
Aircraft-LBDet: Multi-Task Aircraft Detection with Landmark and Bounding Box Detection

Abstract
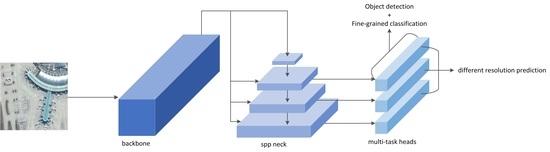
:
1. Introduction
- We propose a multi-task joint training method for remote sensing aircraft detection, within which landmark detection provides stronger semantic structural features for bounding box localization in dense areas, which helps to improve the accuracy of aircraft detection and recognition;
- We propose a multi-task joint inference algorithm, within which landmarks provide more accurate supervision for the NMS filtering of bounding boxes, thus substantially reducing post-processing complexity and effectively reducing false positives;
- We optimize the landmark loss function for more effective multi-task learning, thereby further improving the accuracy of aircraft detection.
2. Related Work
2.1. General Object Detection Methods
2.2. Object Detection in Remote Sensing Images
3. Proposed Method
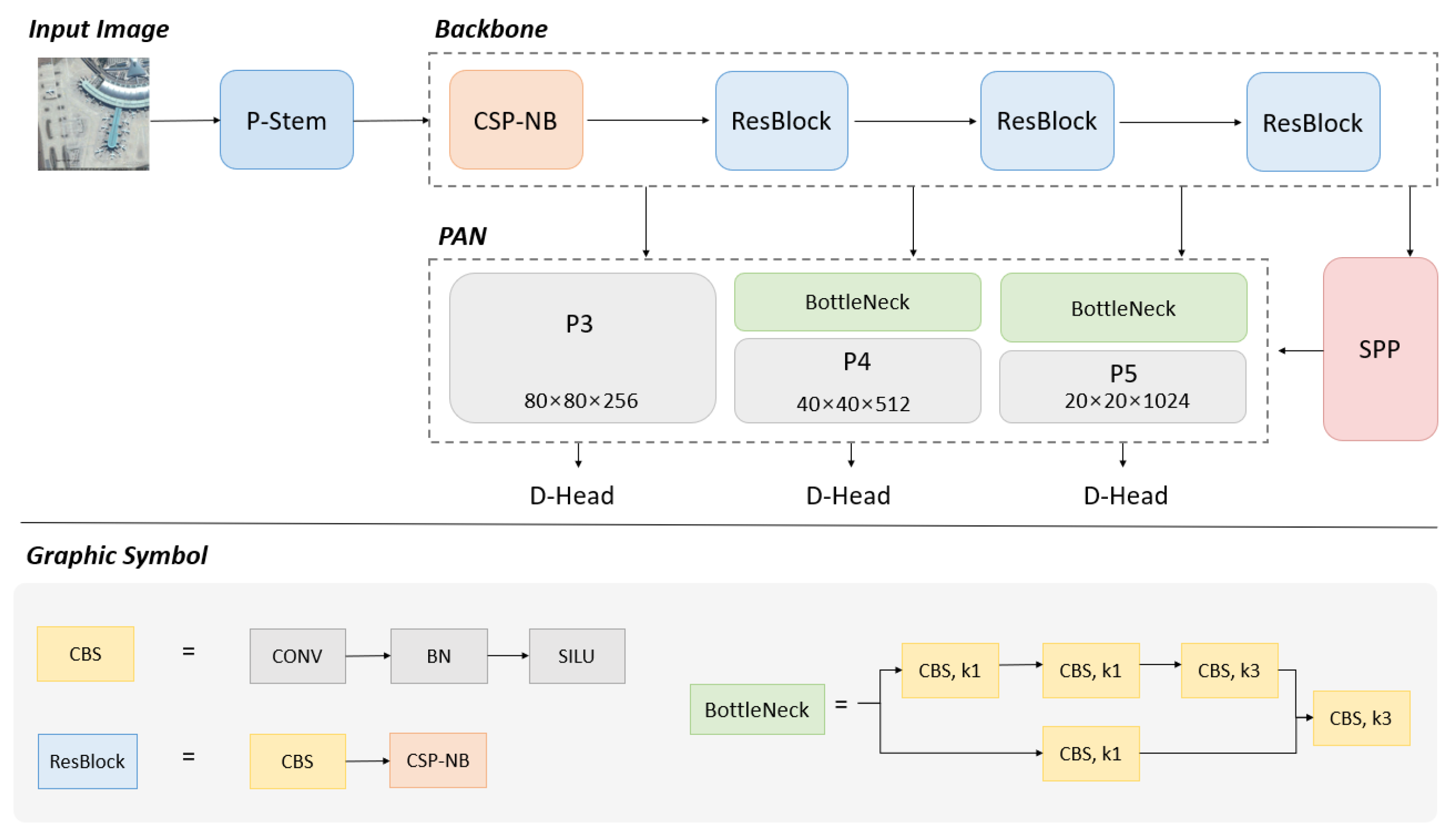
3.1. Overview
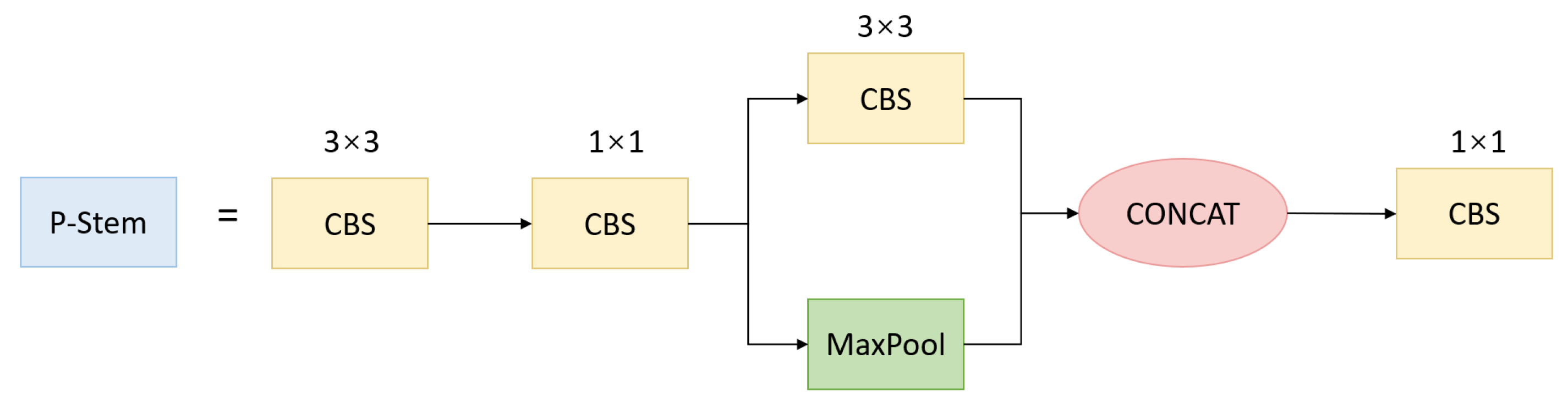
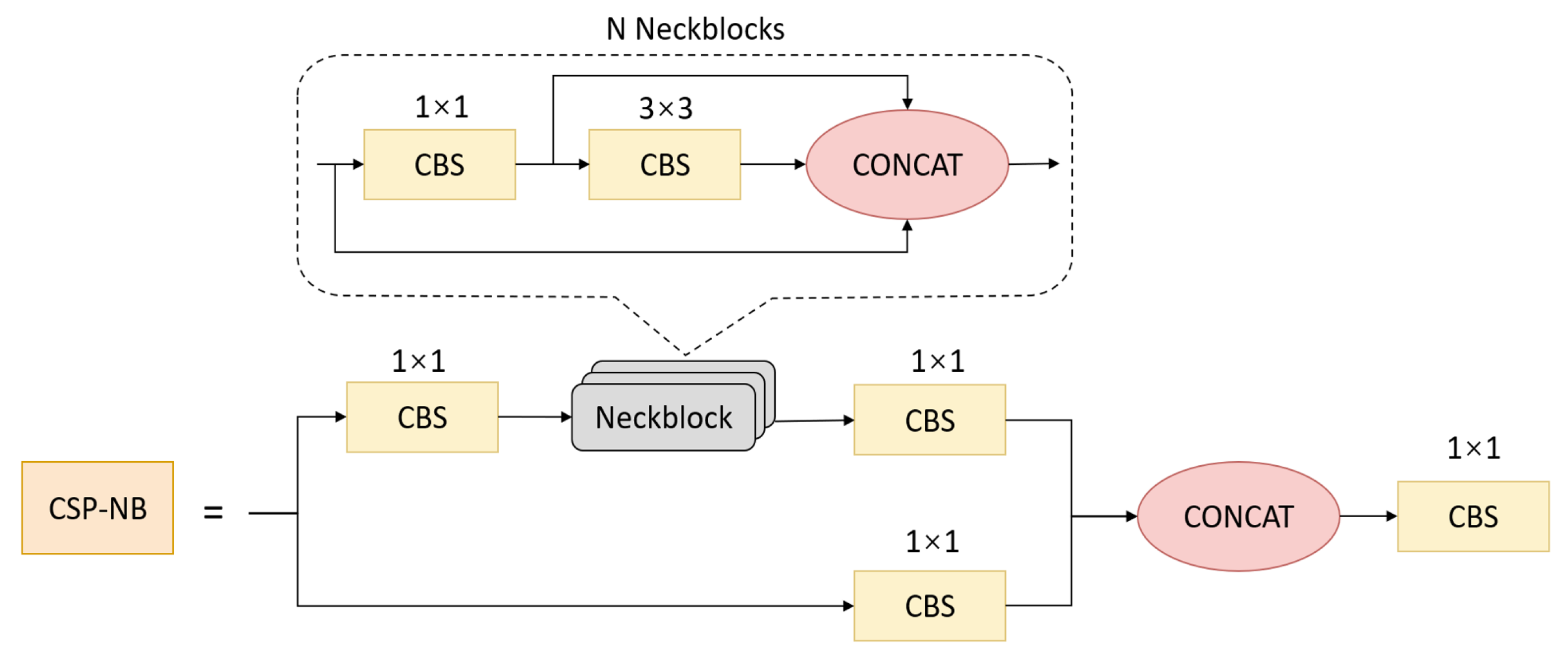
3.2. Feature Extraction Backbone
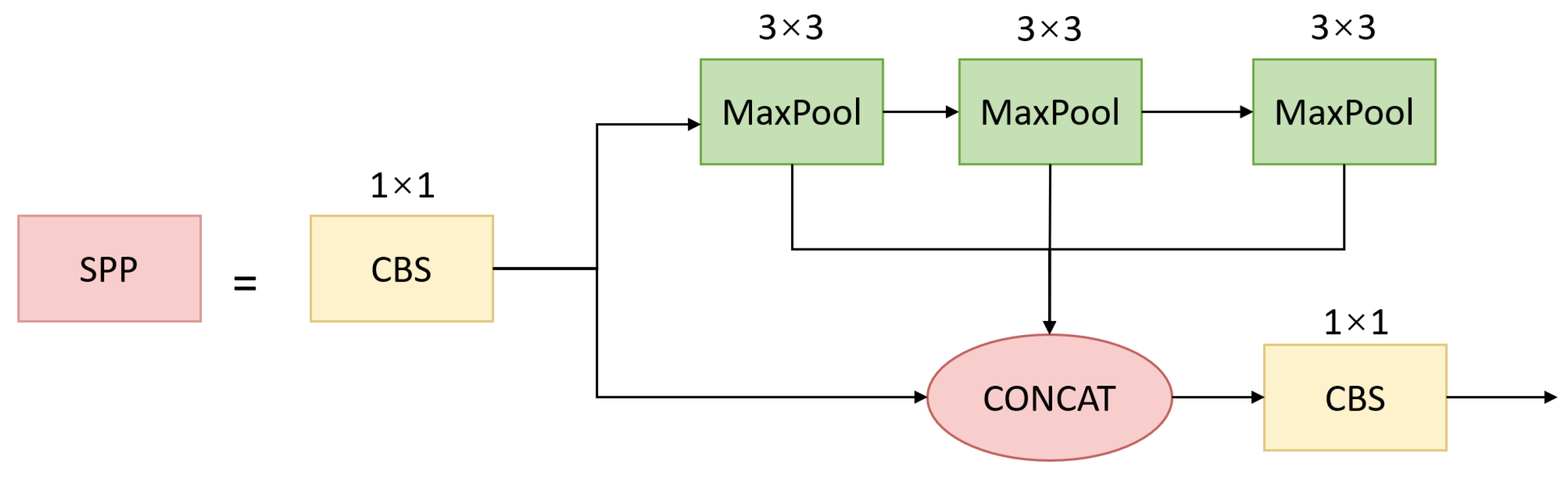
3.3. Multi-Scale Feature Pyramid Module
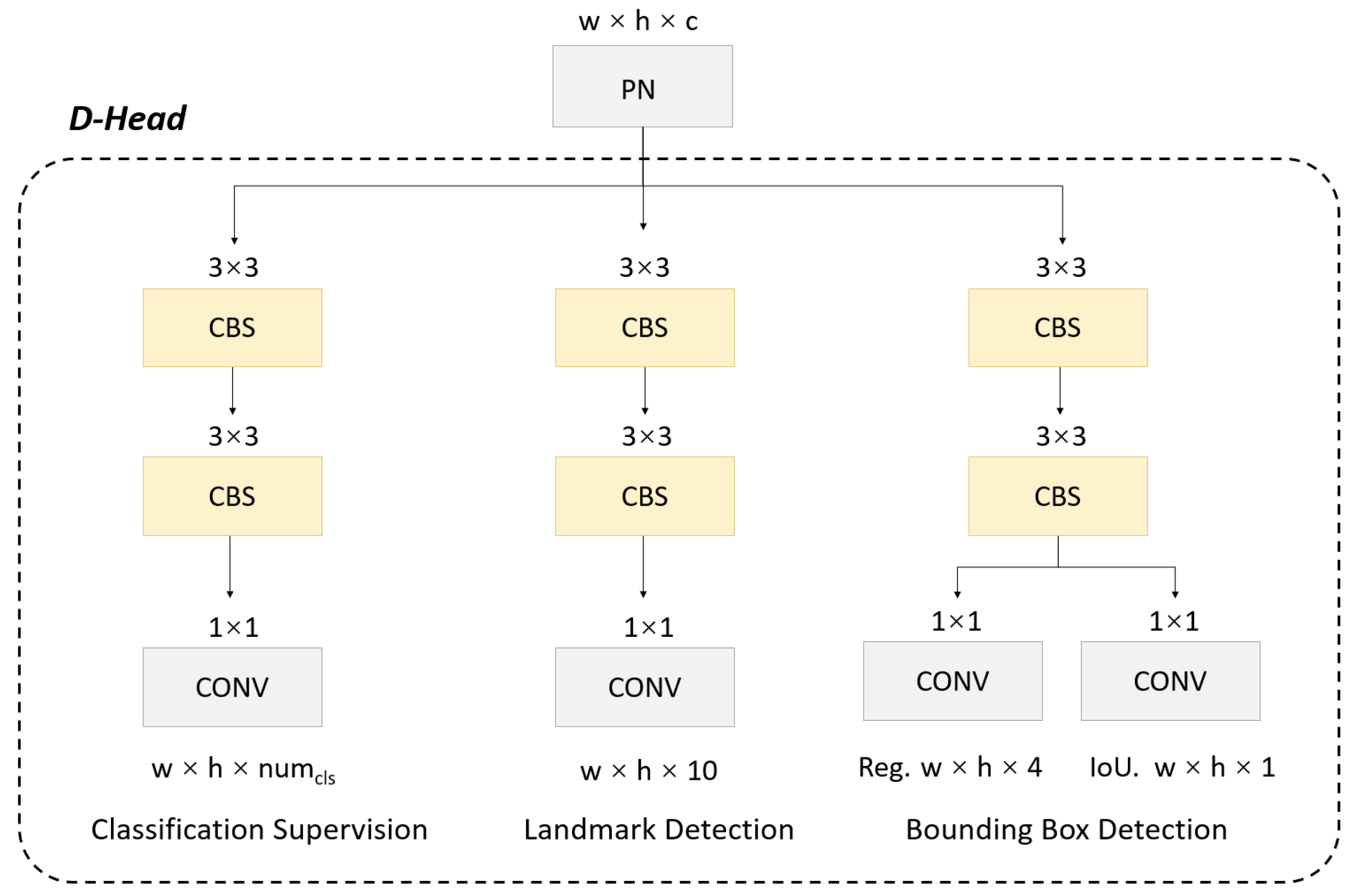
3.4. Object and Landmark Detection Head
3.5. Central-Constraint NMS
| Algorithm 1 Central-constraint non-maximum suppression (central-constraint NMS) algorithm. |
| Inputs: ; A represents the list of initial detection boxes; P contains the corresponding detection scores; t denotes the NMS threshold. |
