






MCAFNet: A Multiscale Channel Attention Fusion Network for Semantic Segmentation of Remote Sensing Images

 ,
,
Abstract
:1. Introduction
- (1)
- We combine the ResNet-50 and a transformer hybrid model to improve the current mainstream semantic segmentation network structure, and the proposed global–local transformer block models the spatial distance correlation in the image while maintaining the hierarchical characteristics.
- (2)
- We propose a channel attention module decoder (CAMD). In the module, a pooling fusion module is designed to enrich the feature expression of the network. We evaluated the efficiency of each part of the decoder module through ablation research.
- (3)
- We added a fusion module to optimize the structure of the hybrid model, merge feature maps from different scales, and improve semantic representation of the underlying features.
2. Related Work
2.1. Methods for Semantic Segmentation Based on Deep Learning
2.2. Methods for Semantic Segmentation Based on Transformers
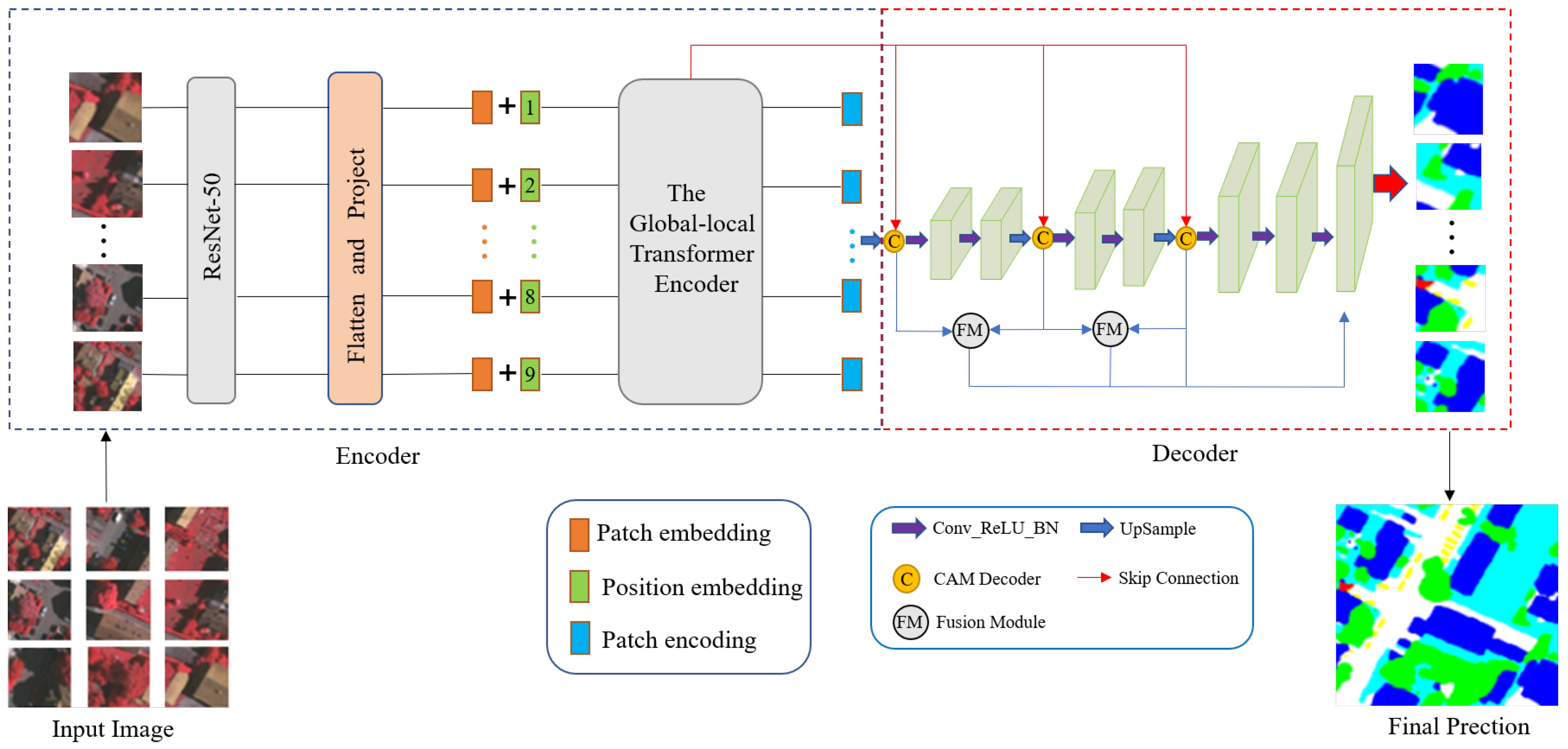
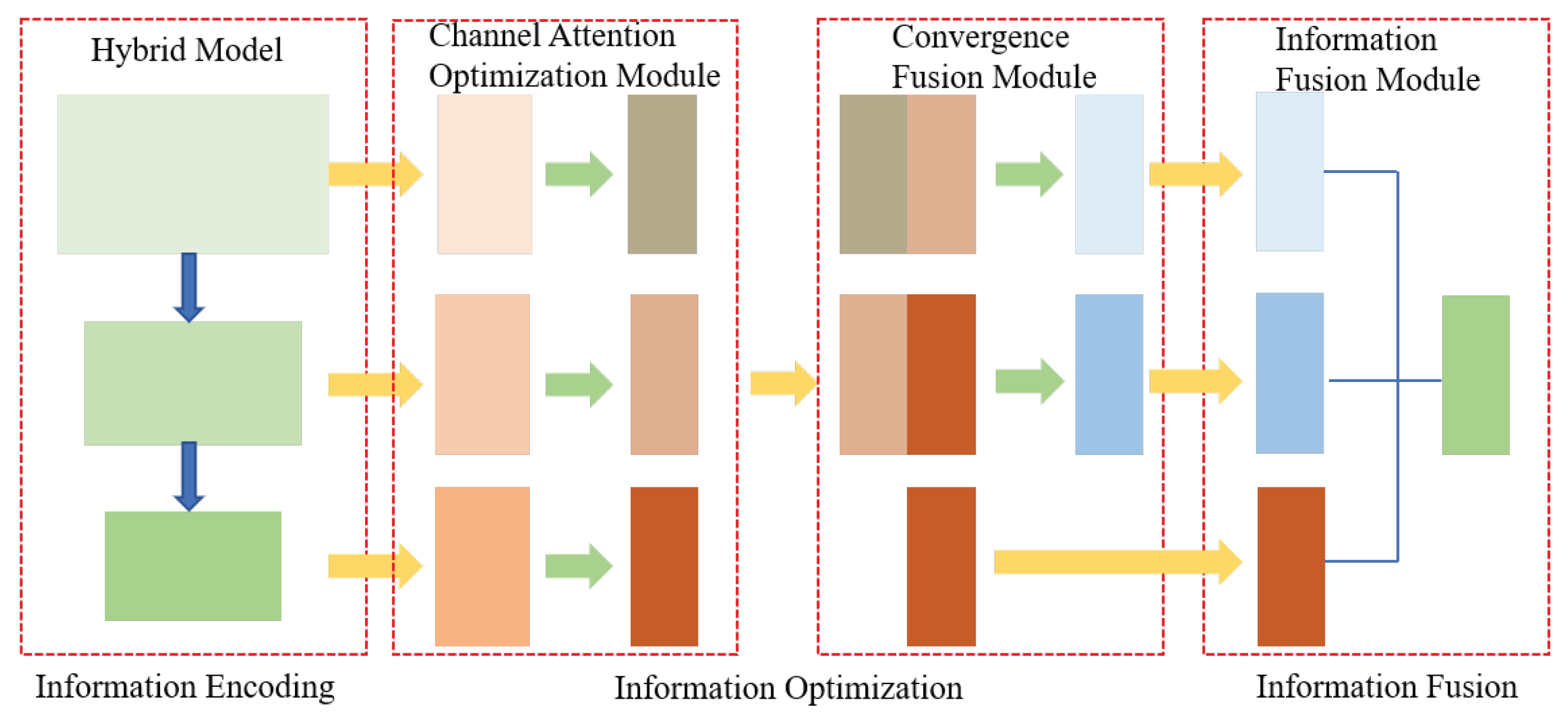
3. The Proposed Method
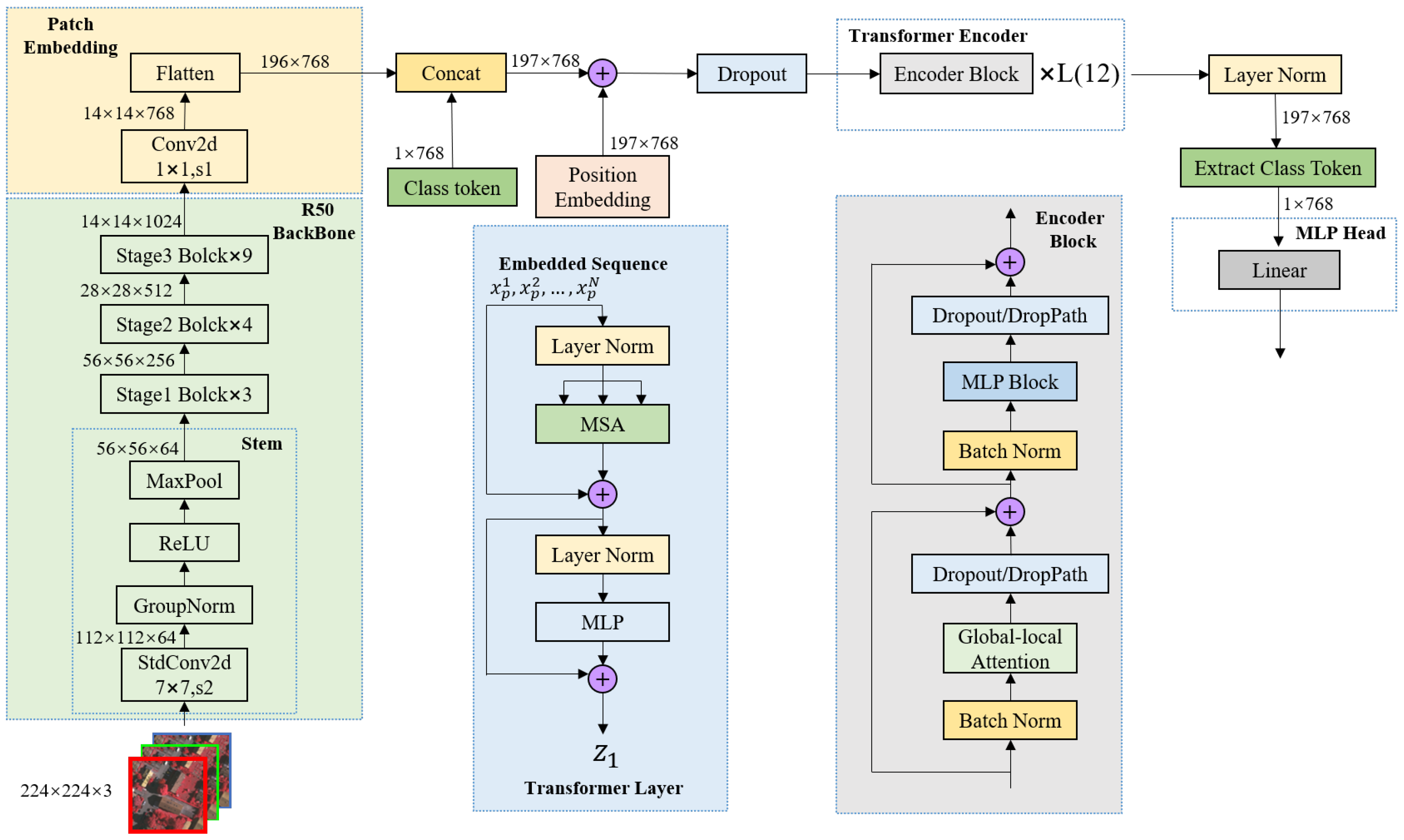
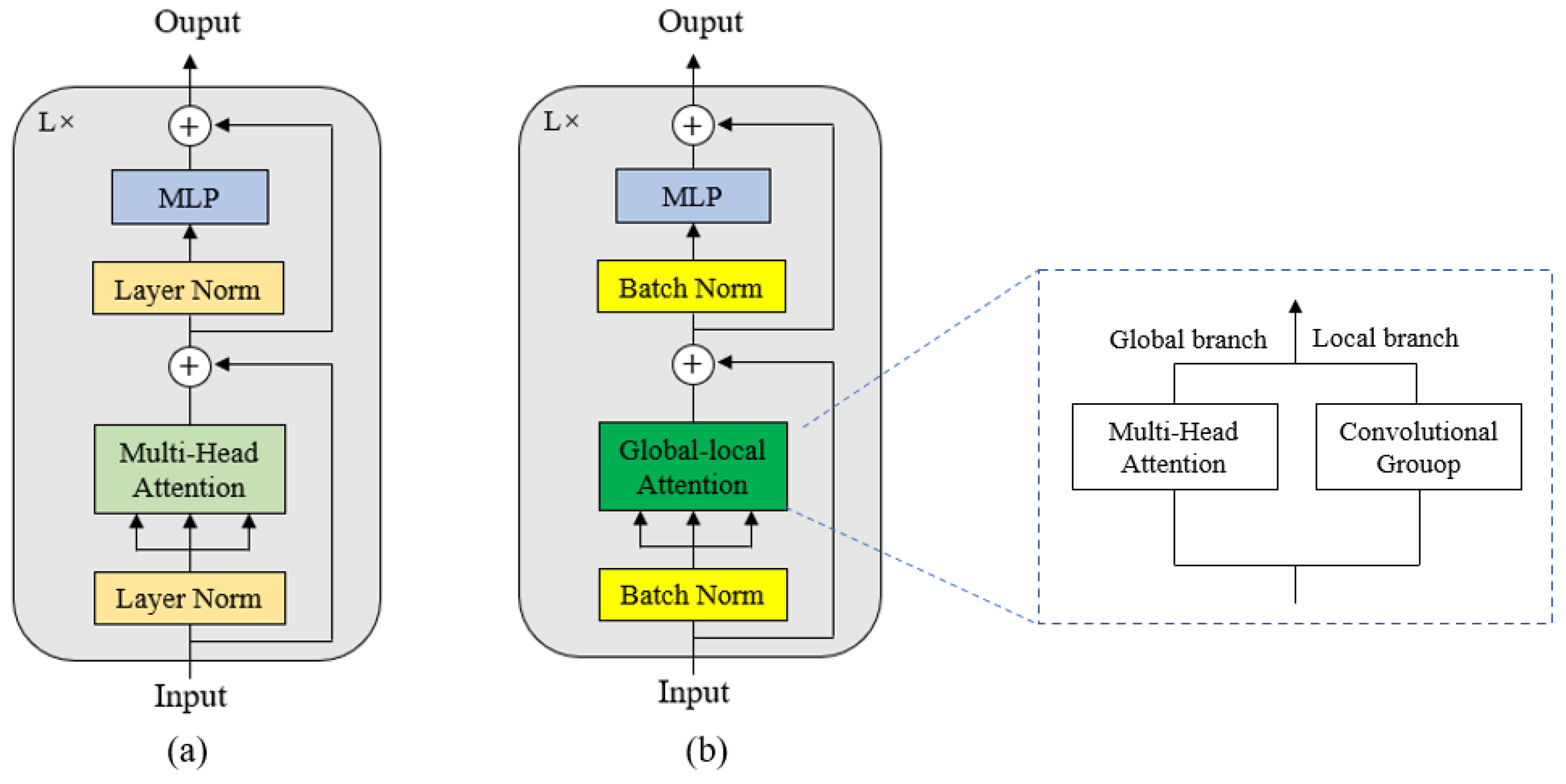
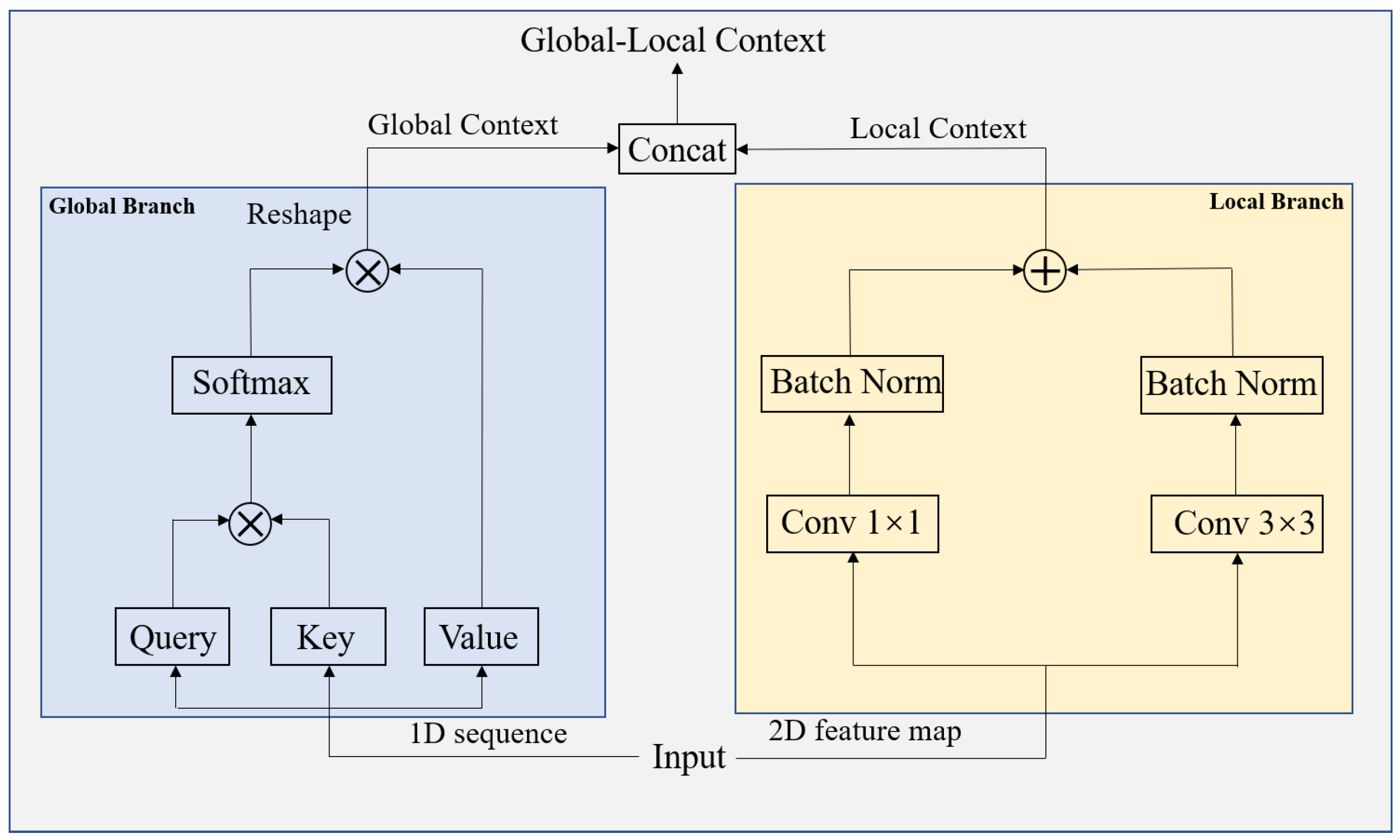
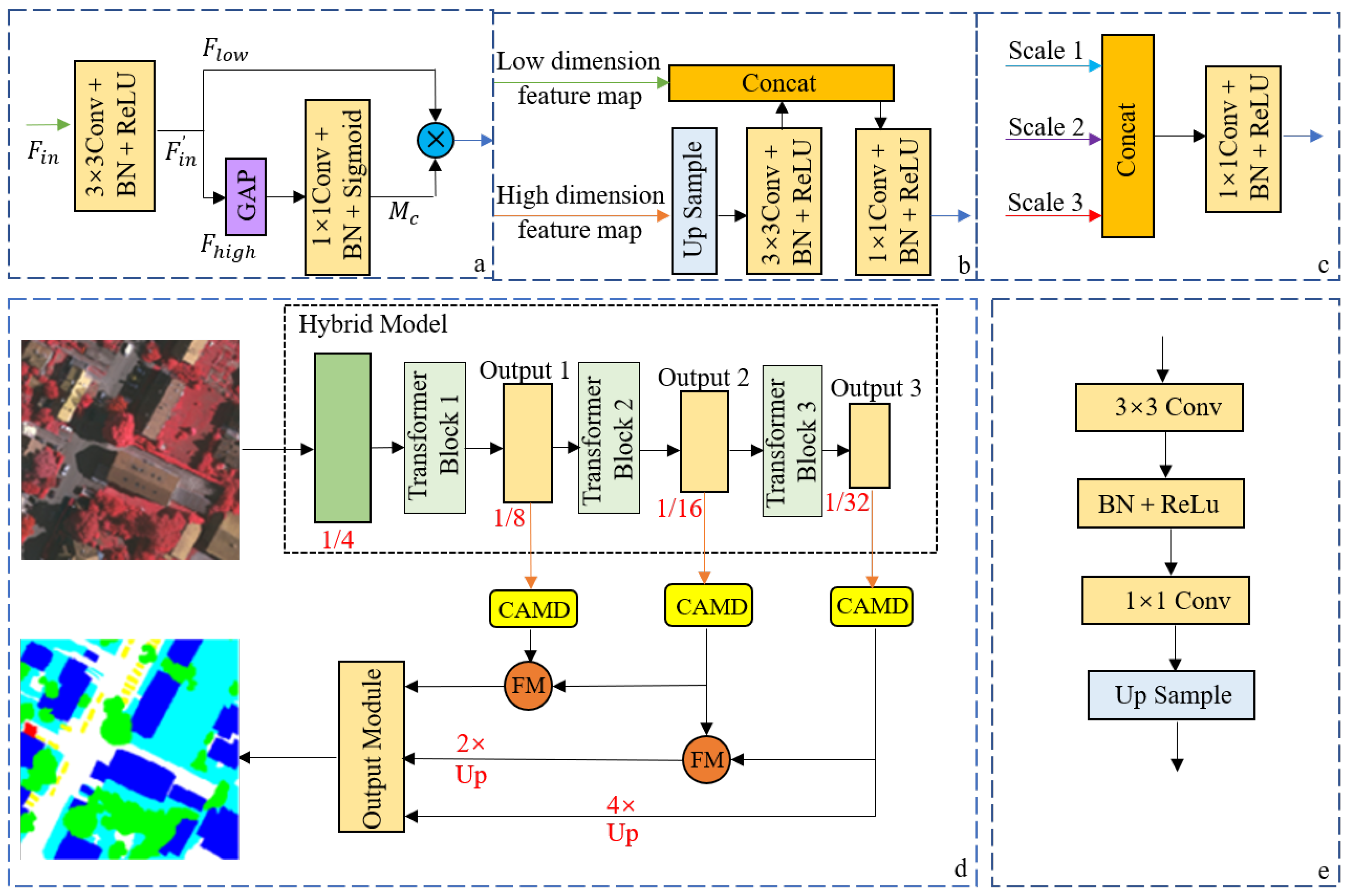
3.1. CNN-Transformer Hybrid as Encoder
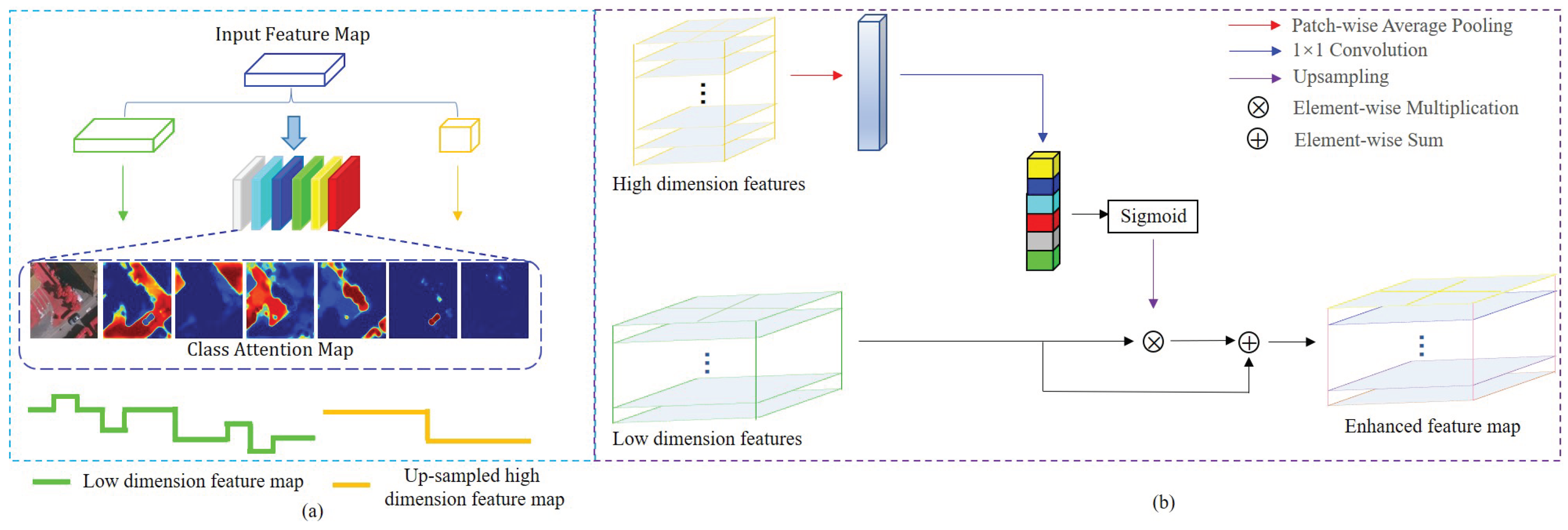
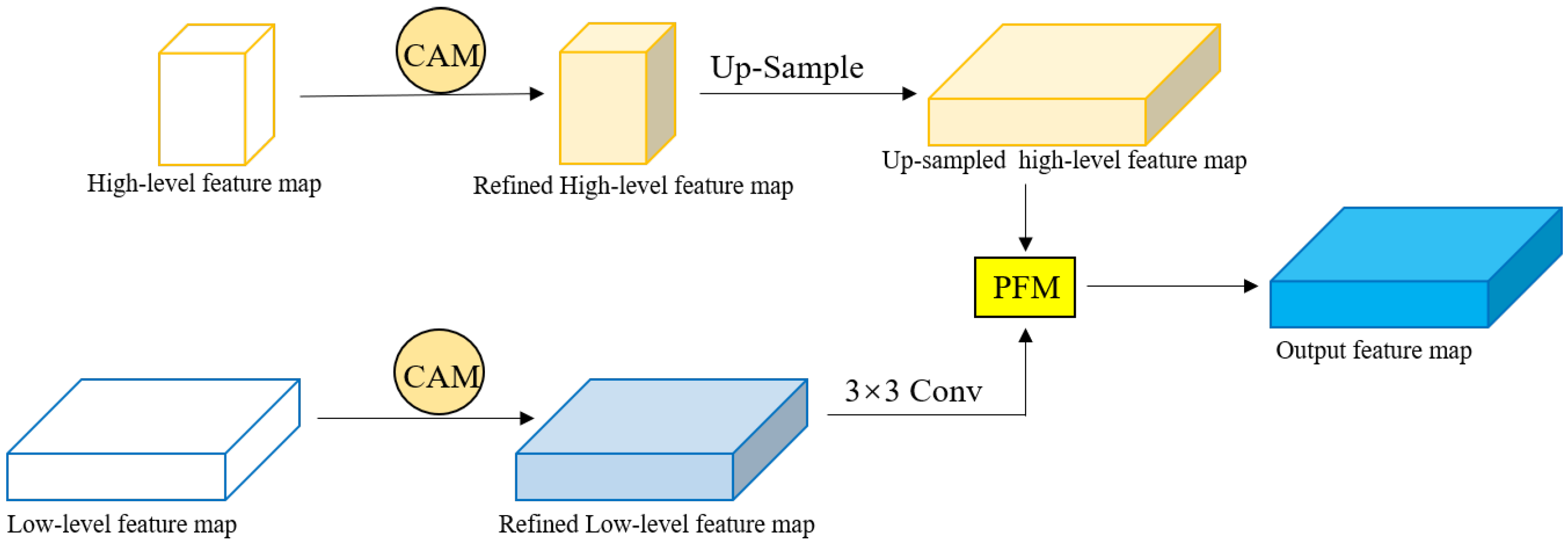
3.2. CNN-Based Decoder
3.3. Network Architecture
4. Experiment Setup
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
5. Experiments and Results
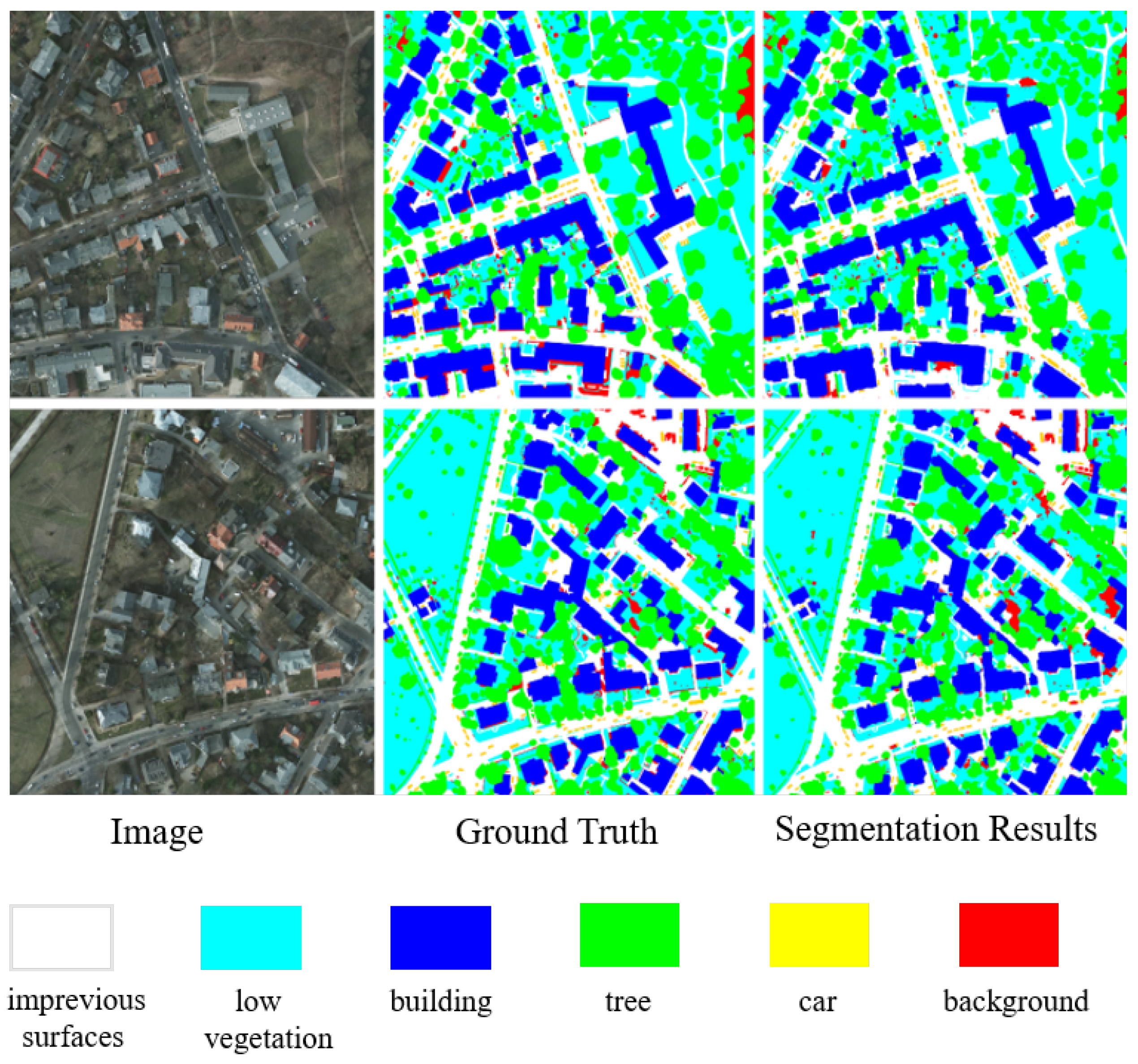
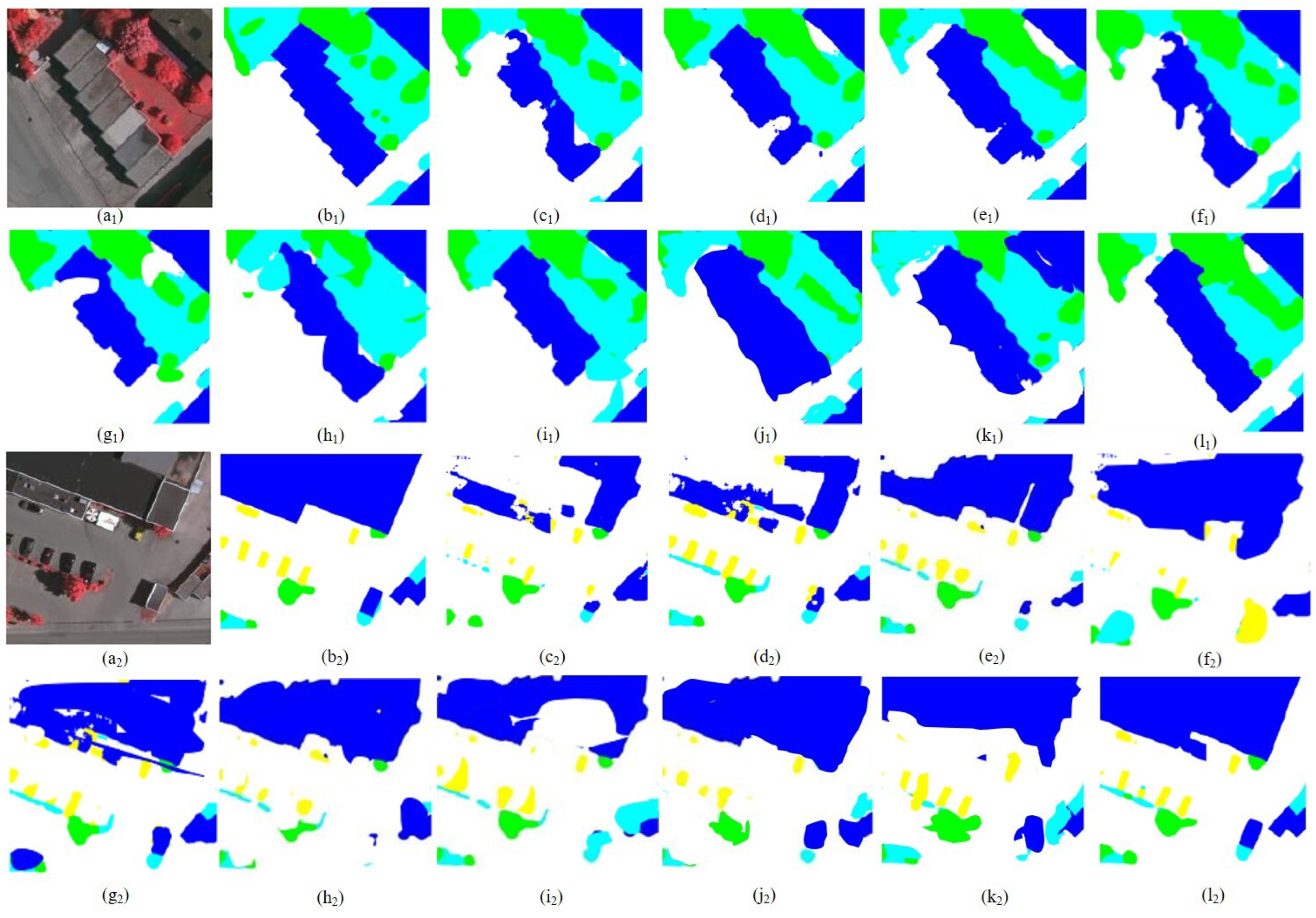
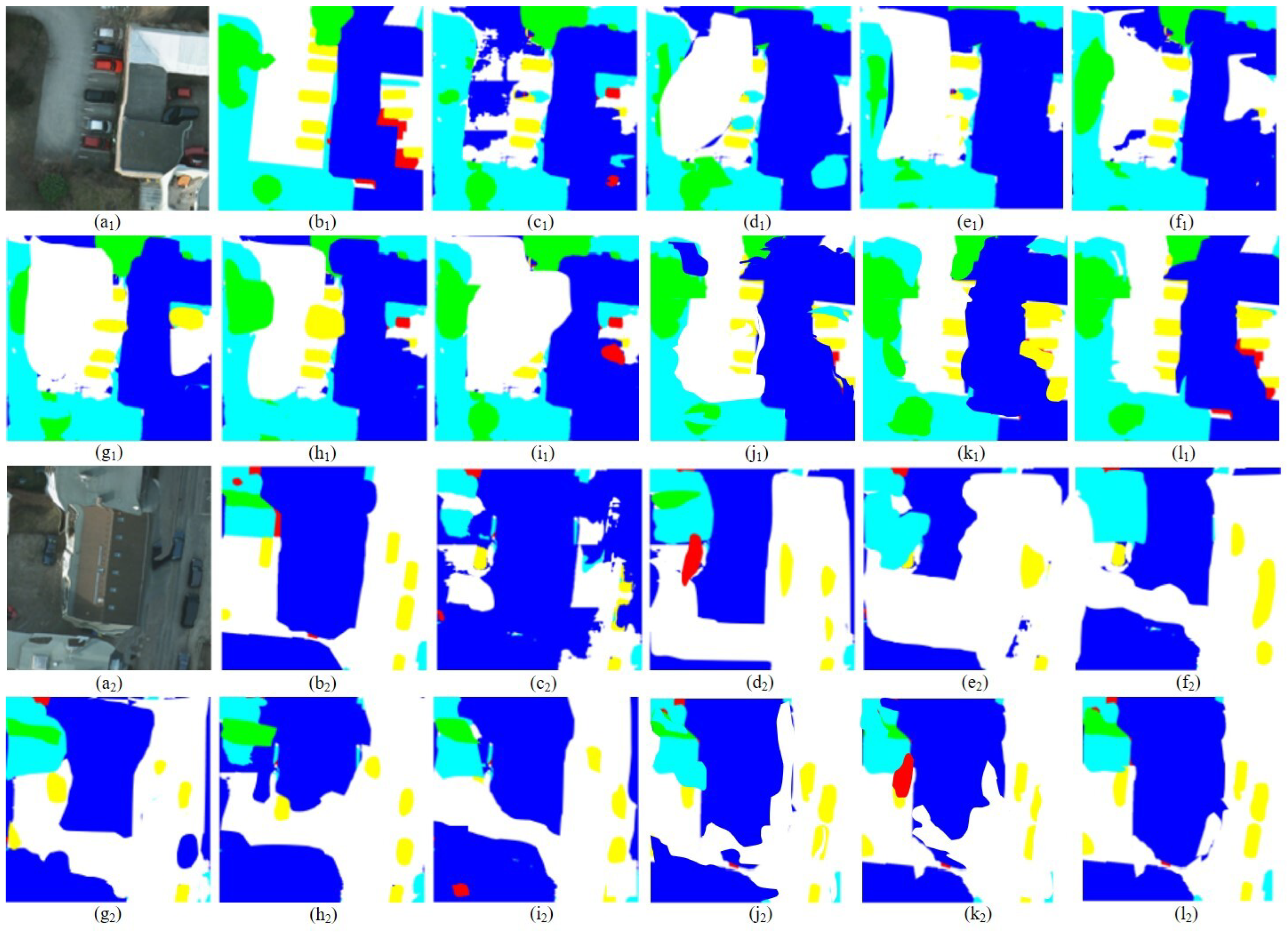
5.1. Result Display
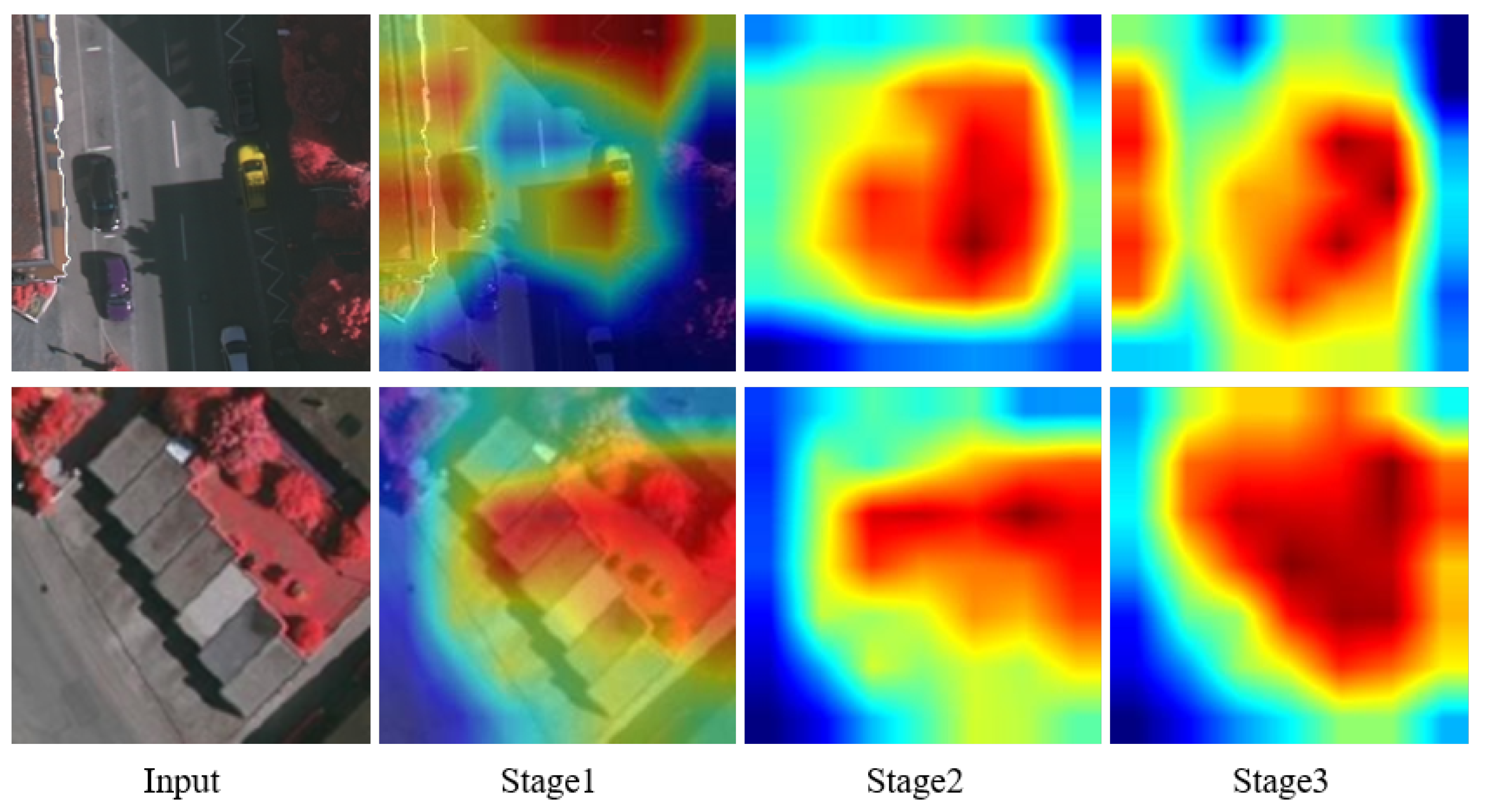
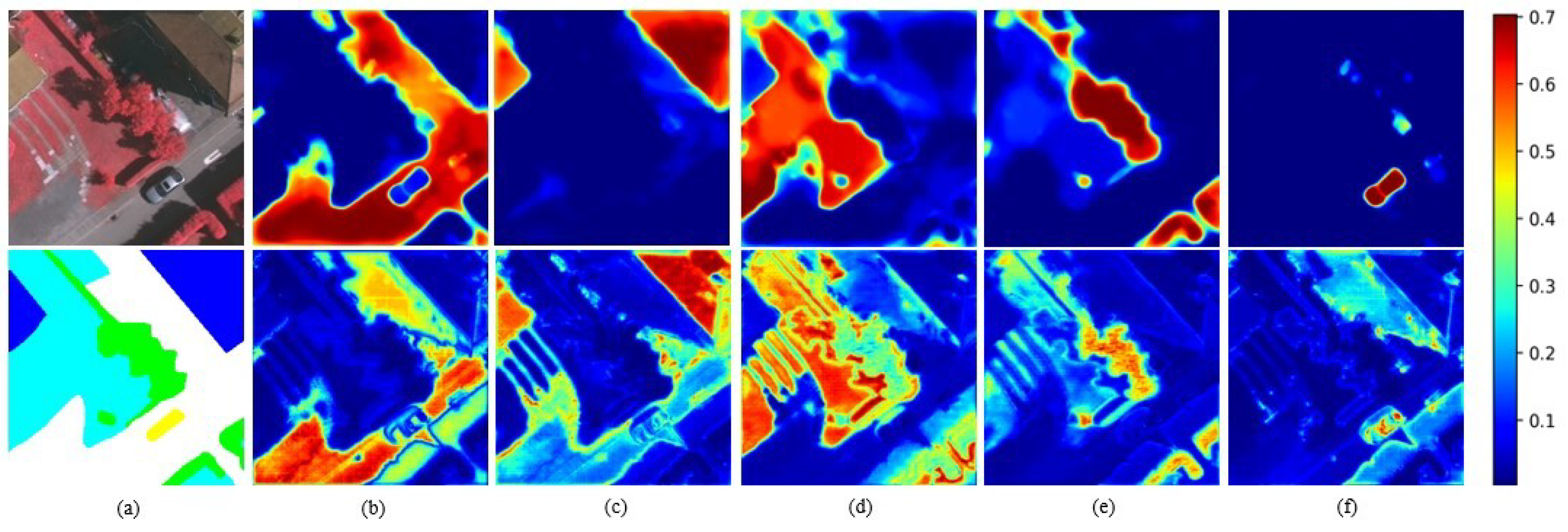
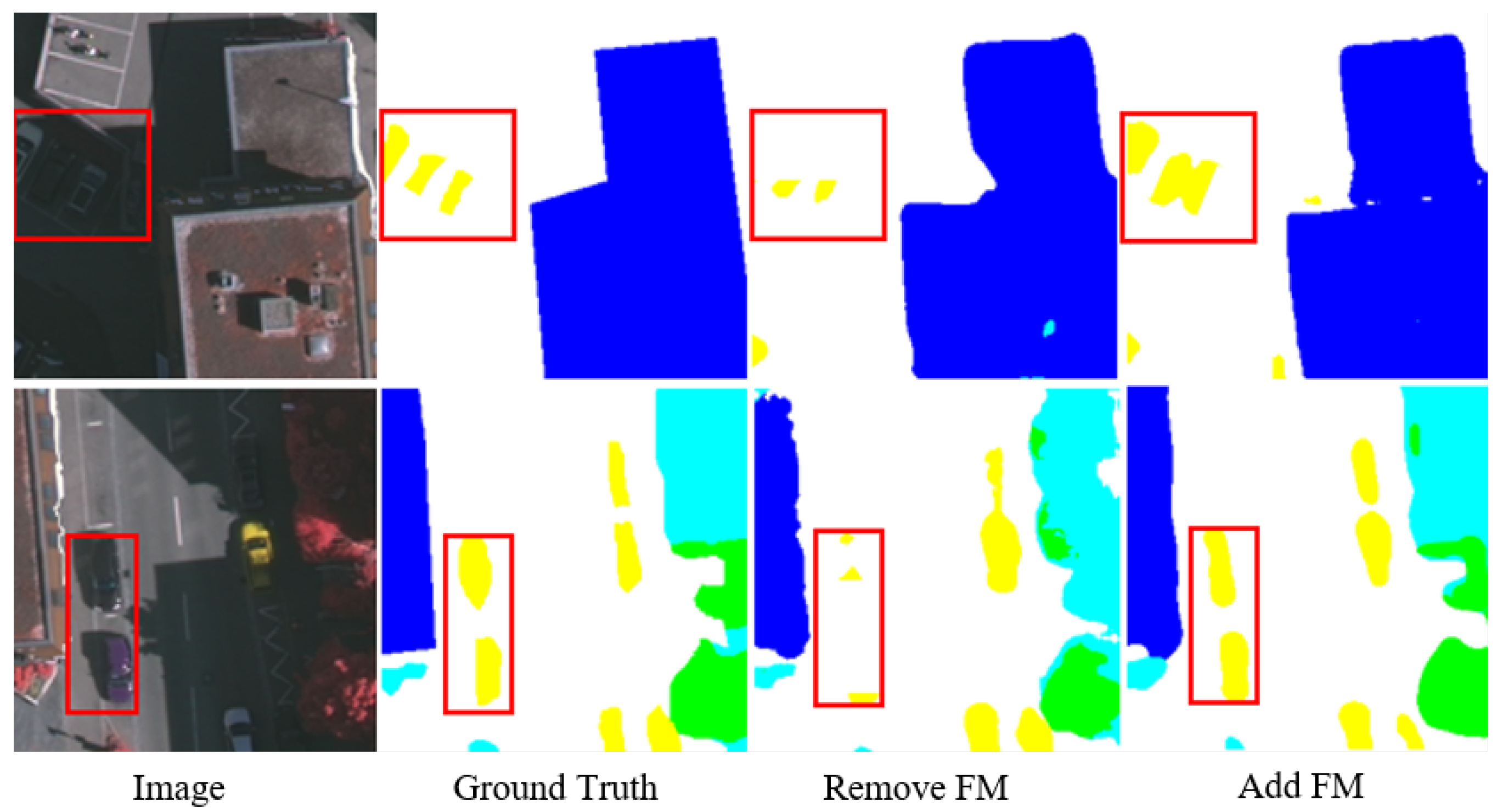
5.2. CAM Visualization Analysis
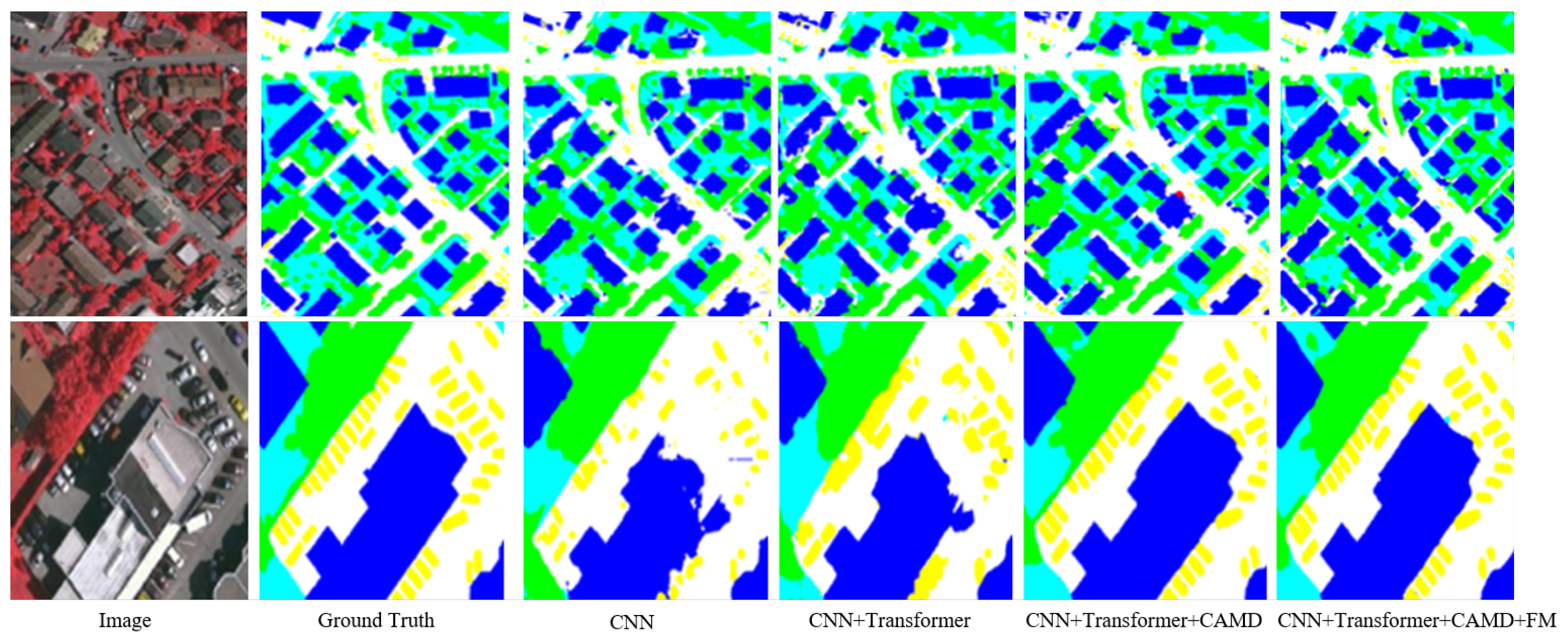
5.3. Architecture Ablation Study
- (1)
- Baseline network:
- (2)
- Channel attention optimization module:
- (3)
- Fusion module:
- (4)
- Advanced contrast:
