
Multi-Label Remote Sensing Image Land Cover Classification Based on a Multi-Dimensional Attention Mechanism


Abstract
:1. Introduction
2. Related Work
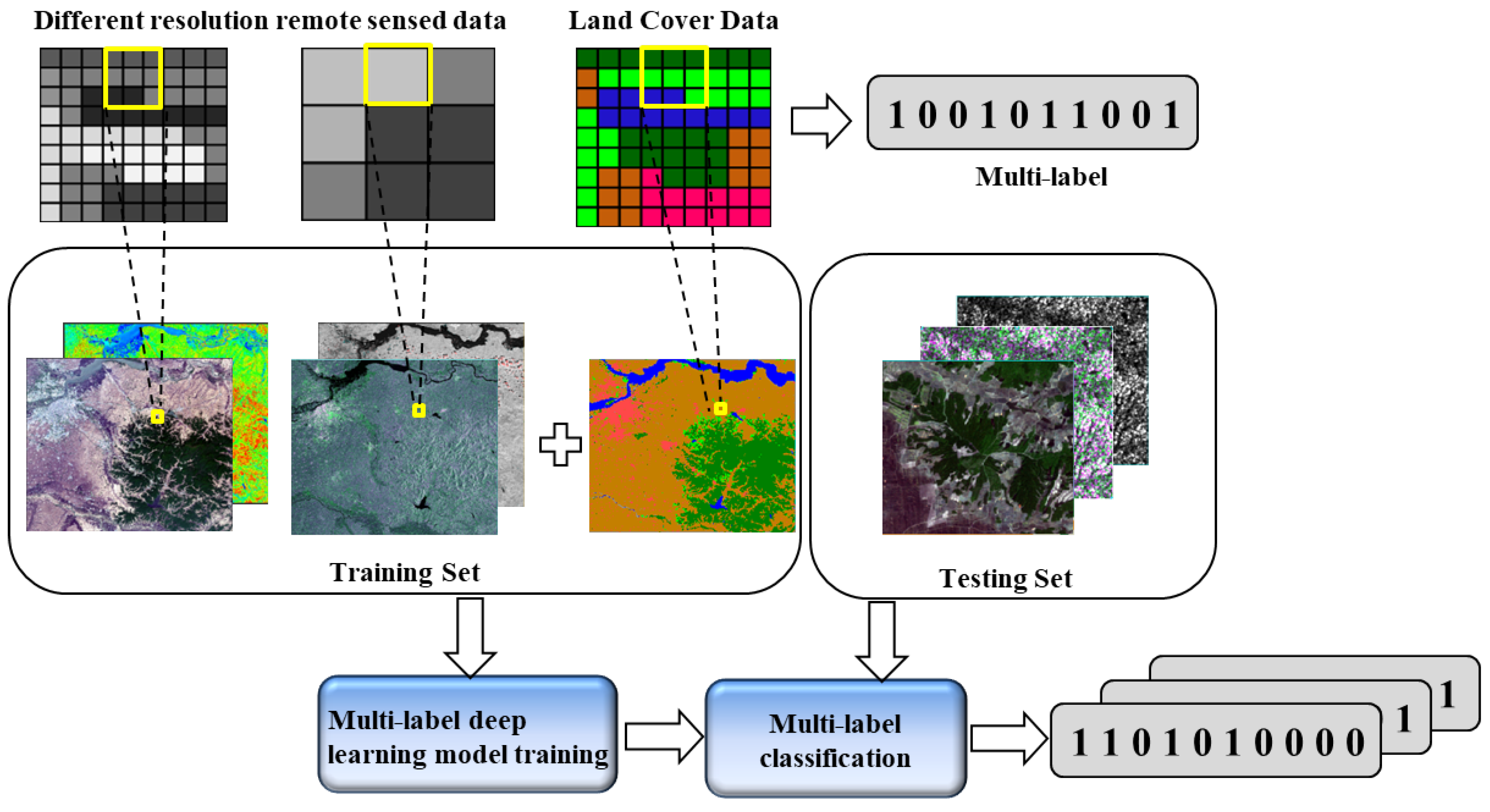
3. Methodology
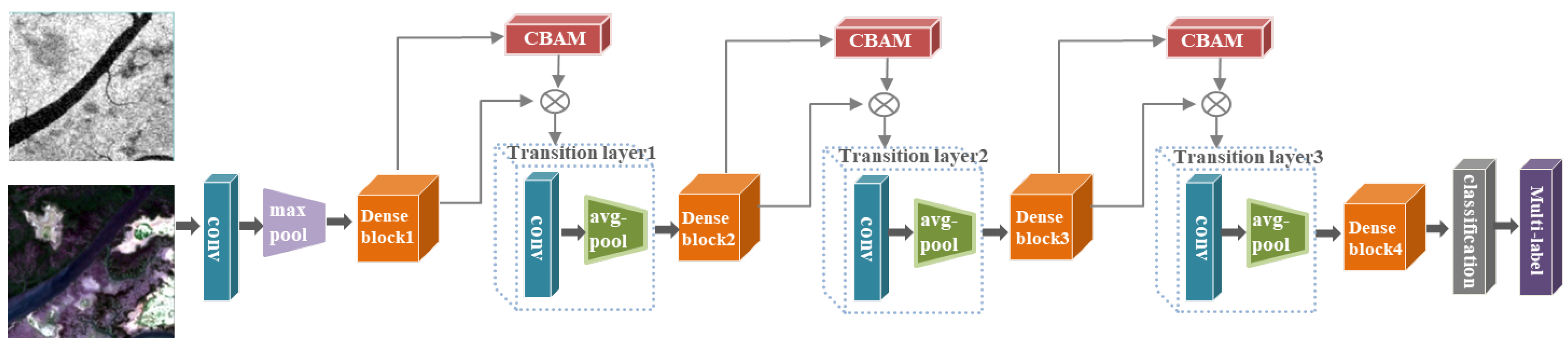
3.1. Model Structure
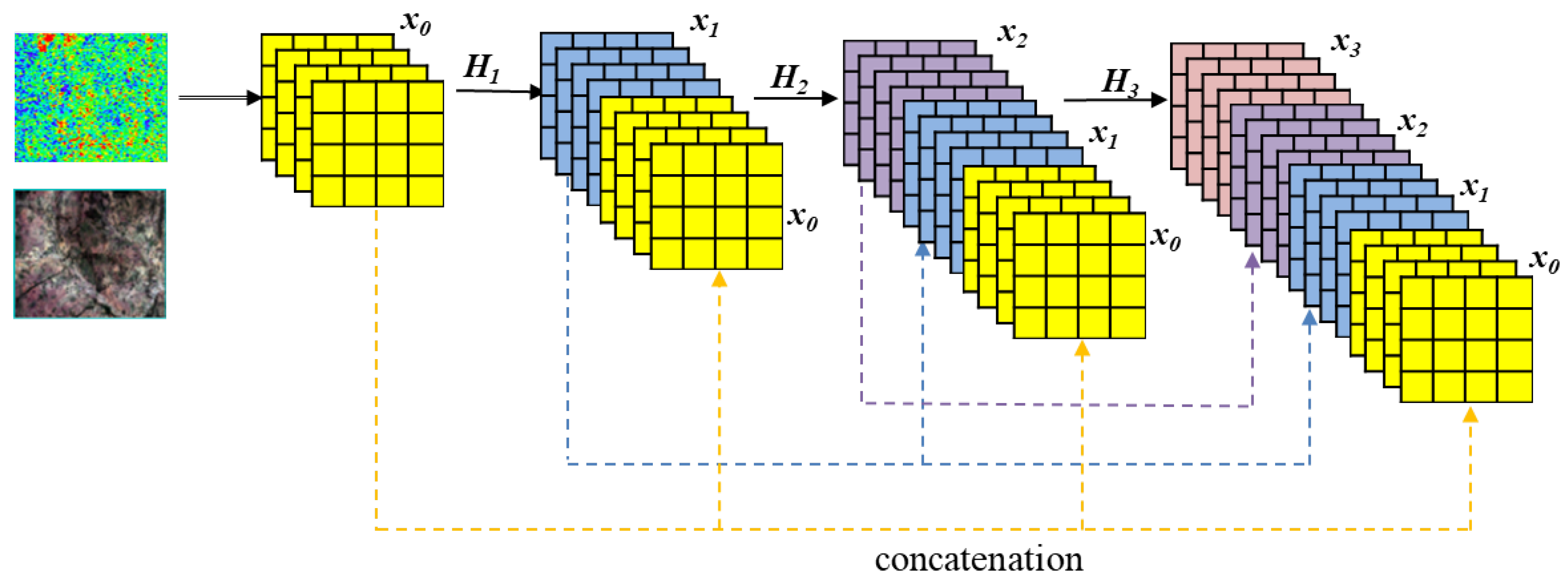
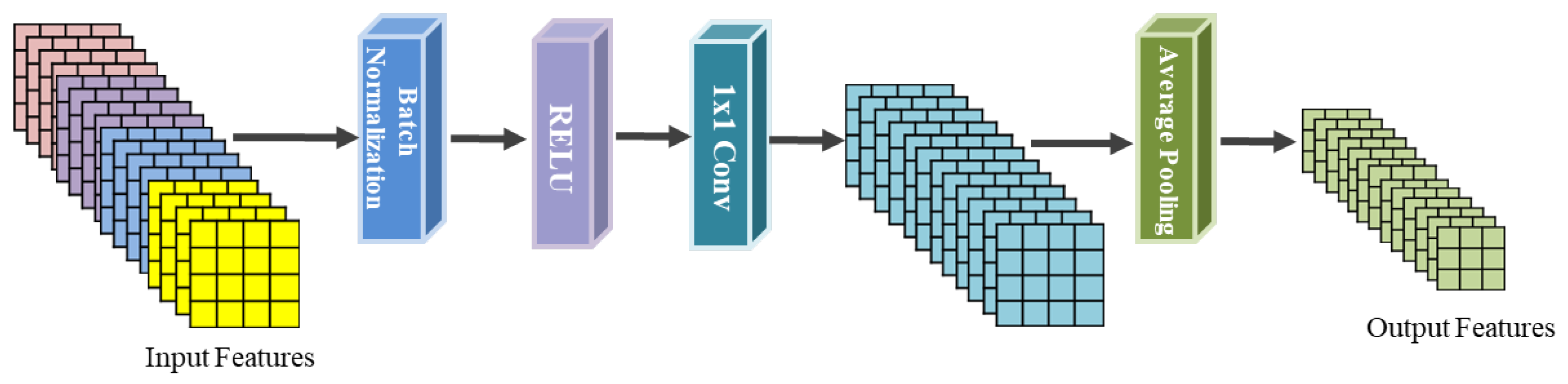
3.2. Feature Extraction
3.3. Attention
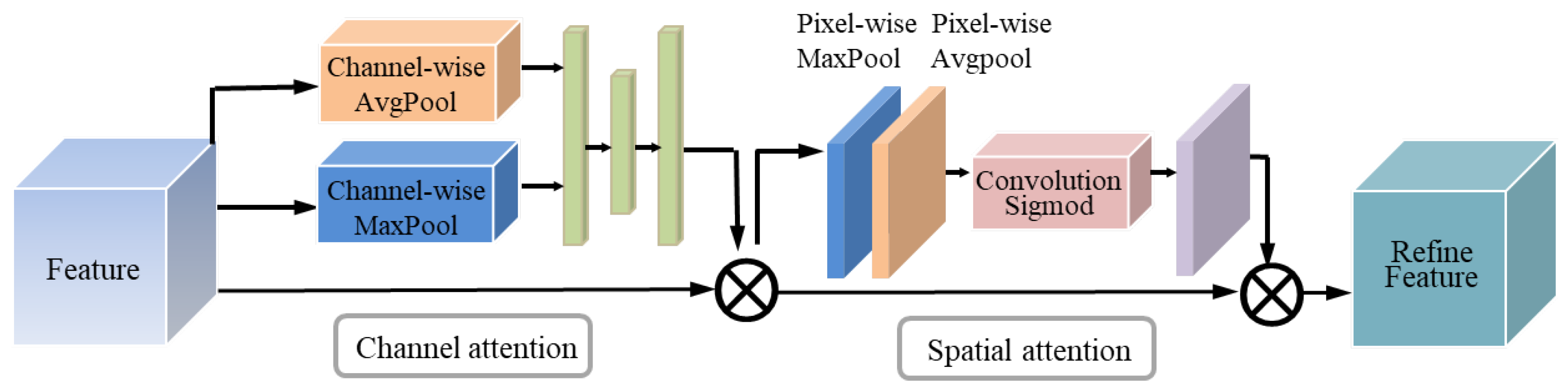
3.3.1. CBAM Structure
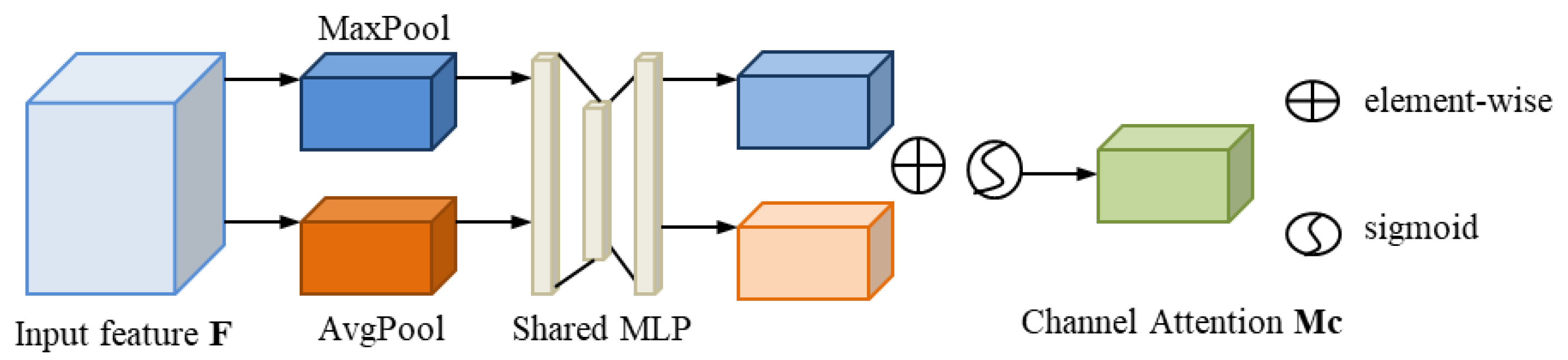
3.3.2. Channel Attention Dimension Module (CAM)
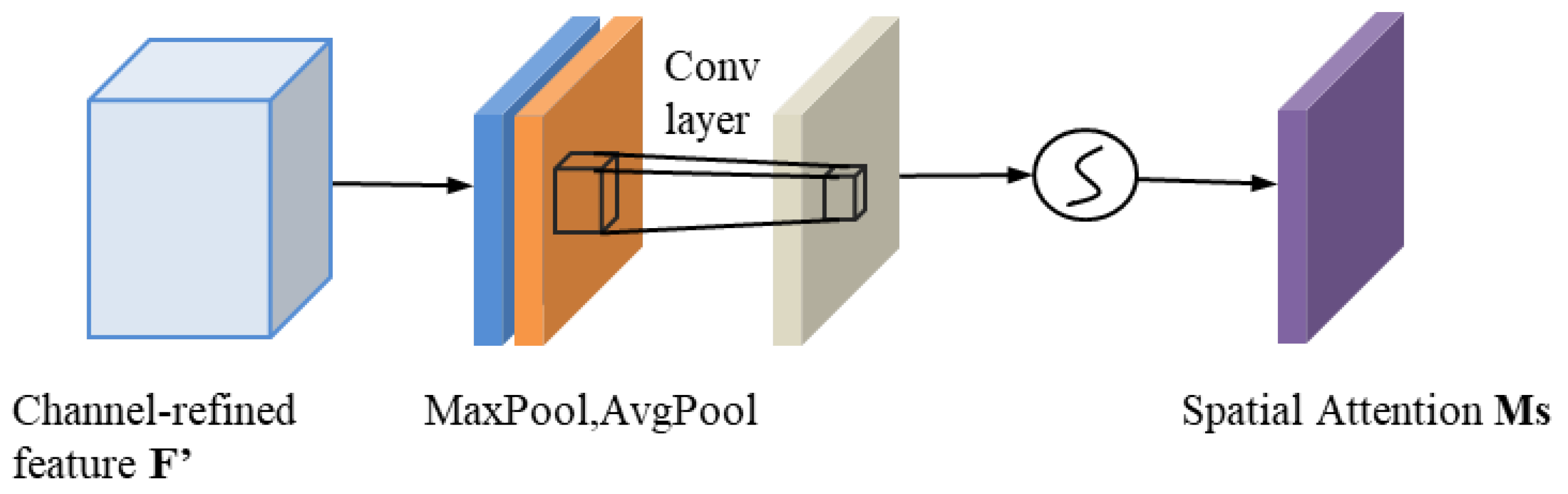
3.3.3. Spatial Attention Dimension Module (SAM)
3.4. Classifier
4. Experiment
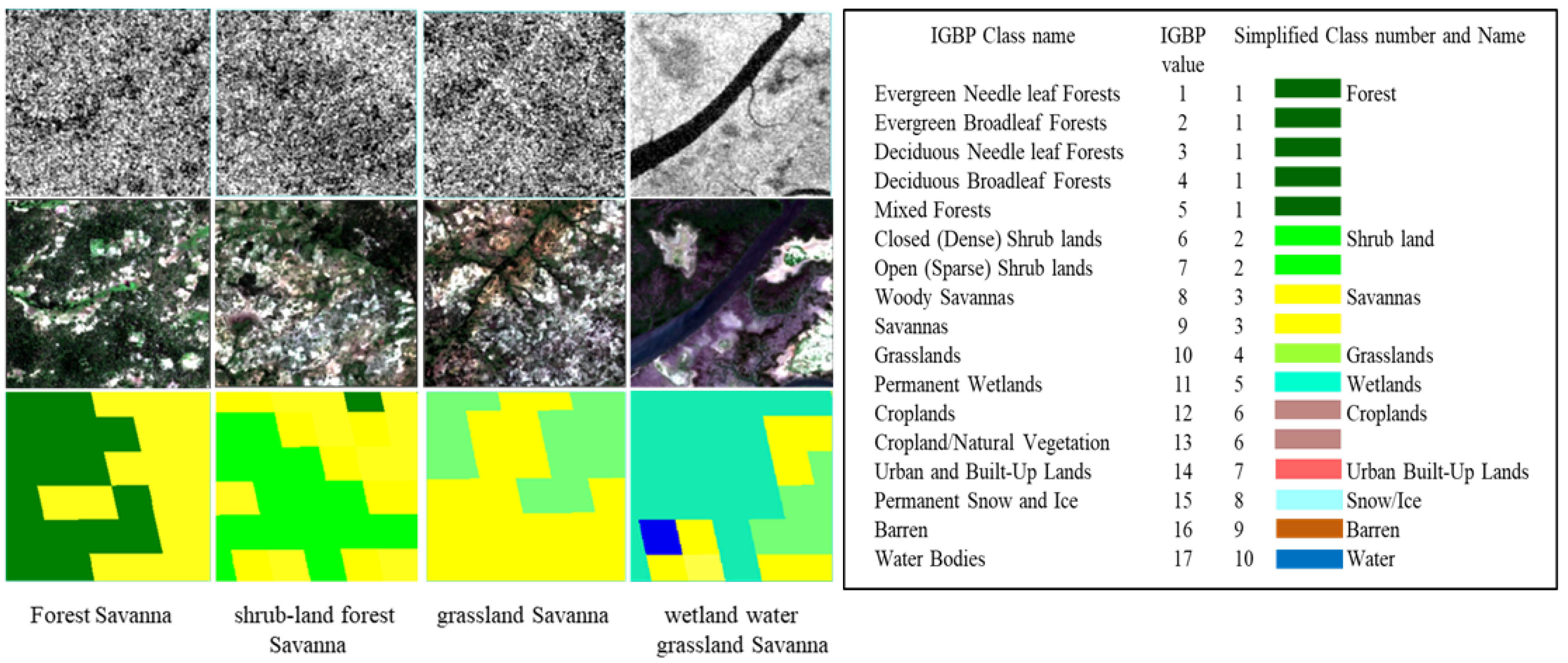
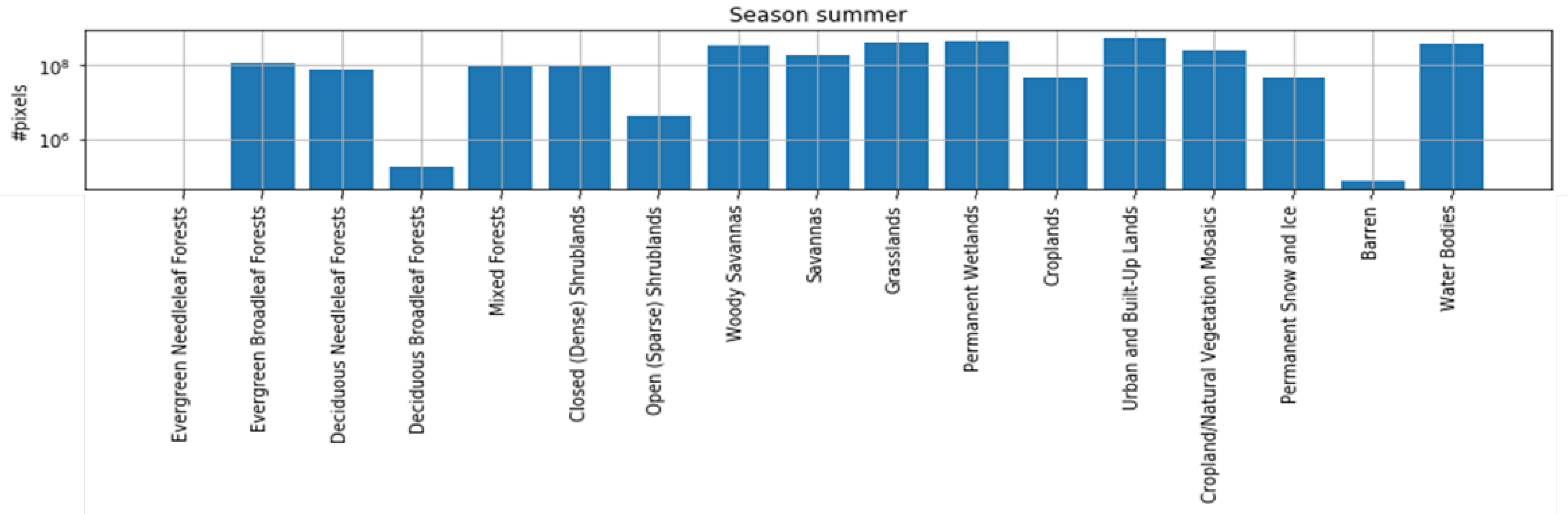
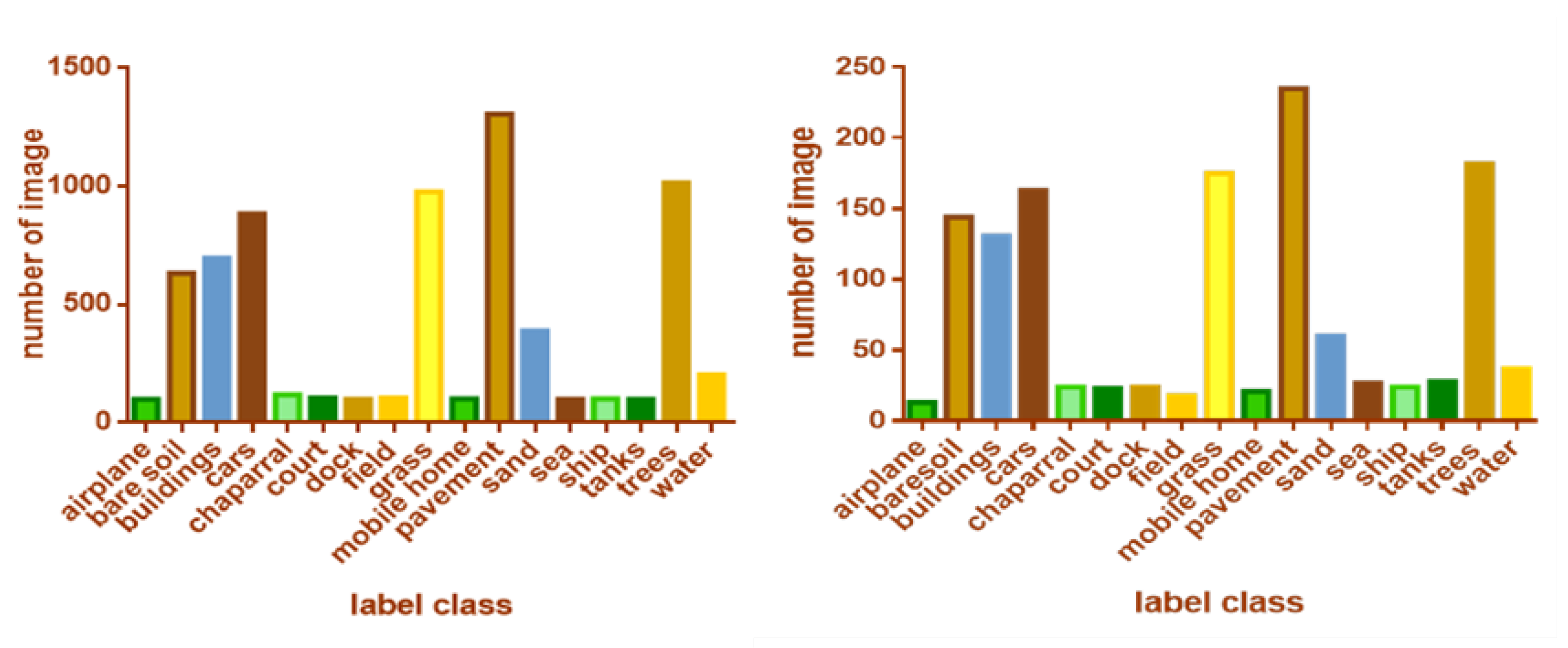
4.1. Dataset
4.1.1. SEN12MS
4.1.2. UC-Merced
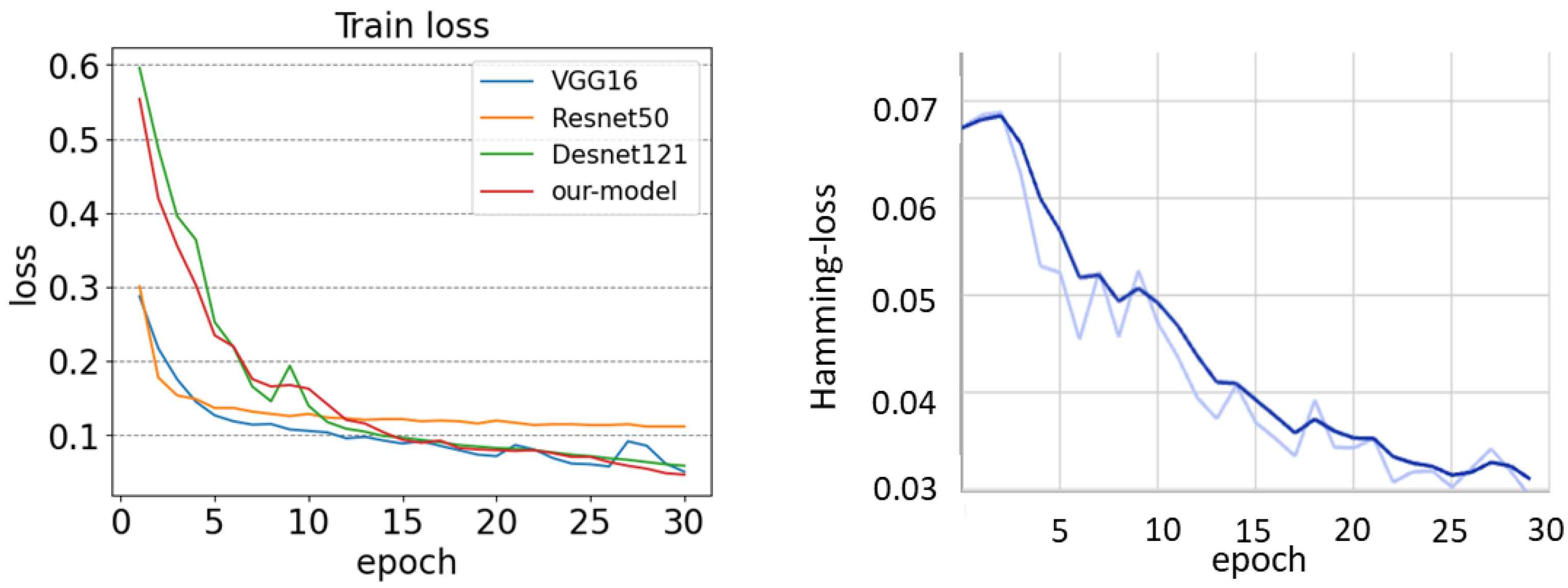
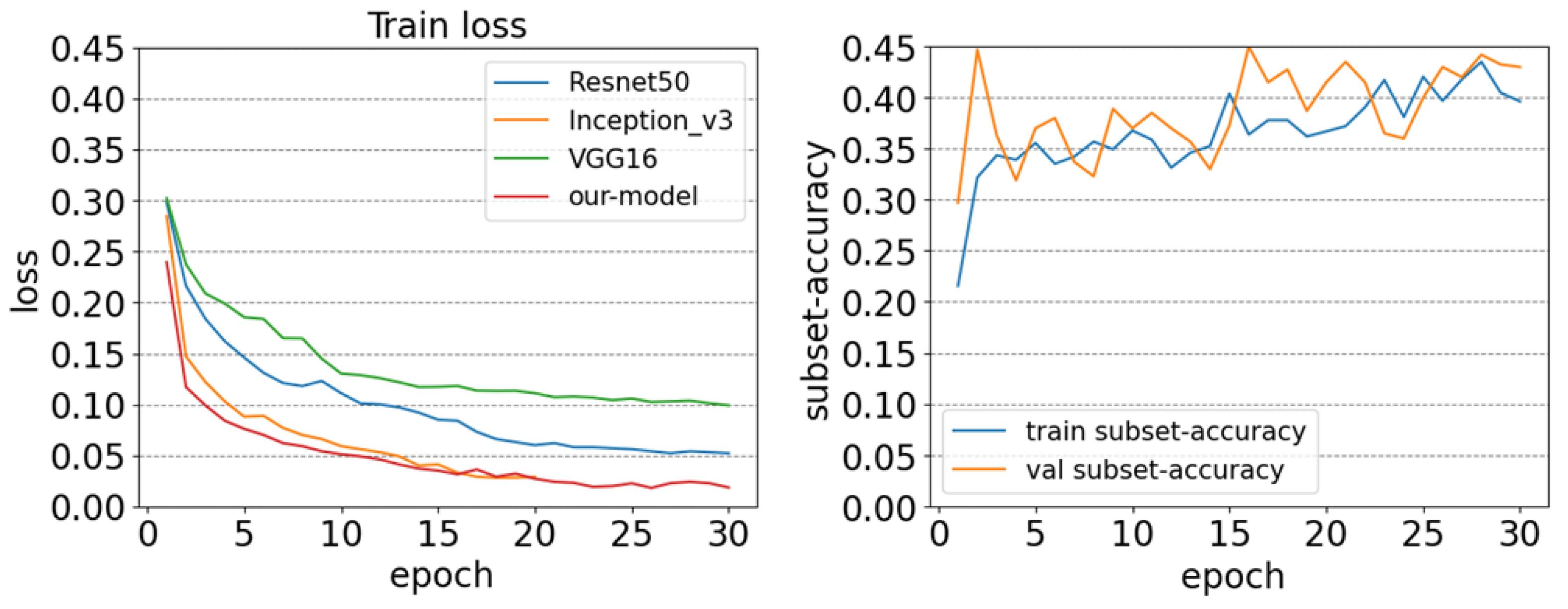
4.2. Training Details
| Algorithm 1: The training process of the proposed model. |
 |
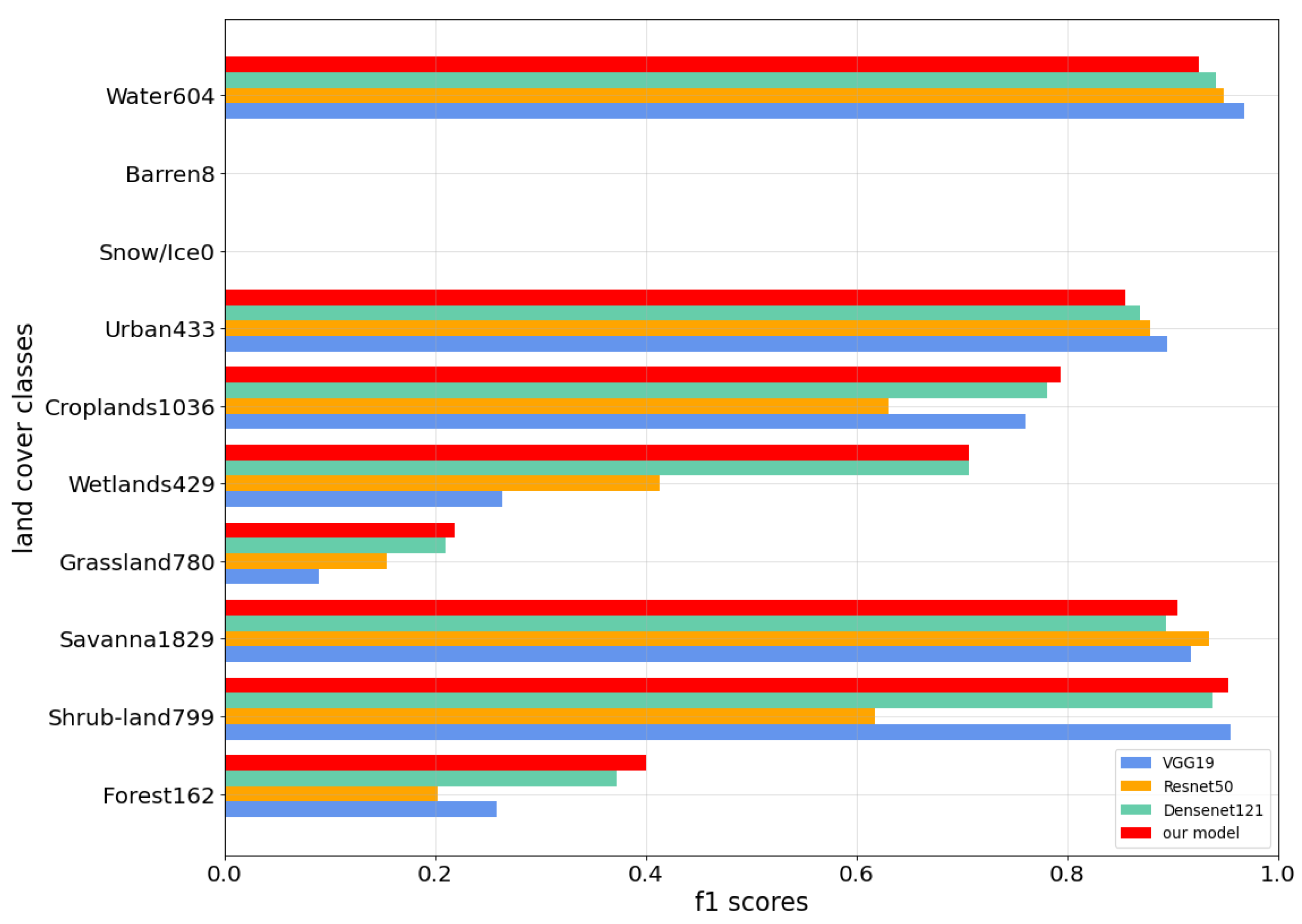
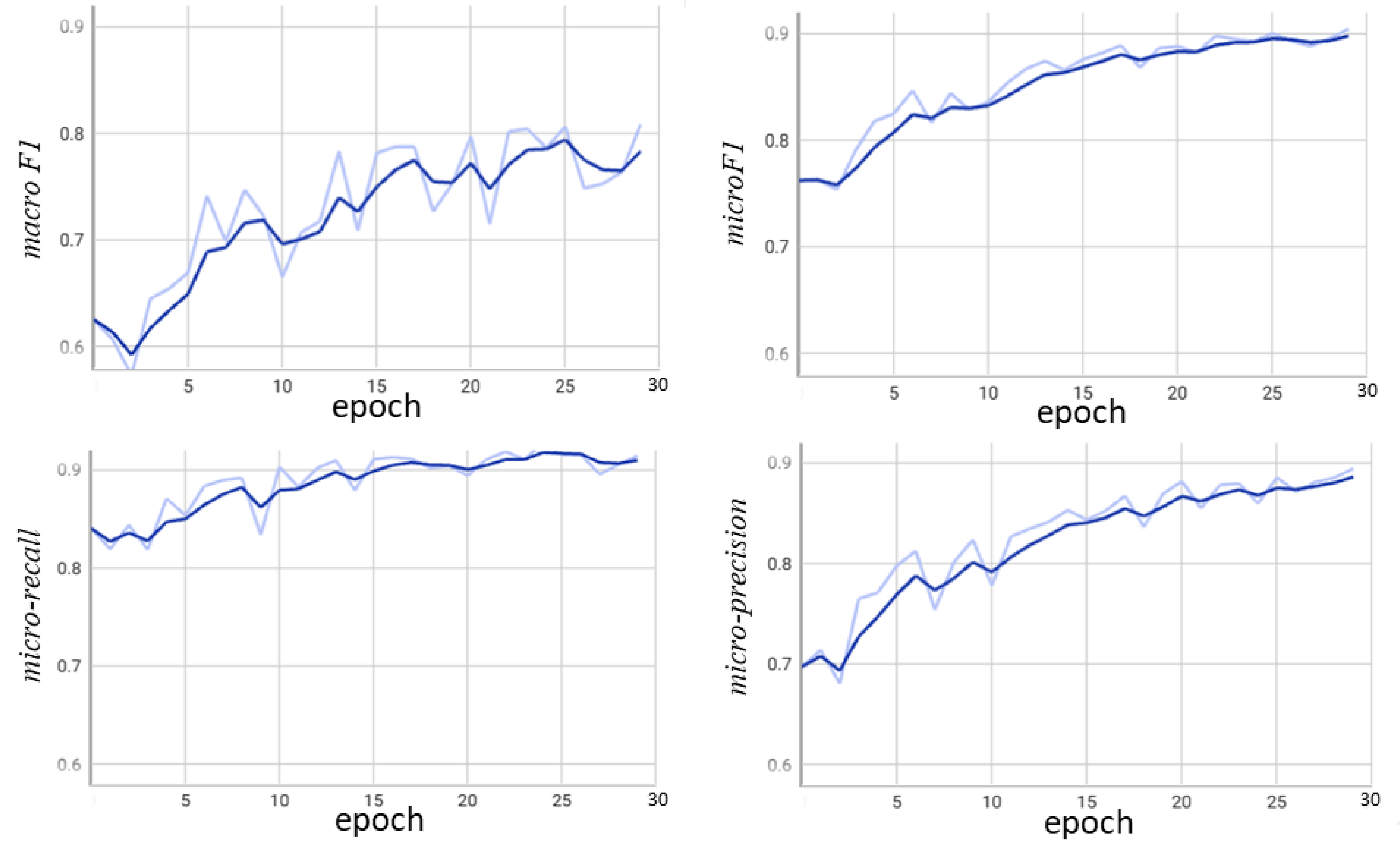
4.3. Evaluation