| Output: |
| 1: |
| 2: while do: |
| 3: for do: |
| 4: ScoreUpdate() |
| 5: end |
| 6: |
| 7: |
| 8: |
| 9: for do: |
| 10: if then: |
| 11: |
| 12: end |
| 13: end |
| 14: end |
| 15: return |
3.6. Landmark Box Loss Function
4. Results
4.1. Dataset
4.2. Implementation Details
4.3. Comparison Experiments
4.4. Ablation Experiments
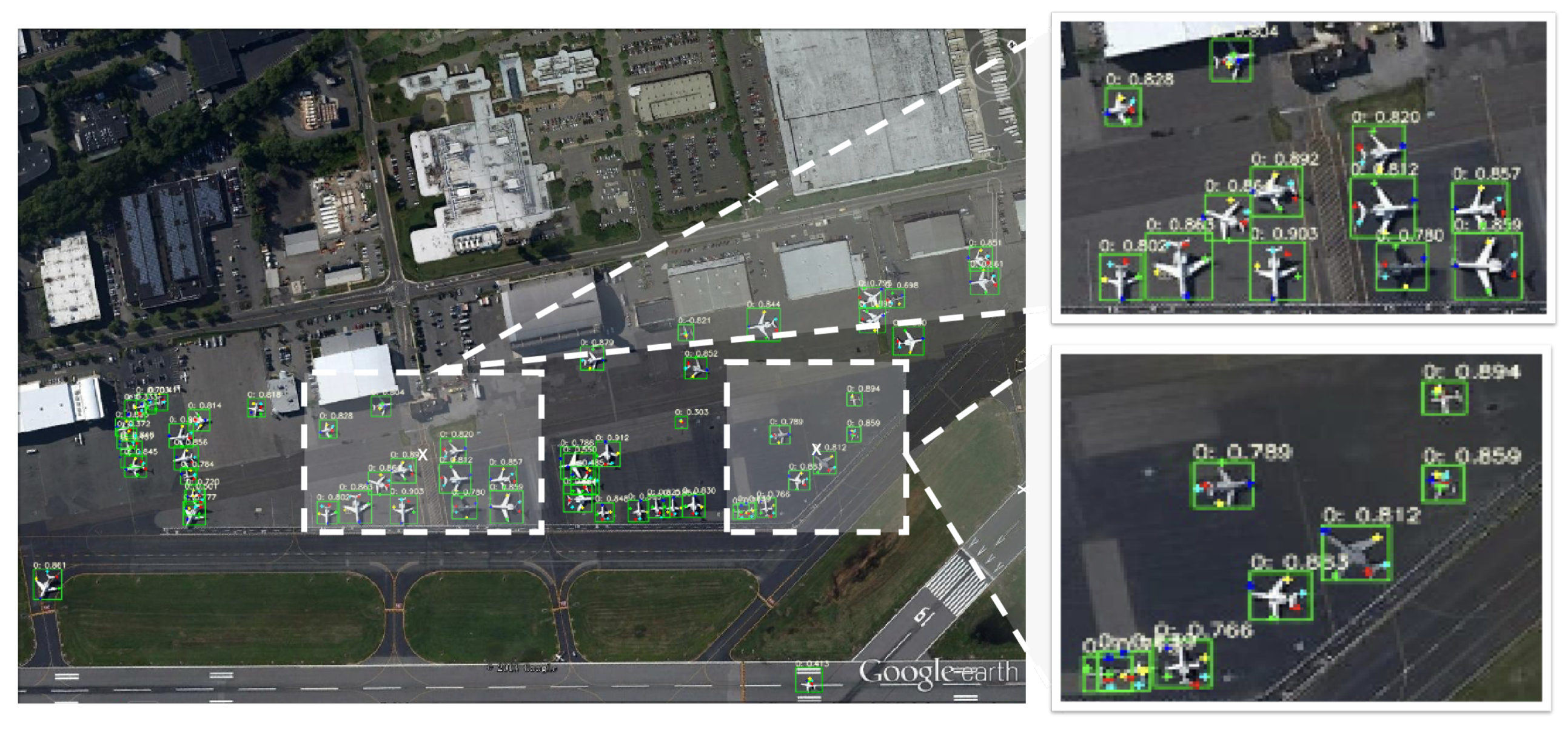
4.5. Visualization
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Zhang, H.; Xue, X.; Jiang, Y.; Shen, Q. Deep learning for remote sensing image classification: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1264. [Google Scholar] [CrossRef]
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of image classification algorithms based on convolutional neural networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Rajendran, G.B.; Kumarasamy, U.M.; Zarro, C.; Divakarachari, P.B.; Ullo, S.L. Land-use and land-cover classification using a human group-based particle swarm optimization algorithm with an LSTM Classifier on hybrid pre-processing remote-sensing images. Remote Sens. 2020, 12, 4135. [Google Scholar] [CrossRef]
- Wu, H.; Prasad, S. Semi-supervised deep learning using pseudo labels for hyperspectral image classification. IEEE Trans. Image Process. 2017, 27, 1259–1270. [Google Scholar] [CrossRef]
