

Local Differential Privacy Based Membership-Privacy-Preserving Federated Learning for Deep-Learning-Driven Remote Sensing


Abstract
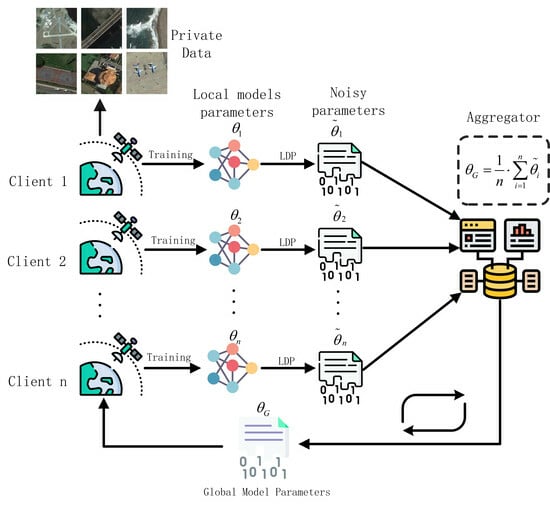
:
1. Introduction
- We propose and implement LDP-Fed to defend against white-box MIAs in the federated learning system on remote sensing, especially for global attacks launched from the central server. It allows participants to collaboratively train DNN models with formal LDP guarantees.
- To achieve optimal privacy-utility trade-offs, we optimize the noise addition method according to the characteristics of white-box MIAs and apply the piecewise mechanism (PM) that is more suitable for the parameters of the DNN models in LDP-Fed. It gives our framework more utility than others while resisting white-box membership inference attacks.
- We extensively evaluate LDP-Fed on various datasets to show the advanced trade-offs of the local participants’ privacy and model utility. For the remote sensing image dataset NWPU-RESISC45 with VGG, it reduced the adversary advantage Adv of global attacks from 46.2% to 10.6% while decreasing the model accuracy by 5.0%.
2. Related Works and Background Techniques
2.1. Related Works
2.1.1. Machine Learning in Remote Sensing
2.1.2. Membership Inference Attack
2.1.3. Defense Mechanism against Membership Inference Attack
2.2. Background Techniques
2.2.1. Federated Learning
2.2.2. Local Differential Privacy
2.2.3. Piecewise Mechanism
2.2.4. Membership Inference Attack in Federated Learning
3. Methodology
3.1. Overview of LDP-Fed
3.1.1. Main Motivation of LDP-Fed
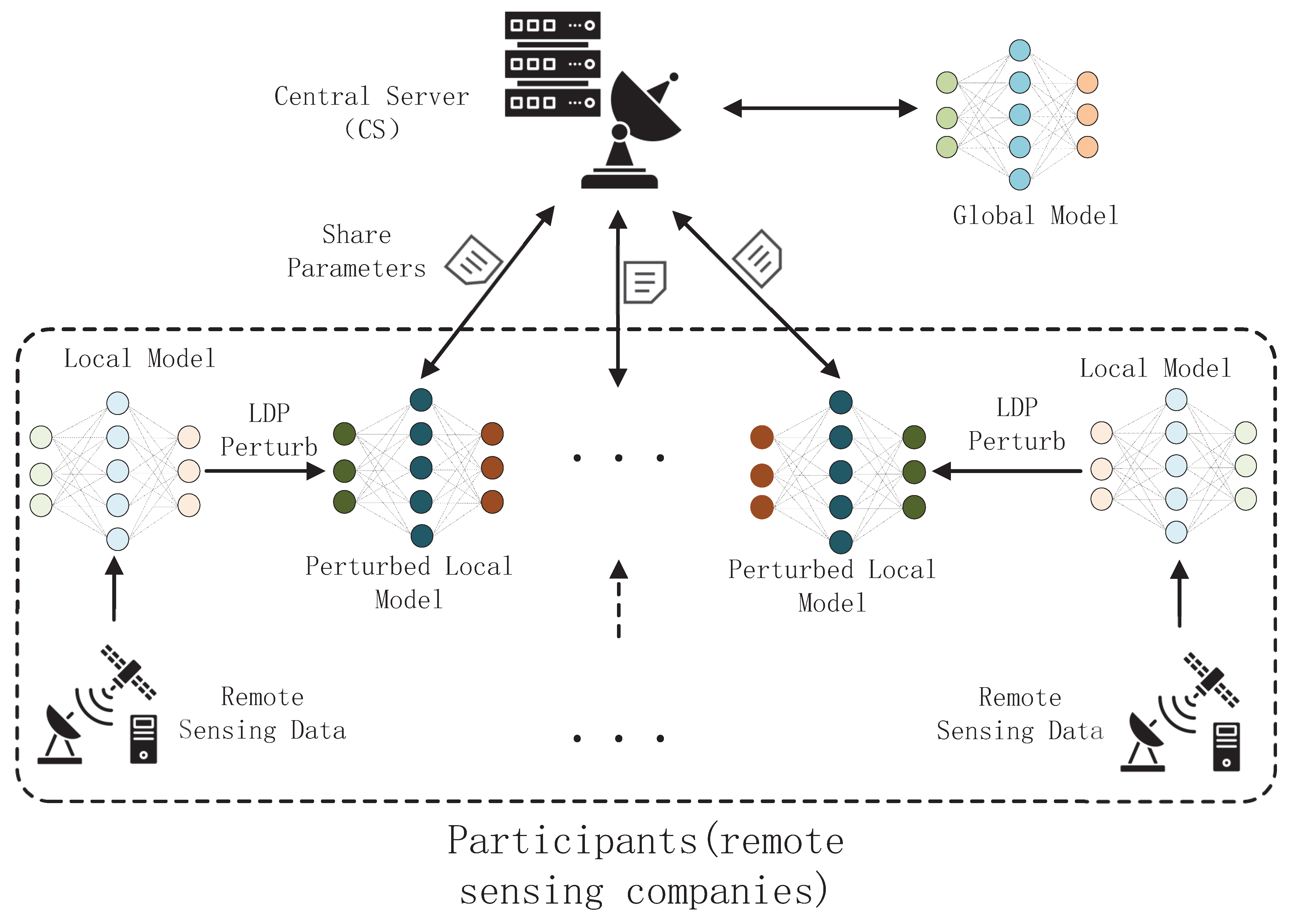
3.1.2. Framework of LDP-Fed
3.1.3. Adversary Model
3.1.4. Privacy Requirement
3.2. Details of LDP-Fed
3.2.1. Federated Learning with LDP
| Algorithm 1: LDP-Fed. |
 |
| Algorithm 2: PM_Perturbation. |
 |
3.2.2. Parameter Norm Clipping
3.2.3. Parameter Perturbation
3.2.4. Privacy Budget Allocation of LDP-Fed
4. Experimental Setup
4.1. Datasets
4.2. Target Model Setting
4.3. Threat Model Setting
4.4. Metrics
5. Experimental Results and Discussion
5.1. Defende against White-Box MIA
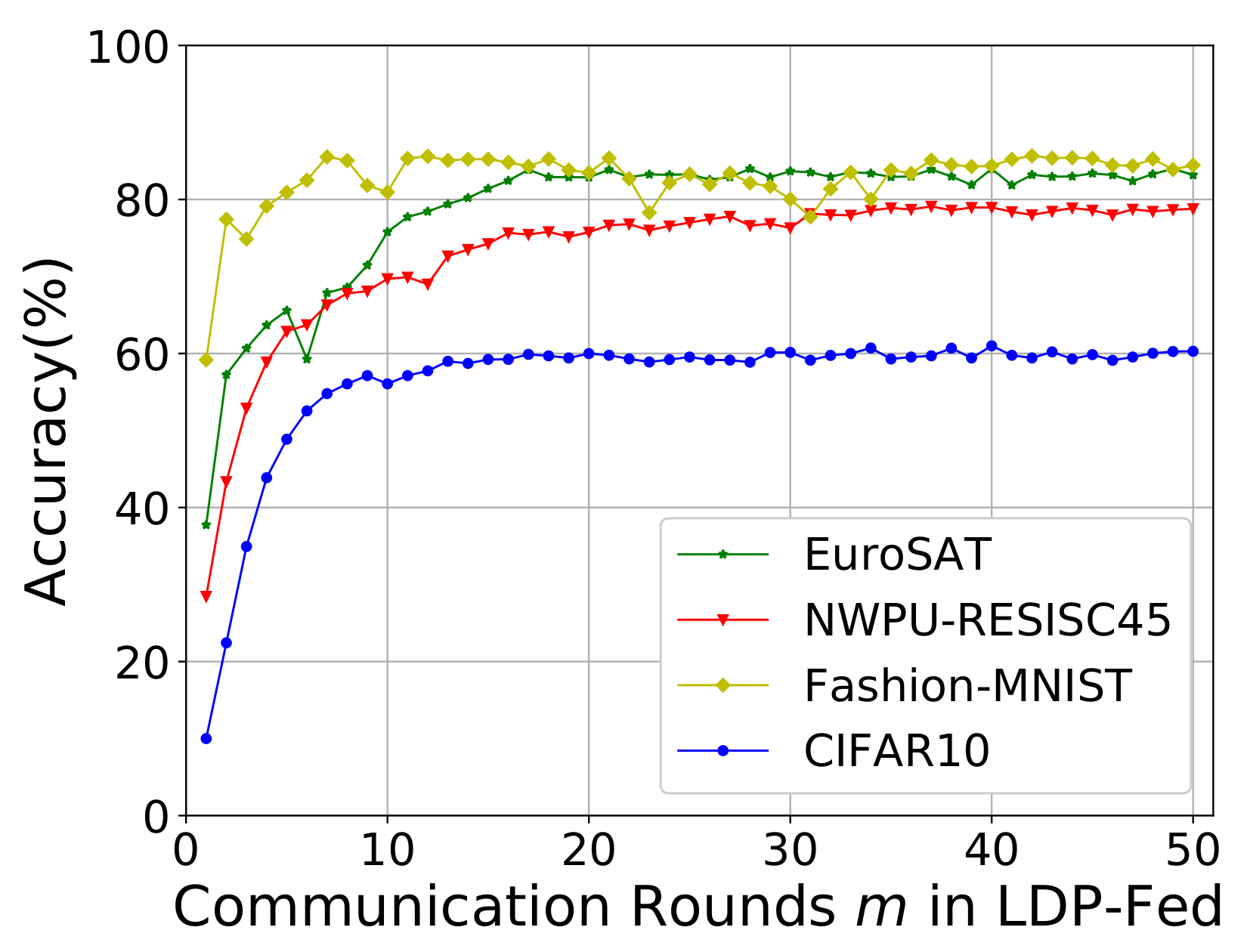
5.2. Hyperarameter of LDP-Fed Analysis
5.3. Performance Comparison
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Thapa, A.; Horanont, T.; Neupane, B.; Aryal, J. Deep Learning for Remote Sensing Image Scene Classification: A Review and Meta-Analysis. Remote. Sens. 2023, 15, 4804. [Google Scholar] [CrossRef]
- Gadamsetty, S.; Ch, R.; Ch, A.; Iwendi, C.; Gadekallu, T.R. Hash-based deep learning approach for remote sensing satellite imagery detection. Water 2022, 14, 707. [Google Scholar] [CrossRef]
