all theoretically achieve the 2D DOA estimation. However, these methods are unsuitable for solving the AMM-DOA and DAMM-DOA models, i.e., (5) and (13). This paper analyzes the ANM-ADMM and the DANM-ADMM algorithms to address the above problem in
Section 3.1 and
Section 3.3, respectively. The algorithms are expanded into the deep neural network ANM-ADMM-Net and DANM-ADMM-Net to achieve fast and accurate 1D and 2D DOA estimation in
Section 3.2 and
Section 3.4, respectively.
3.1. 1D ANM-ADMM DOA
To facilitate the solution, (5) is rewritten as (15).
where
is the regularization factor.
The augmented Lagrangian function of the problem (15) can be defined via [
41].
where
is the Lagrangian multiplier, and
is the penalty factor.
Note (16) is an unconstrained optimization problem, so that given the received signal
, unknown signal components
, and vector
can be estimated by alternatively minimizing the cost function of
,
,
,
and
[
14]. The specific iterative process can be found in
Appendix A.
In conclusion, the ADMM algorithm for solving (5) is provided in Algorithm 1.
| Algorithm 1: ANM-ADMM-DOA algorithm. |
Input:, iterations , penalty factor , regularization factor .
Initialization: and .
For do
(1) ;
(2) ;
(3) ;
(4) ;
(5) ;
End
Output: Recovered signal of interest , the optimal estimate .
Then: Estimate and by Vandermonde decomposition of and compute DOA by . |
According to the above derivation, the parameters of the model-driven ADMM algorithm, including the penalty factor
and the regularization factor
, need to be set in advance, which is a challenge for practical applications. Meanwhile, inappropriate parameter settings will decrease the convergence speed and accuracy of the ADMM algorithm, thus adding to the computing complexity of (5) and degrading the DOA estimation performance. Even if the proper parameters can be chosen by theoretical analysis and cross-validation method [
41], the fixed parameter settings fail to guarantee the optimal convergence of the ANM-ADMM algorithm. Based on the idea of the DU method, this paper expands the algorithm into a deep neural network ANM-ADMM-Net and learns its optimal parameters from the constructed data obeying a particular distribution, thus solving the above problems.
It is necessary to note that the optimal estimates of the algorithm are the critical points of the following estimation. Therefore, we can consider the output as a label and construct a proper loss function in the next subsection.
3.2. 1D ANM-ADMM-Net DOA
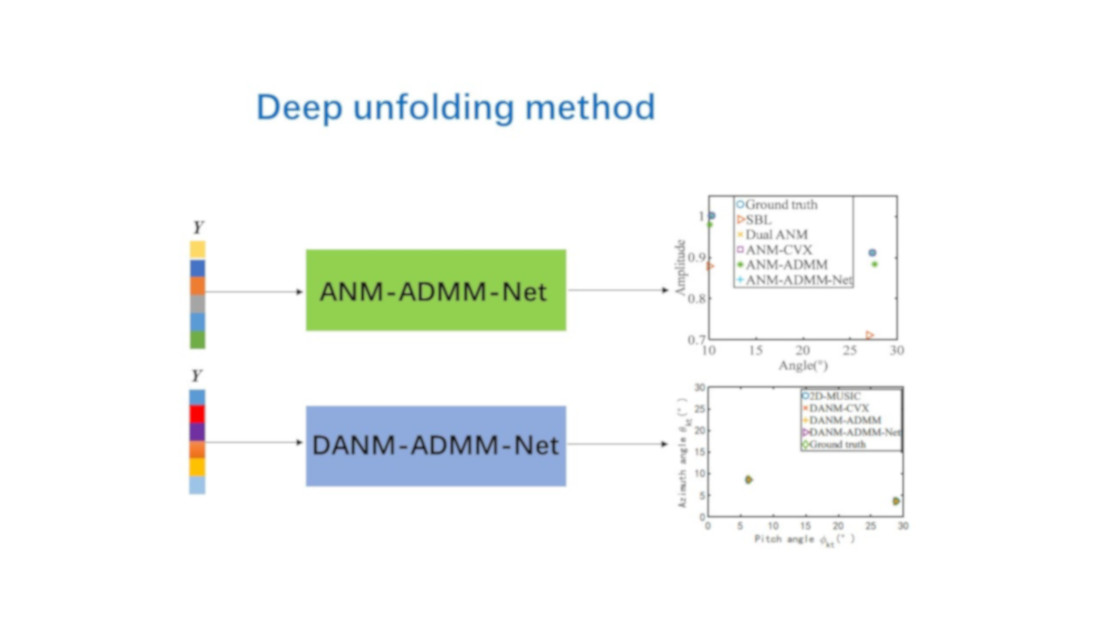
For the optimization problem shown in (5), when the system parameters are given and the complex amplitude and noise all obey a particular distribution, the received data will also have a particular distribution. At this point, assume that an optimal set of parameter sequences exists so that (5) can be solved quickly and accurately by the ADMM algorithm for all received signals, with the DOA obeying a specific distribution. Therefore, this subsection constructs the network ANM-ADMM-Net to tackle the problems of the ADMM algorithm based on its iterative steps. This network couples the interpretability of the model-driven algorithm and the nonlinear fitting capability of the data-driven deep learning method. Training networks based on a sufficient and complete training data set can obtain optimal iterative parameters, thereby reducing the number of iterations and further enabling higher speed and ameliorated performance of DOA estimation. In the following, the four parts of ANM-ADMM-Net: network structures, dataset construction, network initialization, and training are described thoroughly.
