1. Introduction
The ocean covers a vast volume and contains abundant resources. With the depletion of land resources, the development of the world economy and technology, and the continuous enhancement of military strength, countries worldwide have shifted their research focus to the ocean. Imaging Radar and Sonar (RS) are indispensable sensor devices in underwater remote sensing and can provide rich visual information about the observed area. Consequently, considerable research has been conducted on automatic target recognition [
1] in sonar images. Side-Scan Sonar (SSS) emits short sound pulses, and the sound waves propagate outward in the form of spherical waves.
The sound waves are scattered when they hit objects, and the backscattered waves will be received by the transducer according to the original propagation route and converted into a series of electrical pulses. The received data of each emission cycle are arranged vertically to form a row of an SSS image, and multiple such rows are concatenated to form a complete SSS image. Due to the complexity of underwater environments and severe seabed reverberation, sonar images are affected by various types of noise, such as Gaussian, impulse, and speckle noise [
2,
3,
4,
5,
6]. Noise can result in the loss of image detail, reduced contrast, and blurred edges, making SSS target identification more difficult. Therefore, target identification in sonar images acquired in harsh environments is an ongoing research challenge.
In recent years, RS target detection and recognition using Deep Learning (DL) have been extensively investigated due to the advantages of high accuracy, strong robustness, and amenity to parallelized implementations [
7,
8,
9]. This has resulted in a new trend of using DL methods for the automated recognition of targets in SSS images. Related studies have shown that utilizing a CNN for SSS object recognition is more effective than traditional methods (K-nearest neighbors [
10], SVM [
11], Markov random field [
12]) [
13,
14,
15,
16,
17,
18]. In order to extract deeper target features, Simonyan, Krizhevsky Alex, and HeKaiming et al. proposed the VGG [
19], AlexNet [
20], ResNet [
21], and DenseNet [
22] algorithms, respectively, based on Convolutional Neural Networks (CNNs). Especially in the cases of ResNet and DenseNet, the number of deep network layers is expanded to 152 and 161 layers, respectively (ResNet-152, DenseNet-161) [
23,
24], proving that deep network models are excellent for image recognition. However, for SSS image target recognition, where it is difficult to obtain training samples, it is challenging to develop practical DL methods.
Deep networks are generally divided into a backbone and a head. The backbone network utilizes a CNN for feature extraction [
20,
25,
26], and the head network uses the features obtained from the backbone network to predict the target category. In target recognition using Transfer Learning (TL) methods, the backbone network is pre-trained on an external large-scale classification dataset (such as ImageNet [
27]), and then, the head network is fine-tuned on the target dataset to alleviate the problem of insufficient target sample data. Pre-training on ImageNet has an advantage in general object recognition and is helpful for object recognition on small-scale datasets, such as those available for SSS [
28].
Therefore, using TL methods to identify SSS targets is a practical approach and a research focus to solve the problem of SSS data shortage. Researchers have thus conducted a series of related studies on TL-based object recognition in SSS images.
2. Related Work
Regarding current research on TL, Ye, X. et al.applied VGG-11 and ResNet-18 to target recognition in SSS images under water and adopted the TL method to fine-tune the fully connected layer to address the problem of the low recognition rates caused by insufficient data samples. However, the data difference between the source and transfer datasets was not fully considered during the data transfer process, so the effect was not significantly improved [
13]. Yulin, T. et al. applied TL to the target detection method. In the head network, two loss functions, the position and target recognition errors, were employed to perform position detection concurrently with target recognition. The algorithm is an improvement of YOLO [
29] and R-CNN [
30], but in the target detection process, the size of the feature anchor box is predetermined based on experience, limiting the detection ability of targets with large-scale changes [
31,
32,
33]. Chandrashekar et al. utilized TL from optical to SSS images to enhance underwater sediment images and increase their signal-to-noise ratio [
34]. Guanying H. et al. used semi-synthetic data and different modal data to fine-tune the parameters of VGG-19 to improve its generalization further. Using semi-synthetic data requires the target’s segmentation in the optical image, which is then transplanted into the SSS image. Only the background of the synthesized image possesses the SSS image’s characteristics, while the target does not. There is still a difference between the synthesized image and the SSS image sample, which directly affects the target recognition result [
14,
35].
