

Improving Crop Mapping by Using Bidirectional Reflectance Distribution Function (BRDF) Signatures with Google Earth Engine




Abstract
:1. Introduction
2. Study Area and Data
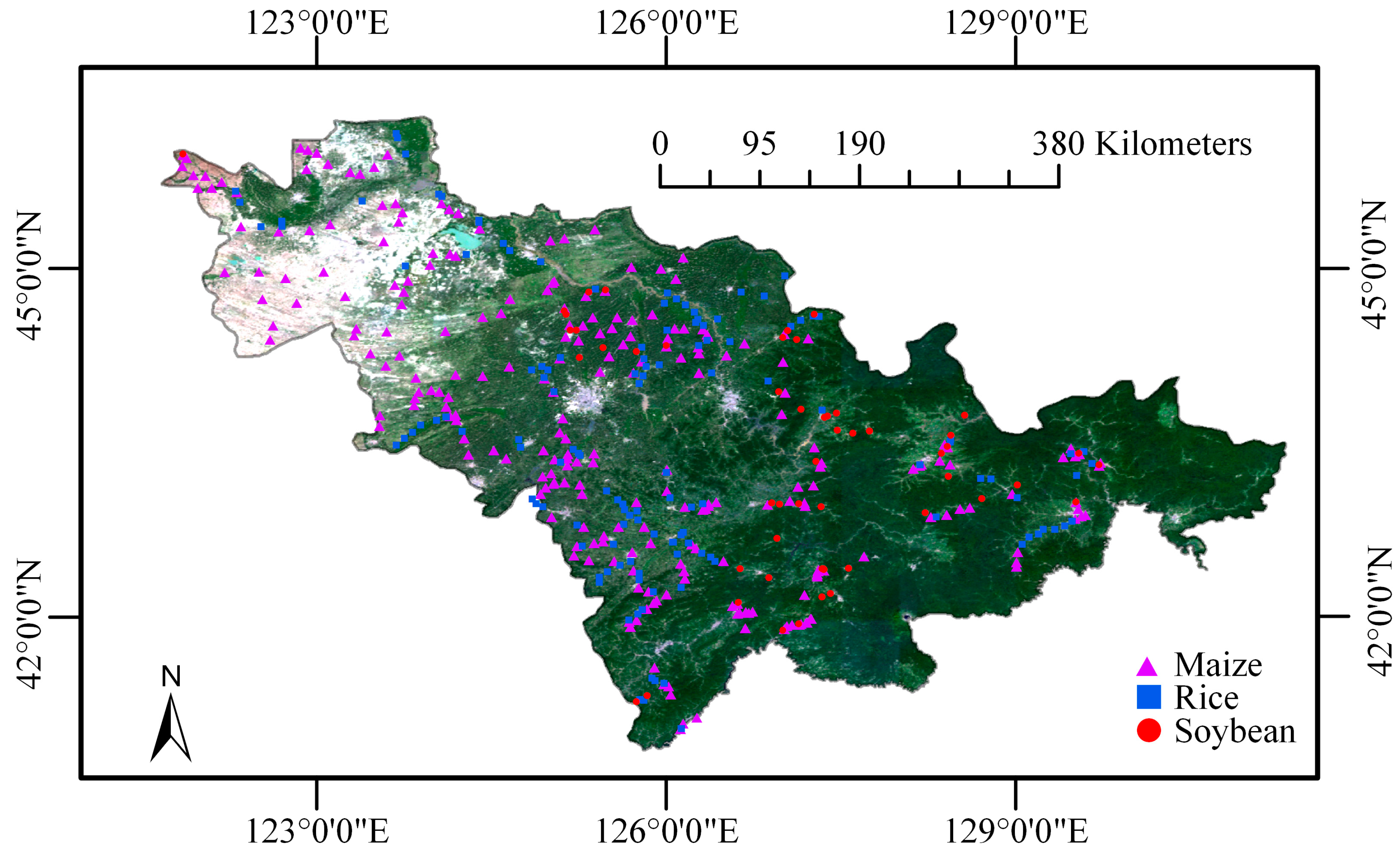
2.1. Study Area
2.2. Data
2.2.1. Reflectance Data
2.2.2. Cropland Boundary Data
2.2.3. Field Sampling Data
3. Methods
3.1. Overall Processing
3.2. Data Preprocessing
3.3. Supervised Classification
4. Classification Results and Accuracy Assessment
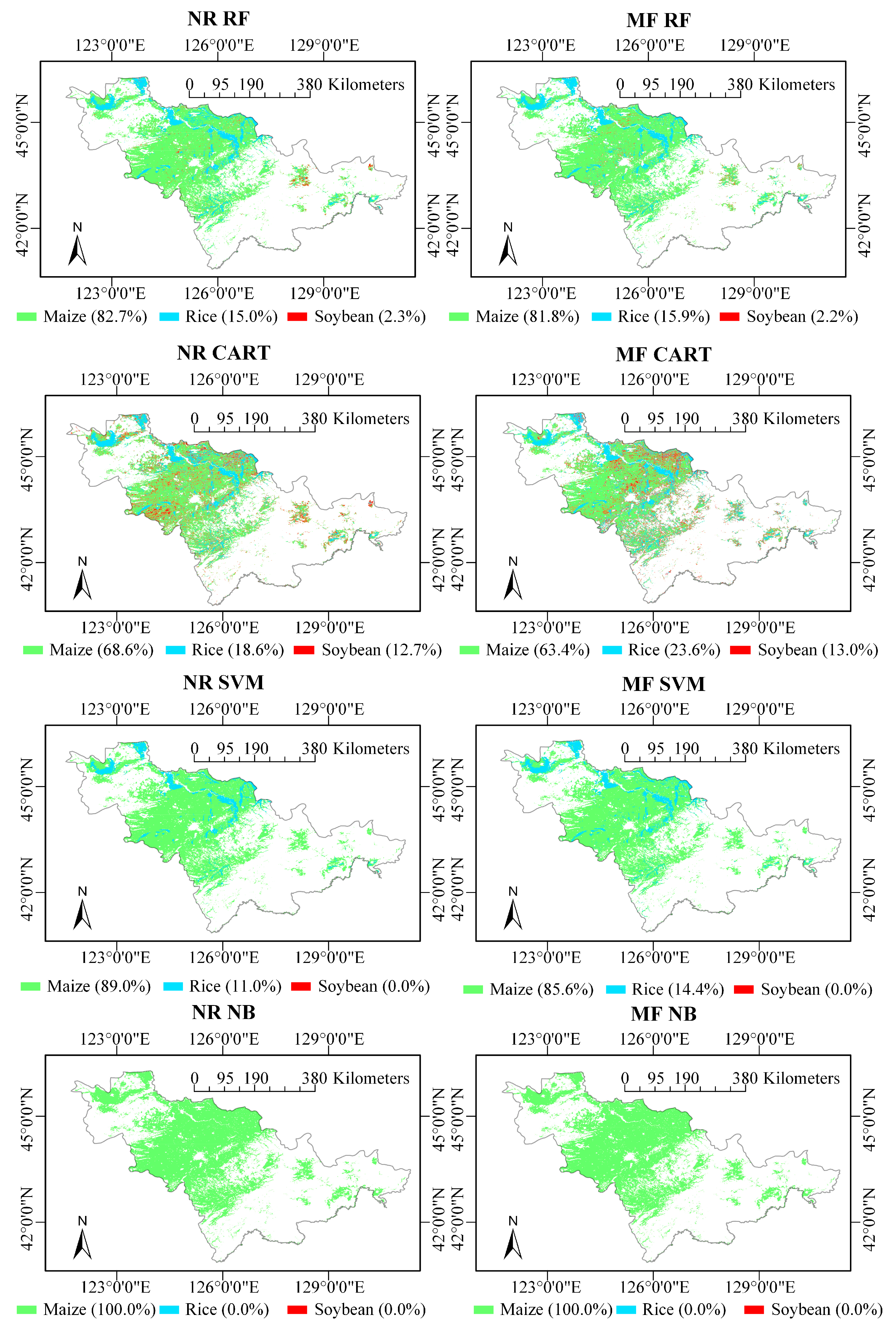
4.1. Classification Results
4.2. Accuracy Assessment
4.2.1. Evaluation of the Classifiers
4.2.2. Evaluation of the Multi-Angle Observations
4.2.3. Accuracy Comparison among Crop Types
5. Discussion and Conclusions
5.1. Discussion
5.1.1. Discussion of the Classifiers for Optical Data
5.1.2. Discussion of the Multi-Angle Optical Observations
5.1.3. Discussion of the Accuracy Comparison among Crop Types
5.2. Conclusions
- Using BRDF signatures leads to a moderate improvement in classification results compared to using reflectance data from a single nadir observation direction.
