
BEMF-Net: Semantic Segmentation of Large-Scale Point Clouds via Bilateral Neighbor Enhancement and Multi-Scale Fusion
 , , and
, , and 
Abstract
:
1. Introduction
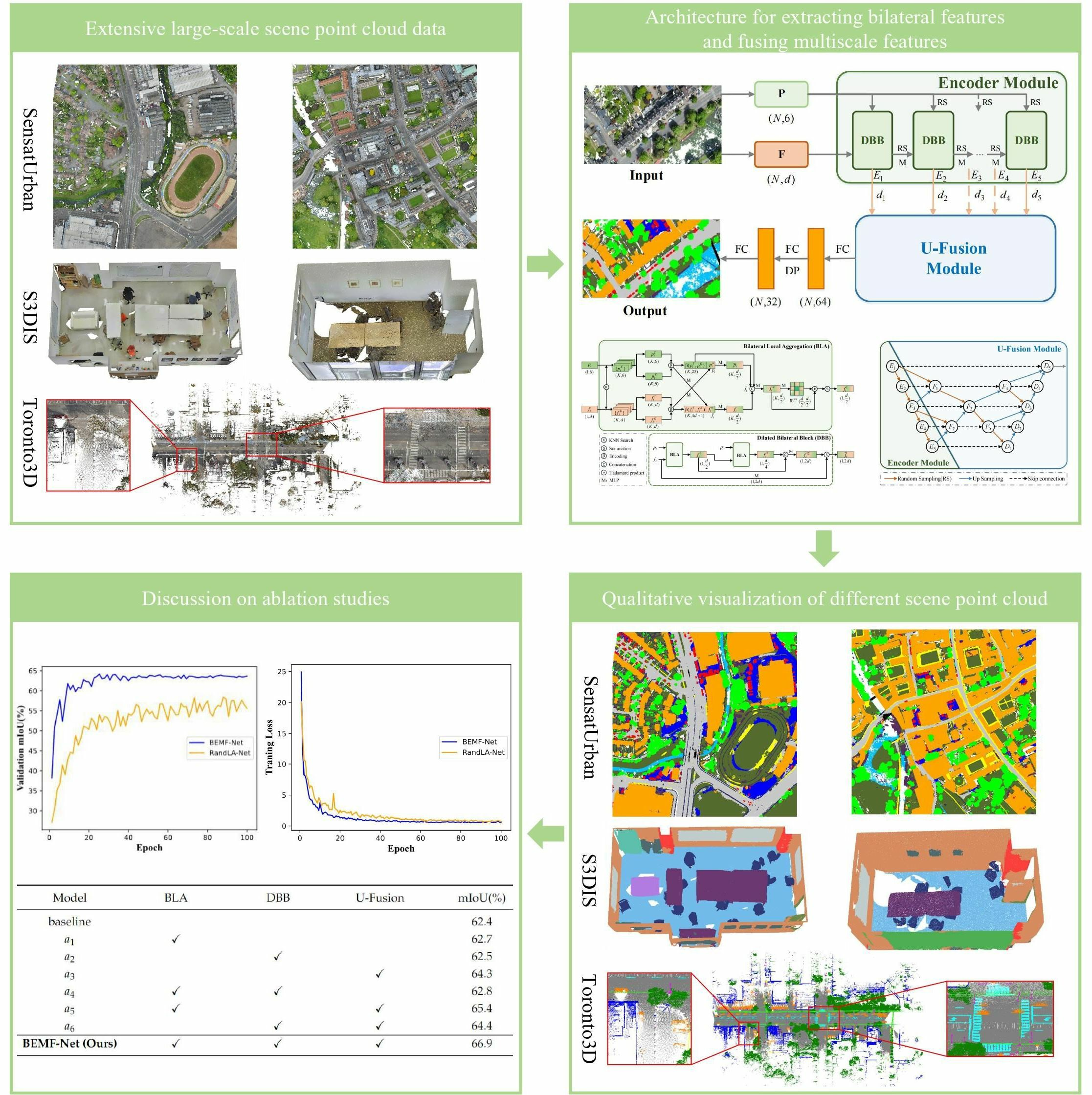
- We propose the dilated bilateral block (DBB) module, which allows the fine-grained learning of point clouds and optimizes the understanding of their local relationships. The module enriches the neighborhood representation by constructing local texture relations. In addition, it uses the differences in the neighborhood space to effectively differentiate semantic class boundaries.
