1. Introduction
Tropical and subtropical dry forests are one of fourteen biomes identified at the global scale [
1]. In Mexico, tropical dry forests (TDFs) cover extensive areas in the western Pacific lowland from southern Sonora to northern and central Chiapas [
2]. TDFs host a large variety of fauna and flora, playing an important role in biodiversity conservation and providing food and shelter for local people [
3,
4]. Despite having the highest level of endemism in the American continent [
5], TDFs in Mexico are conventionally perceived as having less commercial value compared with temperate forests, and they are mainly designated for shifting cultivation and cattle ranching [
6,
7].
Land use and land cover change (LULCC) contributes to about one-tenth of the annual carbon emissions [
8], in which deforestation shares more than three times that of the other LULCC categories combined [
9]. In Mexico, at the national level, TDF decreased at a rate of 0.4%, about 100,000 ha every year [
10]. Regional studies have reported higher deforestation rates, reaching 1.4% per year [
11]. Large dry forest tracts have disappeared in recent years mainly to support agriculture and cattle ranching. About 70% of pre-Hispanic TDF has been converted to other land use types, and about 62% of the remaining TDF is in an altered and disturbed state [
6]. In addition to carbon loss, the loss of TDF leads to the loss of biodiversity and soil erosion and increases the vulnerability of local people who depend on TDFs for food and shelter. The disturbance also fundamentally alters environmental conditions and constrains the forest’s capacity to regenerate [
12].
In previous studies, different drivers have been associated with the LULCC of tropical forests, such as the expansion of agriculture (frequently large-scale and industrialized) or livestock activities, as well as socio-economic conditions such as poverty. Especially, topographical and distance-related measures have been reported as determinant factors to explain which areas will undergo a LULCC process. For example, it was reported that the probability of an area experiencing a LULCC process is related to a poverty index, the population size of nearby settlements, topographical variables, and distance to roads [
13]. Nonetheless, these can sometimes be a product of complex relationships [
13,
14].
Shifting cultivation is widely practiced in the global south and plays an important role in food security in Asian, African, and Latin American countries [
15,
16]. In Mexico, shifting cultivation is the main driver of disturbances in TDFs, especially in the southern part of the country [
17]. This agriculture system includes cycles of clearing, cultivation, and fallow period. During clearing, the standing vegetation is cut down and burned to create fields and produce ash which provides nutrients for farming. The cleared parcels have an average size of 2.5 ha and crops are grown for subsistence [
18]. Cultivation starts during the rainy season when maize crops are planted and harvested after six months of growth. After harvesting until the next plantation, livestock graze on crop residues. The cultivation cycle repeats for about 2–3 years and then the land is left to rest in a fallow period for about 3–8 or more years, during which natural vegetation grows as a mixture of shrubs and trees. Shifting cultivation creates a landscape with a mosaic of patches currently being cropped and patches in the fallow period with natural vegetation under various stages of regeneration. The regenerated natural vegetation keeps the area a forest, however, with less biomass density [
19].
This paper aims to understand the contributing factors to the dynamics of TDFs and whether there is a balance between TDF loss and gain under the influence of shifting cultivation. We first obtained areas of TDF loss and gain by comparing multiple dates of land use land cover maps created by classifying Sentinel-2A images with a machine learning algorithm. Then, using a logistic regression model, we analyzed the plausible factors including topographic, anthropogenic, and land ownership that are associated with TDF changes. Lastly, we projected the areas of future TDF loss and gain to shifting cultivation.
2. Materials and Methods
2.1. Study Area
The study area is within the Ayuquila River watershed, in the state of Jalisco, Mexico (
Figure 1). It is one of the first areas in Mexico designated as a Reduction of Emission from Deforestation and Forest Degradation (REDD+) experimental area because of its importance in biodiversity and water provision, among other ecosystem services [
20]. The watershed has a wide range in topography, from 260 m to 2500 m above mean sea level (amsl). The monthly average temperature is about 18–22 degrees Celsius, and the annual average precipitation is 800–1200 mm, which occurs mainly during the rainy season, from June to October [
21]. The dominant forest type is TDF, which is comprised of deciduous and semi-deciduous trees that lose their leaves during the dry season, typically from November to May. TDF covers about 24% of the watershed, and it has been intensively used for shifting cultivation, cattle grazing, and fuel wood collection. As in the rest of Mexico, most of the forests (59% to 80%) in the Ayuquila watershed are under the authority of ejidos, which is a communally managed land tenure system of rural agrarian settlements [
18].
