
A Novel Hybrid Method for Urban Green Space Segmentation from High-Resolution Remote Sensing Images
 ,
, 
Abstract
:1. Introduction
- (1)
- Design the MSPA module to extract the intra-contextual information of multiscale UGS, and then improve the relevance of the MAFANet model to capture the long-range feature information of UGS, thus improving the overall USG segmentation effect;
- (2)
- Designing the DE and BFF module construction new decoder to enhance the dual-channel communication capability, so that the two neighboring layers of ResNet50 network can guide each other in feature mining and improve the anti-interference capability of the MAFANet model;
- (3)
- Introducing false color image synthesis and NDVI vegetation index to improve segmentation accuracy while proving that false color feature is better than the vegetation index in the process of UGS information extraction.
2. Materials and Methods
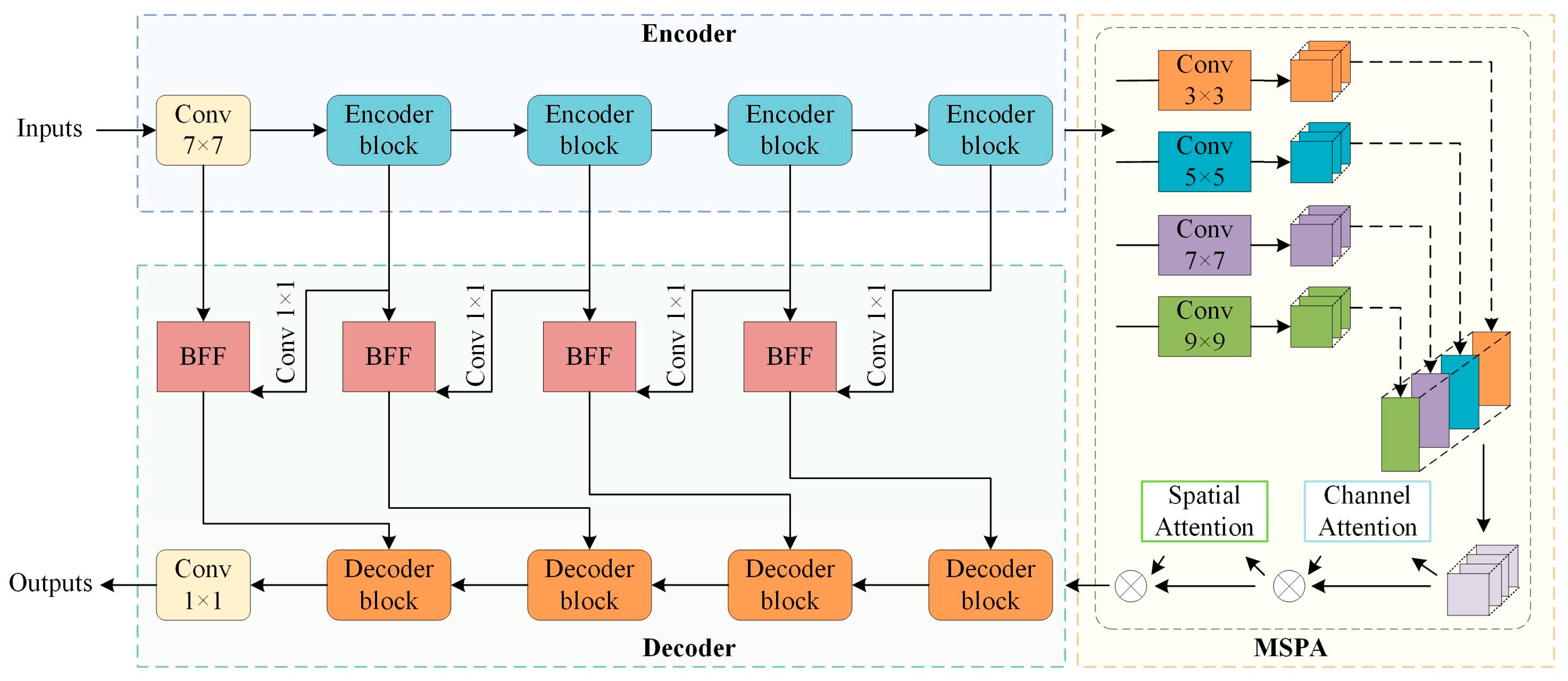
2.1. MAFANet Network
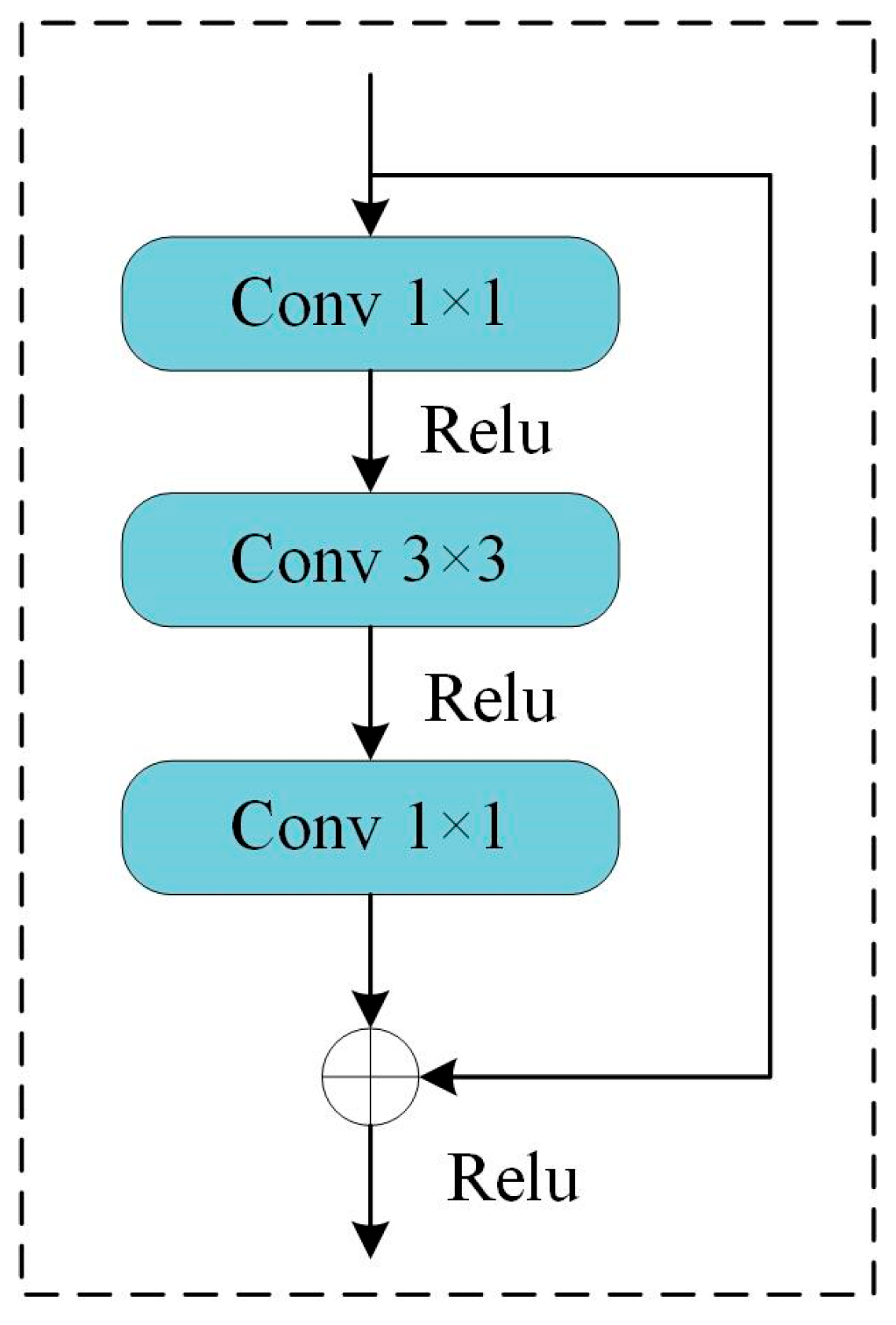
2.2. Encoder with Residual Network
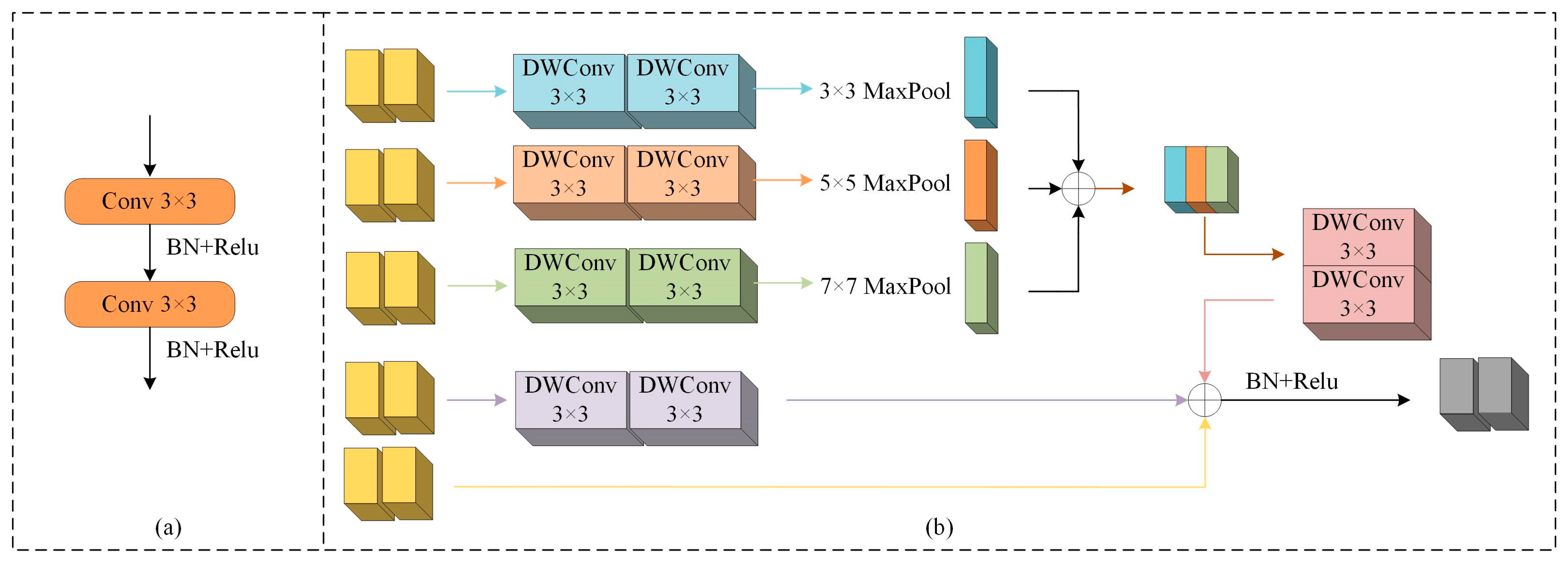
2.3. Decoder with Decoder Block and Bilateral Feature Fusion Module
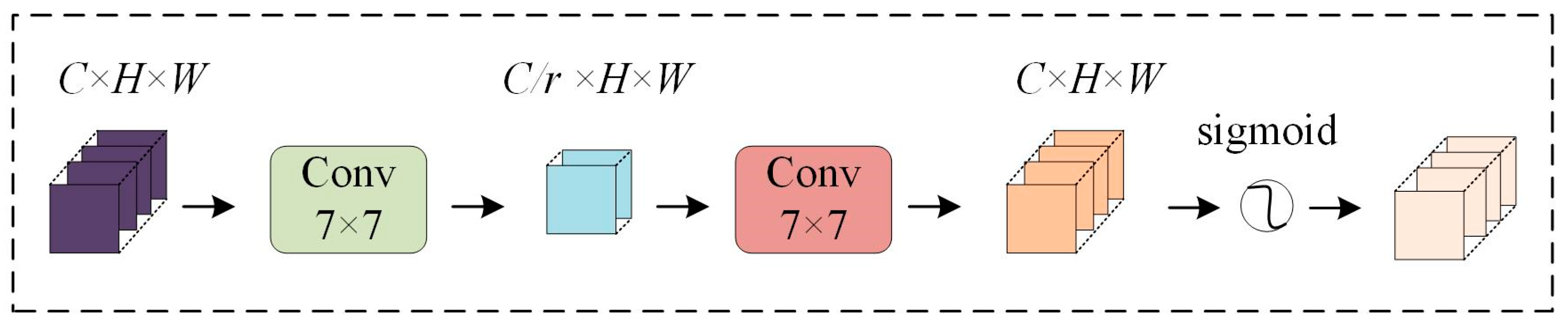
2.4. Multiscale Pooling Attention Module
2.5. Data and Experiment Details
2.5.1. HRS Image Data
2.5.2. False Color Data
2.5.3. Vegetation Index Data
2.5.4. Dataset Construction
2.5.5. Experimental Environment and Evaluation Metrics
3. Results
3.1. Comparison Experiment
3.1.1. Comparison Experiment of the UGS-1 Dataset
3.1.2. Comparison Experiment of the UGS-2 Dataset
3.2. Ablation Experiments
3.2.1. Ablation Experiment on UGS-1 and UGS-2
3.2.2. Ablation Experiment of the Feature Engineering
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Name | Abbreviation |
| high-resolution remote sensing | HRS |
| deep learning | DL |
| urban green space | UGS |
| GaoFen-2 | GF-2 |
| Multiscale Attention Feature Aggregation Network | MAFANet |
| Normalized Difference Vegetation Index | NDVI |
| state-of- the-art | SOTA |