- Zhou, F.; Hang, R.; Liu, Q.; Yuan, X. Hyperspectral image classification using spectral-spatial LSTMs. Neurocomputing 2019, 328, 39–47. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Zhao, P.; Gao, H.; Zhang, Y.; Li, H.; Yang, R. An aircraft detection method based on improved mask R-CNN in remotely sensed imagery. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1370–1373. [Google Scholar]
- Han, Q.; Yin, Q.; Zheng, X.; Chen, Z. Remote sensing image building detection method based on Mask R-CNN. Complex Intell. Syst. 2021, 8, 1847–1855. [Google Scholar] [CrossRef]
- Chen, J.; Sun, J.; Li, Y.; Hou, C. Object detection in remote sensing images based on deep transfer learning. Multimed. Tools Appl. 2022, 81, 12093–12109. [Google Scholar] [CrossRef]
- Yu, D.; Ji, S. A new spatial-oriented object detection framework for remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Shivappriya, S.; Priyadarsini, M.J.P.; Stateczny, A.; Puttamadappa, C.; Parameshachari, B. Cascade object detection and remote sensing object detection method based on trainable activation function. Remote Sens. 2021, 13, 200. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Gu, W.; Lv, Z.; Hao, M. Change detection method for remote sensing images based on an improved Markov random field. Multimed. Tools Appl. 2017, 76, 17719–17734. [Google Scholar] [CrossRef]
- Shafique, A.; Cao, G.; Khan, Z.; Asad, M.; Aslam, M. Deep learning-based change detection in remote sensing images: A review. Remote Sens. 2022, 14, 871. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention network for semantic segmentation of fine-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Dong, Y.; Chen, F.; Han, S.; Liu, H. Ship object detection of remote sensing image based on visual attention. Remote Sens. 2021, 13, 3192. [Google Scholar] [CrossRef]