2.2. Data
This study collected and used a variety of datasets (
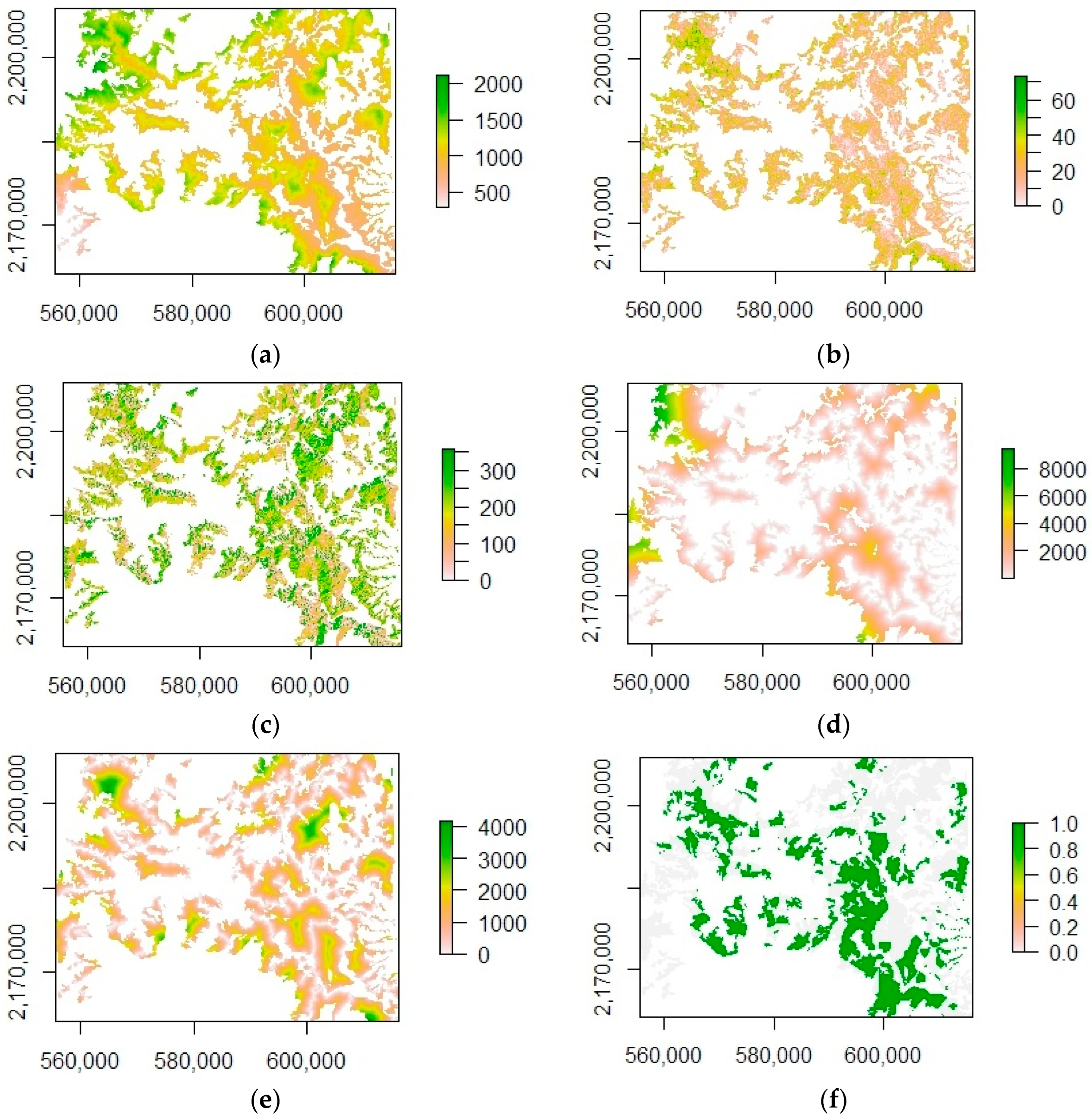
Table 1). Sentinel-2A images were obtained from Google Earth Engine archive. All Sentinel-2A bottom-of-atmosphere reflectance images were atmospherically corrected with Copernicus scihub using the sen2cor algorithm. In addition, elevation data (Digital Elevation Model: DEM) were obtained from the official website of the National Institute of Statistics and Geography (INEGI) of Mexico with a 15 m spatial resolution, and the topographic variables of slope and aspect were calculated using the DEM to reflect terrain changes. Data on accessibility including distance to roads and distance to agriculture were calculated using the proximity function with roads data downloaded from the INEGI and agriculture data (including both irrigated and temporal agriculture) extracted from the INEGI land use land cover and vegetation maps, series VII, at the scale of 1:250,000.