| multiscale pooling attention | MSPA |
| decoder block | DE |
| bilateral feature fusion | BFF |
| Global attention mechanism | GAM |
| Pyramidal convolution | Pyconv |
| Batch Normalization | BN |
| Multi-Layer Perceptron | MLP |
| convolution | conv |
| Precision | P |
| Recall | R |
| Pixel Accuracy | PA |
| Mean Pixel Accuracy | MPA |
| Intersection over Union | IOU |
| Mean Intersection over Union | MIOU |
References
- Kuang, W.; Dou, Y. Investigating the patterns and dynamics of urban green space in China’s 70 major cities using satellite remote sensing. Remote Sens. 2020, 12, 1929. [Google Scholar] [CrossRef]
- Zhang, B.; Li, N.; Wang, S. Effect of urban green space changes on the role of rainwater runoff reduction in Beijing, China. Landsc. Urban Plan. 2015, 140, 8–16. [Google Scholar] [CrossRef]
- Astell-Burt, T.; Hartig, T.; Putra, I.G.N.E.; Walsan, R.; Dendup, T.; Feng, X. Green space and loneliness: A systematic review with theoretical and methodological guidance for future research. Sci. Total Environ. 2022, 847, 157521. [Google Scholar] [CrossRef] [PubMed]
- De Ridder, K.; Adamec, V.; Bañuelos, A.; Bruse, M.; Bürger, M.; Damsgaard, O.; Dufek, J.; Hirsch, J.; Lefebre, F.; Prez-Lacorzana, J.M.; et al. An integrated methodology to assess the benefits of urban green space. Sci. Total Environ. 2004, 334, 489–497. [Google Scholar] [CrossRef] [PubMed]
- Schmidt-Traub, G.; Kroll, C.; Teksoz, K.; Durand-Delacre, D.; Sachs, J.D. National baselines for the Sustainable Development Goals assessed in the SDG Index and Dashboards. Nat. Geosci. 2017, 10, 547–555. [Google Scholar] [CrossRef]
- Chen, B.; Wu, S.; Song, Y.; Webster, C.; Xu, B.; Gong, P. Contrasting inequality in human exposure to greenspace between cities of Global North and Global South. Nat. Commun. 2022, 13, 4636. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, Y.C. Spatial–temporal dynamics of urban green space in response to rapid urbanization and greening policies. Landsc. Urban Plan. 2011, 100, 268–277. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, R.; Meadows, M.E.; Sengupta, D.; Xu, D. Changing urban green spaces in Shanghai: Trends, drivers and policy implications. Land Use Policy 2019, 87, 104080. [Google Scholar] [CrossRef]