- Ma, D.; Wu, R.; Xiao, D.; Sui, B. Cloud Removal from Satellite Images Using a Deep Learning Model with the Cloud-Matting Method. Remote Sens. 2023, 15, 904. [Google Scholar] [CrossRef]
- Devi, N.B.; Kavida, A.C.; Murugan, R. Feature extraction and object detection using fast-convolutional neural network for remote sensing satellite image. J. Indian Soc. Remote Sens. 2022, 50, 961–973. [Google Scholar] [CrossRef]
- Tam, P.; Math, S.; Nam, C.; Kim, S. Adaptive resource optimized edge federated learning in real-time image sensing classifications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10929–10940. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Ruiz-de Azua, J.A.; Garzaniti, N.; Golkar, A.; Calveras, A.; Camps, A. Towards federated satellite systems and internet of satellites: The federation deployment control protocol. Remote Sens. 2021, 13, 982. [Google Scholar] [CrossRef]
- Büyüktaş, B.; Sumbul, G.; Demir, B. Learning Across Decentralized Multi-Modal Remote Sensing Archives with Federated Learning. arXiv 2023, arXiv:2306.00792. [Google Scholar]
- Jia, Z.; Zheng, H.; Wang, R.; Zhou, W. FedDAD: Solving the Islanding Problem of SAR Image Aircraft Detection Data. Remote Sens. 2023, 15, 3620. [Google Scholar] [CrossRef]
- Zhu, J.; Wu, J.; Bashir, A.K.; Pan, Q.; Wu, Y. Privacy-Preserving Federated Learning of Remote Sensing Image Classification with Dishonest-Majority. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4685–4698. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L. Assessing the threat of adversarial examples on deep neural networks for remote sensing scene classification: Attacks and defenses. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1604–1617. [Google Scholar] [CrossRef]
- Bai, T.; Wang, H.; Wen, B. Targeted universal adversarial examples for remote sensing. Remote Sens. 2022, 14, 5833. [Google Scholar] [CrossRef]
- Brewer, E.; Lin, J.; Runfola, D. Susceptibility & defense of satellite image-trained convolutional networks to backdoor attacks. Inf. Sci. 2022, 603, 244–261. [Google Scholar]
- Naseri, M.; Hayes, J.; De Cristofaro, E. Local and central differential privacy for robustness and privacy in federated learning. arXiv 2020, arXiv:2009.03561. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE symposium on security and privacy (SP), IEEE, San Jose, CA, USA, 22–24 May 2017; pp. 3–18. [Google Scholar]
- Jia, J.; Salem, A.; Backes, M.; Zhang, Y.; Zhenqiang Gong, N. MemGuard: Defending against Black-Box Membership Inference Attacks via Adversarial Examples. arXiv 2019, arXiv:1909.10594. [Google Scholar]