2.3. Classification
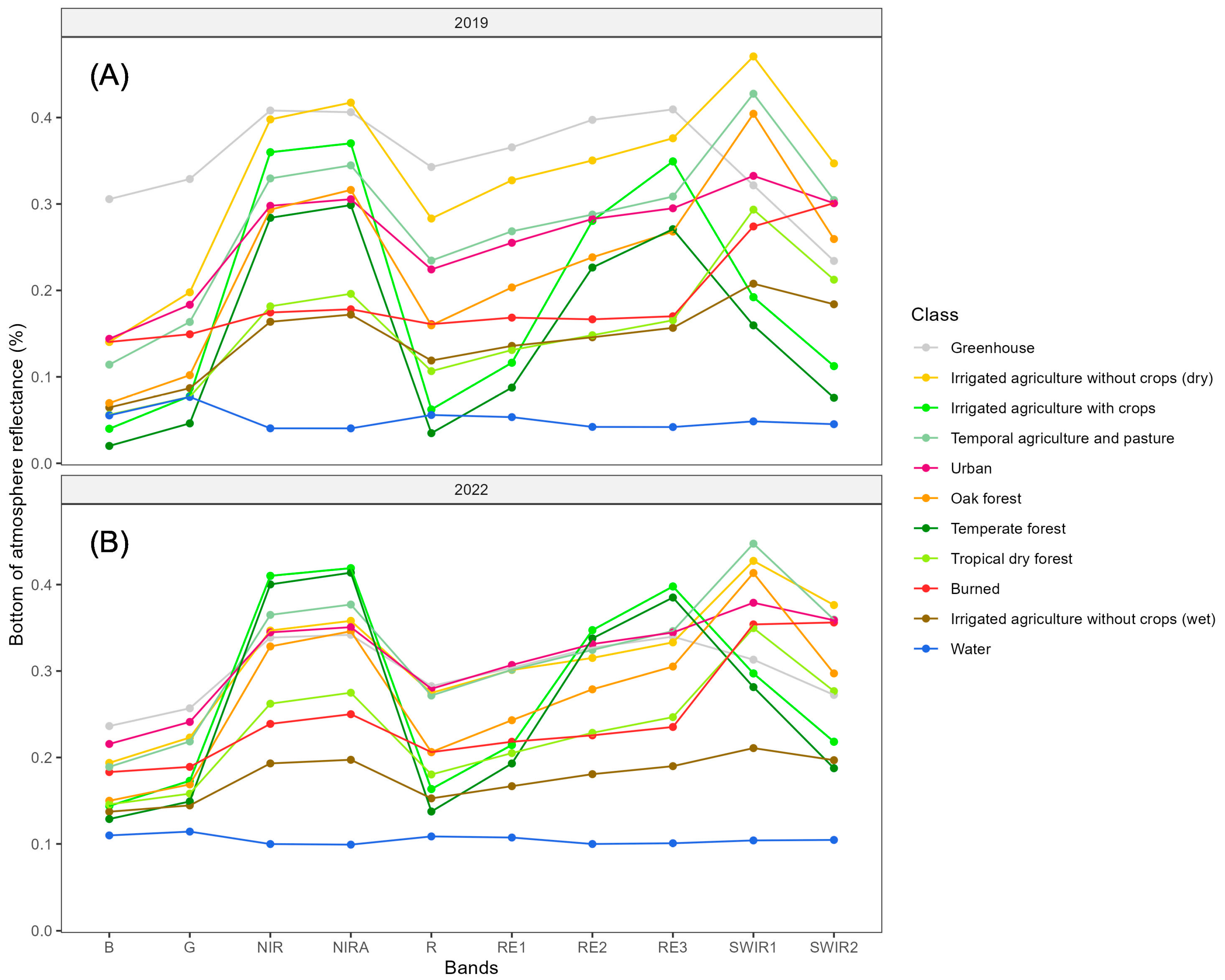
Training samples were collected for the eleven land use/land cover classes (
Table 2), using Sentinel-2A images and high spatial resolution images in Google Earth (GE) as reference. The number of training samples for the 2019 and 2022 imagery is presented in the last column of
Table 2.
Figure 2 shows the distribution of the sample classes in Sentinel-2A bands. We also referred to the INEGI land use land cover and vegetation maps, series VII (1:250,000), which was produced during the period of 2015–2017 for the spatial distribution of different types of forests and agriculture. The distribution of TDF and oak and pine forests shows a general ascending pattern following elevation. We used two classification algorithms, namely artificial neural network and random forest, to classify the Sentinel-2A images in 2019 and 2022.
2.3.1. Artificial Neural Network
Artificial neural network (ANN) is a machine learning algorithm that uses a network of nodes to perform supervised classifications [
22,
23]. Typically, each neuron in an ANN receives a series of inputs, and then performs a weighted sum of them and outputs a value of 1 if its sum is over a threshold and a value of 0 if not. Finally, the complete network can classify a different set of inputs based on the neuron’s weights [
24]. Training a neural network requires that the user specifies the network structure and sets the learning parameters [
22]. In our case, to train the ANN, the sample data were split in the proportion of 0.7, with 70% of the data assigned as training data and the remaining 30% as test data. This algorithm applied a 5-fold cross-validation (CV) with 5 repetitions.
A 5-fold CV involves randomly dividing the training data into 5 groups, or folds, of approximately equal size [
25]. The first fold is treated as a validation set, and the method is fit on the remaining 4 folds. The mean squared error, MSE, is computed with the data in the held-out fold. The process resulted in 5 estimates of the test error and the 5-fold CV estimate is computed by averaging these errors (Equation (1)).
