1. Introduction
A hyperspectral remote sensing image (HSI) can be regarded as a 3D cube, which reflects the material’s spatial, spectral, and radiation information and land cover. Based on such abundant spectral bands, HSI data presents great importance in many practical applications, such as agriculture [
1], environmental science [
2], urban remote sensing [
3], military defense [
4], and other fields [
5]. Various methods have been proposed for the HSI classification regarding the rich spectral information. Traditional representative algorithms such as sparse represent classification (SRC) [
6], collaborative represent classification (CRC) [
7], SVM with a nonlinear kernel projection method [
8], and other kernel-based methods [
9,
10] are proposed by utilizing the rich discriminant spectral information. Spectral–spatial (SS) algorithms were gradually proposed to improve classification performance for sufficiently involving and fusing spatial correlation information. By introducing spatial features into HSI classification, a spatial–spectral derivative-aided kernel joint sparse representation (KJSR-SSDK) [
11] and an adaptive nonlocal spatial–spectral kernel (ANSSK) [
12] are proposed for extracting SS combination features. The above-mentioned algorithms are mainly keen on handcrafted features (spectral information or dimension reduction information of spectral information) with classifiers for HSI classification.
Inspired by the success of DL techniques, DL-based methods present prospects in the computer vision area, which can discover distributed feature representations of data by combining low-level features to form more abstract high-level representation features [
13]. Spacial–spectral (SS)-based DL methods have presented promising performance for HSI classification. Additionally, 2D-CNN-based methods are proposed for extracting SS features, whereas dimension reduction of the HSI data is required first [
14,
15,
16]. Considering the input data is a 3D cube in HSI processing, multi-scale 3D-CNN is introduced by considering filters of different sizes [
17]. By combining ResNet with SS CNN, SSRN (SS residual network) is introduced to learn robust SS features from HSI [
15]. RCDN (Residual Conv–Deconv Network) is proposed by densely connecting the deep residual networks [
18]. Meanwhile, the deep feature fusion network (DFFN) was proposed to alleviate the overfitting and gradient disappearance problems of CNNs by taking into account the strong complementary correlation information between different layers of the neural network [
19]. A novel deep generative spectral–spatial classifier (DGSSC) is proposed for addressing the issues of imbalanced HSIC [
20]. Zhang et al. further proposed a deep 3D lightweight convolutional network consisting of dozens of 3D convolutional layers to improve classification performance [
21]. However, it is worth noting that CNN-based algorithms are liable to indicate local information loss due to pooling layers. To cope with the problem, a dual-channel capsule network with GAN (DcCapsGAN) is proposed, which can generate pseudo-samples more efficiently and improve the classification accuracy and performance [
22]. Additionally, a novel quaternion transformer network (QTN) for recovering self-adaptive and long-range correlations in HSIs is proposed in [
23]. The Lightweight SS Attention Feature Fusion Framework (LMAFN) [
24] is constructed based on architectural guidelines provided by NAS [
25], and the proposed LMAFN achieves commendable classification accuracy and performance with a reduced parameter quantity. Specifically, LMAFN is a manually-designed neural network that incorporates the architectural principles from NAS to guide its feature fusion and network architecture. Therefore the entire network of LMAFN is manually constructed by the guiding rules established by NAS, but does not utilize automated searches for its architecture.
Nonetheless, in the realm of hyperspectral image classification, deep learning confronts multifaceted challenges, encompassing model intricacy, burdensome architectural design, and the inherent scarcity of accessible labeled hyperspectral data. These factors collectively impede the training efficacy and generalization prowess of deep learning paradigms. As a practical solution, transfer learning helps improve model performance when there is not much data available. It does this by transferring useful knowledge from a source domain, where plenty of data exists, to the target domain, which is lacking in data. Deep convolutional recurrent neural networks with transfer learning [
26] present a sophisticated methodology for the extraction of spatial–spectral features, even in scenarios where the availability of training samples is limited. HT-CNN [
27] propose a heterogeneous transfer learning that adjusts the differences between heterogeneous datasets through an attention mechanism. TL-ELM [
28] introduces an ensemble migration learning algorithm built upon Extreme Learning Machines. This innovative approach not only preserves the input weights and hidden biases acquired from the target domain, but also iteratively fine-tunes the output weights using instances from the source domain.
Recently, the limitation of storage resources, power consumption, computational complexity, and parameter size hindered the application and implementation of DL-based algorithms for relevant applications, especially for edge devices and embedded platforms. Therefore, how to further realize lightweight and automated architecture design with limited storage and power constraints became a crucial issue [
29,
30]. Mobilenet V3 [
31] efficiently combined the depthwise (DW) separable convolution, the inverted residual, and SE attention modules. Furthermore, EfficientNet V2 [
32] and Squeezenet [
33] all simultaneously involved attention modules and lightweight structures for efficiently improving classification performance. Nevertheless, the above-mentioned algorithms are mainly manually designed for specific tasks. In a real application, it is inherently a difficult and time-consuming task that relies heavily on expert knowledge. As research becomes more complex, the cost of debugging the model parameters of deep networks increases dramatically.