- Wang, J.; Ma, A.; Zhong, Y.; Zheng, Z.; Zhang, L. Cross-sensor domain adaptation for high spatial resolution urban land-cover mapping: From airborne to spaceborne imagery. Remote Sens. Environ. 2022, 277, 113058. [Google Scholar] [CrossRef]
- Sun, J.; Wang, X.; Chen, A.; Ma, Y.; Cui, M.; Piao, S. NDVI indicated characteristics of vegetation cover change in China’s metropolises over the last three decades. Environ. Monit. Assess. 2011, 179, 1–14. [Google Scholar] [CrossRef]
- Jun, C.; Ban, Y.; Li, S. Open access to Earth land-cover map. Nature 2014, 514, 434. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Yang, J.; Jiang, P. Assessing impacts of urban form on landscape structure of urban green spaces in China using Landsat images based on Google Earth Engine. Remote Sens. 2018, 10, 1569. [Google Scholar] [CrossRef]
- Yang, J.; Huang, C.; Zhang, Z.; Wang, L. The temporal trend of urban green coverage in major Chinese cities between 1990 and 2010. Urban For. Urban Green. 2014, 13, 19–27. [Google Scholar] [CrossRef]
- Huang, C.; Yang, J.; Lu, H.; Huang, H.; Yu, L. Green spaces as an indicator of urban health: Evaluating its changes in 28 mega-cities. Remote Sens. 2017, 9, 1266. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Q.; Zhang, Y.; Wang, L.; Zhong, Y.; Guan, Q.; Lu, X.; Zhang, L.; Li, D. A global context-aware and batch-independent network for road extraction from VHR satellite imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 353–365. [Google Scholar] [CrossRef]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Liu, W.; Yue, A.; Shi, W.; Ji, J.; Deng, R. An automatic extraction architecture of urban green space based on DeepLabv3plus semantic segmentation model. In Proceedings of the International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019; pp. 311–315. [Google Scholar]