- We designed a novel U-Fusion module, which facilitates the exchange of information from point clouds at multiple resolutions and ensures the effective utilization of features at each resolution.
- We proposed BEMF-Net for the task of semantic segmentation of large-scale point cloud scenes and achieved excellent results on all public benchmark datasets.
2. Related Work
2.1. Semantic Segmentation on Point Cloud
2.2. Point Cloud Feature Extraction
2.3. Multi-Scale Feature Fusion
3. Methodology
3.1. Encoder Module
3.1.1. Bilateral Local Aggregation
3.1.2. Dilated Bilateral Block
3.2. U-Fusion Module
4. Experiments
4.1. Experiment Settings
4.2. Dataset Description
4.3. Experiment Result and Analysis
4.3.1. Evaluation on SensatUrban
4.3.2. Evaluation on Toronto3D
4.3.3. Evaluation on S3DIS
4.4. Ablation Studies
- : Replace RandLA-Net’s local spatial encoding and attentive pooling modules with our BLA module. This is intended to validate the effectiveness of the proposed encoder and the enhancement provided by the inclusion of multifaceted reinforced features including coordinates, colors, and semantics for the segmentation task.
- : Replace RandLA-Net’s dilated residual block with our proposed DBB. This aims to demonstrate the effectiveness of the multi-receptive field space provided by dense connections for feature representation.
- : Embed the interlayer multi-scale fusion module U-Fusion into RandLA-Net to illustrate the advantages of multi-scale feature fusion over the single-scale feature connections of the traditional U-Net.
- : Remove multi-scale features from the complete network structure to demonstrate the importance of multi-scale information.
- : Remove DBB from the entire network structure to demonstrate the effectiveness of dense connections.
- : Remove BLA from the full network to highlight the effectiveness of bilateral features.
5. Discussion
5.1. Discussion on Hyperparameter
5.2. Discussion on Loss Function
5.3. Discussion on Computational Efficiency
5.4. Learning Process of Our Methods
6. Conclusions
- Enhancing the network’s ability to describe the point cloud is possible by adding extra data, such as color information. The simultaneous use of geometry and color data can help distinguish semantic class boundaries.
- Effective utilization of features at different resolutions is essential to improve scene understanding. Ablation tests show that the proposed U-Fusion method is sensitive to feature changes and provides positive feedback.
- This methodology can effectively function in three separate urban environments: SensatUrban, Toronto3D, and S3DIS. SensatUrban pertains to capturing large-scale outdoor urban scenes through the means of UAVs, while Toronto3D entails localized urban scenes captured by radar mounted on vehicles. S3DIS encompasses indoor scene data. This showcases the ability to address data variability to a certain extent.