The Neural Architecture Search (NAS) approach effectively solves the problem of efficient and lightweight architectures for edge devices that are difficult to design. In general, there are mainly three mainstreams in NAS literature: reinforcement-learning-based (RL-based) NAS approaches, evolutionary-learning-based (EL-based) NAS approaches, and gradient-based (GD-based) NAS approaches. In RL-based NAS literature, the strategy is mainly iteratively generating new architectures based on learning a maximized reward from an objective (i.e., the accuracy on the validation set or model latency) [
34,
35,
36]. In EL-based literature, architectures are represented as individuals in a population. Individuals with high fitness scores (verification accuracy) are privileged to generate offspring, thereby replacing individuals with low fitness scores. Large-Scale Evolution is proposed in [
37], which applies evolutionary algorithms to discovery architectures for the first time. A new hierarchical genetic representation scheme and an expression search space supporting complex topologies are combined in Hier-Evolution [
38], which outperforms various manually designed architectures for image classification tasks. However, most RL-based and EL-based NAS usually require high computational demand for the revolution in neural architecture design. For instance, NASNet [
39] based on RL strategy demands 450GPUs for 4 days resulting in 1800 GPU-hours and MnasNet [
40] used 64TPUs for 4.5 days in CIFAR-10. Similarly, Hier-Evolution [
38] based on EL strategy needs to spend 300 GPU days to acquire a satisfying architecture in CIFAR-10. RL-based and EL-based NAS methods indicate that the neural architecture search in a discrete search strategy is usually regarded as a black-box optimization problem with an excessive process of structural performance evaluation.
In contrast to RL-based and EL-based NAS, the GD-based NAS approach continuously relaxes the original discrete search space, making it possible to optimize the architectural search space efficiently in a gradient descent manner. Following the cell-based search space of NASNet and exploring the possibility of transforming the discrete neural architecture space into a continuously differentiable form, DARTS [
41] is developed by introducing an architecture parameter for each path and jointly training weights and architecture parameters via a gradient descent algorithm, which makes more efficient way for architecture search problem.
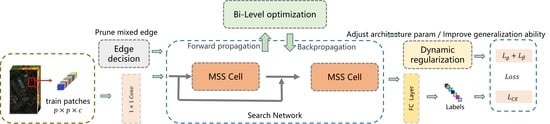
Therefore, inspired by the abovementioned problem and the literature, we construct an efficient attention architecture search (EL-NAS) for HSI classification in this paper. First, because of the efficiency of the GD-based architecture search, we mainly adopt the manner of differentiable neural architecture search as the main automatic DL design strategy to realize the efficient search procedure. Considering the real application for a mobile and embedded device, the lightweight and the attention module and 3D decomposition convolution are simultaneously exploited to construct the searching space, which can efficiently improve the classification accuracy with lower computation and storage costs. Meanwhile, aiming to mitigate the performance collapse caused by the number of skip operations in the searching procedure, the edge decision strategy, and the dynamic regularization is designed by the entropy and distribution of the non-skip operations to preserve the most efficient searching structure. Furthermore, generalization loss is introduced to improve the generalization of the searched model.
We then summarize the main contribution and the innovation of the proposed EL-NAS as follows:
EL-NAS successfully introduces the lightweight and attention module and 3D decomposition convolution for automatically realizing the efficient design of DL structure in the hyperspectral image classification area. Therefore, the efficient automatic searching strategy enables us to establish a task-driven automatic design of DL structure for different datasets from different acquisition sensors or scenarios.
EL-NAS presents remarkable searching efficiency through edge decision strategy to realize lightweight attention DL structure by imposing (i) the knowledge of successful lightweight 3D decomposition convolution and attention module in the searching space. (ii) The entropy of operation distribution estimated over non-skip operation is implemented to make the edge decision. (iii) Dynamic regularization loss based on the impact of the number of skip connections is adopted for further improving the searching performance. Therefore, the most effective and lightweight operations will be preserved by utilizing the edge decision strategy.
Compared with several state-of-the-art methods via comprehensive experiments in accuracy, classification maps, the number of parameters, and the execution cost, EL-NAS presents fewer GPU searching costs and lower parameters and computation costs. The experimental results on three real HSI datasets demonstrate that EL-NAS can search out a more lightweight network structure and realize more robust classification results even under data-independent and sensor-independent scenarios.
The rest of this article is organized as follows.
Section 2 reviews the related works in HSI classification. The details of the proposed EL-NAS are described in
Section 3. Experiments performance and analysis are designed and discussed in
Section 4. Finally, the conclusions are summarized in
Section 5 in this article.
4. Experiments
In this section, we mainly introduce five HSI data sets and the evaluation metrics utilized in this paper. The experiments performance, ablation studies, the parameters of the model and the running time are discussed and analyzed. In order to verify the effectiveness of EL-NAS in different scenarios, we also evaluate our method under independent scenarios with the same sensors (IN and SA) and also independent scenarios under different sensor circumstances (IN, UP, HU, SA, and IMDB).
4.1. Hyperspectral Data Sets
Indian Pines (IN) was collected by AVIRIS sensors in northwest India in 1992. This scene has 220 data channels, the spectral range is 0.2 to 2.4
m, and the size of each spectral dimension is 145 × 145. The image has a spatial resolution of 20 m/pixel and contains 16 feature categories, in which two-thirds are agriculture and one-third is forests or other natural perennial plants.
