
A Transformer-Based Neural Network with Improved Pyramid Pooling Module for Change Detection in Ecological Redline Monitoring

Abstract
:1. Introduction
- A Siamese self-supervised learning network is constructed using the idea of contrast. The original image and the data-augmented image are used as two inputs to the network, and the classification of each data augmentation is the output. By training with a large amount of unlabeled remote sensing data from the study area, a set of pre-trained models for loading into subsequent supervised networks is finally obtained. We have verified through experiments that this method helps the proposed network better adapted to remote sensing change detection;
- Based on the idea of Swin-T and multi-scale fusion, a self-attention mechanism-based pyramid pooling module SPPM is constructed and applied to the Siamese Swin-UNet network adopted in this experiment. The self-attention module can better utilize global information to obtain more complete features, while the multi-scale fusion method can maximize the use of the information of each pixel and reduce the loss of key features;
- We apply the Siamese Swin-UNet network using a special pre-trained model and improved pooling module SPPM to the problem of remote sensing change detection for ecological redline monitoring and verify the performance of this change detection method through experiments.
2. Dataset Details
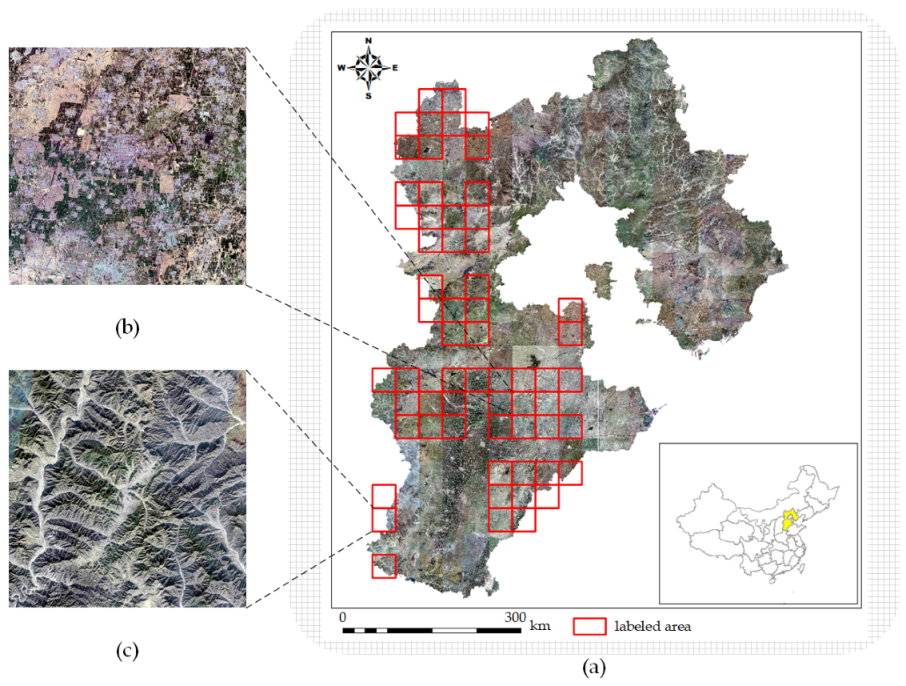
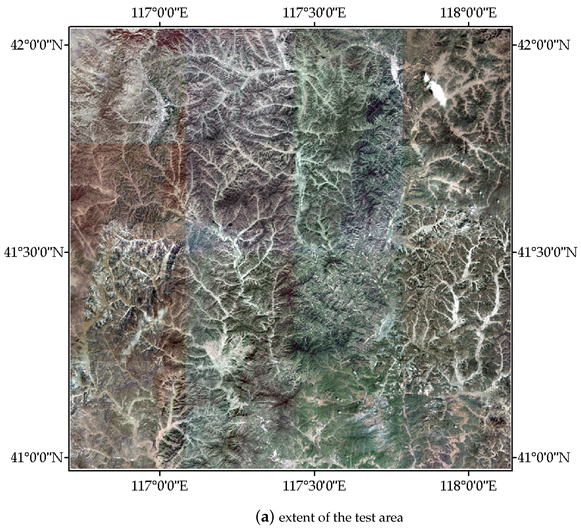
2.1. Study Area and Data Source
2.2. Labeling Method
2.3. Dataset Prepocessing
3. Proposed Methods
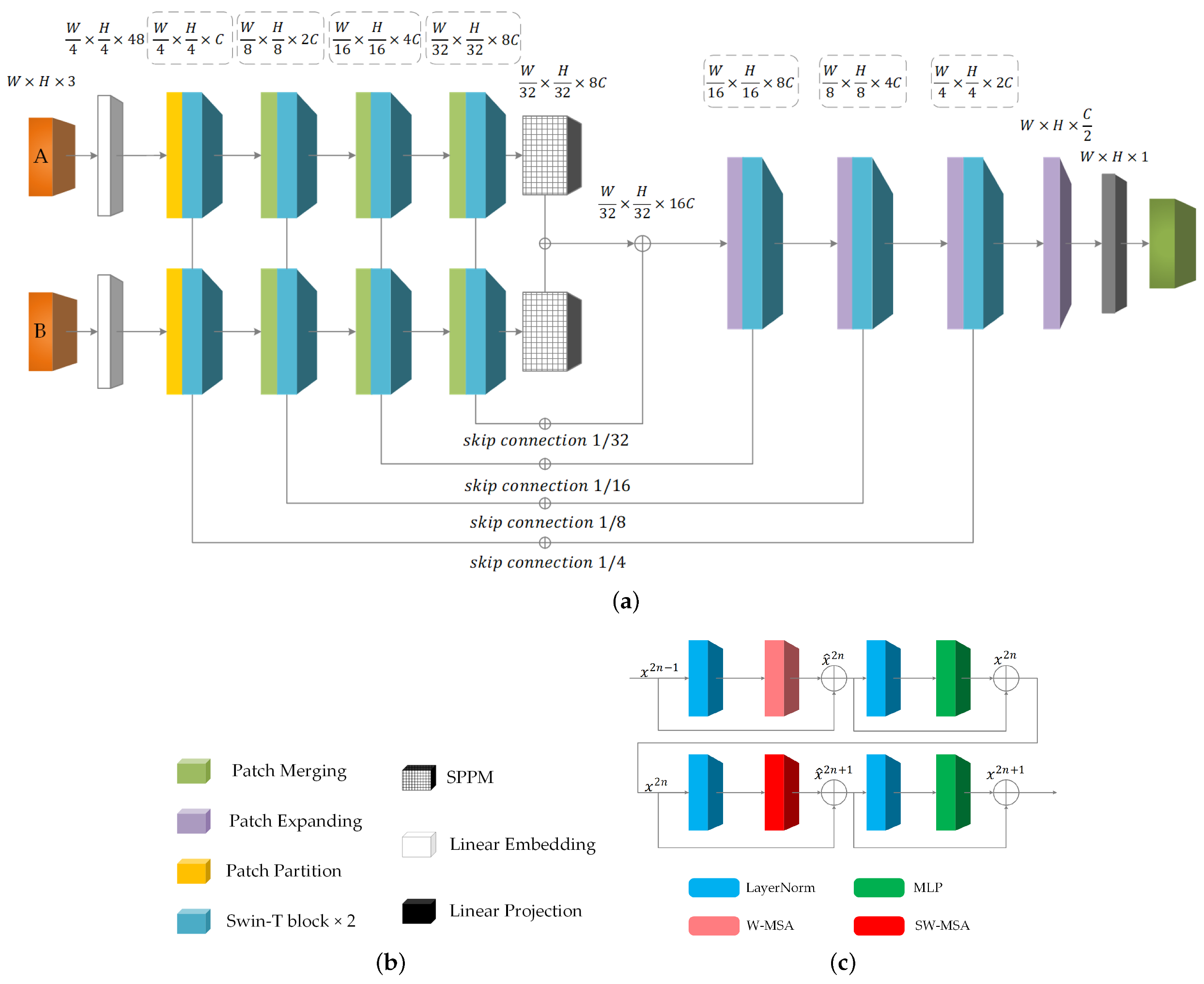
3.1. SWUNet-CD
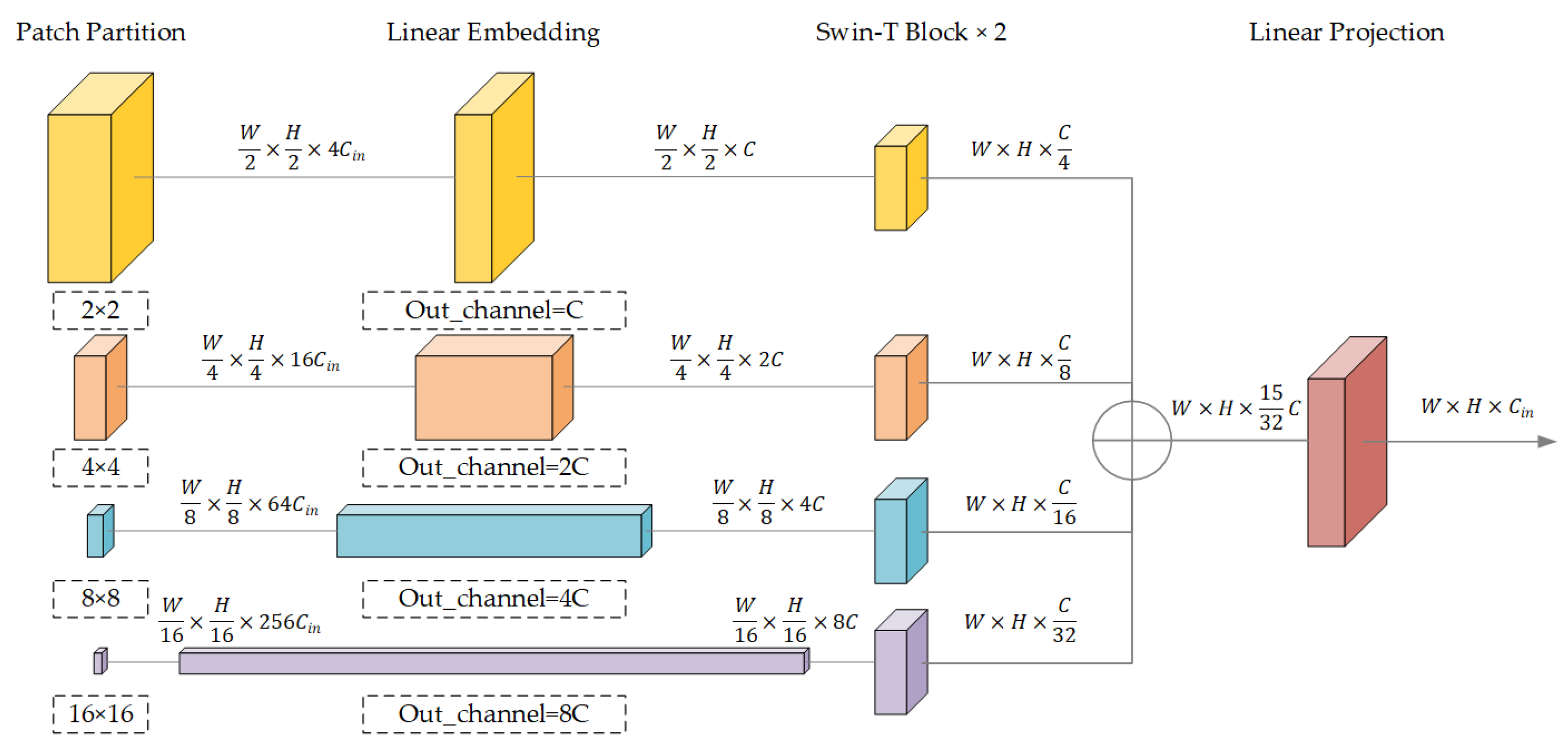
3.2. Swin-Based Pyramid Pooling Module
