1. Introduction
With the advances in data mining and machine learning techniques, many research problems now involve the analysis of multiple datasets. These datasets frequently contain numerous irrelevant, noisy, and/or redundant features, which significantly affect the classification performance. Specifically, irrelevant or noisy features can significantly degrade the classification performance due to their misleading information [
1]. Feature selection (FS) aims to enhance classification performance, reduce data dimensionality, save storage space, improve computational efficiency, and facilitate data visualization and understanding by selecting a small subset of relevant features. The increase in data and dimensionality leads to an increasingly difficult feature selection [
2].
In recent years, feature selection has found widespread application in various research domains, including text classification, remote sensing [
3], intrusion detection, gene analysis, and image retrieval [
4]. Notably, feature selection plays a crucial role in remote sensing image classification tasks. Remote sensing images often contain a vast amount of pixel data and diverse spectral information [
5,
6], yet only a subset of features contributes significantly to the classification process. Hence, feature selection techniques are used to identify the most informative and relevant features, reduce the complexity of the classification tasks, and improve the overall accuracy. By effectively selecting pertinent features, the interference of redundant information and noise can be minimized, while emphasizing the spatial, spectral, and textural characteristics of objects in remote sensing images. Consequently, feature selection holds paramount significance in achieving precise land object classification and monitoring in remote sensing applications [
7,
8]. To this end, the development of efficient feature selection methods becomes imperative, aiming to optimize classification accuracy and computational efficiency.
Feature selection methods are mainly divided into two categories: filters and wrappers [
9]. Filter-based methods use the intrinsic information of features, such as correlation, information gain, and consistency [
10], to determine features [
11]. The wrapper-based approach is used to generate feature subsets through a classifier and a learning model and perform accuracy evaluation by a learning algorithm to determine the feature subsets [
12,
13]. Although wrapper-based methods can produce better feature subsets, they are computationally expensive, especially when the search space is large and complex. In contrast, filter-based methods are usually less computationally expensive, but have lower classification accuracy and cannot select a good subset of features [
14].
Although feature selection is an indispensable process, it is also a complex and challenging combinatorial optimization problem. The challenges of feature selection mainly revolve around three aspects. Firstly, the search space for feature selection exponentially grows with the number of features, as
N features can yield
feature subsets [
15,
16]. Therefore, an exhaustive search of all possible subsets is impractical, especially when dealing with numerous features. Secondly, features have complex interactions with each other. Thirdly, feature selection is inherently a multiobjective problem. The two primary objectives of feature selection are to maximize classification performance and to minimize the number of selected features. However, these objectives are often conflicting [
17]. A robust and powerful search algorithm forms the foundation for addressing feature selection problems effectively.
In recent years, metaheuristics have been successfully applied to feature selection methods. Metaheuristic algorithms are inspired by natural phenomena, such as particle swarm optimization (PSO) [
18,
19,
20], genetic algorithms (GA) [
21], the differential evolution algorithm (DE) [
22,
23], the bat algorithm (BA) [
24,
25], the gray wolf optimization algorithm (GWO) [
26,
27,
28], the dragonfly algorithm (DA) [
29], cuckoo search (CS) [
30], the salp swarm algorithm (SSA) [
31], Harris hawks optimization (HHO) [
32], etc. When using or designing metaheuristic algorithms, there needs to be an effective way to maintain a balance between development and exploration. Metaheuristic algorithms need to search as much of the search space as possible in the early stages and develop the optimal region in the later stages, so a balance between exploration and development is essential.
The dragonfly algorithm (DA) is a recently developed optimization algorithm inspired by the collective behavior of dragonflies in nature. Initially designed for continuous optimization tasks, a binary version called the binary dragonfly algorithm (BDA) was later introduced to address discrete problems [
33]. While BDA has shown strong performance on various datasets, it may suffer from limited exploration capabilities, potentially leading to local optimization problems.
In this study, we propose a hybrid method that combines the BDA algorithm with the directed differential operator to improve the performance of BDA. An adaptive step-updating mechanism is also proposed to enhance the exploration capability of the algorithm which improves the search performance. The proposed method has been tested on 14 mainstream datasets and compared with seven representative feature selection methods, including the DA variant algorithms. The main contributions of this study are as follows:
The algorithm incorporates an adaptive step-updating mechanism to optimize the search process. It adjusts the step size based on the stage of exploration: a longer step size benefits an early search, while a smaller step size is advantageous for later exploration. To achieve this, the dragonfly’s step size gradually decreases with each iteration, adapting to the evolving search landscape. This adaptive mechanism enhances the algorithm’s ability to balance exploration and exploitation, resulting in improved overall performance.