Figure 6 shows the three-band false color composite of IN images and the corresponding ground truth data, respectively.
The ROSIS-03 sensor recorded the Pavia University (UP) image of the University of Pavia over Pavia in northern Italy. The image captures the urban area around the University of Pavia. The image size is 610 × 340 × 115, the spatial resolution is 1.3 m/pixel, and the spectral coverage is 0.43 to 0.86
m. The image contains nine categories. Before the experiment, 12 frequency bands and some samples containing no information were removed.
Figure 7 shows the three-band false-color composite of the UP image and the corresponding ground truth data.
The Houston (HU) data set was collected by the Compact Aerial Spectral Imager (CASI) in 2013 on the University of Houston campus and adjacent urban areas. HU has 144 spectral channels, the wavelength range is 0.38 to 1.05
m, and the space size of 1905 × 349 is 2.5 m/pixel. It has 15 different ground truth classes with 15,029 marked pixels.
Figure 8 shows the three-band false-color composite of the HU image and the corresponding ground truth data.
Salinas (SA) is captured by the 224-band AVIRIS sensor over the Salinas Valley in California and features high spatial resolution (3.7m pixels). The coverage area includes 512 rows by 217 samples. Like Indian Pines, 20 water absorption bands were discarded, leaving 224 bands remaining. The image contains 16 categories.
Figure 9 shows the three-band false-color composite of the SA image and the corresponding ground truth data.
The Chikusei (IMDB) data set was collected by Hyperspectral Visible Near-Infrared Cameras (Hyperspec-VNIR-C) in Chikusei, Ibaraki, Japan, on 19 July 2014. It contains 19 classes and has 2517 × 2335 pixels. Its spatial resolution is 2.5 m per pixel. It consists of 128 spectral bands, which range from 363 to 1018 nm. The IMDB dataset was utilized in the sensor-independent scenario to verify the effects of the proposed EL-NAS.
Figure 10 shows the three-band false-color composite of the IMDB image and the corresponding ground truth data.
4.2. Experimental Configuration
We take a pixel-centered patch of size
as input data. The classification results are all summarized with the standard deviation of the estimated means by five independent random runs in experiments to avoid possible bias caused by the random sampling. The number of samples in each category in the training set and test set is also shown in
Table 1.
All the experiments in this paper are executed under the computer configuration as follows: An Intel Xeon W-2123 CPU at 3.60 GHz with 32-GB RAM and an NVIDIA GeForce GTX 2080 Ti graphical processing unit (GPU) with 27.8-GB RAM. The software environment is the system of 64-bit Windows 10 and DL frameworks of Pytorch 1.6.0.
4.3. Search Space Configuration
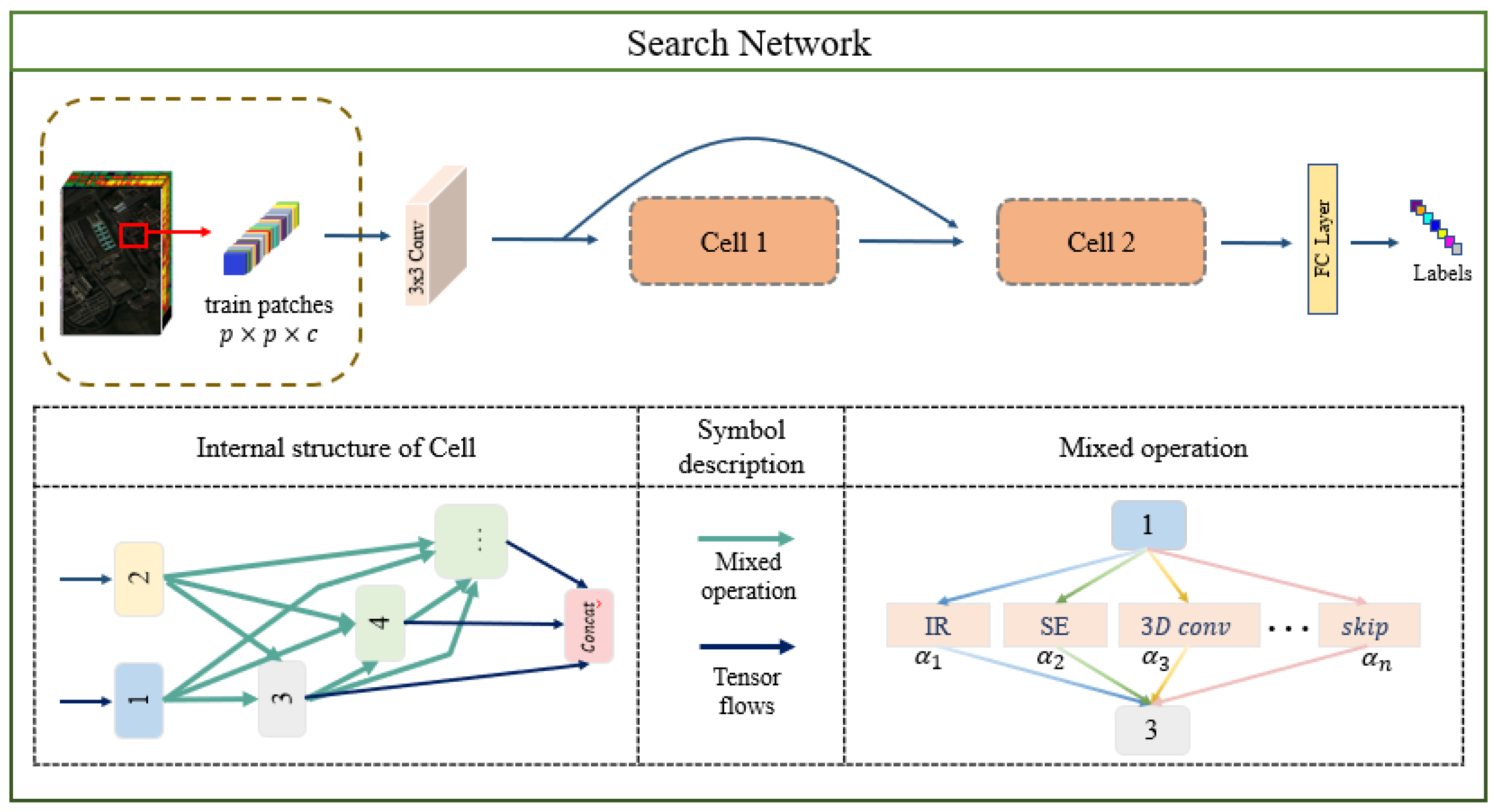
Five types of candidate operations are selected to construct the modular search space (MSS):
Lightweight modules ( and inverted residual modules, IR).