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tapasvi, B.; Udaya Kumar, N.; Gnanamanoharan, E. A Survey on Semantic Segmentation using Deep Learning Techniques. Int. J. Eng. Res. Technol. 2021, 9, 50–56. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Wang, H.; Zhu, Y.; Adam, H.; Yuille, A.; Chen, L.C. Max-deeplab: End-to-end panoptic segmentation with mask transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5463–5474. [Google Scholar]
- He, L.; Zhou, Q.; Li, X.; Niu, L.; Cheng, G.; Li, X.; Liu, W.; Tong, Y.; Ma, L.; Zhang, L. End-to-end video object detection with spatial-temporal transformers. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 1507–1516. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12873–12883. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 11976–11986. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Borjigin, S.; Sahoo, P.K. Color image segmentation based on multi-level Tsallis–Havrda–Charvát entropy and 2D histogram using PSO algorithms. Pattern Recognit. 2019, 92, 107–118. [Google Scholar] [CrossRef]
- Wu, Z.; Shen, C.; Hengel, A.V.d. Real-time semantic image segmentation via spatial sparsity. arXiv 2017, arXiv:1712.00213. [Google Scholar]
- Xu, Q.; Ma, Y.; Wu, J.; Long, C. Faster BiSeNet: A Faster Bilateral Segmentation Network for Real-time Semantic Segmentation. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Poudel, R.P.; Liwicki, S.; Cipolla, R. Fast-scnn: Fast semantic segmentation network. arXiv 2019, arXiv:1902.04502. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. Segnet: A deep convolutional encoder–decoder architecture for robust semantic pixel-wise labelling. arXiv 2015, arXiv:1505.07293. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Wang, L.; Fang, S.; Zhang, C.; Li, R.; Duan, C. Efficient Hybrid Transformer: Learning Global-local Context for Urban Scene Segmentation. arXiv 2021, arXiv:2109.08937. [Google Scholar]