2.3.2. Random Forest
Random forest (RF) is a non-parametric machine learning algorithm that generates robust predictions by creating a set of regression trees from the bootstrap sampling of the original data and improving prediction accuracy by aggregating the results [
26]. RF has been shown to be resistant to problems of overfitting and noise, and it has been widely used for the supervised classification of land use and land cover [
27,
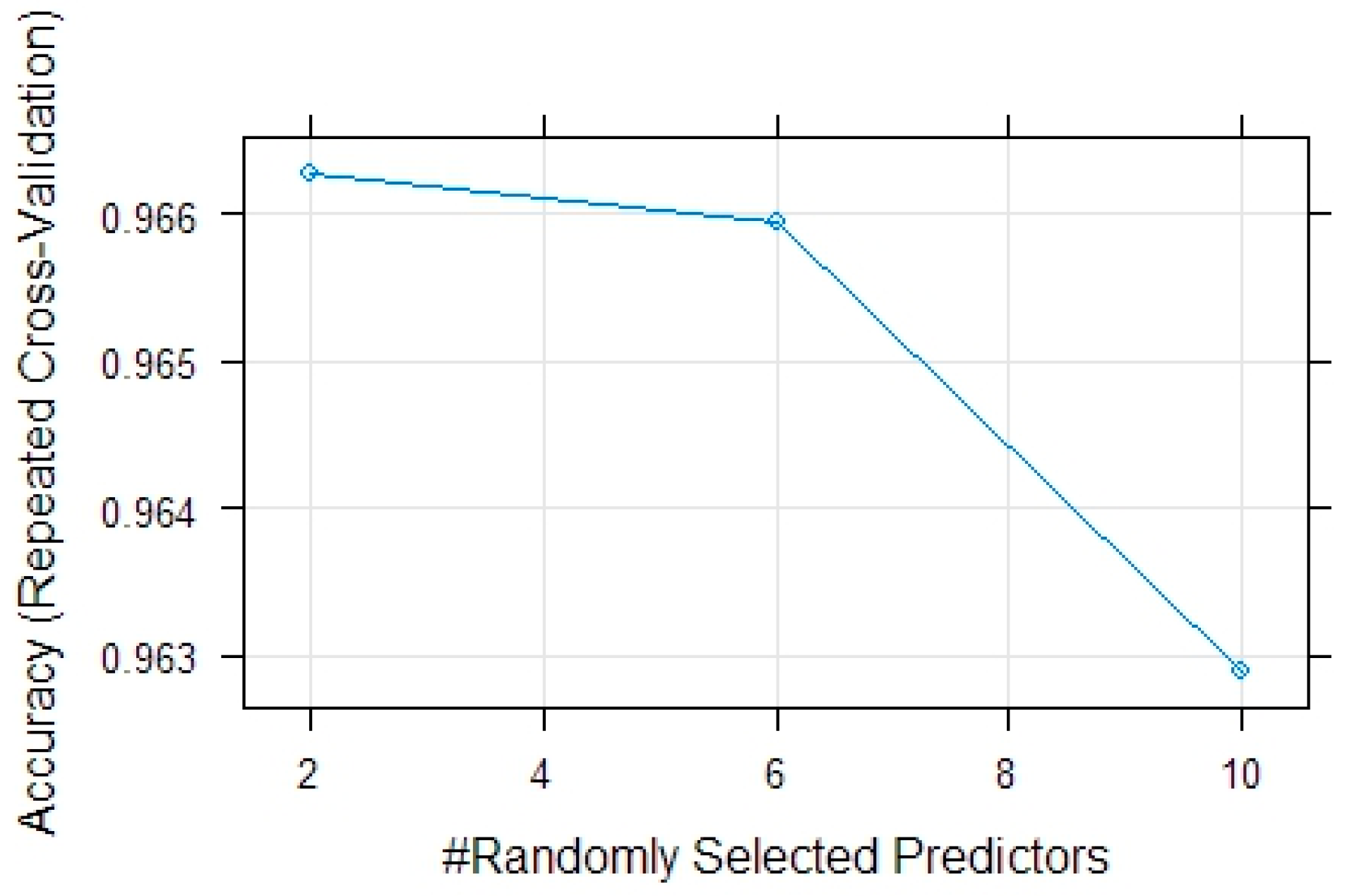
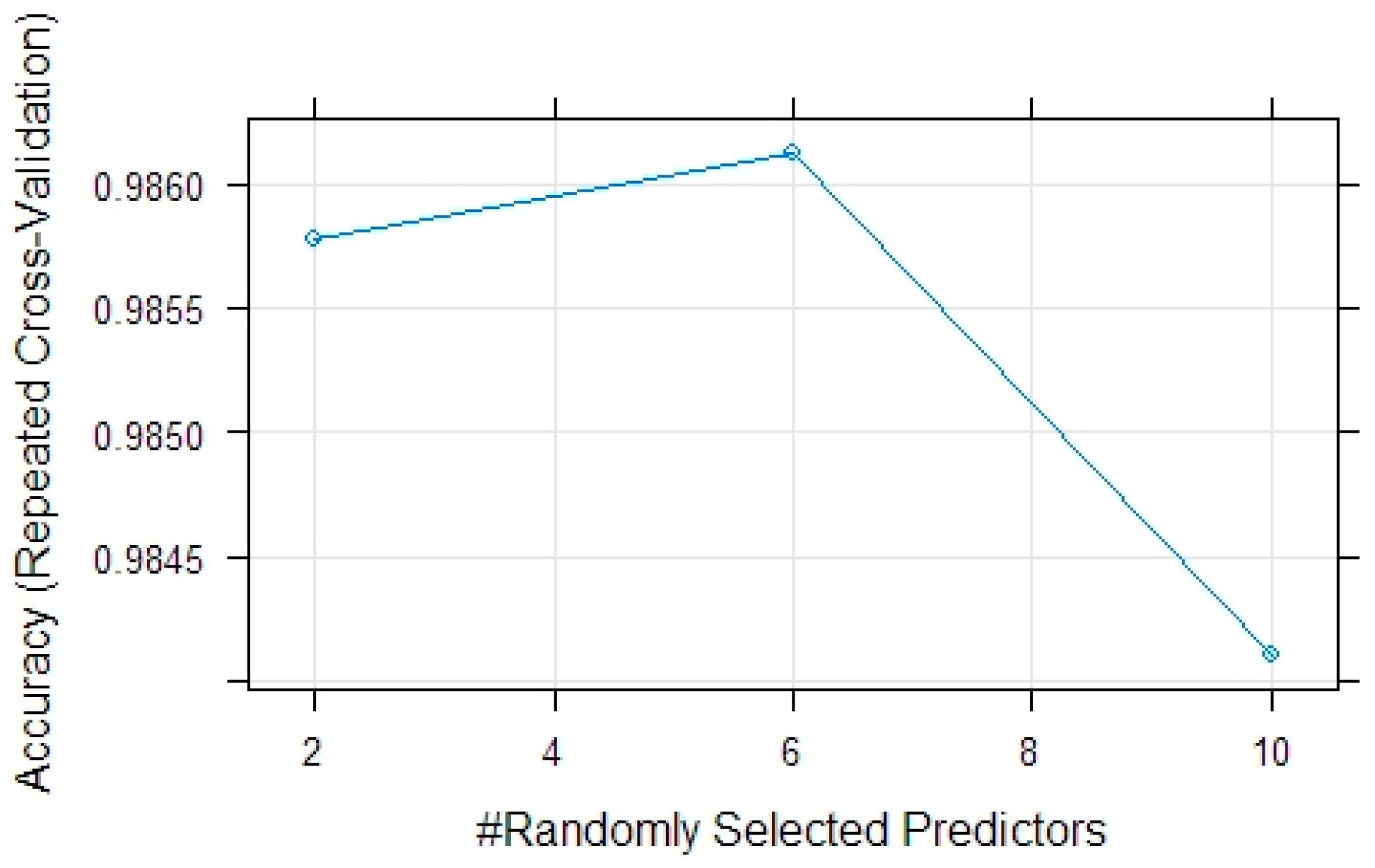
28]. In this study, we used RF to classify land use/land cover types of the study area in 2019 and 2022 using Sentinel-2A images. The sample was split with a proportion of 0.2, with 20% of the samples used as training data and the remaining 80% as test data. The tuning parameters were tested for the number of variables randomly sampled as candidates at each split (mtry: 2, 6, 10) and accuracy was used to select the optimal model. The final value used for the model of the 2022 image classification was mtry = 2 (
Figure A1), and for the model of the 2019 image classification, the value was mtry = 6 (
Figure A2). The “rf” method uses a default ntree of 500, which is a recommended value for remote sensing applications [
29].
Consistent with the ANN classification algorithm, the RF algorithm also applied 5-fold cross-validation with 5 repetitions.
2.4. Change Analysis
We first reclassified the land use/land cover maps in 2019 and 2022 by grouping the classes of irrigated agriculture, temporal agriculture, greenhouse, and burned area into the class of agriculture, and by grouping water and urban into the class other (
Table 2). The class burned area was grouped into the agriculture class because burning is part of the shifting cultivation and temporal agriculture field preparation practice [
30]. The reclassified land use/land cover maps had five classes, namely TDF, temperate forest, oak forest, agriculture, and other.
