
A Generic Self-Supervised Learning (SSL) Framework for Representation Learning from Spectral–Spatial Features of Unlabeled Remote Sensing Imagery



Abstract
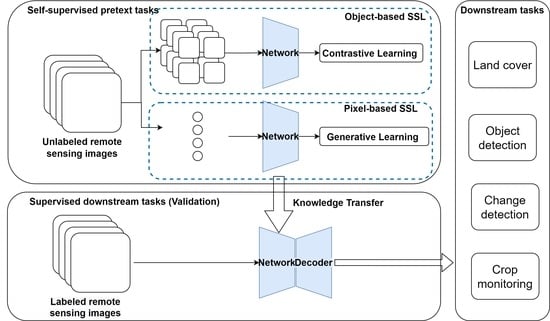
:
1. Introduction
- 1.
- We propose a generic SSL framework for both pixel-based and object-based remote sensing applications. Two pretext tasks are proposed. One is used to reconstruct the spectral profile from the masked data, which can be used to extract a representation of pixel information and improve the performance of downstream tasks associated with pixel-based analysis. The other pretext task can be used to identify objects from multiple views of the same object on multispectral data. These multiple views, including global views, local views, and innovative spectral views, are derived from extensive spatial and spectral transformations of the data to allow the model to learn representations from the spatial–spectral information of the data. These representations can be used to improve the performance of downstream tasks associated with object-based analysis;
- 2.
- We demonstrate that the proposed SSL framework is a novel way to learn representations from unlabeled large-scale remote sensing data. This proposed SSL method is applied to two downstream tasks on large multispectral and hyperspectral remote sensing datasets. One is a multilabel land cover classification on Sentinel-2 multispectral datasets and the other is a ground soil parameter retrieval on hyperspectral datasets. We also compare the proposed methods with existing SSL frameworks. The results show that the proposed SSL method emphasizes the spectral and spatial features in remote sensing data with higher performance than the three other methods tested;
- 3.
- We analyze the impact of spatial–spectral features on the performance of the proposed SSL framework and visualize the features learned through SSL, which contribute to a deeper understanding of what would make a self-supervised feature representation useful for remote sensing data analysis.
2. Related Work
2.1. Remote Sensing Analysis Methods
2.2. Self-Supervised Learning on Remote Sensing (SSL)
3. The Proposed Method
- 1.
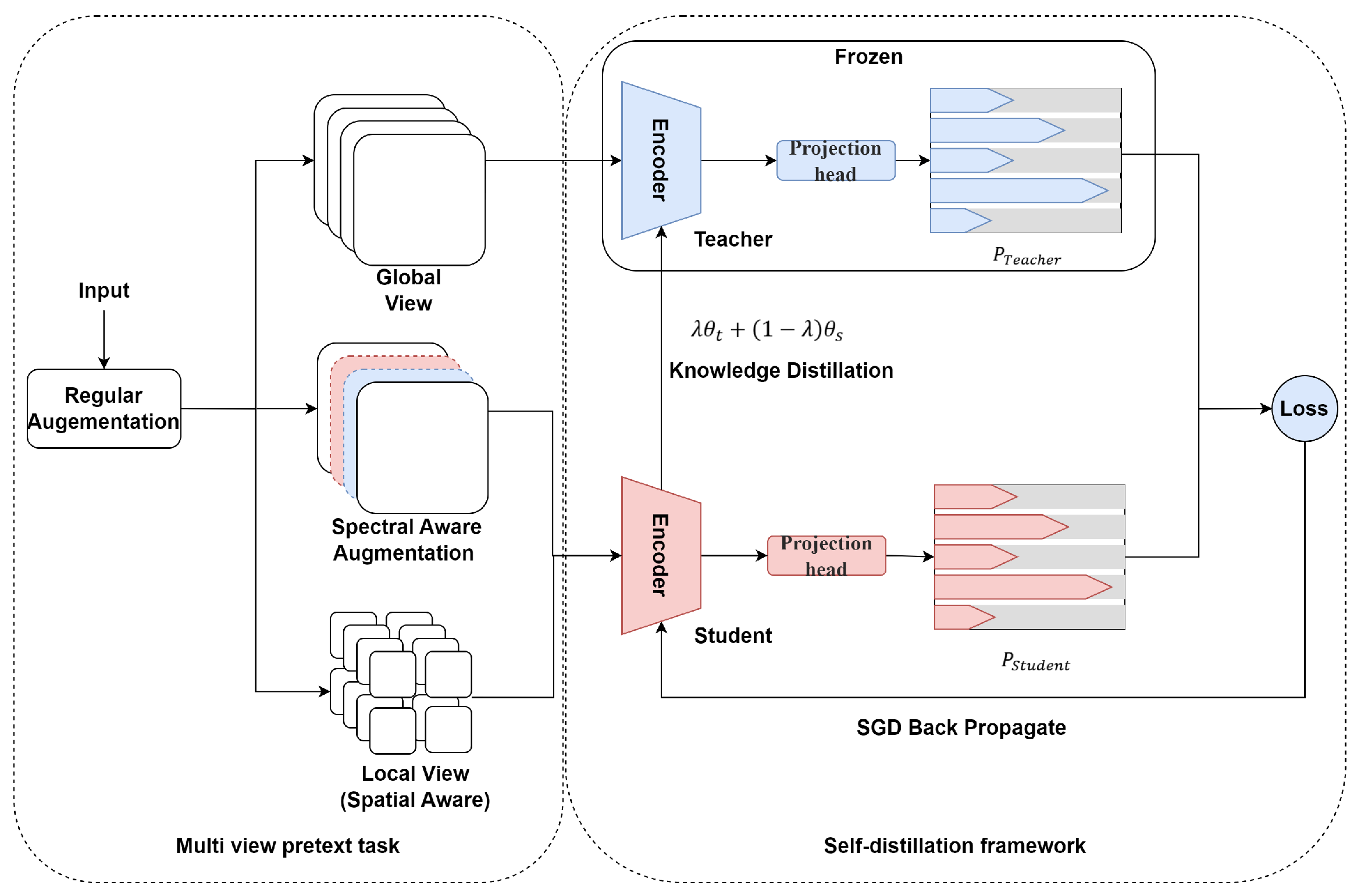
- The object-based SSL method (ObjSSL) employs contrastive learning. This method is suitable for extracting features from high- to very-high-spatial-resolution remote sensing data. ObjSSL employs a joint spatial–spectral-aware multiview pretext task, which is a classification problem. It uses cross-entropy loss to measure how well the network can classify the representation among a set of multiviews of a single target.
- 2.
- The pixel-based SSL method (PixSSL) employs generative learning and is suitable for low- to medium-spatial-resolution images. We propose a spectral-aware pretext task for reconstructing the original spectral profile. A spectral masked, auto encoder–decoder is designed to learn meaningful latent representations.
3.1. Object-Based SSL (ObjSSL)
- 1.
- A novel multi-view pretext task that generates positive pairs for ObjSSL by generating different views of remote sensing data from both the spectral and spatial perspectives. This is a composition of multiple data augmentation operations, including spectral aware augmentation, regular augmentation, and local and global augmentation.
- 2.
- A self-distillation framework that uses two networks, a student network and a teacher network, to learn the representation from multiviews of the data. The student network is trained to match the output of a given teacher network.