- Tong, X.; Xia, G.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- Cao, Y.; Huang, X. A deep learning method for building height estimation using high-resolution multi-view imagery over urban areas: A case study of 42 Chinese cities. Remote Sens. Environ. 2021, 264, 112590. [Google Scholar] [CrossRef]
- Wu, F.; Wang, C.; Zhang, H.; Li, J.; Li, L.; Chen, W.; Zhang, B. Built-up area mapping in China from GF-3 SAR imagery based on the framework of deep learning. Remote Sens. Environ. 2021, 262, 112515. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Duta, I.C.; Liu, L.; Zhu, F.; Shao, L. Pyramidal convolution: Rethinking convolutional neural networks for visual recognition. arXiv 2020, arXiv:2006.11538. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Tucker, C.J.; Pinzon, J.E.; Brown, M.E.; Slayback, D.A.; Pak, E.W.; Mahoney, R.; Vermote, E.F.; Saleous, N.E. An extended AVHRR 8-km NDVI dataset compatible with MODIS and SPOT vegetation NDVI data. Int. J. Remote Sens. 2005, 26, 4485–4498. [Google Scholar] [CrossRef]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3684–3692. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2881–2890. [Google Scholar]
- Li, H.; Xiong, P.; Fan, H.; Sun, J. Dfanet: Deep feature aggregation for real-time semantic segmentation. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9522–9531. [Google Scholar]
- Li, G.; Yun, I.; Kim, J.; Kim, J. Dabnet: Depth-wise asymmetric bottleneck for real-time semantic segmentation. arXiv 2019, arXiv:1907.11357. [Google Scholar]
- Mehta, S.; Rastegari, M.; Shapiro, L.; Hajishirzi, H. Espnetv2: A light-weight, power efficient, and general purpose convolutional neural network. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9190–9200. [Google Scholar]
- Zhang, F.; Chen, Y.; Li, Z.; Hong, Z.; Liu, J.; Ma, F.; Han, J.; Ding, E. Acfnet: Attentional class feature network for semantic segmentation. In Proceedings of the International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 6798–6807. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. Erfnet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2017, 19, 263–272. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5693–5703. [Google Scholar]
