
Remote Sensing Image Change Detection Based on Deep Multi-Scale Multi-Attention Siamese Transformer Network



Abstract
:1. Introduction
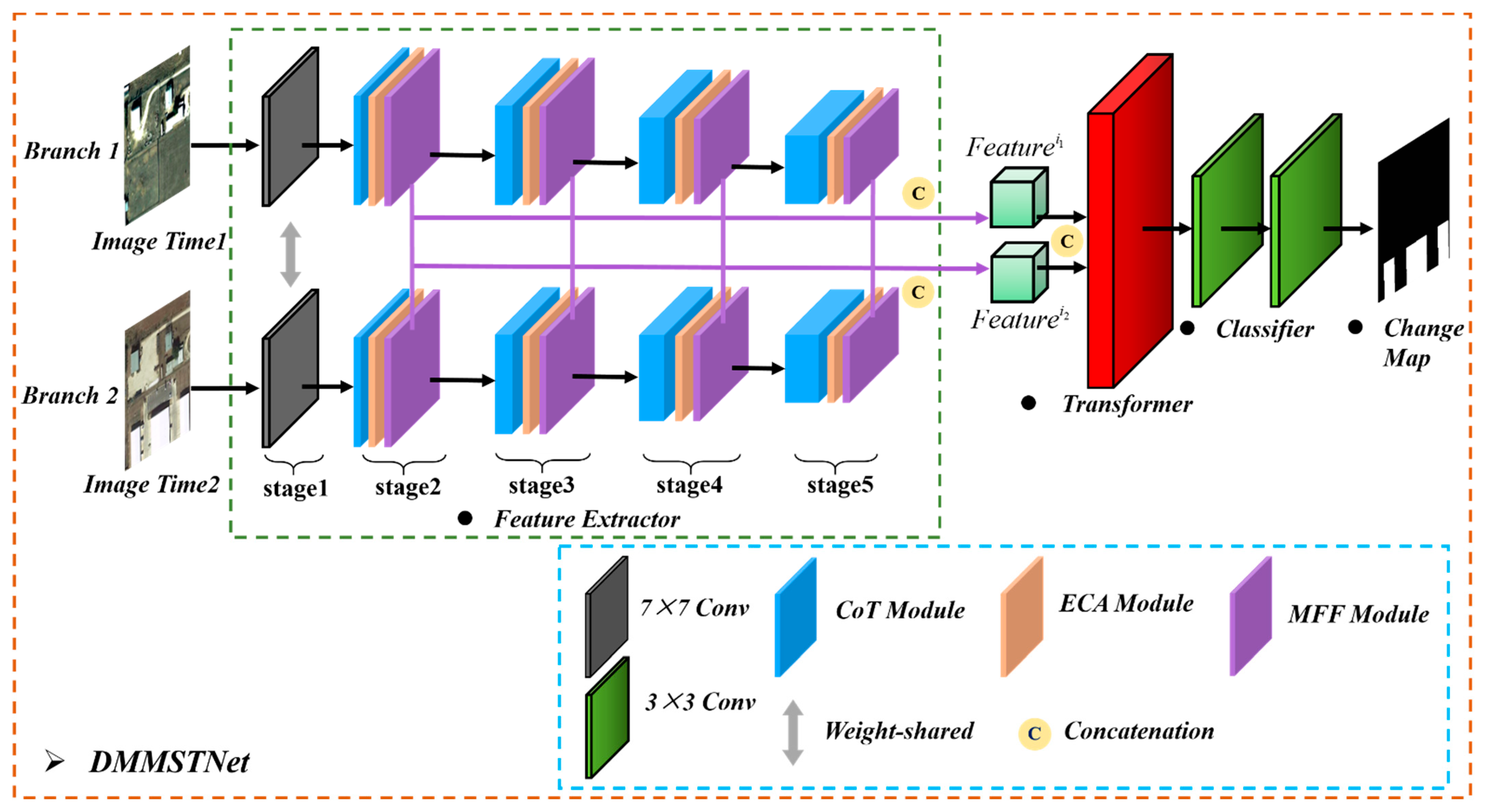
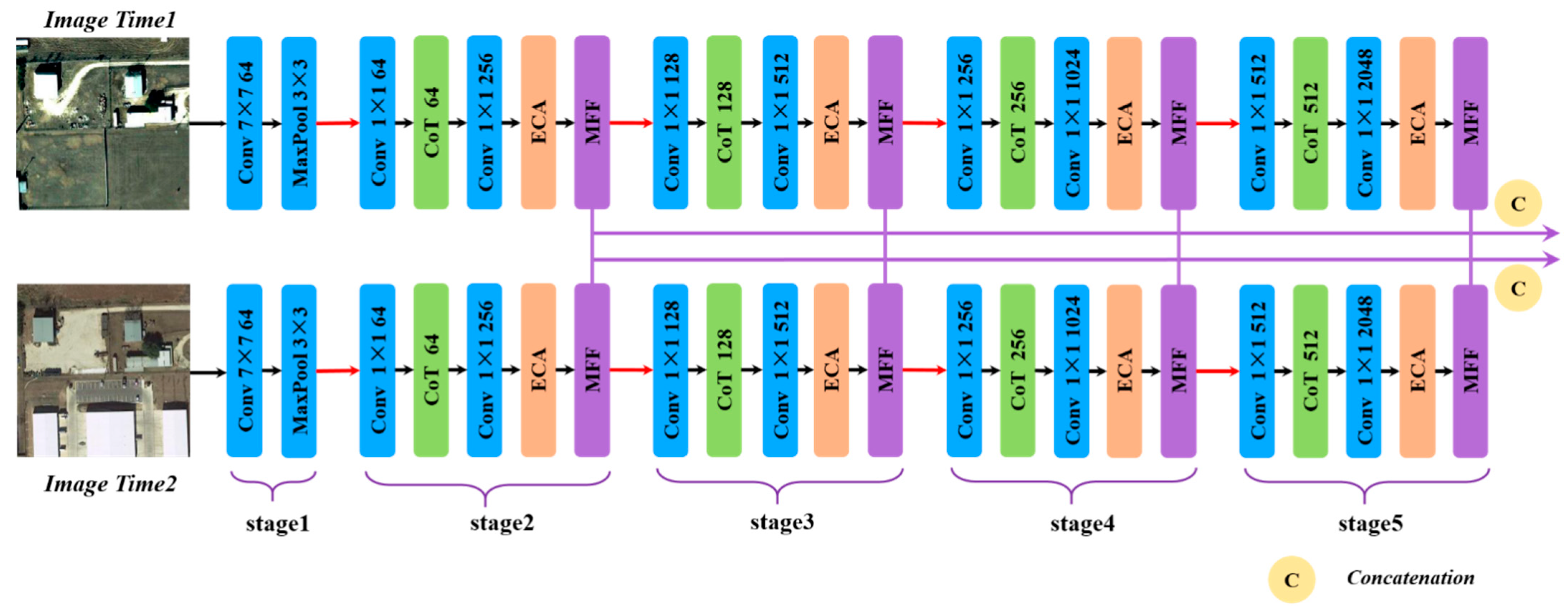
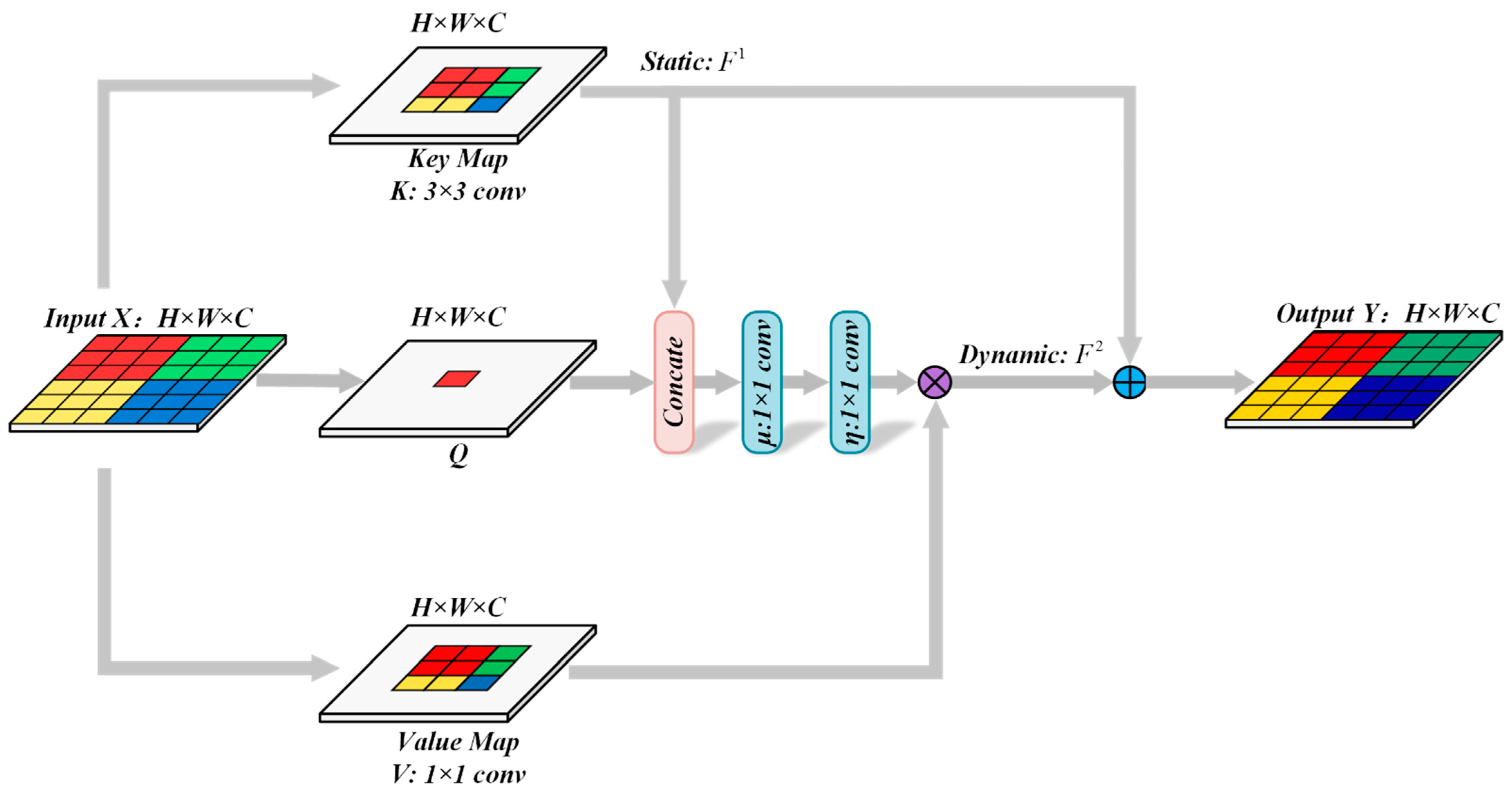
- The DMMSTNet is based on the multi-scale contextual transformer and the channel attention. It takes full advantage of remote sensing images’ rich spatial, channel and semantic information. The DMMSTNet incorporates the CoT module into the siamese feature extractor to acquire rich global spatial image features. The CoT module is a hybrid module that combines the advantages of self-attention and convolution. It calculates the attention score of each pixel in a 3 × 3 grid to generate a self-attention matrix, and the gained matrix is used to multiply the input to obtain the attention relationship.
