
An Intelligent Detection Method for Small and Weak Objects in Space

Abstract
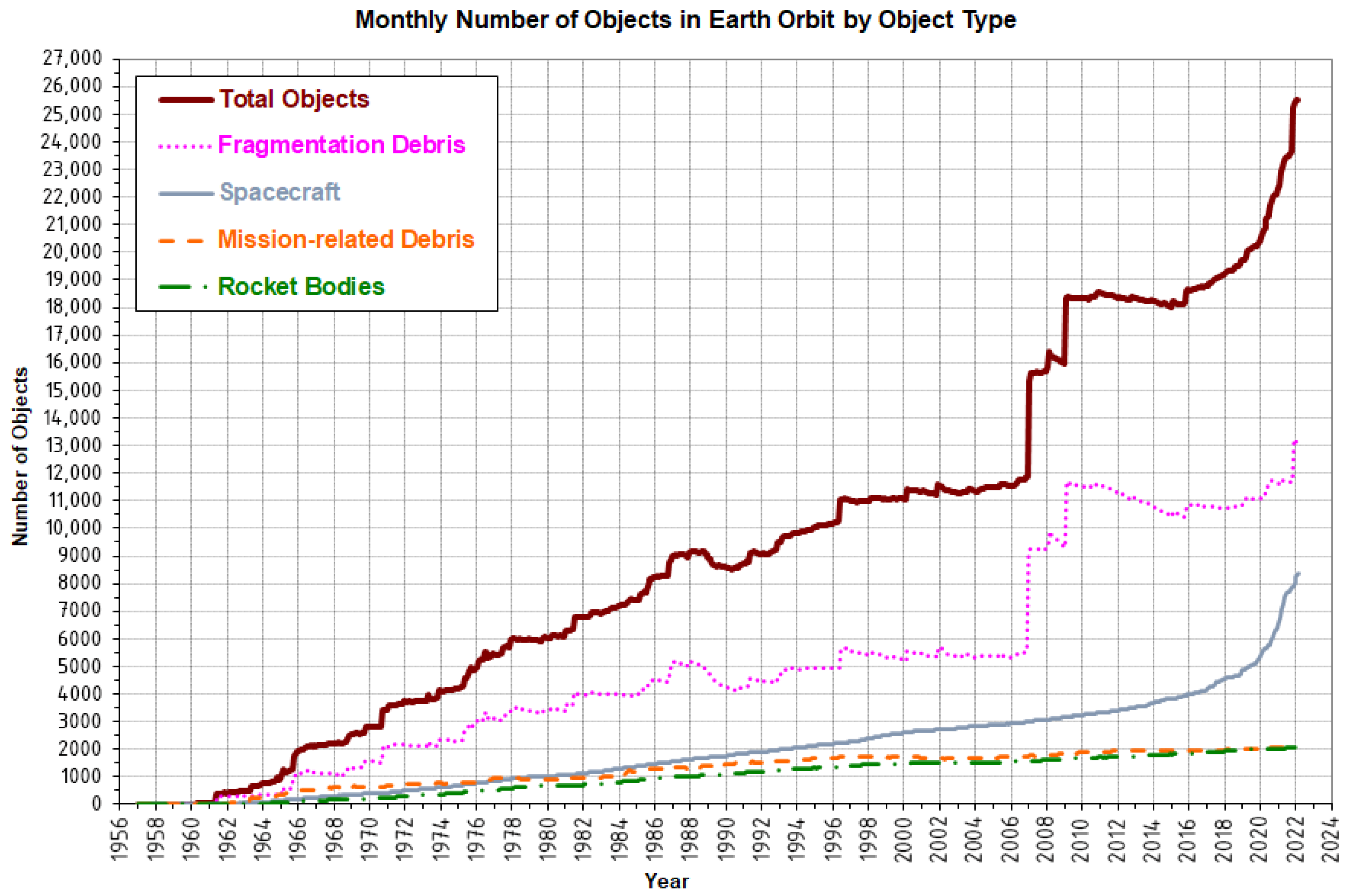
:1. Introduction
2. Related Work
2.1. Data Augmentation
