
Mix MSTAR: A Synthetic Benchmark Dataset for Multi-Class Rotation Vehicle Detection in Large-Scale SAR Images

Abstract
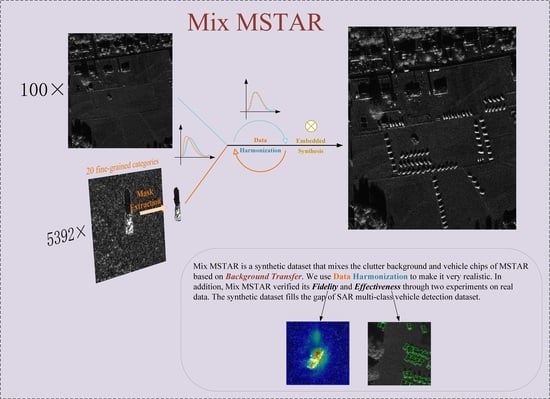
:
1. Introduction
- We improved the method of background transfer and generated realistic synthetic data by linearly fusing vehicle masks in Chips and Clutters, resulting in the fusion of 20 types of vehicles (5392 in total) into 100 large background images. The dataset adopts rotation bounding box annotation and includes one Standard Operating Condition (SOC) and two EOC partitioning strategies, making it a challenging and diverse dataset;
- Based on the Mix MSTAR, we evaluated nine benchmark models for general remote sensing object detection and analyzed their strengths and weaknesses for SAR-ATR;
- To address potential artificial traces and data variance in synthetic images, we designed two experiments to demonstrate the fidelity and effectiveness of Mix MSTAR in SAR image features, demonstrating that Mix MSTAR can serve as a benchmark dataset for evaluating deep learning-based SAR-ATR algorithms.
2. Materials and Methods
2.1. Preliminary Feasibility Assessment
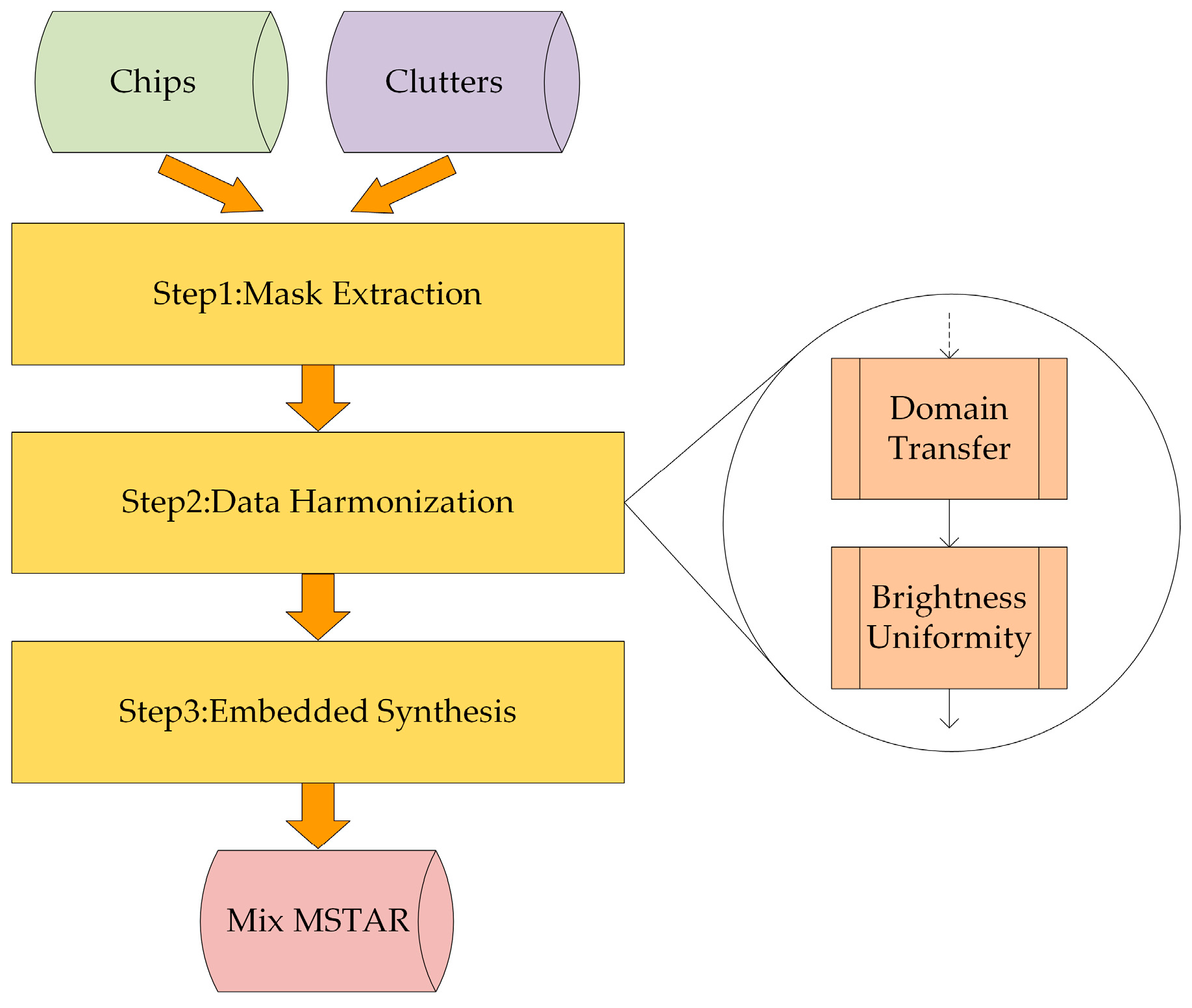
2.2. Mask Extraction
2.3. Data Harmonization
2.3.1. Domain Transfer
2.3.2. Brightness Uniformity
2.4. Embedded Synthesis
2.5. Analysis of the Dataset
3. Results
3.1. Models Selected
3.1.1. RotatedRetinanet
3.1.2. S2A-Net
3.1.3. R3Det
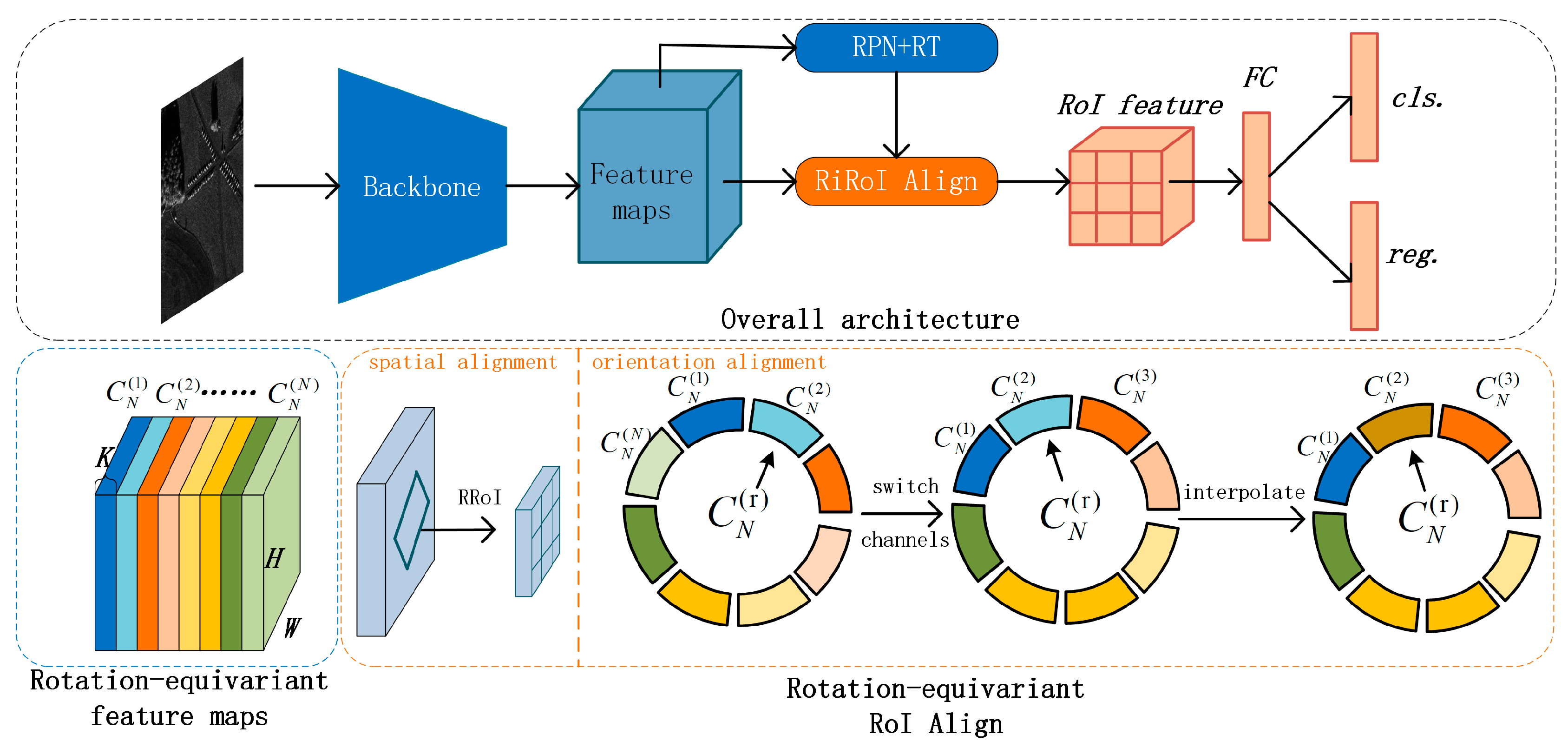
3.1.4. ROI Transformer
3.1.5. Oriented RCNN
3.1.6. Gliding Vertex
3.1.7. ReDet
3.1.8. Rotated FCOS
3.1.9. Oriented RepPoints
3.2. Evaluation Metrics
3.3. Environment and Details
3.4. Result Analysis on Mix MSTAR
- In terms of the mAP metric, Oriented RepPoints achieved the best accuracy, which we attribute to its unique proposal approach based on sampling points. This approach successfully combines deformation convolution and non-axis-aligned feature extraction. Additionally, being a two-stage model, its feature extraction is more accurate. Compared to other refine-stage models, it has more sampling points, up to 9, which makes the extracted features more comprehensive. However, the heavy use of deformation convolution has made its training speed slow. The two-stage model performs better than the single-stage network due to the initial screening of the RPN network. However, the performance of Gliding Vertex is average, which may be due to its failure to use directed proposals in the first stage, resulting in inaccurate feature extraction. ReDet has poor performance, possibly because the rotation-invariant network used in ReDet is not suitable for SAR images with low depression. Mix MSTAR is simulated at a depression