
Sat-Mesh: Learning Neural Implicit Surfaces for Multi-View Satellite Reconstruction


Abstract
:
1. Introduction
- For the first time, we applied implicit surface reconstruction techniques to satellite imagery, directly generating high-quality 3D mesh models.
- We introduce a robust MVS constraint for accurately learning the implicit surface. By minimizing the photo-consistency between multi-view satellite images, we guarantee that the learned surface is geometry-consistent.
- We introduce the latent appearance in the network architecture to learn the seasonal variations of the satellite images. The learned latent allows for the realistic rendering of novel views with different seasonal appearances, achieving varied seasonal texture mapping for the reconstructed mesh.
2. Related Work
2.1. Pair-Based Satellite Reconstruction
2.2. NeRF-Based Satellite Photogrammetry
2.3. Nueal Surface Reconstruction
2.4. Photometric 3D Reconstruction
2.5. Perspective Approximate for RPC Camera
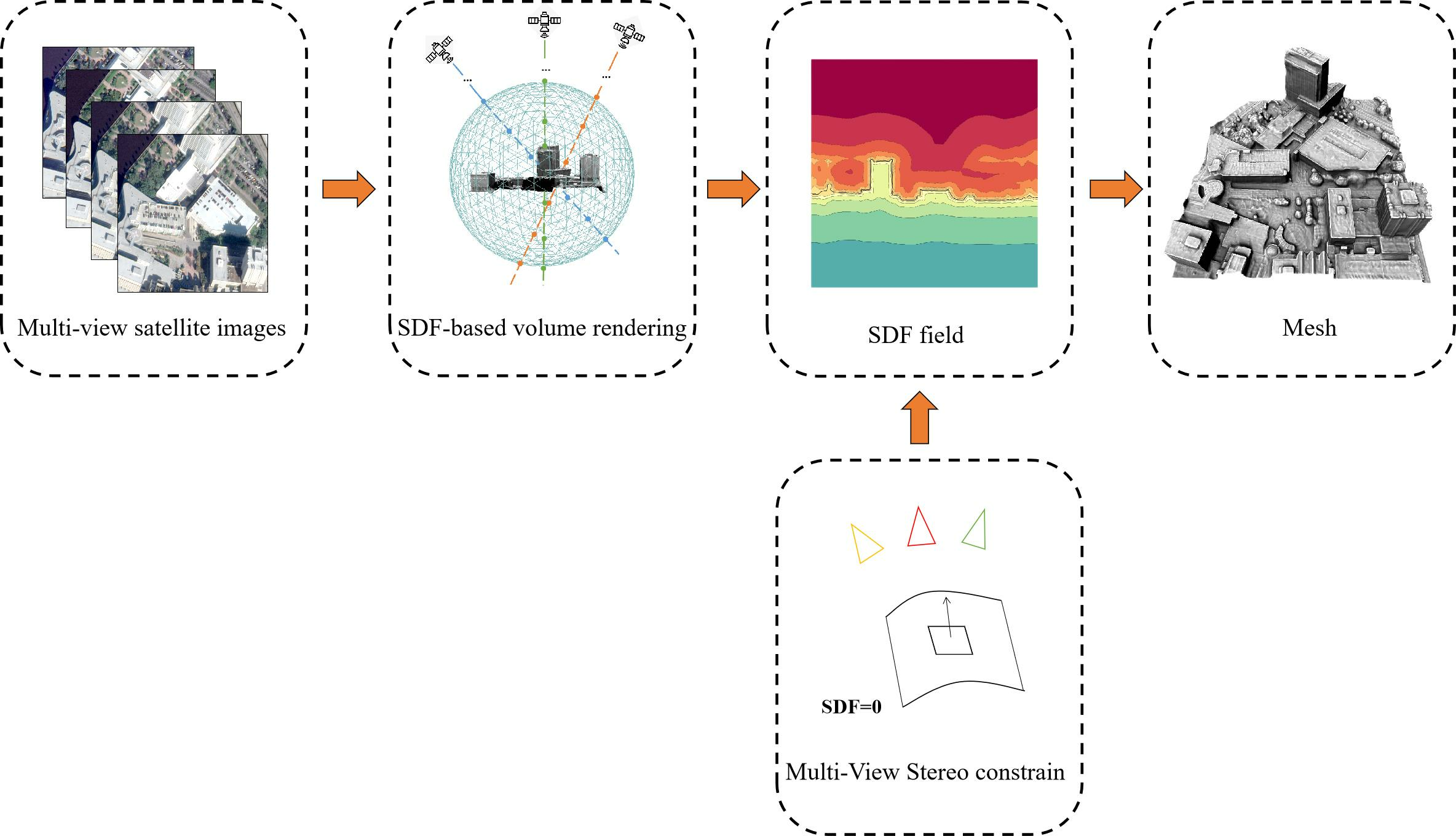
3. Method
3.1. SDF-Based Volume Rendering
3.2. Multi-View Stereo Constrain
3.3. Network Architecture
3.4. Loss Function and Implement Details
4. Results
4.1. Baseline and Datasets
4.2. Qualitative Analysis
4.3. Quantitative Analysis
4.4. Ablation Study
4.5. Latent Appearance and Texturing
5. Discussion
5.1. Our One-Stage Method vs. Two-Stage Methods
5.2. Computing Power
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, Q.; Yu, L.; Du, Z.; Peng, D.; Hao, P.; Zhang, Y.; Gong, P. An overview of the applications of earth observation satellite data: Impacts and future trends. Remote Sens. 2022, 14, 1863. [Google Scholar] [CrossRef]
- Beyer, R.A.; Alexandrov, O.; McMichael, S. The Ames Stereo Pipeline: NASA’s open source software for deriving and processing terrain data. Earth Space Sci. 2018, 5, 537–548. [Google Scholar] [CrossRef]
- Rupnik, E.; Daakir, M.; Pierrot Deseilligny, M. MicMac—A free, open-source solution for photogrammetry. Open Geospat. Data Softw. Stand. 2017, 2, 14. [Google Scholar] [CrossRef]
- Qin, R. Rpc stereo processor (rsp)—A software package for digital surface model and orthophoto generation from satellite stereo imagery. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 77–82. [Google Scholar] [CrossRef]
- Facciolo, G.; De Franchis, C.; Meinhardt-Llopis, E. Automatic 3D reconstruction from multi-date satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 57–66. [Google Scholar]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Rothermel, M.; Gong, K.; Fritsch, D.; Schindler, K.; Haala, N. Photometric multi-view mesh refinement for high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 52–62. [Google Scholar] [CrossRef]
- Bullinger, S.; Bodensteiner, C.; Arens, M. 3D Surface Reconstruction From Multi-Date Satellite Images. arXiv 2021, arXiv:2102.02502. [Google Scholar] [CrossRef]