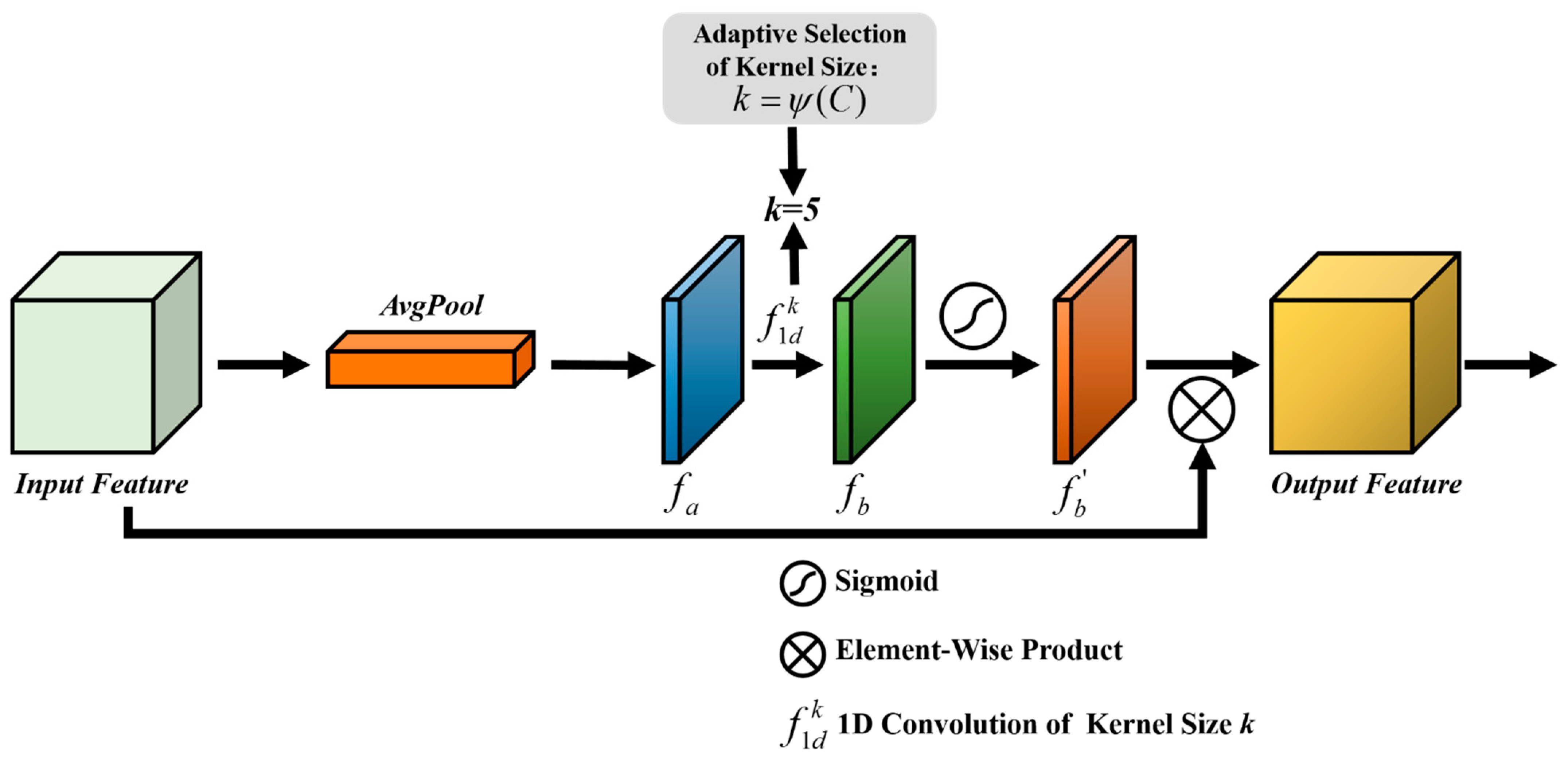
- The ECA is embedded in the feature extractor to concern the information correlation among the channels in this study. The channel attention aims to establish the correlation among the different channels and acquire the significance of each channel features automatically. The important channel features can be strengthened, and the unimportant features can be suppressed. Obtaining the information correlation among the channels of images is helpful for boosting the performance of the feature extractor.