3.2.1. Network Structure
According to the steps in Algorithm 1, the ANM-ADMM algorithm can be mapped to a
layer network ANM-ADMM-Net shown in
Figure 2, whose inputs are
,
, and
, and the learnable parameters are
, to arrive at the signal components
and the Toeplitz matrix
. The
-th layer operation of ANM-ADMM-Net can be expressed as
where
contains five main structural sub-layers, including reconstruction sub-layer
, the auxiliary variable update sub-layer
, the Toeplitz transform sub-layer
, the nonlinear sub-layer
, and the multiplier update sub-layer
corresponding to (17). The specific description is as follows.
- (1)
Reconstruction sub-layer : Taking the output of the sub-layer and of the sub-layer of -th layer and received signal as the input, the output is updated as
where
is the learnable parameter. The output
of
can be used as the input of the sub-layer
and
in the
-th layer.
- (2)
Auxiliary variable update sub-layer : Taking the output of the sub-layer and of the sub-layer in the -th layer are used as inputs, the output of is given by
where
is the learnable parameter. The output
is the input of the sub-layer
and
in the
-th layer.
- (3)
Toeplitz transform sub-layer : The output of the sub-layer and of the sub-layer in the -th layer are used as inputs, and the output is represented by
where
can be the input of the sub-layer
and
in the
-th layer.
- (4)
Nonlinear sub-layer : Taking the output of the sub-layer of the -th layer, the output of the sub-layer , and the output of the sub-layer as the input, the output of can be given as
where the output
of
can be used as the input of the sub-layer
,
, and
in the
-th layer.
- (5)
Multiplier update sub-layer : Taking the output of the sub-layer of the -th layer, the output , , and of the sub-layer , , and respectively as input, the output of can be updated by
where the multiplier update rate
is the learnable parameter, and the output
of
can be used as the input in the
-th layer. It is essential to emphasize that the new parameters
are added to enhance the learning capability further and the performance of ANM-ADMM-Net compared to updating multipliers by
of ANM-ADMM (as shown in Algorithm 1).
Considering that each sub-layer’s parameters are learned and tuned, there will be
parameters for
layer ANM-ADMM-Net generally, i.e.,
,
,
. Compared with the ANM-ADMM algorithm, where the parameters
and
are fixed, this parameter learning strategy of ANM-ADMM-Net has the advantages of superior flexibility and brilliant nonlinear fitting capability [
36]. More importantly, the design of the network is guided by the model and is highly interpretable.
3.2.2. Data Construction
The proposed ANM-ADMM-Net is a sparse recovery approach jointly driven by model and data. The key to its effectiveness is constructing a reasonable dataset with generalization capability. By building an adequate and complete dataset, ANM-ADMM-Net is less prone to overfitting during the training process, performing better DOA estimation. Thus, this paper randomly generates the signal data obeying a particular distribution and forms the received data . Specifically:
- (1)
Given the array element number , the frequency range , corresponding angle range , number of snapshots .
