1. Introduction
The field of remote sensing has seen rapid development in the last few decades, with applications in areas, such as environmental resources, hydrology, and geology. Object recognition, which involves mapping visual features to object classes, is a crucial problem in remote sensing image analysis and has diverse civil applications, such as geographic information system (GIS) mapping, transportation planning, and navigation [
1,
2,
3,
4,
5,
6,
7]. With the release of more remote sensing datasets and the increasing spatial and spectral resolutions, identifying fine-grained object classes, such as the detailed models of airplanes has now become possible. Fine-grained object recognition in computer vision requires the identification of the subtle differences in the local regions of an object. The current methods of fine-grained object recognition include deep convolutional neural network (DCNN)-based methods, localization/recognition-based methods, network integration based methods, and higher-order feature-coding-based methods. The part-based R-CNNs [
8] are a representative approach that use a region-based convolutional neural network (R-CNN) to detect objects and their discriminative parts. Meanwhile, attention mechanisms have been applied to learn models without bounding box labels [
9,
10,
11]. The network-integration-based methods learn multiple models and then integrate the predictions [
12,
13,
14]. High-level feature encoding combines feature maps using outer products [
15,
16,
17], with the bilinear model being the most representative. It is, however, unclear how these methods perform with remote sensing objects, but some studies have attempted to apply them. For example, Sumbul et al. [
18] introduced multiple sources of data to address the low inter-class variance, small training set size for rare classes, and large class imbalance, while Aygünes et al. [
19,
20] used weakly supervised location-based recognition for fine-grained tree recognition.
The fine-grained object recognition task, which involves identifying the types of objects among a large number of closely related subcategories, differs from the traditional object identification tasks commonly studied in the remote sensing literature in at least two ways:
The difficulty of accumulating a large number of similar subcategory samples can greatly limit the size of the training set for certain subcategories;
The class imbalance can lead the traditional supervised formulations to prefer fitting to classes that occur frequently, while ignoring classes with a limited sample size.
In the data-driven models, these differences can create recognition difficulties, especially when there are limited labeled data, which is known as the few-shot learning (FSL) problem. This is a significant issue in the fine-grained object recognition task. The current FSL methods adapt models learned from auxiliary datasets with large amounts of data to new data with limited labeled data. During training, the concept of a “task” is introduced, where a small set of class-balanced samples are iteratively sampled from the auxiliary dataset, and the model learns the task distribution. New data with limited annotation can be considered a few-shot task and adapted using the task distribution learned from the auxiliary dataset.
Most of the current FSL methods can be divided into three main categories: (1) generation-based methods; (2) initialization-based methods; and (3) metric-based learning methods. The generation-based methods aim to learn a generator that can augment the data for new classes [
21,
22,
23], while the initialization-based approaches [
24] focus on learning a good initialization for the model parameters. The metric-based methods involve measuring the distance between a query set and a support set in the embedding space to determine the predicted categories [
25,
26]. For the FSL problem of remote sensing object recognition, there is not much current research. However, Fu et al. [
27] did introduce an initialization-based few-shot approach to synthetic aperture radar (SAR) object recognition, while noting that the few-shot classification of remote sensing objects is more difficult than that of natural images. Some works have improved the effect of FSL on SAR data by modifying the network and metric functions [
28,
29]. There have also been some studies that have focused on addressing the few-shot transfer learning problem in SAR data [
30,
31].
However, the above FSL methods are not able to deal with remote sensing objects very effectively. The diverse sources of remote sensing data make the learned distribution inaccurate, and the complex background of remote sensing objects, the high image noise, and the small size of the objects make the features more difficult to detect with the model, which leads to a reduction of the FSL effect.
The current few-shot methods rely on a meta-learning training paradigm, i.e., learning the task distributions by learning them on sampled tasks. Factors, such as the source of the data and the way the samples are composed in the task, affect the task distribution, while the latter can be considered to be determined by the sampling strategy. Naturally, in order to make the learned task distribution closer to the real task distribution, we start from the perspective of improving the effectiveness of the sampling strategy. We therefore propose an improved sampling strategy for FSL tasks:
We improve the sampling strategy for the fine-grained object recognition task. The task sampling strategy is improved so that each sampled task contains only subcategory samples belonging to the same broad category, e.g., fine-grained airplane samples belonging to the airplane category. This sampling strategy is used to keep each task-specific model focused on mining fine-grained features and solving the problem of the difficult extraction of remote sensing object features.
The category synthesis method keeps the sampling task length consistent. For each task sampling operation, for the case where the number of fine-grained categories is less than the number of sampling operations, a category synthesis method is proposed to fill the gaps, to maintain the same task length for each sampling operation, and to ensure that an accurate task distribution is learned instead of a mixed distribution.