- Jian, L.; Pu, Z.; Zhu, L.; Yao, T.; Liang, X. SS R-CNN: Self-Supervised learning improving mask R-CNN for ship detection in remote sensing images. Remote Sens. 2022, 14, 4383. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-grained visual classification of aircraft. arXiv 2013, arXiv:1306.5151. [Google Scholar]
- Yu, L.; Hu, H.; Zhong, Z.; Wu, H.; Deng, Q. GLF-Net: A target detection method based on global and local multiscale feature fusion of remote sensing aircraft images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, N.; Xu, H.; Liu, Y.; Tian, T.; Tian, J. AFA-NET: Adaptive feature aggregation network for aircraft fine-grained detection in cloudy remote sensing images. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 1704–1707. [Google Scholar]
- Wei, H.; Zhang, Y.; Wang, B.; Yang, Y.; Li, H.; Wang, H. X-LineNet: Detecting aircraft in remote sensing images by a pair of intersecting line segments. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1645–1659. [Google Scholar] [CrossRef]
- Liu, C.; Yu, H.; Wei, H.; Sun, X.; Fu, K. S2CGNet: A robust aircraft detector based on the sword-shaped component geometry. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, J.; Li, W.; Shan, P.; Wang, X.; Li, L.; Fu, Q. MS-IAF: Multi-Scale information augmentation framework for aircraft detection. Remote Sens. 2022, 14, 3696. [Google Scholar] [CrossRef]
