
Learning to Adapt Adversarial Perturbation Consistency for Domain Adaptive Semantic Segmentation of Remote Sensing Images

 , , and
, , and
Abstract
:1. Introduction
- We propose an AdvCDA method for high-resolution RSIs based on adversarial perturbation consistency. The method combines AT and ST strategies to provide feature perturbation information through interdomain alignment in order to improve the domain generalization of the model during the ST process. Moreover, the ST method provides high-quality labels that maintain the predictive consistency of the model during AT, thus alleviating the over robustness that is prone to arise during domain alignment.
- We propose a confidence estimation mechanism to determine the learning weights of the weak-to-strong consistency stream and the adversarial perturbation consistency stream so that the model can adaptively adjust the optimization direction according to different scenarios. Our method has been effectively demonstrated in various domain discrepancy scenarios of high-resolution RSIs.
2. Related Works
2.1. Image-Level Alignment for UDA
2.2. Feature-Level Alignment by AT
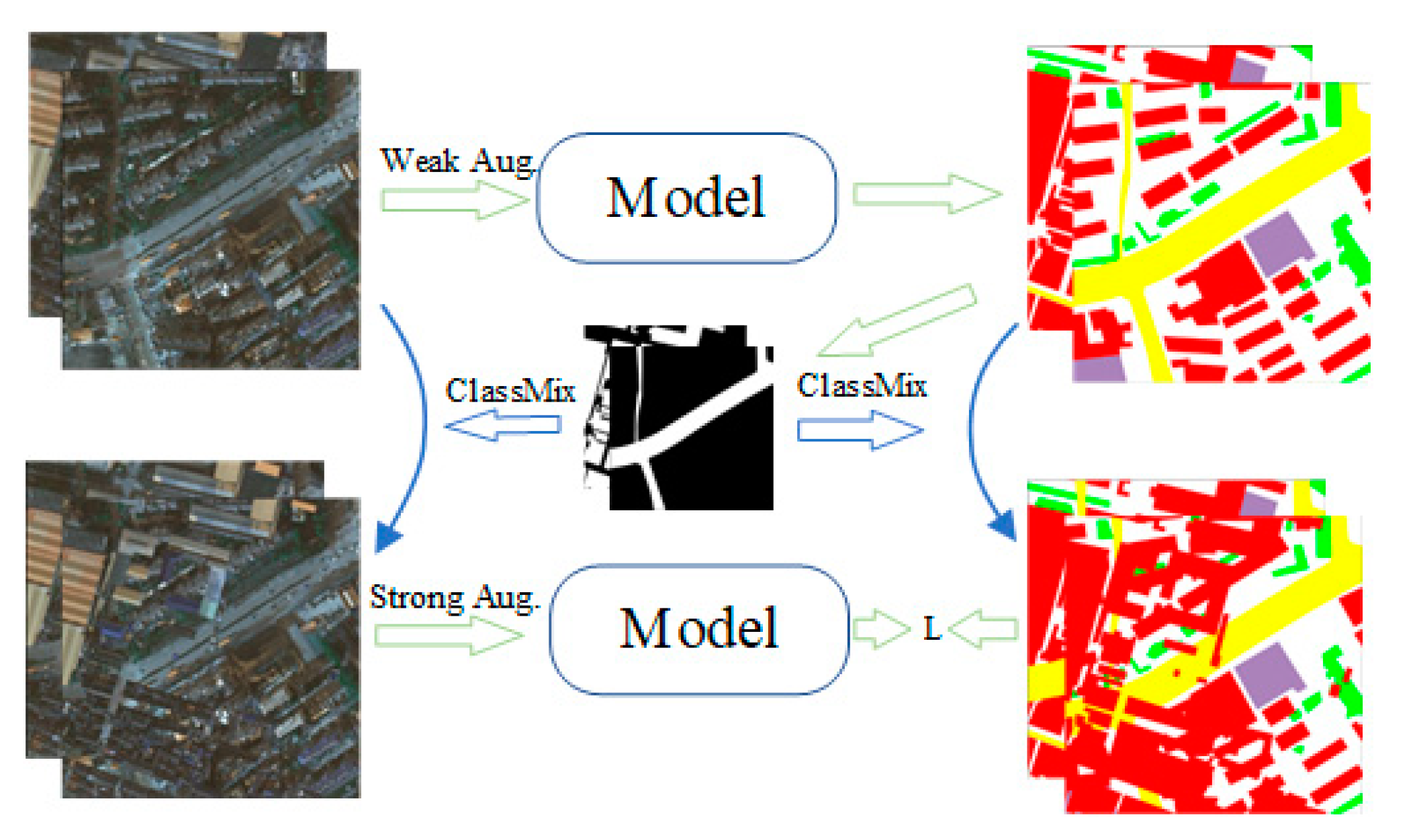
2.3. Self-Training for UDA
2.4. Consistency Regularization
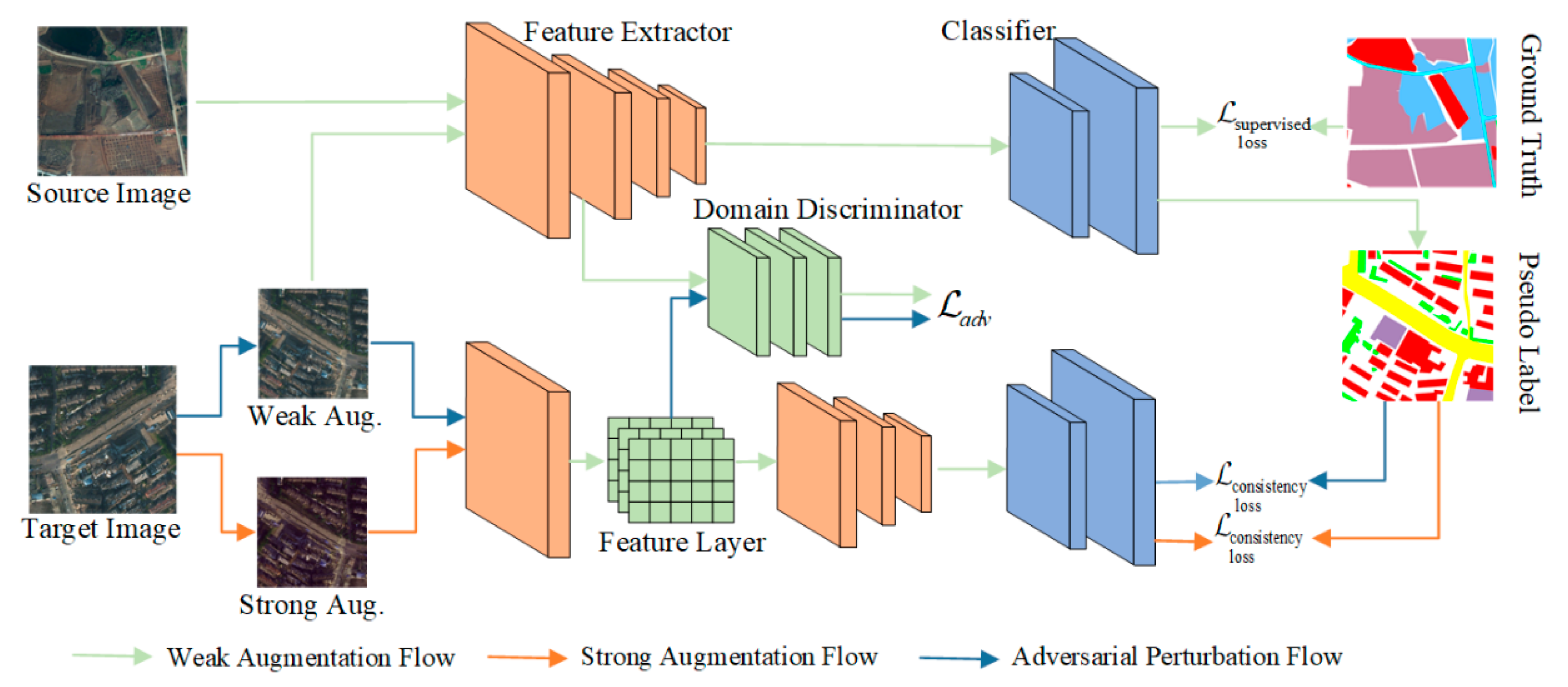
3. Materials and Methods
3.1. Preliminaries
- (1)
- First, and of the segmentation network are frozen, and only the determination network is optimized, which improves the domain discrimination ability of the discriminator to distinguish the output features of different domains:where and are feature extractors whose inputs are source images and target images . d denotes the domain indicator, where 0 denotes the source domain, and 1 denotes the target domain. and denote the output probability that discriminator determines; the input comes from the source and target domains, respectively.
- (2)
- The segmentation network G not only conducts supervised training tasks with labeled source domains, but also participates in the AT process. Specifically, the adversarial loss is as follows, and this process is achieved by fixing the discriminative network D and optimizing F and C of the segmentation network.
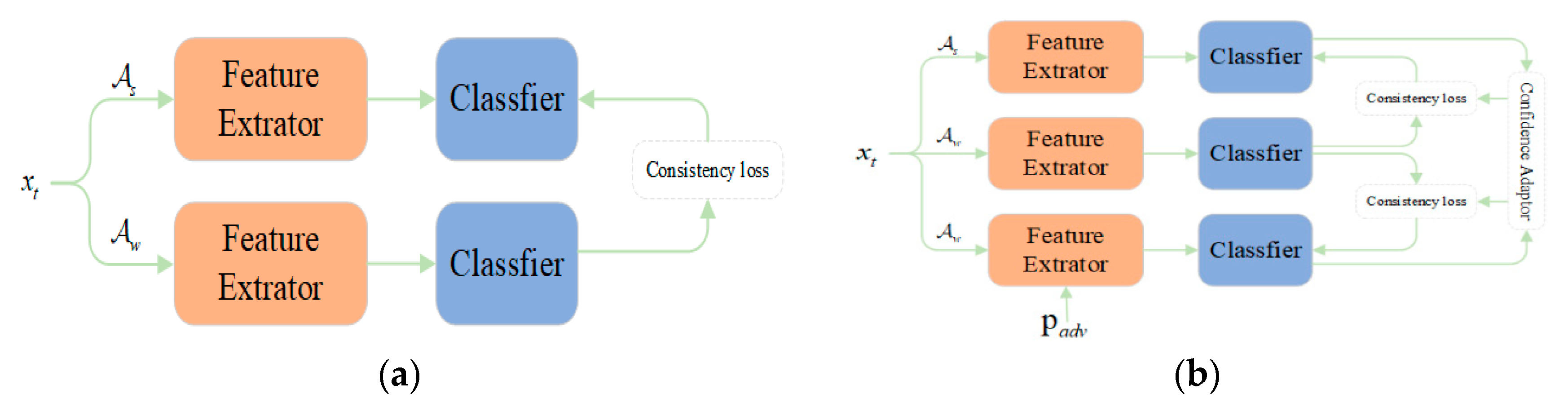
3.2. Adversarial Perturbations Consistency
3.3. Confidence Estimation Mechanism
4. Experimental Results and Discussion
4.1. Dataset Description
4.2. Experimental Settings and Evaluation Metrics
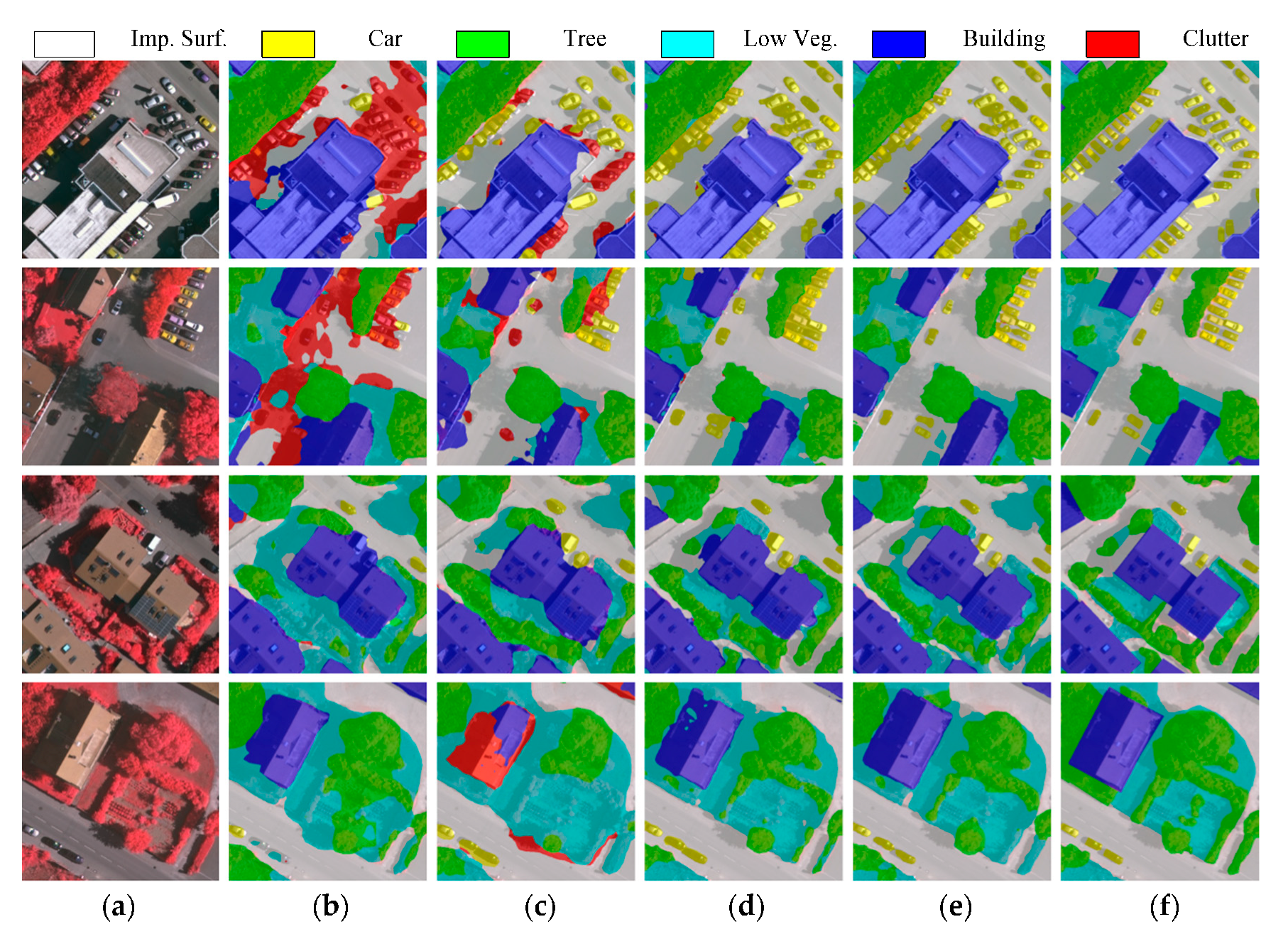
4.3. Comparisons with Other Methods
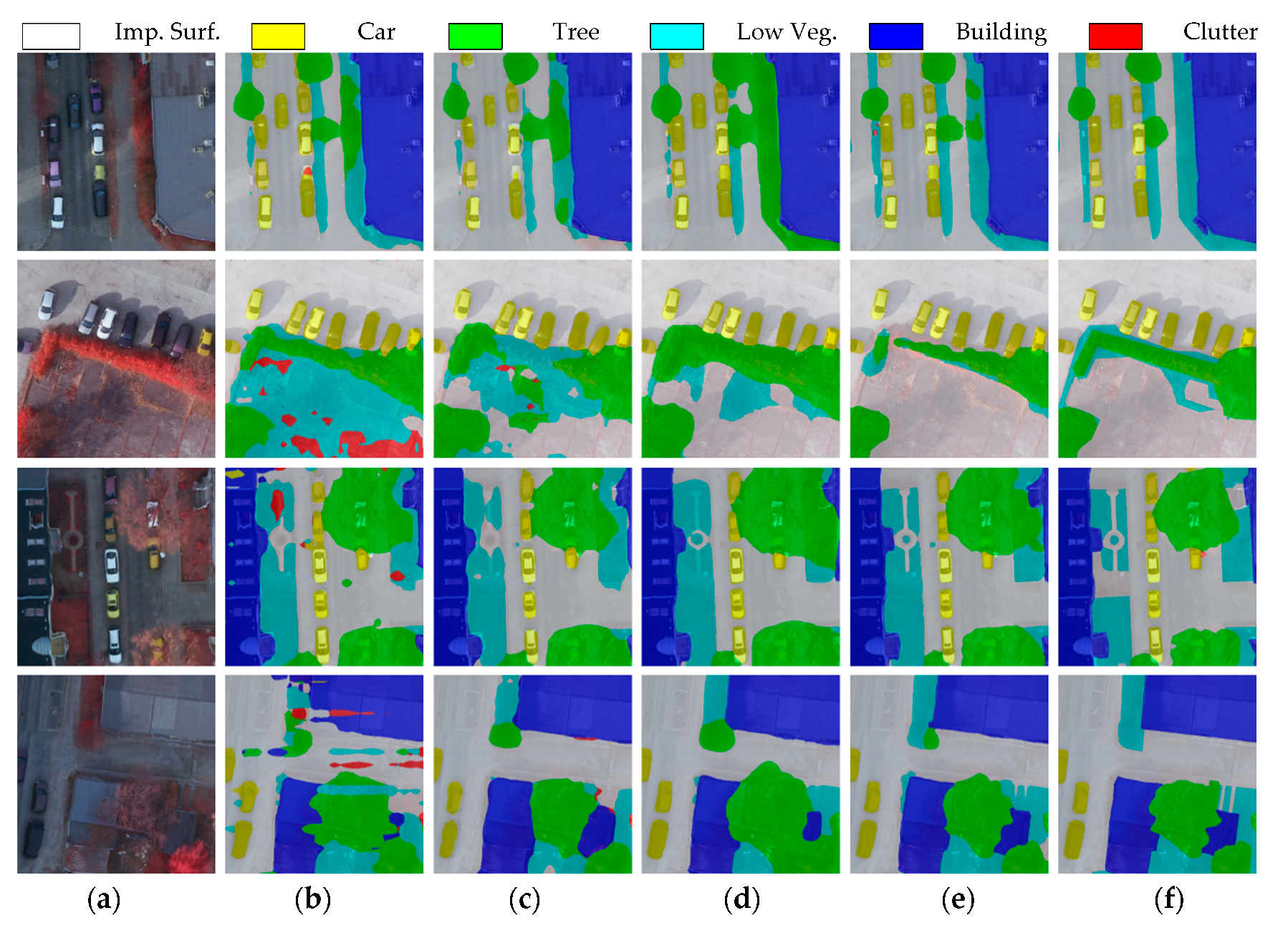
4.3.1. Cross-Space Scenarios
4.3.2. Cross-Spectral Scenarios
4.3.3. Complex Domain Discrepancy Scenarios
4.4. Ablation Study and Analysis
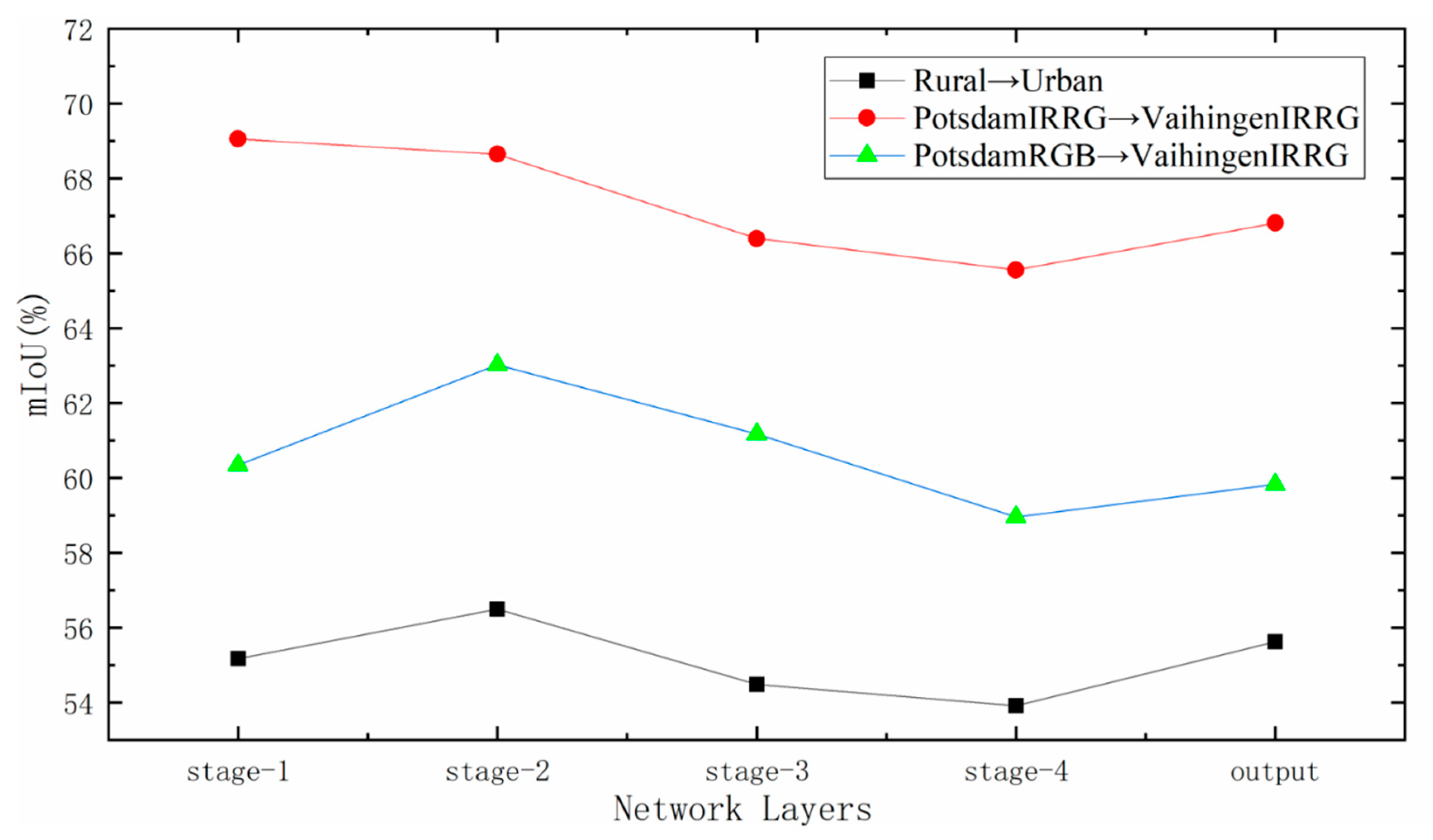
