
Risk Factors and Prediction of the Probability of Wildfire Occurrence in the China–Mongolia–Russia Cross-Border Area

 , ,
, ,
Abstract
:1. Introduction
- Estimating the probability of wildfire occurrence as a function of biophysical and human-related drivers.
- Assessing the relative importance of each driver.
- Analyze the performance of the ANFIS model with GA and PSO for wildfire modeling in the China–Mongolia–Russia cross-border area.
- This study explores the applicability of hybrid modeling in predicting wildfire occurrence and the probability of wildfire risk assessment for a sizeable spatial domain that crosses three countries.
2. Material and Methods
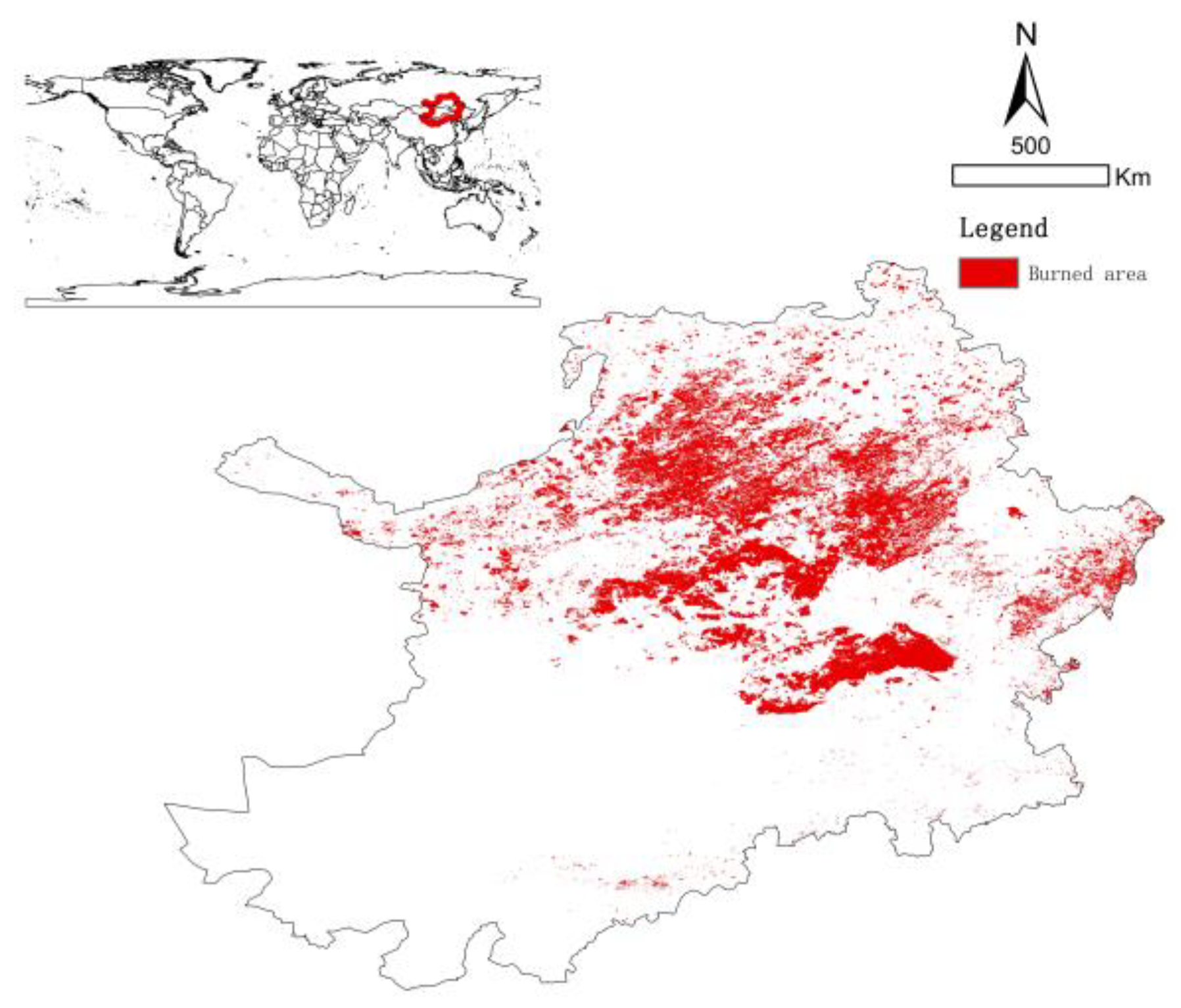
2.1. Study Area
2.2. Data Source
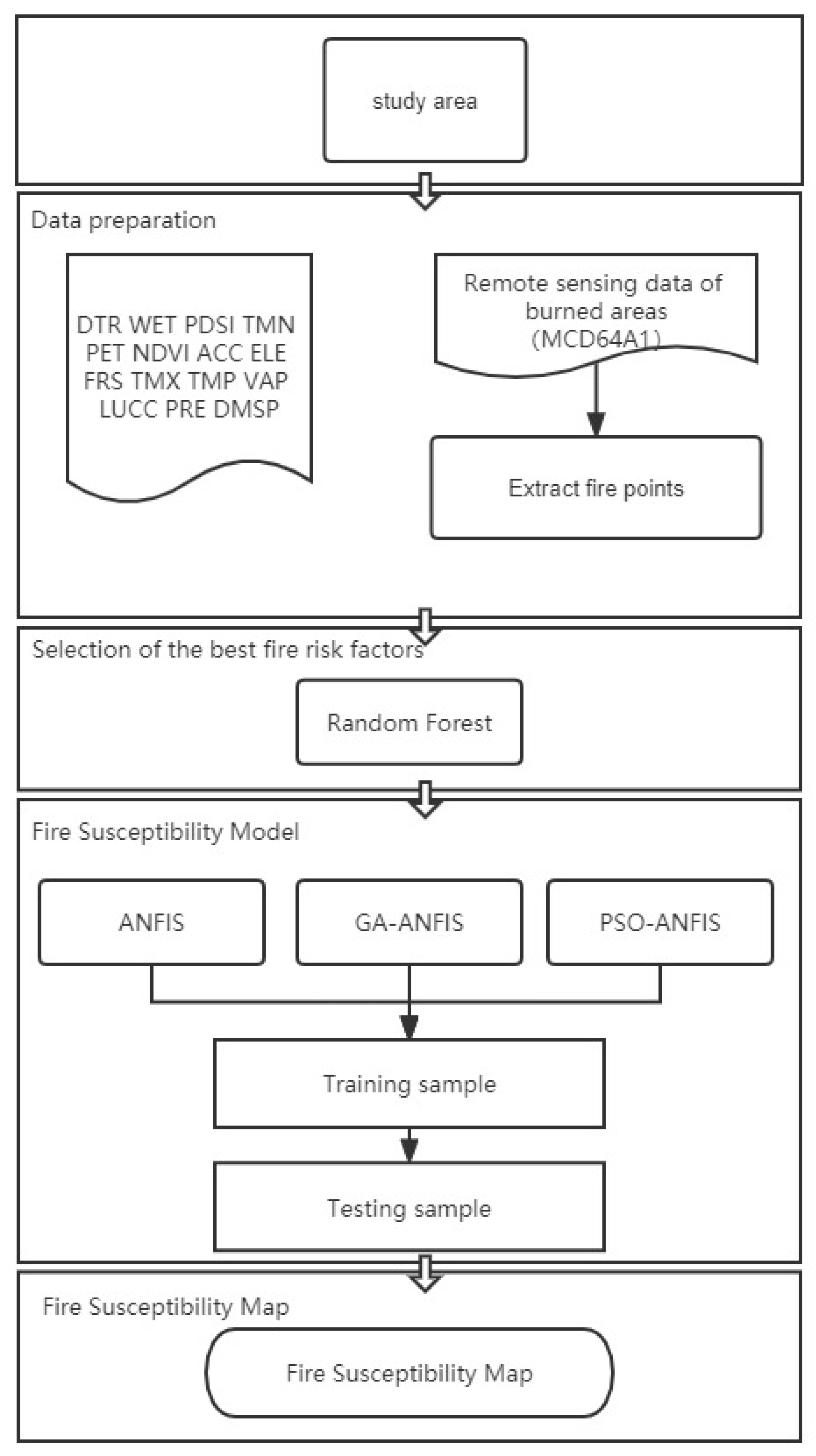
2.3. Wildfire-Risk Factor Importance Analysis Using the Random Forest Model
2.4. Wildfire Probability Modeling
2.4.1. Adaptive Neuro-Fuzzy Inference System (ANFIS)
2.4.2. Genetic Algorithm (GA)
2.4.3. Particle Swarm Optimization (PSO)
2.5. Model Training
2.6. Model Evaluation
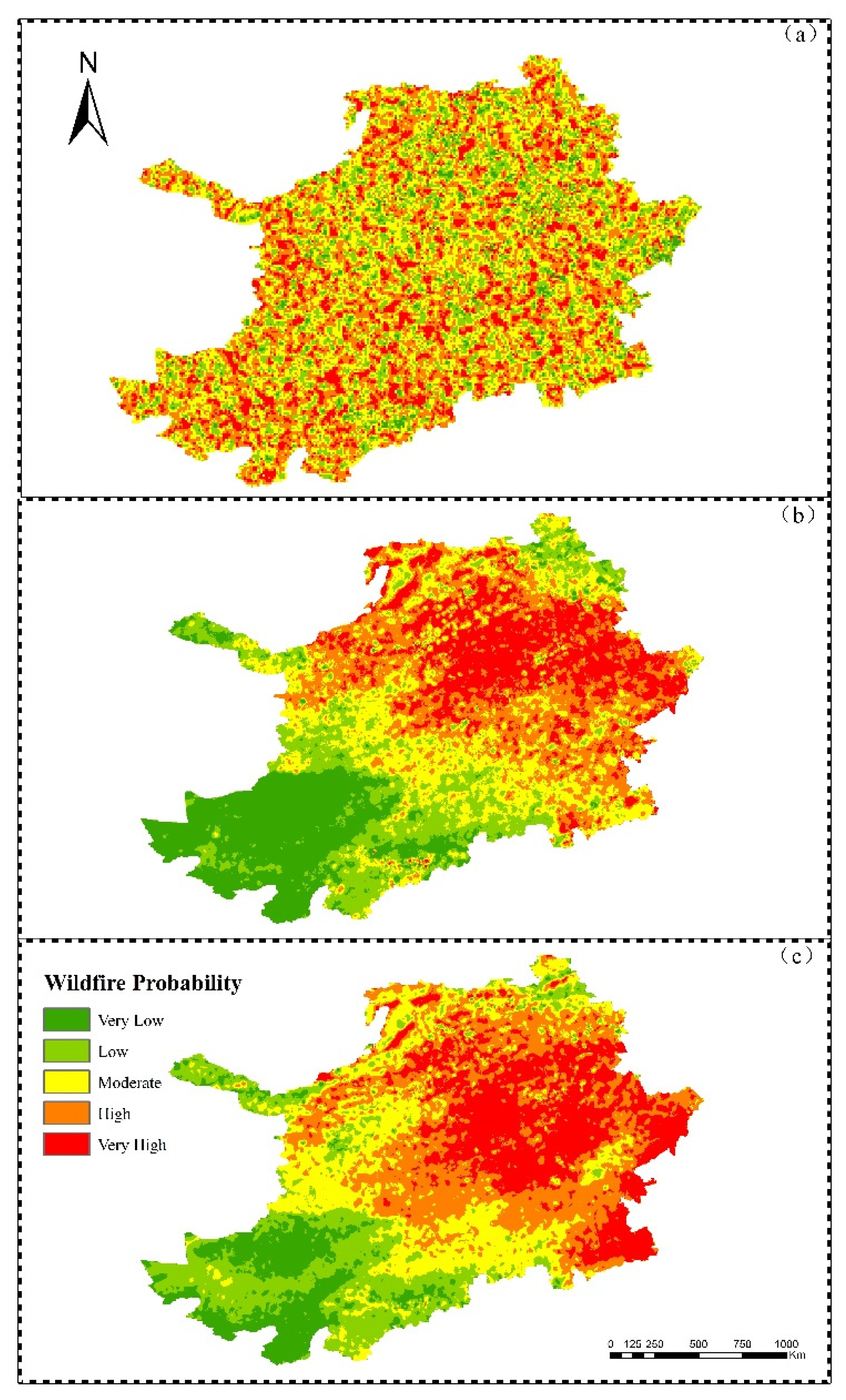
2.7. Wildfire Probability Map
3. Results
3.1. Factor Importance of Wildfire Occurrence
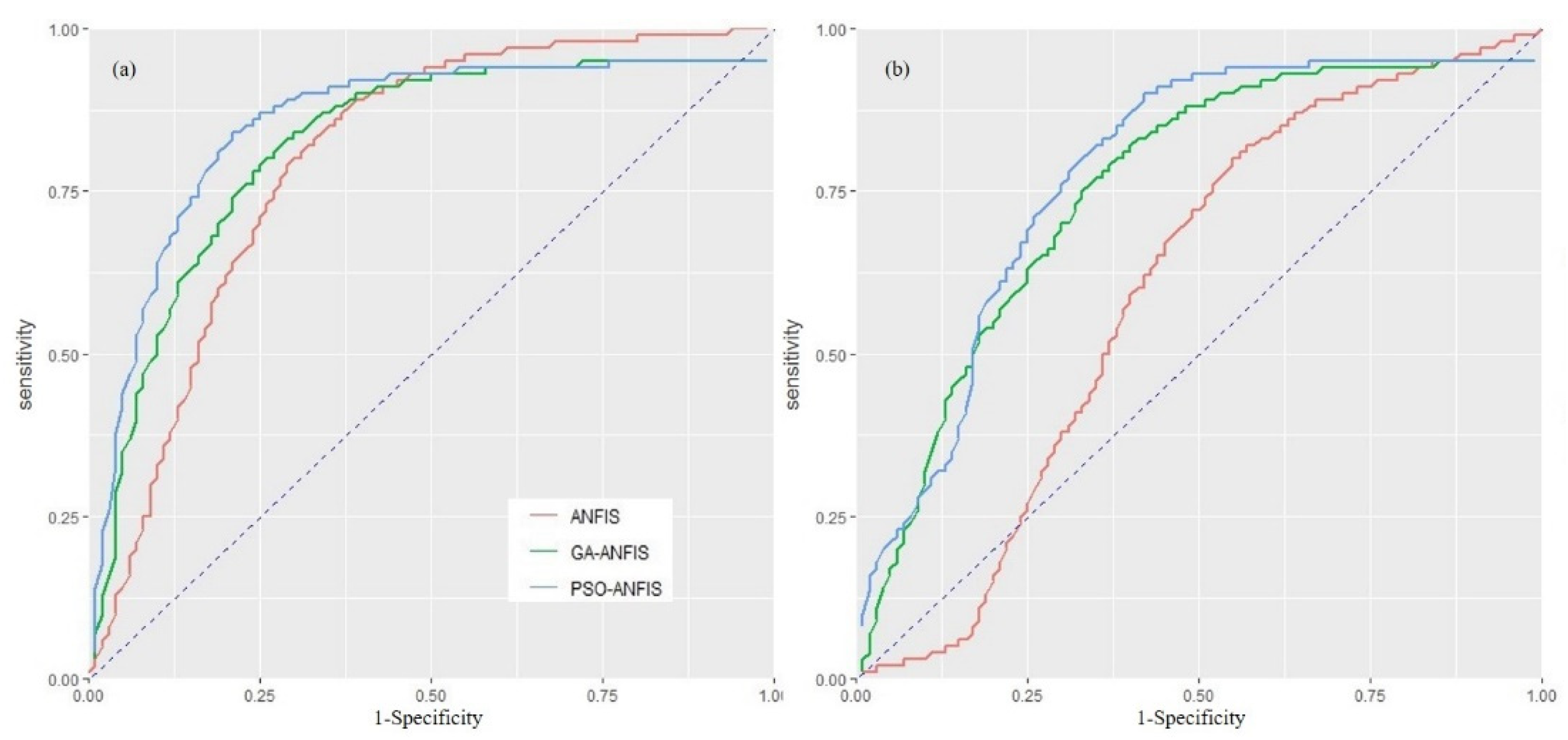
3.2. Model Validation
3.3. Probability of Wildfire Occurrence
4. Discussion
4.1. Comparison of PSO and GA to Optimize ANFIS
4.2. Importance of Variables Affecting Wildfire Occurrence
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Meng, Y.; Deng, Y.; Shi, P. Mapping Forest Wildfire Risk of the World. In World Atlas of Natural Disaster Risk; Shi, P., Kasperson, R., Eds.; IHDP/Future Earth-Integrated Risk Governance Project Series; Springer: Berlin/Heidelberg, Germany, 2015; pp. 261–275. ISBN 978-3-662-45429-9. [Google Scholar]
- Flannigan, M.; Cantin, A.S.; de Groot, W.J.; Wotton, M.; Newbery, A.; Gowman, L.M. Global Wildland Fire Season Severity in the 21st Century. For. Ecol. Manag. 2013, 294, 54–61. [Google Scholar] [CrossRef]
- Stephens, S.L.; Agee, J.K.; Fulé, P.Z.; North, M.P.; Romme, W.H.; Swetnam, T.W.; Turner, M.G. Managing Forests and Fire in Changing Climates. Science 2013, 342, 41–42. [Google Scholar] [CrossRef] [PubMed]
- International Strategy for Disaster Reduction (ISDR). 2009 Global Assessment Report on Disaster Risk Reduction: Patterns, Trends and Drivers; United Nations: Geneva, Switzerland, 2009. [Google Scholar]