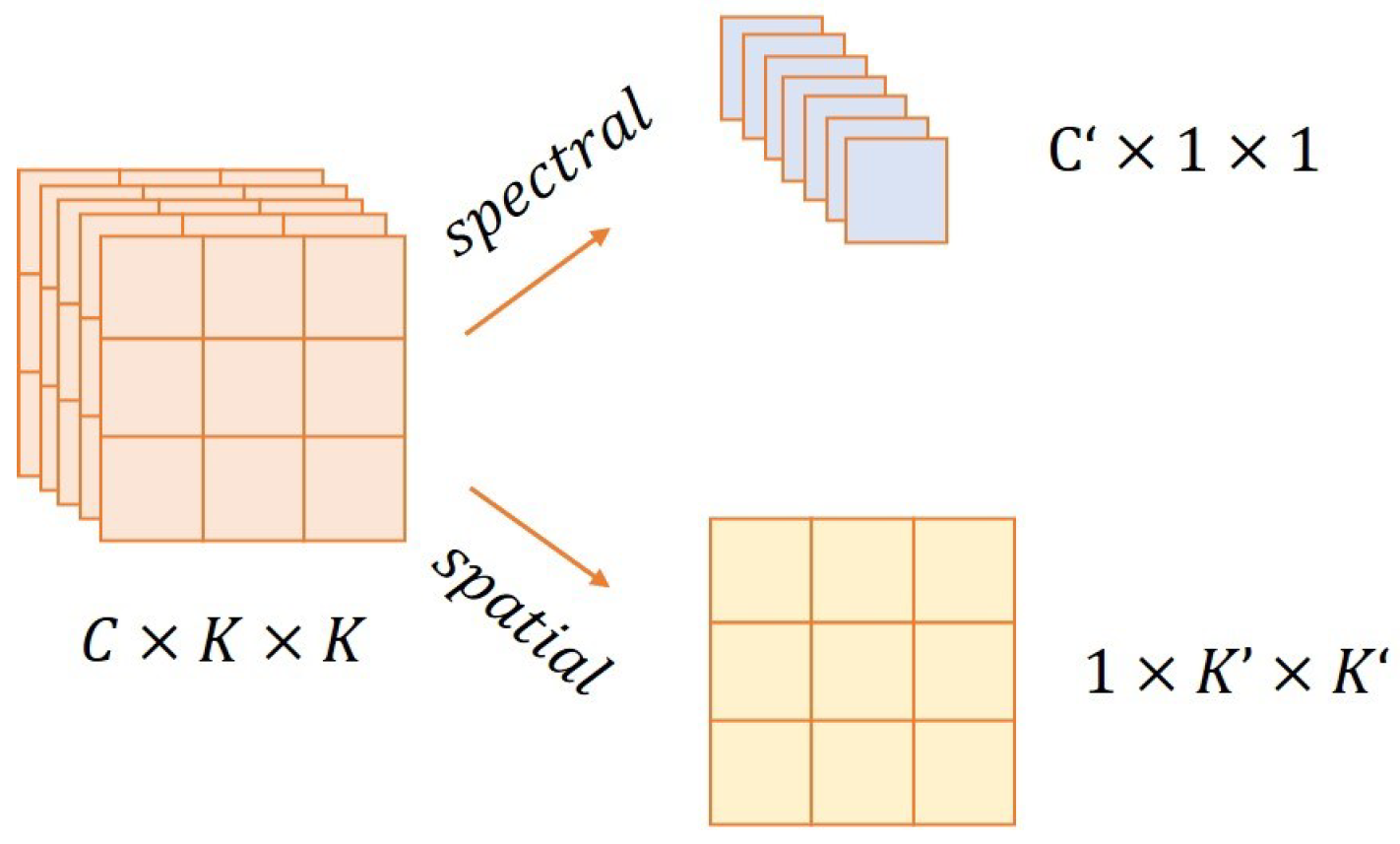
Three-dimensional decomposition convolution (3D convolution with kernel size of (SPA)and (SPE)).