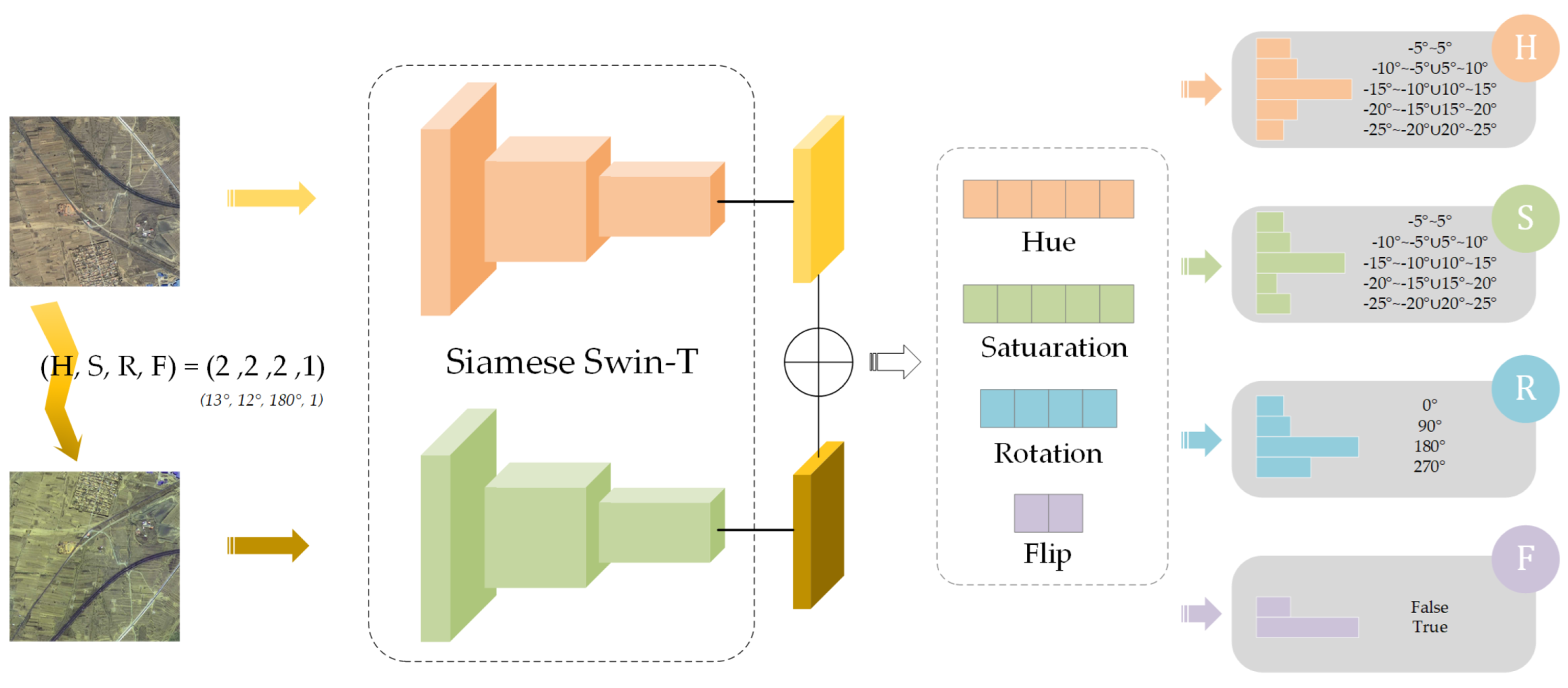
3.3. Pre-Trained Model Obtained by Self-Supervised Network
4. Experimental Results
4.1. Experimental Settings
4.2. Accuracy Evalucation
4.3. Ablation Study
4.3.1. Effects of Different Pooling Modules
4.3.2. Effects of Self-Supervised Study
- SPPM combining W-MSA/SW-MSA and the idea of multi-scale fusion can not only effectively improve the performance of the basic network but also has significant advantages compared to other multi-scale fusion modules such as ASPP and PPM.
- Self-supervised learning method can obtain a pre-trained model that is more suitable for the research area than the normal pre-trained model, which can further improve the performance of the network and optimize the prediction results without adding additional data labeling work.
4.4. Comparison with Other Neural Networks
- Fully Convolutional Siamese Concatenation network(FC-Siam-Conc) [43,44]: A Siamese change detection network designed based on FC-EF. This network uses the idea of feature-level fusion and builds on the structure of U-Net. It concatenates different feature maps obtained after down-sampling in the channel dimension.
- Deeply-Supervised image fusion network (DSIFN) [45]: A change detection network for high-resolution remote sensing images. It uses VGG-16 as the backbone to downsample and obtain the image’s features and then fuses multi-level depth features and image features through a difference discrimination network using an attention mechanism.
- CDNet [46]: A network first used in building change detection. It combines point cloud data of different phases with orthophotos. The two inputs of the final network are the height differences of ALS-DSM and DIM-DSM, and the corresponding orthophoto data.