- Park, S.-Y.; Seo, D.; Lee, M.-J. GEMVS: A novel approach for automatic 3D reconstruction from uncalibrated multi-view Google Earth images using multi-view stereo and projective to metric 3D homography transformation. Int. J. Remote Sens. 2023, 44, 3005–3030. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Martin-Brualla, R.; Radwan, N.; Sajjadi, M.S.; Barron, J.T.; Dosovitskiy, A.; Duckworth, D. Nerf in the wild: Neural radiance fields for unconstrained photo collections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Barron, J.T.; Mildenhall, B.; Verbin, D.; Srinivasan, P.P.; Hedman, P. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5470–5479. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. 2022, 41, 1–15. [Google Scholar] [CrossRef]
- Derksen, D.; Izzo, D. Shadow neural radiance fields for multi-view satellite photogrammetry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1152–1161. [Google Scholar]
- Marí, R.; Facciolo, G.; Ehret, T. Sat-nerf: Learning multi-view satellite photogrammetry with transient objects and shadow modeling using rpc cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 1311–1321. [Google Scholar]
- Fu, Q.; Xu, Q.; Ong, Y.S.; Tao, W. Geo-neus: Geometry-consistent neural implicit surfaces learning for multi-view reconstruction. Adv. Neural Inf. Process. Syst. 2022, 35, 3403–3416. [Google Scholar]
- Sun, J.; Chen, X.; Wang, Q.; Li, Z.; Averbuch-Elor, H.; Zhou, X.; Snavely, N. Neural 3d reconstruction in the wild. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–9. [Google Scholar]
- Wang, Y.; Skorokhodov, I.; Wonka, P. PET-NeuS: Positional Encoding Tri-Planes for Neural Surfaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12598–12607. [Google Scholar]
- Wang, P.; Liu, L.; Liu, Y.; Theobalt, C.; Komura, T.; Wang, W. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. arXiv 2021, arXiv:2106.10689. [Google Scholar]
- Bojanowski, P.; Joulin, A.; Lopez-Paz, D.; Szlam, A. Optimizing the latent space of generative networks. arXiv 2017, arXiv:1707.05776. [Google Scholar]
- Zhang, K.; Snavely, N.; Sun, J. Leveraging vision reconstruction pipelines for satellite imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Kajiya, J.T.; Von Herzen, B.P. Ray tracing volume densities. ACM SIGGRAPH Comput. Graph. 1984, 18, 165–174. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Zabih, R.; Woodfill, J. Non-parametric local transforms for computing visual correspondence. In Proceedings of the Computer Vision—ECCV’94: Third European Conference on Computer Vision, Stockholm, Sweden, 2–6 May 1994; Springer: Berlin/Heidelberg, Germany; Volume II 3, pp. 151–158. [Google Scholar]
- Facciolo, G.; De Franchis, C.; Meinhardt, E. MGM: A significantly more global matching for stereovision. In Proceedings of the BMVC 2015, Swansea, UK, 7–10 September 2015. [Google Scholar]
- Rothermel, M.; Wenzel, K.; Fritsch, D.; Haala, N. SURE: Photogrammetric surface reconstruction from imagery. In Proceedings of the LC3D Workshop, Berlin, Germany, 4–5 December 2012; Volume 8. [Google Scholar]
- Lastilla, L.; Ravanelli, R.; Fratarcangeli, F.; Di Rita, M.; Nascetti, A.; Crespi, M. FOSS4G DATE for DSM generation: Sensitivity analysis of the semi-global block matching parameters. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 67–72. [Google Scholar] [CrossRef]