- Jolly, W.M.; Cochrane, M.A.; Freeborn, P.H.; Holden, Z.A.; Brown, T.J.; Williamson, G.J.; Bowman, D.M.J.S. Climate-Induced Variations in Global Wildfire Danger from 1979 to 2013. Nat. Commun. 2015, 6, 7537. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ying, H.; Shan, Y.; Zhang, H.; Yuan, T.; Rihan, W.; Deng, G. The Effect of Snow Depth on Spring Wildfires on the Hulunbuir from 2001–2018 Based on MODIS. Remote Sens. 2019, 11, 321. [Google Scholar] [CrossRef] [Green Version]
- Rodrigues, M.; de la Riva, J.; Fotheringham, S. Modeling the Spatial Variation of the Explanatory Factors of Human-Caused Wildfires in Spain Using Geographically Weighted Logistic Regression. Appl. Geogr. 2014, 48, 52–63. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Valizadeh Kamran, K.; Blaschke, T.; Aryal, J.; Naboureh, A.; Einali, J.; Bian, J. Spatial Prediction of Wildfire Susceptibility Using Field Survey GPS Data and Machine Learning Approaches. Fire 2019, 2, 43. [Google Scholar] [CrossRef] [Green Version]
- Upadhyay, R.K. Markers for Global Climate Change and Its Impact on Social, Biological and Ecological Systems: A Review. AJCC 2020, 9, 159–203. [Google Scholar] [CrossRef]
- Povak, N.A.; Hessburg, P.F.; Salter, R.B. Evidence for Scale-dependent Topographic Controls on Wildfire Spread. Ecosphere 2018, 9. [Google Scholar] [CrossRef] [Green Version]
- Aldersley, A.; Murray, S.J.; Cornell, S.E. Global and Regional Analysis of Climate and Human Drivers of Wildfire. Sci. Total Environ. 2011, 409, 3472–3481. [Google Scholar] [CrossRef]
- Chuvieco, E.; Congalton, R.G. Application of Remote Sensing and Geographic Information Systems to Forest Fire Hazard Mapping. Remote Sens. Environ. 1989, 29, 147–159. [Google Scholar] [CrossRef]
- Cardille, J.A.; Ventura, S.J.; Turner, M.G. Environmental and Social Factors Influencing Wildfires in the Upper Midwest, United States. Ecol. Appl. 2001, 11, 111–127. [Google Scholar] [CrossRef]
- Liu, Z.; Yang, J.; Chang, Y.; Weisberg, P.J.; He, H.S. Spatial Patterns and Drivers of Fire Occurrence and Its Future Trend under Climate Change in a Boreal Forest of Northeast China. Glob. Change Biol. 2012, 18, 2041–2056. [Google Scholar] [CrossRef]
- Martínez, J.; Vega-Garcia, C.; Chuvieco, E. Human-Caused Wildfire Risk Rating for Prevention Planning in Spain. J. Environ. Manag. 2009, 90, 1241–1252. [Google Scholar] [CrossRef]
- Prasad, V.K.; Badarinath, K.V.S.; Eaturu, A. Biophysical and Anthropogenic Controls of Forest Fires in the Deccan Plateau, India. J. Environ. Manag. 2008, 86, 1–13. [Google Scholar] [CrossRef]
- Cao, X.; Chen, J.; Matsushita, B.; Imura, H.; Wang, L. An Automatic Method for Burn Scar Mapping Using Support Vector Machines. Int. J. Remote Sens. 2009, 30, 577–594. [Google Scholar] [CrossRef]