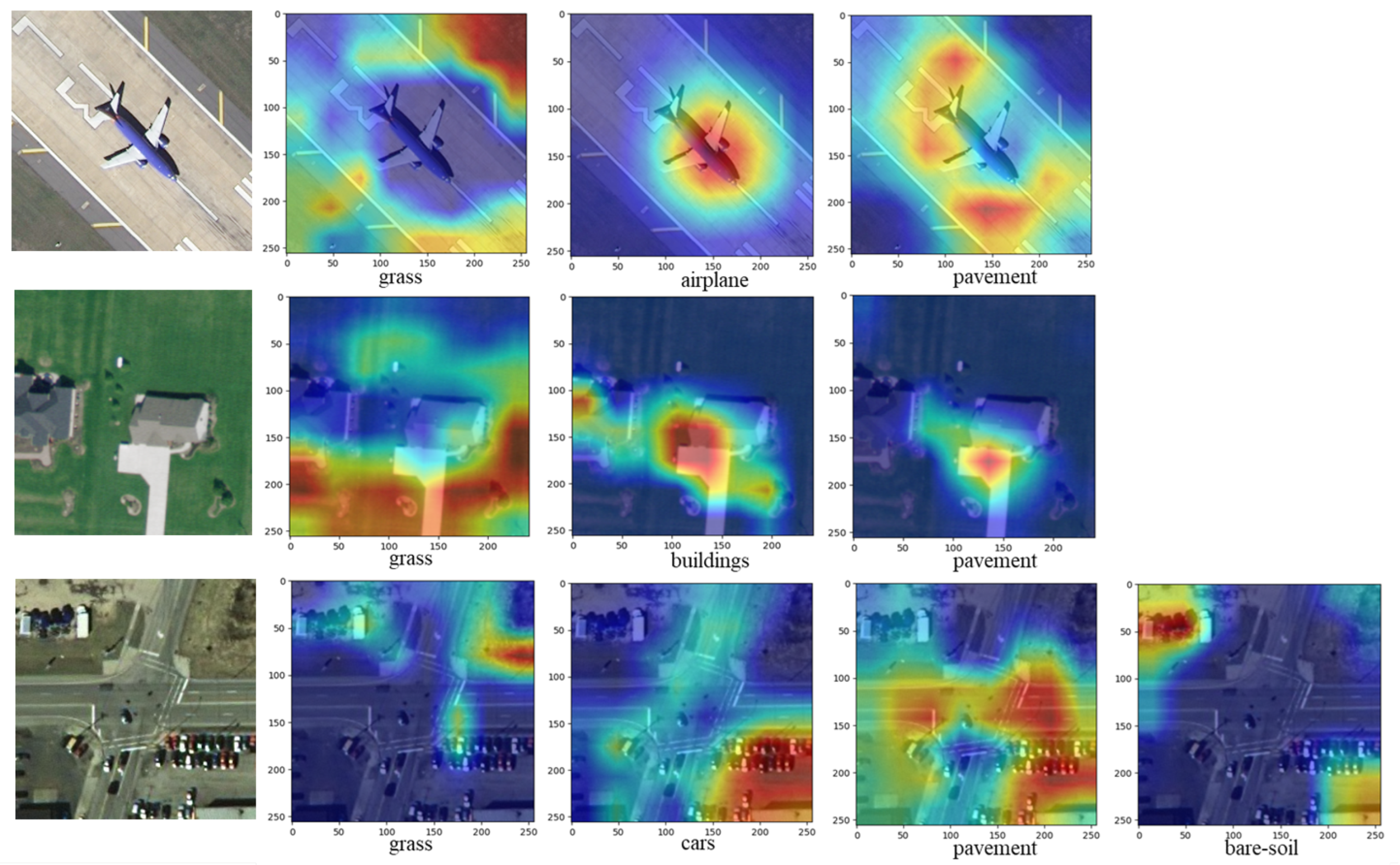
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sumbul, G.; Demİr, B. A deep multi-attention driven approach for multi-label remote sensing image classification. IEEE Access 2020, 8, 95934–95946. [Google Scholar] [CrossRef]
- Zhang, T.; Yan, W.; Li, J.; Chen, J. Multiclass labeling of very high-resolution remote sensing imagery by enforcing nonlocal shared constraints in multilevel conditional random fields model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2854–2867. [Google Scholar] [CrossRef]
- Law, A.; Ghosh, A. Multi-label classification using a cascade of stacked autoencoder and extreme learning machines. Neurocomputing 2019, 358, 222–234. [Google Scholar] [CrossRef]
- Koda, S.; Zeggada, A.; Melgani, F.; Nishii, R. Spatial and structured SVM for multilabel image classification. IEEE Trans. Geosci. Remote. Sens. 2018, 56, 5948–5960. [Google Scholar] [CrossRef]
- Zeggada, A.; Melgani, F.; Bazi, Y. A deep learning approach to UAV image multilabeling. IEEE Geosci. Remote Sens. Lett. 2017, 14, 694–698. [Google Scholar] [CrossRef]