- Real-world point cloud data are commonly obtained by radar or UAVs, which often leads to inherent problems such as noise and incomplete data. In the future, we will focus on overcoming these challenges and achieving accurate point cloud segmentation, especially in regions characterized by low data quality.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, G.; Xue, F.; Zhang, Q.; Xie, K.; Fu, C.W.; Huang, H. UrbanBIS: A Large-Scale Benchmark for Fine-Grained Urban Building Instance Segmentation. In Proceedings of the ACM SIGGRAPH Conference Proceedings, Los Angeles, CA, USA, 6–10 August 2023. [Google Scholar] [CrossRef]
- Marsocci, V.; Coletta, V.; Ravanelli, R.; Scardapane, S.; Crespi, M. New trends in urban change detection: Detecting 3D changes from bitemporal optical images. In Proceedings of the EGU General Assembly, Vienna, Austria, 24–28 April 2023. [Google Scholar] [CrossRef]
- Wang, L.; Huang, Y.; Shan, J.; He, L. MSNet: Multi-Scale Convolutional Network for Point Cloud Classification. Remote Sens. 2018, 10, 612. [Google Scholar] [CrossRef]
- Shao, J.; Zhang, W.; Shen, A.; Mellado, N.; Cai, S.; Luo, L.; Wang, N.; Yan, G.; Zhou, G. Seed point set-based building roof extraction from airborne LiDAR point clouds using a top-down strategy. Autom. Constr. 2021, 126, 103660. [Google Scholar] [CrossRef]
- Zheng, Q.; Zhao, P.; Li, Y.; Wang, H.; Yang, Y. Spectrum interference-based two-level data augmentation method in deep learning for automatic modulation classification. Neural Comput. Appl. 2021, 33, 7723–7745. [Google Scholar] [CrossRef]
- Li, Z.; Chen, Z.; Li, A.; Fang, L.; Jiang, Q.; Liu, X.; Jiang, J. Unsupervised Domain Adaptation For Monocular 3D Object Detection Via Self-Training. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 245–262. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D Object Detection Network for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6526–6534. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection From Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12689–12697. [Google Scholar] [CrossRef]
- Xie, X.; Liu, Y.; Xu, Y.; He, Z.; Chen, X.; Zheng, X.; Xie, Z. Building Function Recognition Using the Semi-Supervised Classification. Appl. Sci. 2022, 12, 9900. [Google Scholar] [CrossRef]
- Yongyang, X.; Shuai, J.; Zhanlong, C.; Xuejing, X.; Sheng, H.; Zhong, X. Application of a graph convolutional network with visual and semantic features to classify urban scenes. Int. J. Geogr. Inf. Sci. 2022, 36, 2009–2034. [Google Scholar] [CrossRef]
- Jaboyedoff, M.; Oppikofer, T.; Abellán, A.; Derron, M.H.; Loye, A.; Metzger, R.; Pedrazzini, A. Use of LIDAR in landslide investigations: A review. Nat. Hazards 2012, 61, 5–28. [Google Scholar] [CrossRef]
- Rim, B.; Lee, A.; Hong, M. Semantic Segmentation of Large-Scale Outdoor Point Clouds by Encoder–Decoder Shared MLPs with Multiple Losses. Remote Sens. 2021, 13, 3121. [Google Scholar] [CrossRef]
- Yang, S.; Li, Q.; Li, W.; Li, X.; Liu, A.A. Dual-Level Representation Enhancement on Characteristic and Context for Image-Text Retrieval. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8037–8050. [Google Scholar] [CrossRef]