- (2)
Given the maximum value of the number of sources and randomly generate the sources number .
- (3)
For each
, its frequency
has a uniform distribution U (
), and the frequency interval between any two sources in the case of multiple sources needs to satisfy
[
38], then the angle of the source can be obtained as
. The received signal
is generated according to (1), where
,
, the complex amplitude matrix
obeys the standard normal distribution and
is Gaussian noise with SNR.
- (4)
Repeat the above to obtain the set of
received signals
, the set of the frequencies and the angles
. The ideal label set vector
can be obtained according to Vandermonde decomposition after the dual atomic norm minimization method [
34,
37].
- (5)
Divide randomly the above set into a training dataset and a testing dataset .
3.2.3. Network Initialization and Training
Consider the difficulty of mapping in (5), and eigen-decomposition in Algorithm 1 when training ANM-ADMM-Net. Proper initialization of the parameters and an appropriate training method, including loss function, optimizer, and learning schedules, will make it easier to reach convergence and avoid falling into a locally optimal solution to a certain extent.
- (1)
Network initialization
The initial values of the parameters in each layer are set as
,
, and
to enhance the proposed method’s flexibility based on the theoretical analysis [
41]. Compared with the ANM-ADMM algorithm with fixed parameter settings, ANM-ADMM-Net will substantially increase the convergence rate (i.e., reduce the number of iterations) and shorten the time to solve (5), with guaranteed convergence performance.
- (2)
Network training
The Adam algorithm is adopted for learning and tuning the parameters with an initial learning rate of 1 × 10
−3 to achieve the possible global optimum rapidly. Based on the training dataset
constructed in
Section 3.2.2 and given the network layer
, the optimal parameters
can be obtained by minimizing the following normalized mean square error (NMSE) loss function using the principle of Back Propagation (BP) [
42], i.e.,
where
,
denotes the estimated components of the
-th Toeplitz transform sub-layer output of the network with parameters
,
,
and
as inputs, respectively.
Then, according to the given testing dataset
, after obtaining the optimal parameters
, the recovered signal
and the Toeplitz matrix
can be estimated online by
At the end of the ANM-ADMM-Net DOA method, can be the input of the Vandermonde decomposition to obtain the frequency and amplitude values , thereby achieving the estimated DOA .
3.3. 2D DANM-ADMM DOA
To facilitate the solution, (13) is rewritten as (25):
where
is the regularization factor.
Then, the augmented Lagrangian function of the problem (25) can be defined via [
41]
where
is the Lagrangian multiplier, and
is the penalty factor. Note (26) is an unconstrained optimization problem, so that, given the received signal
, unknown signal components
and Toeplitz matrix
and
can be estimated by minimizing the objective function of
alternatively.
By the same token as in Algorithm 1, the ADMM algorithm for solving (13) is provided in Algorithm 2.
| Algorithm 2: DANM-ADMM DOA algorithm. |
Input:, number of iterations , penalty factor , regularization factor .
Initialization: and .
For do
(1) ;
(2);
(3) ;
(4) ;
(5) ;
End
Output: Recovered signal of interest , the optimal estimate and .
Then: Compute matrix and ; Retrieve two dimensional frequencies without pairing by root music algorithm or matrix pencil method [38]. Then, final 2D DOA estimation can be obtained by following pairing technique.
, where denotes the frequency index of that matched to , i.e., .
Finally: Obtain the pared and compute the corresponding angles , final pitch angle and azimuth angle can be calculated by (6) and (7). |
where
are
Hermitian matrices, and
,
,
,
,
,
;
,
denotes that all elements smaller than zero are set to zero; and
is an orthogonal matrix satisfying
.
According to the above derivation, the parameters of the model-driven ADMM algorithm, including the penalty factor
and the regularization factor
, need to be set in advance, which is a challenge for practical applications. Based on the idea of the DU method, this paper also expands the algorithm into a deep neural network DANM-ADMM-Net as
Section 3.2, thus solving the above problems. The optimal estimates
and
can be considered as labels and construct a proper loss function in the next subsection.