- Zeggada, A.; Benbraika, S.; Melgani, F.; Mokhtari, Z. Multilabel conditional random field classification for UAV images. IEEE Geosci. Remote. Sens. Lett. 2018, 15, 399–403. [Google Scholar] [CrossRef]
- Khan, N.; Chaudhuri, U.; Banerjee, B.; Chaudhuri, S. Graph convolutional network for multi-label VHR remote sensing scene recognition. Neurocomputing 2019, 357, 36–46. [Google Scholar] [CrossRef]
- Shendryk, I.; Rist, Y.; Lucas, R.; Thorburn, P.; Ticehurst, C. Deep learning-a new approach for multi-label scene classification in planetscope and sentinel-2 imagery. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1116–1119. [Google Scholar]
- Karalas, K.; Tsagkatakis, G.; Zervakis, M.; Tsakalides, P. Land classification using remotely sensed data: Going multilabel. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3548–3563. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhao, X.; Zhang, J.; Tian, J.; Zhuo, L.; Zhang, J. Residual dense network based on channel-spatial attention for the scene classification of a high-resolution remote sensing image. Remote Sens. 2020, 12, 1887. [Google Scholar] [CrossRef]
- Gao, Y.; Shi, J.; Li, J.; Wang, R. Remote sensing scene classification with dual attention-aware network. In Proceedings of the 2020 IEEE 5th International Conference on Image, Vision and Computing (ICIVC), Beijing, China, 10–12 July 2020; pp. 171–175. [Google Scholar]
- Tong, W.; Chen, W.; Han, W.; Li, X.; Wang, L. Channel-attention-based DenseNet network for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Ioffe S, S.C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning.pmlr, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Schmitt, M.; Hughes, L.H.; Qiu, C.; Zhu, X.X. SEN12MS–A Curated Dataset of Georeferenced Multi-Spectral Sentinel-1/2 Imagery for Deep Learning and Data Fusion. arXiv 2019, arXiv:1906.07789. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Gray, J.M.; Abercrombie, S.P.; Friedl, M.A. Hierarchical mapping of annual global land cover 2001 to present: The MODIS Collection 6 Land Cover product. Remote Sens. Environ. 2019, 222, 183–194. [Google Scholar] [CrossRef]