- Guo, F.; Zhang, L.; Jin, S.; Tigabu, M.; Su, Z.; Wang, W. Modeling Anthropogenic Fire Occurrence in the Boreal Forest of China Using Logistic Regression and Random Forests. Forests 2016, 7, 250. [Google Scholar] [CrossRef] [Green Version]
- Jafari Goldarag, Y.; Mohammadzadeh, A.; Ardakani, A.S. Fire Risk Assessment Using Neural Network and Logistic Regression. J. Indian Soc. Remote Sens. 2016, 44, 885–894. [Google Scholar] [CrossRef]
- Tien Bui, D.; Bui, Q.-T.; Nguyen, Q.-P.; Pradhan, B.; Nampak, H.; Trinh, P.T. A Hybrid Artificial Intelligence Approach Using GIS-Based Neural-Fuzzy Inference System and Particle Swarm Optimization for Forest Fire Susceptibility Modeling at a Tropical Area. Agric. For. Meteorol. 2017, 233, 32–44. [Google Scholar] [CrossRef]
- Jain, P.; Coogan, S.C.P.; Subramanian, S.G.; Crowley, M.; Taylor, S.; Flannigan, M.D. A Review of Machine Learning Applications in Wildfire Science and Management. Environ. Rev. 2020, 28, 478–505. [Google Scholar] [CrossRef]
- Jaafari, A.; Zenner, E.K.; Panahi, M.; Shahabi, H. Hybrid Artificial Intelligence Models Based on a Neuro-Fuzzy System and Metaheuristic Optimization Algorithms for Spatial Prediction of Wildfire Probability. Agric. For. Meteorol. 2019, 266–267, 198–207. [Google Scholar] [CrossRef]
- de Bem, P.P.; de Carvalho Júnior, O.A.; Matricardi, E.A.T.; Guimarães, R.F.; Gomes, R.A.T. Predicting Wildfire Vulnerability Using Logistic Regression and Artificial Neural Networks: A Case Study in Brazil’s Federal District. Int. J. Wildland Fire 2019, 28, 35. [Google Scholar] [CrossRef]
- Elia, M.; D’Este, M.; Ascoli, D.; Giannico, V.; Spano, G.; Ganga, A.; Colangelo, G.; Lafortezza, R.; Sanesi, G. Estimating the Probability of Wildfire Occurrence in Mediterranean Landscapes Using Artificial Neural Networks. Environ. Impact Assess. Rev. 2020, 85, 106474. [Google Scholar] [CrossRef]
- Jaafari, A.; Pourghasemi, H.R. Factors Influencing Regional-Scale Wildfire Probability in Iran. In Spatial Modeling in GIS and R for Earth and Environmental Sciences; Elsevier: Amsterdam, The Netherlands, 2019; pp. 607–619. ISBN 978-0-12-815226-3. [Google Scholar]
- Jaafari, A.; Zenner, E.K.; Pham, B.T. Wildfire Spatial Pattern Analysis in the Zagros Mountains, Iran: A Comparative Study of Decision Tree Based Classifiers. Ecol. Inform. 2018, 43, 200–211. [Google Scholar] [CrossRef]
- Jaafari, A.; Razavi Termeh, S.V.; Bui, D.T. Genetic and Firefly Metaheuristic Algorithms for an Optimized Neuro-Fuzzy Prediction Modeling of Wildfire Probability. J. Environ. Manag. 2019, 243, 358–369. [Google Scholar] [CrossRef] [PubMed]