- Siamese NestedUNet (SNUNet-CD) [49]: A Siamese network for change detection designed and proposed based on the idea of NestedUNet [50]. It has two main characteristics, which are listed as follows: (1) there exist highly dense connections distributed in the network, including a large number of skip connections between encoders and decoders. Such a structure can allow it to ensure high-resolution and fine-grained representation, and alleviate the loss of localization information in the deep layers of the neural network. (2) A deep monitoring method with an ensembled channel attention module (ECAM) is proposed. This module can aggregate and refine features from multiple semantic levels, suppressing semantic gaps and localization errors to a certain extent.
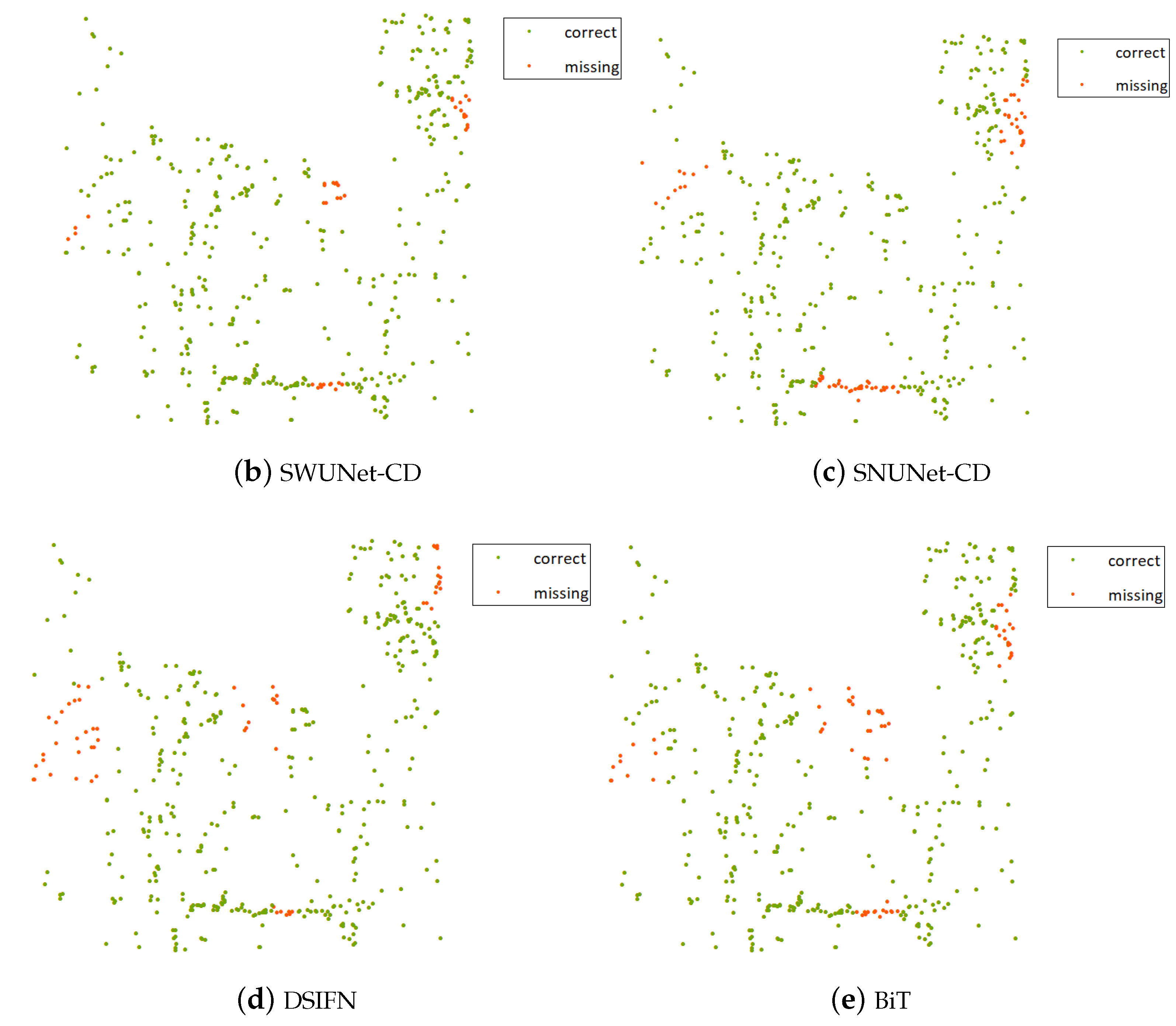
4.5. Intersection Analysis of Network Extracted Spots and Manually Extracted Spots
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ECL | Ecological redline |
| CNN | convolutional neural network |
| ViT | Visual Transformer |
| Swin | Shifted Window-based Self-attention |
| FN | False negative |
| FP | False positive |
| TP | True positive |
| TN | True negative |
| PPM | Pyramid Pooling Module |
| ASPP | Atrous Spatial Pyramid Pooling |
| IoU | Intersection over Union |
| SWUNet-CD | Siamese Swin-UNet for change detection |
| FC-EF | Fully Convolutional Early Fusion |
| FC-Siame-Conc | Fully Convolutional Siamese-Concatenation |
| FC-Siam-Diff | Fully Convolutional Siamese-Difference |
| Swin-T | Hierarchical Vision Transformer using Shifted Windows |
| Swin-UNet | Unet-like Pure Transformer for Medical Image Segmentation |
| DSIFN | Deeply supervised image fusion network for change detection |
| SNUNet-CD | Siamese NestedUNet |
| AIFM | Attention Information Module |
| ECAM | Ensembled Channel Attention Module |
| PCA | Principal component analysis |
| ICA | Independent component analysis |
| MAD | Multivariate alteration detection |
| SPPM | Swin-based Pyramid Pooling Module |
References
- Fan, J.; Sun, W.; Zhou, K.; Chen, D. Major function oriented zone: New method of spatial regulation for reshaping regional development pattern in China. Chin. Geogr. Sci. 2012, 22, 196–209. [Google Scholar] [CrossRef]
- Bai, Y.; Jiang, B.; Wang, M.; Li, H.; Alatalo, J.M.; Huang, S. New ecological redline policy (ERP) to secure ecosystem services in China. Land Use Policy 2016, 55, 348–351. [Google Scholar] [CrossRef] [Green Version]
- Amani, M.; Mahdavi, S.; Afshar, M.; Brisco, B.; Huang, W.; Mohammad Javad Mirzadeh, S.; White, L.; Banks, S.; Montgomery, J.; Hopkinson, C. Canadian wetland inventory using Google Earth Engine: The first map and preliminary results. Remote Sens. 2019, 11, 842. [Google Scholar] [CrossRef] [Green Version]
- Tamiminia, H.; Salehi, B.; Mahdianpari, M.; Quackenbush, L.; Adeli, S.; Brisco, B. Google Earth Engine for geo-big data applications: A meta-analysis and systematic review. ISPRS J. Photogramm. Remote Sens. 2020, 164, 152–170. [Google Scholar] [CrossRef]