- Yokoya, N.; Ghamisi, P.; Xia, J.; Sukhanov, S.; Heremans, R.; Tankoyeu, I.; Bechtel, B.; Le Saux, B.; Moser, G.; Tuia, D. Open data for global multimodal land use classification: Outcome of the 2017 IEEE GRSS data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1363–1377. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Chaudhuri, B.; Demir, B.; Chaudhuri, S.; Bruzzone, L. Multilabel remote sensing image retrieval using a semisupervised graph-theoretic method. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1144–1158. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar] [CrossRef]
- Dembczyński, K.; Waegeman, W.; Cheng, W.; Hüllermeier, E. Regret analysis for performance metrics in multi-label classification: The case of hamming and subset zero-one loss. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2010, Barcelona, Spain, 20–24 September 2010; pp. 280–295. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Prechelt, L. Early stopping-but when. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2002; pp. 55–69. [Google Scholar]
- Schmitt, M.; Wu, Y.L. Remote sensing image classification with the SEN12MS dataset. arXiv 2021, arXiv:2104.00704. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Output Size | DenseNet-121-CBAM |
|---|---|---|
| Convolution | conv, Sride 2 | |
| Pooling | Max pool, Stride 2 | |
| Dense Block 1 | 6 | |
| CBAM Layer 1 | scale | |
| conv | ||
| Transition Layer 1 | Average Pool, Stride 2 | |
| Dense Block 2 | ||
| CBAM Layer 2 | scale | |
| conv | ||
| Transition Layer 2 | Average Pool, Stride 2 | |
| Dense Block 3 | ||
| CBAM Layer 3 | scale | |
| conv | ||
| Transition Layer 3 | Average Pool, Stride 2 | |
| Dense Block 4 | ||
| Classification Layer Fully-connected, sigmoid | Glogal Average Pool |
| Model | Macro-Precision | Macro-Recall | Macro F1 | Hamming-Loss | Subset-Accuracy |
|---|---|---|---|---|---|
| VGG19 | 0.5511 | 0.5625 | 0.5106 | 0.0745 | 0.4769 |
| Resnet50 | 0.5526 | 0.4663 | 0.4779 | 0.0773 | 0.5391 |
| Desnet121 | 0.5614 | 0.6059 | 0.5713 | 0.0610 | 0.5716 |
| Our-model | 0.5764 | 0.5837 | 0.5754 | 0.0589 | 0.5832 |
| Model | Micro-Precision | Micro-Recall | Micro F1 | Micro-Accuracy |
|---|---|---|---|---|
| VGG19 | 0.7167 | 0.7351 | 0.7258 | 0.9254 |
| Resnet50 | 0.7327 | 0.6668 | 0.6981 | 0.9226 |