- Li, W.; Wang, Y.; Su, Y.; Li, X.; Liu, A.A.; Zhang, Y. Multi-Scale Fine-Grained Alignments for Image and Sentence Matching. IEEE Trans. Multimed. 2023, 25, 543–556. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, B.; Ma, A.; Peng, M.; Li, H.; Chen, T.; Chen, C.; Dong, Z. Joint alignment of the distribution in input and feature space for cross-domain aerial image semantic segmentation. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103107. [Google Scholar] [CrossRef]
- de Gélis, I.; Lefèvre, S.; Corpetti, T. Change Detection in Urban Point Clouds: An Experimental Comparison with Simulated 3D Datasets. Remote Sens. 2021, 13, 2629. [Google Scholar] [CrossRef]
- Marsocci, V.; Coletta, V.; Ravanelli, R.; Scardapane, S.; Crespi, M. Inferring 3D change detection from bitemporal optical images. ISPRS J. Photogramm. Remote Sens. 2023, 196, 325–339. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Q.; Peng, W.; Xu, H.; Li, X.; Xu, W. Disparity-Based Multiscale Fusion Network for Transportation Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18855–18863. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, G.; Myint, S.W.; Zhou, Y.; Hay, G.J.; Vukomanovic, J.; Meentemeyer, R.K. UrbanWatch: A 1-meter resolution land cover and land use database for 22 major cities in the United States. Remote Sens. Environ. 2022, 278, 113106. [Google Scholar] [CrossRef]
- Wu, W.; Xie, Z.; Xu, Y.; Zeng, Z.; Wan, J. Point Projection Network: A Multi-View-Based Point Completion Network with Encoder-Decoder Architecture. Remote Sens. 2021, 13, 4917. [Google Scholar] [CrossRef]
- Qin, N.; Hu, X.; Wang, P.; Shan, J.; Li, Y. Semantic Labeling of ALS Point Cloud via Learning Voxel and Pixel Representations. IEEE Geosci. Remote Sens. Lett. 2020, 17, 859–863. [Google Scholar] [CrossRef]
- Han, X.; Dong, Z.; Yang, B. A point-based deep learning network for semantic segmentation of MLS point clouds. ISPRS J. Photogramm. Remote Sens. 2021, 175, 199–214. [Google Scholar] [CrossRef]
- Poursaeed, O.; Jiang, T.; Qiao, H.; Xu, N.; Kim, V.G. Self-Supervised Learning of Point Clouds via Orientation Estimation. In Proceedings of the International Conference on 3D Vision (3DV), Virtual Event, 25–28 November 2020; pp. 1018–1028. [Google Scholar] [CrossRef]
- Liu, Z.; Zhao, Y.; Zhan, S.; Liu, Y.; Chen, R.; He, Y. PCDNF: Revisiting Learning-based Point Cloud Denoising via Joint Normal Filtering. IEEE Trans. Vis. Comput. Graph. 2023, 1–18. [Google Scholar] [CrossRef]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5105–5114. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11105–11114. [Google Scholar] [CrossRef]
- Shuai, H.; Xu, X.; Liu, Q. Backward Attentive Fusing Network With Local Aggregation Classifier for 3D Point Cloud Semantic Segmentation. IEEE Trans. Image Process. 2021, 30, 4973–4984. [Google Scholar] [CrossRef]
- Li, F.; Zhou, Z.; Xiao, J.; Chen, R.; Lehtomäki, M.; Elberink, S.O.; Vosselman, G.; Hyyppä, J.; Chen, Y.; Kukko, A. Instance-Aware Semantic Segmentation of Road Furniture in Mobile Laser Scanning Data. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17516–17529. [Google Scholar] [CrossRef]
- Shen, S.; Xia, Y.; Eich, A.; Xu, Y.; Yang, B.; Stilla, U. SegTrans: Semantic Segmentation With Transfer Learning for MLS Point Clouds. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Atik, M.E.; Duran, Z. Selection of Relevant Geometric Features Using Filter-Based Algorithms for Point Cloud Semantic Segmentation. Electronics 2022, 11, 3310. [Google Scholar] [CrossRef]