3.1.1. Multiview Pretext Task
Regular Augmentation
Local and Global (LaG) Augmentation
Spectral Aware Augmentation
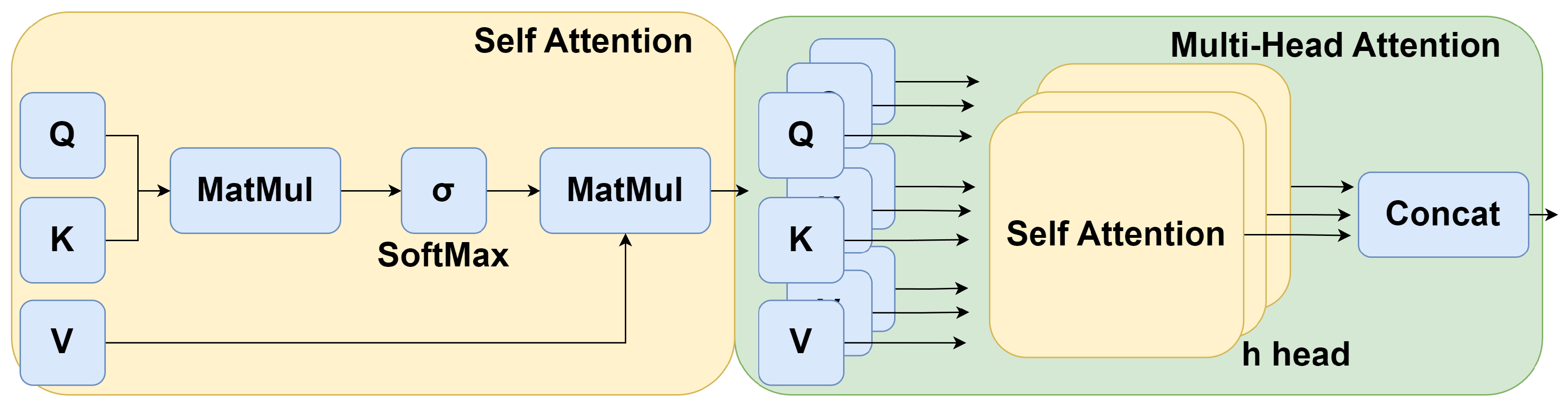
3.1.2. Self-Distillation Framework
| Algorithm 1 Object-Based SSL algorithm |
| Input: : One batch images; T: Teacher Network; S: Student Network; 1: set ; 2: set # Frozen Teacher’s params; 3: for x in do # One batch training 4: # Global view with regular augmentation 5: # Local view with regular augmentation 6: # Spectral mask with regular augmentation 7: 8: 9: # 10: loss.backward() # Back-propagate 11: Update(S.params) # Student params update by SGD 12: # Teacher params update by knowledge distillation 13: 14: 15: 16: loss.backward() 17: Update(S.params) 18: 19: end for |
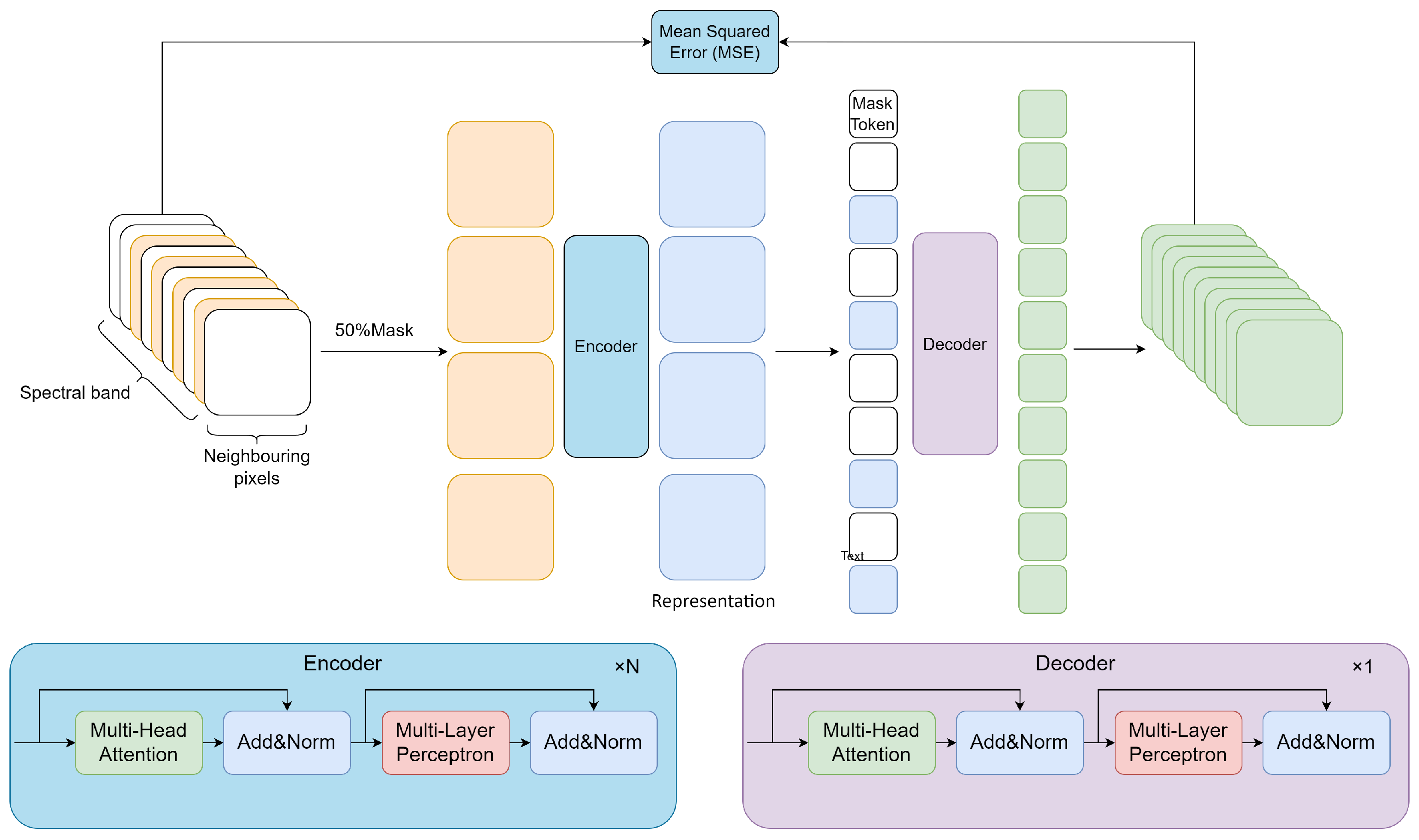
3.2. Pixel-Based SSL (PixSSL)
- 1.
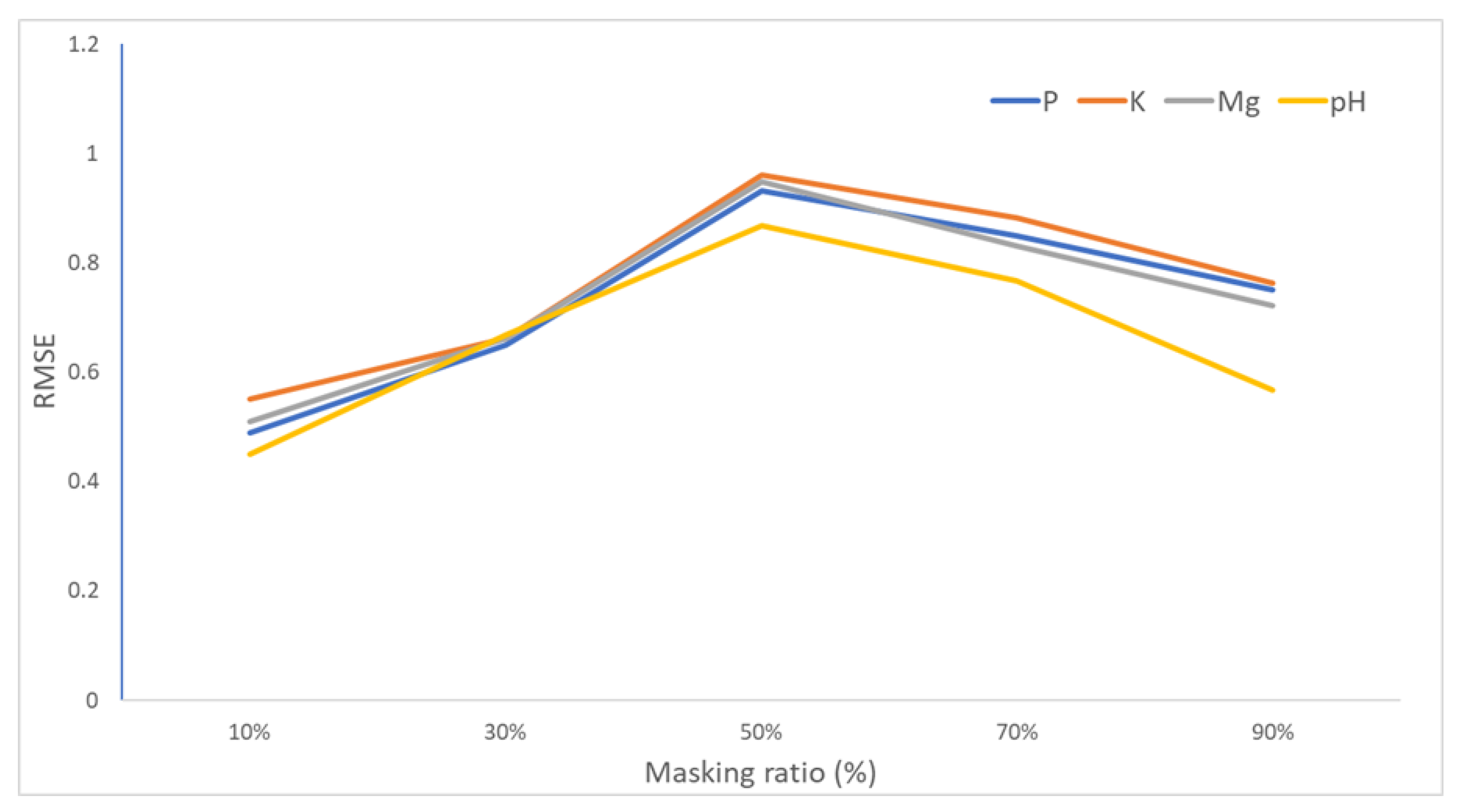
- To ensure that the relationships and relative positions of the different spectral channels remain unchanged, a spectral reconstructive pretext task is introduced to recover each pixel’s spectral profile from masked data. Based on our experiments, we find that masking 50% of the spectral information yields a meaningful self-supervisory task.