Based on the renowned differential evolution algorithm, we propose a directed differential operator. This operator utilizes information from both the best and worst positions of the dragonflies to guide the algorithm towards promising regions, facilitating more effective search and convergence to optimal solutions. Additionally, the size of the directed differential operator influences the balance between targeted exploitation and broad exploration. A larger operator emphasizes guidance, while a smaller one allows for greater exploration of the solution space. To achieve this balance, we design an adaptive updating mechanism to adjust the directed differential operator, playing a crucial role in optimizing exploration and exploitation within the search space.
We enhance BDA’s exploration capability by integrating it with the differential evolution algorithm (DE). During the position-updating phase of the dragonfly algorithm, individual positions are combined with the directed differential operator to guide the search in promising directions, accelerating convergence. To maintain population diversity, we introduce an adaptive method for updating the directed differential operator. Additionally, an adaptive update mechanism for the dragonfly step dynamically adjusts the step size to improve exploration in later stages. This integration significantly improves BDA’s performance and exploration capabilities.
The paper’s structure is as follows: In
Section 2, related works are discussed, focusing on recent feature selection algorithms and the binary dragonfly algorithm (BDA).
Section 3 provides a detailed explanation of the proposed hybrid BDA-DDO algorithm, including the three improvement mechanisms and the algorithm’s specific process.
Section 4 describes the experimental setup and analysis of the obtained results. Finally,
Section 5 presents the conclusion and proposes future research directions.
4. Experiments and Results Analysis
In this section, we evaluate the performance of three proposed BDA-DDO algorithms, namely LBDA-DDO, QBDA-DDO, and SBDA-DDO, which are the improved versions based on BDA.
Section 4.1 presents the details of the mainstream datasets. The parameter information of related algorithms is introduced in
Section 4.2.
Section 4.3 introduces the performance comparison analysis of the proposed algorithm and LBDA.
Section 4.4 presents a comparison between the proposed algorithm and QBDA.
Section 4.5 introduces the SBDA-DDO algorithm for comparison with SBDA.
Section 4.6 presents a comparison of BDA-DDO with other binary versions of metaheuristic-based feature selection algorithms.
4.1. Datasets
In this section, the performance of the proposed algorithm was evaluated on 14 popular datasets collected from the UCI repository [
47].
Table 1 provides detailed information about each of the datasets, which are commonly used by researchers to study feature selection methods. From
Table 1, it can be observed that the datasets vary in terms of the number of instances, features, and dimensions. This demonstrates that the proposed algorithm’s performance has been tested on datasets with different structures. Each dataset in
Table 1 was randomly divided into two sets: 80% for training and 20% for testing. To account for the algorithm’s randomness, we conducted 30 independent runs for each algorithm.
4.2. Parameter Settings
In this study, K-nearest neighbors (KNN) was utilized as the classification algorithm to evaluate the accuracy of the selected features. The datasets were divided into training and test sets using 10-fold cross-validation, and the classification error was calculated using K-nearest neighbors (KNN) with
k = 5. This experiment was conducted on a WIN10 system with NVIDIA GTX 1660 graphics card, Inter Core i5-11400 processor, 2.6 GHz main frequency, and 16 GB RAM; the 2021a version of matlab was used. To ensure the fairness of the experiments, we used the same parameter settings and biomimetic environment as described in the original paper. The relevant parameters of the algorithm are set as shown in
Table 2 below:
4.3. Comparison with LBDA Method
In this section, we obtain results on 14 mainstream datasets using the proposed FS method. The obtained results are compared with LBDA in three aspects: classification accuracy, number of selected features and fitness value.
Table 3 shows the comparison between BDA-DDO and LBDA in terms of classification accuracy, and it should be noted that LBDA1 indicates that the proposed algorithm does not apply an adaptive step-updating mechanism.
Table 4 shows the comparison of the proposed algorithm with LBDA in selecting the number of features.
Table 5 shows that BDA-DDO compares with LBDA in terms of fitness value.