of 15°, and the shadow area is quite large, leading to significant imaging differences for the same object under different azimuth angles. For example, rotating a vehicle image at an angle of θ by α degrees would produce an image that is significantly different from the image of the same vehicle captured at (θ + α) degrees, which may cause ReResNet to extract incorrect rotation-invariant features. Compared to single-stage models, refined-stage models demonstrate a significant performance improvement, suggesting that refined-stage models are more accurate in extracting non-axis-aligned features of rotated objects, which can reduce the gap between refined-stage models and two-stage models. While the performance of R3Det is slightly inferior, it is similar to ReDet, and its reason may lie in the sampling points in its refined stage, which are fixed at the four corners and the center point. In low-pitch-angle SAR images, one vertex far from the radar sensor is necessarily shaded, which means that the feature extraction of the sampling point interferes with the overall feature expression. S2A-Net uses deformation convolution, with the position of the sampling point being learnable. Although there is still a probability of collecting data from the shaded vertexes, there are nine sampling points, which dilutes the influence of features from the shaded vertexes;
- In terms of speed, Rotated FCOS performs the best, benefiting from its anchor-free design and full convolution structure. Its parameters and computation are both lower than those of Rotated Retinanet. In contrast, other models use deformation convolution, non-conventional feature Alignment Convolution, or non-full convolution structures, making network speed relatively slow. Due to its special rotation-equivariant convolution, ReDet has the slowest inference speed, even though its parameters and computation are the lowest. In terms of parameter quantities, the two anchor-free models and the single-stage model have fewer parameters than other models. The RPN of the ROI Transformer requires two stages to extract the rotation ROI, so it has the most parameters. In terms of computation, due to its multi-head design, the detection head of the single-stage model is too cumbersome, making its computation not significantly lower than that of the two-stage model. However, Mix MSTAR is a small target data set, with most of its ground truth width being below 32. After five downsamplings, its localization information has been lost. A better balance may be obtained by optimizing the regression subnetwork of layers with downsample sizes greater than 32;