2.2. Multi-Scale Object Detection
2.3. Space Object Detection
3. Proposed Method
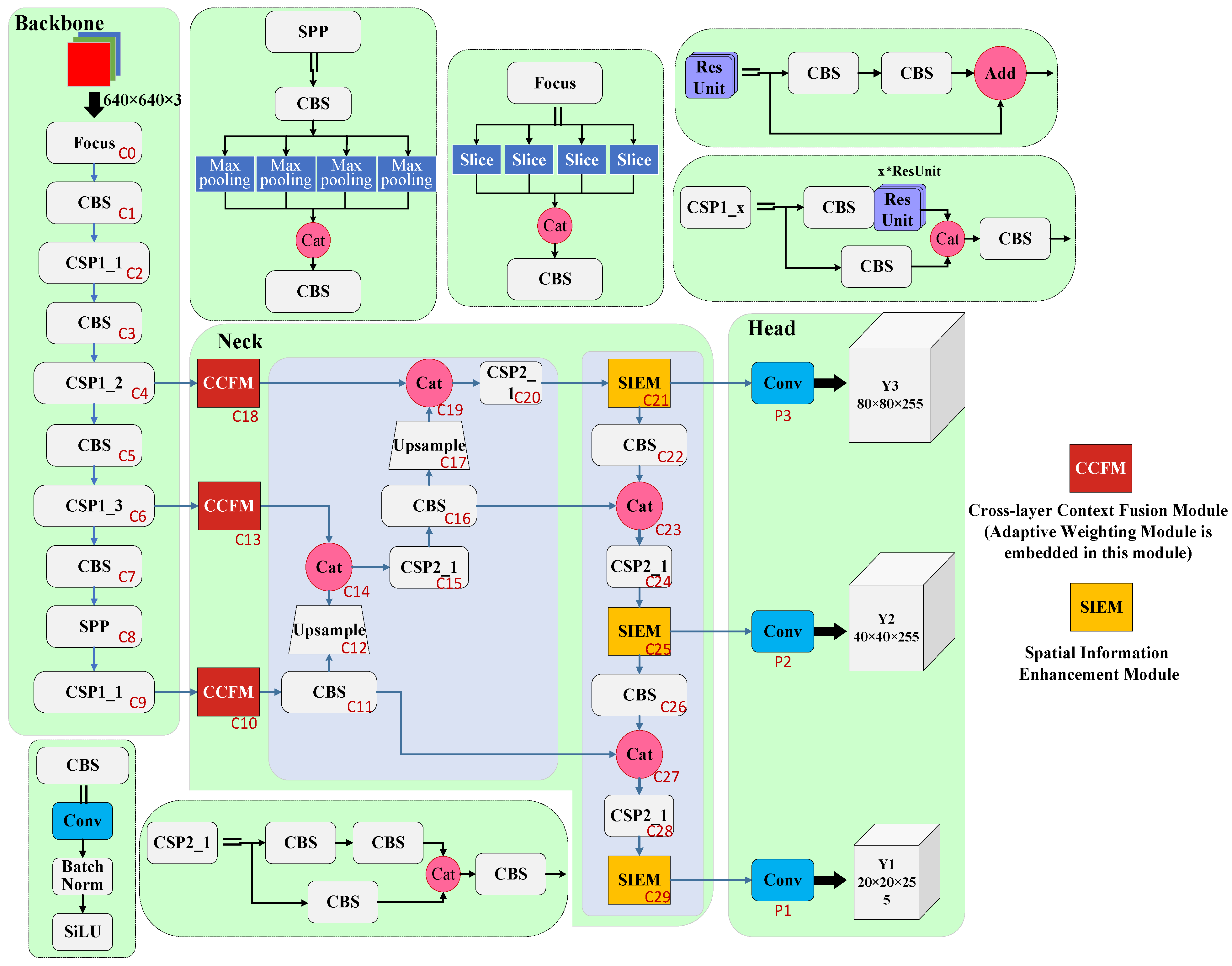
3.1. Context Sensing-YOLOv5