4.4.1. Design of Feature Alignment
4.4.2. Effectiveness Analysis of Each Component
4.4.3. Effectiveness of Augmentation Perturbation Strategies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, Q.; Sun, X.; Zhong, Y.; Zhang, L. High-Resolution Remote Sensing Image Scene Understanding: A Review. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3061–3064. [Google Scholar] [CrossRef]
- Kotaridis, I.; Lazaridou, M. Remote Sensing Image Segmentation Advances: A Meta-Analysis. ISPRS J. Photogramm. Remote Sens. 2021, 173, 309–322. [Google Scholar] [CrossRef]
- Zhao, C.; Qin, B.; Feng, S.; Zhu, W.; Sun, W.; Li, W.; Jia, X. Hyperspectral Image Classification with Multi-Attention Transformer and Adaptive Superpixel Segmentation-Based Active Learning. IEEE Trans. Image Process. 2023, 32, 3606–3621. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Zhu, W.; Feng, S. Superpixel Guided Deformable Convolution Network for Hyperspectral Image Classification. IEEE Trans. Image Process. 2022, 31, 3838–3851. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Li, S.; Chen, Z.; Chanussot, J.; Jia, X.; Zhang, B.; Li, B.; Chen, P. An Attention-Fused Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 177, 238–262. [Google Scholar] [CrossRef]
- Marcos, D.; Volpi, M.; Kellenberger, B.; Tuia, D. Land Cover Mapping at Very High Resolution with Rotation Equivariant CNNs: Towards Small yet Accurate Models. ISPRS J. Photogramm. Remote Sens. 2018, 145, 96–107. [Google Scholar] [CrossRef]
- Soto Vega, P.J.; da Costa, G.A.O.P.; Feitosa, R.Q.; Ortega Adarme, M.X.; de Almeida, C.A.; Heipke, C.; Rottensteiner, F. An Unsupervised Domain Adaptation Approach for Change Detection and Its Application to Deforestation Mapping in Tropical Biomes. ISPRS J. Photogramm. Remote Sens. 2021, 181, 113–128. [Google Scholar] [CrossRef]
- Deng, Y.; Chen, J.; Yi, S.; Yue, A.; Meng, Y.; Chen, J.; Zhang, Y. Feature-Guided Multitask Change Detection Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9667–9679. [Google Scholar] [CrossRef]
- Wilson, G.; Cook, D.J. A Survey of Unsupervised Deep Domain Adaptation. arXiv 2018, arXiv:1812.02849. [Google Scholar] [CrossRef]
- Zhao, C.; Qin, B.; Feng, S.; Zhu, W.; Zhang, L.; Ren, J. An Unsupervised Domain Adaptation Method Towards Multi-Level Features and Decision Boundaries for Cross-Scene Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Jiang, Z.; Li, Y.; Yang, C.; Gao, P.; Wang, Y.; Tai, Y.; Wang, C. Prototypical Contrast Adaptation for Domain Adaptive Semantic Segmentation. arXiv 2022, arXiv:2207.06654. [Google Scholar]
- Yan, L.; Fan, B.; Xiang, S.; Pan, C. Adversarial Domain Adaptation with a Domain Similarity Discriminator for Semantic Segmentation of Urban Areas. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1583–1587. [Google Scholar] [CrossRef]