Table 3 shows the classification accuracy obtained by LBDA-DDO, LBDA1, and LBDA on the 14 datasets. The results indicate that LBDA1 achieves higher classification accuracy on most datasets compared to LBDA, while LBDA-DDO consistently outperforms LBDA in terms of classification accuracy on all 14 datasets. Furthermore, considering the standard deviations, LBDA-DDO demonstrates better robustness than LBDA, indicating its ability to handle variations in the datasets more effectively. Therefore, LBDA-DDO can achieve better results by utilizing an adaptive step size strategy, which enhances the algorithm’s search capability in the later stages and balances the trade-off between exploration and exploitation.
Table 4 illustrates the average number of selected features by the proposed LBDA-DDO algorithm on the datasets, with the best results highlighted in bold. The findings in
Table 4 indicate that LBDA-DDO consistently selects fewer features than LBDA and LBDA1 across all 14 datasets. Furthermore, LBDA1 demonstrates a lower feature count compared to LBDA. These results demonstrate the ability of the proposed algorithm to effectively reduce the number of selected features in comparison to LBDA, thereby eliminating noisy or irrelevant features that may have been chosen by the LBDA method. This outcome aligns perfectly with our main objective.
Table 5 illustrates the average fitness results obtained by the proposed LBDA-DDO algorithm. As before, the best results are shown in bold. The results show that the fitness values obtained by LBDA-DDO on the nine datasets are lower than those of LBDA and LBDA1. On the two datasets Breastcancer and penglungEW, LBDA-DDO and LBDA1 exhibit the same fitness values. On Lymphography, LBDA1 achieves the best results. Overall, LBDA-DDO performs better than LBDA.
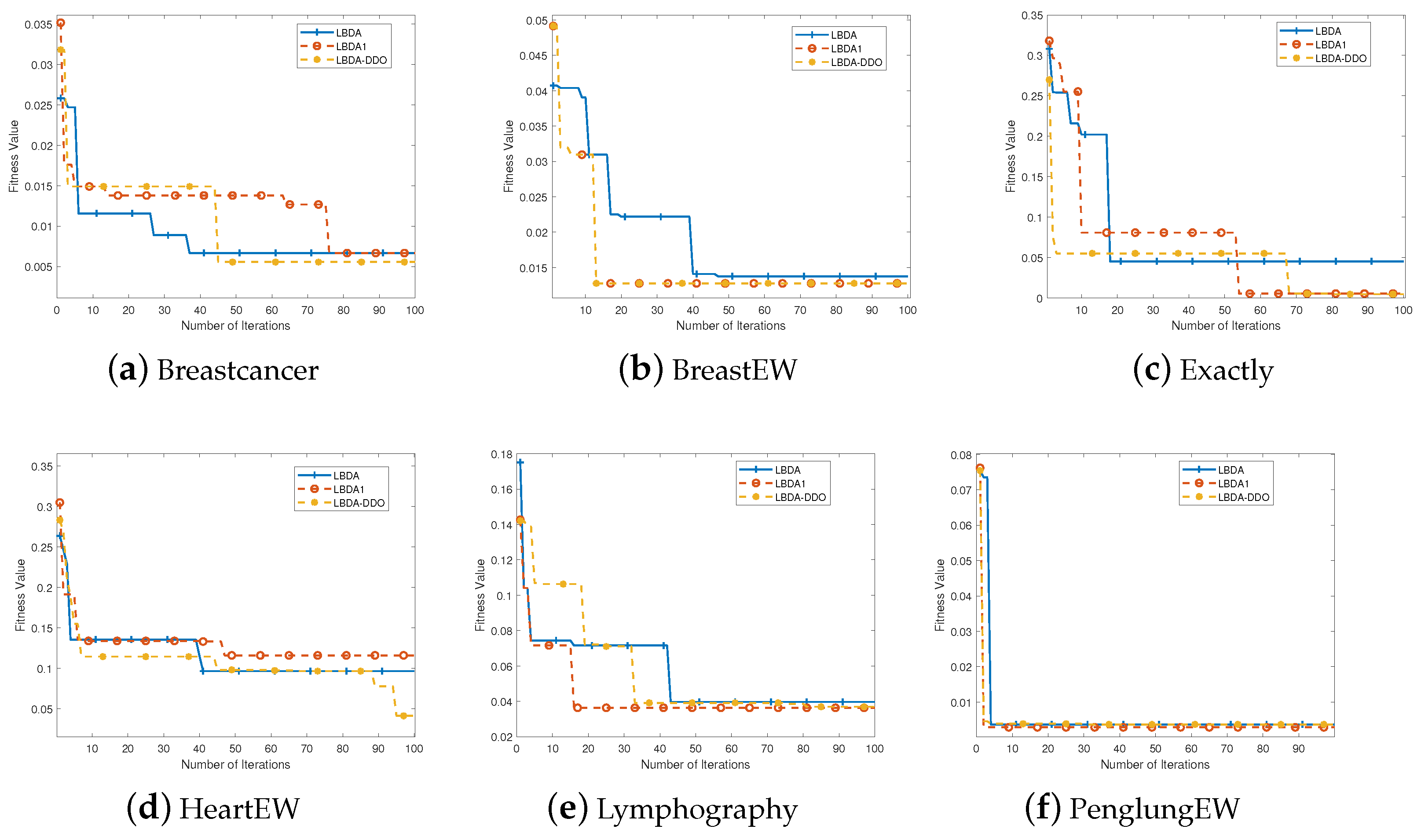
Figure 1 presents the convergence behavior of the proposed LBDA-DDO algorithm on 14 mainstream datasets, comparing it with LBDA and LBDA1. LBDA refers to the binary dragonfly algorithm with linear model updating, while LBDA1 represents the proposed algorithm(LBDA-DDO) without the adaptive step-updating mechanism. The