- Choquette-Choo, C.A.; Tramer, F.; Carlini, N.; Papernot, N. Label-only membership inference attacks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 1964–1974. [Google Scholar]
- Nasr, M.; Shokri, R.; Houmansadr, A. Machine learning with membership privacy using adversarial regularization. In Proceedings of the the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 634–646. [Google Scholar]
- Li, J.; Li, N.; Ribeiro, B. Membership inference attacks and defenses in classification models. In Proceedings of the the Eleventh ACM Conference on Data and Application Security and Privacy, Virtual, 22 March 2021; pp. 5–16. [Google Scholar]
- Salem, A.; Zhang, Y.; Humbert, M.; Berrang, P.; Fritz, M.; Backes, M. ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models. In Proceedings of the 26th Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 24–27 February 2019. [Google Scholar]
- Shejwalkar, V.; Houmansadr, A. Membership privacy for machine learning models through knowledge transfer. In Proceedings of the the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 9549–9557. [Google Scholar]
- Tang, X.; Mahloujifar, S.; Song, L.; Shejwalkar, V.; Nasr, M.; Houmansadr, A.; Mittal, P. Mitigating membership inference attacks by self-distillation through a novel ensemble architecture. arXiv 2021, arXiv:2110.08324. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Jayaraman, B.; Evans, D. Evaluating differentially private machine learning in practice. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 1895–1912. [Google Scholar]
- Xie, Y.; Chen, B.; Zhang, J.; Wu, D. Defending against Membership Inference Attacks in Federated learning via Adversarial Example. In Proceedings of the 2021 17th International Conference on Mobility, Sensing and Networking (MSN) IEEE, Exeter, UK, 13–15 December 2021; pp. 153–160. [Google Scholar]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), IEEE, Santa Clara, CA, USA, 20–22 May 2019; pp. 739–753. [Google Scholar]
- Truex, S.; Liu, L.; Chow, K.H.; Gursoy, M.E.; Wei, W. LDP-Fed: Federated learning with local differential privacy. In Proceedings of the the Third ACM International Workshop on Edge Systems, Analytics and Networking, Heraklion, Greece, 27 April 2020; pp. 61–66. [Google Scholar]
- Sun, L.; Qian, J.; Chen, X. Ldp-fl: Practical private aggregation in federated learning with local differential privacy. arXiv 2020, arXiv:2007.15789. [Google Scholar]
- Fadlullah, Z.M.; Kato, N. On smart IoT remote sensing over integrated terrestrial-aerial-space networks: An asynchronous federated learning approach. IEEE Netw. 2021, 35, 129–135. [Google Scholar] [CrossRef]