- In terms of precision and recall metrics, all networks tend to maintain high recall. As using inter-class NMS limits the Recall integration range of mAP, like the DOTA, inter-class NMS is disabled. But this resulted in lower accuracy. Among them, ROI Transformer achieved a balance between accuracy and recall and obtained the highest F1 score;
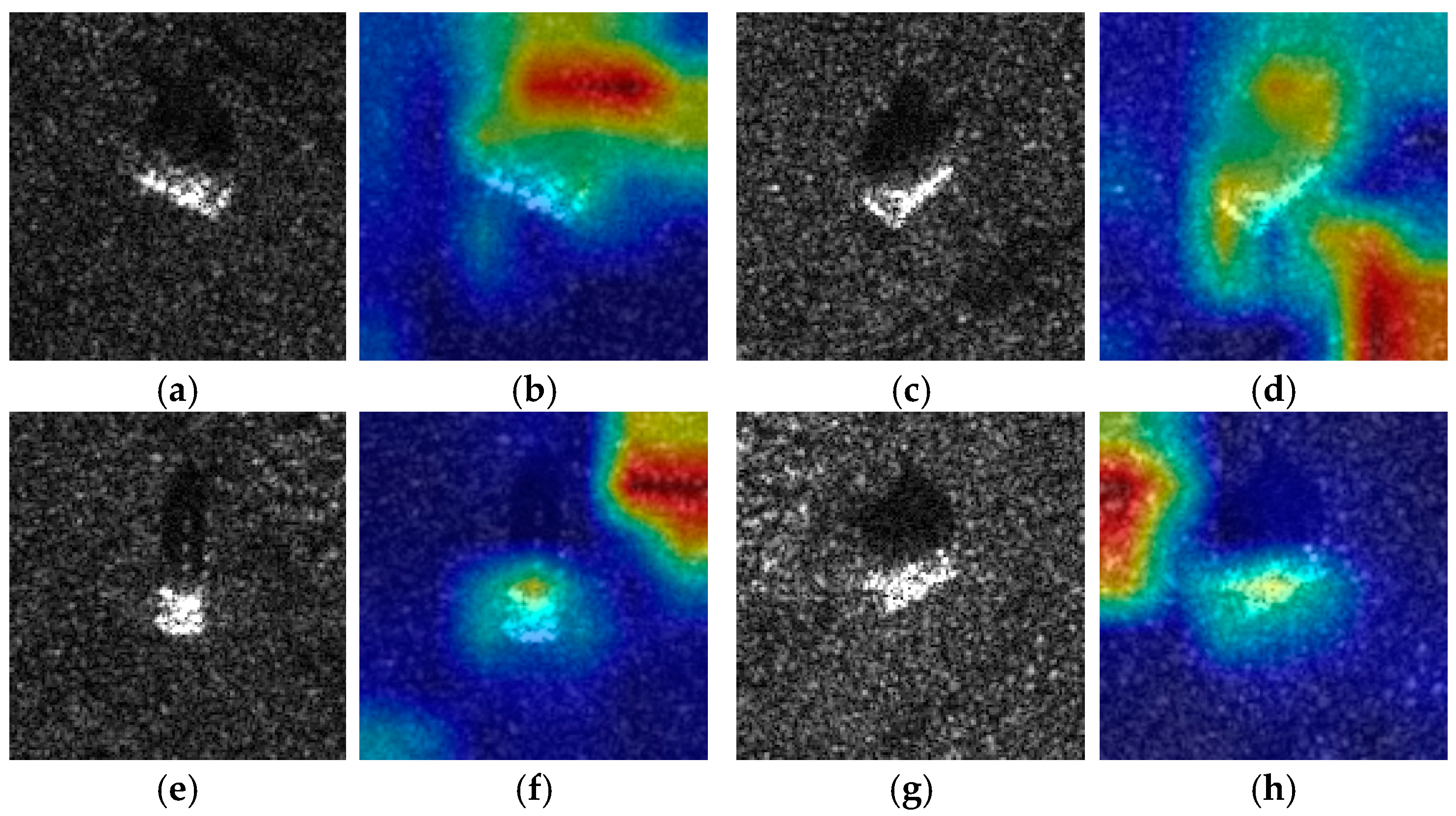
- From the results presented in Table 7, it is evident that the fine-grained classification result of the T72 tank is poor and has a significant impact on all detectors. Figure 16a further illustrates this point, as the confusion matrix of Oriented RepPoints indicates a considerable number of FP assigned to wrong subtypes of the T72 tank, which is also observed in cross-category confusion intervals such as BTR70-BTR60, 2S1-T62, and T72-T62. Another notable observation is the poor detection effect of BMP2 under EOC, as indicated in the confusion matrix. Many BMP2 subtypes that did not appear in the train set were mistaken for other vehicles in testing. Figure 16b depicts the P-R curves of all detectors;
- Figure 17 presents the detection results of three detectors on the same picture. The results showed that the localization of the vehicles was accurate, but the recognition accuracy was not high, with a small number of false positives and misses. Additionally, we discovered two unknown vehicles in the scene, which were initially hidden among the Clutters and did not belong to the Chips. One vehicle was recognized as T62 by all three models, while the other vehicle was classified as background, possibly because its area was significantly larger than the vehicles in the Mix MSTAR. This indicates that the model trained by Mix MSTAR has the ability to recognize real vehicles.
4. Discussion
- Artificial traces: The vehicle masks manually extracted can alter the contour features of the vehicles and leave artificial traces in the synthetic images. Even though Gaussian smoothing was applied to reduce this effect on the vehicle edges, theoretically, these traces could still be utilized by overfitting models to identify targets;
- Data variance: The vehicle and background data in Mix MSTAR were collected under different operating modes. Although we harmonized the data amplitude based on reasonable assumptions, Chips was collected using spotlight mode, while Clutters used strip mode. The two different scanning modes of radar can cause variances in the image style (particularly spatial distribution) of the foreground and background in the synthetic images. This could lead detection models to find some cheating shortcuts due to the non-realistic effects of the synthetic images, failing to extract common image features.