We performed the LULCC by overlaying and comparing the reclassified maps in 2019 and 2022. To analyze the dynamics of TDF, we focused on the following classes of changes and persistence: TDF persistence (35.1% of the study area), TDF loss to agriculture (1.7%), TDF gain from agriculture (1.1%), and other changes (62.1%). To remove the noise, we applied a filter of 2 ha since the average size of shifting cultivation was recorded as 2.5 ha and applied a 4-neighbor rule (QGIS sieve function) since it obtained better results.
2.5. Accuracy Assessment
Since classification errors often propagate to the result of change analysis, especially with post-classification comparison, it is important to evaluate the accuracy of the map of change in addition to the classifications. In a map of change detection, the classes of change usually occupy small proportions in comparison to the classes of persistence, and therefore, omission errors in the classes of change classes are often exaggerated due to the imbalance in area proportions and cause big uncertainty in the estimation of accuracy and areas. To counterbalance this effect, we implemented the method that was detailed in [
31]. We created a buffer area the size of 12 pixels around the classes of change, assuming changes are more prone to occur in the buffer areas, and assigned 75 points to the class of TDF persistence and 75 points to the class other persistence. Following stratified random sampling [
32], and assuming the standard error of the change map as 0.01, the user’s accuracy of TDF persistence 84%, TDF loss 60%, TDF gain 50%, and other 90%, and counting the 150 points from the buffer areas, the total number of random points needed for a statistically valid accuracy assessment was 1178 points. The points were distributed as follows: 331 points in TDF persistence, 300 points in TDF gain, 300 points in TDF loss, and 93 points in other persistence. The distribution of the verification points is shown in
Figure 3.