- Cheng, Y.; Wang, W.; Ren, Z.; Zhao, Y.; Liao, Y.; Ge, Y.; Wang, J.; He, J.; Gu, Y.; Wang, Y.; et al. Multi-scale Feature Fusion and Transformer Network for urban green space segmentation from high-resolution remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103514. [Google Scholar] [CrossRef]
- Yang, X.; Fan, X.; Peng, M.; Guan, Q.; Tang, L. Semantic segmentation for remote sensing images based on an AD-HRNet model. Int. J. Digit. Earth 2022, 15, 2376–2399. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, W.; Deng, X.; Zhang, M.; Cheng, Q. Multilabel remote sensing image retrieval based on fully convolutional network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 318–328. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Marinoni, A.; Liao, X. UGS-1m: Fine-grained urban green space mapping of 31 major cities in China based on the deep learning framework. Earth Syst. Sci. Data 2023, 15, 555–577. [Google Scholar] [CrossRef]
- Zhu, F.; Gao, J.; Yang, J.; Ye, N. Neighborhood linear discriminant analysis. Pattern Recognit. 2022, 123, 108422. [Google Scholar] [CrossRef]
- Zhu, F.; Zhang, W.; Chen, X.; Gao, X.; Ye, N. Large margin distribution multi-class supervised novelty detection. Expert Syst. Appl. 2023, 224, 119937. [Google Scholar] [CrossRef]
- Du, S.; Liu, X.; Chen, J.; Duan, W.; Liu, L. Addressing validation challenges for TROPOMI solar-induced chlorophyll fluorescence products using tower-based measurements and an NIRv-scaled approach. Remote Sens. Environ. 2023, 290, 113547. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Overall Results | Class IOU | ||||
|---|---|---|---|---|---|
| Method | PA (%) | MPA (%) | MIOU (%) | Low Vegetation (%) | Tree (%) |
| DensASPP(mobilenet) | 83.71 | 75.22 | 64.19 | 40.35 | 74.11 |
| ESPNetv2 | 84.94 | 75.52 | 65.68 | 41.75 | 75.63 |