3. Methodology
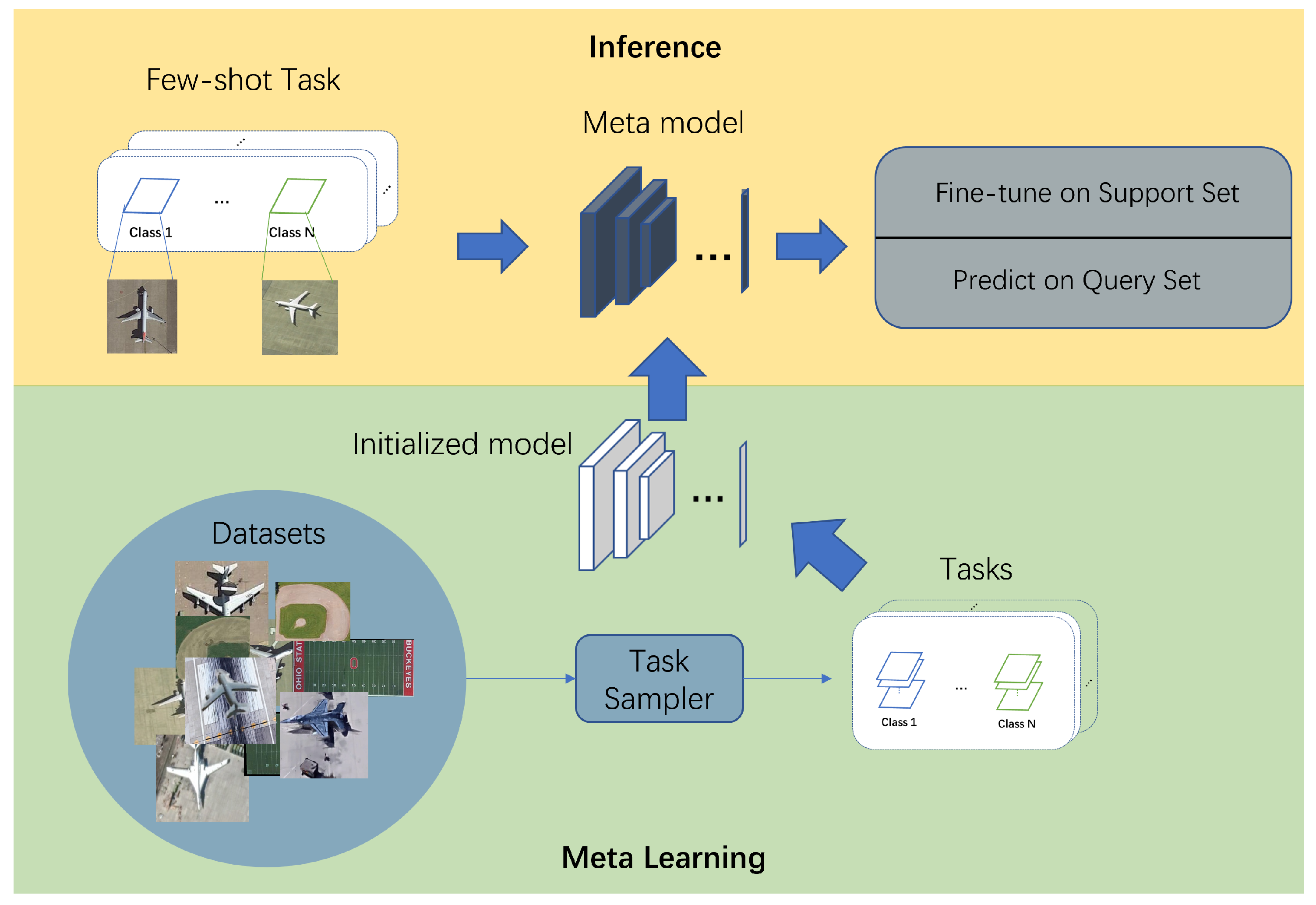
The overall system for fine-grained object recognition in remote sensing applications is illustrated in
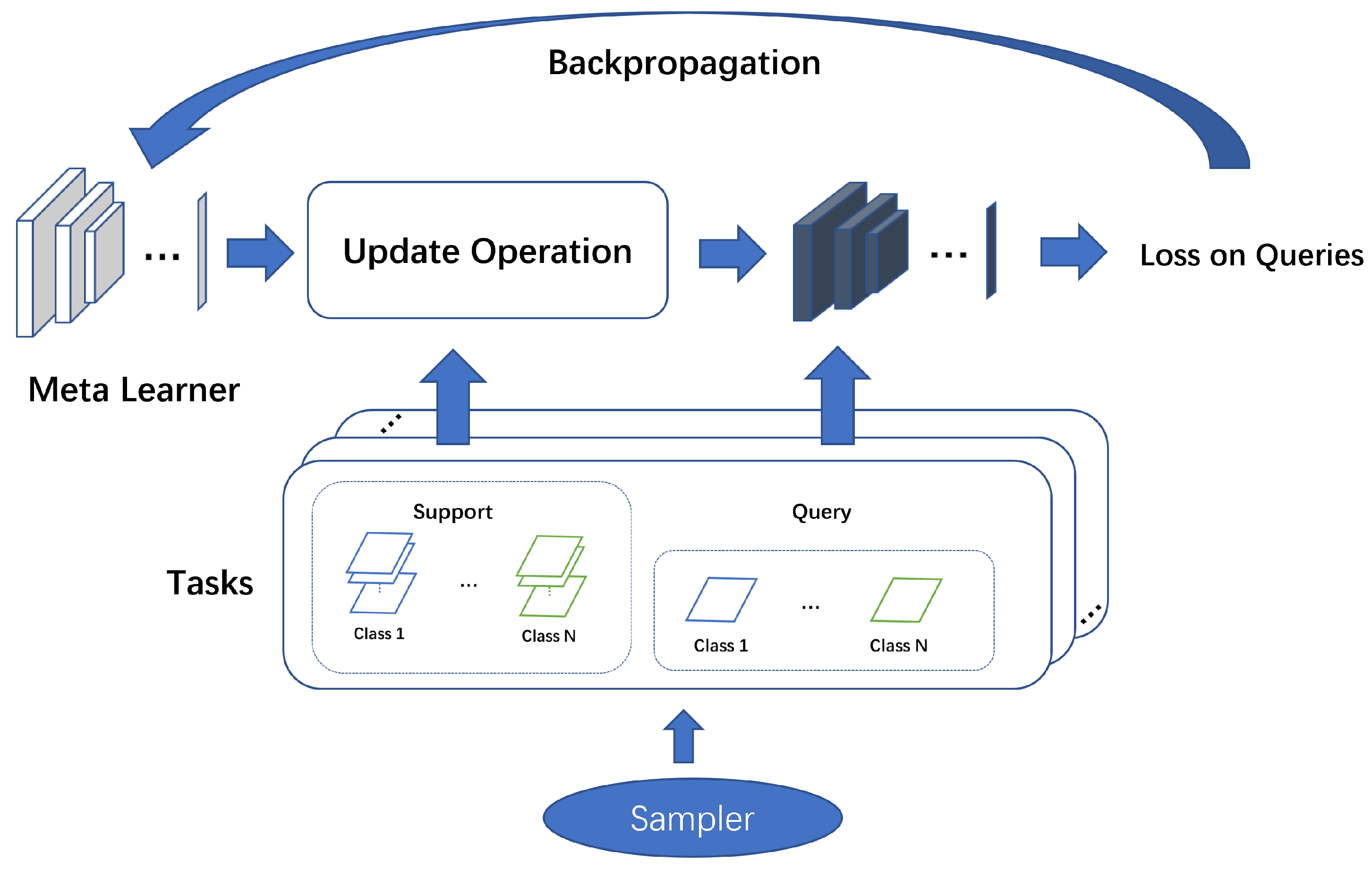
Figure 2, showing the input and output schematic. In the meta-learning step, the initialized model is transformed into a meta-model by learning on the auxiliary dataset through the tasks generated by the task sampler. The specific learning process is described in
Figure 1. In the inference phase, we sample the few-shot task, fine-tune the meta-model on the support set, and finally output the prediction results for the query set.
3.1. Problem Formulation
3.1.1. Fine-Grained Problem
In
Section 2.1, we discussed the task sampling paradigm for FSL training. However, this sampling strategy does not have a way to solve the problem of the difficult extraction of fine-grained remote sensing object features because the sampled tasks are not focused on mining fine-grained features, and in each task sampling operation, the sampled categories are:
We explicitly define each category to belong to some broad category and have . It is seen that does not always hold, and under extreme conditions there are even for any , which means that the task is concerned with distinguishing differences between rather than fine-grained and .
Further, such a sampling approach has a bias for some
, since
for each sampled category
from
, and the bias on
depends on the molecular
.
Although the original intention of using this sampling paradigm is for the categories to be balanced in each task, each task will still have a bias toward certain broad categories, which is detrimental to the model learning of a generic large few-shot model.
3.1.2. Validity Issues of Task Distribution Learning
In
Section 2.1 and
Section 2.2, we showed that the purpose of the model optimization is to eventually learn a task distribution. For the remote sensing recognition task, due to the diverse sample sources, the number of certain categories may not reach the required number of samples during the task sampling process, resulting in such a task being considered as coming from a different task distribution, and thus the learned distribution is a mixed distribution, which brings inaccuracy to the model learning.