- Peng, C.; Tian, T.; Chen, C.; Guo, X.; Ma, J. Bilateral attention decoder: A lightweight decoder for real-time semantic segmentation. Neural Netw. 2021, 137, 188–199. [Google Scholar] [CrossRef] [PubMed]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local attention embedding to improve the semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 426–435. [Google Scholar] [CrossRef]
- Peng, C.; Zhang, K.; Ma, Y.; Ma, J. Cross fusion net: A fast semantic segmentation network for small-scale semantic information capturing in aerial scenes. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5601313. [Google Scholar] [CrossRef]
- Yang, H.; Wu, P.; Yao, X.; Wu, Y.; Wang, B.; Xu, Y. Building extraction in very high resolution imagery by dense-attention networks. Remote Sens. 2018, 10, 1768. [Google Scholar] [CrossRef] [Green Version]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multiscale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17), San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transformer | CAMD | FM | Mean (%) | |
|---|---|---|---|---|
| × | × | × | 81.24 | |
| √ | × | × | 83.25 | |
| MCAFNet | √ | √ | × | 85.46 |
| √ | × | √ | 83.78 | |
| √ | √ | √ | 88.41 |
| Method | Overall Accuracy | Recall | Mean | MIoU |
|---|---|---|---|---|
| U-Net | 87.5 | 83.6 | 82.7 | 81.2 |
| SegNet | 89.4 | 86.9 | 86.7 | 83.6 |
| PSPNet | 89.7 | 87.1 | 86.9 | 84.6 |
| HRNetV2 | 87.2 | 84.1 | 83.2 | 81.4 |
| DeepLab V3+ | 89.8 | 87.0 | 86.7 | 85.2 |
| TransUnet | 90.1 | 87.2 | 87.3 | 86.2 |
| SegFormer | 89.5 | 86.8 | 87.1 | 85.9 |
| Inception-ResNetV2 | 88.1 | 86.5 | 86.4 | 85.5 |
| Swin Transformer | 90.2 | 87.3 | 87.9 | 87.3 |
| MCAFNet | 90.8 | 87.9 | 88.4 | 88.2 |
| Method | #Param | Building | Car | Low_veg | Imp | Tree | GFLOPs |
|---|---|---|---|---|---|---|---|
| U-Net | 118 M | 88.2 | 75.2 | 80.2 | 86.9 | 85.4 | 135.4 |
| SegNet | 104 M | 90.1 | 84.2 | 81.7 | 90.5 | 86.8 | 82.9 |
| PSPNet | 121 M | 91.2 | 85.7 | 82.9 | 91.1 | 86.4 | 20.5 |
| HRNetV2 | 40 M | 90.8 | 76.8 | 80.4 | 87.5 | 86.5 | 51.5 |
| DeepLab V3+ | 223 M | 91.7 | 81.4 | 82.1 | 88.9 | 87.6 | 72.3 |
| TransUnet | 257 M | 92.3 | 85.1 | 83.2 | 89.7 | 87.1 | 112.4 |