- Pereira, J.; Mendes, J.; Júnior, J.S.S.; Viegas, C.; Paulo, J.R. A Review of Genetic Algorithm Approaches for Wildfire Spread Prediction Calibration. Mathematics 2022, 10, 300. [Google Scholar] [CrossRef]
- Guo, F.; Wang, G.; Su, Z.; Liang, H.; Wang, W.; Lin, F.; Liu, A. What Drives Forest Fire in Fujian, China? Evidence from Logistic Regression and Random Forests. Int. J. Wildland Fire 2016, 25, 505. [Google Scholar] [CrossRef]
- Zhao, P.; Zhang, F.; Lin, H.; Xu, S. GIS-Based Forest Fire Risk Model: A Case Study in Laoshan National Forest Park, Nanjing. Remote Sens. 2021, 13, 3704. [Google Scholar] [CrossRef]
- Yang, X.; Jin, X.; Zhou, Y. Wildfire Risk Assessment and Zoning by Integrating Maxent and GIS in Hunan Province, China. Forests 2021, 12, 1299. [Google Scholar] [CrossRef]
- Sharma, L.K.; Gupta, R.; Fatima, N. Assessing the Predictive Efficacy of Six Machine Learning Algorithms for the Susceptibility of Indian Forests to Fire. Int. J. Wildland Fire 2022, 31, 735–758. [Google Scholar] [CrossRef]
- Shmuel, A.; Heifetz, E. Global Wildfire Susceptibility Mapping Based on Machine Learning Models. Forests 2022, 13, 1050. [Google Scholar] [CrossRef]
- Nur, A.S.; Kim, Y.J.; Lee, C.-W. Creation of Wildfire Susceptibility Maps in Plumas National Forest Using InSAR Coherence, Deep Learning, and Metaheuristic Optimization Approaches. Remote Sens. 2022, 14, 4416. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, Z.; Ying, H.; Chen, J.; Zhen, S.; Wang, X.; Shan, Y. The Spatial Patterns of Climate-Fire Relationships on the Mongolian Plateau. Agric. For. Meteorol. 2021, 308–309, 108549. [Google Scholar] [CrossRef]
- Giglio, L.; Randerson, J.T.; van der Werf, G.R. Analysis of Daily, Monthly, and Annual Burned Area Using the Fourth-Generation Global Fire Emissions Database (GFED4): ANALYSIS OF BURNED AREA. J. Geophys. Res. Biogeosci. 2013, 118, 317–328. [Google Scholar] [CrossRef] [Green Version]
- Chen, D.; Shevade, V.; Baer, A.; Loboda, T.V. Missing Burns in the High Northern Latitudes: The Case for Regionally Focused Burned Area Products. Remote Sens. 2021, 13, 4145. [Google Scholar] [CrossRef]
- Giglio, L.; Boschetti, L.; Roy, D.P.; Humber, M.L.; Justice, C.O. The Collection 6 MODIS Burned Area Mapping Algorithm and Product. Remote Sens. Environ. 2018, 217, 72–85. [Google Scholar] [CrossRef]
- Liu, Y.; Goodrick, S.; Heilman, W. Wildland Fire Emissions, Carbon, and Climate: Wildfire–Climate Interactions. For. Ecol. Manag. 2014, 317, 80–96. [Google Scholar] [CrossRef]