3.4. 2D DANM-ADMM-Net DOA
In the following, the four parts of DANM-ADMM-Net: network structures, dataset construction, network initialization, and training, are described thoroughly.
3.4.1. Network Structure
According to the steps in Algorithm 2, the ADMM algorithm can be mapped to a
layer network DANM-ADMM-Net, shown in
Figure 3, whose inputs are
,
and
, and the learnable parameters are
, to arrive at the signal components
and two Toeplitz matrixes
,
. The
-th layer operation of DANM-ADMM-Net can be expressed as
where
contains five main structure sub-layers, including reconstruction sub-layer
, the Toeplitz transform sub-layer
, the Toeplitz transform sub-layer
, the nonlinear sub-layer
, and the multiplier update sub-layer
. The specific description is as follows.
- (1)
Reconstruction sub-layer : Taking the output of the sub-layer and of the sub-layer of -th layer and received signal as the inputs, the output is updated as
where
is the learnable parameter. The output
of
can be used as the input of the sub-layer
and
in the
-th layer.
- (2)
Toeplitz transform sub-layer : Taking the output of the sub-layer and of the sub-layer in the -th layer as inputs, the output of is represented by
where
is the learnable parameter. The output
is the input of the sub-layer
and
in the
-th layer.
- (3)
Toeplitz transform sub-layer : Taking the output of the sub-layer and of the sub-layer in the -th layer as inputs, the output of can be expressed as
where the output
can be used as the input of the sub-layer
and
in the
-th layer.
- (4)
Nonlinear sub-layer : Taking the output of the sub-layer of the -th layer, the output of the sub-layer , the output of the sub-layer and the output of the sub-layer as inputs, the output of can be given as
where the output
of
can be used as the input of the sub-layer
,
, and
in the
-th layer.
- (5)
Multiplier update sub-layer : Taking the output of the sub-layer of the -th layer, the output , , , of the sub-layer , , , respectively, as inputs, the output of can be updated by
where multiplier update rate
is the learnable parameter, the output
of
can be used as the input in the
-th layer. The new parameters
are also added to enhance the learning capability further and the performance of DANM-ADMM-Net compared to updating multipliers by
of DANM-ADMM (as shown in Algorithm 2).
Considering that each sub-layer’s parameters are learned and tuned, there will be parameters for layer DANM-ADMM-Net generally, i.e., , , . The parameters and of the DANM-ADMM algorithm are fixed.
3.4.2. Data Construction
This subsection randomly generates the received data and constructs the dataset. Specifically:
- (1)
Given the array element number , the pulse number , pitch angle , azimuth angle , and number of samples .
- (2)
Given the maximum value of the number of sources and randomly generate the sources number .
- (3)
For each
, compute
and
satisfying
and
[
19]. Then received signal
is produced by
, where
, and amplitude
obeys complex standard normal distribution.
is the complex Gaussian white noise with SNR.
- (4)
Randomly divide the received signal data into training data and testing data .
- (5)
Use the DANM-CVX method to address (13), thereby obtaining the training label set , the testing label set according to the pairing technique in Algorithm 2.
3.4.3. Network Initialization and Training
The initial values of the parameters in each layer are set as
,
, and
. The Adam algorithm is adopted for learning and tuning the parameters with an initial learning rate of 2 × 10
−3 to achieve the possible global optimum rapidly. Based on the training dataset
constructed in
Section 3.4.2 and given the number of network layers
, the optimal parameters
can be obtained by minimizing the following NMSE loss function, i.e.,
where
,
, and denotes the estimated components of the -th Toeplitz transform sub-layer output of the network with parameters , , and as inputs, respectively.
Then, according to the given testing dataset
, after obtaining the optimal parameters
, the recovered signal
and the Toeplitz matrix
,
can be estimated online by
Follow the procedures of the DANM-ADMM algorithm in Algorithm 2 and thereby achieve 2D DOA estimation perfectly at the end of the DANM-ADMM-Net method.