| Desnet121 | 0.7667 | 0.7842 | 0.7753 | 0.9389 |
| Our-model | 0.7818 | 0.8955 | 0.8348 | 0.9410 |
| Model | Micro-Precision | Micro-Recall | Micro F1 | Hamming-Loss | Accuracy |
|---|---|---|---|---|---|
| VGG16 | 0.91 | 0.93 | 0.86 | 0.031 | 0.885 |
| InceptionV3 | 0.92 | 0.91 | 0.91 | 0.034 | 0.876 |
| Resnet50 | 0.90 | 0.92 | 0.91 | 0.035 | 0.874 |
| Our-model | 0.90 | 0.94 | 0.92 | 0.033 | 0.881 |
| Dataset Test Images | Ground Labels | Predictions | ||
|---|---|---|---|---|
| (a) |  |  | savanna | savanna |
| grassland | water | |||
| wetland | wetland | |||
| cropland | cropland | |||
| water | Urban/built-up | |||
| urban/built-up | ||||
| (b) |  |  | savanna | savanna |
| urban/built-up | Urban/built-up | |||
| cropland | cropland | |||
| (c) |  |  | savannas | savannas |
| forest | forest | |||
| urban/built-up | ||||
| (d) |  | buildings | buildings | |
| cars | cars | |||
| grass | grass | |||
| pavement | pavement | |||
| trees | trees | |||
| (e) |  | buildings | buildings | |
| cars | cars | |||
| court | court | |||
| grass | grass | |||
| trees | trees | |||