4.1. The Artificial Traces Problem
4.2. The Data Variance Problem
4.3. Potential Application
- SAR image generation. While mutual conversion between optical and SAR imagery is no longer a groundbreaking achievement, current style transfer methods between visible light and SAR are primarily used for low-resolution terrain classification [59]. Given the scarcity of high-resolution SAR images and the abundance of high-resolution labeled visible light images, a promising avenue is to combine the two to generate more synthetic SAR images to address the lack of labeled SAR data and ultimately improve real SAR object detection. Although the synthetic image obtained in this way cannot be used for model evaluation, it can help the detection model obtain stronger positioning ability when detecting real SAR objects through pre-training or mixed training. Figure 23 demonstrates an example of using CycleGAN [60] to transfer vehicle images from the DOTA domain to the Mix MSTAR domain;
- Out-of-distribution detection. Out-of-distribution detection, or OOD detection, aims to detect test samples that are drawn from a distribution that is different from the training distribution [61]. Using the model trained by synthetic images to classify real images was regarded as a challenging problem in SAMPLE [25]. Unlike visible-light imagery, SAR imaging is heavily influenced by sensor operating parameters, resulting in significant stylistic differences between images captured under different conditions. Our experiments found that current models’ performance on different SAR datasets is poorly generalizable. If reannotation and retraining are required for every new dataset, the cost will increase significantly, exacerbating the scarcity of SAR imagery and limiting the application scenarios of SAR-ATR. Therefore, it is an important research direction to use the limited labeled datasets to detect more unlabeled data. We used the Redet model trained on Mix MSTAR to detect real vehicles in an image from FARAD KA BAND. Due to resolution differences, three vehicles were detected after applying multi-scale test techniques, as shown in Figure 24.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–11493. [Google Scholar] [CrossRef] [PubMed]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A SAR dataset of ship detection for deep learning under complex backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef]
- Xian, S.; Zhirui, W.; Yuanrui, S.; Wenhui, D.; Yue, Z.; Kun, F. AIR-SARShip-1.0: High-resolution SAR ship detection dataset. J. Radars 2019, 8, 852–863. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Zhan, X.; Shi, J.; Wei, S.; Pan, D.; Li, J.; Su, H.; Zhou, Y. LS-SSDD-v1. 0: A deep learning dataset dedicated to small ship detection from large-scale Sentinel-1 SAR images. Remote Sens. 2020, 12, 2997. [Google Scholar] [CrossRef]
- Lei, S.; Lu, D.; Qiu, X.; Ding, C. SRSDD-v1. 0: A high-resolution SAR rotation ship detection dataset. Remote Sens. 2021, 13, 5104. [Google Scholar] [CrossRef]
- The Air Force Moving and Stationary Target Recognition Database. Available online: https://www.sdms.afrl.af.mil/datasets/mstar/ (accessed on 10 March 2011).
- Zhang, L.; Leng, X.; Feng, S.; Ma, X.; Ji, K.; Kuang, G.; Liu, L. Domain knowledge powered two-stream deep network for few-shot SAR vehicle recognition. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Zhang, L.; Leng, X.; Feng, S.; Ma, X.; Ji, K.; Kuang, G.; Liu, L. Azimuth-Aware Discriminative Representation Learning for Semi-Supervised Few-Shot SAR Vehicle Recognition. Remote Sens. 2023, 15, 331. [Google Scholar] [CrossRef]
- SANDIA FARAD SAR DATA COLLECTION—X BAND—4” RESOLUTION. Available online: https://www.sandia.gov/files/radar/complex-data/FARAD_X_BAND.zip (accessed on 30 April 2023).
- SANDIA FARAD SAR DATA COLLECTION—KA BAND—4” RESOLUTION. Available online: https://www.sandia.gov/files/radar/complex-data/FARAD_KA_BAND.zip (accessed on 30 April 2023).
- SANDIA Spotlight SAR. Available online: https://www.sandia.gov/files/radar/complex-data/20060214.zip (accessed on 30 April 2023).
- SANDIA Mini SAR Complex Imagery. Available online: https://www.sandia.gov/files/radar/complex-data/MiniSAR20050519p0009image003.zip (accessed on 30 April 2023).
- Casteel, C.H., Jr.; Gorham, L.A.; Minardi, M.J.; Scarborough, S.M.; Naidu, K.D.; Majumder, U.K. A challenge problem for 2D/3D imaging of targets from a volumetric data set in an urban environment. In Proceedings of the Algorithms for Synthetic Aperture Radar Imagery XIV, Orlando, FL, USA, 9–13 April 2007; pp. 97–103. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Gao, F.; Yang, Y.; Wang, J.; Sun, J.; Yang, E.; Zhou, H. A deep convolutional generative adversarial networks (DCGANs)-based semi-supervised method for object recognition in synthetic aperture radar (SAR) images. Remote Sens. 2018, 10, 846. [Google Scholar] [CrossRef]
- Cui, Z.; Zhang, M.; Cao, Z.; Cao, C. Image data augmentation for SAR sensor via generative adversarial nets. IEEE Access 2019, 7, 42255–42268. [Google Scholar] [CrossRef]
- Vignaud, L. GAN4SAR: Generative Adversarial Networks for Synthetic Aperture Radar imaging of targets signature. In Proceedings of the SET-273 Specialists Meeting on Multidimensional Radar Imaging and ATR-CfP, Marseille, France, 25–26 October 2021. [Google Scholar]
- Auer, S.; Bamler, R.; Reinartz, P. RaySAR-3D SAR simulator: Now open source. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 6730–6733. [Google Scholar]
- Malmgren-Hansen, D.; Kusk, A.; Dall, J.; Nielsen, A.A.; Engholm, R.; Skriver, H. Improving SAR automatic target recognition models with transfer learning from simulated data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1484–1488. [Google Scholar] [CrossRef]
- Cha, M.; Majumdar, A.; Kung, H.; Barber, J. Improving SAR automatic target recognition using simulated images under deep residual refinements. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2606–2610. [Google Scholar]
- Lewis, B.; Scarnati, T.; Sudkamp, E.; Nehrbass, J.; Rosencrantz, S.; Zelnio, E. A SAR dataset for ATR development: The Synthetic and Measured Paired Labeled Experiment (SAMPLE). In Proceedings of the Algorithms for Synthetic Aperture Radar Imagery XXVI, Baltimore, MD, USA, 14–18 April 2019; pp. 39–54. [Google Scholar]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.-Q. Target classification using the deep convolutional networks for SAR images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Han, Z.-S.; Wang, C.-P.; Fu, Q. Arbitrary-oriented target detection in large scene sar images. Def. Technol. 2020, 16, 933–946. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, W.; Zhang, Q.; Ni, H.; Zhang, X. Improved YOLOv5 with transformer for large scene military vehicle detection on SAR image. In Proceedings of the 2022 7th International Conference on Image, Vision and Computing (ICIVC), Xi’an, China, 26–28 July 2022; pp. 87–93. [Google Scholar]
- labelme: Image Polygonal Annotation with Python (Polygon, Rectangle, Circle, Line, Point and Image-Level Flag Annotation). Available online: https://github.com/wkentaro/labelme (accessed on 30 April 2023).