Although TL has helped generic DL object recognition models achieve accuracies as high as 87% [
13] and 97.76% [
14] on small-scale SSS datasets, little attention has been paid to the following challenges:
Challenge 1: Because optical and SSS images have apparent differences in terms of perspective, noise, background noise, and resolution, current attempts to transfer optical image training models to SSS images cannot strictly meet the requirements of TL-based target recognition.
Challenge 2: For SSS images, generic DL network frameworks (such as VGG, ResNet, and others) have many parameters, making them susceptible to overfitting when trained on small sample datasets for object identification. This severely limits their generalization capability.
To tackle the first challenge, the proposed approach in this paper changes the style of the optical images using suitable transformations. Hence, the transformed image has the characteristics of noise, background noise, and resolution similar to SSS images. This reduces the discrepancies between the optical and SSS images, decreasing the occurrence of negative transfer in TL and the hindering effect of optical images on SSS images during network parameter learning, and improves the adaptability of transfer networks to SSS images.
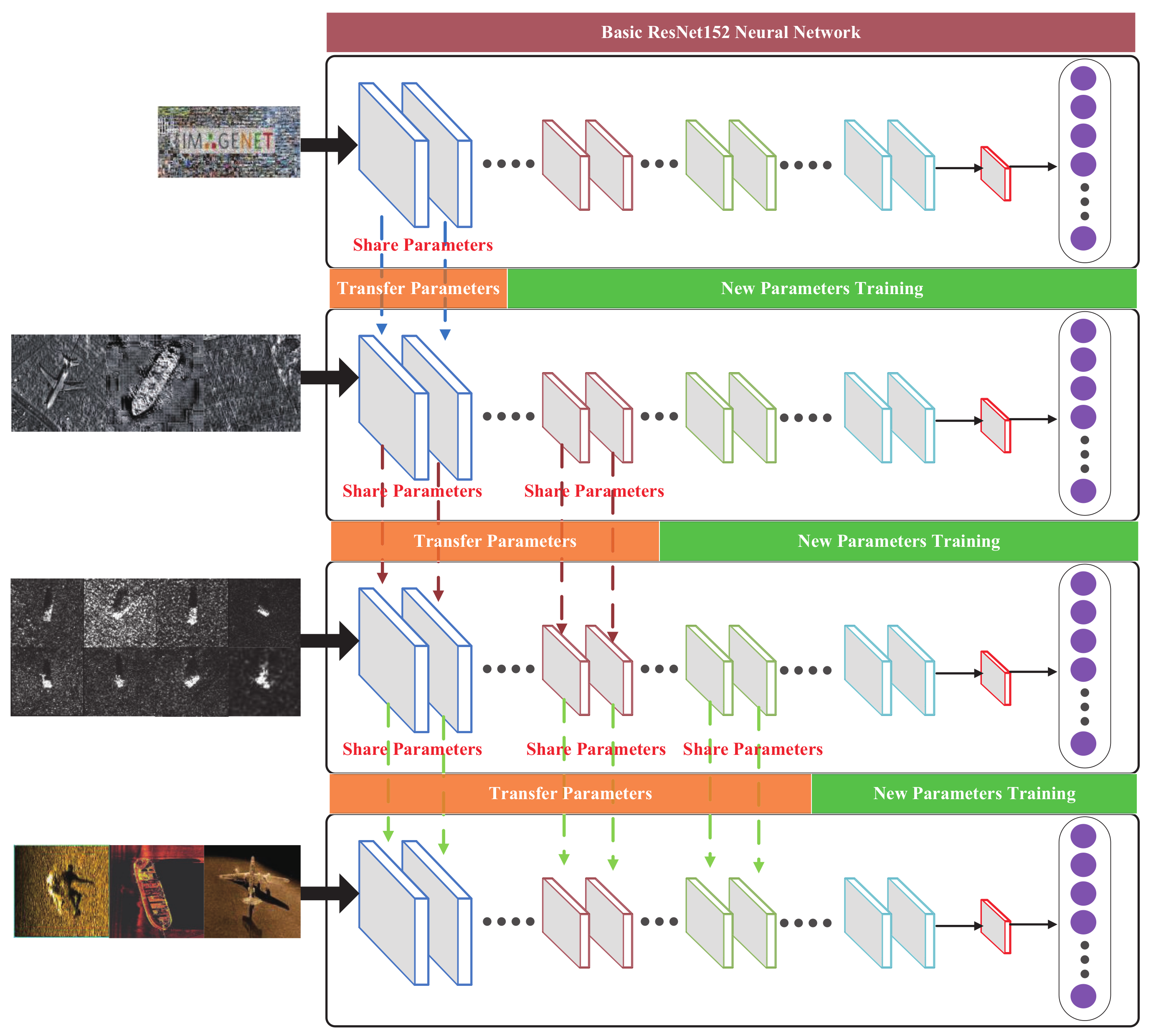
For the second challenge, it is necessary to design a particular dataset and TL strategy to pre-train a backbone network with many parameters and fine-tune the features of a head network with a smaller number of parameters based on the SSS dataset. Following a traditional TL approach, the backbone network is divided into multiple sub-backbone networks, and optical, synthetic, and SAR datasets are used in sequence to train the backbone network. In this manner, the ability of the backbone network to extract features is increased.
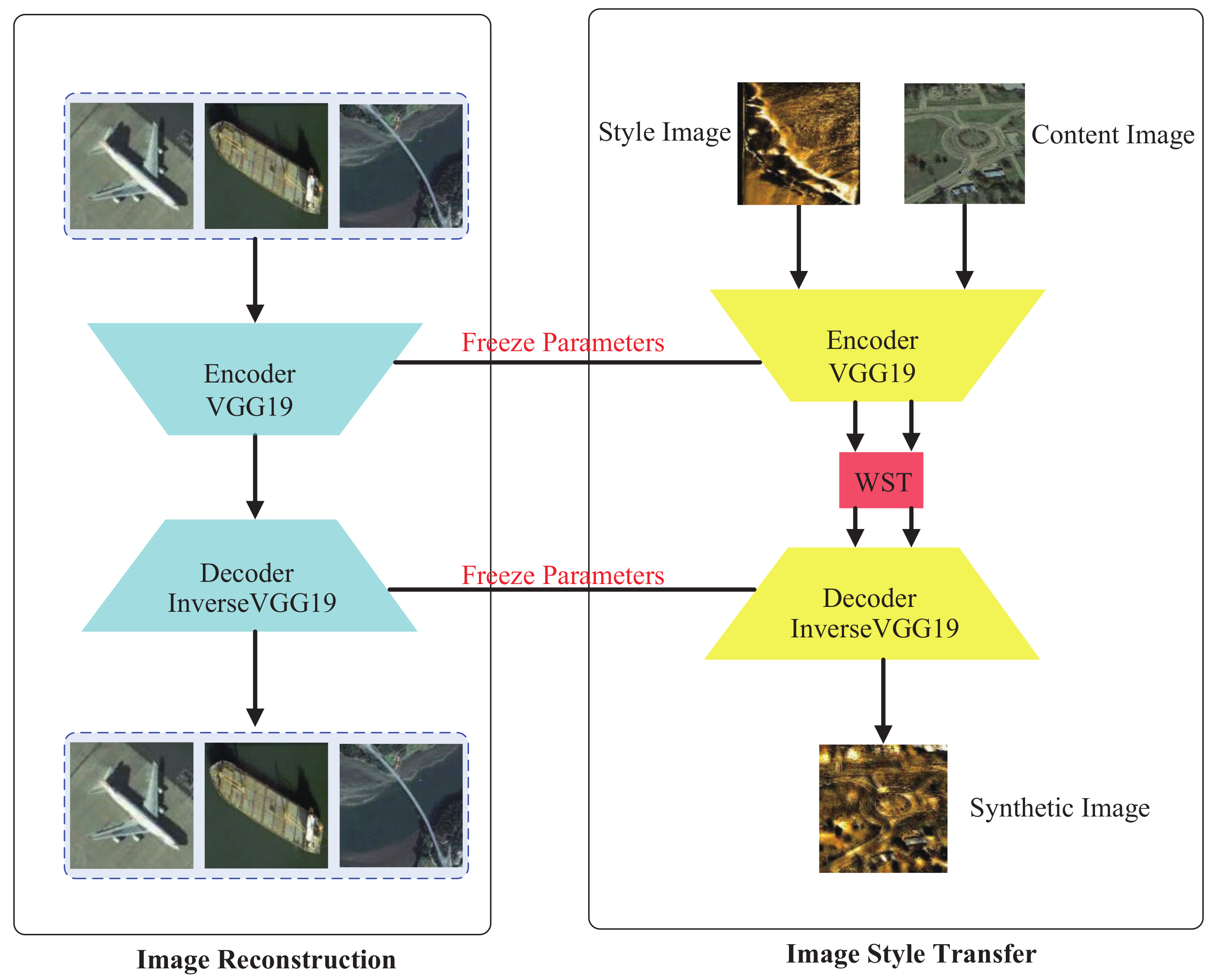
In this work, the problem of the recognition accuracy degradation caused by the difference between optical images and SSS images was addressed via TL. First, optical images were transformed