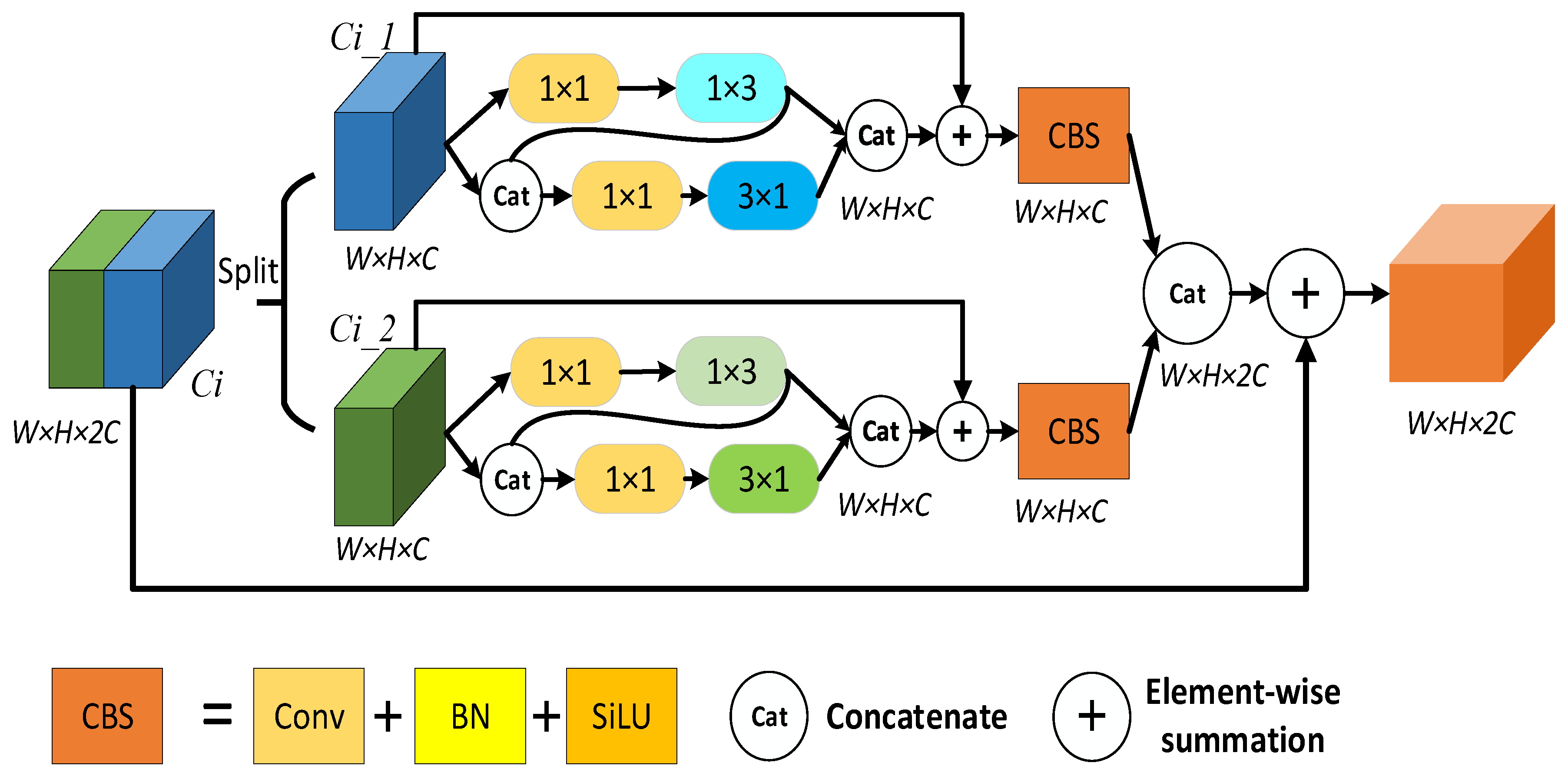
3.2. Cross-Layer Context Fusion Module
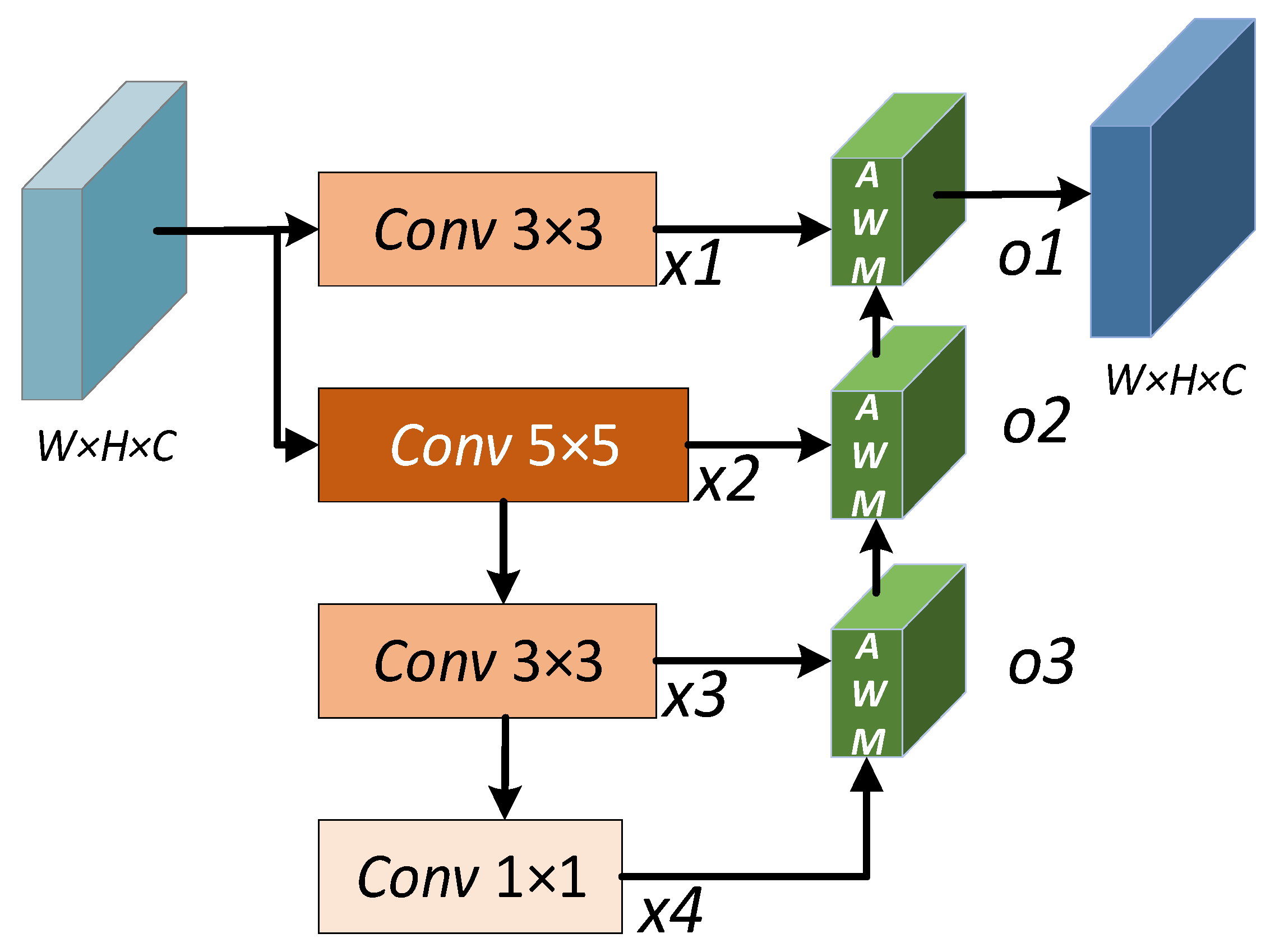
3.3. Adaptive Weighting Module
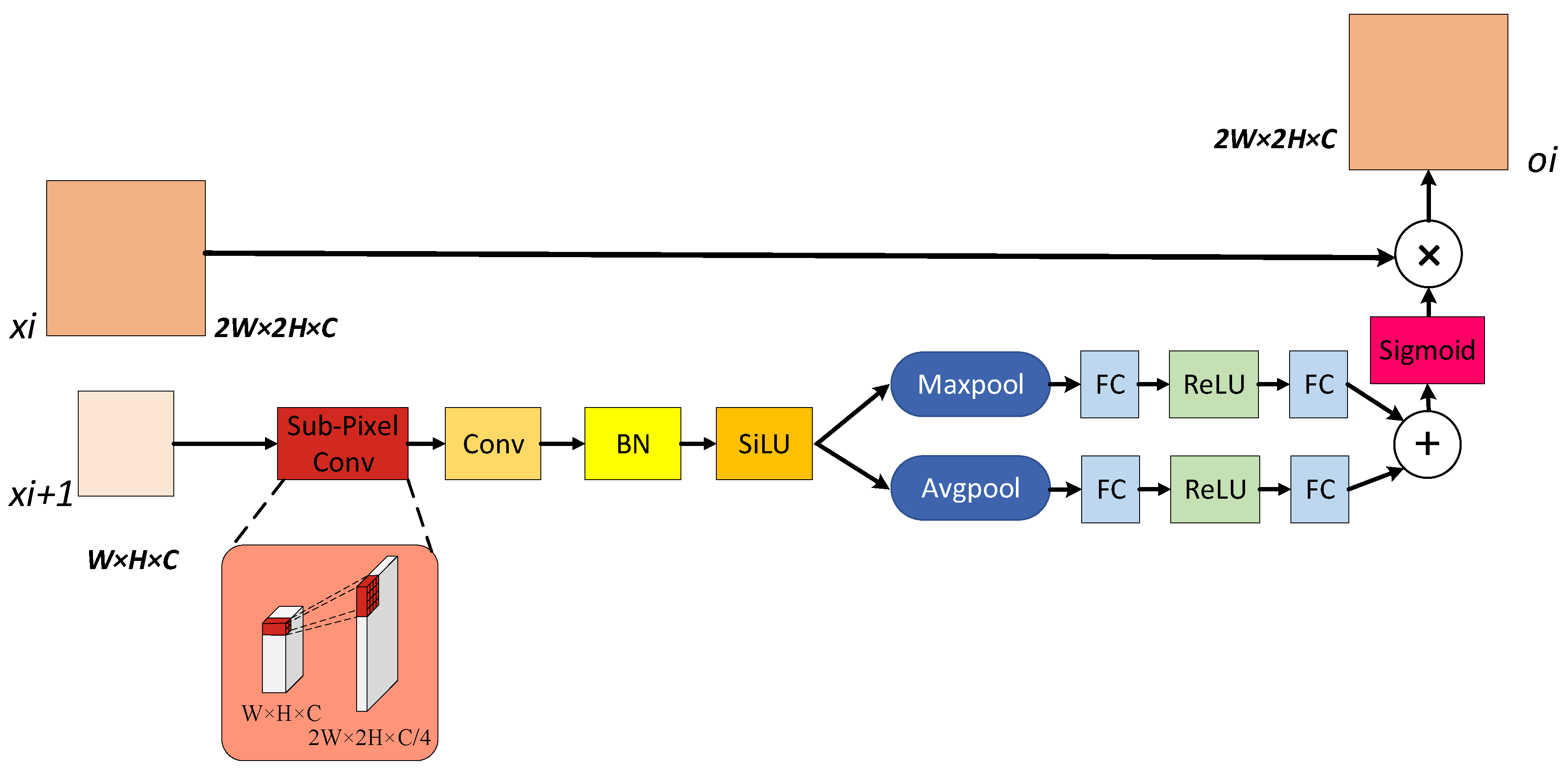