- Bovolo, F.; Bruzzone, L. A split-based approach to unsupervised change detection in large-size multitemporal images: Application to tsunami-damage assessment. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1658–1670. [Google Scholar] [CrossRef]
- Yan, Z.; De Sheng, C.; Zhong, R.H. The research of building earthquake damage object-oriented segmentation based on multi feature combination with remote sensing image. Procedia Comput. Sci. 2019, 154, 817–823. [Google Scholar] [CrossRef]
- Zhang, D.; Zhou, G. Estimation of soil moisture from optical and thermal remote sensing: A review. Sensors 2016, 16, 1308. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, S.; Marinelli, D.; Bruzzone, L.; Bovolo, F. A review of change detection in multitemporal hyperspectral images: Current techniques, applications, and challenges. IEEE Geosci. Remote Sens. Mag. 2019, 7, 140–158. [Google Scholar] [CrossRef]
- Khelifi, L.; Mignotte, M. Deep learning for change detection in remote sensing images: Comprehensive review and meta-analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Celik, T. Unsupervised change detection in satellite images using principal component analysis and k-means clustering. IEEE Geosci. Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- Zhong, J.; Wang, R. Multi-temporal remote sensing change detection based on independent component analysis. Int. J. Remote Sens. 2006, 27, 2055–2061. [Google Scholar] [CrossRef]
- Nielsen, A.A.; Conradsen, K.; Simpson, J.J. Multivariate alteration detection (MAD) and MAF postprocessing in multispectral, bitemporal image data: New approaches to change detection studies. Remote Sens. Environ. 1998, 64, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends® Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Lin, K.; Han, M. A novel joint change detection approach based on weight-clustering sparse autoencoders. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 685–699. [Google Scholar] [CrossRef]
- Liu, J.; Gong, M.; Qin, K.; Zhang, P. A deep convolutional coupling network for change detection based on heterogeneous optical and radar images. IEEE Trans. Neural Netw. Learn. Syst. 2016, 29, 545–559. [Google Scholar] [CrossRef]
- Niu, X.; Gong, M.; Zhan, T.; Yang, Y. A conditional adversarial network for change detection in heterogeneous images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 45–49. [Google Scholar] [CrossRef]
- Lyu, H.; Lu, H.; Mou, L. Learning a transferable change rule from a recurrent neural network for land cover change detection. Remote Sens. 2016, 8, 506. [Google Scholar] [CrossRef]
- Liu, G.; Yuan, Y.; Zhang, Y.; Dong, Y.; Li, X. Style transformation-based spatial-spectral feature learning for unsupervised change detection. IEEE Trans. Geosci. Remote Sens. 2020, 60, 5401515. [Google Scholar] [CrossRef]