- Qiu, S.; Anwar, S.; Barnes, N. Semantic Segmentation for Real Point Cloud Scenes via Bilateral Augmentation and Adaptive Fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1757–1767. [Google Scholar] [CrossRef]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6410–6419. [Google Scholar] [CrossRef]
- Chen, J.; Zhao, Y.; Meng, C.; Liu, Y. Multi-Feature Aggregation for Semantic Segmentation of an Urban Scene Point Cloud. Remote Sens. 2022, 14, 5134. [Google Scholar] [CrossRef]
- Du, J.; Cai, G.; Wang, Z.; Huang, S.; Su, J.; Marcato Junior, J.; Smit, J.; Li, J. ResDLPS-Net: Joint residual-dense optimization for large-scale point cloud semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 182, 37–51. [Google Scholar] [CrossRef]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10288–10297. [Google Scholar] [CrossRef]
- Ku, T.; Veltkamp, R.C.; Boom, B.; Duque-Arias, D.; Velasco-Forero, S.; Deschaud, J.E.; Goulette, F.; Marcotegui, B.; Ortega, S.; Trujillo, A.; et al. SHREC 2020: 3D point cloud semantic segmentation for street scenes. Comput. Graph. 2020, 93, 13–24. [Google Scholar] [CrossRef]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D Semantic Parsing of Large-Scale Indoor Spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1534–1543. [Google Scholar] [CrossRef]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. SEGCloud: Semantic Segmentation of 3D Point Clouds. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar] [CrossRef]
- Liu, H.; Yuan, H.; Hou, J.; Hamzaoui, R.; Gao, W. PUFA-GAN: A Frequency-Aware Generative Adversarial Network for 3D Point Cloud Upsampling. IEEE Trans. Image Process. 2022, 31, 7389–7402. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. Adv. Neural Inf. Process. Syst. (NeurIPS) 2018, 31. [Google Scholar]
- Li, Y.; Ma, L.; Zhong, Z.; Cao, D.; Li, J. TGNet: Geometric Graph CNN on 3-D Point Cloud Segmentation. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3588–3600. [Google Scholar] [CrossRef]
- Fan, S.; Dong, Q.; Zhu, F.; Lv, Y.; Ye, P.; Wang, F.Y. SCF-Net: Learning Spatial Contextual Features for Large-Scale Point Cloud Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14499–14508. [Google Scholar] [CrossRef]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R.; Hu, S.M. PCT: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Zeng, Z.; Xu, Y.; Xie, Z.; Tang, W.; Wan, J.; Wu, W. LEARD-Net: Semantic segmentation for large-scale point cloud scene. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102953. [Google Scholar] [CrossRef]
- Landrieu, L.; Simonovsky, M. Large-Scale Point Cloud Semantic Segmentation with Superpoint Graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4558–4567. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Xiao, X.; Lian, S.; Luo, Z.; Li, S. Weighted Res-UNet for High-Quality Retina Vessel Segmentation. In Proceedings of the International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; pp. 327–331. [Google Scholar] [CrossRef]