| DensASPP | 85.29 | 76.10 | 66.39 | 42.81 | 76.67 |
| DFANet | 85.18 | 76.40 | 66.44 | 43.56 | 75.29 |
| ShuffleNetV2 | 86.22 | 77.73 | 68.22 | 45.74 | 77.68 |
| DeepLabv3+ | 86.31 | 78.12 | 68.38 | 45.66 | 78.08 |
| FCN8s | 87.01 | 79.49 | 69.71 | 47.35 | 79.11 |
| SegNet | 87.17 | 79.51 | 69.93 | 47.59 | 79.59 |
| HRNet | 87.53 | 78.96 | 69.97 | 46.40 | 79.92 |
| ERFNet | 87.47 | 79.22 | 70.06 | 46.95 | 79.92 |
| DABNet | 87.53 | 79.21 | 70.22 | 47.47 | 79.97 |
| ACFNet | 87.51 | 79.87 | 70.42 | 47.84 | 80.11 |
| MFFTNet | 87.97 | 79.29 | 70.55 | 46.73 | 80.54 |
| PSPNet | 87.84 | 79.99 | 70.93 | 48.66 | 80.16 |
| ResNet50 | 88.03 | 80.06 | 71.11 | 48.44 | 80.64 |
| UNet | 88.25 | 80.51 | 71.53 | 48.94 | 81.12 |
| MAFANet | 88.52 | 81.55 | 72.15 | 49.53 | 81.64 |
| Overall Results | Class IOU | ||||
|---|---|---|---|---|---|
| Method | PA (%) | MPA (%) | MIOU (%) | Low Vegetation (%) | Tree (%) |
| DensASPP (mobilenet) | 84.73 | 75.48 | 64.89 | 38.62 | 73.85 |
| DFANet | 87.30 | 77.48 | 68.37 | 41.05 | 78.29 |
| ESPNetv2 | 88.07 | 77.67 | 69.43 | 42.40 | 80.08 |
| DensASPP | 88.45 | 78.73 | 70.58 | 45.00 | 80.80 |
| DeepLabv3+ | 88.53 | 79.63 | 70.88 | 44.94 | 81.06 |
| ShuffleNetV2 | 88.26 | 80.53 | 71.43 | 48.45 | 80.43 |
| FCN8s | 88.87 | 79.87 | 71.58 | 46.57 | 81.27 |
| HRNet | 89.21 | 80.41 | 72.24 | 47.45 | 81.92 |
| ERFNet | 89.42 | 80.81 | 72.71 | 48.25 | 82.11 |
| DABNet | 89.34 | 81.18 | 72.97 | 49.71 | 81.73 |
| ACFNet | 89.47 | 81.81 | 73.35 | 50.29 | 82.06 |
| PSPNet | 89.61 | 81.48 | 73.37 | 49.87 | 82.61 |
| SegNet | 89.59 | 81.49 | 73.40 | 50.17 | 82.49 |
| ResNet50 | 89.84 | 81.70 | 73.82 | 50.71 | 82.68 |
| MFFTNet | 89.82 | 82.27 | 74.01 | 51.24 | 82.63 |
| UNet | 89.97 | 82.29 | 74.09 | 50.71 | 83.28 |
| MAFANet | 90.19 | 83.10 | 74.64 | 51.43 | 83.72 |
| Class IOU | |||
|---|---|---|---|
| Method | MIOU (%) | Low Vegetation (%) | Tree (%) |
| baseline | 71.11 | 48.44 | 80.64 |
| baseline+ DE | 71.44 | 48.85 | 80.76 |
| baseline+ DE+ BFF | 71.98 | 49.22 | 81.60 |
| baseline+ DE+ BFF+ Pyconv | 71.80 | 49.14 | 81.34 |