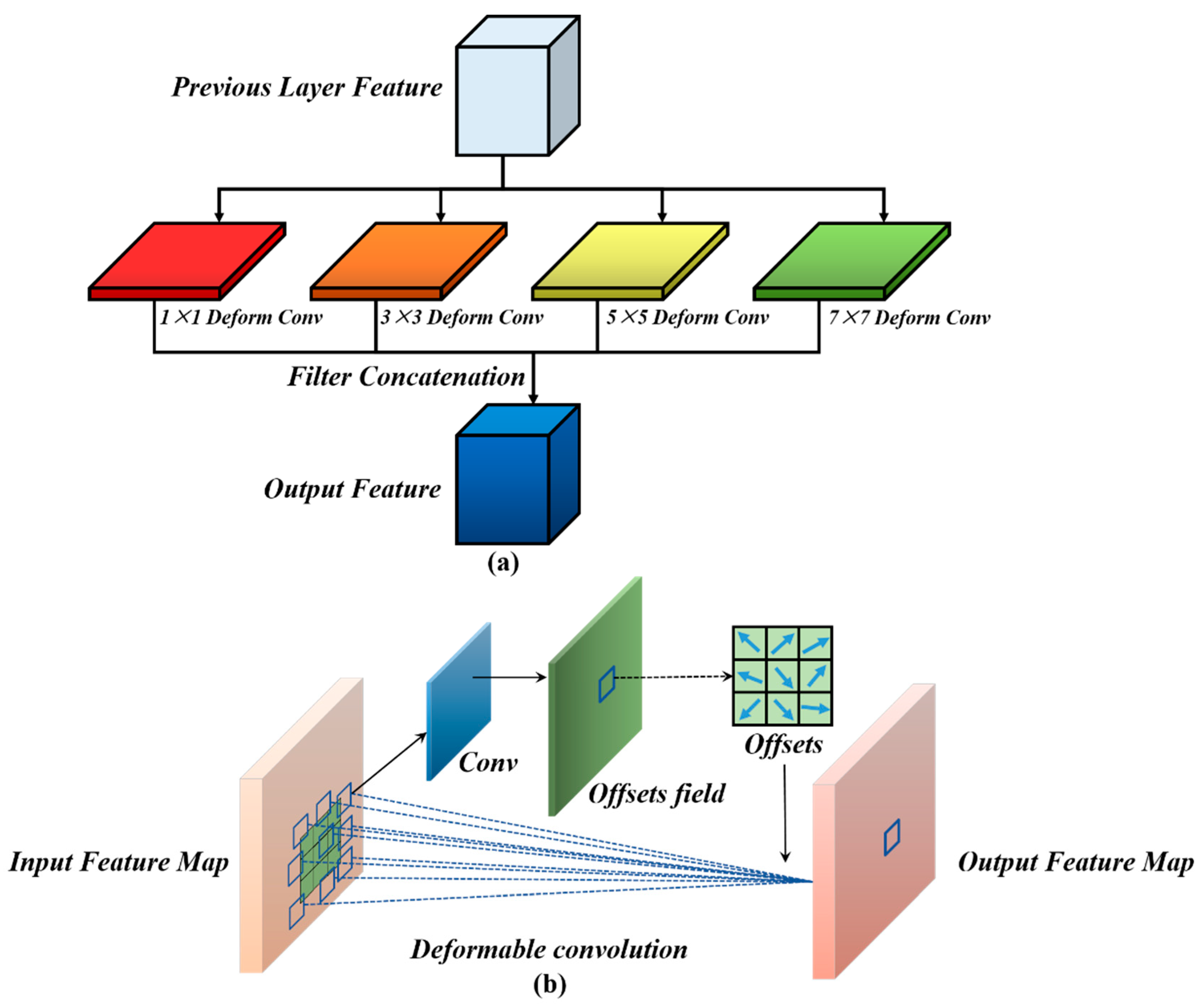
- The MFF module is proposed in this study. Background objects of different sizes and shapes usually have different receptive field requirements. The semantic information of the different layers needs to be fused while identifying background objects of different sizes. The multi-scale feature representation of the images can be extracted, and the different levels of semantic information can be fused by the MFF. Then, the MFF can obtain the receptive fields of different sizes. The ground objects in remote sensing images have different sizes. The MFF module can obtain ground objects of different sizes, which shows the effectiveness of the change detection.
2. Related Works
2.1. Deep Siamese Network in Change Detection
2.2. Attention Mechanism
3. The Proposed Method
3.1. Overview
3.2. Feature Extractor in DMMSTNet
3.2.1. Contextual Transformer Module

3.2.2. Efficient Channel Attention Module