3.4. Spatial Information Enhancement Module
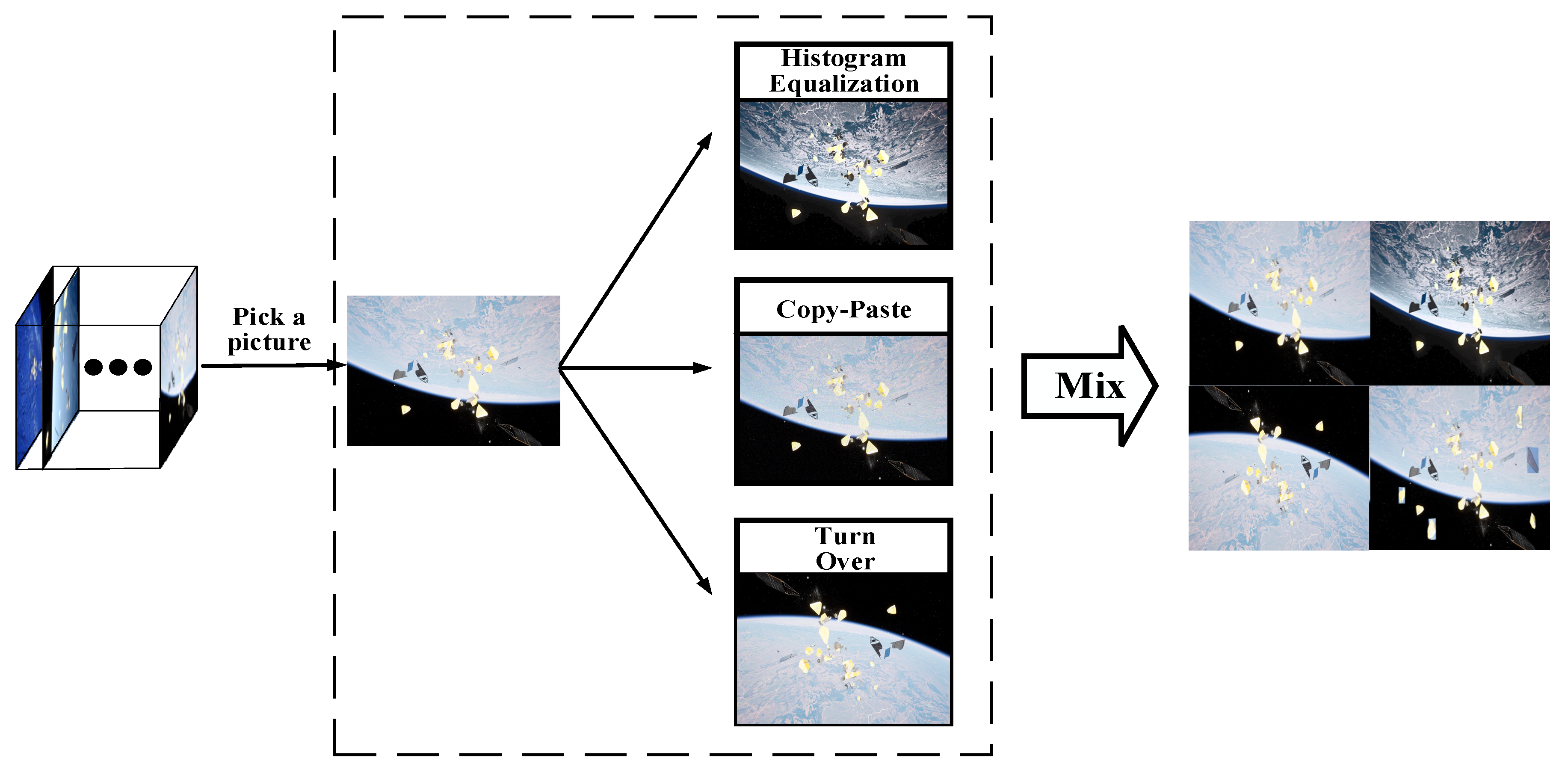
3.5. Contrast Mosaic Data Augment
4. Results
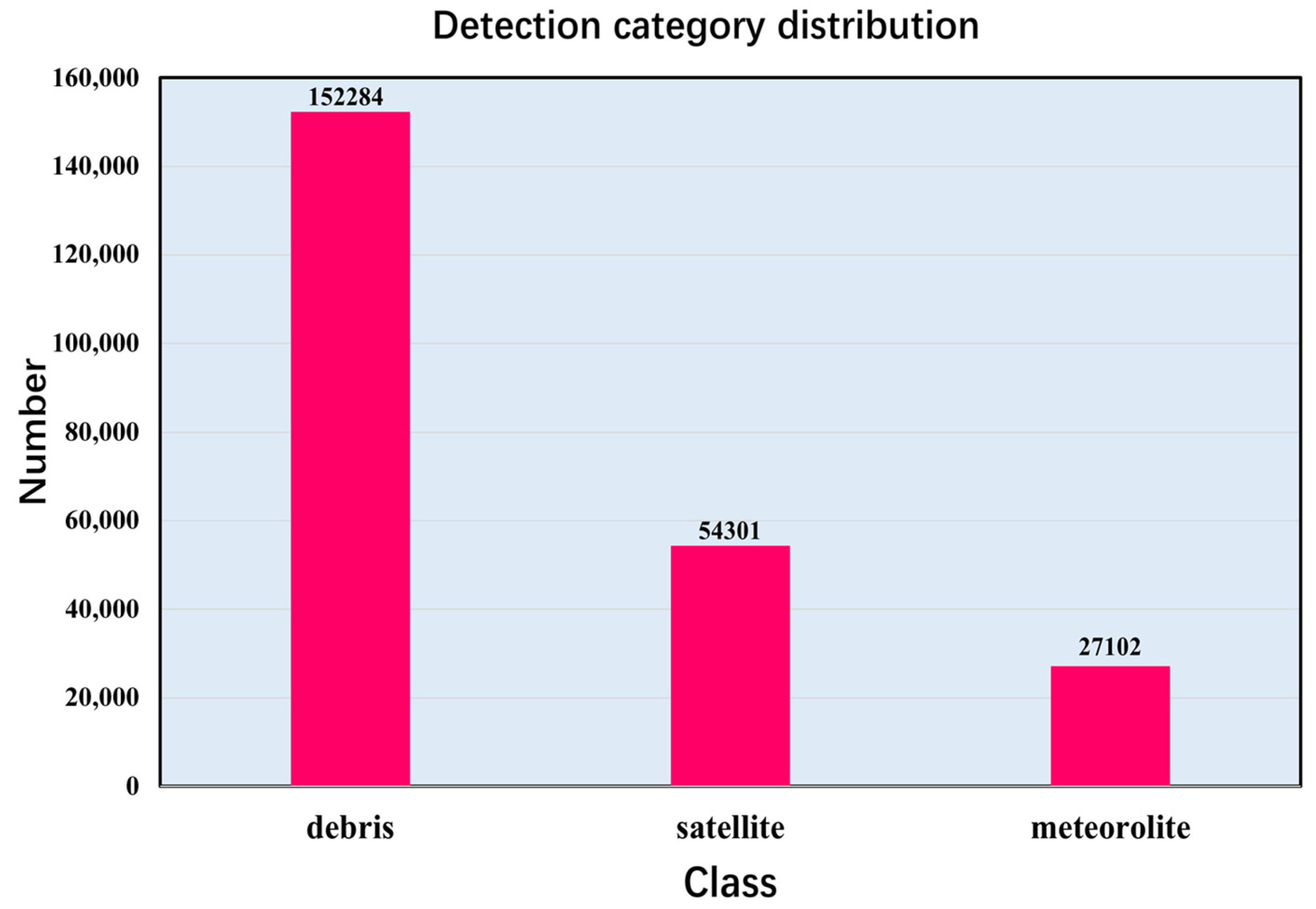
