
CTFuseNet: A Multi-Scale CNN-Transformer Feature Fused Network for Crop Type Segmentation on UAV Remote Sensing Imagery

Abstract
:1. Introduction
- We proposed CTFuseNet, a global–local feature-fused network based on transformer and CNN architectures for accurate crop-type segmentation. It provides a parallel structure of CNN and transformer branches in the encoder to extract both local and global semantic features of remote sensing imagery and outputs multi-scale features for aggregation.
- We design a new lightweight feature-fusion module to flexibly aggregate the multi-scale local and global features output from CNN and transformer branches in the proposed CTFuseNet.
- The FPNHead from feature pyramid network servers as the decoder in the proposed CTFuseNet, instead of maintaining the original All-MLP decoder in SegFormer. It allows decoding features at different scales, thus adapting to the fused features and further improving the accuracy.
2. Methodology
2.1. Parallel Structure of CNN and Transformer for Local and Global Feature Extraction
2.2. Multi-Scale Feature-Fusion Module
2.3. FPNHead for Multi-Scale Feature Decoding
2.4. Objective Function
3. Dataset and Experimental Settings
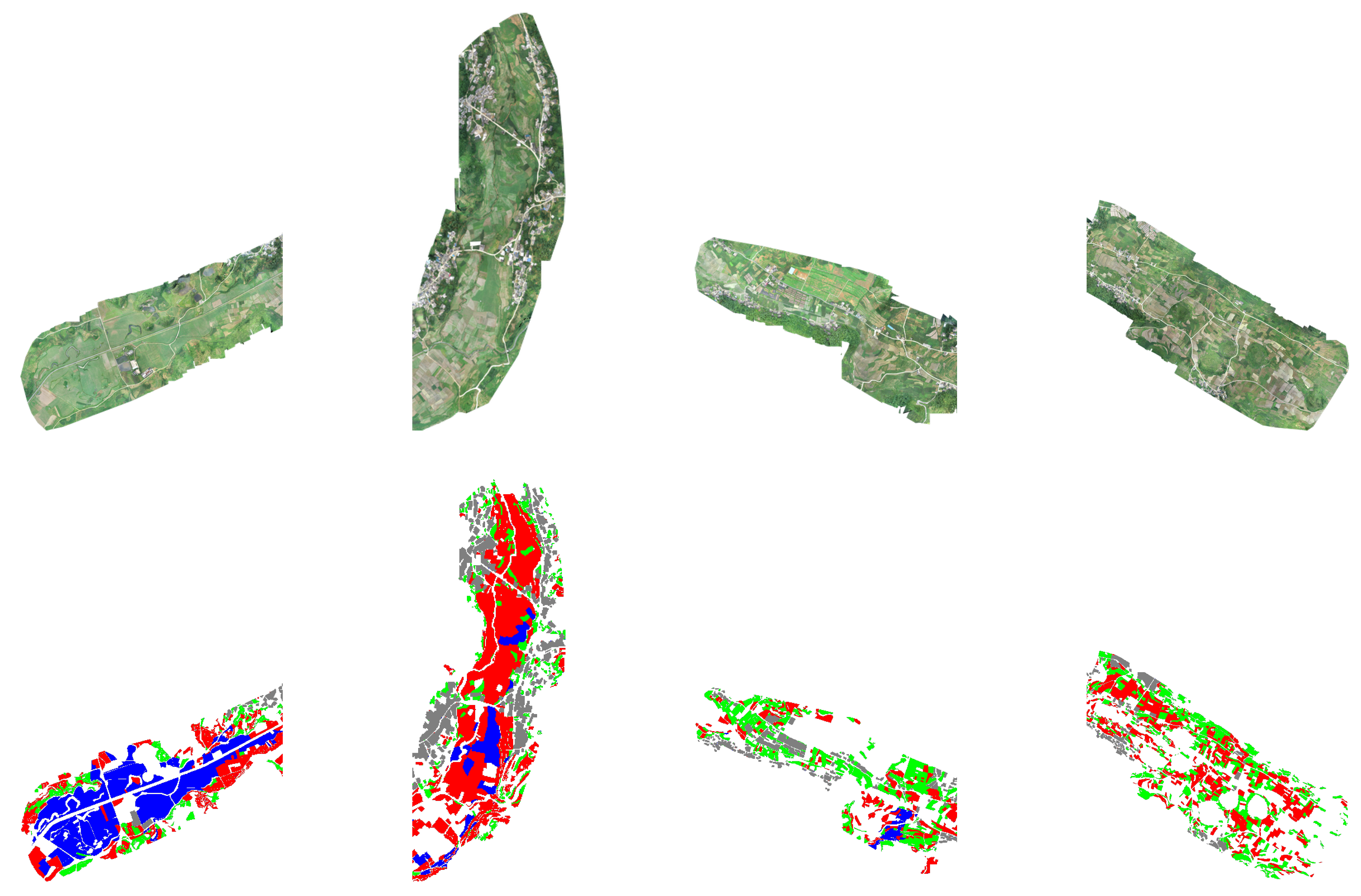
3.1. Study Area and Dataset
3.2. Data Preprocessing
3.3. Experimental Setup
3.4. Evaluation Criteria
3.5. Methods for Performance Comparison
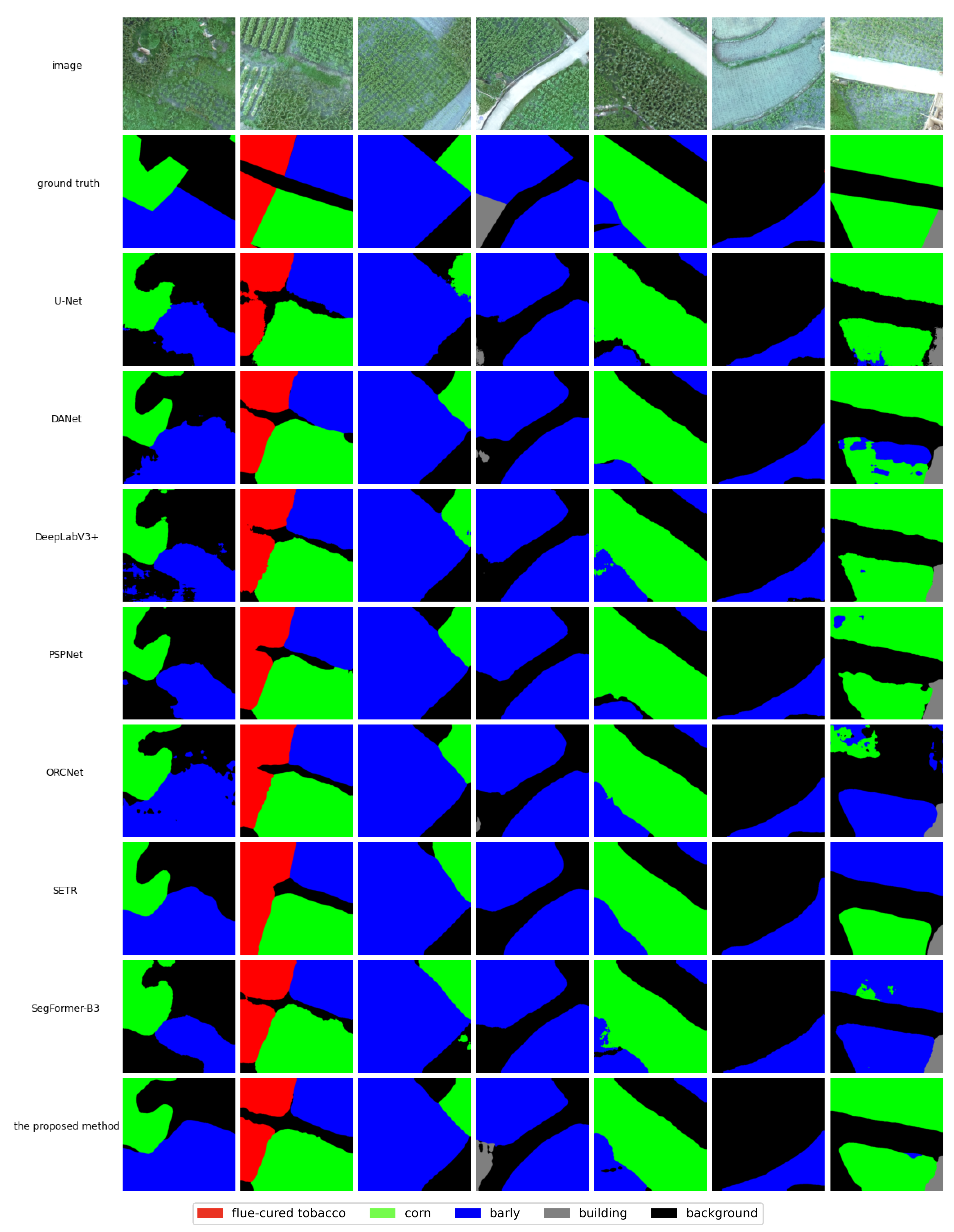
- U-Net [16] uses a U-shaped structured network to propagate contextual information from low-resolution layers to high-resolution layers via upsampling.