3.2.3. Multiscale Feature Fusion Module
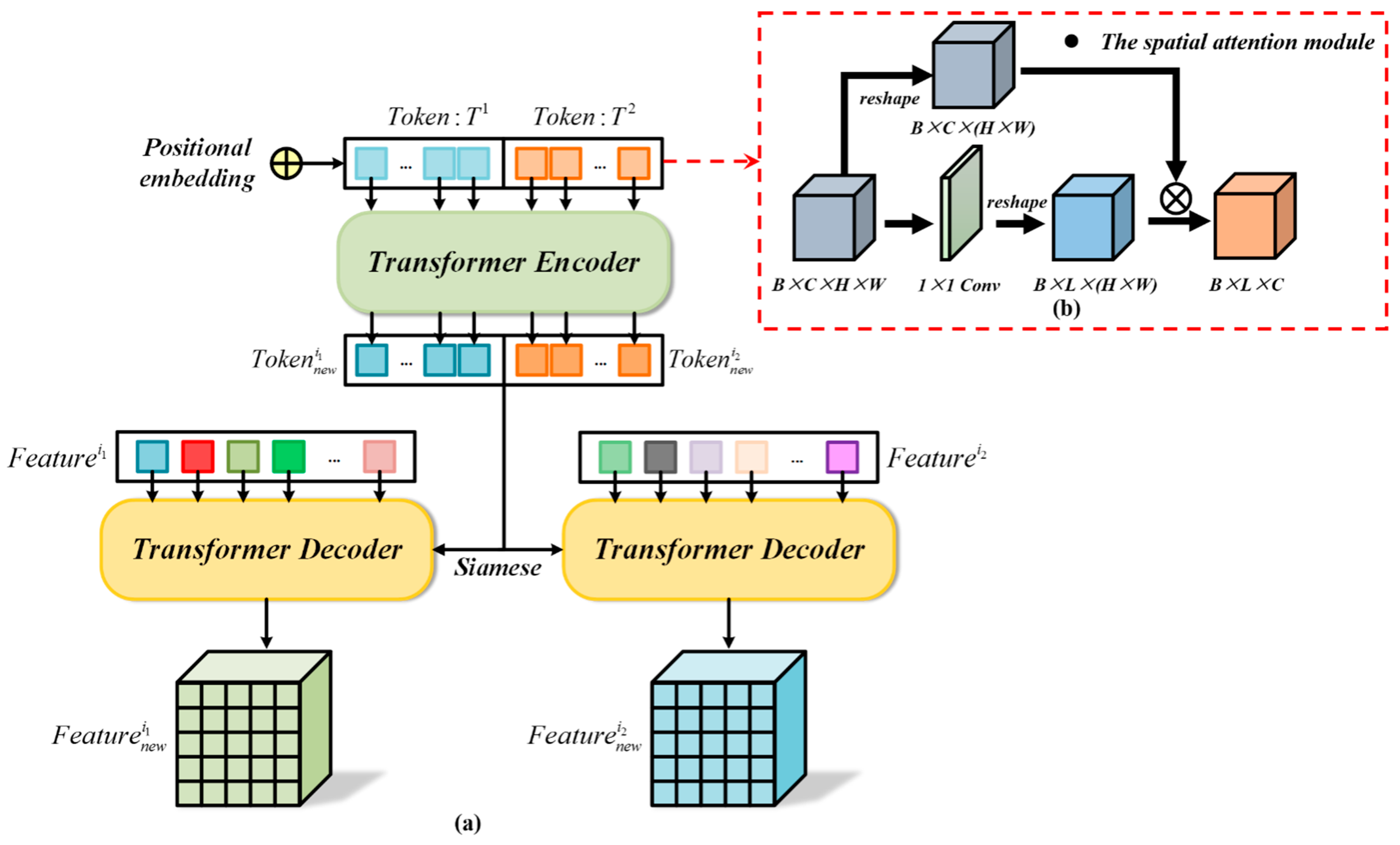
3.3. Transformer Module
3.3.1. Transformer Encoder
3.3.2. Transformer Decoder
3.4. Classifier and Loss Function
4. Experimental Results
4.1. Experiment Setting
4.1.1. Experimental Datasets
4.1.2. Comparison Methods
- (1)
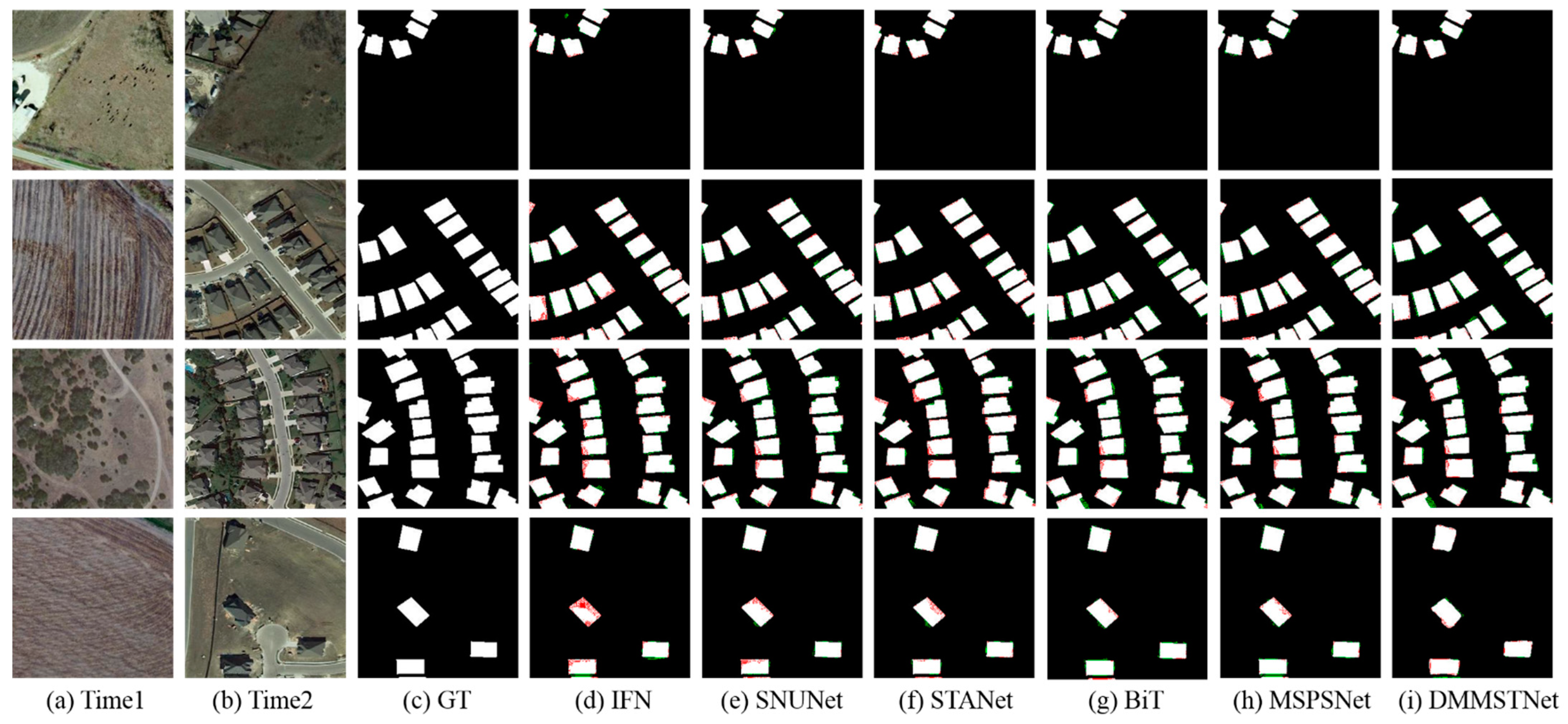
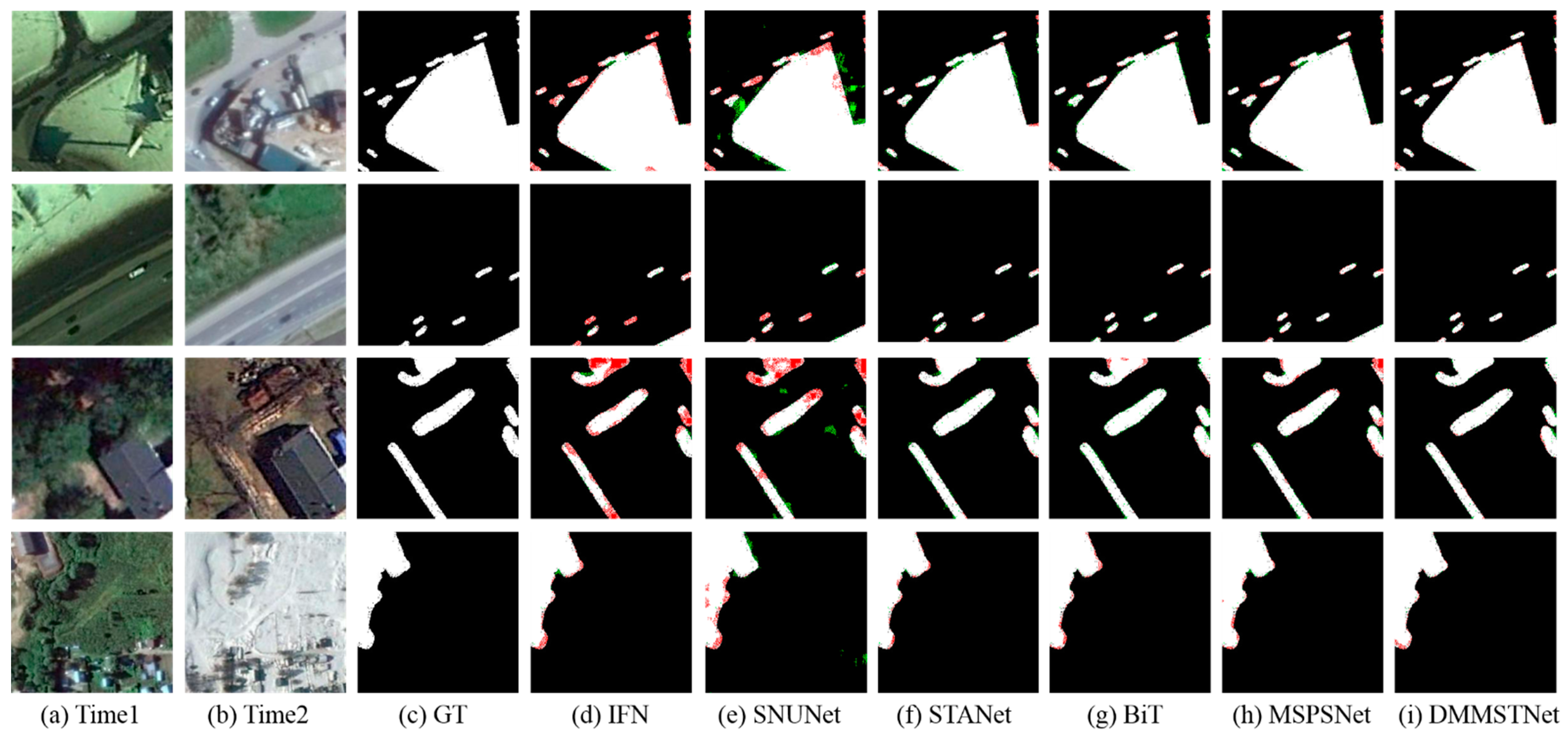
- IFN [26] is a network that combines a deep supervision block and an attention module. It can learn the representative deep image features based on a siamese VGG net. The reconstructed change map can be acquired by fusing the multi-level depth feature of the original image with the image difference feature through the attention module.
- (2)
- SNUNet [28] is based on the NestedUnet and contains the densely connected structure. It can alleviate the loss of the deep localization information in whole networks through dense skip connections. An integrated channel attention block is introduced for deep supervision to enhance the features at different semantic levels.
- (3)
- STANet [53] utilizes the spatial-temporal attention block to refine the image features. The spatial-temporal attention block can model the spatial-temporal relationship in the image, which is embedded into the feature extraction process to acquire the discriminative features. The change graph is finally obtained using the metrics module.
- (4)
- BiT [30] is a transformer-based network. The transformer encoder is applied to model the spatial-temporal context of the compact pixel information. Then, the original features can be refined through a transformer decoder.
- (5)
- MSPSNet [52] contains parallel convolutional structures and a self-attention module. Parallel convolution introduces different dilated convolutions to perform feature aggregation and improve the receptive field. The self-attention module highlights the regions where changes are easier to detect.