- Dong, H.; Ma, W.; Wu, Y.; Gong, M.; Jiao, L. Local descriptor learning for change detection in synthetic aperture radar images via convolutional neural networks. IEEE Access 2018, 7, 15389–15403. [Google Scholar] [CrossRef]
- Foo, P.H.; Ng, G.W. High-level information fusion: An overview. J. Adv. Inf. Fusion 2013, 8, 33–72. [Google Scholar]
- Schierl, J. A 2D/3D Feature-Level Information Fusion Architecture For Remote Sensing Applications. PhD Thesis, University of Dayton, Dayton, OH, USA, 2022. [Google Scholar]
- Chen, P.; Guo, L.; Zhang, X.; Qin, K.; Ma, W.; Jiao, L. Attention-Guided Siamese Fusion Network for Change Detection of Remote Sensing Images. Remote Sens. 2021, 13, 4597. [Google Scholar] [CrossRef]
- Zhan, Y.; Fu, K.; Yan, M.; Sun, X.; Wang, H.; Qiu, X. Change detection based on deep siamese convolutional network for optical aerial images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1845–1849. [Google Scholar] [CrossRef]
- Wang, M.; Tan, K.; Jia, X.; Wang, X.; Chen, Y. A deep siamese network with hybrid convolutional feature extraction module for change detection based on multi-sensor remote sensing images. Remote Sens. 2020, 12, 205. [Google Scholar] [CrossRef] [Green Version]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Wang, D.; Gao, F.; Dong, J.; Wang, S. Change detection in synthetic aperture radar images based on convolutional block attention module. In Proceedings of the 2019 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Shanghai, China, 5–7 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Peng, X.; Zhong, R.; Li, Z.; Li, Q. Optical remote sensing image change detection based on attention mechanism and image difference. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7296–7307. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Yu, B.; Yang, L.; Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Cao, L.; Zhang, L. Pre-trained alexnet architecture with pyramid pooling and supervision for high spatial resolution remote sensing image scene classification. Remote Sens. 2017, 9, 848. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Gross, L.; Li, Z.; Li, X.; Fan, X.; Qi, W. Automatic building extraction on high-resolution remote sensing imagery using deep convolutional encoder-decoder with spatial pyramid pooling. IEEE Access 2019, 7, 128774–128786. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1422–1430. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 649–666. [Google Scholar]
- Feng, Z.; Xu, C.; Tao, D. Self-supervised representation learning by rotation feature decoupling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10364–10374. [Google Scholar]
- Noroozi, M.; Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 69–84. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4063–4067. [Google Scholar]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Zhang, Z.; Vosselman, G.; Gerke, M.; Persello, C.; Tuia, D.; Yang, M.Y. Detecting building changes between airborne laser scanning and photogrammetric data. Remote Sens. 2019, 11, 2417. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A densely connected Siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Panchromatic Camera | Multispectral Camera | |