- Liu, W.; Su, F. Unsupervised Adversarial Domain Adaptation Network for Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1978–1982. [Google Scholar] [CrossRef]
- Tong, X.Y.; Xia, G.S.; Zhu, X.X. Enabling Country-Scale Land Cover Mapping with Meter-Resolution Satellite Imagery. ISPRS J. Photogramm. Remote Sens. 2023, 196, 178–196. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Zhang, J.; Du, B.; Tao, D.; Zhang, L. Scaling-up Remote Sensing Segmentation Dataset with Segment Anything Model. arXiv 2023, arXiv:2305.02034. [Google Scholar]
- Zhang, L.; Xia, G.S.; Wu, T.; Lin, L.; Tai, X.C. Deep Learning for Remote Sensing Image Understanding. J. Sens. 2016, 2016, 7954154. [Google Scholar] [CrossRef]
- Tasar, O.; Happy, S.L.; Tarabalka, Y.; Alliez, P. ColorMapGAN: Unsupervised Domain Adaptation for Semantic Segmentation Using Color Mapping Generative Adversarial Networks. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7178–7193. [Google Scholar] [CrossRef]
- Jiang, J.; Shu, Y.; Wang, J.; Long, M. Transferability in Deep Learning: A Survey. arXiv 2022, arXiv:2201.05867. [Google Scholar]
- Zhao, S.; Yue, X.; Zhang, S.; Li, B.; Zhao, H.; Wu, B.; Krishna, R.; Gonzalez, J.E.; Sangiovanni-Vincentelli, A.L.; Seshia, S.A.; et al. A Review of Single-Source Deep Unsupervised Visual Domain Adaptation. IEEE Trans. Neural Networks Learn. Syst. 2022, 33, 473–493. [Google Scholar] [CrossRef]
- Bai, L.; Du, S.; Zhang, X.; Wang, H.; Liu, B.; Ouyang, S. Domain Adaptation for Remote Sensing Image Semantic Segmentation: An Integrated Approach of Contrastive Learning and Adversarial Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–3. [Google Scholar] [CrossRef]
- Tuia, D.; Persello, C.; Bruzzone, L. Recent Advances in Domain Adaptation for the Classification of Remote Sensing Data. IEEE Geosci. Remote Sens. Mag. 2021, 4, 41–57. [Google Scholar] [CrossRef]
- Zhao, Y.; Guo, P.; Sun, Z.; Chen, X.; Gao, H. ResiDualGAN: Resize-Residual DualGAN for Cross-Domain Remote Sensing Images Semantic Segmentation. Remote Sens. 2023, 15, 1428. [Google Scholar] [CrossRef]
- Deng, X.; Zhu, Y.; Tian, Y.; Newsam, S. Scale Aware Adaptation for Land-Cover Classification in Remote Sensing Imagery. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 2159–2168. [Google Scholar] [CrossRef]
- Zhao, Q.; Lyu, S.; Liu, B.; Chen, L.; Zhao, H. Self-Training Guided Disentangled Adaptation for Cross-Domain Remote Sensing Image Semantic Segmentation. arXiv 2023, arXiv:2301.05526. [Google Scholar]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to Adapt Structured Output Space for Semantic Segmentation. arXiv 2018, arXiv:1802.10349. [Google Scholar]