4. Experiment Results
In this section, we evaluate the DU-DOA method based on the ANM-ADMM-Net and DANM-ADMM-Net through simulation experiments. Considering that the ADMM algorithm is the only iterative algorithm for solving the ANM and DANM models, we compare it to traditional 1D and 2D DOA estimation methods with fixed parameters. For the convenience of training and testing, all offline training procedures are implemented based on Python 3.8 with the configuration of Intel(R) Core i7-6246 3.30GHz CPU and NVIDIA Quadro GV100 GPU. Once the optimal parameters after training obtaining, all testing simulations will be implemented based on MATLAB 2020b online.
Since the noise level is generally unknown in the practical application, only the training data without noise are used in the training process of the ADMM network in this paper. Then noise is added to the data in the test data to verify the ADMM algorithm’s performance under different SNRs. Therefore, the training and testing datasets for DOA estimation can be constructed with parameters in
Table 1 and
Table 2 according to
Section 3.2.2 and
Section 3.4.2, respectively.
4.1. Network Convergence Analysis
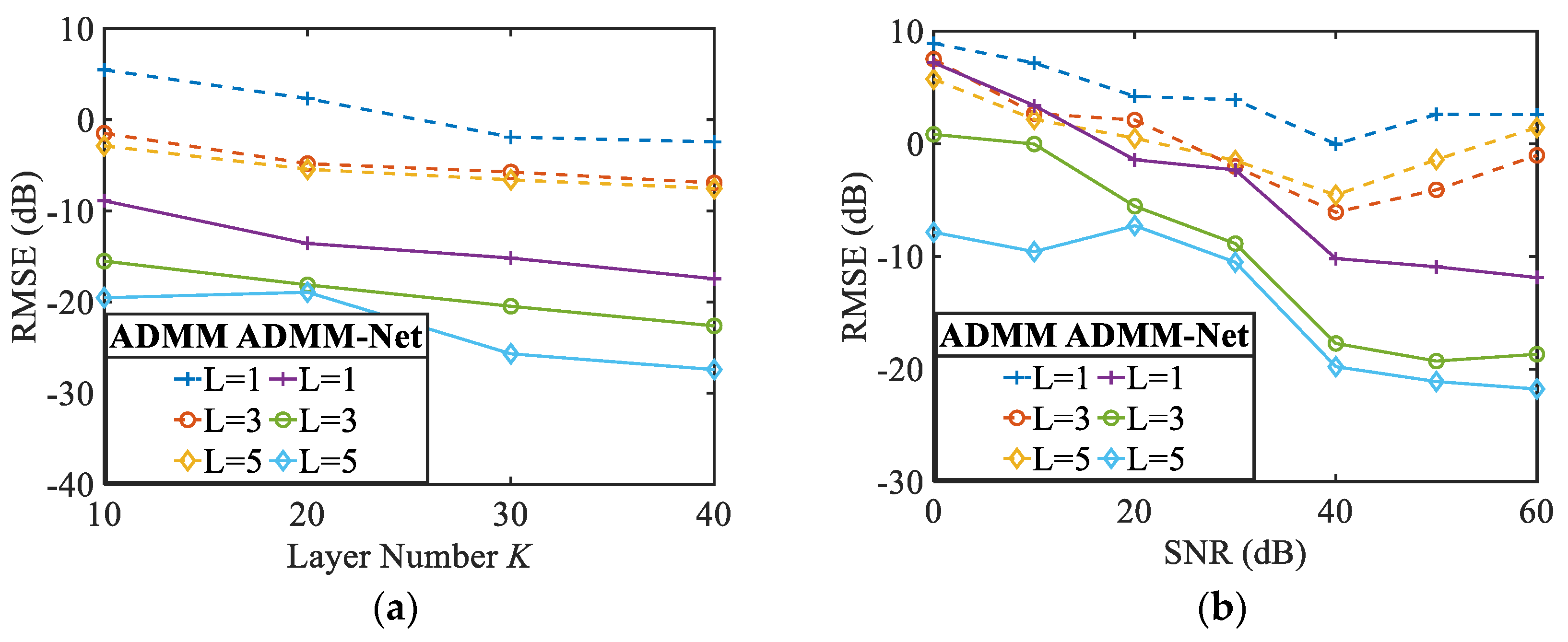
This subsection investigates the convergence performance of the ANM-ADMM-Net and DANM-ADMM-Net under different layers and compares it with the traditional algorithms with fixed iterative parameters.