4.1. Datasets
4.2. Implementation Details
4.3. Metrics
4.4. Ablation Experiments
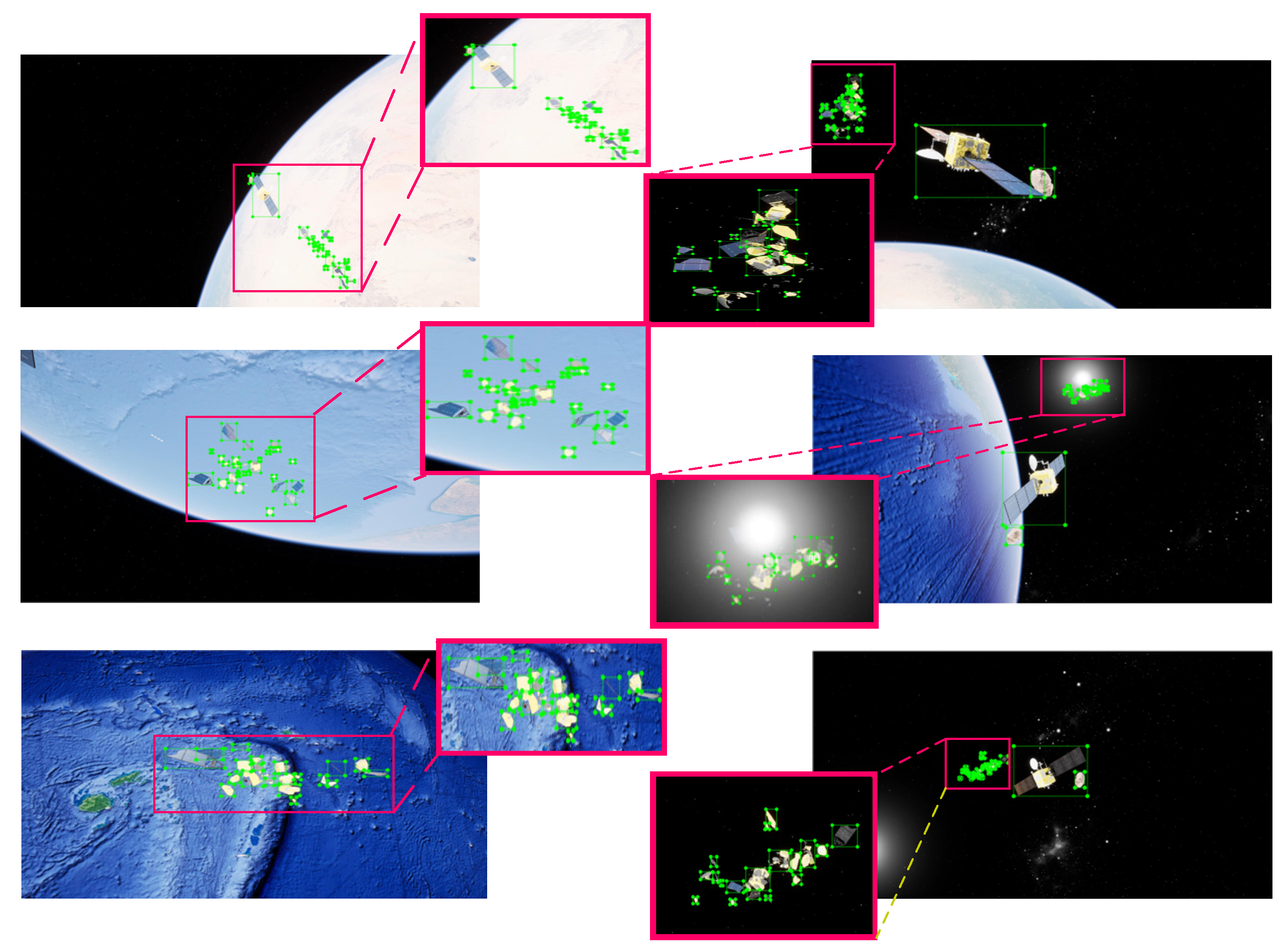
4.5. Performance Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- LEGEND: 3D/OD Evolutionary Model. Available online: https://orbitaldebris.jsc.nasa.gov/modeling/legend.html (accessed on 14 September 2022).