- Among the four classifiers, RF has the highest validation accuracy for crop mapping, followed by CART, SVM, and NB.
- The selection of a classifier plays a crucial role in classification accuracy, regardless of whether NR or MF data is used.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Kernel-Based BRDF Model
Appendix B. The Generation of the MCD43A1/MCD43A4 Product
Appendix C. The Generation of the MCD12Q1 Product
Appendix D. Supervised Machine Learning Classifiers in GEE
- (1)
- Random Forest
- (2)
- Classification and Regression Trees
- (3)
- Support Vector Machine
- (4)
- Naïve Bayes
References
- Khodadadzadeh, M.; Li, J.; Plaza, A.; Ghassemian, H.; Bioucas-Dias, J.M.; Li, X. Spectral–spatial classification of hyperspectral data using local and global probabilities for mixed pixel characterization. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6298–6314. [Google Scholar] [CrossRef]
- Song, T.; Wang, Y.; Gao, C.; Chen, H.; Li, J. Mslan: A two-branch multi-directional spectral-spatial lstm attention network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5528814. [Google Scholar] [CrossRef]
- Mahlayeye, M.; Darvishzadeh, R.; Nelson, A. Cropping Patterns of Annual Crops: A Remote Sensing Review. Remote Sens. 2022, 14, 2404. [Google Scholar] [CrossRef]
- Zhen, Z.; Chen, S.; Yin, T.; Chavanon, E.; Lauret, N.; Guilleux, J.; Henke, M.; Qin, W.; Cao, L.; Li, J.; et al. Using the Negative Soil Adjustment Factor of Soil Adjusted Vegetation Index (SAVI) to Resist Saturation Effects and Estimate Leaf Area Index (LAI) in Dense Vegetation Areas. Sensors 2021, 21, 2115. [Google Scholar] [CrossRef] [PubMed]
- Abdelmoula, H.; Kallel, A.; Roujean, J.-L.; Gastellu-Etchegorry, J.-P. Dynamic retrieval of olive tree properties using Bayesian model and Sentinel-2 images. IEEE J. Sel. Top. Appl. Earth Observ. 2021, 14, 9267–9286. [Google Scholar] [CrossRef]
- Zhen, Z. Simulation de la Réflectance de la Végétation et Inversion des Propriétés Bio-optiques Basées sur un Modèle de Transfert Radiatif Tridimensionnel. Ph.D. Thesis, Université de Toulouse, Toulouse, France, 2021. [Google Scholar]
- Zhen, Z.; Gastellu-Etchegorry, J.-P.; Chen, S.; Yin, T.; Chavanon, E.; Lauret, N.; Guilleux, J. Quantitative Analysis of DART Calibration Accuracy for Retrieving Spectral Signatures Over Urban Area. IEEE J. Sel. Top. Appl. Earth Observ. 2021, 14, 10057–10068. [Google Scholar] [CrossRef]
- Duthoit, S.; Demarez, V.; Gastellu-Etchegorry, J.-P.; Martin, E.; Roujean, J.-L. Assessing the effects of the clumping phenomenon on BRDF of a maize crop based on 3D numerical scenes using DART model. Agric. For. Meteorol. 2008, 148, 1341–1352. [Google Scholar] [CrossRef]
- Zhen, Z.; Chen, S.; Yin, T.; Gastellu-Etchegorry, J.-P. Spatial Resolution Requirements for the Application of Temperature and Emissivity Separation (TES) Algorithm over Urban Areas. IEEE J. Sel. Top. Appl. Earth Observ. 2022, 15, 1–15. [Google Scholar] [CrossRef]