- Gómez, A.; Randall, G.; Facciolo, G.; von Gioi, R.G. An experimental comparison of multi-view stereo approaches on satellite images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 844–853. [Google Scholar]
- He, S.; Zhou, R.; Li, S.; Jiang, S.; Jiang, W. Disparity estimation of high-resolution remote sensing images with dual-scale matching network. Remote Sens. 2021, 13, 5050. [Google Scholar] [CrossRef]
- Marí, R.; Ehret, T.; Facciolo, G. Disparity Estimation Networks for Aerial and High-Resolution Satellite Images: A Review. Image Process. Line 2022, 12, 501–526. [Google Scholar] [CrossRef]
- Zhang, F.; Prisacariu, V.; Yang, R.; Torr, P.H. Ga-net: Guided aggregation net for end-to-end stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 185–194. [Google Scholar]
- Chang, J.-R.; Chen, Y.-S. Pyramid stereo matching network. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5410–5418. [Google Scholar]
- Yang, G.; Manela, J.; Happold, M.; Ramanan, D. Hierarchical deep stereo matching on high-resolution images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5515–5524. [Google Scholar]
- Marí, R.; Facciolo, G.; Ehret, T. Multi-Date Earth Observation NeRF: The Detail Is in the Shadows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2034–2044. [Google Scholar]
- Yu, Z.; Peng, S.; Niemeyer, M.; Sattler, T.; Geiger, A. Monosdf: Exploring monocular geometric cues for neural implicit surface reconstruction. Adv. Neural Inf. Process. Syst. 2022, 35, 25018–25032. [Google Scholar]
- Li, Z.; Müller, T.; Evans, A.; Taylor, R.H.; Unberath, M.; Liu, M.-Y.; Lin, C.-H. Neuralangelo: High-Fidelity Neural Surface Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8456–8465. [Google Scholar]
- Wang, Y.; Han, Q.; Habermann, M.; Daniilidis, K.; Theobalt, C.; Liu, L. Neus2: Fast learning of neural implicit surfaces for multi-view reconstruction. arXiv 2022, arXiv:2212.05231. [Google Scholar]
- Ju, Y.; Peng, Y.; Jian, M.; Gao, F.; Dong, J. Learning conditional photometric stereo with high-resolution features. Comput. Vis. Media 2022, 8, 105–118. [Google Scholar] [CrossRef]
- Chen, G.; Han, K.; Wong, K.-Y.K. PS-FCN: A flexible learning framework for photometric stereo. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–18. [Google Scholar]
- Yao, Z.; Li, K.; Fu, Y.; Hu, H.; Shi, B. Gps-net: Graph-based photometric stereo network. Adv. Neural Inf. Process. Syst. 2020, 33, 10306–10316. [Google Scholar]
- Lv, B.; Liu, J.; Wang, P.; Yasir, M. DSM Generation from Multi-View High-Resolution Satellite Images Based on the Photometric Mesh Refinement Method. Remote Sens. 2022, 14, 6259. [Google Scholar] [CrossRef]
- Qu, Y.; Yan, Q.; Yang, J.; Xiao, T.; Deng, F. Total Differential Photometric Mesh Refinement with Self-Adapted Mesh Denoising. Photonics 2022, 10, 20. [Google Scholar] [CrossRef]