- Yang, Y.; Lin, H. Automatic Detecting and Tracking Space Debris Objects Using Active Contours from Astronomical Images. Geomat. Inf. Sci. Wuhan Univ. 2010, 35, 209–214. [Google Scholar]
- Lowe, D. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Richard, O.D.; Peter, E. Use of the hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar]
- Freund, Y.; Schapire, R. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.; Girshick, R.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 November 2021).
- Park, T.; Märtens, M.; Lecuyer, G.; Izzo, D. SPEED+: Next-generation dataset for spacecraft pose estimation across domain gap. In Proceedings of the IEEE Aerospace Conference (AERO), Big Sky, MT, USA, 5–12 March 2022; pp. 1–15. [Google Scholar]
- Chawla, N.; Bowyer, K.; Hall, L.; Kegelmeyer, W. SMOTE: Synthetic minority over-sampling technique. Artif. Intell. Res. 2022, 16, 321–357. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. In Proceedings of the ICLR 2018 Conference Blind Submission, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–13. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6022–6031. [Google Scholar]
- Inoue, H. Data Augmentation by Pairing Samples for Images Classification. arXiv 2018, arXiv:1801.02929. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland; Munich, Germany, 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Receptive field block net for accurate and fast object detection. In Proceedings of the European conference on computer vision, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland; Munich, Germany, 2018; pp. 385–400. [Google Scholar]
- Li, C.; Xu, C.; Cui, Z.; Wan, D.; Jie, Z.; Zhang, T.; Yang, J. Learning object-wise semantic representation for detection in remote sensing imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 20–27. [Google Scholar]
- Guo, Y.; Xu, Y.; Li, S. Dense construction vehicle detection based on orientationaware feature fusionconvolutional neural network. Autom. Constr. 2020, 112, 103124. [Google Scholar] [CrossRef]
- Wang, J.; Ding, J.; Guo, H.; Cheng, W.; Pan, T.; Yang, W. Mask OBB: A semantic attention-based mask oriented bounding box representation for multi-category object detection in aerial images. Remote Sens. 2019, 11, 2930. [Google Scholar] [CrossRef] [Green Version]
- Tang, G.; Zhuge, Y.; Claramunt, C.; Men, S. N-YOLO: A SAR Ship Detection Using Noise-Classifying and Complete-Target Extraction. Remote Sens. 2021, 13, 871. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Z.; Lin, Z.; Qi, H. Image super-resolution by neural texture transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7982–7991. [Google Scholar]
- Li, S.; Li, Y.; Li, Y.; Li, M.; Xu, X. YOLO-FIRI: Improved YOLOv5 for Infrared Image Object Detection. IEEE Access 2021, 9, 141861–141875. [Google Scholar] [CrossRef]
- Lu, Y.; Gao, J.; Yu, Q.; Li, Y.; Lv, Y.; Qiao, H. A Cross-Scale and Illumination Invariance-Based Model for Robust Object Detection in Traffic Surveillance Scenarios. IEEE Trans. Intell. Transp. Syst. 2023, 22, 1–11. [Google Scholar] [CrossRef]
- Song, Y.; Xie, Z.; Wang, X.; Zou, Y. MS-YOLO: Object Detection Based on YOLOv5 Optimized Fusion Millimeter-Wave Radar and Machine Vision. IEEE Sens. J. 2022, 22, 15435–15447. [Google Scholar] [CrossRef]
- Kim, E.J.; Brunner, R.J. Star–galaxy classification using deep convolutional neural networks. Mon. Not. R. Astron. Soc. 2016, 464, 4463–4475. [Google Scholar] [CrossRef] [Green Version]
- Wu, T.; Yang, X.; Song, B.; Wang, N.; Gao, X.; Kuang, L.; Nan, X.; Chen, Y.; Yang, D. T-SCNN: A Two-Stage Convolutional Neural Network for Space Target Recognition. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1334–1337. [Google Scholar]
- Xiang, Y.; Xi, J.; Cong, M.; Yang, Y.; Ren, C.; Han, L. Space debris detection with fast grid-based learning. In Proceedings of the 2020 IEEE 3rd International Conference of Safe Production and Informatization (IICSPI), Chongqing, China, 28–30 November 2020; pp. 205–209. [Google Scholar]
- Wang, G.; Lei, N.; Liu, H. Improved-YOLOv3 network for object detection in simulated Space Solar Power Systems images. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 7177–7181. [Google Scholar]