- Trevisan, R.G.; Shiratsuchi, L.S.; Bullock, D.S.; Martin, N.F. Improving yield mapping accuracy using remote sensing. In Precision Agriculture’19; Wageningen Academic Publishers: Wageningen, The Netherlands, 2019; pp. 1–16. [Google Scholar]
- Koh, K.; Hyder, A.; Karale, Y.; Kamel Boulos, M.N. Big Geospatial Data or Geospatial Big Data? A Systematic Narrative Review on the Use of Spatial Data Infrastructures for Big Geospatial Sensing Data in Public Health. Remote Sens. 2022, 14, 2996. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Jardim, A.M.d.R.F.; Araújo Júnior, G.d.N.; Silva, M.V.d.; Santos, A.d.; Silva, J.L.B.d.; Pandorfi, H.; Oliveira-Júnior, J.F.d.; Teixeira, A.H.d.C.; Teodoro, P.E.; de Lima, J.L. Using remote sensing to quantify the joint effects of climate and land use/land cover changes on the caatinga biome of northeast Brazilian. Remote Sens. 2022, 14, 1911. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.; Li, J.; Pla, F. Capsule networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2145–2160. [Google Scholar] [CrossRef]
- Teodoro, P.E.; Teodoro, L.P.R.; Baio, F.H.R.; da Silva Junior, C.A.; dos Santos, R.G.; Ramos, A.P.M.; Pinheiro, M.M.F.; Osco, L.P.; Gonçalves, W.N.; Carneiro, A.M. Predicting days to maturity, plant height, and grain yield in soybean: A machine and deep learning approach using multispectral data. Remote Sens. 2021, 13, 4632. [Google Scholar] [CrossRef]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M.; Furuya, D.E.G.; Santana, D.C.; Teodoro, L.P.R.; Gonçalves, W.N.; Baio, F.H.R.; Pistori, H.; Junior, C.A.d.S. Leaf nitrogen concentration and plant height prediction for maize using UAV-based multispectral imagery and machine learning techniques. Remote Sens. 2020, 12, 3237. [Google Scholar] [CrossRef]
- Makhloufi, A.; Kallel, A.; Chaker, R.; Gastellu-Etchegorry, J.-P. Retrieval of olive tree biophysical properties from Sentinel-2 time series based on physical modelling and machine learning technique. Int. J. Remote Sens. 2021, 42, 8542–8571. [Google Scholar] [CrossRef]
- Ennouri, K.; Kallel, A. Remote sensing: An advanced technique for crop condition assessment. Math. Probl. Eng. 2019, 2019, 9404565. [Google Scholar] [CrossRef]
- Huang, X.; Li, S.; Li, J.; Jia, X.; Li, J.; Zhu, X.X.; Benediktsson, J.A. A multispectral and multiangle 3-D convolutional neural network for the classification of ZY-3 satellite images over urban areas. IEEE Trans. Geosci. Remote Sens. 2020, 59, 10266–10285. [Google Scholar] [CrossRef]
- Liang, B.; Liu, C.; Li, J.; Plaza, A.; Bioucas-Dias, J.M. Semisupervised Discriminative Random Field for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Observ. 2021, 14, 12403–12414. [Google Scholar] [CrossRef]
- Santana, D.C.; Teixeira Filho, M.C.M.; da Silva, M.R.; Chagas, P.H.M.d.; de Oliveira, J.L.G.; Baio, F.H.R.; Campos, C.N.S.; Teodoro, L.P.R.; da Silva Junior, C.A.; Teodoro, P.E. Machine Learning in the Classification of Soybean Genotypes for Primary Macronutrients’ Content Using UAV–Multispectral Sensor. Remote Sens. 2023, 15, 1457. [Google Scholar] [CrossRef]