- 2.
- An encoder–decoder architecture is designed to perform this pretext task. The encoder is used to generate meaningful latent representation and the decoder is used to recover the masked spectral profile.
- 3.
- Pixel-based analysis methods require processing every pixel within an image, which significantly increases the amount of computation. To optimize computational efficiency, our proposed encoder can operate on a subset of the spectral data (masked data) to reduce the data input. Meanwhile, the aim of the SSL is to train an encoder to generate meaningful latent representations for downstream tasks. Therefore, we only added a lightweight decoder that reconstructs the spectral profile to reduce computational consumption.
| Algorithm 2 Pixel-Based SSL algorithm |
| Input: : One batch pixels; E: Encoder Network; D: Decoder Network; 1: for x in do # One batch training 2: # Mask random spectrum, mask means masked data 3: # Forward Encoder 4: Restore the maksed data 5: # Forward Decoder 6: 7: loss.backward() # Back-propagate 8: Update(S.params) #params update 9: end for |
3.2.1. Spectral Reconstructive Pretext Task
3.2.2. The Spectral Masked Auto Encoder–Decoder Network
Encoder
Decoder
4. Experiments Evaluation
4.1. ObjSSL Performance Evaluation
- 1.
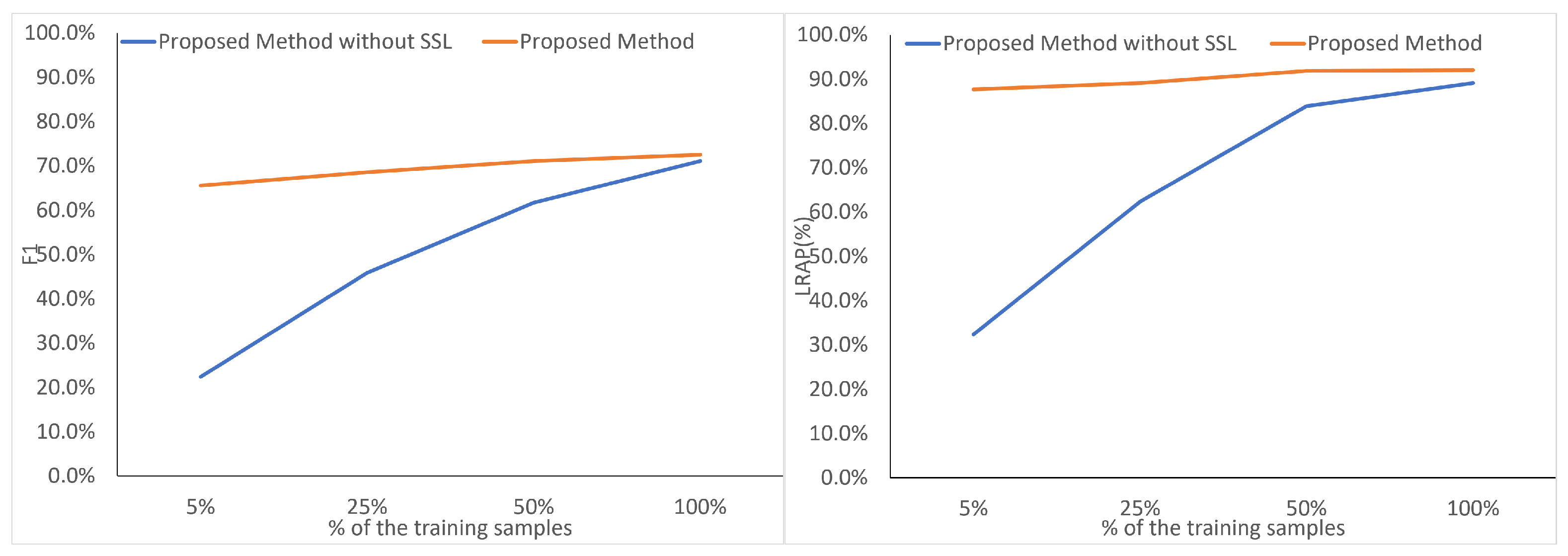
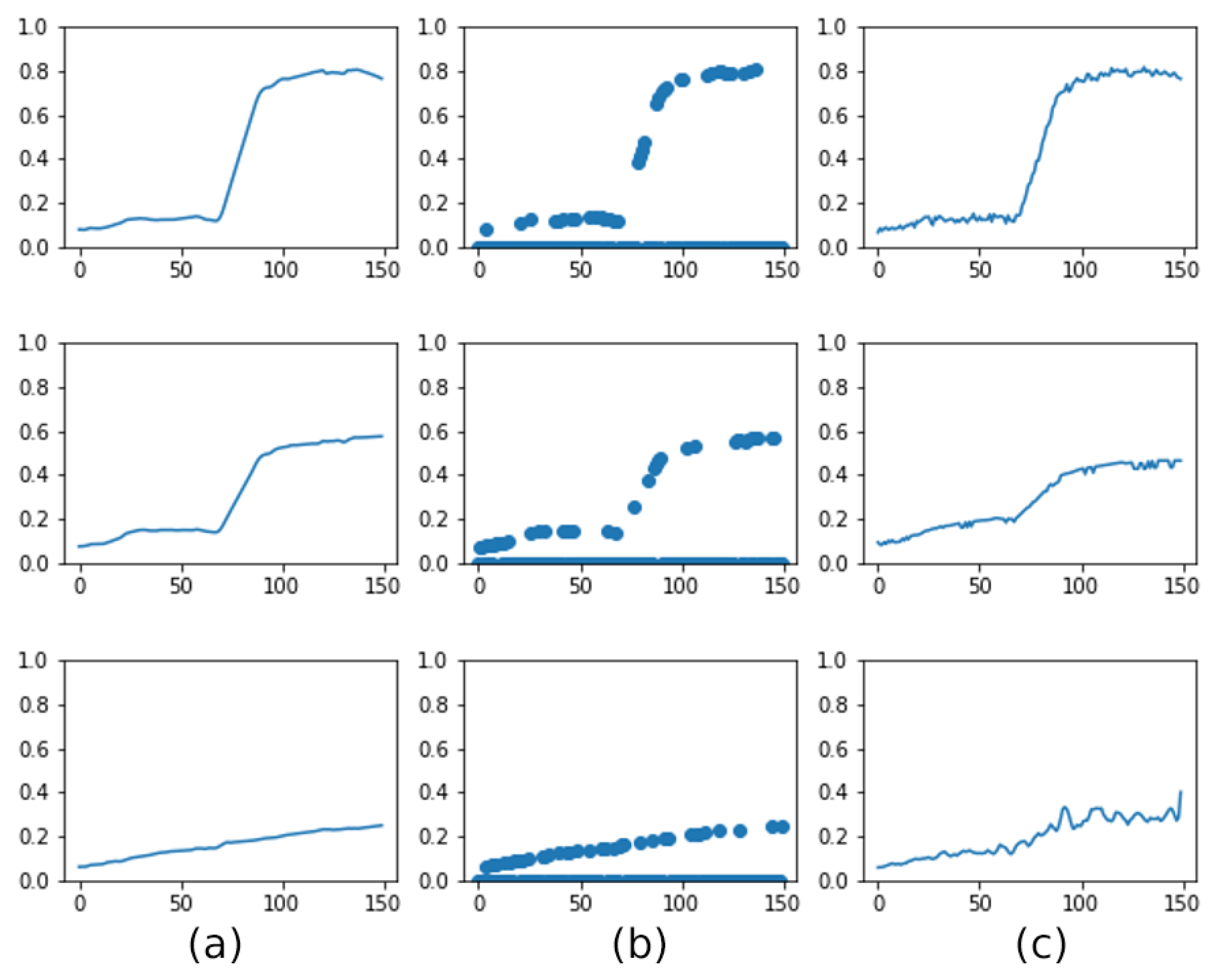
- Sensitivity Analysis of the Proposed Approach. In this experiment, we analyze the sensitivity of the proposed approach under different settings and strategies. Firstly, we analyze downstream task performance with and without the spectral-aware and LaG data augmentations to evaluate the impact of the designed pretext task. Then, we report the model performance with 5%, 25%, 50%, and 100% of the training data with and without SSL to demonstrate the effect of SSL on the supervised classification task.