- Chhikara, P.; Tekchandani, R.; Kumar, N.; Tanwar, S. Federated learning-based aerial image segmentation for collision-free movement and landing. In Proceedings of the the 4th ACM MobiCom Workshop on Drone Assisted Wireless Communications for 5G and Beyond, Virtual, 29 October 2021; pp. 13–18. [Google Scholar]
- Lee, W. Federated reinforcement learning-based UAV swarm system for aerial remote sensing. Wirel. Commun. Mob. Comput. 2022, 2022, 4327380. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L. Artificial intelligence for remote sensing data analysis: A review of challenges and opportunities. IEEE Geosci. Remote Sens. Mag. 2022, 10, 270–294. [Google Scholar] [CrossRef]
- Geiß, C.; Pelizari, P.A.; Blickensdörfer, L.; Taubenböck, H. Virtual support vector machines with self-learning strategy for classification of multispectral remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2019, 151, 42–58. [Google Scholar] [CrossRef]
- Wang, X.; Gao, X.; Zhang, Y.; Fei, X.; Chen, Z.; Wang, J.; Zhang, Y.; Lu, X.; Zhao, H. Land-cover classification of coastal wetlands using the RF algorithm for Worldview-2 and Landsat 8 images. Remote Sens. 2019, 11, 1927. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef]
- Li, Y.; Chen, R.; Zhang, Y.; Zhang, M.; Chen, L. Multi-label remote sensing image scene classification by combining a convolutional neural network and a graph neural network. Remote Sens. 2020, 12, 4003. [Google Scholar] [CrossRef]
- Tang, X.; Ma, Q.; Zhang, X.; Liu, F.; Ma, J.; Jiao, L. Attention consistent network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2030–2045. [Google Scholar] [CrossRef]
- Chen, J.; Guo, Y.; Zhu, J.; Sun, G.; Qin, D.; Deng, M.; Liu, H. Improving Few-Shot Remote Sensing Scene Classification with Class Name Semantics. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Yeom, S.; Giacomelli, I.; Fredrikson, M.; Jha, S. Privacy Risk in Machine Learning: Analyzing the Connection to Overfitting. In Proceedings of the 2018 IEEE 31st Computer Security Foundations Symposium (CSF), Oxford, UK, 9–12 July 2018; pp. 268–282. [Google Scholar]
- Song, L.; Mittal, P. Systematic evaluation of privacy risks of machine learning models. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Virtual, 11–13 August 2021; pp. 2615–2632. [Google Scholar]
- Carlini, N.; Chien, S.; Nasr, M.; Song, S.; Terzis, A.; Tramer, F. Membership inference attacks from first principles. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), IEEE, Santa Clara, CA, USA, 23–25 May 2022; pp. 1897–1914. [Google Scholar]
- Liu, P.; Xu, X.; Wang, W. Threats, attacks and defenses to federated learning: Issues, taxonomy and perspectives. Cybersecurity 2022, 5, 4. [Google Scholar]