X-axis shows the number of iterations, and the
Y-axis displays the fitness value. The results show that the proposed algorithm achieves better convergence on most datasets. This indicates an enhanced search capability, especially with the inclusion of the adaptive step-updating mechanism. The proposed algorithm effectively avoids getting stuck in local optima.
Additionally, it can be observed that LBDA exhibits slower convergence on certain datasets, necessitating more iterations to attain satisfactory fitness values. Consequently, the proposed algorithm holds an advantage in terms of convergence behavior, enabling it to swiftly discover high-quality solutions. This highlights the efficacy of the introduced directional difference operator strategy in accelerating convergence speed, while the adaptive step-updating mechanism enhances search capabilities. In summary, the proposed algorithm outperforms LBDA by achieving faster convergence and yielding solutions with higher fitness values.
4.4. Comparison with QBDA Method
In this section, the performance of the proposed QBDA-DDO algorithm is examined, which combines the QBDA method with DE. QBDA1 is also included as an algorithm without the adaptive step size mechanism. For the performance of the algorithm, a comparison is conducted with QBDA in three aspects: classification accuracy, selected features, and fitness values.
Table 6 presents the comparison of the classification accuracy between the proposed algorithm and QBDA.
Table 7 shows the comparison of selected features between QBDA-DDO and QBDA. Additionally,
Table 8 provides a comparison of fitness values between the QBDA-DDO algorithm and QBDA. Furthermore,
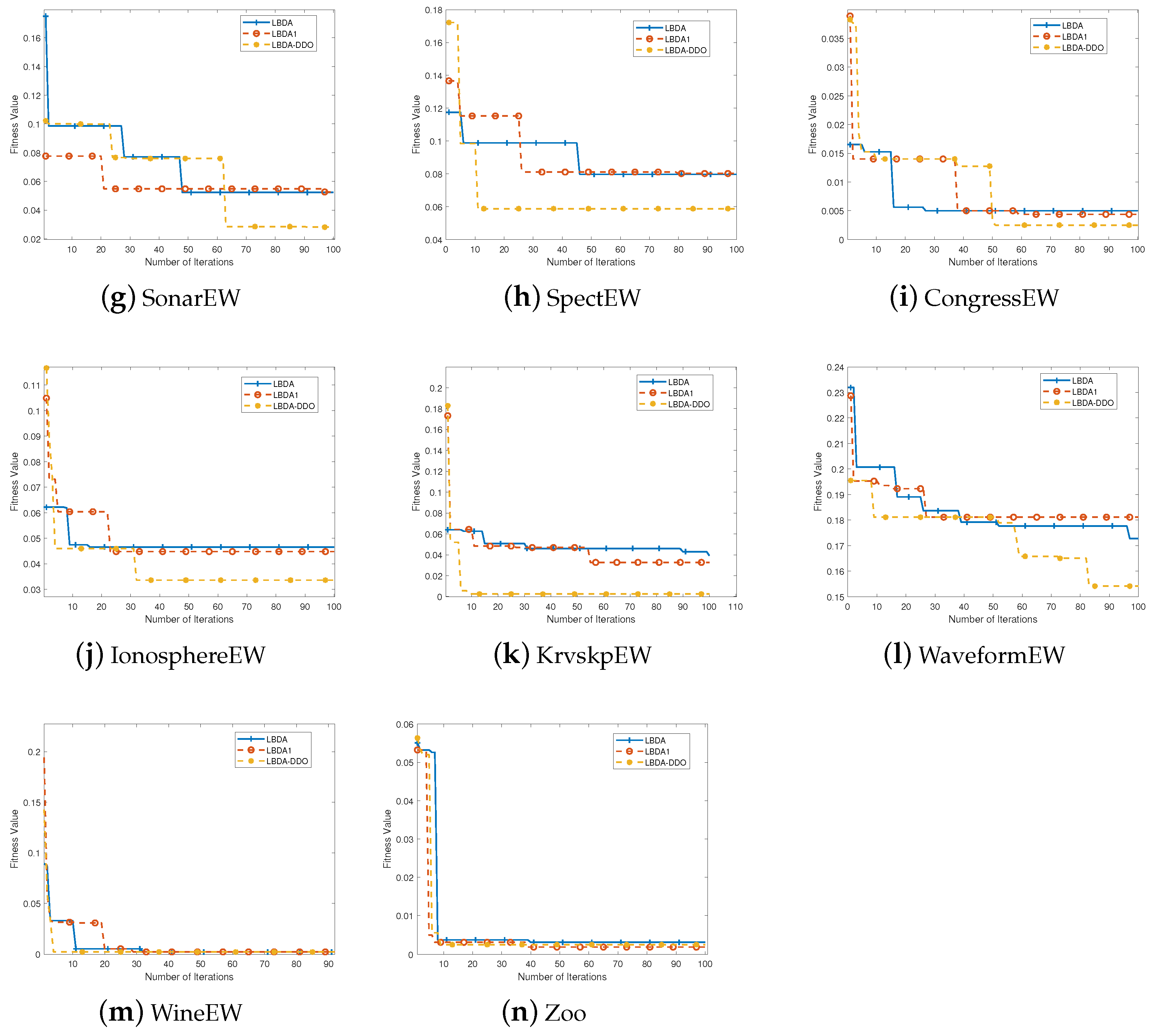
Figure 2 shows the convergence speed of the three algorithms on the 14 mainstream datasets for visual analysis.