- Zou, Y.; Yu, Z.; Vijaya Kumar, B.V.K.; Wang, J. Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training. In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 297–313. [Google Scholar] [CrossRef]
- Mei, K.; Zhu, C.; Zou, J.; Zhang, S. Instance Adaptive Self-Training for Unsupervised Domain Adaptation. In Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 415–430. [Google Scholar] [CrossRef]
- Lai, X.; Tian, Z.; Xu, X.; Chen, Y.; Liu, S.; Zhao, H.; Wang, L.; Jia, J. DecoupleNet: Decoupled Network for Domain Adaptive Semantic Segmentation. In Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 369–387. [Google Scholar] [CrossRef]
- Chen, R.; Rong, Y.; Guo, S.; Han, J.; Sun, F.; Xu, T.; Huang, W. Smoothing Matters: Momentum Transformer for Domain Adaptive Semantic Segmentation. arXiv 2022, arXiv:2203.07988. [Google Scholar]
- Sohn, K.; Berthelot, D.; Zizhao, C.L.; Nicholas, Z.; Cubuk, E.D.; Kurakin, A.; Zhang, H.; Raffel, C. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. arXiv 2020, arXiv:2001.07685. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical Automated Data Augmentation with a Reduced Search Space. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 3008–3017. [Google Scholar] [CrossRef]
- Olsson, V. ClassMix: Segmentation-Based Data Augmentation for Semi-Supervised Learning. arXiv 2020, arXiv:2007.07936. [Google Scholar]
- Xu, Q.; Ma, Y.; Wu, J.; Long, C.; Huang, X. CDAda: A Curriculum Domain Adaptation for Nighttime Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2962–2971. [Google Scholar] [CrossRef]
- Tasar, O.; Happy, S.L.; Tarabalka, Y.; Alliez, P. SEMI2I: Semantically Consistent Image-to-Image Translation for Domain Adaptation of Remote Sensing Data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1837–1840. [Google Scholar] [CrossRef]
- Hoffman, J.; Tzeng, E.; Park, T.; Phillip, J.Z.; Kate, I.; Alexei, S.; Darrell, T.; Chang, W.G.W.L.; Wang, H.P.; Peng, W.H.; et al. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7346–7354. [Google Scholar]
- Tasar, O.; Giros, A.; Tarabalka, Y.; Alliez, P.; Clerc, S. DAugNet: Unsupervised, Multisource, Multitarget, and Life-Long Domain Adaptation for Semantic Segmentation of Satellite Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1067–1081. [Google Scholar] [CrossRef]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2868–2876. [Google Scholar] [CrossRef]
- Yang, Y.; Soatto, S. FDA: Fourier Domain Adaptation for Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4084–4094. [Google Scholar] [CrossRef]
- Peng, D.; Guan, H.; Zang, Y.; Bruzzone, L. Full-Level Domain Adaptation for Building Extraction in Very-High-Resolution Optical Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. Adv. Comput. Vis. Pattern Recognit. 2017, 17, 189–209. [Google Scholar] [CrossRef]