- Kaya, Y.; Dumitras, T. When does data augmentation help with membership inference attacks? In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 5345–5355. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zheng, J.; Cao, Y.; Wang, H. Resisting membership inference attacks through knowledge distillation. Neurocomputing 2021, 452, 114–126. [Google Scholar] [CrossRef]
- Cynthia, D. Differential privacy. In Automata, Languages and Programming; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–12. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Aguera y Arcas, B. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Wang, N.; Xiao, X.; Yang, Y.; Zhao, J.; Hui, S.C.; Shin, H.; Shin, J.; Yu, G. Collecting and Analyzing Multidimensional Data with Local Differential Privacy. arXiv 2019, arXiv:1907.00782. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Theory of Cryptography Conference, New York, NY, USA, 4–7 March 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Duchi, J.C.; Jordan, M.I.; Wainwright, M.J. Minimax optimal procedures for locally private estimation. J. Am. Stat. Assoc. 2018, 113, 182–201. [Google Scholar] [CrossRef]
- Sablayrolles, A.; Douze, M.; Schmid, C.; Ollivier, Y.; Jégou, H. White-box vs black-box: Bayes optimal strategies for membership inference. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5558–5567. [Google Scholar]
- Chen, D.; Yu, N.; Fritz, M. Relaxloss: Defending membership inference attacks without losing utility. arXiv 2022, arXiv:2207.05801. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- McSherry, F.; Talwar, K. Mechanism design via differential privacy. In Proceedings of the 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07), IEEE, Washington, DC, USA, 21–23 October 2007; pp. 94–103. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2009. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Geyer, R.C.; Klein, T.; Nabi, M. Differentially private federated learning: A client level perspective. arXiv 2017, arXiv:1712.07557. [Google Scholar]
- Bhowmick, A.; Duchi, J.; Freudiger, J.; Kapoor, G.; Rogers, R. Protection against reconstruction and its applications in private federated learning. arXiv 2018, arXiv:1812.00984. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function/Method | [16] | [20] | [22] | [24] | LDP-Fed |
|---|---|---|---|---|---|
| Data Type | Arbitrary | Image | Arbitrary | Arbitrary | Arbitrary |
| Federated Learning | ✕ | ✓ | ✓ | ✓ | ✓ |
| Defend against white-box MIA | ✕ | ✕ | ✓ | ✓ | ✓ |
| Defend against black-box MIA | ✓ | ✓ | ✓ | ✓ | ✓ |
| Defense Mechanism | Confidence Masking | Mixup Regularization | Knowledge Distillation | DP-SGD | LDP |