- Cao, Y.; Liu, S.; Peng, Y.; Li, J. DenseUNet: Densely connected UNet for electron microscopy image segmentation. IET Image Process. 2020, 14, 2682–2689. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Khalid, S.; Xiao, W.; Trigoni, N.; Markham, A. Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4975–4985. [Google Scholar] [CrossRef]
- Tan, W.; Qin, N.; Ma, L.; Li, Y.; Du, J.; Cai, G.; Yang, K.; Li, J. Toronto-3D: A Large-scale Mobile LiDAR Dataset for Semantic Segmentation of Urban Roadways. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 797–806. [Google Scholar] [CrossRef]
- Tatarchenko, M.; Park, J.; Koltun, V.; Zhou, Q.Y. Tangent Convolutions for Dense Prediction in 3D. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3887–3896. [Google Scholar] [CrossRef]
- Graham, B.; Engelcke, M.; Maaten, L.v.d. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 9224–9232. [Google Scholar] [CrossRef]
- Yang, Z.; Ye, Q.; Stoter, J.; Nan, L. Enriching Point Clouds with Implicit Representations for 3D Classification and Segmentation. Remote Sens. 2023, 15, 61. [Google Scholar] [CrossRef]
- Xu, Y.; Tang, W.; Zeng, Z.; Wu, W.; Wan, J.; Guo, H.; Xie, Z. NeiEA-NET: Semantic segmentation of large-scale point cloud scene via neighbor enhancement and aggregation. Int. J. Appl. Earth Obs. Geoinf. 2023, 119, 103285. [Google Scholar] [CrossRef]
- Ma, L.; Li, Y.; Li, J.; Tan, W.; Yu, Y.; Chapman, M.A. Multi-Scale Point-Wise Convolutional Neural Networks for 3D Object Segmentation From LiDAR Point Clouds in Large-Scale Environments. IEEE Trans. Intell. Transp. Syst. 2021, 22, 821–836. [Google Scholar] [CrossRef]
- Zeng, Z.; Xu, Y.; Xie, Z.; Wan, J.; Wu, W.; Dai, W. RG-GCN: A Random Graph Based on Graph Convolution Network for Point Cloud Semantic Segmentation. Remote Sens. 2022, 14, 4055. [Google Scholar] [CrossRef]
- Jiang, T.; Sun, J.; Liu, S.; Zhang, X.; Wu, Q.; Wang, Y. Hierarchical semantic segmentation of urban scene point clouds via group proposal and graph attention network. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102626. [Google Scholar] [CrossRef]
- Chen, J.; Kakillioglu, B.; Velipasalar, S. Background-Aware 3-D Point Cloud Segmentation With Dynamic Point Feature Aggregation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Du, Z.; Ye, H.; Cao, F. A Novel Local-Global Graph Convolutional Method for Point Cloud Semantic Segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–15. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | OA | mIoU | Grd. | Veg. | Build. | Wall | Bridge | Park. | Rail | Traffic. | Street. | Car | Foot. | Bike | Water |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [25] | 80.8 | 23.7 | 67.9 | 89.5 | 80.1 | 0.0 | 0.0 | 3.9 | 0.0 | 31.6 | 0.0 | 35.1 | 0.0 | 0.0 | 0.0 |
| PointNet++ [26] | 84.3 | 32.9 | 72.5 | 94.2 | 84.8 | 2.7 | 2.1 | 25.8 | 0.0 | 31.5 | 11.4 | 38.8 | 7.1 | 0.0 | 56.9 |
| TagentConv [55] | 76.9 | 33.3 | 71.5 | 91.4 | 75.9 | 35.2 | 0.0 | 45.3 | 0.0 | 26.7 | 19.2 | 67.6 | 0.0 | 0.0 | 0.0 |
| SPGraph [47] | 85.3 | 37.3 | 69.9 | 94.6 | 88.9 | 32.8 | 12.6 | 15.8 | 15.5 | 30.6 | 22.9 | 56.4 | 0.5 | 0.0 | 44.2 |
| SparseConv [56] | 88.7 | 42.7 | 74.1 | 97.9 | 94.2 | 63.3 | 7.5 | 24.2 | 0.0 | 30.1 | 34.0 | 74.4 | 0.0 | 0.0 | 54.8 |