- Westerling, A.L.; Bryant, B.P. Climate Change and Wildfire in California. Clim. Change 2008, 87, 231–249. [Google Scholar] [CrossRef]
- Gralewicz, N.J.; Nelson, T.A.; Wulder, M.A. Factors Influencing National Scale Wildfire Susceptibility in Canada. For. Ecol. Manag. 2012, 265, 20–29. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification And Regression Trees, 1st ed.; Routledge: London, UK, 2017; ISBN 978-1-315-13947-0. [Google Scholar]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. Multi-Scale Object-Based Image Analysis and Feature Selection of Multi-Sensor Earth Observation Imagery Using Random Forests. Int. J. Remote Sens. 2012, 33, 4502–4526. [Google Scholar] [CrossRef]
- Hong, H. Flood Susceptibility Assessment in Hengfeng Area Coupling Adaptive Neuro-Fuzzy Inference System with Genetic Algorithm and Differential Evolution. Sci. Total Environ. 2018, 621, 1124–1141. [Google Scholar] [CrossRef] [PubMed]
- Jang, J.S.R.; Sun, C.T.; Mizutani, E. Neuro-Fuzzy and Soft Computing-A Computational Approach to Learning and Machine Intelligence [Book Review]. IEEE Trans. Automat. Contr. 1997, 42, 1482–1484. [Google Scholar] [CrossRef]
- Abdollahizad, S.; Balafar, M.A.; Feizizadeh, B.; Babazadeh Sangar, A.; Samadzamini, K. Using Hybrid Artificial Intelligence Approach Based on a Neuro-Fuzzy System and Evolutionary Algorithms for Modeling Landslide Susceptibility in East Azerbaijan Province, Iran. Earth Sci. Inf. 2021, 14, 1861–1882. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Rostamzadeh, H.; Blaschke, T.; Gholaminia, K.; Aryal, J. A New GIS-Based Data Mining Technique Using an Adaptive Neuro-Fuzzy Inference System (ANFIS) and k-Fold Cross-Validation Approach for Land Subsidence Susceptibility Mapping. Nat. Hazards 2018, 94, 497–517. [Google Scholar] [CrossRef] [Green Version]
- Shirmohammadi, B.; Moradi, H.; Moosavi, V.; Semiromi, M.T.; Zeinali, A. Forecasting of Meteorological Drought Using Wavelet-ANFIS Hybrid Model for Different Time Steps (Case Study: Southeastern Part of East Azerbaijan Province, Iran). Nat. Hazards 2013, 69, 389–402. [Google Scholar] [CrossRef]
- Tien Bui, D.; Khosravi, K.; Li, S.; Shahabi, H.; Panahi, M.; Singh, V.; Chapi, K.; Shirzadi, A.; Panahi, S.; Chen, W.; et al. New Hybrids of ANFIS with Several Optimization Algorithms for Flood Susceptibility Modeling. Water 2018, 10, 1210. [Google Scholar] [CrossRef] [Green Version]