- 2.
- 3.
4.1.1. Data Collection
4.1.2. Evaluation Metrics
4.1.3. Experimental Setup
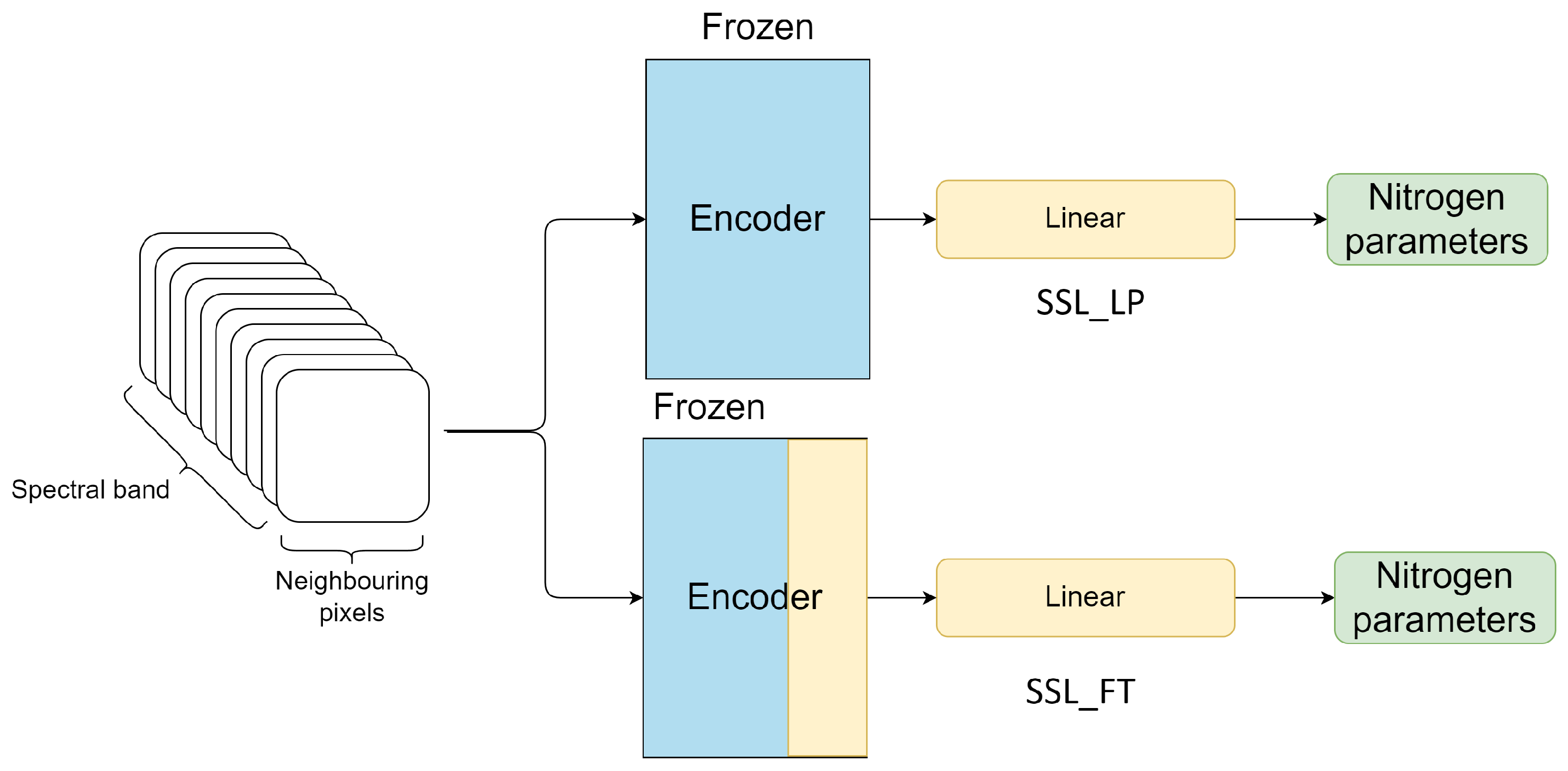
4.2. PixSSL Performance Evaluation
4.2.1. Data Collection
4.2.2. Experimental Setup
5. Results
5.1. ObjSSL Performance
5.1.1. Sensitivity Analysis of the Proposed Approach
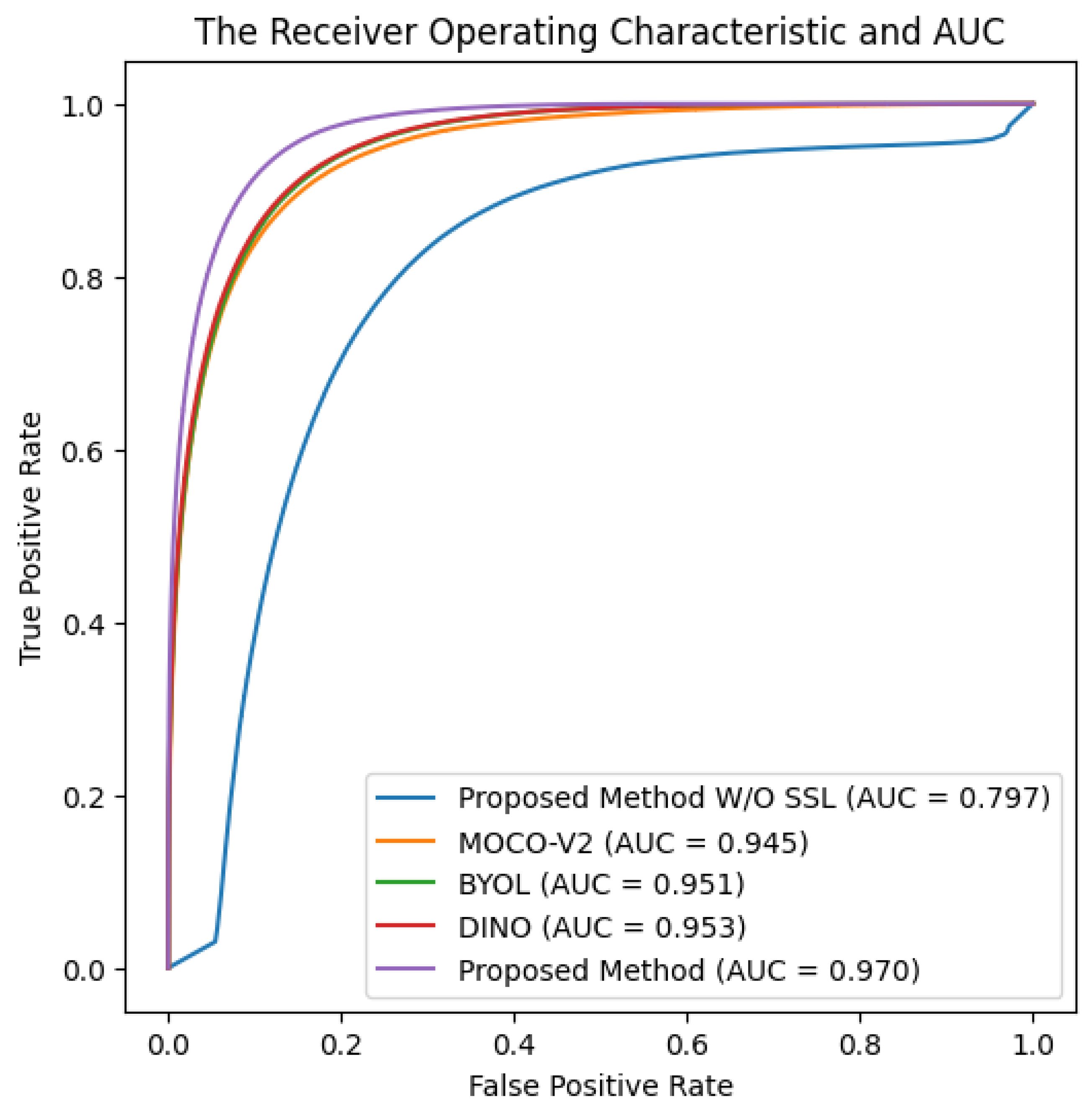
5.1.2. Comparison with Existing SSL Frameworks
5.1.3. Comparison with Existing Networks
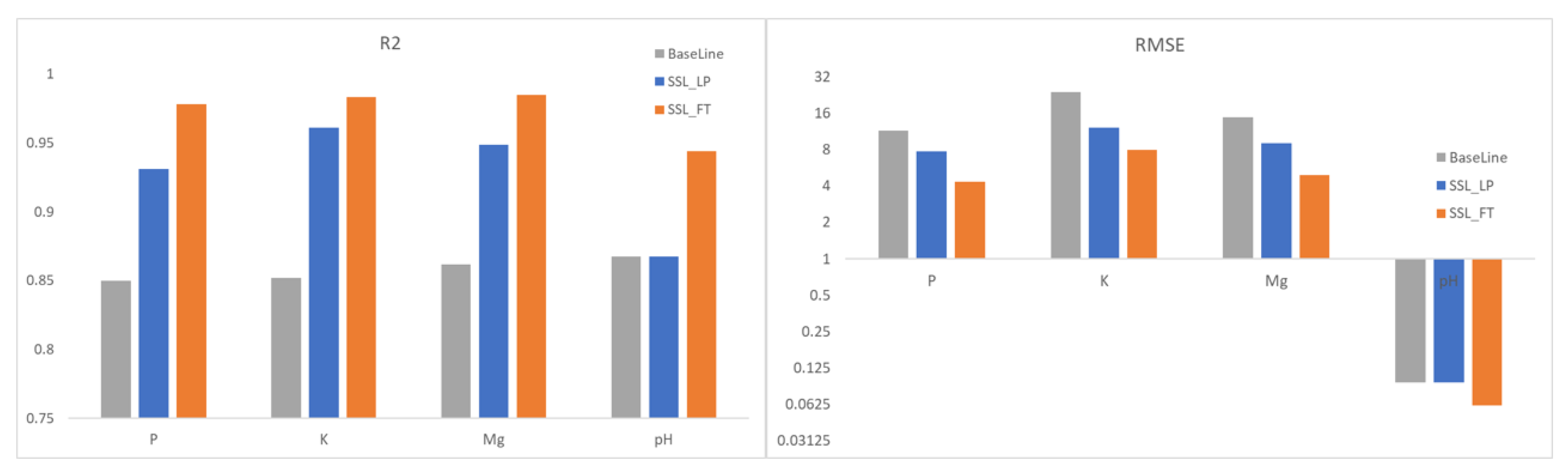
5.2. PixSSL Performance
6. Discussion
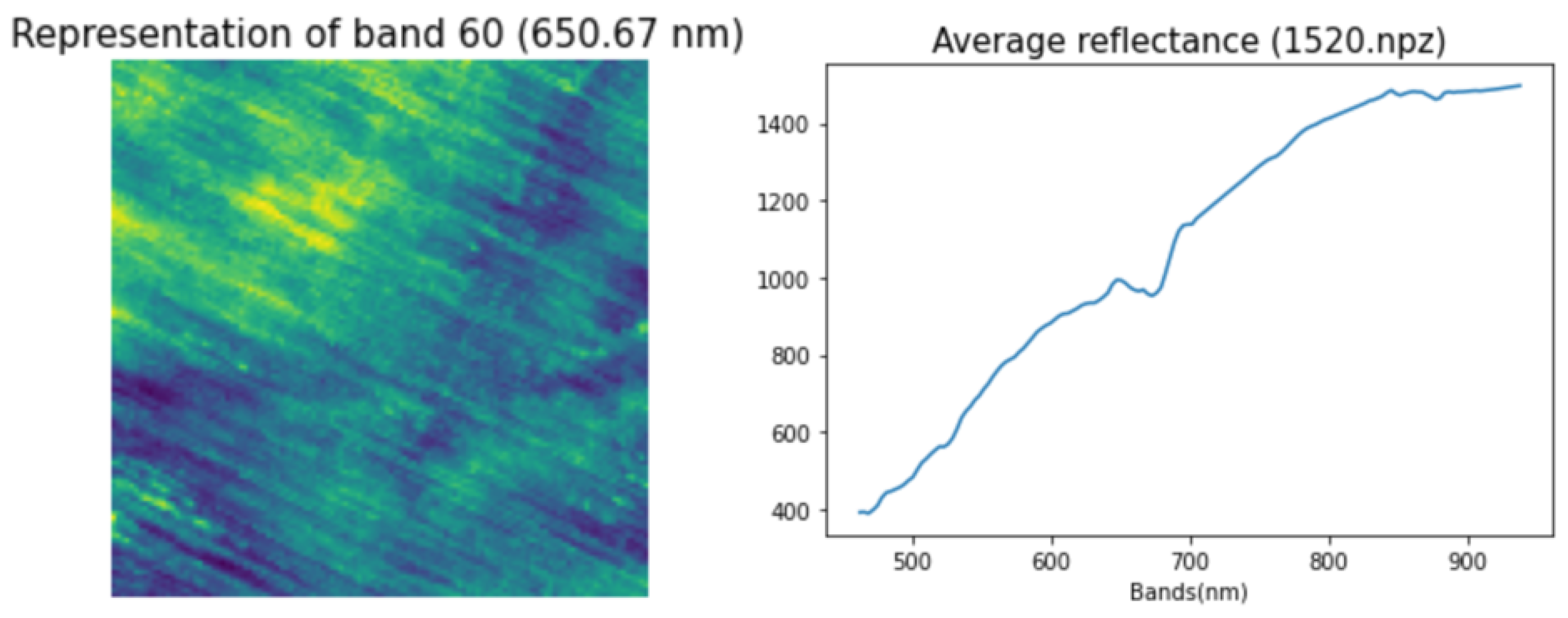
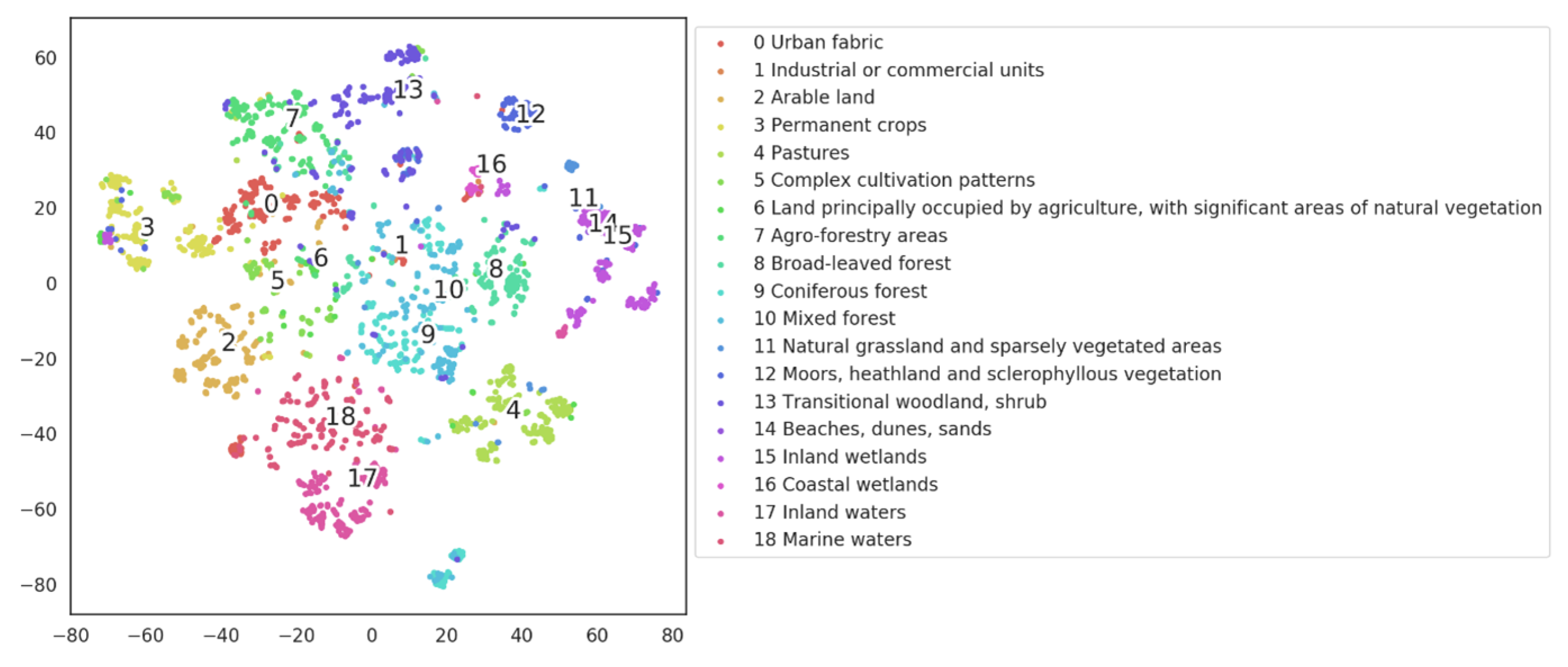
6.1. The Representation of ObjSSL
6.2. The Representation of PixSSL
6.3. Challenges and Future Directions
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ban, Y.; Gong, P.; Giri, C. Global Land Cover Mapping Using Earth Observation Satellite Data: Recent Progresses and Challenges. ISPRS J. Photogramm. Remote Sens. 2015, 103, 1–6. [Google Scholar] [CrossRef]
- Li, D.; Zhang, P.; Chen, T.; Qin, W. Recent Development and Challenges in Spectroscopy and Machine Vision Technologies for Crop Nitrogen Diagnosis: A Review. Remote Sens. 2020, 12, 2578. [Google Scholar] [CrossRef]
- Osco, L.P.; Marcato Junior, J.; Marques Ramos, A.P.; de Castro Jorge, L.A.; Fatholahi, S.N.; de Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A review on deep learning in UAV remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Ghamisi, P.; Plaza, J.; Chen, Y.; Li, J.; Plaza, A.J. Advanced Spectral Classifiers for Hyperspectral Images: A review. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–32. [Google Scholar] [CrossRef]
- Richards, J.A. Remote Sensing Digital Image Analysis; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Chen, G.; Weng, Q.; Hay, G.J.; He, Y. Geographic object-based image analysis (GEOBIA): Emerging trends and future opportunities. GISci. Remote Sens. 2018, 55, 159–182. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Environ. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Safari, A.; Sohrabi, H.; Powell, S.; Shataee, S. A comparative assessment of multi-temporal Landsat 8 and machine learning algorithms for estimating aboveground carbon stock in coppice oak forests. Int. J. Remote Sens. 2017, 38, 6407–6432. [Google Scholar] [CrossRef]
- Singh, C.; Karan, S.K.; Sardar, P.; Samadder, S.R. Remote sensing-based biomass estimation of dry deciduous tropical forest using machine learning and ensemble analysis. J. Environ. Manag. 2022, 308, 114639. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Zhang, X.; Han, L.; Han, L.; Zhu, L. How Well Do Deep Learning-Based Methods for Land Cover Classification and Object Detection Perform on High Resolution Remote Sensing Imagery? Remote Sens. 2020, 12, 417. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Chan, C.S. A Comprehensive Survey of Deep Learning in Remote Sensing: Theories, Tools and Challenges for the Community. J. Appl. Remote Sens. 2017, 11, 1. [Google Scholar] [CrossRef]
- Romero, A.; Gatta, C.; Camps-Valls, G. Unsupervised Deep Feature Extraction for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1349–1362. [Google Scholar] [CrossRef]
- Hatano, T.; Tsuneda, T.; Suzuki, Y.; Shintani, K.; Yamane, S. Image Classification with Additional Non-decision Labels using Self-supervised learning and GAN. In Proceedings of the IEEE 2020 Eighth International Symposium on Computing and Networking Workshops (CANDARW), Naha, Japan, 24–27 November 2020; pp. 125–129. [Google Scholar]
- Li, Y.; Chen, J.; Zheng, Y. A multi-task self-supervised learning framework for scopy images. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 2005–2009. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Leiter, C.; Zhang, R.; Chen, Y.; Belouadi, J.; Larionov, D.; Fresen, V.; Eger, S. ChatGPT: A Meta-Analysis after 2.5 Months. arXiv 2023, arXiv:2302.13795. [Google Scholar] [CrossRef]
- Misra, I.; van der Maaten, L. Self-supervised learning of pretext-invariant representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6707–6717. [Google Scholar]