through whitening and style transforms (WSTs) using an encoding–decoding model, resulting in a synthetic dataset. Then, using optical, synthetic, SAR, and SSS data, the different feature layers of the network were trained in stages to obtain stable features that were robust to interference. Finally, the features were applied to identify the SSS targets.
The main contributions of this article are summarized as follows:
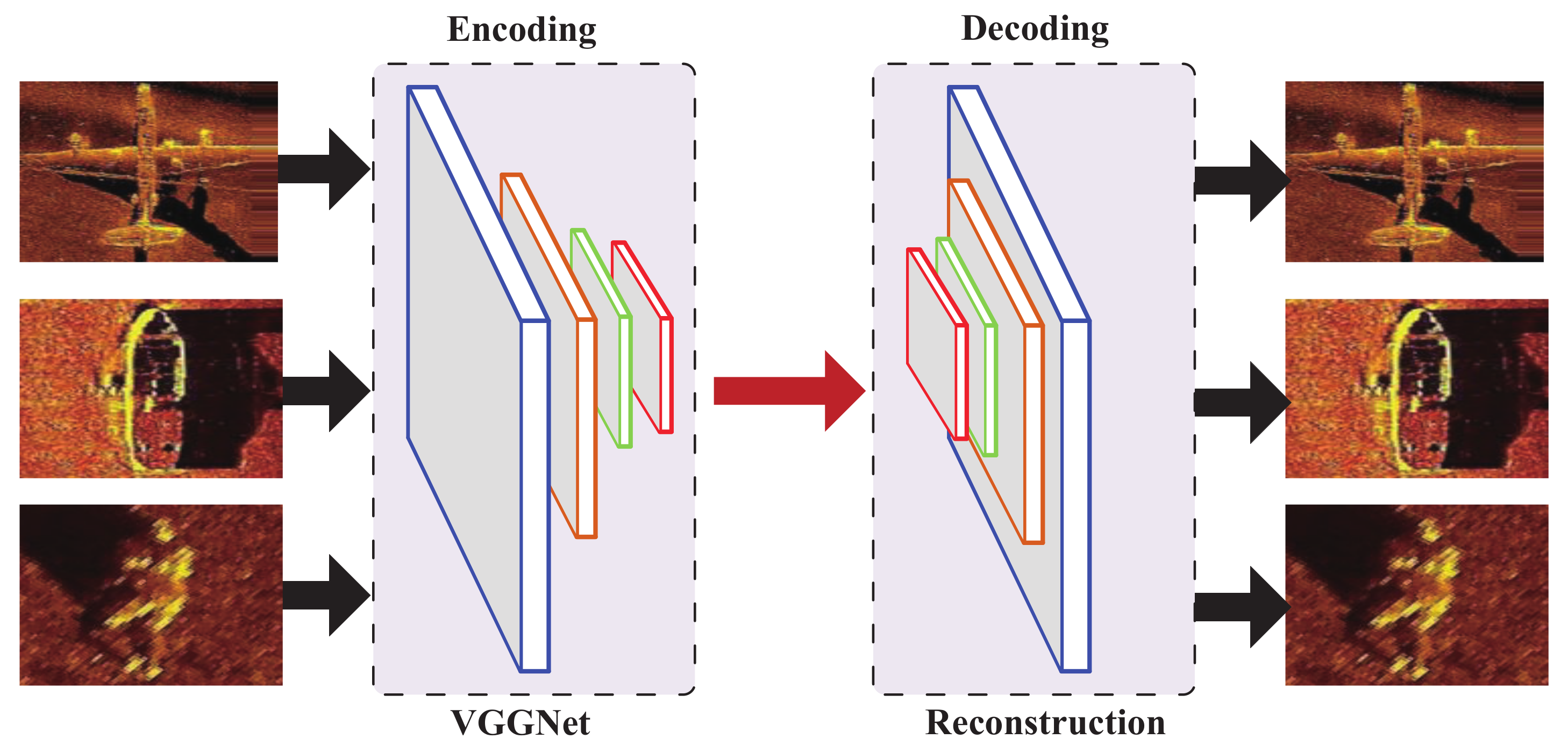
1. Using the WST method, the optical target image is styled through an encoder–decoder model to achieve a simulated SSS target image with similar background noise and characteristics to the actual SSS image.
2. Based on a TL framework, a multi-modal staged parameter optimization strategy is designed. Four modal datasets (ImageNet, a transformed SSS-style, a synthetic aperture radar, and actual SSS datasets) were used, and the parameters were roughly adjusted for the backbone network’s front, middle, and rear sections and then fine-tuned. This solves the problem of network overfitting and poor generalization performance in target recognition.