- Wang, H.; Shen, T.; Zhang, W.; Duan, L.Y.; Mei, T. Classes Matter: A Fine-Grained Adversarial Approach to Cross-Domain Semantic Segmentation. In Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 1–17. [Google Scholar] [CrossRef]
- Xu, Q.; Yuan, X.; Ouyang, C. Class-Aware Domain Adaptation for Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 60, 1–18. [Google Scholar] [CrossRef]
- Chen, J.; Zhu, J.; Guo, Y.; Sun, G.; Zhang, Y.; Deng, M. Unsupervised Domain Adaptation for Semantic Segmentation of High-Resolution Remote Sensing Imagery Driven by Category-Certainty Attention. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Wang, J. Cross-Domain Road Detection Based on Global-Local Adversarial Learning Framework from Very High Resolution Satellite Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 180, 296–312. [Google Scholar] [CrossRef]
- Chapelle, O.; Schölkopf, B.; Zien, E.A. Semi-Supervised Learning. IEEE Trans. Neural Netw. 2009, 20, 2015975. [Google Scholar]
- Zhang, P.; Zhang, B.; Zhang, T.; Chen, D.; Wang, Y.; Wen, F. Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation. arXiv 2021, arXiv:2101.10979. [Google Scholar]
- Vayyat, M.; Kasi, J.; Bhattacharya, A.; Ahmed, S.; Tallamraju, R. CLUDA: Contrastive Learning in Unsupervised Domain Adaptation for Semantic Segmentation. arXiv 2022, arXiv:2208.14227. [Google Scholar]
- Zhang, L.; Lan, M.; Zhang, J.; Tao, D. Stagewise Unsupervised Domain Adaptation With Adversarial Self-Training for Road Segmentation of Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Chen, X.; Yuan, Y.; Zeng, G.; Wang, J. Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2613–2622. [Google Scholar] [CrossRef]
- Yang, L.; Qi, L.; Feng, L.; Zhang, W.; Shi, Y. Revisiting Weak-to-Strong Consistency in Semi-Supervised Semantic Segmentation. arXiv 2022, arXiv:2208.09910. [Google Scholar]
- Kuo, C.W.; Ma, C.Y.; Huang, J.B.; Kira, Z. FeatMatch: Feature-Based Augmentation for Semi-Supervised Learning. In Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 479–495. [Google Scholar] [CrossRef]
- Liu, Y.; Tian, Y.; Chen, Y.; Liu, F.; Belagiannis, V.; Carneiro, G. Perturbed and Strict Mean Teachers for Semi-Supervised Semantic Segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4248–4257. [Google Scholar] [CrossRef]
- Xi, Z.; He, X.; Meng, Y.; Yue, A.; Chen, J.; Deng, Y.; Chen, J. A Multilevel-Guided Curriculum Domain Adaptation Approach to Semantic Segmentation for High-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, M.T.; Le, Q.V. Unsupervised Data Augmentation for Consistency Training. arXiv 2020, arXiv:1904.12848. [Google Scholar]