- Mitash, C.; Bekris, K.E.; Boularias, A. A self-supervised learning system for object detection using physics simulation and multi-view pose estimation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 545–551. [Google Scholar]
- Alosaimi, N.; Alhichri, H.; Bazi, Y.; Ben Youssef, B.; Alajlan, N. Self-supervised learning for remote sensing scene classification under the few shot scenario. Sci. Rep. 2023, 13, 433. [Google Scholar] [CrossRef]
- Tao, C.; Qi, J.; Lu, W.; Wang, H.; Li, H. Remote Sensing Image Scene Classification With Self-Supervised Paradigm Under Limited Labeled Samples. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhao, Z.; Luo, Z.; Li, J.; Chen, C.; Piao, Y. When Self-Supervised Learning Meets Scene Classification: Remote Sensing Scene Classification Based on a Multitask Learning Framework. Remote Sens. 2020, 12, 3276. [Google Scholar] [CrossRef]
- Dong, H.; Ma, W.; Wu, Y.; Zhang, J.; Jiao, L. Self-Supervised Representation Learning for Remote Sensing Image Change Detection Based on Temporal Prediction. Remote Sens. 2020, 12, 1868. [Google Scholar] [CrossRef]
- Zhang, X.; Han, L.; Sobeih, T.; Lappin, L.; Lee, M.A.; Howard, A.; Kisdi, A. The Self-Supervised Spectral–Spatial Vision Transformer Network for Accurate Prediction of Wheat Nitrogen Status from UAV Imagery. Remote Sens. 2022, 14, 1400. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. arXiv 2021, arXiv:2111.06377. [Google Scholar]
- Komodakis, N.; Gidaris, S. Unsupervised representation learning by predicting image rotations. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Imani, M.; Ghassemian, H. An overview on spectral and spatial information fusion for hyperspectral image classification: Current trends and challenges. Inf. Fusion 2020, 59, 59–83. [Google Scholar] [CrossRef]
- Fauvel, M.; Chanussot, J.; Benediktsson, J.A.; Sveinsson, J.R. Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–27 July 2007; pp. 4834–4837. [Google Scholar] [CrossRef]
- Lee, W.; Park, B.; Han, K. Svm-based classification of diffusion tensor imaging data for diagnosing alzheimer’s disease and mild cognitive impairment. In Proceedings of the International Conference on Intelligent Computing, Harbin, China, 17–18 January 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 489–499. [Google Scholar]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Chasmer, L.; Hopkinson, C.; Veness, T.; Quinton, W.; Baltzer, J. A decision-tree classification for low-lying complex land cover types within the zone of discontinuous permafrost. Remote Sens. Environ. 2014, 143, 73–84. [Google Scholar] [CrossRef]
- Friedl, M.A.; Brodley, C.E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Chan, C.S. Special Section Guest Editorial: Feature and Deep Learning in Remote Sensing Applications. J. Appl. Remote Sens. 2018, 11, 1. [Google Scholar] [CrossRef]
- Ellouze, A.; Ksantini, M.; Delmotte, F.; Karray, M. Multiple Object Tracking: Case of Aircraft Detection and Tracking. In Proceedings of the IEEE 2019 16th International Multi-Conference on Systems, Signals & Devices (SSD), Istanbul, Turkey, 21–24 March 2019; pp. 473–478. [Google Scholar]
- Brown, C.F.; Brumby, S.P.; Guzder-Williams, B.; Birch, T.; Hyde, S.B.; Mazzariello, J.; Czerwinski, W.; Pasquarella, V.J.; Haertel, R.; Ilyushchenko, S.; et al. Dynamic World, Near real-time global 10 m land use land cover mapping. Sci. Data 2022, 9, 251. [Google Scholar] [CrossRef]
- Wang, Y.; Albrecht, C.M.; Braham, N.A.A.; Mou, L.; Zhu, X.X. Self-Supervised Learning in Remote Sensing: A review. IEEE Geosci. Remote Sens. Mag. 2022, 10, 213–247. [Google Scholar] [CrossRef]
- Bruzzone, L.; Prieto, D.F. Unsupervised retraining of a maximum likelihood classifier for the analysis of multitemporal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 456–460. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Ball, G.H.; Hall, J. ISODATA: A Novel Method for Data Analysis and Pattern Classification; Stanford Research Institute: Menlo Park, CA, USA, 1965. [Google Scholar]
- Kanungo, T.; Mount, D.; Netanyahu, N.; Piatko, C.; Silverman, R.; Wu, A. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, M.; Zheng, Y.; Wu, B. Crop Mapping Using PROBA-V Time Series Data at the Yucheng and Hongxing Farm in China. Remote Sens. 2016, 8, 915. [Google Scholar] [CrossRef]