- PSPNet [39] exploits the capability of global contextual information by different region-based contextual aggregation through a pyramid pooling module.
- DeepLabV3+ [40] is the latest version of the DeepLab series networks, which uses atrous convolution to expand the receptive field and depth-wise separable convolution to improve feature-extraction efficiency.
- DANet [48] models semantic information using attention mechanism in both spatial and channel dimensions.
- OCRNet [49] explicitly transforms the pixel classification problem into an object–region classification problem using the object–contextual-representations approach.
- SETR [21] is a transformer-based network that replaces CNN completely with self-attention modules.
- SegFormer [28] is a simple and efficient, yet powerful, semantic segmentation network that is based on a transformer.
4. Results and Analysis
4.1. Crop-Type Segmentation Performance
4.2. Performance of Feature-Fusion Module
4.3. Performance of Decoders
5. Discussion
5.1. Classification vs. Segmentation for Crop Mapping
5.2. Local–Global Fusion Features of CTFuseNet
5.3. Fusion Strategies of CNN and Transformer
5.4. Statistical Significance Analysis
5.5. Model Transferability
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- FAO. The Future of Food and Agriculture–Trends and Challenges. Annu. Rep. 2017, 296, 1–180. [Google Scholar]
- Yi, Z.; Jia, L.; Chen, Q. Crop Classification Using Multi-Temporal Sentinel-2 Data in the Shiyang River Basin of China. Remote Sens. 2020, 12, 4052. [Google Scholar] [CrossRef]
- Mulla, D.J. Twenty Five Years of Remote Sensing in Precision Agriculture: Key Advances and Remaining Knowledge Gaps. Biosyst. Eng. 2013, 114, 358–371. [Google Scholar] [CrossRef]
- Liu, J.; Xiang, J.; Jin, Y.; Liu, R.; Yan, J.; Wang, L. Boost Precision Agriculture with Unmanned Aerial Vehicle Remote Sensing and Edge Intelligence: A Survey. Remote Sens. 2021, 13, 4387. [Google Scholar] [CrossRef]
- Valente, J.; Doldersum, M.; Roers, C.; Kooistra, L. Detecting Rumex Obtusifolius Weed Plants In Grasslands from UAV RGB Imagery Using Deep Learning. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. 2019, IV-2/W5, 179–185. [Google Scholar] [CrossRef] [Green Version]
- Furuya, D.E.G.; Ma, L.; Pinheiro, M.M.F.; Gomes, F.D.G.; Goncalvez, W.N.; Marcato Junior, J.; Rodrigues, D.d.C.; Blassioli-Moraes, M.C.; Michereff, M.F.F.; Borges, M.; et al. Prediction of Insect-Herbivory-Damage and Insect-Type Attack in Maize Plants Using Hyperspectral Data. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102608. [Google Scholar] [CrossRef]
- Abdulridha, J.; Batuman, O.; Ampatzidis, Y. UAV-Based Remote Sensing Technique to Detect Citrus Canker Disease Utilizing Hyperspectral Imaging and Machine Learning. Remote Sens. 2019, 11, 1373. [Google Scholar] [CrossRef] [Green Version]
- Apolo-Apolo, O.E.; Martínez-Guanter, J.; Egea, G.; Raja, P.; Pérez-Ruiz, M. Deep Learning Techniques for Estimation of the Yield and Size of Citrus Fruits Using a UAV. Eur. J. Agron. 2020, 115, 126030. [Google Scholar] [CrossRef]
- Feng, S.; Zhao, J.; Liu, T.; Zhang, H.; Zhang, Z.; Guo, X. Crop Type Identification and Mapping Using Machine Learning Algorithms and Sentinel-2 Time Series Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3295–3306. [Google Scholar] [CrossRef]
- Useya, J.; Chen, S. Comparative Performance Evaluation of Pixel-Level and Decision-Level Data Fusion of Landsat 8 OLI, Landsat 7 ETM+ and Sentinel-2 MSI for Crop Ensemble Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4441–4451. [Google Scholar] [CrossRef]