- Cong, W.; Zhang, J.; Niu, L.; Liu, L.; Ling, Z.; Li, W.; Zhang, L. Dovenet: Deep image harmonization via domain verification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8394–8403. [Google Scholar]
- Reinhard, E.; Adhikhmin, M.; Gooch, B.; Shirley, P. Color transfer between images. IEEE Comput. Graph. Appl. 2001, 21, 34–41. [Google Scholar] [CrossRef]
- Pérez, P.; Gangnet, M.; Blake, A. Poisson image editing. ACM Siggraph 2003, 2, 313–318. [Google Scholar] [CrossRef]
- Sunkavalli, K.; Johnson, M.K.; Matusik, W.; Pfister, H. Multi-scale image harmonization. ACM Trans. Graph. (TOG) 2010, 29, 1–10. [Google Scholar] [CrossRef]
- Tsai, Y.-H.; Shen, X.; Lin, Z.; Sunkavalli, K.; Lu, X.; Yang, M.-H. Deep image harmonization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3789–3797. [Google Scholar]
- Zhang, L.; Wen, T.; Shi, J. Deep image blending. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 231–240. [Google Scholar]
- Ling, J.; Xue, H.; Song, L.; Xie, R.; Gu, X. Region-aware adaptive instance normalization for image harmonization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9361–9370. [Google Scholar]
- Schumacher, R.; Rosenbach, K. ATR of battlefield targets by SAR classification results using the public MSTAR dataset compared with a dataset by QinetiQ UK. In Proceedings of the RTO SET Symposium on Target Identification and Recognition Using RF Systems, Oslo, Norway, 11–13 October 2004. [Google Scholar]
- Schumacher, R.; Schiller, J. Non-cooperative target identification of battlefield targets-classification results based on SAR images. In Proceedings of the IEEE International Radar Conference, Arlington, VA, USA, 9–12 May 2005; pp. 167–172. [Google Scholar]
- Geng, Z.; Xu, Y.; Wang, B.-N.; Yu, X.; Zhu, D.-Y.; Zhang, G. Target Recognition in SAR Images by Deep Learning with Training Data Augmentation. Sensors 2023, 23, 941. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference Part V 13, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.-S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI conference on artificial intelligence, Washington, DC, USA, 7–14 February 2023; pp. 3163–3171. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2019; pp. 2849–2858. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.-S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Ding, J.; Xue, N.; Xia, G.-S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2786–2795. [Google Scholar]
- Weiler, M.; Cesa, G. General e (2)-equivariant steerable cnns. arXiv 2019, arXiv:1911.08251. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF international conference on computer vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF international conference on computer vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9657–9666. [Google Scholar]