- Rambod, M.; Rezaeian, J. Robust Meta-Heuristics Implementation for Unrelated Parallel Machines Scheduling Problem with Rework Processes and Machine Eligibility Restrictions. Comput. Ind. Eng. 2014, 77, 15–28. [Google Scholar] [CrossRef]
- Poli, R.; Kennedy, J.; Blackwell, T. Particle Swarm Optimization: An Overview. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Soleimani, H.; Kannan, G. A Hybrid Particle Swarm Optimization and Genetic Algorithm for Closed-Loop Supply Chain Network Design in Large-Scale Networks. Appl. Math. Model. 2015, 39, 3990–4012. [Google Scholar] [CrossRef]
- Eberhart, R.; Kennedy, J. A New Optimizer Using Particle Swarm Theory. In Proceedings of the Sixth International Symposium on Micro Machine and Human Science, MHS’95, Nagoya, Japan, 4–6 October 1995; IEEE: Nagoya, Japan, 1995; pp. 39–43. [Google Scholar]
- Diaz-Uriarte, R. GeneSrF and VarSelRF: A Web-Based Tool and R Package for Gene Selection and Classification Using Random Forest. BMC Bioinform. 2007, 8, 328. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; El-Haddad, B.A.; Dhahry, B.K. Landslide Susceptibility Maps Using Different Probabilistic and Bivariate Statistical Models and Comparison of Their Performance at Wadi Itwad Basin, Asir Region, Saudi Arabia. Bull. Eng. Geol. Environ. 2016, 75, 63–87. [Google Scholar] [CrossRef]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A Novel Hybrid Artificial Intelligence Approach for Flood Susceptibility Assessment. Environ. Model. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Rossi, M. Forest Fire Susceptibility Mapping in the Minudasht Forests, Golestan Province, Iran. Environ. Earth Sci. 2015, 73, 1515–1533. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Aretano, R.; Semeraro, T. Investigation of General Indicators Influencing on Forest Fire and Its Susceptibility Modeling Using Different Data Mining Techniques. Ecol. Indic. 2016, 64, 72–84. [Google Scholar] [CrossRef]
- Sexton, R.S.; Dorsey, R.E.; Johnson, J.D. Toward Global Optimization of Neural Networks: A Comparison of the Genetic Algorithm and Backpropagation. Decis. Support Syst. 1998, 22, 171–185. [Google Scholar] [CrossRef]
- Tahmasebi, P.; Hezarkhani, A. A Hybrid Neural Networks-Fuzzy Logic-Genetic Algorithm for Grade Estimation. Comput. Geosci. 2012, 42, 18–27. [Google Scholar] [CrossRef] [Green Version]
- Moosavi, V.; Niazi, Y. Development of Hybrid Wavelet Packet-Statistical Models (WP-SM) for Landslide Susceptibility Mapping. Landslides 2016, 13, 97–114. [Google Scholar] [CrossRef]