- Kwon, H. Adversarial image perturbations with distortions weighted by color on deep neural networks. Multimed. Tools Appl. 2023, 82, 13779–13795. [Google Scholar] [CrossRef]
- Kwon, H.; Kim, S. Dual-Mode Method for Generating Adversarial Examples to Attack Deep Neural Networks. IEEE Access 2023, 1. [Google Scholar] [CrossRef]
- Kwon, H.; Lee, S. Toward Backdoor Attacks for Image Captioning Model in Deep Neural Networks. Secur. Commun. Netw. 2022, 2022, 1525052. [Google Scholar] [CrossRef]
- Kwon, H.; Lee, J. AdvGuard: Fortifying deep neural networks against optimized adversarial example attack. IEEE Access 2020, 1. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9657–9666. [Google Scholar]
- Dong, Z.; Li, G.; Liao, Y.; Wang, F.; Ren, P.; Qian, C. Centripetalnet: Pursuing high-quality keypoint pairs for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10519–10528. [Google Scholar]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-insensitive and context-augmented object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2337–2348. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Qian, X.; Lin, S.; Cheng, G.; Yao, X.; Ren, H.; Wang, W. Object detection in remote sensing images based on improved bounding box regression and multi-level features fusion. Remote Sens. 2020, 12, 143. [Google Scholar] [CrossRef]