Attention modules (SE).
Skip connection ().
None ().
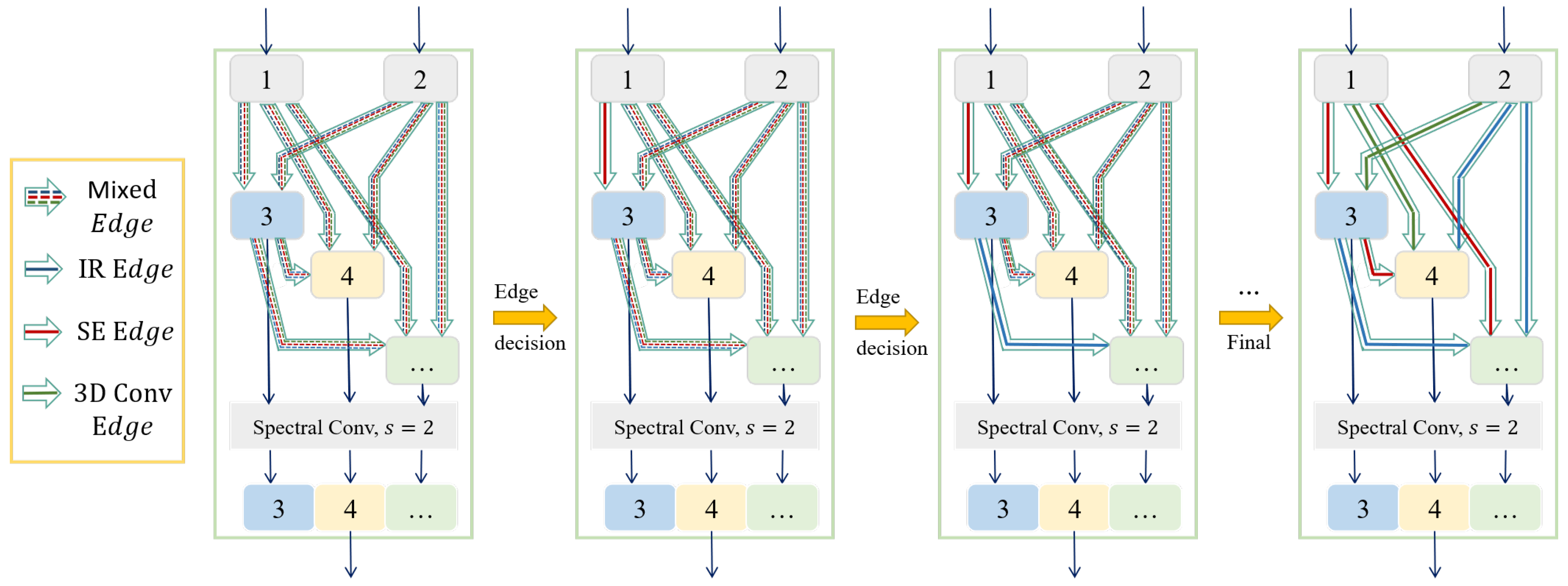
During the searching phase, a network is constructed using two normal cells. Within each normal cell, the stride for each convolution is set to 1. Throughout the search process, each cell comprises eight nodes, which include five intermediate nodes and a total of 20 edges.
4.4. Hyperparameter Settings
In the searching phase, we divide the training set into training and validation samples at a ratio of 0.5. Stochastic gradient descent (SGD) is used to optimize the model weight W, the initial learning rate is 0.005, the momentum is 0.9, and the weight decay is . For the architecture parameter A, an Adam optimizer with an initial learning rate of , momentum , and weight decay of is used. Edge decisions are made according to the selection criterion, and a complete supernet is not trained during the entire searching phase. After 50 epochs of warm-up, the edge decision is executed every five epochs. In addition, the batch size is increased by 16 after each edge decision, which can further improve the search efficiency.
In the training phase, we perform model training in 1000 epochs with a batch size of 128 and use a random gradient with an initial learning rate of 0.005, a momentum of 0.9, and a weight decay of . The gradient descent optimizer optimizes the model weight W. Other essential hyperparameters include gradient clipping set to 1 and dropout probability set to 0.3.
4.5. Ablation Study
4.5.1. Different Candidate Operations
In this section, we will analyze the effects of different candidate operations and verify the effectiveness of the modular search space, which is shown in
Table 2. Based on the comparison between IR and BASE, the results of using the lightweight module are better than the basic convolution. The channel attention SE is ideally suited to datasets with a massive spectrum and significantly boosts performance. The performance of SPE and SPA further improves the performance because of the enhanced ability to extract 3D features of hyperspectral images. We can observe that MSS candidate operations achieved the optimal performance.
4.5.2. Strategy Optimisation Scheme
Three distinct architectural designs were explored within each optimization strategy to assess their impact on the search process. The evaluation results for these architectures are presented in
Table 3. The regularization term
serves to constrain exceedingly large
, thereby allowing for the inclusion of architectural parameters that better represent high-quality architectures. The term
enhances model performance by approximately
, corroborating the notion that a more generalized search model is likely to yield an optimally performing architecture.