Table 6 displays the average classification accuracy achieved by the proposed QBDA-DDO algorithm. QBDA-DDO achieves the best results on seven datasets, while the results of the three algorithms are equal on three datasets. QBDA1 and BDA-DDO obtain the same results on Breastcancer and CongressEW. For BreastEW and SonarEW, QBDA1 performs the best. Therefore, the directional differential operator and adaptive step size, when applied to QBDA, can effectively improve the classification accuracy of feature selection, highlighting the effectiveness of the algorithm innovation.
Table 7 shows the average number of selected features obtained by the proposed BDA-DDO algorithm, with the best results highlighted in bold. The results demonstrate that the BDA-DDO algorithm achieves the best results on all 13 datasets, while QBDA1 outperforms QBDA on most datasets. This indicates that the directional differential operator mechanism assists QBDA in converging to favorable solutions, while the adaptive step size enhances the algorithm’s search capability in the later stages. In summary, these improvements facilitate the removal of redundant and noisy features, resulting in enhancing algorithm performance.
Table 8 presents the average fitness values obtained by the QBDA-DDO algorithm, with the best results highlighted in bold. It is evident from the table that QBDA-DDO consistently outperforms QBDA in terms of average fitness values on the majority of datasets. The fitness value serves as an indicator of the combined performance in terms of classification accuracy and the number of selected features. Thus, the proposed algorithm demonstrates superior performance compared to QBDA, showcasing its effectiveness in better overall results.
Figure 2 depicts the convergence behavior of the proposed QBDA-DDO algorithm compared to QBDA and QBDA1 on 14 mainstream datasets. QBDA represents the binary dragonfly algorithm with quadratic model-based parameter updates. The
X-axis represents the number of iterations, and the
Y-axis represents the fitness values. The results demonstrate that the proposed QBDA-DDO algorithm exhibits superior search capability in the later stages compared to QBDA for most datasets. The proposed algorithm effectively avoids getting trapped in local optima.