- Hariharan, S.; Mandal, D.; Tirodkar, S.; Kumar, V.; Bhattacharya, A.; Lopez-Sanchez, J.M. A Novel Phenology Based Feature Subset Selection Technique Using Random Forest for Multitemporal PolSAR Crop Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4244–4258. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Zhong, Y.; Hu, X.; Wei, L.; Zhang, L. A Robust Spectral-Spatial Approach to Identifying Heterogeneous Crops Using Remote Sensing Imagery with High Spectral and Spatial Resolutions. Remote Sens. Environ. 2020, 239, 111605. [Google Scholar] [CrossRef]
- Lei, L.; Wang, X.; Zhong, Y.; Zhao, H.; Hu, X.; Luo, C. DOCC: Deep One-Class Crop Classification via Positive and Unlabeled Learning for Multi-Modal Satellite Imagery. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102598. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. arXiv 2016, arXiv:1511.00561. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv 2017, arXiv:1606.00915. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, M.D.; Tseng, H.H.; Hsu, Y.C.; Tseng, W.C. Real-Time Crop Classification Using Edge Computing and Deep Learning. In Proceedings of the 2020 IEEE 17th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 10–13 January 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Osco, L.P.; Nogueira, K.; Marques Ramos, A.P.; Faita Pinheiro, M.M.; Furuya, D.E.G.; Gonçalves, W.N.; de Castro Jorge, L.A.; Marcato Junior, J.; dos Santos, J.A. Semantic Segmentation of Citrus-Orchard Using Deep Neural Networks and Multispectral UAV-based Imagery. Precis. Agric. 2021, 22, 1171–1188. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. arXiv 2021, arXiv:2012.15840. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems, Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. arXiv 2019, arXiv:1709.01507. [Google Scholar]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global Second-Order Pooling Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3024–3033. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Advances in Neural Information Processing Systems, Proceedings of the Conference on Neural Information Processing Systems, Virtual, 6–14 December 2021; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 12077–12090. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-Resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2021, 13, 71. [Google Scholar] [CrossRef]
- Wang, H.; Chen, X.; Zhang, T.; Xu, Z.; Li, J. CCTNet: Coupled CNN and Transformer Network for Crop Segmentation of Remote Sensing Images. Remote Sens. 2022, 14, 1956. [Google Scholar] [CrossRef]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. CMT: Convolutional Neural Networks Meet Vision Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12165–12175. [Google Scholar] [CrossRef]
- Li, Z.; Chen, G.; Zhang, T. A CNN-Transformer Hybrid Approach for Crop Classification Using Multitemporal Multisensor Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 847–858. [Google Scholar] [CrossRef]
- Li, Q.; Chen, Y.; Zeng, Y. Transformer with Transfer CNN for Remote-Sensing-Image Object Detection. Remote Sens. 2022, 14, 984. [Google Scholar] [CrossRef]
- Li, S.; Guo, Q.; Li, A. Pan-Sharpening Based on CNN plus Pyramid Transformer by Using No-Reference Loss. Remote Sens. 2022, 14, 624. [Google Scholar] [CrossRef]
- Liu, X.; Wu, Y.; Liang, W.; Cao, Y.; Li, M. High Resolution SAR Image Classification Using Global-Local Network Structure Based on Vision Transformer and CNN. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4505405. [Google Scholar] [CrossRef]
- Huang, L.; Wang, F.; Zhang, Y.; Xu, Q. Fine-Grained Ship Classification by Combining CNN and Swin Transformer. Remote Sens. 2022, 14, 3087. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Kirillov, A.; Girshick, R.; He, K.; Dollar, P. Panoptic Feature Pyramid Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 6399–6408. [Google Scholar]
- Tianchi. Barley Remote Sensing Dataset. 2020. Available online: https://tianchi.aliyun.com/dataset/74952 (accessed on 28 December 2022).