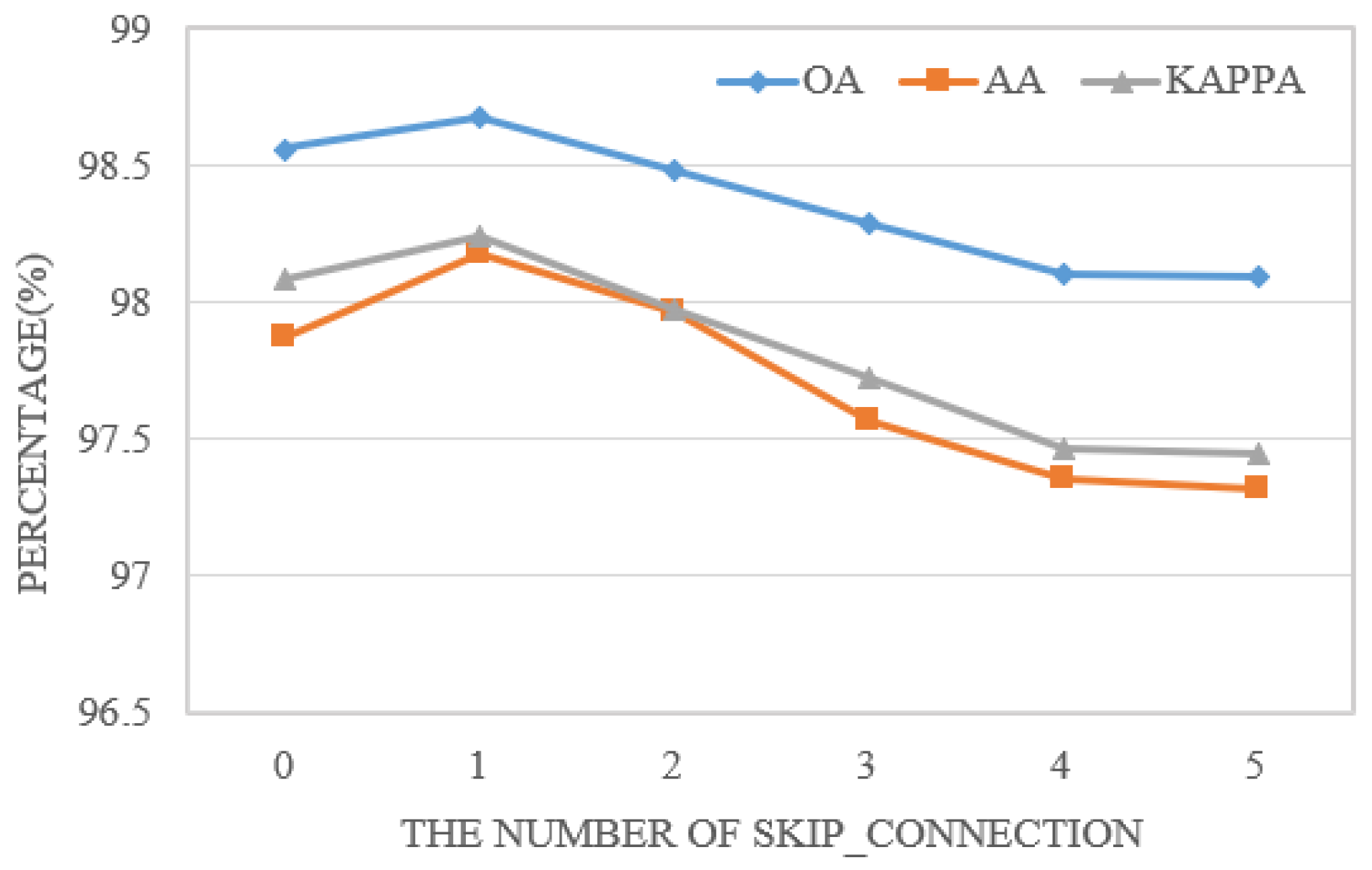
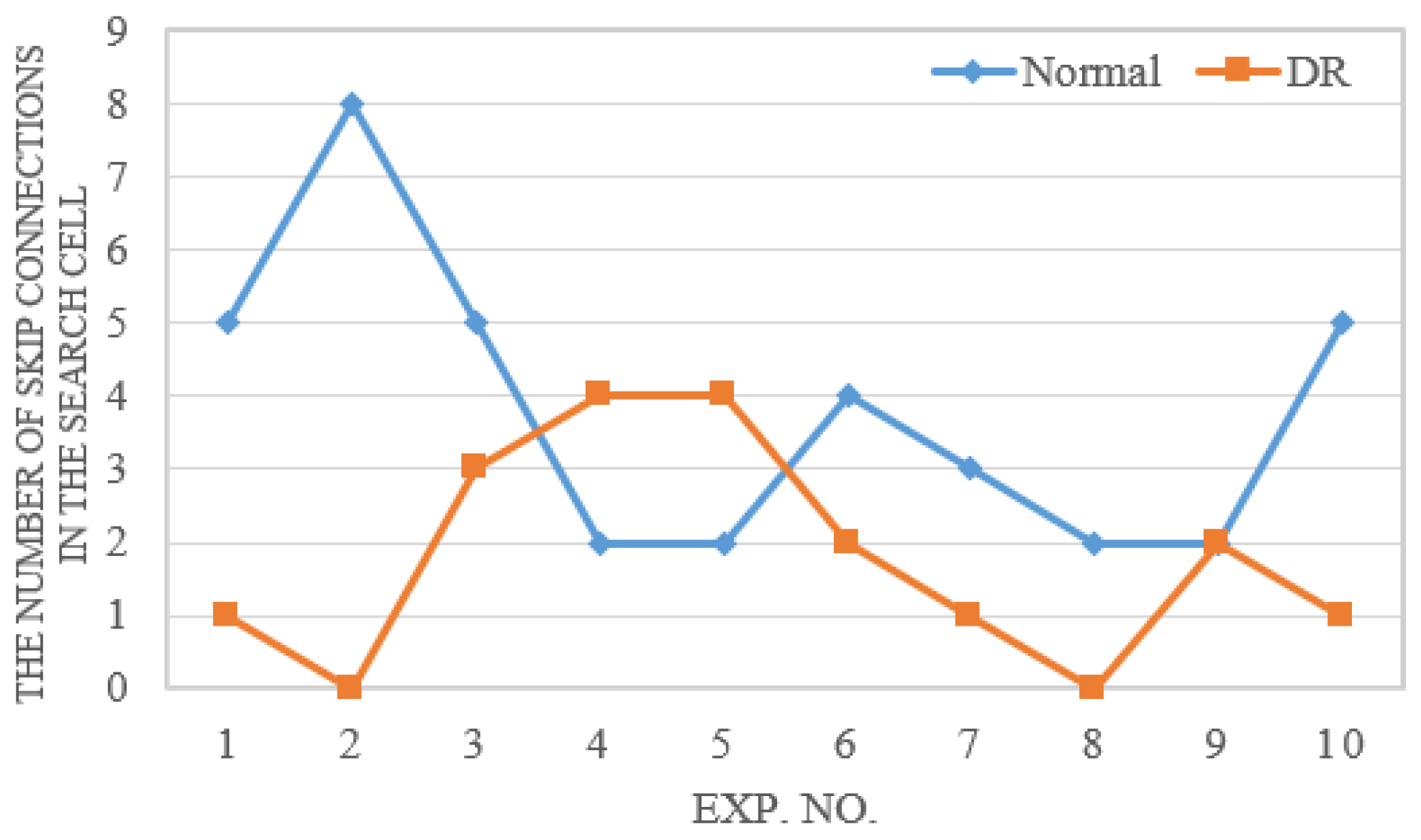
Figure 11 compares the number of skip connections in models with and without Dynamic Regularization (DR) across ten different searches. DR enables the automatic, dynamic adjustment of weights based on the current number of skip connections during each iteration, thereby reducing the frequency of skip operations and leading to more stable search outcomes.
4.6. Architecture Evaluation
In the first set of experiments, we mainly verify the proposed EL-NAS performance under the same scenario (Searching and Test under the same dataset). We randomly select
of whole labeled samples as the training set,
of the whole labeled samples as the validation sets, and the remaining
is used as the test set for the three HSI data sets of IN, UP and HU. We first search for the architecture on the training set and reserve an optimal architecture for evaluation. The optimal cell structures obtained from the three data sets are shown in
Figure 12. We compare the proposed EL-NAS model with traditional methods SVMCK, six DL methods (2D-CNN, 3D-CNN, DFFN, SSRN, DcCapsGAN, and LMAFN), and one NAS method for HSI classification (Auto-CNN, i.e., 3D-Auto-CNN).
According to the quantitative comparison results shown in
Table 4,
Table 5 and
Table 6, compared with the traditional method SVMCK, DL-based algorithms can achieve better classification results on the three data sets. CNN-based methods can be divided into 2D-CNN and 3D-CNN. Overall, 2D-CNN can extract more discriminative SS features through convolution operation and the nonlinear activation function. Compared with 2D-CNN, 3D-CNN achieves better classification accuracy by fully learning spectral features. Both DFFN and SSRN fuse SS features, and SSRN indicates better results than