We exported those points to Google Earth and interpreted them visually to obtain the ground truth data. During visual interpretation, we considered an area of 100 m
2 around each point, which is equivalent to the pixel size of Sentinel-2A images. We compared the ground truth data with the map of LULCC and verified the obtained changes and persistence. We summarized the results of the accuracy assessment in an error matrix. We incorporated the area proportion of the mapped changes and calculated the overall accuracy, producer’s accuracy, and user’s accuracy with confidence intervals (CIs) and estimated the weighted areas of TDF loss and gain with their respective CIs. The accuracy assessment was carried out using Open Foris tools developed by the FAO (
https://github.com/openforis/accuracy-assessment/ (accessed on 15 December 2022)).
2.6. Examining the Spatial Variables Contributing to TDF Loss and Gain
We used the verified points of TDF change and persistence to analyze the effect of spatial variables on TDF dynamics (loss to and gain from shifting cultivation). We considered topographic variables, such as elevation, aspect, and slope, and anthropogenic variables, such as distance to roads and distance to agriculture and land tenure represented by ejido and communal lands or other land ownership (
Table 1). The spatial variables were resampled to 10 m spatial resolution to be consistent with the LULCC maps. We fitted two types of logistic regression models, one for TDF loss and the other for TDF gain. In these models, the dependent variables were change (1) and persistence (0), and the independent variables are the spatial variables (
Figure 4).
First, we fitted the models including all the spatial variables to detect the significant terms, and then we fitted additional models using only the significant terms. We used the Akaike information criterion (AIC) to select the best model (Equation (2)). AIC is calculated using the number of independent variables (K) and the log-likelihood estimate of the model (L). Using AIC as a criterion, the best model would explain the biggest amount of variation in the data using the smallest number of independent variables [
33]. We selected the best model that had the lowest AIC and was at least two units lower than the AICs of other competing models.
Before fitting the models, a Pearson correlation analysis was performed to avoid using strongly colinear variables in the models. A Pearson correlation coefficient of ≥0.8 was interpreted as an indicator of strongly collinear variables.
The TDF loss models had 94 verified random points for TDF loss and TDF persistence, respectively, with the explicative variables extracted to each of these 188 points. The TDF gain models had 46 verified random points for TDF gain and persistence, respectively, also with the variables extracted to each of those 92 points. Both TDF loss and TDF gain points were a subset of the verification dataset for the change analysis.
2.7. Projecting Future TDF Loss and Gain
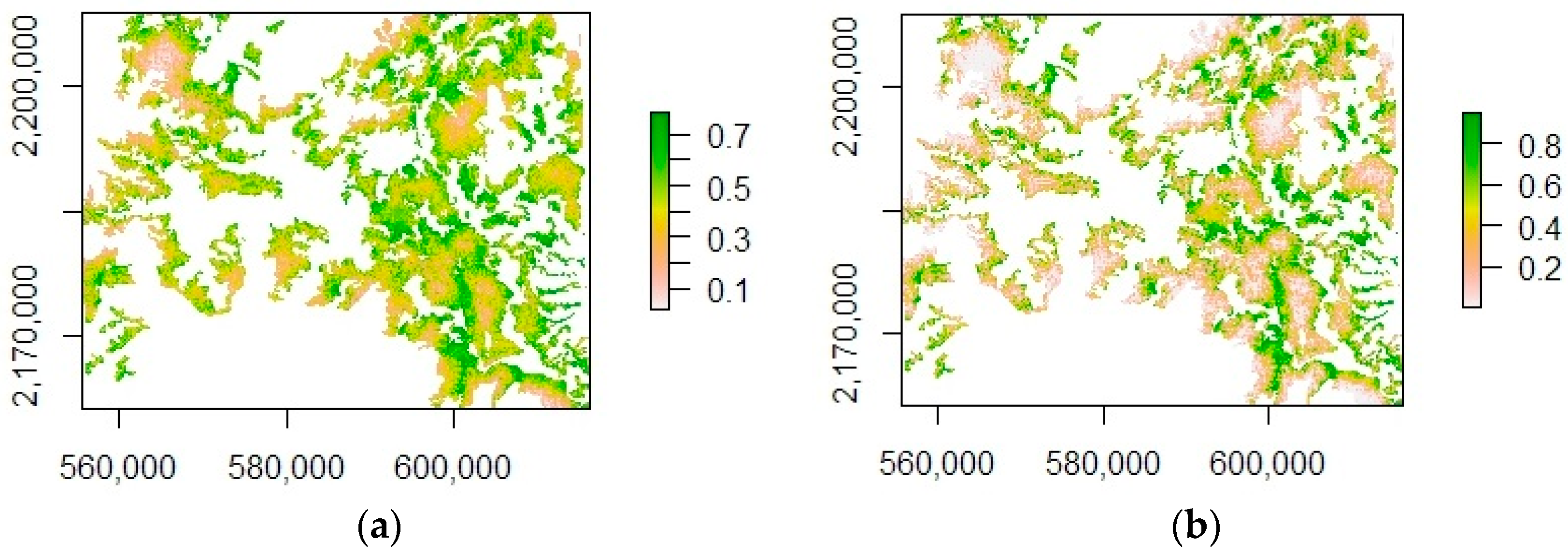
We predicted the probability of the occurrence of TDF loss and TDF gain using the best models. We reclassified the probability maps using a threshold of 0.5 and calculated the map areas with a probability higher than 0.5 as predicted areas of TDF loss or TDF gain.