- Zhang, H.; Zhai, H.; Zhang, L.; Li, P. Spectral–spatial sparse subspace clustering for hyperspectral remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3672–3684. [Google Scholar] [CrossRef]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1422–1430. [Google Scholar]
- Noroozi, M.; Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 69–84. [Google Scholar]
- Alexey, D.; Fischer, P.; Tobias, J.; Springenberg, M.R.; Brox, T. Discriminative, unsupervised feature learning with exemplar convolutional, neural networks. IEEE TPAMI 2016, 38, 1734–1747. [Google Scholar] [CrossRef]
- Arora, S.; Khandeparkar, H.; Khodak, M.; Plevrakis, O.; Saunshi, N. A Theoretical Analysis of Contrastive Unsupervised Representation Learning. arXiv 2019, arXiv:1902.09229. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. arXiv 2021, arXiv:2104.14294. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap your own latent: A new approach to self-supervised Learning. arXiv 2020, arXiv:2006.07733. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Chen, X.; Xie, S.; He, K. An Empirical Study of Training Self-Supervised Vision Transformers. arXiv 2021, arXiv:2104.02057. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, X.; He, K. Exploring Simple Siamese Representation Learning. arXiv 2020, arXiv:2011.10566. [Google Scholar] [CrossRef]
- Wen, Z.; Liu, Z.; Zhang, S.; Pan, Q. Rotation awareness based self-supervised learning for SAR target recognition with limited training samples. IEEE Trans. Image Process. 2021, 30, 7266–7279. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.; Batra, A.; Pang, G.; Torresani, L.; Basu, S.; Paluri, M.; Jawahar, C.V. Self-Supervised Feature Learning for Semantic Segmentation of Overhead Imagery. In Proceedings of the BMVC, Newcastle upon Tyne, UK, 3–6 September 2018; Volume 1, p. 4. [Google Scholar]
- Geng, W.; Zhou, W.; Jin, S. Multi-view urban scene classification with a complementary-information learning model. Photogramm. Eng. Remote Sens. 2022, 88, 65–72. [Google Scholar] [CrossRef]
- Rao, W.; Qu, Y.; Gao, L.; Sun, X.; Wu, Y.; Zhang, B. Transferable network with Siamese architecture for anomaly detection in hyperspectral images. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102669. [Google Scholar] [CrossRef]
- Zhang, L.; Lu, W.; Zhang, J.; Wang, H. A Semisupervised Convolution Neural Network for Partial Unlabeled Remote-Sensing Image Segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Jean, N.; Wang, S.; Samar, A.; Azzari, G.; Lobell, D.; Ermon, S. Tile2Vec: Unsupervised representation learning for spatially distributed data. arXiv 2018, arXiv:1805.02855. [Google Scholar] [CrossRef]
- Hou, S.; Shi, H.; Cao, X.; Zhang, X.; Jiao, L. Hyperspectral imagery classification based on contrastive learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Duan, P.; Xie, Z.; Kang, X.; Li, S. Self-supervised learning-based oil spill detection of hyperspectral images. Sci. China Technol. Sci. 2022, 65, 793–801. [Google Scholar] [CrossRef]
- Zhu, M.; Fan, J.; Yang, Q.; Chen, T. SC-EADNet: A Self-Supervised Contrastive Efficient Asymmetric Dilated Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Dong, Y.; Cordonnier, J.B.; Loukas, A. Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth. arXiv 2021, arXiv:2103.03404. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Sumbul, G.; De Wall, A.; Kreuziger, T.; Marcelino, F.; Costa, H.; Benevides, P.; Caetano, M.; Demir, B.; Markl, V. BigEarthNet-MM: A Large-Scale, Multimodal, Multilabel Benchmark Archive for Remote Sensing Image Classification and Retrieval [Software and Data Sets]. IEEE Geosci. Remote Sens. Mag. 2021, 9, 174–180. [Google Scholar] [CrossRef]
- Sumbul, G.; Kang, J.; Kreuziger, T.; Marcelino, F.; Costa, H.; Benevides, P.; Caetano, M.; Demir, B. Bigearthnet deep learning models with a new class-nomenclature for remote sensing image understanding. arXiv 2020, arXiv:2001.06372. [Google Scholar]