- Kim, J.; Min, Y.; Kim, D.; Lee, G.; Seo, J.; Ryoo, K.; Kim, S. ConMatch: Semi-Supervised Learning with Confidence-Guided Consistency Regularization. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXII. Springer: Berlin/Heidelberg, Germany, 2022; pp. 674–690. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation. arXiv 2021, arXiv:2111.14887. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation. arXiv 2022, arXiv:2204.13132. [Google Scholar]
- Mittal, S.; Tatarchenko, M.; Brox, T. Semi-Supervised Semantic Segmentation with High- And Low-Level Consistency. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1369–1379. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014; pp. 1–10. [Google Scholar]
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6022–6031. [Google Scholar] [CrossRef]
- Gao, H.; Zhao, Y.; Guo, P.; Sun, Z.; Chen, X.; Tang, Y. Cycle and Self-Supervised Consistency Training for Adapting Semantic Segmentation of Aerial Images. Remote Sens. 2022, 14, 1527. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Wu, L.; Lu, M.; Fang, L. Deep Covariance Alignment for Domain Adaptive Remote Sensing Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhang, B.; Chen, T.; Wang, B. Curriculum-Style Local-to-Global Adaptation for Cross-Domain Remote Sensing Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Liu, W.; Su, F.; Jin, X.; Li, H.; Qin, R. Bispace Domain Adaptation Network for Remotely Sensed Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Lian, Q.; Lv, F.; Duan, L.; Gong, B. Constructing Self-Motivated Pyramid Curriculums for Cross-Domain Semantic Segmentation: A Non-Adversarial Approach. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6758–6767. [Google Scholar]
- Tranheden, W.; Olsson, V.; Pinto, J.; Svensson, L. DACS: Domain Adaptation via Cross-Domain Mixed Sampling. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual, 5–9 January 2021; pp. 1378–1388. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Architecture | Impervious Surfaces | Car | Tree | Low Vegetation | Building | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | mIoU | mFscore | ||
| AdaptSegNet [25] | ResNet-Based | 54.39 | 70.39 | 6.40 | 11.99 | 52.65 | 68.96 | 28.98 | 44.91 | 63.14 | 77.40 | 41.11 | 54.73 |
| FADA [41] | 60.01 | 75.00 | 26.79 | 42.25 | 58.06 | 73.46 | 47.23 | 64.16 | 70.96 | 83.01 | 52.61 | 67.58 | |
| DualGAN [37] | 49.41 | 66.13 | 34.34 | 51.09 | 57.66 | 73.14 | 38.87 | 55.97 | 62.30 | 76.77 | 48.52 | 64.62 | |
| ResiDualGAN [22] | 72.29 | 83.89 | 57.01 | 72.51 | 63.81 | 77.88 | 49.69 | 66.29 | 80.57 | 89.23 | 64.67 | 77.96 | |
| Zhang et al. [66] | 67.74 | 80.13 | 44.90 | 61.94 | 55.03 | 71.90 | 47.02 | 64.16 | 76.75 | 86.65 | 58.29 | 72.96 | |
| ST-DASegNet [24] | Transformer-based | 74.43 | 85.36 | 43.38 | 60.49 | 67.36 | 80.49 | 48.57 | 65.37 | 85.23 | 92.03 | 63.79 | 76.75 |