2.8. Comparison of Forest Loss and Gain
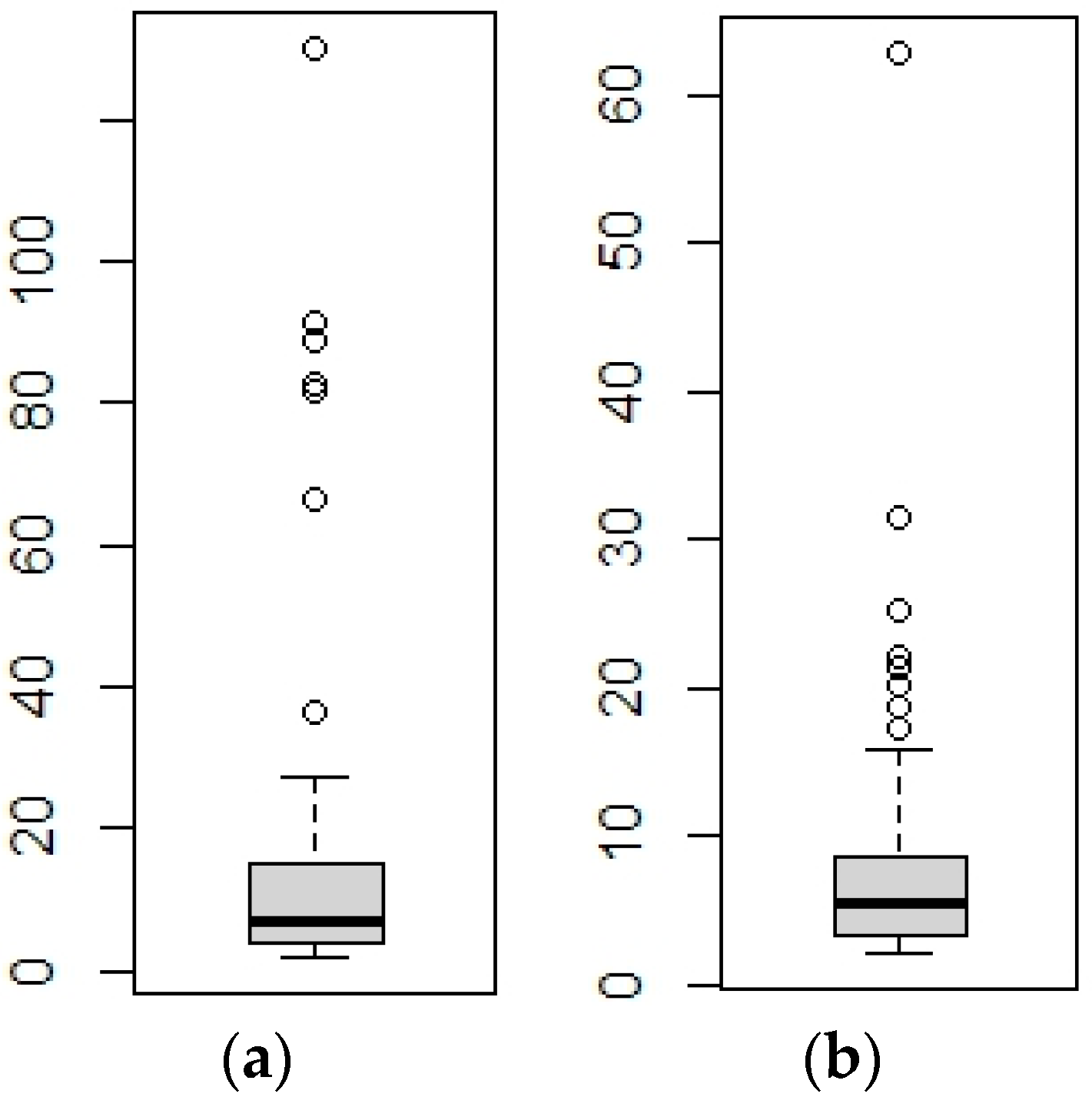
We compared the TDF loss and TDF gain by computing the statistics of their patch size and distribution. We assumed that smaller areas of forest loss might be related to areas under a shifting cultivation scheme (around 2.5 ha), contrary to larger areas of forest loss, which might be related to large-scale agricultural management. Thus, we expected a smaller area in TDF gain in comparison to TDF loss. We used a non-parametric Mann–Whitney test to test the difference between the median values of the areas of the TDF loss and TDF gain [
34].
4. Discussion
4.1. TDF Dynamics
During 2019–2022, in our study area, the average TDF loss and TDF gain were estimated at 6235 ha and 2784 ha, respectively, and the average rate of TDF loss and TDF gain was estimated at 1.6% and 0.7% per year, respectively. The rate of TDF loss was higher than the national level TDF loss estimated at 0.4% per year by [
10], but it was comparable with the annual TDF loss rate of 1.4% at the regional level estimated by [
12]. As for TDF gain, we did not find studies at the national or regional level to compare with. Both the areas and the rate of TDF loss were much higher than TDF gain. Nonetheless, the confidence intervals of the estimated areas of both classes overlapped; thus, we cannot be sure that there is a significant difference between both estimates. According to our results, TDF gain and loss are in equilibrium in the region. However, due to the relatively large confidence intervals for both area estimates, we recommend taking this conclusion with precaution.