| SegFormer | 246 M | 91.1 | 81.3 | 81.5 | 86.9 | 86.9 | 88.7 |
| Inception-ResNetV2 | 153 M | 90.7 | 84.9 | 82.5 | 89.1 | 86.7 | 98.5 |
| Swin Transformer | 238 M | 92.4 | 85.5 | 84.1 | 91.3 | 87.2 | 131.4 |
| MCAFNet | 334 M | 93.6 | 86.4 | 84.9 | 92.6 | 88.1 | 164.2 |
| Method | #Param | Building | Car | Low_veg | Imp | Tree | GFLOPs |
|---|---|---|---|---|---|---|---|
| U-Net | 114M | 87.2 | 76.2 | 80.8 | 86.2 | 84.6 | 123.5 |
| SegNet | 97M | 89.4 | 83.6 | 82.3 | 90.1 | 85.9 | 80.5 |
| PSPNet | 114M | 90.3 | 84.7 | 81.9 | 89.6 | 85.4 | 16.1 |
| HRNetV2 | 38M | 91.2 | 77.8 | 80.1 | 86.9 | 85.6 | 43.8 |
| DeepLab V3+ | 207M | 91.4 | 80.9 | 81.8 | 88.2 | 87.2 | 62.7 |
| TransUnet | 231M | 91.8 | 84.6 | 82.8 | 89.1 | 86.7 | 98.7 |
| SegFormer | 220M | 90.7 | 81.1 | 81.1 | 86.4 | 86.3 | 81.2 |
| Inception-ResNetV2 | 141M | 90.1 | 83.9 | 80.9 | 87.7 | 85.5 | 87.3 |
| Swin Transformer | 217M | 91.6 | 85.1 | 83.1 | 90.4 | 87.4 | 108.7 |