- Baio, F.H.R.; Santana, D.C.; Teodoro, L.P.R.; Oliveira, I.C.d.; Gava, R.; de Oliveira, J.L.G.; Silva Junior, C.A.d.; Teodoro, P.E.; Shiratsuchi, L.S. Maize Yield Prediction with Machine Learning, Spectral Variables and Irrigation Management. Remote Sens. 2022, 15, 79. [Google Scholar] [CrossRef]
- Zhao, Q.; Yu, L.; Li, X.; Peng, D.; Zhang, Y.; Gong, P. Progress and trends in the application of Google Earth and Google Earth Engine. Remote Sens. 2021, 13, 3778. [Google Scholar] [CrossRef]
- Gastellu-Etchegorry, J.; Lauret, N.; Tavares, L.; Lamquin, N.; Bruniquel, V.; Roujean, J.; Hagolle, O.; Zhen, Z.; Wang, Y.; Regaieg, O. Correction of Directional Effects in Sentinel-2 and-3 Images with Sentinel-3 Time Series and Dart 3D Radiative Transfer Model. In Proceedings of IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 4563–4566. [Google Scholar]
- Bian, Z.; Qi, J.; Gastellu-Etchegorry, J.-P.; Roujean, J.-L.; Cao, B.; Li, H.; Du, Y.; Xiao, Q.; Liu, Q. A GPU-Based Solution for Ray Tracing 3-D Radiative Transfer Model for Optical and Thermal Images. IEEE Geosci. Remote Sens. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Strahler, A. MODIS land cover product algorithm theoretical basis document (ATBD) version 5.0. MODIS Doc. 1999, 42, 47. [Google Scholar]
- Jiao, Z.; Woodcock, C.; Schaaf, C.B.; Tan, B.; Liu, J.; Gao, F.; Strahler, A.; Li, X.; Wang, J. Improving MODIS land cover classification by combining MODIS spectral and angular signatures in a Canadian boreal forest. Can. J. Remote Sens. 2011, 37, 184–203. [Google Scholar] [CrossRef]
- Huang, W.; Niu, Z.; Wang, J.; Liu, L.; Zhao, C.; Liu, Q. Identifying crop leaf angle distribution based on two-temporal and bidirectional canopy reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3601–3609. [Google Scholar] [CrossRef]
- Hasegawa, K.; Matsuyama, H.; Tsuzuki, H.; Sweda, T. Improving the estimation of leaf area index by using remotely sensed NDVI with BRDF signatures. Remote Sens. Environ. 2010, 114, 514–519. [Google Scholar] [CrossRef]
- Zhen, Z.; Chen, S.; Qin, W.; Yan, G.; Gastellu-Etchegorry, J.-P.; Cao, L.; Murefu, M.; Li, J.; Han, B. Potentials and Limits of Vegetation Indices With BRDF Signatures for Soil-Noise Resistance and Estimation of Leaf Area Index. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5092–5108. [Google Scholar] [CrossRef]
- Goel, N.S.; Qin, W.; Wang, B. On the estimation of leaf size and crown geometry for tree canopies from hotspot observations. J. Geophys. Res. Atmos. 1997, 102, 29543–29554. [Google Scholar] [CrossRef]
- Han, C.; Chen, S.; Yu, Y.; Xu, Z.; Zhu, B.; Xu, X.; Wang, Z. Evaluation of Agricultural Land Suitability Based on RS, AHP, and MEA: A Case Study in Jilin Province, China. Agriculture 2021, 11, 370. [Google Scholar] [CrossRef]
- Wang, J. Analysis on the Grain-Production Growth and Influence Factors in Jilin Province; Jilin Agricultural University: Changchun, China, 2006. [Google Scholar]
- SINERGISE. Sentinel Hub. Available online: https://docs.sentinel-hub.com/api/latest/data/modis/mcd/#available-bands-and-data (accessed on 23 May 2023).