4.5. Comparison with SBDA Method
In this section, we carried out tests on the proposed method from three perspectives: classification accuracy, number of selected features, and fitness value. We also compared it with the SBDA algorithm, where SBDA1 represents the algorithm without the application of an adaptive step size mechanism.
Table 9 presents the classification accuracy achieved by the proposed method on the 14 mainstream datasets.
Table 10 displays the number of selected features obtained by SBDA-DDO.
Table 11 shows the fitness values achieved by SBDA-DDO on the 14 datasets. Additionally,
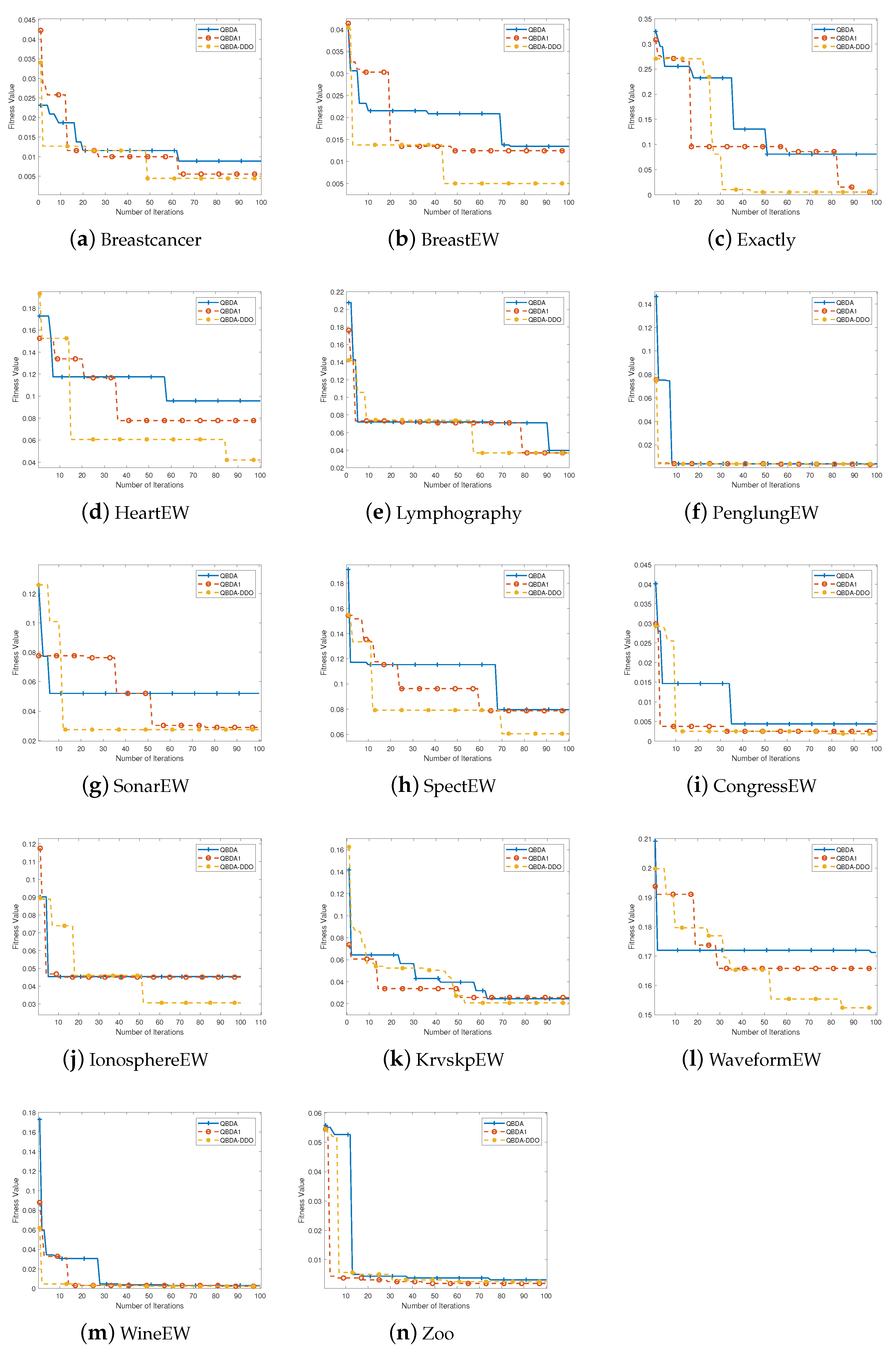
Figure 3 is used to compare the convergence speed of SBDA-DDO and SBDA on the 14 mainstream datasets.