- Moayedi, H.; Khari, M.; Bahiraei, M. Spatial Assessment of Landslide Risk Using Two Novel Integrations of Neuro-Fuzzy System and Metaheuristic Approaches; Ardabil Province, Iran. Geomat. Nat. Hazards Risk 2020, 11, 230–258. [Google Scholar] [CrossRef] [Green Version]
- Cortez, P.; Morais, A. New Trends in Artificial Intelligence. In Proceedings of the 13th Portuguese Conference on Artificial Intelligence (EPIA 2007), Guimarães, Portugal, 3–7 December 2007; APPIA: Lisbon, Portugal, 2007; pp. 512–523, ISBN 978-989-95618-0-9. [Google Scholar]
- Nebot, À.; Mugica, F. Forest Fire Forecasting Using Fuzzy Logic Models. Forests 2021, 12, 1005. [Google Scholar] [CrossRef]
- Adab, H.; Kanniah, K.D.; Solaimani, K. Modeling Forest Fire Risk in the Northeast of Iran Using Remote Sensing and GIS Techniques. Nat. Hazards 2013, 65, 1723–1743. [Google Scholar] [CrossRef]
- Chen, W.; Panahi, M.; Pourghasemi, H.R. Performance Evaluation of GIS-Based New Ensemble Data Mining Techniques of Adaptive Neuro-Fuzzy Inference System (ANFIS) with Genetic Algorithm (GA), Differential Evolution (DE), and Particle Swarm Optimization (PSO) for Landslide Spatial Modelling. CATENA 2017, 157, 310–324. [Google Scholar] [CrossRef]
- Tien Bui, D.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Landslide Susceptibility Assessment in the Hoa Binh Province of Vietnam: A Comparison of the Levenberg–Marquardt and Bayesian Regularized Neural Networks. Geomorphology 2012, 171–172, 12–29. [Google Scholar] [CrossRef]
- Holden, Z.A.; Swanson, A.; Luce, C.H.; Jolly, W.M.; Maneta, M.; Oyler, J.W.; Warren, D.A.; Parsons, R.; Affleck, D. Decreasing Fire Season Precipitation Increased Recent Western US Forest Wildfire Activity. Proc. Natl. Acad. Sci. USA 2018, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, M.; Zhao, J.; Guo, X.; Zhang, Z.; Tan, G.; Yang, J. Study on Climate and Grassland Fire in HulunBuir, Inner Mongolia Autonomous Region, China. Sensors 2017, 17, 616. [Google Scholar] [CrossRef] [Green Version]
- Ganteaume, A.; Long-Fournel, M. Driving Factors of Fire Density Can Spatially Vary at the Local Scale in South-Eastern France. Int. J. Wildland Fire 2015, 24, 650. [Google Scholar] [CrossRef]
- Rihan, W.; Zhao, J.; Zhang, H.; Guo, X.; Ying, H.; Deng, G.; Li, H. Wildfires on the Mongolian Plateau: Identifying Drivers and Spatial Distributions to Predict Wildfire Probability. Remote Sens. 2019, 11, 2361. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Variable | Implication | Scale | Source |
|---|---|---|---|---|
| Climate | PRE | Precipitation | 0.5˚ | CRU TS v.4.03 database, British Atmospheric Data Centre (BADC) |
| DTR | Diurnal temperature range | |||