- Sumbul, G.; Demİr, B. A Deep Multi-Attention Driven Approach for Multi-Label Remote Sensing Image Classification. IEEE Access 2020, 8, 95934–95946. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Koçyiğit, M.T.; Hospedales, T.M.; Bilen, H. Accelerating Self-Supervised Learning via Efficient Training Strategies. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 5654–5664. [Google Scholar]
- Nalepa, J.; Le Saux, B.; Longépé, N.; Tulczyjew, L.; Myller, M.; Kawulok, M.; Smykala, K.; Gumiela, M. The Hyperview Challenge: Estimating Soil Parameters from Hyperspectral Images. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 4268–4272. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. arXiv 2019, arXiv:1706.09516. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Wightman, R.; Touvron, H.; Jégou, H. ResNet strikes back: An improved training procedure in timm. arXiv 2021, arXiv:2110.00476. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. LaMDA: Language Models for Dialog Applications. arXiv 2022, arXiv:2201.08239. [Google Scholar] [CrossRef]
- Baevski, A.; Babu, A.; Hsu, W.N.; Auli, M. Efficient self-supervised learning with contextualized target representations for vision, speech and language. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 1416–1429. [Google Scholar]
- Ciga, O.; Xu, T.; Martel, A.L. Resource and data efficient self supervised learning. arXiv 2021, arXiv:2109.01721. [Google Scholar]
- Li, C.; Yang, J.; Zhang, P.; Gao, M.; Xiao, B.; Dai, X.; Yuan, L.; Gao, J. Efficient self-supervised vision transformers for representation learning. arXiv 2021, arXiv:2106.09785. [Google Scholar]
- Diao, S.; Wang, P.; Lin, Y.; Zhang, T. Active Prompting with Chain-of-Thought for Large Language Models. arXiv 2023, arXiv:2302.12246. [Google Scholar] [CrossRef]
- Liu, J.; Shen, D.; Zhang, Y.; Dolan, B.; Carin, L.; Chen, W. What Makes Good In-Context Examples for GPT-3? arXiv 2021, arXiv:2101.06804. [Google Scholar] [CrossRef]
- Saravia, E. Prompt Engineering Guide. 2022. Available online: https://github.com/dair-ai/Prompt-Engineering-Guide (accessed on 16 December 2022).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CATEGORY | Name | Pretext Task |
|---|---|---|
| Generative based | Denoising AE [52] | Reconstruct clear image from noisy input |
| Masked AE (MAE) [28] | Reconstruct randomly masked patches | |
| GANs [53] | Adversarial training with a generator and a discriminator | |
| Wasserstein GAN [54] | Train the generator to produce samples that are as close as possible to the real data distribution | |
| Relative position [46] | Predict the relative positions of random patch pairs | |
| Rotation [29] | Predict the rotation angle of a randomly rotated image | |
| puzzle [47] | Predict the correct order of the puzzle | |
| Contrastive learning based | MoCo V1-V3 [55,56,57] | Store negative samples in a queue and perform momentum updates to the key code. |
| SwAV [50] | Contrastive learning for online clustering | |
| BYOL [51] | Average a teacher network with a predictor on top of a teacher encoder | |
| SimSiam [58] | Explore the simplest contrasting SSL designs |
| Class Nomenclature | Training | Validation |
|---|---|---|
| Urban fabric | 56,963 | 17,928 |
| Industrial or commercial units | 9057 | 2808 |
| Arable land | 146,998 | 47,150 |
| Permanent crops | 22,538 | 6812 |
| Pastures | 74,827 | 24,170 |
| Complex cultivation patterns | 78,565 | 25,638 |
| Land principally occupied by agriculture, with significant areas of natural vegetation | 98,585 | 32,052 |
| Agro-forestry areas | 23,388 | 7261 |
| Broad-leaved forest | 107,170 | 34,130 |
| Coniferous forest | 125,243 | 39,532 |
| Mixed forest | 133,926 | 42,641 |
| Natural grassland and sparsely vegetated areas | 9223 | 2799 |
| Moors, heathland and sclerophyllous vegetation | 12,408 | 3859 |
| Transitional woodland, shrub | 112,739 | 36,211 |
| Beaches, dunes, sands | 1315 | 221 |
| Inland wetlands | 16,751 | 5349 |
| Coastal wetlands | 1256 | 310 |
| Inland waters | 51,100 | 16,177 |
| Marine waters | 56,854 | 18,023 |
| Total number of images | 393,418 | 125,866 |
| W/o Spectral-Aware and LaG | W/o Spectral-Aware | Full Augmentations | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | f1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| Urban fabric | 72.84% | 60.08% | 65.84% | 72.22% | 65.94% | 68.94% | 86.51% | 71.45% | 78.26% |