- You, N.; Dong, J.; Huang, J.; Du, G.; Zhang, G.; He, Y.; Yang, T.; Di, Y.; Xiao, X. The 10-m crop type maps in Northeast China during 2017–2019. Sci. Data 2021, 8, 1–11. [Google Scholar] [CrossRef]
- Mandal, D.; Kumar, V.; Rao, Y.S. An assessment of temporal RADARSAT-2 SAR data for crop classification using KPCA based support vector machine. Geocarto. Int. 2022, 37, 1547–1559. [Google Scholar] [CrossRef]
- Mitraka, Z.; Chrysoulakis, N.; Kamarianakis, Y.; Partsinevelos, P.; Tsouchlaraki, A. Improving the estimation of urban surface emissivity based on sub-pixel classification of high resolution satellite imagery. Remote Sens. Environ. 2012, 117, 125–134. [Google Scholar] [CrossRef]
- Useya, J.; Chen, S.; Murefu, M. Cropland Mapping and Change Detection: Toward Zimbabwean Cropland Inventory. IEEE Access 2019, 7, 53603–53620. [Google Scholar] [CrossRef]
- GEE. Available online: https://developers.google.com/earth-engine/guides/classification (accessed on 23 May 2023).
- Goldblatt, R.; You, W.; Hanson, G.; Khandelwal, A.K. Detecting the boundaries of urban areas in india: A dataset for pixel-based image classification in google earth engine. Remote Sens. 2016, 8, 634. [Google Scholar] [CrossRef]
- Shetty, S. Analysis of Machine Learning Classifiers for LULC Classification on Google Earth Engine; University of Twente: Enschede, The Netherlands, 2019. [Google Scholar]
- Richards, J.A.; Richards, J.A. Remote Sensing Digital Image Analysis; Springer: Berlin/Heidelberg, Germany, 2022; Volume 5. [Google Scholar]
- Jensen, J.R. Introductory Digital Image Processing: A Remote Sensing Perspective; Prentice-Hall Inc.: Hoboken, NJ, USA, 1996. [Google Scholar]
- Ghorbanian, A.; Kakooei, M.; Amani, M.; Mahdavi, S.; Mohammadzadeh, A.; Hasanlou, M. Improved land cover map of Iran using Sentinel imagery within Google Earth Engine and a novel automatic workflow for land cover classification using migrated training samples. ISPRS J. Photogramm. Remote Sens. 2020, 167, 276–288. [Google Scholar] [CrossRef]
- Amani, M.; Ghorbanian, A.; Ahmadi, S.A.; Kakooei, M.; Moghimi, A.; Mirmazloumi, S.M.; Moghaddam, S.H.A.; Mahdavi, S.; Ghahremanloo, M.; Parsian, S. Google earth engine cloud computing platform for remote sensing big data applications: A comprehensive review. IEEE J. Sel. Top. Appl. Earth Observ. 2020, 13, 5326–5350. [Google Scholar] [CrossRef]
- Shelestov, A.; Lavreniuk, M.; Kussul, N.; Novikov, A.; Skakun, S. Exploring Google Earth Engine platform for big data processing: Classification of multi-temporal satellite imagery for crop mapping. Front. Earth Sci. 2017, 5, 17. [Google Scholar] [CrossRef]
- Shelestov, A.; Lavreniuk, M.; Kussul, N.; Novikov, A.; Skakun, S. Large scale crop classification using Google earth engine platform. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3696–3699. [Google Scholar]
- Kamal, M.; Jamaluddin, I.; Parela, A.; Farda, N.M. Comparison of Google Earth Engine (GEE)-based machine learning classifiers for mangrove mapping. In Proceedings of the 40th Asian Conference Remote Sensing, ACRS, Daejeon, Korea, 14–18 October 2019; pp. 1–8. [Google Scholar]