| WET | Rain daily frequency | |||
| PDSI | Self-calculation Palmer drought index | |||
| TMN | Monthly minimum temperature | |||
| TMX | Monthly maximum temperature | |||
| PET | Potential evapotranspiration | |||
| TMP | Monthly mean temperature | |||
| VAP | Saturated vapor pressure | |||
| FRS | Frost daily frequency | |||
| Topography | ELE | Elevation | 30 m | Geospatial Data Cloud |
| SLOPE | Slope | |||
| ASPECT | Aspect | |||
| Vegetation | NDVI | Normalized vegetation index | 500 m | National Aeronautics and Space Administration (NASA) |
| LUCC | Land use/land cover | 500 m | ||
| Anthropogenic factors | ACC | Actual carrying capacity | 1 km | Gridded Livestock of the World (GLW), Harvard Dataverse |
| DMSP | Night-light intensity | 1 km | Geospatial Data Cloud |
| Accuracy | Sample1 | Sample2 | Sample3 | Sample4 | Sample5 |
|---|---|---|---|---|---|
| Average | 0.9325 | 0.9311 | 0.9328 | 0.9327 | 0.9324 |
| Burned | 0.9552 | 0.9496 | 0.9613 | 0.9553 | 0.9549 |
| Unburned | 0.9113 | 0.9138 | 0.9061 | 0.9116 | 0.9114 |
| Model | Dataset | RMSE | Sensitivity | Specificity | Success Rate | Prediction Rate |
|---|---|---|---|---|---|---|
| ANFIS | Training | 0.432 | 0.84 | 0.66 | 0.796 | — |
| Validation | 0.512 | 0.78 | 0.47 | — | 0.597 | |
| PSO-ANFIS | Training | 0.353 | 0.86 | 0.81 | 0.898 | — |
| Validation | 0.497 | 0.86 | 0.81 | — | 0.835 | |
| GA-ANFIS | Training | 0.396 | 0.88 | 0.69 | 0.862 | — |
| Validation | 0.507 | 0.83 | 0.74 | — | 0.786 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Xu, S.; Fan, Z.; Zhang, X.; Yang, X.; Wen, S.; Shi, Z. Risk Factors and Prediction of the Probability of Wildfire Occurrence in the China–Mongolia–Russia Cross-Border Area. Remote Sens. 2023, 15, 42. https://doi.org/10.3390/rs15010042
Li Y, Xu S, Fan Z, Zhang X, Yang X, Wen S, Shi Z. Risk Factors and Prediction of the Probability of Wildfire Occurrence in the China–Mongolia–Russia Cross-Border Area. Remote Sensing. 2023; 15(1):42. https://doi.org/10.3390/rs15010042
Chicago/Turabian StyleLi, Yuheng, Shuxing Xu, Zhaofei Fan, Xiao Zhang, Xiaohui Yang, Shuo Wen, and Zhongjie Shi. 2023. "Risk Factors and Prediction of the Probability of Wildfire Occurrence in the China–Mongolia–Russia Cross-Border Area" Remote Sensing 15, no. 1: 42. https://doi.org/10.3390/rs15010042
APA StyleLi, Y., Xu, S., Fan, Z., Zhang, X., Yang, X., Wen, S., & Shi, Z. (2023). Risk Factors and Prediction of the Probability of Wildfire Occurrence in the China–Mongolia–Russia Cross-Border Area. Remote Sensing, 15(1), 42. https://doi.org/10.3390/rs15010042