| MCAFNet | 320M | 92.4 | 86.1 | 83.9 | 91.3 | 88.3 | 153.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, M.; Ren, D.; Feng, Q.; Wang, Z.; Dong, Y.; Lu, F.; Wu, X. MCAFNet: A Multiscale Channel Attention Fusion Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2023, 15, 361. https://doi.org/10.3390/rs15020361
Yuan M, Ren D, Feng Q, Wang Z, Dong Y, Lu F, Wu X. MCAFNet: A Multiscale Channel Attention Fusion Network for Semantic Segmentation of Remote Sensing Images. Remote Sensing. 2023; 15(2):361. https://doi.org/10.3390/rs15020361
Chicago/Turabian StyleYuan, Min, Dingbang Ren, Qisheng Feng, Zhaobin Wang, Yongkang Dong, Fuxiang Lu, and Xiaolin Wu. 2023. "MCAFNet: A Multiscale Channel Attention Fusion Network for Semantic Segmentation of Remote Sensing Images" Remote Sensing 15, no. 2: 361. https://doi.org/10.3390/rs15020361
APA StyleYuan, M., Ren, D., Feng, Q., Wang, Z., Dong, Y., Lu, F., & Wu, X. (2023). MCAFNet: A Multiscale Channel Attention Fusion Network for Semantic Segmentation of Remote Sensing Images. Remote Sensing, 15(2), 361. https://doi.org/10.3390/rs15020361