- Pan, X.; Wang, Z.; Gao, Y.; Dang, X.; Han, Y. Detailed and automated classification of land use/land cover using machine learning algorithms in Google Earth Engine. Geocarto. Int. 2022, 37, 5415–5432. [Google Scholar] [CrossRef]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring issues of training data imbalance and mislabelling on random forest performance for large area land cover classification using the ensemble margin. ISPRS J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Foody, G.M.; Pal, M.; Rocchini, D.; Garzon-Lopez, C.X.; Bastin, L. The sensitivity of mapping methods to reference data quality: Training supervised image classifications with imperfect reference data. ISPRS Int. J. Geo.-Inf. 2016, 5, 199. [Google Scholar] [CrossRef]
- Maponya, M.G.; Van Niekerk, A.; Mashimbye, Z.E. Pre-harvest classification of crop types using a Sentinel-2 time-series and machine learning. Comput. Electron. Agric. 2020, 169, 105164. [Google Scholar] [CrossRef]
- Li, J.; Chen, S.; Qin, W.; Murefu, M.; Wang, Y.; Yu, Y.; Zhen, Z. Spatio-temporal Characteristics of Area Coverage and Observation Geometry of the MISR Land-surface BRF Product: A Case Study of the Central Part of Northeast Asia. Chin. Geogr. Sci. 2019, 29, 679–688. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- Schaaf, C.; Strahler, A.; Chopping, M.; Gao, F.; Hall, D.; Jin, Y.; Liang, S.; Nightingale, J.; Román, M.; Roy, D. MODIS MCD43 Product User Guide V005; University of Massachusetts Boston: Boston, MA, USA, 2021. [Google Scholar]
- Moody, A.; Strahler, A. Characteristics of composited AVHRR data and problems in their classification. Int. J. Remote Sens. 1994, 15, 3473–3491. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining data with random forests: A survey and results of new tests. Pattern Recognit. 2011, 44, 330–349. [Google Scholar] [CrossRef]
- Lorena, A.C.; Jacintho, L.F.; Siqueira, M.F.; De Giovanni, R.; Lohmann, L.G.; De Carvalho, A.C.; Yamamoto, M. Comparing machine learning classifiers in potential distribution modelling. Expert Syst. Appl. 2011, 38, 5268–5275. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.; Olshen, R. Classification and Regression Trees; Raton, B., Ed.; Taylor & Francis Ltd.: Oxfordshire, UK, 1984. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J.; Bach, F. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT press: Cambridge, MA, USA, 2002. [Google Scholar]
- Haykin, S. Neural Networks and Learning Machines, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2008. [Google Scholar]
- Hand, D.J.; Yu, K. Idiot’s Bayes—Not so stupid after all? Int. Stat. Rev. 2001, 69, 385–398. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Band Sequence | Band | Spatial Resolution (m) | Bandwidth (nm) |
|---|---|---|---|
| 1 | Red | 500 | 620–670 |
| 2 | NIR | 500 | 841–876 |
| 3 | Blue | 500 | 459–479 |
| 4 | Green | 500 | 545–565 |
| 5 | N/A | 500 | 1230–1250 |
| 6 | SWIR16 | 500 | 1628–1652 |
| 7 | SWIR22 | 500 | 2105–2155 |
| Parameters | Values |
|---|---|
| Random forest (RF) | |
| The amount of decision trees to be created for rifles by class | 10 |
| The quantity of variables in each division | 0 |
| The smallest size of a terminal node | 1 |
| The percentage of input to the bag for each tree | 0.5 |
| Whether or not the out-of-bag mode should be used by the classifier | False |
| Classification and regression trees (CART) | |
| The greatest amount of leaf nodes in each tree | None |
| Create nodes only if the training set includes this many values or more | 1 |
| Support vector machine (SVM) | |
| The process for making decisions | Voting |
| The SVM type | C_SVC |
| The kernel type | RBF |
| Using or not using reducing algorithms | True |
| The degree of the polynomial | None |