3. In this paper, an image synthesis method is proposed that uses feature transformation to directly match the content and style information in the style image and combines feature transformation with a pre-trained encoder–decoder model to achieve image style conversion through simple forward transfer. This addresses the challenging problems of the simulation of targets with varying complex shapes and reduces the computational load and the effect of the too-ideal intensity distribution in the SSS image synthesis method.
The rest of this article is organized as follows: In
Section 3, the image synthesis method based on an encoder–decoder model is discussed from a theoretical perspective, and a style-culling method (whitening transformation) and a style-adding method (style transfer) are presented for the content images. From the perspective of TL-based SSS target recognition, a multi-stage TL strategy is designed to obtain consistent features. In
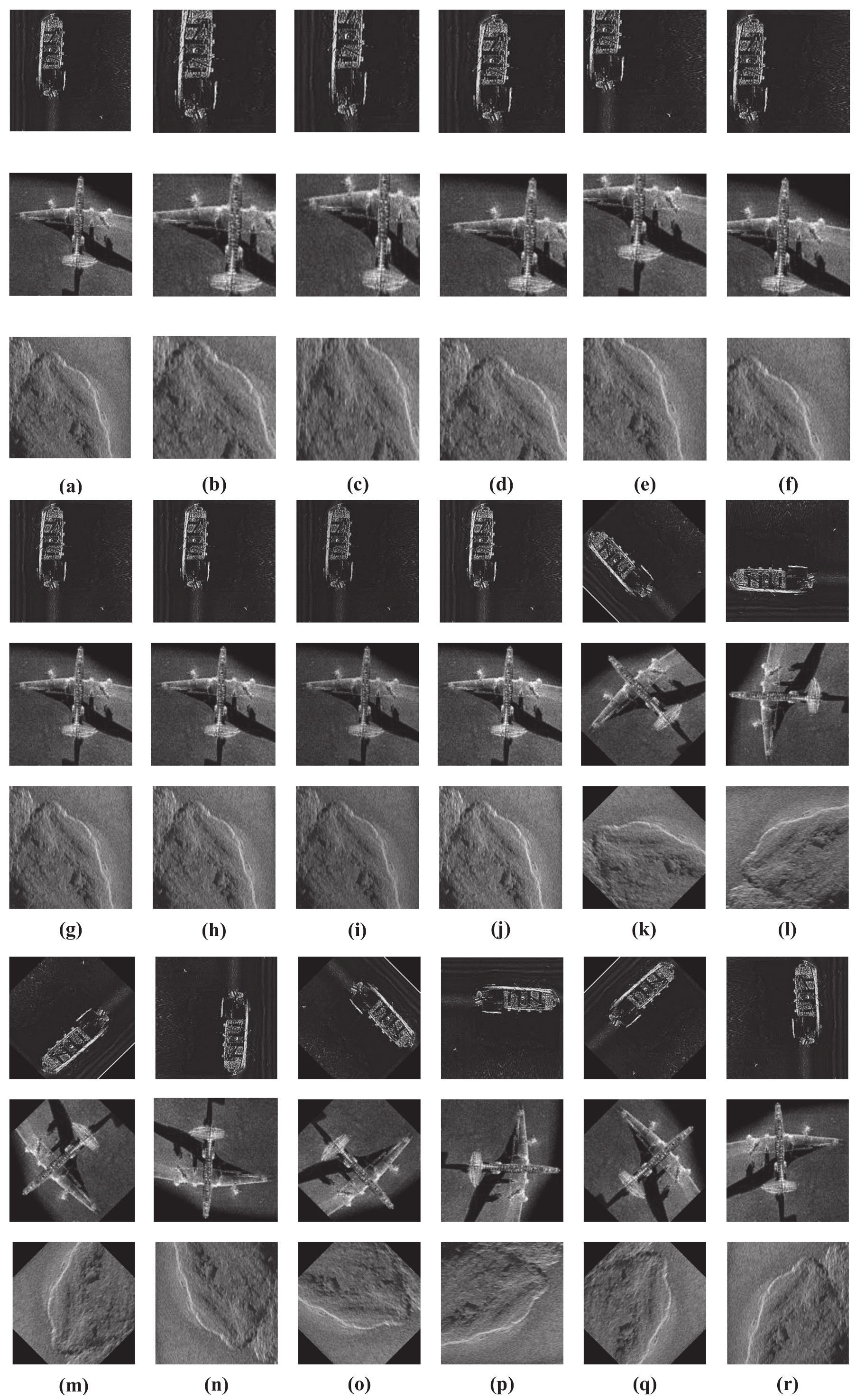