In terms of classification accuracy, according to the results in
Table 9, the SBDA-DDO algorithm achieves the best results on seven datasets, which are highlighted in bold. It is noteworthy that SBDA1 achieves the same classification accuracy as QBDA-DDO on five datasets, and all three algorithms show the same accuracy on three datasets. This indicates that the integration of the direction differential operator and the adaptive step size mechanism further improves the performance of the SBDA algorithm. Therefore, SBDA-DDO demonstrates superior ability to classify the datasets.
In terms of the number of selected features, it can be seen from
Table 10 that BDA-DDO can achieve better performance, BDA-DDO achieves the best results on eight datasets, and SBDA1 obtained the best results on six datasets. Therefore, BDA-DDO is able to select fewer features, proving that the adaptive step can improve the performance of the algorithm, while the results obtained by SBDA1 are better than the original SBDA algorithm.
Table 11 illustrates the results obtained by the proposed SBDA-DDO algorithm in terms of fitness values, with the best results highlighted in bold. It can be observed that SBDA-DDO outperforms other algorithms on 13 datasets, while SBDA1 achieves the best results on 6 datasets. Remarkably, SBDA-DDO and SBDA1 yield the same results on five datasets. These findings confirm the effectiveness of our innovative approach, which incorporates direction differential operators and adaptive step size mechanisms into three different methods. The combination of these innovations with each algorithm demonstrates superior performance compared to the original algorithms. Consequently, our proposed approach enhances the algorithm’s performance by achieving improved classification accuracy while selecting fewer features.
Figure 3 depicts the convergence behavior of the proposed SBDA-DDO algorithm on 14 datasets, and the comparison with SBDA and SBDA1. SBDA represents the binary dragonfly algorithm with parameter updates using the cosine model. The
X-axis represents the number of iterations, and the
Y-axis displays the corresponding fitness values. Results show that SBDA-DDO exhibits faster convergence than SBDA for most datasets, thanks to the direction differential operator guiding individuals towards more promising directions. In addition, the later search ability of this algorithm is obviously stronger than that of SBDA, especially after using the adaptive step size mechanism.
The result of
Figure 1,
Figure 2 and
Figure 3 confirms the significant impact of the proposed innovative mechanisms on enhancing the performance of BDA with various update strategies (linear, quadratic, and cosine). The results indicate that the introduced improvements effectively boost the performance of the three BDA variants, particularly improving their search capabilities in later stages and facilitating escape from local optima. This highlights the versatility and effectiveness of the proposed mechanisms in various scenarios, affirming the algorithm’s robustness and adaptability.
4.6. Comparison with Other Binary Optimization Algorithms
In the previous section, we compared the proposed BDA-DDO algorithm and three enhanced versions of BDA (LBDA, QBDA, SBDA) [
40] in terms of classification accuracy, selected feature count, and fitness values. Now, we extend the comparison to four other typical metaheuristic feature selection algorithms: binary grey wolf optimization (BGWO) [
48], the binary bat algorithm (BBA) [
49], binary atomic search optimization (BASO) [
50], and the binary gravitational search algorithm (BGSA) [
49]. The results are presented in
Table 12,
Table 13 and
Table 14 for classification accuracy, selected feature count, and fitness values, respectively. By considering these additional algorithms, we aim to provide a comprehensive evaluation of the performance of the proposed BDA-DDO algorithm.
Based on the results in
Table 12, we compared our proposed method with BGWO, BBA, BASO, and BGSA in terms of classification accuracy. The best results are highlighted in bold. QBDA-DDO achieved the highest classification accuracy on 12 datasets, while LBDA-DDO and SBDA-DDO obtained the best results on 8 and 6 datasets, respectively. Therefore, QBDA outperformed other algorithms in improving classification accuracy.
The superior performance of QBDA-DDO can be attributed to its specific algorithmic strategies. By integrating the strengths of the QBDA algorithm and incorporating the direction bias operator and adaptive step size mechanism, QBDA-DDO provides efficient and accurate search capabilities. These strategies guide individuals in more promising directions, leading to improved classification accuracy. Furthermore, both LBDA-DDO and SBDA-DDO also demonstrate competitive performance on their respective datasets, achieving relatively good results.