DFFN. DcCapsGAN integrates GAN and capsule networks to preserve features’ relative location further to improve classification performance. LMAFN adopts lightweight structures, which greatly increases the network depth while reducing the size of the model as well as enhances the nonlinear fitting ability of the model. Additionally, the above traditional algorithms and manually designed DL-based methods are subject to the constraints of subjective human cognition. Auto-CNN achieves satisfactory results in an automated way for neural architecture generation.
Upon a meticulous evaluation of the empirical results, it is evident that the proposed EL-NAS consistently outperforms all comparison algorithms, including Auto-CNN, across the board on all three examined datasets. Specifically focusing on the University of Pavia (UP) dataset, EL-NAS exhibits an exemplary classification accuracy of . This result eclipses the performance metrics of other established algorithms as follows: it is more accurate than the Spectral–Spatial Residual Network (SSRN) which scores , higher than DcCapsGAN with , greater than Lightweight Multiscale Attention Fusion Network (LMAFN) at , and notably superior to Auto-CNN, which has an accuracy of . The superior performance of EL-NAS is due to its innovative integration of a lightweight structure, an attention module, and 3D decomposition convolutions. These elements work synergistically to enhance computational efficiency and focus on key features, contributing to its high classification accuracy. Moreover, EL-NAS leverages automated architecture search, avoiding manual design biases and delivering an optimized, resource-efficient model. This results in better performance metrics across all evaluated datasets, highlighting the algorithm’s efficacy and robustness.