| The gamma value in the kernel function | 0.5 |
| The coef0 value in the kernel function | None |
| The cost (C) parameter | 1 |
| The nu parameter | None |
| The termination criterion tolerance | None |
| The epsilon in the loss function | None |
| The class of the training data on which to train in a one-class SVM | None |
| Naïve Bayes (NB) | |
| Smoothing lambda | 0.000001 |
| Classifier | Data | Areas (km2) | TA | VA | TK | VK | ||
|---|---|---|---|---|---|---|---|---|
| Maize | Rice | Soybean | ||||||
| RF | NR | 90,835.50 | 16,419.25 | 2542.25 | 96.1% | 75.5% | 0.929 | 0.539 |
| RF | MF | 89,836.50 | 17,500.75 | 2459.75 | 97.4% | 79.4% | 0.953 | 0.602 |
| CART | NR | 75,355.75 | 20,469.00 | 13,972.25 | 98.7% | 58.8% | 0.977 | 0.307 |
| CART | MF | 69,580.75 | 25,934.25 | 14,282.00 | 98.7% | 63.7% | 0.977 | 0.368 |
| SVM | NR | 97,668.50 | 12,128.50 | 0.00 | 73.0% | 73.5% | 0.442 | 0.450 |
| SVM | MF | 94,010.50 | 15,786.00 | 0.50 | 76.5% | 77.5% | 0.531 | 0.542 |
| NB | NR | 109,797.00 | 0.00 | 0.00 | 55.7% | 54.9% | 0.000 | 0.000 |
| NB | MF | 109,797.00 | 0.00 | 0.00 | 55.7% | 54.9% | 0.000 | 0.000 |
| Classifier | Data | PA | UA | ||||
|---|---|---|---|---|---|---|---|
| Maize | Rice | Soybean | Maize | Rice | Soybean | ||
| RF | NR | 98.4% | 93.8% | 90.5% | 94.7% | 98.7% | 95.0% |
| RF | MF | 97.7% | 97.5% | 95.2% | 97.7% | 98.8% | 90.9% |
| CART | NR | 99.2% | 97.5% | 100.0% | 98.4% | 100.0% | 95.5% |
| CART | MF | 99.2% | 97.5% | 100.0% | 98.4% | 100.0% | 95.5% |
| SVM | NR | 98.4% | 51.9% | 0.0% | 68.1% | 93.3% | 0.0% |
| SVM | MF | 94.5% | 67.9% | 0.0% | 72.9% | 85.9% | 0.0% |
| NB | NR | 100.0% | 0.0% | 0.0% | 55.7% | 0.0% | 0.0% |
| NB | MF | 100.0% | 0.0% | 0.0% | 55.7% | 0.0% | 0.0% |
| Classifier | Data | PA | UA | ||||
|---|---|---|---|---|---|---|---|
| Maize | Rice | Soybean | Maize | Rice | Soybean | ||
| RF | NR | 87.5% | 68.3% | 0.0% | 75.4% | 96.6% | 0.0% |
| RF | MF | 87.5% | 78.0% | 0.0% | 77.8% | 88.9% | 0.0% |
| CART | NR | 62.5% | 53.7% | 60.0% | 66.0% | 78.6% | 14.3% |
| CART | MF | 69.6% | 61.0% | 20.0% | 70.9% | 80.6% | 6.2% |
| SVM | NR | 98.2% | 48.8% | 0.0% | 67.9% | 95.2% | 0.0% |
| SVM | MF | 94.6% | 63.4% | 0.0% | 72.6% | 89.7% | 0.0% |
| NB | NR | 100.0% | 0.0% | 0.0% | 54.9% | 0.0% | 0.0% |
| NB | MF | 100.0% | 0.0% | 0.0% | 54.9% | 0.0% | 0.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhen, Z.; Chen, S.; Yin, T.; Gastellu-Etchegorry, J.-P. Improving Crop Mapping by Using Bidirectional Reflectance Distribution Function (BRDF) Signatures with Google Earth Engine. Remote Sens. 2023, 15, 2761. https://doi.org/10.3390/rs15112761
Zhen Z, Chen S, Yin T, Gastellu-Etchegorry J-P. Improving Crop Mapping by Using Bidirectional Reflectance Distribution Function (BRDF) Signatures with Google Earth Engine. Remote Sensing. 2023; 15(11):2761. https://doi.org/10.3390/rs15112761
Chicago/Turabian StyleZhen, Zhijun, Shengbo Chen, Tiangang Yin, and Jean-Philippe Gastellu-Etchegorry. 2023. "Improving Crop Mapping by Using Bidirectional Reflectance Distribution Function (BRDF) Signatures with Google Earth Engine" Remote Sensing 15, no. 11: 2761. https://doi.org/10.3390/rs15112761
APA StyleZhen, Z., Chen, S., Yin, T., & Gastellu-Etchegorry, J. -P. (2023). Improving Crop Mapping by Using Bidirectional Reflectance Distribution Function (BRDF) Signatures with Google Earth Engine. Remote Sensing, 15(11), 2761. https://doi.org/10.3390/rs15112761