Table 13 shows the average number of selected features for the proposed algorithm and four comparison algorithms on the 14 datasets. LBDA-DDO, QBDA-DDO, and BASO achieved similar performance, obtaining the best results on four datasets. On the other hand, the BBA algorithm demonstrated its advantage in feature selection by obtaining the best results on two datasets. The comparable performance of LBDA-DDO, QBDA-DDO, and BASO indicates their effectiveness in selecting a reasonable number of features on different datasets.
Overall, the results in
Table 13 emphasize the importance of algorithm selection in the feature selection task. This comparison provides us with the advantages and disadvantages of different algorithms and helps researchers and practitioners to choose the most suitable method according to the specific dataset and needs.
Table 14 presents a comprehensive comparison of our proposed BDA-DDO algorithm and four comparison algorithms (BGWO, BBA, BASO, and BGSA) based on their average fitness values across 14 datasets. The results clearly demonstrate that QBDA-DDO outperforms the other algorithms, achieving the best fitness values on all 13 datasets. Additionally, LBDA-DDO and SBDA-DDO also show strong competitiveness by obtaining the best results on seven and three datasets, respectively. This highlights the effectiveness of the proposed algorithm compared to the four representative feature selection methods, demonstrating its superior performance.
Based on the analysis of the classification accuracy, number of selected features, and fitness, the proposed BDA-DDO algorithm consistently outperforms other algorithms across the majority of datasets. Among them, the QBDA-DDO algorithm demonstrates the highest performance, followed by LBDA-DDO and SBDA-DDO. The results highlight the effectiveness of our proposed method in selecting a smaller subset of features while achieving superior classification accuracy. Moreover, the proposed algorithm exhibits faster convergence speed and higher solution quality compared to three improved BDA algorithms. Furthermore, it proves to be highly competitive when compared to other feature selection algorithms.
5. Conclusions and Future Work
The purpose of this paper is to enhance the performance of the BDA algorithm through a hybrid approach. This goal has been successfully achieved by introducing three improvement mechanisms. Firstly, a novel differential operator, called the directed differential operator, is designed. Combining BDA with the directed differential operator provides a correct direction for the search process, resulting in faster convergence. Secondly, an adaptive update method is devised to enhance population diversity by updating the directed differential vector. Lastly, an adaptive step-updating mechanism is proposed to enhance the algorithm’s exploration capability by adjusting the dragonfly step.
The proposed algorithm is evaluated on 14 mainstream datasets from the UCI library and compared with seven representative feature selection algorithms. The experimental results show that the proposed BDA-DDO algorithm outperforms LBDA on 10 datasets in terms of classification accuracy, while achieving the same accuracy on 4 datasets. Additionally, BDA-DDO selects smaller feature subsets than LBDA on all 14 datasets. Compared to QBDA, BDA-DDO achieves higher classification accuracy on 10 datasets and the same accuracy on some low-dimensional datasets (reaching 1). Moreover, BDA-DDO selects smaller feature subsets than QBDA on all 14 datasets. When compared with SBDA, BDA-DDO achieves higher classification accuracy on nine datasets and selects fewer features on 13 datasets. In conclusion, BDA-DDO demonstrates its superiority over the three BDA algorithms (LBDA, QBDA, and SBDA) by consistently achieving higher classification accuracy while selecting smaller feature subsets on most datasets. Moreover, when compared to four other typical feature selection algorithms (BGWO, BBA, BASO, and BGSA), it also achieves higher classification accuracy.
Although the proposed improvement mechanisms have successfully enhanced the performance of the BDA algorithm, there are still some limitations. Specifically, the algorithm’s performance may be constrained when dealing with complex optimization scenarios, such as high-dimensional or large-scale datasets. Additionally, the feature selection problem is a multimodal problem, where the same number of features may correspond to different feature subsets. Currently, the algorithm may not be able to find all possible feature subsets. Moreover, the algorithm has not been tested in real-world applications, such as remote sensing tasks. Therefore, further research and experimentation is needed to address these issues and ensure the algorithm’s applicability and effectiveness in practical scenarios.
In future research, our main focus will be to explore the practical applications of the proposed algorithm, particularly in the field of remote sensing [
51]. Remote sensing datasets often exhibit high dimensionality and large scale, with a substantial number of features, samples, and classes, and may contain feature correlations or redundancies. These characteristics make the feature selection problem in remote sensing datasets more complex and challenging, requiring consideration of feature interactions and impacts, as well as the efficiency and stability of feature selection algorithms.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}