| DAFormer [56] | 76.01 | 86.54 | 51.40 | 70.69 | 68.43 | 80.62 | 51.23 | 67.81 | 81.99 | 88.40 | 65.81 | 78.81 | |
| AdvCDA | 77.19 | 87.13 | 61.63 | 76.26 | 65.78 | 79.36 | 52.21 | 68.60 | 86.44 | 92.73 | 68.65 | 80.82 | |
| Method | Arch. | Background | Building | Road | Water | Barren | Forest | Agriculture | mIoU |
|---|---|---|---|---|---|---|---|---|---|
| SegFormer [64] | baseline | 47.14 | 53.28 | 55.50 | 52.93 | 18.52 | 35.37 | 28.97 | 41.67 |
| AdaptSegNet [25] | AT | 42.35 | 23.73 | 15.61 | 81.95 | 13.62 | 28.70 | 22.05 | 32.68 |
| FADA [41] | AT | 43.89 | 12.62 | 12.76 | 80.37 | 12.70 | 32.76 | 24.79 | 31.41 |
| PyCDA [68] | ST | 38.04 | 35.86 | 45.51 | 74.87 | 7.71 | 40.39 | 11.39 | 36.25 |
| CBST [26] | ST | 48.37 | 46.10 | 35.79 | 80.05 | 19.18 | 29.69 | 30.05 | 41.32 |
| IAST [27] | ST | 48.57 | 31.51 | 28.73 | 86.01 | 20.29 | 31.77 | 36.50 | 40.48 |
| DCA [63] | ST | 45.82 | 49.60 | 51.65 | 80.88 | 16.70 | 42.93 | 36.92 | 46.36 |
| DAFormer [56] | ST | 50.94 | 56.66 | 62.83 | 89.41 | 11.99 | 45.81 | 25.26 | 48.99 |
| ST-DASegNet [24] | AT + ST | 51.01 | 54.23 | 60.52 | 87.31 | 15.18 | 47.43 | 36.26 | 50.28 |
| AdvCDA | AT + ST | 50.81 | 56.12 | 58.38 | 87.87 | 15.85 | 41.88 | 44.40 | 50.76 |
| Method | Architecture | Impervious Surfaces | Car | Tree | Low Vegetation | Building | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | mIoU | mFscore | ||
| AdaptSegNet [25] | ResNet-Based | 73.80 | 84.92 | 69.56 | 82.05 | 67.18 | 80.37 | 51.19 | 67.71 | 80.81 | 89.39 | 68.51 | 80.89 |
| FADA [41] | 75.91 | 86.31 | 66.83 | 80.12 | 68.77 | 81.49 | 62.06 | 76.59 | 83.97 | 91.28 | 71.51 | 83.16 | |
| PyCDA [68] | 76.41 | 86.62 | 73.69 | 84.85 | 69.31 | 81.87 | 63.49 | 77.67 | 82.70 | 90.53 | 73.12 | 84.31 | |
| IAST [27] | 76.20 | 86.49 | 66.81 | 80.10 | 68.26 | 81.14 | 54.29 | 70.37 | 83.67 | 91.11 | 69.85 | 81.84 | |
| DACS [69] | 74.09 | 85.12 | 71.16 | 83.15 | 66.83 | 90.11 | 63.44 | 77.63 | 81.14 | 89.59 | 71.33 | 85.12 | |
| DecoupleNet [28] | 76.21 | 86.50 | 72.97 | 84.37 | 68.10 | 81.02 | 59.50 | 74.61 | 82.25 | 90.26 | 71.81 | 83.35 | |
| DAFormer [56] | Transformer-based | 77.94 | 87.28 | 86.59 | 90.02 | 71.57 | 83.80 | 67.94 | 81.99 | 80.23 | 90.09 | 76.85 | 86.64 |
| AdvCDA | 80.06 | 88.92 | 81.72 | 89.94 | 68.66 | 81.42 | 73.56 | 84.76 | 88.32 | 93.80 | 78.46 | 87.77 | |
| Method | Architecture | Impervious Surfaces | Car | Tree | Low Vegetation | Building | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | mIoU | mFscore | ||
| AdaptSegNet [25] | ResNet-Based | 51.26 | 67.77 | 10.25 | 18.54 | 51.51 | 68.02 | 12.75 | 22.61 | 60.72 | 75.55 | 37.30 | 50.50 |