4.1.3. Implementation Details and Evaluation Metrics
4.2. Comparison Experiments
4.2.1. Comparison Results on the LEVIR-CD Dataset
4.2.2. Comparison Results on the CCD Dataset
4.3. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More Diverse Means Better: Multimodal Deep Learning Meets Remote-Sensing Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4340–4354. [Google Scholar]
- Rasti, B.; Hong, D.; Hang, R.; Ghamisi, P.; Kang, X.; Chanussot, J.; Benediktsson, J.A. Feature Extraction for Hyperspectral Imagery: The Evolution from Shallow to Deep: Overview and Toolbox. IEEE Geosci. Remote Sens. Mag. 2020, 8, 60–88. [Google Scholar] [CrossRef]
- Singh, A. Review Article Digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar]
- Koltunov, A.; Ustin, S.L. Early fire detection using non-linear multitemporal prediction of thermal imagery. J Remote Sens. Environ. 2007, 110, 18–28. [Google Scholar]
- Bruzzone, L.; Serpico, S.B. An iterative technique for the detection of land-cover transitions in multitemporal remote-sensing images. J IEEE Trans. Geosci. Remote Sens. 1997, 35, 858–867. [Google Scholar] [CrossRef]
- Mucher, C.A.; Steinnocher, K.; Kressler, F.P.; Heunks, C. Land cover characterization and change detection for environmental monitoring of pan-Europe. Int. J. Remote Sens. 2000, 21, 1159–1181. [Google Scholar]
- Häme, T.; Heiler, I.; Miguel-Ayanz, J.S. An unsupervised change detection and recognition system for forestry. Int. J. Remote Sens. 1998, 19, 1079–1099. [Google Scholar]
- Xiao, J.; Shen, Y.; Ge, J.; Tateishi, R.; Tang, C.; Liang, Y.; Huang, Z. Evaluating urban expansion and land use change in Shijiazhuang, China, by using GIS and remote sensing. Landsc. Urban Plan. 2006, 75, 69–80. [Google Scholar]
- Glass, G.V. Primary, Secondary, and Meta-Analysis of Research1. Educ. Res. 1976, 5, 3–8. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-Time Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 334–349. [Google Scholar]
- Jackson, R.D. Spectral indices in N-Space. Remote Sens. Environ. 1983, 13, 409–421. [Google Scholar]
- Todd, W.J. Urban and regional land use change detected by using Landsat data. J. Res. US Geol. Surv. 1977, 5, 529–534. [Google Scholar]
- Ferraris, V.; Dobigeon, N.; Wei, Q.; Chabert, M. Detecting Changes Between Optical Images of Different Spatial and Spectral Resolutions: A Fusion-Based Approach. IEEE Trans. Geosci. Remote Sens. Environ. 2018, 56, 1566–1578. [Google Scholar]
- Kuncheva, L.I.; Faithfull, W.J. PCA Feature Extraction for Change Detection in Multidimensional Unlabeled Data. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 69–80. [Google Scholar]
- Saha, S.; Bovolo, F.; Bruzzone, L. Unsupervised Deep Change Vector Analysis for Multiple-Change Detection in VHR Images. IEEE Trans. Geosci. Remote Sens. Environ. 2019, 57, 3677–3693. [Google Scholar] [CrossRef]
- Çelik, T. Unsupervised Change Detection in Satellite Images Using Principal Component Analysis and $k$-Means Clustering. IEEE Geosci. Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- Bovolo, F.; Bruzzone, L.; Marconcini, M. A Novel Approach to Unsupervised Change Detection Based on a Semisupervised SVM and a Similarity Measure. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2070–2082. [Google Scholar]
- Wu, C.; Du, B.; Cui, X.; Zhang, L. A post-classification change detection method based on iterative slow feature analysis and Bayesian soft fusion. Remote Sens. Environ. 2017, 199, 241–255. [Google Scholar] [CrossRef]
- Sun, W.; Yang, G.; Ren, K.; Peng, J.; Ge, C.; Meng, X.; Du, Q. A Label Similarity Probability Filter for Hyperspectral Image Postclassification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6897–6905. [Google Scholar]
- Wu, C.; Du, B.; Zhang, L.-p. A Subspace-Based Change Detection Method for Hyperspectral Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 815–830. [Google Scholar]
- Ma, L.; Liu, Y.; Zhang, X.-l.; Ye, Y.; Yin, G.; Johnson, B. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Dong, W.; Zhang, T.; Qu, J.; Xiao, S.; Liang, J.; Li, Y.; Sensing, R. Laplacian Pyramid Dense Network for Hyperspectral Pansharpening. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar]
- Liu, T.; Gong, M.; Lu, D.; Zhang, Q.; Zheng, H.; Jiang, F.; Zhang, M. Building Change Detection for VHR Remote Sensing Images via Local–Global Pyramid Network and Cross-Task Transfer Learning Strategy. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar]
- Daudt, R.C.; Saux, B.L.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Peng, D.; Zhang, Y.; Guan, H. End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. Isprs J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar]
- Simonyan, K.; Zisserman, A.J.C. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual Attentive Fully Convolutional Siamese Networks for Change Detection in High-Resolution Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Hou, X.; Bai, Y.; Li, Y.; Shang, C.; Shen, Q. High-resolution triplet network with dynamic multiscale feature for change detection on satellite images. ISPRS J. Photogramm. Remote Sens. 2021, 177, 103–115. [Google Scholar]