- Yao, Q.; Hu, X.; Lei, H. Multiscale convolutional neural networks for geospatial object detection in VHR satellite images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 23–27. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. ABNet: Adaptive balanced network for multi-scale object detection in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Ye, Y.; Ren, X.; Zhu, B.; Tang, T.; Tan, X.; Gui, Y.; Yao, Q. An adaptive attention fusion mechanism convolutional network for object detection in remote sensing images. Remote Sens. 2022, 14, 516. [Google Scholar] [CrossRef]
- Liu, Q.; Xiang, X.; Wang, Y.; Luo, Z.; Fang, F. Aircraft detection in remote sensing image based on corner clustering and deep learning. Eng. Appl. Artif. Intell. 2020, 87, 103333. [Google Scholar] [CrossRef]
- Shi, L.; Tang, Z.; Wang, T.; Xu, X.; Liu, J.; Zhang, J. Aircraft detection in remote sensing images based on deconvolution and position attention. Int. J. Remote Sens. 2021, 42, 4241–4260. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, R.J.; Li, X.; Ling, C.X. Pelee: A real-time object detection system on mobile devices. In Proceedings of the Advances in Neural Information Processing Systems 2018, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9197–9206. [Google Scholar]
- Song, G.; Liu, Y.; Wang, X. Revisiting the sibling head in object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11563–11572. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2849–2858. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 677–694. [Google Scholar]