| KPConv [33] | 93.2 | 57.6 | 87.1 | 98.9 | 95.3 | 74.4 | 28.7 | 41.4 | 0.0 | 55.9 | 54.4 | 85.7 | 40.4 | 0.0 | 86.3 |
| RandLA-Net [27] | 89.8 | 52.7 | 80.0 | 98.1 | 91.6 | 48.9 | 40.6 | 51.6 | 0.0 | 56.7 | 33.2 | 80.0 | 32.6 | 0.0 | 71.3 |
| BAF-LAC [28] | 91.5 | 54.1 | 84.4 | 98.4 | 94.1 | 57.2 | 27.6 | 42.5 | 15.0 | 51.6 | 39.5 | 78.1 | 40.1 | 0.0 | 75.2 |
| BAAF-Net [32] | 91.8 | 56.1 | 83.3 | 98.2 | 94.0 | 54.2 | 51.0 | 57.0 | 0.0 | 60.4 | 14.0 | 81.3 | 41.6 | 0.0 | 58.0 |
| IR-Net [57] | 91.3 | 56.3 | 84.2 | 98.1 | 94.6 | 61.6 | 60.8 | 44.2 | 15.7 | 49.4 | 37.2 | 79.1 | 37.8 | 0.1 | 68.7 |
| NeiEA-Net [58] | 91.7 | 57.0 | 83.3 | 98.1 | 93.4 | 50.1 | 61.3 | 57.8 | 0.0 | 60.0 | 41.6 | 82.4 | 42.1 | 0.0 | 71.0 |
| Ours (w/o color) | 92.7 | 61.2 | 85.4 | 98.4 | 95.1 | 60.2 | 66.1 | 60.7 | 16.4 | 59.2 | 43.4 | 81.5 | 42.6 | 17.9 | 68.2 |
| Ours (w/ color) | 92.7 | 61.8 | 85.2 | 98.5 | 95.0 | 63.8 | 64.0 | 57.4 | 26.4 | 60.0 | 47.2 | 84.2 | 42.8 | 0.0 | 79.5 |
| Method | OA | mIoU | Road | Rmrk. | Nature | Buil. | Util.line | Pole | Car | Fence |
|---|---|---|---|---|---|---|---|---|---|---|
| PointNet++ [26] | 92.6 | 59.5 | 92.9 | 0.0 | 86.1 | 82.2 | 60.9 | 62.8 | 76.4 | 14.4 |
| DGCNN [48] | 94.2 | 61.7 | 93.9 | 0.0 | 91.3 | 80.4 | 62.4 | 62.3 | 88.3 | 15.8 |
| MS-PCNN [59] | 90.0 | 65.9 | 93.8 | 3.8 | 93.5 | 82.6 | 67.8 | 71.9 | 91.1 | 22.5 |
| KPConv [33] | 95.4 | 69.1 | 94.6 | 0.1 | 96.1 | 91.5 | 87.7 | 81.6 | 85.7 | 15.7 |
| TGNet [43] | 94.1 | 61.3 | 93.5 | 0.0 | 90.8 | 81.6 | 65.3 | 62.9 | 88.7 | 7.9 |
| MS-TGNet [54] | 95.7 | 70.5 | 94.4 | 17.2 | 95.7 | 88.8 | 76.0 | 73.9 | 94.2 | 23.6 |
| RandLA-Net [27] | 94.4 | 81.8 | 96.7 | 64.2 | 96.9 | 94.2 | 88.0 | 77.8 | 93.4 | 42.9 |
| ResDLPS-Net [35] | 96.5 | 80.3 | 95.8 | 59.8 | 96.1 | 90.9 | 86.8 | 79.9 | 89.4 | 43.3 |
| BAAF-Net [32] | 94.2 | 81.2 | 96.8 | 67.3 | 96.8 | 92.2 | 86.8 | 82.3 | 93.1 | 34.0 |
| BAF-LAC [28] | 95.2 | 82.0 | 96.6 | 64.7 | 96.4 | 91.6 | 86.1 | 83.9 | 93.2 | 43.5 |
| RG-GCN [60] | 96.5 | 74.5 | 98.2 | 79.4 | 91.8 | 86.1 | 72.4 | 69.9 | 82.1 | 16.0 |
| MFA [34] | 97.0 | 79.9 | 96.8 | 70.0 | 96.1 | 92.3 | 86.3 | 80.4 | 91.5 | 29.4 |
| NeiEA-Net [58] | 97.0 | 80.9 | 97.1 | 66.9 | 97.3 | 93.0 | 97.3 | 83.4 | 93.4 | 43.1 |
| Ours (w/o color) | 97.0 | 81.3 | 96.3 | 61.2 | 97.1 | 93.8 | 87.8 | 84.5 | 93.1 | 37.5 |
| Ours (w/ color) | 97.0 | 81.4 | 96.2 | 60.0 | 97.6 | 94.1 | 87.9 | 85.7 | 94.1 | 35.9 |
| Method | OA | mIoU | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [25] | - | 41.1 | 88.8 | 97.3 | 69.8 | 0.1 | 3.9 | 46.3 | 10.8 | 59.0 | 52.6 | 5.9 | 40.3 | 26.4 | 33.2 |
| SegCloud [39] | - | 48.9 | 90.1 | 96.1 | 69.9 | 0.0 | 18.4 | 38.4 | 23.1 | 70.4 | 75.9 | 40.9 | 58.4 | 13.0 | 41.6 |
| TangentConv [55] | - | 52.6 | 90.5 | 97.7 | 74.0 | 0.0 | 20.7 | 39.0 | 31.3 | 77.5 | 69.4 | 57.3 | 38.5 | 48.8 | 39.8 |
| PointCNN [42] | 85.9 | 57.3 | 92.3 | 98.2 | 79.4 | 0.0 | 17.6 | 28.8 | 62.1 | 70.4 | 80.6 | 39.7 | 66.7 | 62.1 | 56.7 |
| SPGraph [47] | 86.4 | 58.0 | 89.4 | 96.9 | 78.1 | 0.0 | 42.8 | 48.9 | 61.6 | 84.7 | 75.4 | 69.8 | 52.6 | 2.1 | 52.5 |