3.2. Improved Task Sampler
In order to solve the problem of the difficult extraction of fine-grained features in the few samples of remote sensing imagery, we improve the task sampling strategy to make each task change from a few-shot task to a fine-grained few-shot task and let the model learn fine-grained few-shot features. Specifically, the sample categories in the unimproved task are from different broad categories, and such a task is called a recognition task. However, such a task cannot focus on fine-grained features because the two samples are from different broad categories which differ significantly, such as aircraft and ships(as discussed in
Section 3.1.1).
We improve the sampling strategy by including in each task only samples sampled from a particular large class so that the model will focus on the intra-class differences within the classes in the task, i.e., the fine-grained features. Such improved tasks, which we call fine-grained tasks, end up with a fine-grained task distribution that the model learns. It is worth noting that introducing additional broad category information does not require additional annotation of the original dataset. In fact, for remote sensing data, although there are many fine-grained categories, the broad categories these fine-grained categories belong to are indeed very limited. We do not need additional annotation on the data. We only need to add appropriate judgments in the programming.
At the same time, a category generation technique is designed for the situation of this sampling strategy having an insufficient number of categories to be sampled. We use the idea of mix-up for category generation by sampling the beta distribution to obtain a factor
, where, for any two category samples
i,
j considered to generate a new category, this new category sample is obtained by pixel-level fusion as
. Specifically, lambda belongs to the distribution:
We set the to a random variable instead of a static parameter value in order to avoid duplication of the resulting new category. For example, if there are only two categories and five categories are sampled, if lambda is a constant parameter, then the new categories generated are bound to be duplicated, so there is no guarantee that the length of the picked task is five. We chose the beta distribution because the distribution is symmetric about 0.5 when the two parameters of the beta distribution agree, and the range of the random variables is 0 to 1. Such a distribution is suitable for fusing pairs of samples.
3.3. Framework
The improvement methods discussed previously are integrated into a unified process. The overall flow is shown in Algorithm 1.
| Algorithm 1 Fine-Grained Task Sampling Process |
| Input: |
| The auxiliary dataset ; |
| Collection of categories in the auxiliary dataset ; |
| Collection of broad categories in the auxiliary dataset ; |
| Number of categories in a task N; |
| Number of samples per category in a task ,. |
| Output: |
| Tasks sampled from auxiliary datasets . |
| for iteration i = 1,2,3… do |
| Sample a broad category from , denoted as |
| Calculate , |
| for j=1,2,3,.. do |
| Sample two category where and |
| Sample samples belonging to from , denoted as |
| Sample samples belonging to from , denoted as |
| Sample from Beta Distribution |
| For each image in fused as , denoted as |
| For each image in fused as , denoted as |
| Define |
| end for |
| for do |
| Sample samples belonging to from , denoted as |
| Sample samples belonging to from , denoted as |
| Define |
| end for |
| Define , |
| end for |
| return |
We consider the fusion sample
a brand new category sample. Since
is a random variable, each fusion sample category is considered as different. As can be seen from the algorithm flow, the category sampled by each task belongs to the broad category
. Therefore, each task focuses on the small differences in the fine-grained categories of broad category
, forcing the model to mine fine-grained features. This sampling strategy, which further specifies the tasks as fine-grained few-shot tasks, provides an artificial prior to improve the mining ability for fine-grained features.
Figure 3 briefly illustrates the difference between a task sampled by the proposed approach and a task sampled by the general policy.
6. Conclusions
The remote sensing fine-grained object recognition task has a few-shot problem that is difficult to get around, i.e., the lack of fine-grained object data. Although some few-shot methods have been proposed to address learning from a small number of data samples, these methods have not been adapted to remote sensing objects, where the object context is complex and fine-grained features are difficult to extract. In this study, we first investigated the FSL methods and found that only a small amount of work has been conducted in the field of remote sensing. This inspired us to design a few-shot approach for remote sensing tasks. In this paper, we reviewed the general paradigm of training FSL methods on sampled tasks. We then affirmed the paradigm’s usefulness for FSL, but pointed out its shortcomings for remote sensing data. The problem is that the task has a preference for certain broad categories, the task may not be fine-grained, and the model has difficulty extracting the already hard-to-extract fine-grained features of remote sensing imagery, which can adversely affect the model learning. To solve this problem, we proposed an improved task sampling strategy: the fine-grained task sampling strategy. The fine-grained task sampling strategy ensures that the samples in each sampled task come from a certain broad category, which ensures that the model focuses on the small differences in the fine-grained features on that task. This reinforces the model to learn fine-grained features. We tested the effectiveness of this sampling strategy on the FAIR1M and MTARSI datasets. We found that the FSL method can achieve a large accuracy improvement using the improved sampling strategy. In addition, from the performance effect on the two datasets, we pointed out that the performance of FSL depends on the learning effect on the auxiliary datasets. In our future work, we will attempt to further improve the existing network structure to make it more suitable for remote sensing tasks. We will also bring the few-shot approach to other tasks in remote sensing, such as remote sensing object detection.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}