- Yang, X.; Hou, L.; Zhou, Y.; Wang, W.; Yan, J. Dense label encoding for boundary discontinuity free rotation detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 July 2021; pp. 15819–15829. [Google Scholar]
- Zhou, L.; Wei, H.; Li, H.; Zhao, W.; Zhang, Y.; Zhang, Y. Arbitrary-oriented object detection in remote sensing images based on polar coordinates. IEEE Access 2020, 8, 223373–223384. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, X.; Zhou, S.; Wang, Y. DARDet: A dense anchor-free rotated object detector in aerial images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AP | FPS | Model Size |
|---|---|---|---|
| Faster R-CNN [22] | 0.859 | 11 | 243.5 MB |
| SSD [39] | 0.896 | 17 | 144.2 MB |
| CornerNet [40] | 0.765 | 6.9 | 804.9 MB |
| Yolo v3 [27] | 0.864 | 25 | 248.1 MB |
| RetinaNet+FPN [59] | 0.901 | 7.2 | 228.4 MB |
| Yolo v5s | 0.859 | 80.6 | 14.17 MB |
| Ours | 0.904 | 94.3 | 13.8 MB |
| Method | AP0.5−0.95 | Flops (G) | FA | F1 |
|---|---|---|---|---|
| Yolo v5s | 0.667 | 26.3 | 0.121 | 0.928 |
| Ours | 0.675 | 15.3 | 0.073 | 0.956 |
| Method | Backbone | AP |
|---|---|---|
| FR-O [22] | ResNet-101 | 0.834 |
| ROI-trans [60] | ResNet-101 | 0.889 |
| FPN-CSL [61] | ResNet-101 | 0.892 |
| Det-DCL [62] | ResNet-101 | 0.893 |
| P-RSDet [63] | ResNet-101 | 0.900 |
| DARDet [64] | ResNet-50 | 0.903 |
| Ours | CSP-ResBlock | 0.904 |
| ID | a | b | c | d | e |
|---|---|---|---|---|---|
| Landmark Box Loss | ✓ | ✓ | ✓ | ✓ | |
| CSP-NB | ✓ | ✓ | ✓ | ||
| P-Stem | ✓ | ✓ | |||
| Central-Constraint NMS | ✓ | ||||
| AP | 0.795 | 0.844 | 0.886 | 0.902 | 0.904 |