| HPEIN [61] | 87.2 | 61.9 | 91.5 | 98.2 | 81.4 | 0.0 | 23.3 | 65.3 | 40.0 | 75.5 | 87.7 | 58.8 | 67.8 | 65.6 | 49.4 |
| TG-Net [43] | 88.5 | 57.8 | 93.3 | 97.6 | 78.0 | 0.0 | 9.3 | 57.0 | 39.4 | 83.4 | 76.4 | 60.6 | 41.8 | 58.7 | 55.3 |
| RandLA-Net [27] | 87.2 | 62.4 | 91.1 | 95.6 | 80.2 | 0.0 | 24.7 | 62.3 | 47.7 | 76.2 | 83.7 | 60.2 | 71.1 | 65.7 | 53.8 |
| PCT [45] | - | 61.3 | 92.5 | 98.4 | 80.6 | 0.0 | 19.4 | 61.6 | 48.0 | 76.6 | 85.2 | 46.2 | 67.7 | 67.9 | 52.3 |
| BAAF-Net [32] | 88.9 | 65.4 | 92.9 | 97.9 | 82.3 | 0.0 | 23.1 | 65.5 | 64.9 | 78.5 | 87.5 | 61.4 | 70.7 | 68.7 | 57.2 |
| BAF-LAC [28] | - | 65.7 | 91.9 | 97.4 | 82.0 | 0.0 | 19.9 | 61.5 | 52.9 | 80.3 | 87.8 | 78.9 | 72.7 | 75.0 | 53.8 |
| DPFA-Net [62] | 88.0 | 55.2 | 93.0 | 98.6 | 80.2 | 0.0 | 14.7 | 55.8 | 42.8 | 72.3 | 73.5 | 27.3 | 55.9 | 53.0 | 50.5 |
| LGGCM [63] | 88.8 | 63.3 | 94.8 | 98.3 | 81.5 | 0.0 | 35.9 | 63.3 | 43.5 | 80.2 | 88.4 | 68.8 | 55.8 | 64.6 | 47.8 |
| NeiEA-Net [58] | 88.5 | 66.1 | 92.9 | 97.4 | 83.3 | 0.0 | 34.9 | 61.8 | 53.3 | 78.8 | 86.7 | 77.1 | 69.5 | 67.9 | 54.2 |
| Ours (w/o color) | 89.3 | 66.5 | 93.7 | 98.1 | 82.6 | 0.0 | 21.7 | 61.8 | 55.3 | 82.2 | 89.9 | 69.3 | 74.2 | 77.0 | 58.9 |
| Ours (w/ color) | 89.5 | 66.9 | 93.7 | 98.1 | 83.3 | 0.0 | 21.3 | 62.5 | 57.4 | 80.5 | 90.5 | 67.7 | 74.2 | 80.4 | 60.1 |
| Model | BLA | DBB | U-Fusion | mIoU (%) |
|---|---|---|---|---|
| Baseline | 62.4 | |||
| ✔ | 62.7 | |||
| ✔ | 62.5 | |||
| ✔ | 64.3 | |||
| ✔ | ✔ | 62.8 | ||
| ✔ | ✔ | 65.4 | ||
| ✔ | ✔ | 64.4 | ||
| BEMF-Net (ours) | ✔ | ✔ | ✔ | 66.9 |
| Loss Function | OA | mIoU | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 89.4 | 66.8 | 93.7 | 98.0 | 83.3 | 0.0 | 21.3 | 62.4 | 57.1 | 80.5 | 90.3 | 66.5 | 74.0 | 80.5 | 60.1 | |
| 89.5 | 66.9 | 93.7 | 98.1 | 83.3 | 0.0 | 21.3 | 62.5 | 57.4 | 80.5 | 90.5 | 67.7 | 74.2 | 80.4 | 60.1 | |
| 89.7 | 67.1 | 93.7 | 98.1 | 83.2 | 0.0 | 21.6 | 62.5 | 57.3 | 80.3 | 90.6 | 68.7 | 74.3 | 80.5 | 60.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, H.; Yang, S.; Jiang, Z.; Zhang, J.; Guo, S.; Li, G.; Zhong, S.; Liu, Z.; Xie, Z. BEMF-Net: Semantic Segmentation of Large-Scale Point Clouds via Bilateral Neighbor Enhancement and Multi-Scale Fusion. Remote Sens. 2023, 15, 5342. https://doi.org/10.3390/rs15225342
Ji H, Yang S, Jiang Z, Zhang J, Guo S, Li G, Zhong S, Liu Z, Xie Z. BEMF-Net: Semantic Segmentation of Large-Scale Point Clouds via Bilateral Neighbor Enhancement and Multi-Scale Fusion. Remote Sensing. 2023; 15(22):5342. https://doi.org/10.3390/rs15225342
Chicago/Turabian StyleJi, Hao, Sansheng Yang, Zhipeng Jiang, Jianjun Zhang, Shuhao Guo, Gaorui Li, Saishang Zhong, Zheng Liu, and Zhong Xie. 2023. "BEMF-Net: Semantic Segmentation of Large-Scale Point Clouds via Bilateral Neighbor Enhancement and Multi-Scale Fusion" Remote Sensing 15, no. 22: 5342. https://doi.org/10.3390/rs15225342
APA StyleJi, H., Yang, S., Jiang, Z., Zhang, J., Guo, S., Li, G., Zhong, S., Liu, Z., & Xie, Z. (2023). BEMF-Net: Semantic Segmentation of Large-Scale Point Clouds via Bilateral Neighbor Enhancement and Multi-Scale Fusion. Remote Sensing, 15(22), 5342. https://doi.org/10.3390/rs15225342