| FADA [41] | 56.66 | 72.34 | 27.36 | 42.97 | 34.39 | 51.18 | 36.34 | 53.31 | 65.89 | 79.44 | 44.13 | 59.85 | |
| ProDA [46] | 49.04 | 66.11 | 31.56 | 48.16 | 49.11 | 65.86 | 32.44 | 49.06 | 68.94 | 81.89 | 46.22 | 62.22 | |
| Bai et al. [56] | 62.40 | 76.90 | 38.90 | 56.00 | 53.90 | 70.00 | 35.10 | 51.90 | 74.80 | 85.60 | 53.02 | 68.08 | |
| DualGAN [37] | 49.16 | 61.33 | 40.31 | 57.88 | 55.82 | 70.66 | 27.85 | 42.17 | 65.44 | 83.00 | 47.72 | 63.01 | |
| ResiDualGAN [22] | 55.54 | 71.36 | 48.49 | 65.19 | 57.79 | 73.21 | 29.15 | 44.97 | 78.97 | 88.23 | 53.99 | 68.59 | |
| Zhang et al. [66] | 64.47 | 77.76 | 43.43 | 60.05 | 52.83 | 69.62 | 38.37 | 55.94 | 76.87 | 86.95 | 55.19 | 70.06 | |
| DAFormer [56] | Transformer-based | 58.85 | 75.50 | 46.33 | 65.54 | 62.94 | 79.49 | 18.89 | 27.46 | 74.20 | 86.50 | 52.24 | 66.90 |
| ST-DASegNet [24] | 68.36 | 81.28 | 43.15 | 60.28 | 64.65 | 78.31 | 34.69 | 47.08 | 84.09 | 91.33 | 58.99 | 71.66 | |
| AdvCDA | 72.31 | 83.93 | 61.69 | 76.31 | 61.54 | 76.19 | 34.34 | 51.12 | 85.25 | 92.04 | 63.02 | 75.92 | |
| Methods | FixMatch | Lce | Ladv | AdvC | CB | mIoU |
|---|---|---|---|---|---|---|
| SourceOnly | ✔ | 56.30 | ||||
| FixMatch + ClassMix | ✔ | ✔ | 61.43 | |||
| AdvCDA (w/o AdvC) | ✔ | ✔ | ✔ | 62.29 | ||
| AdvCDA (w/o CB) | ✔ | ✔ | ✔ | ✔ | 65.55 | |
| AdvCDA | ✔ | ✔ | ✔ | ✔ | ✔ | 68.65 |
| Target-only | - | - | - | - | 76.10 |
| Augmentation Strategy | mIoUPotsdamRGB→VaihingenIRRG | mIoUrural→urban(val) |
|---|---|---|
| Baseline | 60.35 | 54.58 |
| Baseline (w/CutMix) | 59.83 | 54.15 |
| Baseline (w/ClassMix) | 61.18 | 55.33 |
| RA (w/o ClassMix) | 62.83 | 55.60 |
| RA (w/ClassMix) | 63.02 | 56. 17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xi, Z.; Meng, Y.; Chen, J.; Deng, Y.; Liu, D.; Kong, Y.; Yue, A. Learning to Adapt Adversarial Perturbation Consistency for Domain Adaptive Semantic Segmentation of Remote Sensing Images. Remote Sens. 2023, 15, 5498. https://doi.org/10.3390/rs15235498
Xi Z, Meng Y, Chen J, Deng Y, Liu D, Kong Y, Yue A. Learning to Adapt Adversarial Perturbation Consistency for Domain Adaptive Semantic Segmentation of Remote Sensing Images. Remote Sensing. 2023; 15(23):5498. https://doi.org/10.3390/rs15235498
Chicago/Turabian StyleXi, Zhihao, Yu Meng, Jingbo Chen, Yupeng Deng, Diyou Liu, Yunlong Kong, and Anzhi Yue. 2023. "Learning to Adapt Adversarial Perturbation Consistency for Domain Adaptive Semantic Segmentation of Remote Sensing Images" Remote Sensing 15, no. 23: 5498. https://doi.org/10.3390/rs15235498
APA StyleXi, Z., Meng, Y., Chen, J., Deng, Y., Liu, D., Kong, Y., & Yue, A. (2023). Learning to Adapt Adversarial Perturbation Consistency for Domain Adaptive Semantic Segmentation of Remote Sensing Images. Remote Sensing, 15(23), 5498. https://doi.org/10.3390/rs15235498