| Comparison | - | 0.049 ↑ | 0.042 ↑ | 0.016 ↑ | 0.002 ↑ |
| Aircraft | Theoretical | Actual | ||
|---|---|---|---|---|
| Wingspan | Fuselage Length | Wingspan | Fuselage Length | |
| MD-90 | 32.9 | 39.5 | 35.4 (7.6% ↑) | 42.8 (8.4% ↑) |
| A330 | 60.3 | 58.8 | 64.1 (6.3% ↑) | 62.9 (7.0% ↑) |
| Boeing787 | 60.1 | 57.7 | 68.0 (13.1% ↑) | 60.5 (4.9% ↑) |
| Boeing777 | 64.8 | 63.7 | 71.4 (10.2% ↑) | 65.4 (2.7% ↑) |
| ARJ21 | 22.5 | 33.5 | 25.8 (14.7% ↑) | 36.7 (9.6% ↑) |
| Boeing747 | 68.5 | 70.6 | 69.3 (1.2% ↑) | 73.2 (3.7% ↑) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Zhou, D.; He, Y.; Zhao, L.; Cheng, P.; Li, H.; Chen, K. Aircraft-LBDet: Multi-Task Aircraft Detection with Landmark and Bounding Box Detection. Remote Sens. 2023, 15, 2485. https://doi.org/10.3390/rs15102485
Ma Y, Zhou D, He Y, Zhao L, Cheng P, Li H, Chen K. Aircraft-LBDet: Multi-Task Aircraft Detection with Landmark and Bounding Box Detection. Remote Sensing. 2023; 15(10):2485. https://doi.org/10.3390/rs15102485
Chicago/Turabian StyleMa, Yihang, Deyun Zhou, Yuting He, Liangjin Zhao, Peirui Cheng, Hao Li, and Kaiqiang Chen. 2023. "Aircraft-LBDet: Multi-Task Aircraft Detection with Landmark and Bounding Box Detection" Remote Sensing 15, no. 10: 2485. https://doi.org/10.3390/rs15102485
APA StyleMa, Y., Zhou, D., He, Y., Zhao, L., Cheng, P., Li, H., & Chen, K. (2023). Aircraft-LBDet: Multi-Task Aircraft Detection with Landmark and Bounding Box Detection. Remote Sensing, 15(10), 2485. https://doi.org/10.3390/rs15102485