- Schonberger, J.L.; Frahm, J.-M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Schönberger, J.L.; Zheng, E.; Frahm, J.-M.; Pollefeys, M. Pixelwise view selection for unstructured multi-view stereo. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part III 14. pp. 501–518. [Google Scholar]
- Xiao, T.; Wang, X.; Deng, F.; Heipke, C. Sequential Cycle Consistency Inference for Eliminating Incorrect Relative Orientations in Structure from Motion. PFG–J. Photogramm. Remote Sens. Geoinf. Sci. 2021, 89, 233–249. [Google Scholar] [CrossRef]
- Furukawa, Y.; Hernández, C. Multi-view stereo: A tutorial. In Foundations and Trends® in Computer Graphics and Vision; Now Publishers Inc.: Hanover, MA, USA, 2015; Volume 9, pp. 1–148. [Google Scholar]
- Romanoni, A.; Matteucci, M. Tapa-mvs: Textureless-aware patchmatch multi-view stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10413–10422. [Google Scholar]
- Xu, Q.; Tao, W. Multi-Scale Geometric Consistency Guided Multi-View Stereo. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lorensen, W.E.; Cline, H.E. Marching cubes: A high resolution 3D surface construction algorithm. In Seminal Graphics: Pioneering Efforts That Shaped the Field; Association for Computing Machinery: New York, NY, USA, 1998; pp. 347–353. [Google Scholar]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multi-view stereopsis (pmvs). In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 165–174. [Google Scholar]
- Salimans, T.; Kingma, D.P. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. arXiv 2016, arXiv:1602.07868. [Google Scholar]
- Gropp, A.; Yariv, L.; Haim, N.; Atzmon, M.; Lipman, Y. Implicit geometric regularization for learning shapes. arXiv 2020, arXiv:2002.10099. [Google Scholar]
- Zhou, Q.-Y.; Park, J.; Koltun, V. Open3D: A modern library for 3D data processing. arXiv 2018, arXiv:1801.09847. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Bosch, M.; Foster, K.; Christie, G.; Wang, S.; Hager, G.D.; Brown, M. Semantic stereo for incidental satellite images. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1524–1532. [Google Scholar]
- Le Saux, B.; Yokoya, N.; Hänsch, R.; Brown, M. 2019 ieee grss data fusion contest: Large-scale semantic 3d reconstruction. IEEE Geosci. Remote Sens. Mag. (GRSM) 2019, 7, 33–36. [Google Scholar] [CrossRef]
- Delaunoy, A.; Prados, E. Gradient flows for optimizing triangular mesh-based surfaces: Applications to 3d reconstruction problems dealing with visibility. Int. J. Comput. Vis. 2011, 95, 100–123. [Google Scholar] [CrossRef]
- Bosch, M.; Kurtz, Z.; Hagstrom, S.; Brown, M. A multiple view stereo benchmark for satellite imagery. In Proceedings of the 2016 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 18–20 October 2016; pp. 1–9. [Google Scholar]
- Waechter, M.; Moehrle, N.; Goesele, M. Let there be color! Large-scale texturing of 3D reconstructions. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part V 13. pp. 836–850. [Google Scholar]
- Gómez, A.; Randall, G.; Facciolo, G.; von Gioi, R.G. Improving the Pair Selection and the Model Fusion Steps of Satellite Multi-View Stereo Pipelines. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6344–6353. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AOI | Images | Latitude | Longitude | Covering Size (m) |