| pavement | pavement | |||
| (f) |  | bare-soil | bare-soil | |
| buildings | buildings | |||
| cars | cars | |||
| court | court | |||
| grass | pavement | |||
| pavement | trees | |||
| trees |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, H.; Gu, J.; Jing, W. Multi-Label Remote Sensing Image Land Cover Classification Based on a Multi-Dimensional Attention Mechanism. Remote Sens. 2023, 15, 4979. https://doi.org/10.3390/rs15204979
You H, Gu J, Jing W. Multi-Label Remote Sensing Image Land Cover Classification Based on a Multi-Dimensional Attention Mechanism. Remote Sensing. 2023; 15(20):4979. https://doi.org/10.3390/rs15204979
Chicago/Turabian StyleYou, Haihui, Juntao Gu, and Weipeng Jing. 2023. "Multi-Label Remote Sensing Image Land Cover Classification Based on a Multi-Dimensional Attention Mechanism" Remote Sensing 15, no. 20: 4979. https://doi.org/10.3390/rs15204979
APA StyleYou, H., Gu, J., & Jing, W. (2023). Multi-Label Remote Sensing Image Land Cover Classification Based on a Multi-Dimensional Attention Mechanism. Remote Sensing, 15(20), 4979. https://doi.org/10.3390/rs15204979