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5122–5130. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. arXiv 2019, arXiv:1809.02983. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. In Lecture Notes in Computer Science, Proceedings of the 16th European Conference Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 173–190. [Google Scholar] [CrossRef]
- Li, J.; Shen, Y.; Yang, C. An Adversarial Generative Network for Crop Classification from Remote Sensing Timeseries Images. Remote Sens. 2021, 13, 65. [Google Scholar] [CrossRef]
- Zhong, Y.; Hu, X.; Luo, C.; Wang, X.; Zhao, J.; Zhang, L. WHU-Hi: UAV-borne Hyperspectral with High Spatial Resolution (H2) Benchmark Datasets and Classifier for Precise Crop Identification Based on Deep Convolutional Neural Network with CRF. Remote Sens. Environ. 2020, 250, 112012. [Google Scholar] [CrossRef]
- Gogineni, R.; Chaturvedi, A.; B S, D.S. A Variational Pan-Sharpening Algorithm to Enhance the Spectral and Spatial Details. Int. J. Image Data Fusion 2021, 12, 242–264. [Google Scholar] [CrossRef]
- Qu, Y.; Zhao, W.; Yuan, Z.; Chen, J. Crop Mapping from Sentinel-1 Polarimetric Time-Series with a Deep Neural Network. Remote Sens. 2020, 12, 2493. [Google Scholar] [CrossRef]
- Shakya, A.; Biswas, M.; Pal, M. Fusion and Classification of Multi-Temporal SAR and Optical Imagery Using Convolutional Neural Network. Int. J. Image Data Fusion 2022, 13, 113–135. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef] [Green Version]
- Gildenblat, J. PyTorch Library for CAM Methods, 2021. Available online: https://github.com/jacobgil/pytorch-grad-cam (accessed on 29 September 2022).
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Lecture Notes in Computer Science, Proceedings of the 16th European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:cs/2102.04306. [Google Scholar] [CrossRef]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. CoAtNet: Marrying Convolution and Attention for All Data Sizes. In Advances in Neural Information Processing Systems, Proceedings of the Conference on Neural Information Processing Systems, Online Event, 6–14 December 2021; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 3965–3977. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local Features Coupling Global Representations for Visual Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 367–376. [Google Scholar]
- McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef]
- Foody, G.M. Thematic Map Comparison. Photogramm. Eng. Remote Sens. 2004, 70, 627–633. [Google Scholar] [CrossRef]
- Crisóstomo de Castro Filho, H.; Abílio de Carvalho Júnior, O.; Ferreira de Carvalho, O.L.; Pozzobon de Bem, P.; dos Santos de Moura, R.; Olino de Albuquerque, A.; Rosa Silva, C.; Guimarães Ferreira, P.H.; Fontes Guimarães, R.; Trancoso Gomes, R.A. Rice Crop Detection Using LSTM, Bi-LSTM, and Machine Learning Models from Sentinel-1 Time Series. Remote Sens. 2020, 12, 2655. [Google Scholar] [CrossRef]
- Greenwood, P.E.; Nikulin, M.S. A Guide to Chi-Squared Testing; John Wiley & Sons: Hoboken, NJ, USA, 1996; Volume 280. [Google Scholar]
- Seabold, S.; Perktold, J. statsmodels: Econometric and statistical modeling with python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June –3 July 2010. [Google Scholar]
- Lunga, D.; Arndt, J.; Gerrand, J.; Stewart, R. ReSFlow: A Remote Sensing Imagery Data-Flow for Improved Model Generalization. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 10468–10483. [Google Scholar] [CrossRef]
- Tong, X.Y.; Xia, G.S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote. Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef] [Green Version]
- Zhang, E.; Liu, L.; Huang, L.; Ng, K.S. An automated, generalized, deep-learning-based method for delineating the calving fronts of Greenland glaciers from multi-sensor remote sensing imagery. Remote. Sens. Environ. 2021, 254, 112265. [Google Scholar] [CrossRef]