| baseline+ DE+ BFF+ GAM | 71.76 | 48.69 | 81.53 |
| baseline+ DE+ BFF+ MSPA | 72.15 | 49.53 | 81.64 |
| Class IOU | |||
|---|---|---|---|
| Method | MIOU (%) | Low Vegetation (%) | Tree (%) |
| baseline | 73.82 | 50.71 | 82.68 |
| baseline+ DE | 74.15 | 50.97 | 83.00 |
| baseline+ DE+ BFF | 74.21 | 51.23 | 83.24 |
| baseline+ DE+ BFF+ Pyconv | 74.46 | 51.24 | 83.43 |
| baseline+ DE+ BFF+ GAM | 74.48 | 51.11 | 83.71 |
| baseline+ DE+ BFF+ MSPA | 74.64 | 51.43 | 83.72 |
| Class IOU | ||||
|---|---|---|---|---|
| Data | Method | MIOU (%) | Low Vegetation (%) | Tree (%) |
| NDVI | UNet | 69.58 | 41.84 | 79.83 |
| MAFANet | 71.10 | 46.26 | 80.38 | |
| UGS-1 | UNet | 71.53 | 48.94 | 81.12 |
| MAFANet | 72.15 | 49.53 | 81.64 | |
| UGS-1+NDVI | UNet | 73.48 | 49.61 | 82.71 |
| MAFANet | 74.09 | 50.67 | 83.34 | |
| UGS-2 | UNet | 74.09 | 50.71 | 83.28 |
| MAFANet | 74.64 | 51.43 | 83.72 | |
| UGS-2+NDVI | UNet | 74.11 | 50.89 | 83.26 |
| MAFANet | 74.73 | 50.96 | 84.05 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Cheng, Y.; Ren, Z.; He, J.; Zhao, Y.; Wang, J.; Zhang, W. A Novel Hybrid Method for Urban Green Space Segmentation from High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 5472. https://doi.org/10.3390/rs15235472
Wang W, Cheng Y, Ren Z, He J, Zhao Y, Wang J, Zhang W. A Novel Hybrid Method for Urban Green Space Segmentation from High-Resolution Remote Sensing Images. Remote Sensing. 2023; 15(23):5472. https://doi.org/10.3390/rs15235472
Chicago/Turabian StyleWang, Wei, Yong Cheng, Zhoupeng Ren, Jiaxin He, Yingfen Zhao, Jun Wang, and Wenjie Zhang. 2023. "A Novel Hybrid Method for Urban Green Space Segmentation from High-Resolution Remote Sensing Images" Remote Sensing 15, no. 23: 5472. https://doi.org/10.3390/rs15235472
APA StyleWang, W., Cheng, Y., Ren, Z., He, J., Zhao, Y., Wang, J., & Zhang, W. (2023). A Novel Hybrid Method for Urban Green Space Segmentation from High-Resolution Remote Sensing Images. Remote Sensing, 15(23), 5472. https://doi.org/10.3390/rs15235472