The iteration parameters of ANM-ADMM are set as
,
,
. Set different network layers
, initialize and train network (450 epochs), and the results are shown in
Figure 4. Among them,
Figure 4a,b shows training NMSEs and testing NMSEs when
, and
Figure 4c shows the NMSEs of two methods. Based on
Figure 4a,b, the training and testing NMSEs of the proposed method decrease with the increase in training time and effectively reach convergence.
Figure 4c shows that, as the number of network layers (the number of iterations) increases, the NMSEs of both ANM-ADMM-Net and ANM-ADMM algorithms gradually decrease, and the former is much smaller than the latter. In addition, only when the number of iterations of the ANM-ADMM algorithm is at least fifty to sixty times higher than the ANM-ADMM-Net, their NMSE is equal, which implies the computing complexity required for convergence is reduced.
The iteration parameters of DANM-ADMM algorithm are set as
,
, and
. Set different network layers
, initialize and train DANM-ADMM-Net (600 epochs), and the results are shown in
Figure 5. Among them,
Figure 5a,b is the training NMSEs and testing NMSEs of DANM-ADMM-Net when
, and
Figure 5c shows the NMSEs of both when the number of network layers (iterations)
.
Figure 5d reveals the NMSEs of algorithm when iterations
. Based on
Figure 5a,b, the training and testing NMSEs of DANM-ADMM-Net decrease with the increase in training time and effectively reach convergence after 500 training epochs. In addition,
Figure 5c shows that as the number of network layers (the number of iterations) increases, the NMSEs of both the DANM-ADMM-Net and DANM-ADMM algorithm decrease. However, the NMSE of the former is much smaller than that of the latter. From
Figure 5c,d, the two have similar NMSE only when the number of iterations of the algorithm is fifty times higher than that of network when
. Therefore, it can be concluded that the proposed can learn the optimal iteration parameters from the constructed dataset and obtain better convergence performance.
In practical applications, the networks can be trained offline based on different simulation conditions to determine the range of network layers that can obtain better DOA estimation performance and lower computational complexity. Then, the network layers can be selected according to the actual situation.
4.2. DOA Estimation Results Analysis
4.2.1. 1D DOA Estimation Results Analysis
This subsection investigates the performance of ANM-ADMM-Net for DOA estimation and its upsides over the SBL algorithm, dual ANM, ANM-CVX and ANM-ADMM methods with simulation experiments. The root mean square error (RMSE) is evaluated by
Monte Carlo trials.
The results of different methods are shown in
Figure 6, where grid numbers
,
and
for the SBL algorithm [
8];
,
for ANM-ADMM and ANM-ADMM-Net. The results indicate that unsuitable grid division inevitably causes the estimated DOA offset of the SBL algorithm. dual ANM and ANM-CVX methods are always the optimal estimation results. ANM-ADMM cannot recover the amplitude and degree of the signal perfectly due to limited iterations. However, the proposed ANM-ADMM-Net has a better estimation of amplitude and degree than the ANM-ADMM algorithm with fixed parameters, demonstrating the effectiveness of the combination of model-driven and data-driven DU methods.
Figure 7 shows the test RMSEs when the number of network layers
. The RMSEs of ANM-ADMM and ANM-ADMM-Net gradually decrease as the number of network layers increases (number of iterations), and the latter is much smaller than the former with fixed parameters. The above results demonstrate that the more layers of the network, the more optimal iterative parameters can be learned from the constructed dataset due to its powerful nonlinear fitting capability and superior flexibility, resulting in better DOA estimation performance. In other words, the DU-gridless DOA method based on ANM-ADMM-Net is suitable for efficiently resolving the different sparsity problems (different target signal problems) at a lower computational cost.