- Li, W.; Chen, Y.; Hu, K.; Zhu, J. Oriented reppoints for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1829–1838. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zhou, Y.; Yang, X.; Zhang, G.; Wang, J.; Liu, Y.; Hou, L.; Jiang, X.; Liu, X.; Yan, J.; Lyu, C. MMRotate: A Rotated Object Detection Benchmark using PyTorch. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 7331–7334. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE conference on computer vision and pattern recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, Las Vegas, NV, USA, 27–30 June 2016; pp. 618–626. [Google Scholar]
- Yang, X.; Zhao, J.; Wei, Z.; Wang, N.; Gao, X. SAR-to-optical image translation based on improved CGAN. Pattern Recognit. 2022, 121, 108208. [Google Scholar] [CrossRef]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Yang, J.; Zhou, K.; Li, Y.; Liu, Z. Generalized out-of-distribution detection: A survey. arXiv 2021, arXiv:2110.11334. [Google Scholar]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Resolution (m) | Image Size (pixel) | Images (n) | Vehicle Quantity | Noise Interference | |
|---|---|---|---|---|---|---|
| FARAD X BAND [13] | 0.1016 × 0.1016 | 1682 × 3334– 5736 × 4028 | 30 | Large | √ | |
| FARAD KA BAND [14] | 0.1016 × 0.1016 | 436 × 1288– 1624 × 4080 | 175 | Large | √ | |
| Spotlight SAR [15] | 0.1000 × 0.1000 | 3000 × 1754 | 64 | Small | × | |
| Mini SAR [16] | 0.1016 × 0.1016 | 2510 × 1638– 2510 × 3274 | 20 | Large | × | |
| MSTAR [10] | Clutters | 0.3047 × 0.3047 | 1472 × 1784– 1478 × 1784 | 100 | 0 | × |
| Chips | 0.3047 × 0.3047 | 128 × 128– 192 × 193 | 17658 | Large | × | |
| Collection Parameters | Chips | Clutters |
|---|---|---|
| Center Frequency | 9.60 GHz | 9.60 GHz |
| Bandwidth | 0.591 GHz | 0.591 GHz |
| Polarization | HH | HH |
| Depression | 15° | 15° |
| Resolution (m) | 0.3047 × 0.3047 | 0.3047 × 0.3047 |
| Pixel Spacing (m) | 0.202148 × 0.203125 | 0.202148 × 0.203125 |
| Platform | airborne | airborne |
| Radar Mode | spot light | strip map |
| Data type | float32 | uint16 |
| Grassland | Collection Date | Mean | Std | CV (Std/Mean) | CSIM |
|---|---|---|---|---|---|
| BMP2 SN9563 | 1 September 1995 – 2 September 1995 | 0.049305962 | 0.030280159 | 0.614127740 | 0.99826 |
| BMP2 SN9566 | 0.046989963 | 0.028360445 | 0.603542612 | 0.99966 | |
| BMP2 SN C21 | 0.046560729 | 0.02830699 | 0.607958479 | 0.99958 | |
| BTR70 SN C71 | 0.046856523 | 0.028143257 | 0.600626235 | 0.99970 | |
| T72 SN132 | 0.045960505 | 0.028047173 | 0.610245101 | 0.99935 | |
| T72 SN812 | 0.04546104 | 0.027559057 | 0.606212638 | 0.99911 | |
| T72 SNS7 | 0.041791245 | 0.025319219 | 0.605849838 | 0.99260 | |
| Clutters | 5 September 1995 | 63.2881255 | 37.850263 | 0.598062633 | 1 1 |
| Original Imaging Algorithm | Improved Imaging Algorithm |
|---|---|
| Input: Amplitude in MSTAR Data a > 0, Whether to enhance enhance = T or F | Input: Amplitude in MSTAR Data a > 0, Threshold thresh |
| Output: uint8 image img | Output: uint8 image img |
| 1: fmin←min(a), fmax←max(a) | 1: for pixel∈a do |