- Zhang, M.; Liu, Z.; Feng, J.; Jiao, L.; Liu, L. Deep Siamese Network with Contextual Transformer for Remote Sensing Images Change Detection. In Proceedings of the Fifth International Conference on Intelligence Science (ICIS), Xi’an, China, 28–31 October 2022; pp. 193–200. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual Transformer Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision Pattern Recognition (CVPR), Seattle, WA, USA, 13 June 2020–19 June 2020; pp. 11531–11539. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, California, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.; LeCun, Y.; Moore, C.; Säckinger, E.; Shah, R. Signature Verification Using a "Siamese" Time Delay Neural Network. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1993. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese Neural Networks for One-Shot Image Recognition. In Proceedings of the International Conference on Machine Learning (ICML) Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2, pp. 1–8. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015, Proceedings, Part III 18; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shao, R.; Du, C.; Chen, H.; Li, J. SUNet: Change Detection for Heterogeneous Remote Sensing Images from Satellite and UAV Using a Dual-Channel Fully Convolution Network. Remote Sens. 2021, 13, 3750. [Google Scholar]
- Zheng, Z.; Wan, Y.; Zhang, Y.; Xiang, S.; Peng, D.; Zhang, B. CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery. Isprs J. Photogramm. Remote Sens. Environ. 2021, 175, 247–267. [Google Scholar]
- Zhang, M.; Shi, W. A Feature Difference Convolutional Neural Network-Based Change Detection Method. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7232–7246. [Google Scholar] [CrossRef]
- Yang, L.; Chen, Y.; Song, S.; Li, F.; Huang, G. Deep Siamese Networks Based Change Detection with Remote Sensing Images. Remote Sens. 2021, 13, 3394. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the NIPS, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, L.; Wu, W.; Qian, C.; Lu, T. TAM: Temporal Adaptive Module for Video Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 13688–13698. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.-S. CBAM: Convolutional Block Attention Module. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Du, W.; Wang, Y.; Qiao, Y. Recurrent Spatial-Temporal Attention Network for Action Recognition in Videos. IEEE Trans. Image Process. 2018, 27, 1347–1360. [Google Scholar]
- Huang, J.; Shen, Q.; Wang, M.; Yang, M. Multiple Attention Siamese Network for High-Resolution Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar]
- Guo, Q.; Zhang, J.; Zhu, S.; Zhong, C.; Zhang, Y. Deep Multiscale Siamese Network with Parallel Convolutional Structure and Self-Attention for Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Lebedev, M.A.; Vizilter, Y.V.; Vygolov, O.V.; Knyaz, V.A.; Rubis, A.Y. Change Detection in Remote Sensing Images Using Conditional Adversarial Networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 422, 565–571. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Pre (%) | Rec (%) | F1 (%) | IoU (%) | OA (%) |
|---|---|---|---|---|---|
| IFN | 90.25 | 80.27 | 84.97 | 73.86 | 98.55 |
| SNUNet | 91.67 | 88.96 | 90.29 | 82.11 | 99.04 |
| STANet | 94.54 | 83.98 | 88.95 | 80.10 | 98.94 |
| BiT | 89.24 | 89.37 | 89.31 | 80.68 | 98.92 |
| MSPSNet | 90.93 | 88.97 | 89.93 | 81.72 | 98.99 |
| DMMSTNet | 92.11 | 89.59 | 90.83 | 83.20 | 99.08 |
| Method | Pre (%) | Rec (%) | F1 (%) | IoU (%) | OA (%) |
|---|---|---|---|---|---|
| IFN | 97.46 | 86.96 | 91.91 | 85.03 | 98.19 |
| SNUNet | 92.07 | 84.64 | 88.20 | 78.69 | 97.33 |
| STANet | 95.61 | 93.81 | 94.70 | 89.94 | 98.76 |
| BiT | 96.02 | 94.29 | 95.14 | 90.74 | 98.86 |
| MSPSNet | 95.65 | 95.11 | 95.38 | 91.17 | 98.91 |
| DMMSTNet | 97.02 | 96.11 | 96.56 | 93.35 | 99.19 |
| Method | Pre (%) | Rec (%) | F1 (%) | IoU (%) | OA (%) |
|---|---|---|---|---|---|
| Base1 [40] | 88.85 | 86.31 | 87.56 | 77.87 | 98.75 |
| Base1 + CoT | 92.19 | 85.86 | 88.92 | 80.05 | 98.79 |
| Base1 + Transformer | 95.26 | 83.89 | 89.22 | 80.53 | 98.88 |
| Method | Pre (%) | Rec (%) | F1 (%) | IoU (%) | OA (%) |
|---|---|---|---|---|---|
| Base1 | 94.98 | 90.66 | 92.77 | 86.51 | 98.33 |
| Base1 + CoT | 97.02 | 95.17 | 96.09 | 92.48 | 99.11 |
| Base1 + Transformer | 96.01 | 94.96 | 95.48 | 91.35 | 98.97 |
| Method | Pre (%) | Rec (%) | F1 (%) | IoU (%) | OA (%) |
|---|---|---|---|---|---|
| Base2 [33] | 90.29 | 89.25 | 89.77 | 81.44 | 98.96 |
| Base2 + ECA | 92.22 | 89.27 | 90.71 | 83.00 | 99.07 |
| Base2 + MFF | 92.51 | 88.84 | 90.64 | 82.88 | 99.06 |
| DMMSTNet | 92.11 | 89.59 | 90.83 | 83.20 | 99.08 |
| Method | Pre (%) | Rec (%) | F1 (%) | IoU (%) | OA (%) |
|---|---|---|---|---|---|
| Base2 | 96.88 | 95.81 | 96.34 | 92.94 | 99.14 |
| Base2 + ECA | 97.18 | 95.06 | 96.11 | 92.51 | 99.09 |
| Base2 + MFF | 96.93 | 96.02 | 96.47 | 93.18 | 99.17 |
| DMMSTNet | 97.02 | 96.11 | 96.56 | 93.35 | 99.19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Liu, Z.; Feng, J.; Liu, L.; Jiao, L. Remote Sensing Image Change Detection Based on Deep Multi-Scale Multi-Attention Siamese Transformer Network. Remote Sens. 2023, 15, 842. https://doi.org/10.3390/rs15030842
Zhang M, Liu Z, Feng J, Liu L, Jiao L. Remote Sensing Image Change Detection Based on Deep Multi-Scale Multi-Attention Siamese Transformer Network. Remote Sensing. 2023; 15(3):842. https://doi.org/10.3390/rs15030842
Chicago/Turabian StyleZhang, Mengxuan, Zhao Liu, Jie Feng, Long Liu, and Licheng Jiao. 2023. "Remote Sensing Image Change Detection Based on Deep Multi-Scale Multi-Attention Siamese Transformer Network" Remote Sensing 15, no. 3: 842. https://doi.org/10.3390/rs15030842
APA StyleZhang, M., Liu, Z., Feng, J., Liu, L., & Jiao, L. (2023). Remote Sensing Image Change Detection Based on Deep Multi-Scale Multi-Attention Siamese Transformer Network. Remote Sensing, 15(3), 842. https://doi.org/10.3390/rs15030842