Having smaller patch sizes, areas of TDF gain can be more readily related to TDF regrowth during the fallow period of shifting cultivation. On the other hand, large patches of TDF loss (around or more than 80 ha) are more readily related to large-scale plantations, which might not be under a shifting cultivation scheme. According to our results, the area of TDF loss and gain were not significantly different. Therefore, although large-scale plantations are more common in the study site, most of the TDF loss areas seem to be related to small-scale areas, probably under shifting cultivation or other management that could further imply a TDF recovery.
Processes such as shifting cultivation do not affect net vegetation distribution; however, they can result in an overall decrease in vegetation density and cause carbon release into the atmosphere and affect the carbon budget [
20]. For TDF regeneration, assisted natural regeneration—a practice to convert degraded forests into more productive forests with improved ecosystem services by managing regeneration rather than relying on pure natural processes—is recommended [
35,
36]. Although this study consists of an evaluation of TDF gain and loss in terms of area, a more detailed analysis should be made to obtain the carbon balance in the study area.
As for the contributing factors, for TDF loss, both slope and distance to roads were significant predictive variables, with slope having a higher coefficient. Both variables had negative coefficients, showing that with the increase in either slope or distance to roads, the probability of TDF being converted to agriculture decreases. For TDF gain, the same variables were significant and with negative coefficients, showing that with the increase in slope and distance to roads, the probability of TDF recovery decreases. Interestingly, in both models, slope had a higher coefficient and therefore is a more important factor to determine the probability of both TDF loss and gain. In the case of TDF loss, this pattern is probably related to the fact that frequently areas with higher slopes and farther away from established roads are not preferred to establish agricultural or livestock activities, due to the costs and difficulties associated with the transportation of products and animals to those areas. In the case of TDF gain, its dependence on TDF loss (i.e., for an area to gain TDF, first it must lose it) causes the same relation with those two variables.
4.2. Methodological Challenges and Insights
The wide range in area estimation of TDF loss and TDF gain partly comes from the fact that these two change classes occupied a small proportion of the area in comparison to classes of persistence, and therefore, (small) a number of omission errors were exaggerated due to the imbalance in area proportions. We intended to counteract this imbalance in area proportion by creating buffer zones of 12 pixels of Sentinel-2A images (120 m) around the change areas, assuming that omission errors are prone to occur near detected changes [
31]. However, we did not succeed in reducing the confidence intervals. One possible reason could be that the buffer size is not wide enough to cover the points of omission errors. For future work, we will consider using different buffer sizes to find out how buffer size affects the reduction in omission errors.
The maps of predicted forest loss and gain created using our models show that forest loss and gain follow a similar spatial distribution because of their dependence on the same explicative variables: slope and distance to roads. These maps were created using a limited number of factors including slope, elevation, and distance to roads; thus, other plausible factors that might explain forest loss and gain were omitted. For example, factors related to the presence of large-scale agriculture companies or certain governmental incentives. Nonetheless, our maps can give a general idea of which areas are prone to being under shifting cultivation management.
We analyzed TDF dynamics for a rather short time window (2019–2022). Although we could capture the TDF gain and loss from shifting cultivation, an analysis with a longer time span, e.g., 10–30 years, could potentially allow us to have a more precise area estimation of TDF gain and loss (with a smaller confidence interval).
For TDF dynamics, time series analysis of climate data (air temperature, precipitation) is useful to exempt false changes introduced by climate variations.
Table 10 shows the annual average temperature and annual precipitation for our study area. The precipitation data were derived from CHIRPS “Climate Hazards Group InfraRed Precipitation with Station Data” and the temperature data are from MODIS “Land surface temperature”. The annual temperature was rather stable for the period of 2018–2022, while the annual precipitation showed some variation, with much higher precipitation in 2022 than in 2019 (
Table 10), which could explain why the vegetation in the 2022 image was greener even in a dry season. Since we used a two-time classification comparison to analyze TDF dynamics, and we provided independent training samples for the classification at each time point, the effect of the interannual climate variations on the vegetation cover was well captured with the image classification. Since we verified the changes using visual interpretation with reference to very high spatial resolution images from Google Earth, the climate-induced effects were largely removed from contributing factor analysis of TDF dynamics.
5. Conclusions
We used multi-temporal Sentinel-2A images and topographic, anthropogenic and land tenure factors to investigate the dynamics of tropical dry forest in terms of gain and loss and the associated factors. We estimated a TDF loss rate of 1.6% per year and a TDF gain rate of 0.7% per year. Although apparently TDF loss rate was higher than TDF gain, because of the large confidence interval in our area estimate, we cannot conclude that TDF loss was more intense but rather that the TDF loss was in equilibrium with TDF gain. In future analysis, we will assess other methods that can help reduce the confidence intervals in area estimates to obtain a clearer conclusion regarding TDF loss and gain.
As for the contributing factors, both TDF loss and gain were inversely related to slope and distance to roads; therefore, these two factors explain the probability of a TDF area in both gain and loss. In the case of TDF loss, this is related to the fact that agricultural or livestock activities generally prefer flat areas for easy access and cheap cost; for TDF gain, since it depends on TDF loss, the same relation with slope could explain the distribution of TDF gain.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