| 2: frange←fmax-fmin, fscale←255/frange | 2: if pixel>thresh then |
| 3: a←(a-fmin)/fscale | 3: pixel←thresh |
| 4: img←uint8(a) | 4: scale←255/thresh |
| 5: if enhance then | 5: img←uint8(a/scale) |
| 6: hist8←hist(img) | 6: Return img |
| 7: maxPixelCountBin←index[max(hist8)] | |
| 8: minPixelCountBin←index[min(hist8)] | |
| 9: if minPixelCountBin>maxPixelCountBin then | |
| 10: thresh←minPixelCountBin-maxPixelCountBin | |
| 11: scaleAdj←255/thresh | |
| 12: img←img * scaleAdj | |
| 13: else | |
| 14: img←img * 3 | |
| 15: img←uint8(img) | |
| 16: Return img |
| Class | Train | Test | Total |
|---|---|---|---|
| 2S1 | 192 | 82 | 274 |
| BMP2 | 195 | 392 | 587 |
| BRDM2 | 192 | 82 | 274 |
| BTR60 | 136 | 59 | 195 |
| BTR70 | 137 | 59 | 196 |
| D7 | 192 | 82 | 274 |
| T62 | 191 | 82 | 273 |
| T72 A04 | 192 | 82 | 274 |
| T72 A05 | 192 | 82 | 274 |
| T72 A07 | 192 | 82 | 274 |
| T72 A10 | 190 | 81 | 271 |
| T72 A32 | 192 | 82 | 274 |
| T72 A62 | 192 | 82 | 274 |
| T72 A63 | 192 | 82 | 274 |
| T72 A64 | 192 | 82 | 274 |
| T72 SN132 | 137 | 59 | 196 |
| T72 SN812 | 136 | 59 | 195 |
| T72 SNS7 | 134 | 57 | 191 |
| ZIL131 | 192 | 82 | 274 |
| ZSU234 | 192 | 82 | 274 |
| Total | 3560 | 1832 | 5392 |
| Category | Model | Params(M) | FLOPs (G) | FPS | mAP | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|
| One-stage | Rotated Retinanet | 36.74 | 218.18 | 29.2 | 61.03 ± 0.75 | 30.98 | 89.36 | 46.01 |
| Refine-stage | S2A-Net | 38.85 | 198.12 | 26.3 | 72.41 ± 0.10 | 31.57 | 95.74 | 47.48 |
| R3Det | 37.52 | 235.19 | 26.1 | 70.87 ± 0.31 | 22.28 | 97.11 1 | 36.24 | |
| Two-stage | ROI Transformer | 55.39 | 225.32 | 25.3 | 75.17 ± 0.24 | 46.90 | 93.27 | 62.42 |
| Oriented RCNN | 41.37 | 211.44 | 26.5 | 73.72 ± 0.45 | 38.24 | 93.56 | 54.29 | |
| ReDet | 31.7 | 54.48 | 18.4 | 70.27 ± 0.75 | 45.83 | 89.99 | 60.73 | |
| Gliding Vertex | 41.37 | 211.31 | 28.5 | 71.81 ± 0.19 | 44.17 | 91.78 | 59.64 | |
| Anchor-free | Rotated FCOS | 32.16 | 207.16 | 29.7 | 72.27 ± 1.27 | 27.52 | 96.47 | 42.82 |
| Oriented RepPoints | 36.83 | 194.35 | 26.8 | 75.37 ± 0.80 | 34.73 | 95.25 | 50.90 |
| Class | Rotated Retinanet | S2A-Net | R3Det | ROI Transformer | Oriented RCNN | ReDet | Gliding Vertex | Rotated FCOS | Oriented RepPoints | Mean |
|---|---|---|---|---|---|---|---|---|---|---|
| 2S1 | 87.95 | 98.02 | 95.16 | 99.48 | 97.52 | 95.48 | 95.38 | 97.22 | 98.16 | 96.0 |
| BMP2 | 88.15 | 90.69 | 90.62 | 90.82 | 90.73 | 90.67 | 90.65 | 90.66 | 90.80 | 90.4 |
| BRDM2 | 90.86 | 99.65 | 98.83 | 99.62 | 99.03 | 98.14 | 98.39 | 99.72 | 99.22 | 98.2 |
| BTR60 | 71.86 | 88.52 | 88.07 | 88.02 | 85.67 | 88.84 | 86.18 | 86.55 | 86.54 | 85.6 |
| BTR70 | 89.03 | 98.06 | 95.36 | 97.57 | 97.68 | 92.53 | 97.02 | 96.67 | 95.06 | 95.4 |
| D7 | 89.76 | 90.75 | 93.38 | 98.02 | 95.70 | 93.42 | 95.51 | 95.52 | 96.21 | 94.3 |
| T62 | 78.46 | 88.66 | 91.20 | 90.29 | 92.39 | 86.53 | 89.70 | 89.99 | 90.20 | 88.6 |
| T72 A04 | 37.43 | 56.71 | 50.23 | 55.97 | 55.42 | 50.44 | 50.01 | 50.46 | 53.40 | 51.1 |