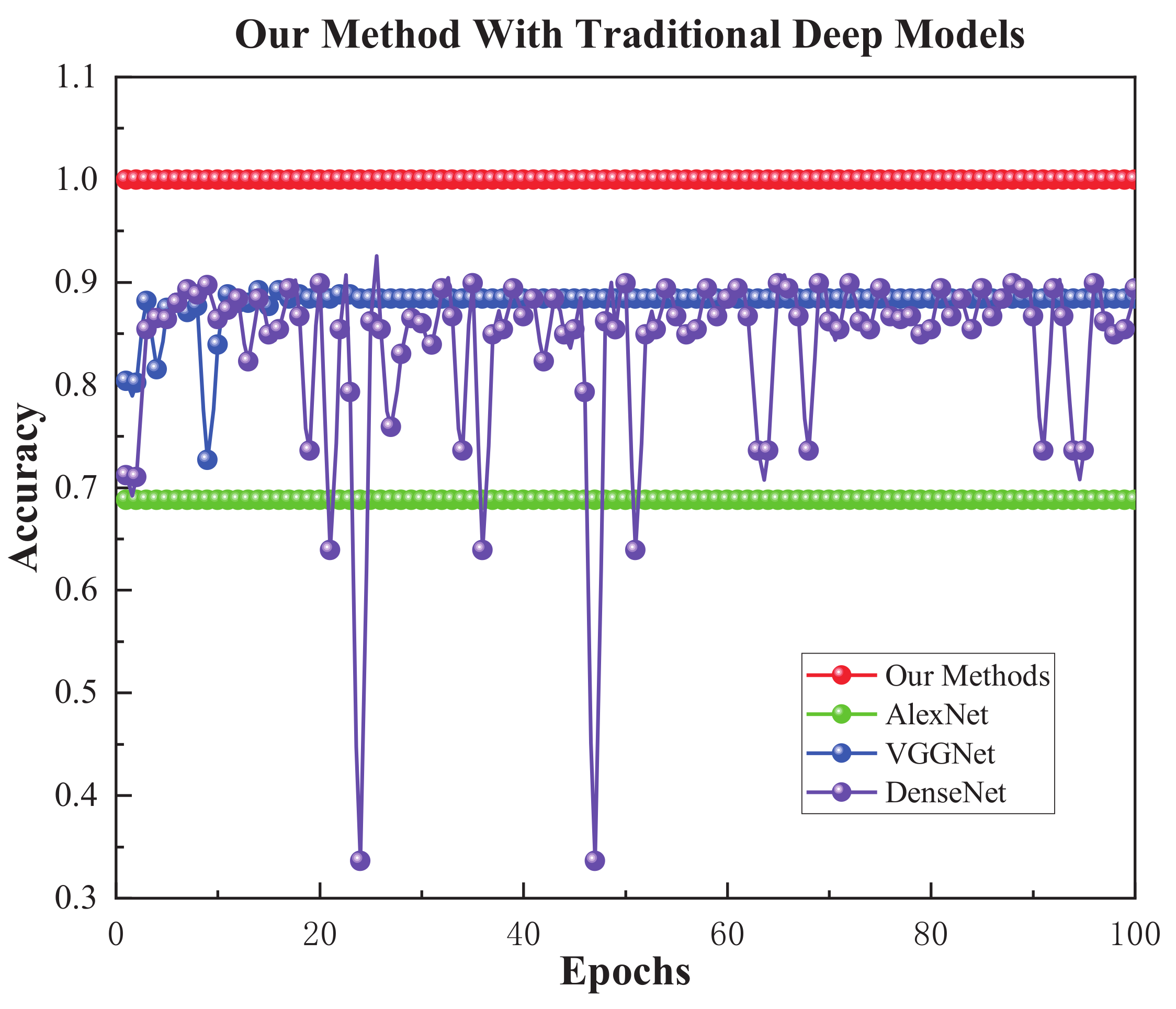
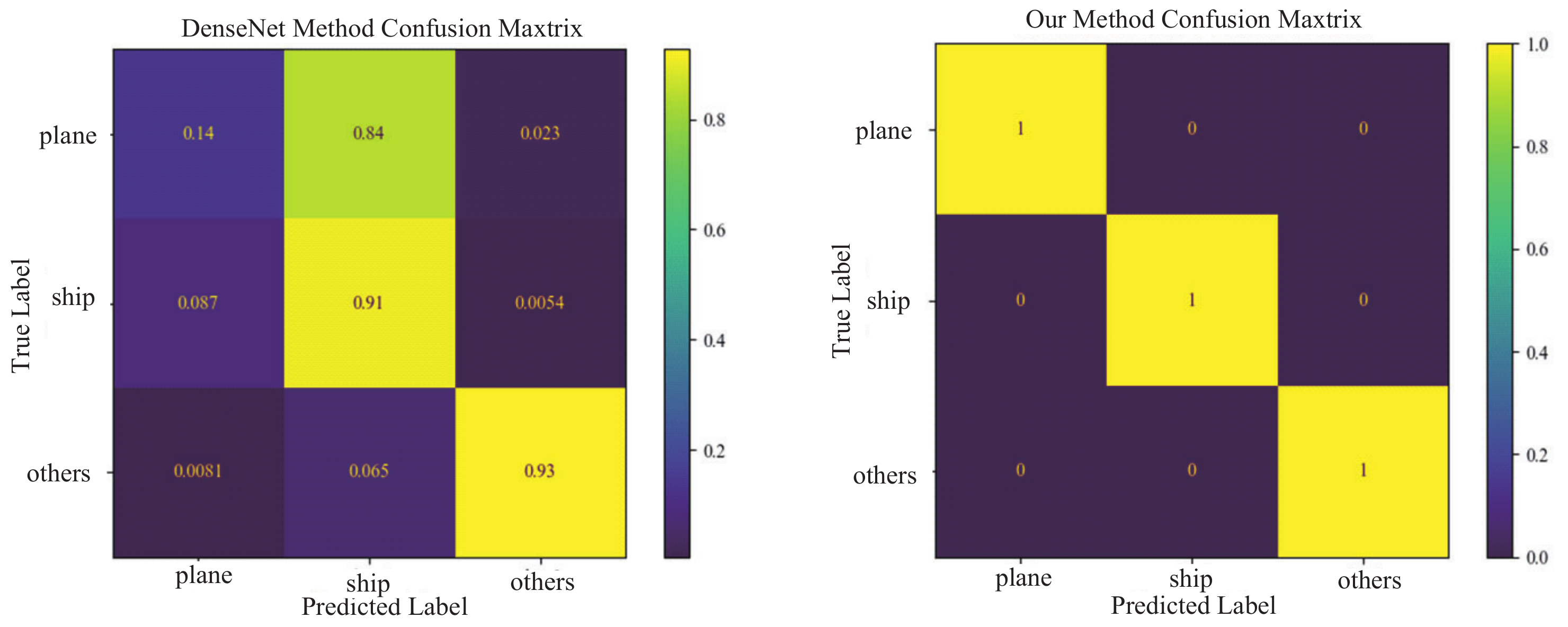
Section 4, the proposed approach is compared to classical DL algorithms, and the accuracy, precision, recall, F1, and other indicators are analyzed. At the same time, the proposed method is compared to various TL networks in terms of the recognition rate.
5. Discussion
This paper solved the problem of the low recognition rates caused by the difference between the transfer domain samples and the target domain samples in the TL target recognition methods. A synthetic sample dataset was thus proposed to identify SSS targets and multi-dataset joint TL-based recognition.
5.1. Method Importance
The data synthesis method proposed in this paper provides a new approach to underwater target recognition. It is extremely useful as a recognition method when small amounts of class samples are available and acquiring additional samples is costly or dangerous.