In addition,
Table 7 compares the parameter, and network depths of 2D-CNN, 3D-CNN, DFFN, SSRN, DcCapsGAN, LMAFN, and EL-NAS on the three datasets. From
Table 7, based on the UP dataset, we can notice that EL-NAS has only 175657 parameters, which is
less than 443929 parameters of DFFN,
less than 229261 parameters of SSRN, and
less than 21468326 parameters of DcCapsGAN. While reducing the model’s size, EL-NAS decreases the network depth to 13 layers and presents the most satisfying accuracies for three different datasets.
Table 8 presents the running time of DcCapsGAN, 2D CNN, 3D CNN, DFFN, SSRN, LMAFN, Auto-CNN, and EL-NAS, including searching time, training time, and test time. For the three data sets, our model runs 68.22 s, 62.66 s, and 71.39 s for searching, 87.81 s, 117.81 s, and 147.43 s for training, and 0.88 s, 3.42 s, and 1.28 s for testing, respectively. Note that we use more efficient and complex modules compared to Auto-CNN, so the searched network takes slightly longer to train and test. The execution time of EL-NAS surpasses that of all comparable handcrafted deep-learning algorithms, and its search time also outperforms that of Auto-CNN. This exceptional performance strongly attests to EL-NAS’s high efficiency in both memory utilization and computational overhead. This efficiency is largely attributed to the incorporation of lightweight modules and the expedited search process facilitated by intelligent edge decision-making.
Figure 13,
Figure 14 and
Figure 15 illustrate the full classification maps obtained from different algorithms on three HSI data sets. Pixel-based approaches SVMCK present more random noise and depict more errors, while SS-based approaches such as 2D-CNN, 3D-CNN, DFFN, SSRN, DcCapsGAN, and LMAFN demonstrate smoother results than pixel-based approaches. In addition, compared with other comparisons, LMAFN exhibits a smoother classification result and higher accuracy because of simultaneously considers spatial and continuous spectral features. Noteworthy, Auto-CNN can obtain precise classification results, which demonstrates the effectiveness of the auto-designed neural network for HSI classification. Nonetheless, when juxtaposed with the aforementioned algorithms, the proposed EL-NAS not only achieves superior accuracy and classification performance, but also does so with a reduced parameter count. This is accomplished through the synergistic integration of lightweight modules and an efficient architecture search algorithm, all underpinned by a highly effective automated architecture search process.
4.7. Cross Domain Experiment
In the second phase of our experiments, we aim to validate the cross-dataset and cross-sensor capabilities of our proposed EL-NAS framework. Specifically, we conduct tests under two distinct scenarios: a dataset-independent scenario, where the neural network architecture is optimized within the same sensor type but across different datasets, and a sensor-independent scenario, where the architecture is optimized across varying sensor types. To facilitate domain adaptation within the classification network, we have engineered dataset-specific classification layers in the latter stages of the network. Additionally, the convolutional layers preceding the shared cells are designed to adapt to diverse datasets.
4.7.1. Cross-Datasets Architecture Search of EL-NAS
In this section, we utilize the IN and SA datasets collected by the AVIRIS sensor for our experiments. EL-NAS is conducted on the IN dataset, and the optimal cell structure identified is then employed to construct the SA classification network. According to
Table 9, using the IN dataset for searching yields classification accuracies of 94.70% and 95.99% on the SA dataset with 10 and 20 labeled samples per class, respectively. Conversely, using the SA dataset for searching results in accuracies of 88.60% and 90.39% on the IN dataset with 10 and 20 labeled samples per class, respectively.
The experimental results further substantiate the efficacy of the proposed EL-NAS method in key evaluation metrics. Notably, the use of a substantial auxiliary dataset (labeled as 10% IN or SA) for architecture searching not only matches but often surpasses the performance achieved using the target datasets. These findings offer an efficient methodology for automatic neural network architecture design across different application scenarios under the same acquisition sensor.
4.7.2. Cross-Sensors Architecture Search of EL-NAS
In this part, we adopt five datasets collected by four kinds of HSI acquisition sensors (i.e., IN and SA from AVIRIS, UP from ROSIS, HU from CASI, IMDB from Hyperspec-VNIR-C). We conduct architecture searching on one of the above datasets, and the classification network derived by the searched architecture is applied to other datasets. The experimental results of the search on HU are shown in
Table 10. Our findings indicate that when target data volume is limited, the proposed EL-NAS method, utilizing a large auxiliary dataset (labeled as 10% HU), can achieve comparable or superior performance on key evaluation metrics, compared to using target datasets. These results offer an effective optimization strategy for cross-domain learning applications facing data scarcity, demonstrating that EL-NAS can automatically yield a neural network architecture design with satisfactory results even under different datasets collected by different acquisition sensors.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}