| T72 A05 | 31.09 | 40.71 | 43.10 | 46.17 | 48.27 | 44.56 | 45.93 | 42.09 | 50.04 | 43.5 |
| T72 A07 | 29.50 | 40.28 | 40.13 | 37.13 | 38.22 | 33.40 | 38.49 | 33.61 | 44.37 | 37.2 |
| T72 A10 | 27.99 | 39.82 | 36.00 | 40.71 | 36.81 | 34.04 | 34.44 | 40.67 | 47.57 | 37.6 |
| T72 A32 | 69.24 | 79.96 | 83.05 | 82.57 | 80.77 | 77.48 | 77.02 | 74.56 | 78.65 | 78.1 |
| T72 A62 | 41.06 | 49.49 | 50.05 | 54.32 | 47.31 | 41.97 | 45.71 | 53.77 | 54.00 | 48.6 |
| T72 A63 | 38.10 | 51.07 | 46.45 | 53.63 | 50.06 | 43.79 | 49.27 | 49.44 | 53.05 | 48.3 |
| T72 A64 | 35.51 | 58.28 | 57.54 | 67.37 | 66.65 | 57.95 | 63.38 | 58.47 | 66.14 | 59.0 |
| T72 SN132 | 34.18 | 54.95 | 45.71 | 59.85 | 58.16 | 56.80 | 52.23 | 54.35 | 65.38 | 53.5 |
| T72 SN812 | 49.27 | 72.01 | 61.86 | 77.42 | 74.23 | 65.13 | 71.34 | 73.33 | 72.14 | 68.5 |
| T72 SNS7 | 43.61 | 59.37 | 56.77 | 66.43 | 65.70 | 57.43 | 64.56 | 64.43 | 67.62 | 60.7 |
| ZIL131 | 96.06 | 96.24 | 97.76 | 99.00 | 97.88 | 98.78 | 96.16 | 95.24 | 99.58 | 97.4 |
| ZSU234 | 91.55 | 95.03 | 96.17 | 99.09 | 96.15 | 98.04 | 94.90 | 98.65 | 99.26 | 96.5 |
| mAP | 61.03 | 72.41 | 70.87 | 75.17 | 73.72 | 70.27 | 71.81 | 72.27 | 75.37 | 71.4 |
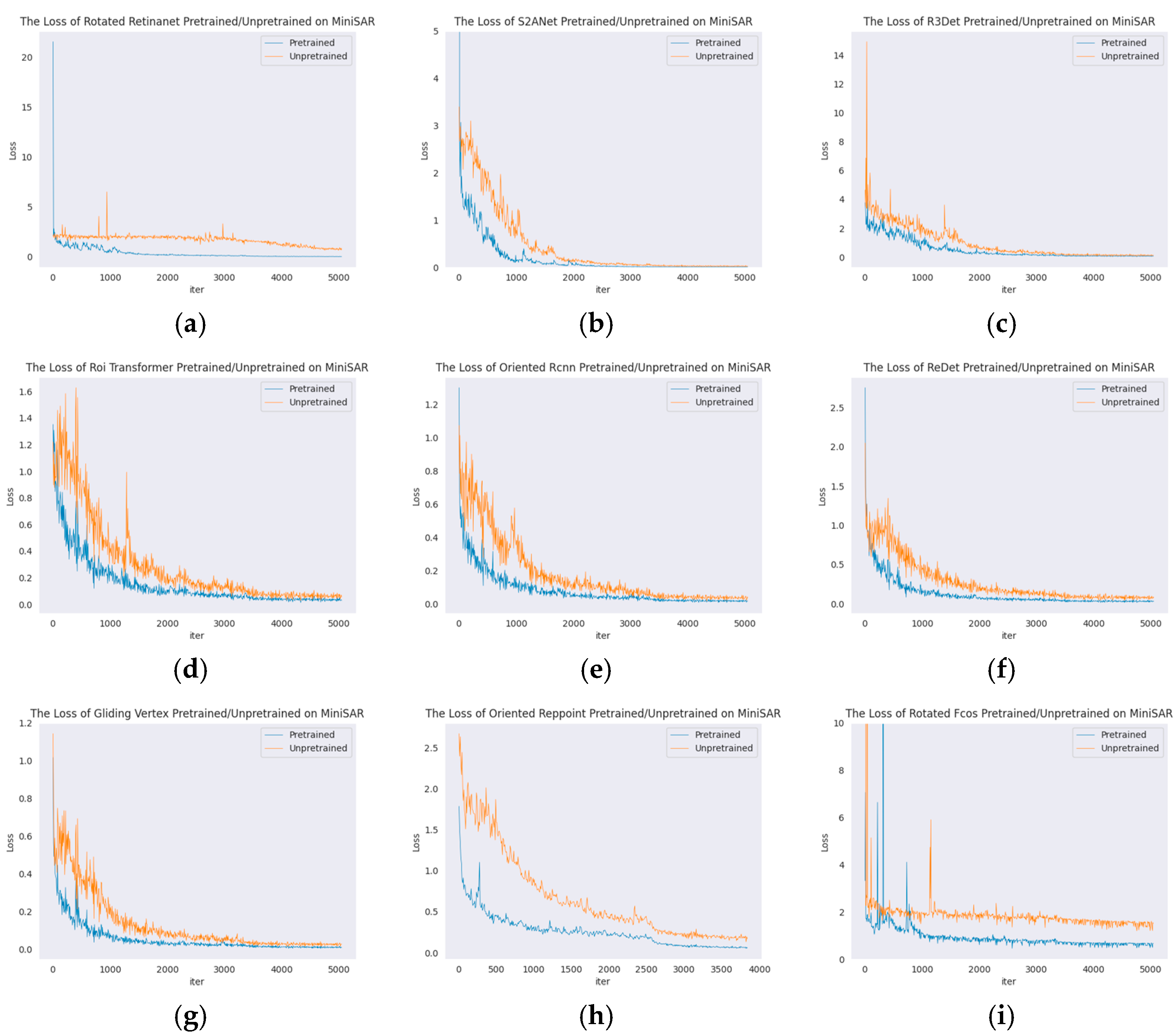
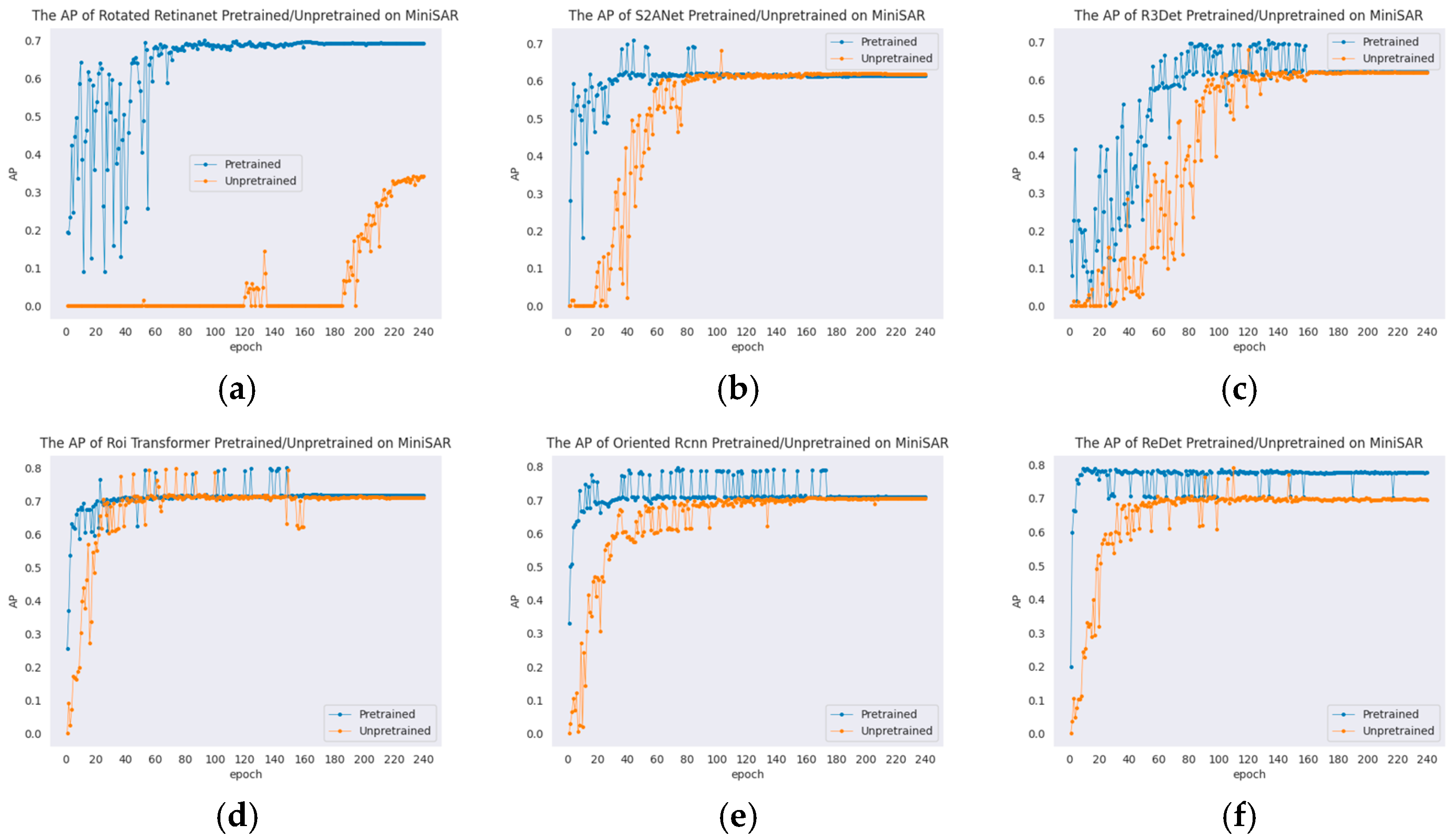
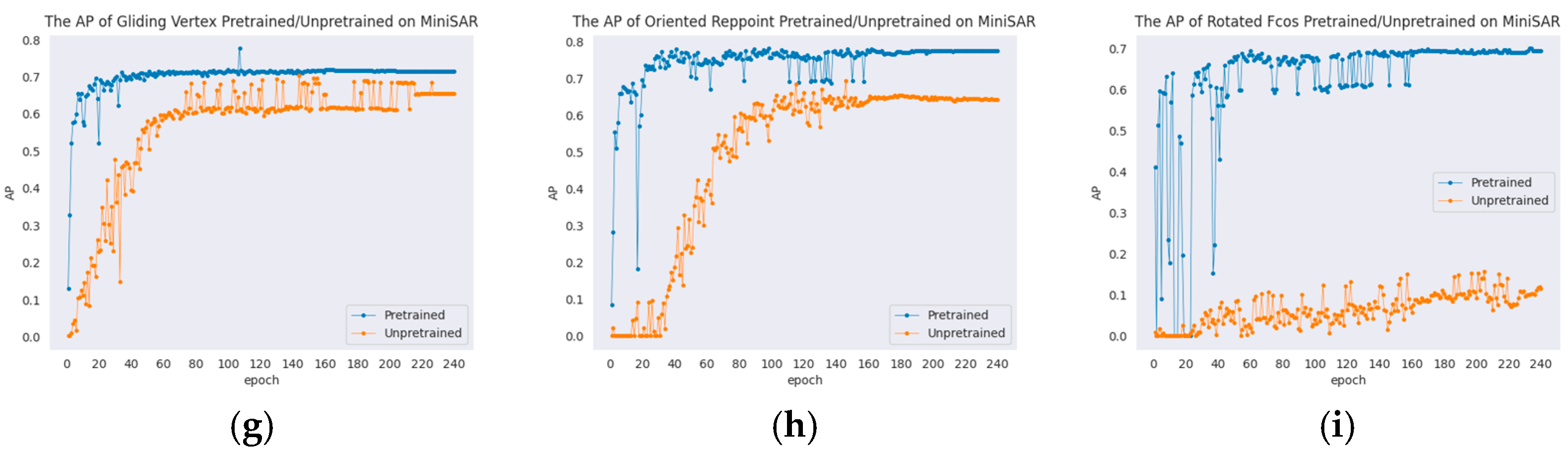
| Model | Unpretrained | Pretrained |
|---|---|---|
| Rotated Retinanet | 38.00 ± 15.52 | 71.40 ± 0.75 |
| S2A-Net | 65.63 ± 1.94 | 69.81 ± 0.89 |
| R3Det | 66.30 ± 2.66 | 70.35 ± 0.18 |
| ROI Transformer | 79.42 ± 0.61 | 80.12 ± 0.01 |
| Oriented RCNN | 70.49 ± 0.47 | 80.07 ± 0.24 |
| ReDet | 79.47 ± 0.58 | 79.64 ± 0.31 |
| Gliding Vertex | 70.71 ± 0.20 | 77.64 ± 0.49 |
| Rotated FCOS | 10.82 ± 3.94 | 74.93 ± 2.60 |
| Oriented RepPoints | 72.72 ± 2.04 | 79.02 ± 0.39 |
| Model | Trained on Mini SAR Only | Pretrained on Mix MSTAR | Add Mix MSTAR |
|---|---|---|---|
| Rotated Retinanet | 38.00 ± 15.52 | 71.40 ± 0.75 | 78.62 ± 0.42 |
| Rotated FCOS | 10.82 ± 3.94 | 74.93 ± 2.60 | 77.70 ± 0.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Luo, S.; Wang, Y. Mix MSTAR: A Synthetic Benchmark Dataset for Multi-Class Rotation Vehicle Detection in Large-Scale SAR Images. Remote Sens. 2023, 15, 4558. https://doi.org/10.3390/rs15184558
Liu Z, Luo S, Wang Y. Mix MSTAR: A Synthetic Benchmark Dataset for Multi-Class Rotation Vehicle Detection in Large-Scale SAR Images. Remote Sensing. 2023; 15(18):4558. https://doi.org/10.3390/rs15184558
Chicago/Turabian StyleLiu, Zhigang, Shengjie Luo, and Yiting Wang. 2023. "Mix MSTAR: A Synthetic Benchmark Dataset for Multi-Class Rotation Vehicle Detection in Large-Scale SAR Images" Remote Sensing 15, no. 18: 4558. https://doi.org/10.3390/rs15184558
APA StyleLiu, Z., Luo, S., & Wang, Y. (2023). Mix MSTAR: A Synthetic Benchmark Dataset for Multi-Class Rotation Vehicle Detection in Large-Scale SAR Images. Remote Sensing, 15(18), 4558. https://doi.org/10.3390/rs15184558