The WST image transformation method was introduced, and the SSS style transfer was performed on optical data using an encoding–decoding model. This method reduces the problem of data source differences in target recognition and provides a solution and a new direction for TL-based underwater target recognition.
The deep network multi-modal migration strategy is introduced in stages so that the recognition model can extract deeper feature information as the number of network layers continues to increase. This approach was adopted because the signal-to-noise ratio of the dataset used was reduced, so the extracted features needed strong noise robustness.
5.2. Algorithm Limitations
The proposed method achieved good performance in the experiment, but the number of data sample categories was small, while the effect of target recognition will decrease as this number increases. At the same time, there are many kinds of targets in underwater environments, including airplanes and ships, and many smaller objects. Therefore, a deep network model that can extract stronger discriminative features is required.
In addition, the datasets used in this paper are suitable for supervised training. The recognition effect of the proposed method will decline when training sets suitable for weak supervision are used.
Because there is a large amount of unlabeled data in the weakly supervised training dataset, making the sample size of the original SSS dataset comparably smaller, in the process of network training, the recognition rate of the training data was high. However, the recognition accuracy on the test dataset reduced, indicating that overfitting occurred. At the same time, the proposed method’s network parameters are large, and the above problems are more likely to occur. Therefore, there is still room for improvement of the proposed method by adopting semi-supervised training methods. A network trained in a semi-supervised manner can learn the parameters of the unsupervised network through the unlabeled data in the limited training dataset and use the labeled data for fine-tuning, improving the semi-supervised target recognition effect.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}