- Jiang, F.; Yuan, J.; Qi, Y.; Liu, Z.; Cai, L. Space target detection based on the invariance of inter-satellite topology. In Proceedings of the 2022 IEEE 10th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 17–19 June 2022; pp. 2151–2155. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Lin, D. MMDetection: Open mmlab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9759–9768. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 840–849. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y. TOOD: Task-aligned One-stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, NA, Canada, 10–17 October 2021; pp. 3490–3499. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sünderhauf, N. VarifocalNet: An IoU-aware Dense Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8514–8523. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss v2: Learning reliable localization quality estimation for dense object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 11632–11641. [Google Scholar]
- Kim, K.; Lee, H. Probabilistic anchor assignment with iou prediction for object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 355–371. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Backbone | Contrast Mosaic | AP (%), IoU | AP (%), Area | ||||
|---|---|---|---|---|---|---|---|---|
| 0.5:0.95 | 0.5 | 0.75 | S | M | L | |||
| YOLOv5 | CSPDarknet-53 | - | 62.9 | 87.0 | 74.4 | 36.2 | 51.3 | 72.9 |
| √ | 66.3 | 89.5 | 75.6 | 47.4 | 76.8 | 87.7 | ||
| ATSS | ResNet-50 | - | 61.1 | 86.2 | 72.0 | 30.3 | 59.2 | 76.3 |
| √ | 64.3 | 88.7 | 76.5 | 42.6 | 73.6 | 85.5 | ||
| FSAF | ResNet-50 | - | 51.8 | 78.4 | 63.5 | 30.1 | 51.7 | 63.6 |
| √ | 60.6 | 84.5 | 69.0 | 40.3 | 68.8 | 78.4 | ||
| FCOS | ResNet-50 | - | 57.1 | 84.8 | 65.8 | 26.7 | 56.4 | 74.3 |
| √ | 63.1 | 90.9 | 73.7 | 33.5 | 71.1 | 78.8 | ||
| TOOD | ResNet-50 | - | 64.3 | 88.6 | 74.6 | 36.2 | 55.6 | 75.7 |
| √ | 65.8 | 90.4 | 77.2 | 46.8 | 76.1 | 87.5 | ||
| RetinaNet | ResNet-50 | - | 51.9 | 77.1 | 67.6 | 30.1 | 55.0 | 63.5 |
| √ | 59.1 | 84.9 | 71.3 | 35.1 | 69.2 | 78.7 | ||
| VFNet | ResNet-50 | - | 56.9 | 84.9 | 64.3 | 32.6 | 55.9 | 64.9 |
| √ | 62.4 | 87.5 | 73.8 | 40.4 | 65.8 | 71.2 | ||
| CS-YOLOv5 | CSPDarknet-53 | - | 67.8 | 91.6 | 79.4 | 48.8 | 68.1 | 79.5 |
| √ | 69.6 | 93.8 | 80.7 | 56.3 | 82.5 | 89.6 | ||
| Methods | CCFM | AWM | SIEM | mAP | AP50 | AP75 | APS | APM | APL | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5 | - | - | - | 62.9 | 87.0 | 76.4 | 36.2 | 51.3 | 72.9 | 58.8 |
| Ours | √ | - | - | 64.7 | 89.4 | 78.5 | 38.4 | 60.2 | 76.0 | 56.3 |
| Ours | √ | √ | - | 65.5 | 89.9 | 79.6 | 41.0 | 65.4 | 78.1 | 54.9 |
| Ours | - | - | √ | 65.3 | 88.8 | 78.2 | 42.2 | 65.6 | 76.7 | 55.4 |
| Ours | √ | √ | √ | 67.8 | 91.6 | 79.4 | 48.8 | 68.1 | 79.5 | 48.4 |
| Methods | FPS | Params | GFLOPS |
|---|---|---|---|
| YOLOv5 | 58.8 | 7,056,607 | 16.3 |
| CS-YOLOv5 | 48.4 | 16,328,668 | 27.4 |
| Method | Backbone | mAP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|
| YOLOv5 | CSPDarknet-53 | 62.9 | 87.0 | 74.4 | 36.2 | 51.3 | 72.9 |
| ATSS | ResNet-50 | 61.1 | 86.2 | 72.0 | 30.3 | 59.2 | 76.3 |
| FSAF | ResNet-50 | 51.8 | 78.4 | 63.5 | 30.1 | 51.7 | 63.6 |
| FCOS | ResNet-50 | 57.1 | 84.8 | 65.8 | 26.7 | 56.4 | 74.3 |
| TOOD | ResNet-50 | 64.3 | 88.6 | 74.6 | 36.2 | 55.6 | 75.7 |
| RetinaNet | ResNet-50 | 51.9 | 77.1 | 67.6 | 30.1 | 55.0 | 63.5 |
| VFNet | ResNet-50 | 56.9 | 84.9 | 64.3 | 32.6 | 55.9 | 64.9 |
| GFL | ResNet-50 | 63.7 | 88.4 | 72.5 | 36.0 | 54.4 | 76.0 |
| PAA | ResNet-50 | 59.1 | 84.9 | 66.3 | 33.1 | 51.2 | 78.7 |
| CS-YOLOv5 | CSPDarknet-53 | 67.8 | 91.6 | 79.4 | 48.8 | 68.1 | 79.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, Y.; Bai, H.; Wu, P.; Guo, H.; Deng, T.; Qin, W. An Intelligent Detection Method for Small and Weak Objects in Space. Remote Sens. 2023, 15, 3169. https://doi.org/10.3390/rs15123169
Yuan Y, Bai H, Wu P, Guo H, Deng T, Qin W. An Intelligent Detection Method for Small and Weak Objects in Space. Remote Sensing. 2023; 15(12):3169. https://doi.org/10.3390/rs15123169
Chicago/Turabian StyleYuan, Yuman, Hongyang Bai, Panfeng Wu, Hongwei Guo, Tianyu Deng, and Weiwei Qin. 2023. "An Intelligent Detection Method for Small and Weak Objects in Space" Remote Sensing 15, no. 12: 3169. https://doi.org/10.3390/rs15123169
APA StyleYuan, Y., Bai, H., Wu, P., Guo, H., Deng, T., & Qin, W. (2023). An Intelligent Detection Method for Small and Weak Objects in Space. Remote Sensing, 15(12), 3169. https://doi.org/10.3390/rs15123169