| Model Performance | High | High | High | Low | High |
| Efficiency of Training | High | Low | Low | High | High |
| Dataset | Architecture | Training Size | Testing Size |
|---|---|---|---|
| EuroSAT | Convolutional Neural Network | 15,000 | 12,000 |
| NWPU-RESISC45 | Convolutional Neural Network(VGG) | 20,000 | 10,000 |
| Fashion-MNIST | Fully Connected Network | 60,000 | 10,000 |
| CIFAR10 | Convolutional Neural Network(Alexnet) | 50,000 | 10,000 |
| Datesets | Client’s Datasets Size | Attack Model Datasets Size | ||||
|---|---|---|---|---|---|---|
| Training | Testing | Training Member | Training Non-Member | Testing Member | Testing Non-Member | |
| EuroSAT | 5000 | 5000 | 2500 | 2500 | 2500 | 2500 |
| NWPU-RESISC45 | 10,000 | 10,000 | 5000 | 5000 | 5000 | 5000 |
| Fashion-MNIST | 5000 | 10,000 | 2500 | 2500 | 2500 | 2500 |
| CIFAR10 | 15,000 | 10,000 | 10,000 | 5000 | 5000 | 5000 |
| Defense | Dateset | Privacy Budget | Acc. | Global Att. | Local Att. |
|---|---|---|---|---|---|
| No Defense | EuroSAT | - | 89.2% | 46.4% | 25.8% |
| CIFAR10 | - | 62.1% | 44.6% | 26.3% | |
| NWPU-RESISC45 | - | 83.5% | 46.2% | 28.4% | |
| Fashion-MNIST | - | 86.5% | 24.5% | 12.5% | |
| Defense with LDP | EuroSAT | 3.0 | 82.5% | 13.8% | 17.6% |
| CIFAR10 | 2.0 | 59.6% | 12.2% | 18.4% | |
| NWPU-RESISC45 | 5.0 | 77.9% | 10.6% | 18.6% | |
| Fashion-MNIST | 2.0 | 83.6% | 4.6% | 8.2% |
| Defense Method | Privacy Budget | Model Acc. | Global Att. | Local Att. |
|---|---|---|---|---|
| No Defense | - | 62.1% | 44.6% | 26.3% |
| LDP-Fed | 2.0 | 59.6% | 12.2% | 18.4% |
| DP-SGD | 2.0 | 42.3% | 5.8% | 4.2% |
| 8.6 | 54.6% | 13.6% | 12.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Ma, X.; Ma, J. Local Differential Privacy Based Membership-Privacy-Preserving Federated Learning for Deep-Learning-Driven Remote Sensing. Remote Sens. 2023, 15, 5050. https://doi.org/10.3390/rs15205050
Zhang Z, Ma X, Ma J. Local Differential Privacy Based Membership-Privacy-Preserving Federated Learning for Deep-Learning-Driven Remote Sensing. Remote Sensing. 2023; 15(20):5050. https://doi.org/10.3390/rs15205050
Chicago/Turabian StyleZhang, Zheng, Xindi Ma, and Jianfeng Ma. 2023. "Local Differential Privacy Based Membership-Privacy-Preserving Federated Learning for Deep-Learning-Driven Remote Sensing" Remote Sensing 15, no. 20: 5050. https://doi.org/10.3390/rs15205050
APA StyleZhang, Z., Ma, X., & Ma, J. (2023). Local Differential Privacy Based Membership-Privacy-Preserving Federated Learning for Deep-Learning-Driven Remote Sensing. Remote Sensing, 15(20), 5050. https://doi.org/10.3390/rs15205050