- Qin, R.; Liu, T. A Review of Landcover Classification with Very-High Resolution Remotely Sensed Optical Images-Analysis Unit, Model Scalability and Transferability. Remote. Sens. 2022, 14, 646. [Google Scholar] [CrossRef]
- Xiong, Y.; Guo, S.; Chen, J.; Deng, X.; Sun, L.; Zheng, X.; Xu, W. Improved SRGAN for Remote Sensing Image Super-Resolution Across Locations and Sensors. Remote. Sens. 2020, 12, 1263. [Google Scholar] [CrossRef] [Green Version]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference On Computer Vision And Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; pp. 3141–3149. [Google Scholar] [CrossRef] [Green Version]
- He, F.; Liu, T.; Tao, D. Why ResNet Works? Residuals Generalize. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5349–5362. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, Q.; Zhang, Y.; Wang, L.; Zhong, Y.; Guan, Q.; Lu, X.; Zhang, L.; Li, D. A Global Context-aware and Batch-independent Network for road extraction from VHR satellite imagery. ISPRS J. Photogramm. Remote. Sens. 2021, 175, 353–365. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resolutions | Categories | Pixel Value |
|---|---|---|
| flue-cured tobacco | 1 | |
| corn | 2 | |
| barley | 3 | |
| building | 4 | |
| background | 0 |
| Method | IoU(%) per Category | PA(%) | mIoU(%) | ||||
|---|---|---|---|---|---|---|---|
| Background | Flue-Cured Tobacco | Corn | Barley | Building | |||
| U-Net | 84.25 | 93.14 | 73.85 | 73.54 | 68.89 | 89.17 | 78.73 |
| DANet | 87.44 | 94.67 | 76.67 | 76.68 | 80.75 | 91.51 | 83.64 |
| DeepLabV3+ | 87.36 | 94.45 | 76.39 | 78.13 | 80.01 | 91.36 | 83.27 |
| PSPNet | 87.86 | 94.37 | 77.43 | 78.77 | 80.65 | 91.69 | 83.82 |
| OCRNet | 87.78 | 93.98 | 76.71 | 77.44 | 81.89 | 91.48 | 83.56 |
| SETR | 87.07 | 94.09 | 76.46 | 77.31 | 79.96 | 91.14 | 82.98 |
| SegFormer-B3 | 88.25 | 95.39 | 77.08 | 78.98 | 82.67 | 91.92 | 84.47 |
| CTFuseNet (SegFormer-B3 + ResNet50) | 88.89 | 95.16 | 78.61 | 80.84 | 83.13 | 92.46 | 85.33 |
| Method | Fuse Strategy | Decoder | PA(%) | mIoU(%) | Img/s |
|---|---|---|---|---|---|
| SegFormer-B3 | - | MLPHead | 91.92 | 84.47 | 18.0 |
| SegFormer-B3 + ResNet50 | Conv2d & Add | FPNHead | 92.25 | 84.98 | 14.3 |
| CTFuseNet (SegFormer-B3 + ResNet50) | CTFuse Module | FPNHead | 92.46 | 85.33 | 14.0 |
| Method | Decoder | PA(%) | mIoU(%) | Img/s |
|---|---|---|---|---|
| SegFormer-B3 | MLPHead | 91.92 | 84.47 | 18.0 |
| SegFormer-B3 + ResNet50 | MLPHead | 92.41 | 85.2 | 14.0 |
| CCTFuseNet (SegFormer-B3 + ResNet50) | FPNHead | 92.46 | 85.33 | 14.0 |
| Classification 2 | ||||
|---|---|---|---|---|
| Correct | Incorrect | ∑ | ||
| Classification 1 | Correct | |||
| Incorrect | ||||
| ∑ | + | 1 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, J.; Liu, J.; Chen, D.; Xiong, Q.; Deng, C. CTFuseNet: A Multi-Scale CNN-Transformer Feature Fused Network for Crop Type Segmentation on UAV Remote Sensing Imagery. Remote Sens. 2023, 15, 1151. https://doi.org/10.3390/rs15041151
Xiang J, Liu J, Chen D, Xiong Q, Deng C. CTFuseNet: A Multi-Scale CNN-Transformer Feature Fused Network for Crop Type Segmentation on UAV Remote Sensing Imagery. Remote Sensing. 2023; 15(4):1151. https://doi.org/10.3390/rs15041151
Chicago/Turabian StyleXiang, Jianjian, Jia Liu, Du Chen, Qi Xiong, and Chongjiu Deng. 2023. "CTFuseNet: A Multi-Scale CNN-Transformer Feature Fused Network for Crop Type Segmentation on UAV Remote Sensing Imagery" Remote Sensing 15, no. 4: 1151. https://doi.org/10.3390/rs15041151
APA StyleXiang, J., Liu, J., Chen, D., Xiong, Q., & Deng, C. (2023). CTFuseNet: A Multi-Scale CNN-Transformer Feature Fused Network for Crop Type Segmentation on UAV Remote Sensing Imagery. Remote Sensing, 15(4), 1151. https://doi.org/10.3390/rs15041151