|---|---|---|
| Spectral range | 0.45–0.90 μm | 0.45–0.52 μm |
| 0.52–0.59 μm | ||
| 0.63–0.69 μm | ||
| 0.77–0.89 μm | ||
| Spatial resolution | 2 m | 8 m/16 m |
| Coverage width | 60 km | 60 km/800 km |
| Revisit period | 4 days | 4 days |
| Label True | Label False | |
|---|---|---|
| Test True | TP (True Positive) | FP (False Positive) |
| Test False | FN (False Negative) | TN (True Negative) |
| Backbone | PPM | ASPP | SPPM | Self-Supervised | Pre | Rec | F1 | IoU |
|---|---|---|---|---|---|---|---|---|
| ✔ | 0.6676 | 0.6834 | 0.6754 | 0.5099 | ||||
| ✔ | ✔ | 0.6722 | 0.6975 | 0.6846 | 0.5205 | |||
| ✔ | ✔ | 0.6856 | 0.6746 | 0.6801 | 0.5152 | |||
| ✔ | ✔ | 07223 | l0.7136 | 0.7179 | 0.5600 | |||
| ✔ | ✔ | 0.7116 | 0.6777 | 0.6942 | 0.5317 | |||
| ✔ | ✔ | ✔ | 0.7340 | 0.7133 | 0.7235 | 0.5668 |
| Network | Precision | Recall | F1 Score | IoU |
|---|---|---|---|---|
| FC-EF | 0.6621 | 0.6596 | 0.6608 | 0.4935 |
| FC-Siam-Conc | 0.6857 | 0.6633 | 0.6743 | 0.5087 |
| FC-Siam-Diff | 0.7072 | 0.6678 | 0.6869 | 0.5232 |
| DSIFN | 0.8140 | 0.6284 | 0.7093 | 0.5495 |
| CDNet | 0.7081 | 0.6913 | 0.6996 | 0.5380 |
| BiT | 0.7237 | 0.6940 | 0.7085 | 0.5486 |
| SNUNet-CD | 0.7344 | 0.6719 | 0.7018 | 0.5405 |
| SWUNet-CD | 0.7340 | 0.7133 | 0.7235 | 0.5668 |
| Network | Prediction | Label | Spots Number | Proportion | Recall |
|---|---|---|---|---|---|
| SWUNet-CD | ✔ | ✔ | 411 | 91.33% | 91.33% |
| ✘ | 23 | ||||
| ✘ | 39 | 8.67% | |||
| SNUNet-CD | ✔ | ✔ | 389 | 86.44% | 86.44% |
| ✘ | 26 | ||||
| ✘ | 61 | 13.56% | |||
| DSIFN | ✔ | ✔ | 388 | 86.22% | 86.22% |
| ✘ | 24 | ||||
| ✘ | 62 | 13.78% | |||
| BiT | ✔ | ✔ | 391 | 86.89% | 86.89% |
| ✘ | 28 | ||||
| ✘ | 59 | 13.11% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, Y.; Shen, T.; Chen, Z.; Chen, P.; Yang, X.; Zan, L. A Transformer-Based Neural Network with Improved Pyramid Pooling Module for Change Detection in Ecological Redline Monitoring. Remote Sens. 2023, 15, 588. https://doi.org/10.3390/rs15030588
Zou Y, Shen T, Chen Z, Chen P, Yang X, Zan L. A Transformer-Based Neural Network with Improved Pyramid Pooling Module for Change Detection in Ecological Redline Monitoring. Remote Sensing. 2023; 15(3):588. https://doi.org/10.3390/rs15030588
Chicago/Turabian StyleZou, Yunjia, Ting Shen, Zhengchao Chen, Pan Chen, Xuan Yang, and Luyang Zan. 2023. "A Transformer-Based Neural Network with Improved Pyramid Pooling Module for Change Detection in Ecological Redline Monitoring" Remote Sensing 15, no. 3: 588. https://doi.org/10.3390/rs15030588
APA StyleZou, Y., Shen, T., Chen, Z., Chen, P., Yang, X., & Zan, L. (2023). A Transformer-Based Neural Network with Improved Pyramid Pooling Module for Change Detection in Ecological Redline Monitoring. Remote Sensing, 15(3), 588. https://doi.org/10.3390/rs15030588