The testing dataset when SNR = 0~60dB is constructed to verify the noise robustness according to
Section 3.2.2 (i.e., generate testing data for every SNR and noise regularization factor of dual ANM is 0.1), and the test results when
are shown in
Figure 7b. It can be seen that when
, ANM-ADMM is unable to be implemented for estimation. However, the proposed method still performs better under limited network layers/iterations, demonstrating the higher noise robustness of the latter with the optimal parameters. In addition, when
, the test RMSE of ANM-ADMM-Net tends to be stable and close to the results obtained in the noise-free case. The above implies that even if noise-free data train the network, the proposed method still obtains better parameter results and can perform DOA estimation for the actual array received data containing noise.
4.2.2. 2D DOA Estimation Results Analysis
This subsection investigates the performance of DANM-ADMM-Net for 2D DOA estimation and its upsides over the conventional 2D DOA methods with simulation experiments. The root mean square error (RMSE) is also evaluated by
Monte Carlo trials.
The 2D DOA results estimated by different methods when
,
are shown in
Figure 8, where the parameters of the 2D-MUSIC method are set to
, and the number of snapshots
. The results in
Figure 8b show that the DANM-ADMM algorithm fails to precisely converge to the ground truth precisely at a finite number of iterations due to improper parameter settings, resulting in some deviations in both azimuth and pitch angles estimated for individual targets. In contrast, the parameters of the proposed method are optimized for data and networks, thus converging to a better result completely at a finite number of layers.
Figure 9a gives the results of the test RMSEs when the number of array elements
and the number of network layers
. The RMSEs of DANM-ADMM and DANM-ADMM-Net gradually decrease as the number of network layers increases (number of iterations). When
, the RMSE of the latter is reduced by 20dB compared to the former with fixed parameters, which indicates that the more layers of the network, the more optimal iterative parameters can be learned from the constructed dataset, resulting in better 2D DOA estimation performance.
The test dataset is constructed by
Section 3.4.3 when SNR = 0~60dB (i.e., test data are generated for each SNR) to verify the noise robustness of DANM-ADMM-Net. The results when
are shown in
Figure 9b. The tested RMSE of both methods decreased with increased SNR under a limited number of network layers/iterations. If we train the network with data when noise exists, for example, SNR = 10 dB, DANM-ADMM-Net performs better than DANM-ADMM under any circumstances. Therefore, to ensure higher noise robustness, one can estimate the signal-to-noise ratio first, and then use the corresponding data containing the noise to train the network.
4.3. Computational Complexity and Running Time Comparsion
This subsection analyzes the computational complexity and running time of SDPT3 based ANM-CVX method and ANM-ADMM-Net at different array elements when network layers
. The running time results when
,
and
,
are shown in
Figure 10. The results of the comparison of DANM-CVX and DANM-ADMM-Net when network layers
are also shown in
Figure 11.
From the paper [
43], it is known that the computational complexity of the solver SDPT3-based CVX method is
, where
denotes the number of variables and
denotes the dimensionality of the SDP matrix. Therefore, the computational complexity of the CVX method for solving the ANM model is
and
for solving the DANM model. In contrast, while that of the ADMM method is
and
, respectively, where
denotes the number of iterations, which indicates that when the matrix size is large, the computational complexity of the ANM-ADMM and DANM-ADMM methods to solve the ANM model and DANM model, respectively, is much smaller than that of the ANM-CVX and DANM-CVX methods, respectively.
It is important to emphasize that the computational complexity analysis of ANM/DANM-ADMM-Net in this paper does not include the computational costs required for network training, since it is possible to train offline and apply online. Moreover, after training to obtain the optimal parameters, the computational complexity of networks and its ADMM algorithms are identical and differ in the iterative parameters. Therefore, networks and ANM/DANM-ADMM algorithms will have the same computational complexity when applied with the same network layers (number of iterations). However, considering the reduced iterations requirements of networks, the computational complexity is further decreased compared to algorithms.
The results in
Figure 10 show that the growth rate of the proposed method’s running time is much lower than that of the ANM-CVX and dual ANM methods, as the number of array elements or snapshots increases. In conclusion, ANM-ADMM-Net can be an alternative in the presence of larger-scale arrays or snapshots and high real-time requirements, and it is consistent with the above theoretical analysis. The same conclusion also can be drawn for DANM-CVX and DANM-ADMM-Net in
Figure 11.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}