| Industrial or commercial units | 59.18% | 28.49% | 38.46% | 62.34% | 39.79% | 48.58% | 83.62% | 25.39% | 38.95% |
| Mixed forest | 78.08% | 79.01% | 78.54% | 82.70% | 78.78% | 80.69% | 85.07% | 82.13% | 83.58% |
| Natural grassland and sparsely vegetated areas | 50.68% | 30.55% | 38.12% | 61.50% | 36.45% | 45.77% | 70.54% | 43.59% | 53.89% |
| Moors, heathland and sclerophyllous vegetation | 58.85% | 41.54% | 48.70% | 71.74% | 46.30% | 56.28% | 73.12% | 61.06% | 66.55% |
| Transitional woodland, shrub | 60.65% | 57.01% | 58.77% | 66.53% | 61.36% | 63.84% | 69.19% | 66.93% | 68.04% |
| Beaches, dunes, sands | 29.25% | 36.44% | 32.45% | 41.43% | 49.15% | 44.96% | 59.72% | 36.44% | 45.26% |
| Inland wetlands | 64.18% | 42.92% | 51.44% | 69.05% | 55.14% | 61.31% | 79.48% | 53.54% | 63.98% |
| Coastal wetlands | 29.63% | 25.57% | 27.45% | 37.19% | 68.95% | 48.32% | 53.70% | 63.01% | 57.98% |
| Inland waters | 83.82% | 79.84% | 81.78% | 88.81% | 79.38% | 83.83% | 90.86% | 80.05% | 85.11% |
| Marine waters | 97.11% | 97.08% | 97.09% | 97.43% | 97.77% | 97.60% | 98.25% | 98.06% | 98.15% |
| Arable land | 83.14% | 79.47% | 81.26% | 82.88% | 83.74% | 83.31% | 89.03% | 83.66% | 86.26% |
| Permanent crops | 53.15% | 43.80% | 48.02% | 71.97% | 38.42% | 50.10% | 73.92% | 60.07% | 66.28% |
| Pastures | 72.48% | 65.55% | 68.85% | 84.83% | 60.43% | 70.58% | 83.39% | 69.27% | 75.67% |
| Complex cultivation patterns | 63.51% | 56.90% | 60.02% | 73.53% | 57.26% | 64.38% | 74.89% | 66.78% | 70.60% |
| Land principally occupied by agriculture, with significant areas of natural vegetation | 61.57% | 56.41% | 58.88% | 75.10% | 46.42% | 57.37% | 71.97% | 63.75% | 67.61% |
| Agro-forestry areas | 69.91% | 66.53% | 68.18% | 79.29% | 65.04% | 71.46% | 79.59% | 78.61% | 79.10% |
| Broad-leaved forest | 74.24% | 68.35% | 71.17% | 84.70% | 62.51% | 71.93% | 81.69% | 76.61% | 79.07% |
| Coniferous forest | 83.75% | 82.77% | 83.26% | 84.04% | 87.48% | 85.73% | 90.03% | 83.45% | 86.62% |
| Average Score | 65.58% | 57.80% | 60.96% | 73.02% | 62.12% | 66.05% | 78.66% | 66.52% | 71.10% |
| MOCO-V2 | BYOL | DINO | Proposed Method | |
|---|---|---|---|---|
| Accuracy(%) | 91.71% | 91.86% | 92.05% | 92.76% |
| Precision(%) | 65.58% | 70.62% | 69.42% | 73.02% |
| Recall(%) | 57.80% | 50.68% | 55.21% | 62.12% |
| F1(%) | 60.96% | 57.03% | 60.65% | 66.05% |
| HL | 0.083 | 0.081 | 0.080 | 0.072 |
| COV | 4.781 | 4.645 | 4.601 | 4.241 |
| LRAP(%) | 86.25% | 86.33% | 87.17% | 89.13% |
| RL | 0.054 | 0.051 | 0.049 | 0.038 |
| VGG16 | ResNet50 | ViT | Proposed Network w/o SSL | Proposed Network | |
|---|---|---|---|---|---|
| Accuracy (%) | 90.96% | 92.32% | 89.94% | 92.83% | 93.84% |
| Precision (%) | 68.59% | 69.62% | 57.91% | 72.66% | 77.87% |
| Recall (%) | 40.05% | 58.04% | 34.16% | 61.52% | 69.25% |
| F1 (%) | 45.85% | 62.52% | 39.00% | 65.10% | 72.50% |
| HL | 0.090 | 0.077 | 0.101 | 0.071 | 0.062 |
| COV | 4.849 | 4.502 | 5.303 | 4.130 | 3.940 |
| LRAP (%) | 83.88% | 87.67% | 80.15% | 89.91% | 92.07% |
| RL | 0.059 | 0.046 | 0.076 | 0.031 | 0.028 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Han, L. A Generic Self-Supervised Learning (SSL) Framework for Representation Learning from Spectral–Spatial Features of Unlabeled Remote Sensing Imagery. Remote Sens. 2023, 15, 5238. https://doi.org/10.3390/rs15215238
Zhang X, Han L. A Generic Self-Supervised Learning (SSL) Framework for Representation Learning from Spectral–Spatial Features of Unlabeled Remote Sensing Imagery. Remote Sensing. 2023; 15(21):5238. https://doi.org/10.3390/rs15215238
Chicago/Turabian StyleZhang, Xin, and Liangxiu Han. 2023. "A Generic Self-Supervised Learning (SSL) Framework for Representation Learning from Spectral–Spatial Features of Unlabeled Remote Sensing Imagery" Remote Sensing 15, no. 21: 5238. https://doi.org/10.3390/rs15215238
APA StyleZhang, X., & Han, L. (2023). A Generic Self-Supervised Learning (SSL) Framework for Representation Learning from Spectral–Spatial Features of Unlabeled Remote Sensing Imagery. Remote Sensing, 15(21), 5238. https://doi.org/10.3390/rs15215238