|---|---|---|---|---|
| JAX_004 | 9 | 30.358 | −81.706 | [256 × 265] |
| JAX_068 | 17 | 30.349 | −81.664 | [256 × 265] |
| JAX_175 | 26 | 30.324 | −81.637 | [400 × 400] |
| JAX_214 | 21 | 30.316 | −81.663 | [256 × 265] |
| JAX_260 | 15 | 30.312 | −81.663 | [256 × 265] |
| OMA_132 | 43 | 41.295 | −95.920 | [400 × 400] |
| OMA_212 | 43 | 41.295 | −95.920 | [400 × 400] |
| OMA_246 | 43 | 41.276 | −95.921 | [400 × 400] |
| OMA_247 | 43 | 41.259 | −95.938 | [700 × 700] |
| OMA_248 | 43 | 41.267 | −95.931 | [400 × 400] |
| OMA_374 | 43 | 41.236 | −95.920 | [400 × 400] |
| JAX_004 | JAX_068 | JAX_214 | JAX_260 | Mean | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE↓ | MED↓ | Perc-1 m↑ | MAE↓ | MED↓ | Perc-1 m↑ | MAE↓ | MED↓ | Perc-1m↑ | MAE↓ | MED↓ | Perc-1 m↑ | MAE↓ | MED↓ | Perc-1 m↑ | |
| VisSat [21] | 1.700 | 0.794 | 0.523 | 1.383 | 0.766 | 0.702 | 2.208 | 1.118 | 0.346 | 1.647 | 0.948 | 0.384 | 1.734 | 0.906 | 0.489 |
| S2P [5] | 2.675 | 1.570 | 0.084 | 1.686 | 0.796 | 0.733 | 2.674 | 0.698 | 0.646 | 2.166 | 0.854 | 0.397 | 2.300 | 0.980 | 0.465 |
| S-NeRF [14] | 1.831 | 1.232 | 0.359 | 1.496 | 0.856 | 0.560 | 3.686 | 2.388 | 0.204 | 3.245 | 2.591 | 0.150 | 2.565 | 1.767 | 0.319 |
| Sat-NeRF [15] | 1.417 | 0.798 | 0.519 | 1.276 | 0.660 | 0.644 | 2.126 | 1.034 | 0.471 | 2.429 | 1.759 | 0.223 | 1.812 | 1.063 | 0.464 |
| Ours | 1.549 | 0.554 | 0.583 | 1.146 | 0.570 | 0.751 | 2.022 | 0.982 | 0.499 | 1.359 | 0.674 | 0.449 | 1.519 | 0.695 | 0.571 |
| Methods | JAX_004 | JAX_068 | JAX_214 | JAX_260 |
|---|---|---|---|---|
| VisSat [21] | 3.5 min | 7.5 min | 9.4 min | 5.9 min |
| S2P [5] | 19.2 min | 21.5 min | 25.4 min | 22.6 min |
| S-NeRF [14] | ~8 h | ~8 h | ~8 h | ~8 h |
| Sat-NeRF [15] | ~10 h | ~10 h | ~10 h | ~10 h |
| Ours | ~8 h | ~8 h | ~8 h | ~8 h |
| JAX_004 | JAX_068 | JAX_214 | JAX_260 | OMA_132 | OMA_212 | OMA_246 | OMA_247 | OMA_374 | |
|---|---|---|---|---|---|---|---|---|---|
| Input images | 9 | 17 | 21 | 15 | 43 | 43 | 43 | 43 | 43 |
| Our method without MVS constrain | 5027 | 5047 | 5049 | 5047 | 5267 | 5267 | 5267 | 5267 | 5267 |
| Our method with MVS constrain | 5671 | 5691 | 5691 | 5691 | 5911 | 5911 | 5911 | 5911 | 5911 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, Y.; Deng, F. Sat-Mesh: Learning Neural Implicit Surfaces for Multi-View Satellite Reconstruction. Remote Sens. 2023, 15, 4297. https://doi.org/10.3390/rs15174297
Qu Y, Deng F. Sat-Mesh: Learning Neural Implicit Surfaces for Multi-View Satellite Reconstruction. Remote Sensing. 2023; 15(17):4297. https://doi.org/10.3390/rs15174297
Chicago/Turabian StyleQu, Yingjie, and Fei Deng. 2023. "Sat-Mesh: Learning Neural Implicit Surfaces for Multi-View Satellite Reconstruction" Remote Sensing 15, no. 17: 4297. https://doi.org/10.3390/rs15174297
APA StyleQu, Y., & Deng, F. (2023). Sat-Mesh: Learning Neural Implicit Surfaces for Multi-View Satellite Reconstruction. Remote Sensing, 15(17), 4297. https://doi.org/10.3390/rs15174297