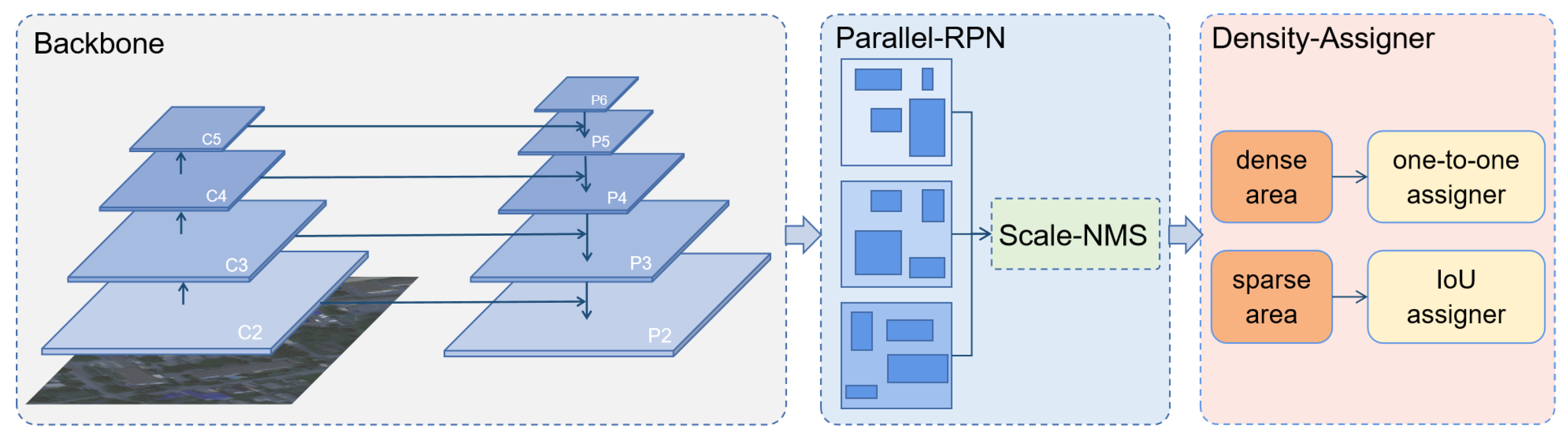
3.2. Parallel RPN
A parallel RPN structure is designed to make use of convolutional kernels with different receptive fields:
,
, and
. Though we can obtain feature maps with different scales in FPN, the raw anchors generated with manually set scales and ratios have some limitations. For example, if the original image is
pixels, when using
convolutional kernels to obtain
and
feature maps, we can obtain theoretical receptive fields close to
and
, respectively. Otherwise, if we use
and
convolutional kernels in
feature maps, the theoretical receptive fields are close to
and
. As a result, convolutional kernels with different sizes can make up for the noncontinuity of receptive fields and improve the quality of proposals. The architecture of Parallel RPN is shown in
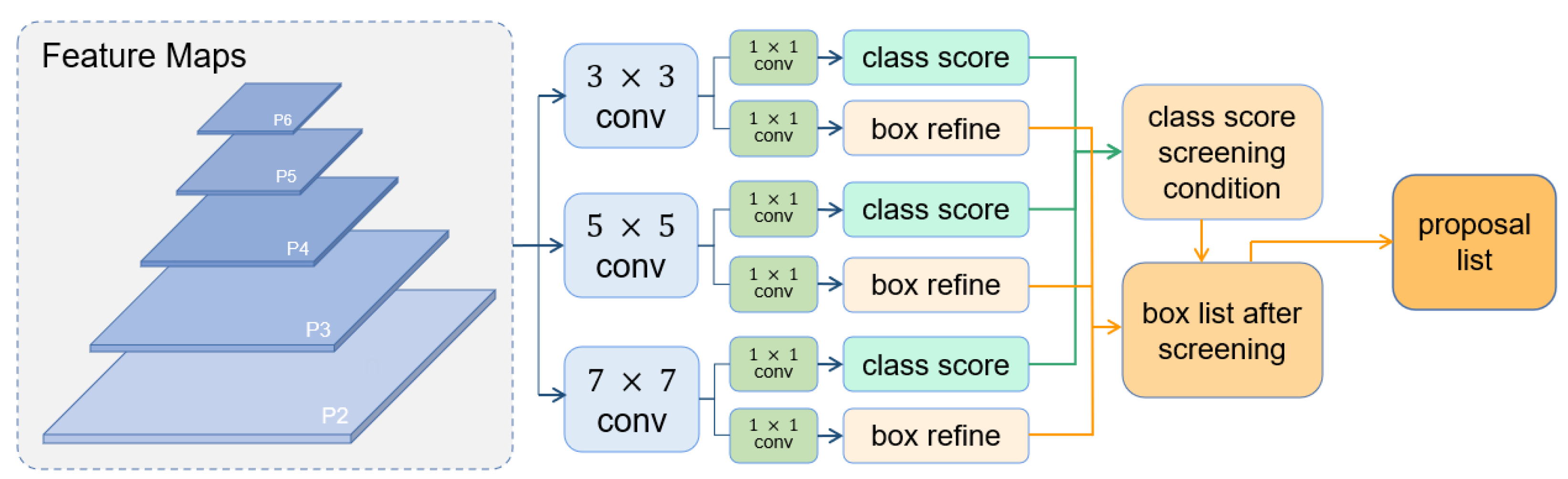
Figure 2.
Given that the feature map sizes of different FPN layers vary by multiple, the deduced receptive field of different layers changes discretely, leading to the large gap between the receptive field size between adjacent FPN layers. However, the vehicle size approximates a continuous change in the aerial imagery; therefore, the discretely changed receptive field is not fine enough to handle the vehicle size variance. As a result, the choice of proposals from different convolutional kernels should also be adjusted dynamically according to the specific situation. In the traditional structure of RPN, proposals are generated together with classification scores (confidence). However, once the final proposals are chosen by their rankings, the scores will never be used again.
In our design, the exact scores are used to screen proposals from different convolutional kernels. The detailed equation and explanation of the architecture are given as follows.
where
means the number of proposals selected from the
convolutional layer,
means the average score of generated proposals from the
convolutional layer, and
N is the final number of proposals selected to construct the proposal list.
The proposed Parallel RPN consists of three parallel convolutional layers with kernel sizes of , , and . After convolution, we can obtain three groups of foreground classification scores and corresponding box refinements. Then, to screen out proper anchor boxes, we take the average classification score of each group as allocation criteria. The ratio of average scores among the three is that of proposals screened for the three groups. To avoid any branch being out of action, a minimum number of 0.2N for each branch is set to ensure that the proposals are screened from all three branches.
3.3. Density-Assigner
In terms of vehicle objects in aerial images, they are generally of small size. On the other hand, a considerable number of vehicles are densely arranged, such as being distributed along the road and gathering in parking lots. For vehicle detection datasets with horizontal annotations, this can cause many overlapping bounding boxes in areas of dense distribution. Meanwhile, NMS is a strategy to eliminate superfluous anchor boxes generated from RPN. To those vehicle objects that not only have tiny sizes but also distribute densely, proposals outputs from the RPN stage are also tiny and dense. In this case, it is very hard for NMS to judge which predicted box accurately locates the vehicle. In dense areas, proposals generated may be insufficient, which means that some foregrounds are not covered by RPN’s proposals. At the same time, some proposals may contain more than one object and have high classification scores. Using a strict NMS strategy in this situation is not optimal, since it can cause a lack of appropriate proposals.
Thus, we designed a scale-based NMS strategy. The NMS threshold is selected according to the FPN layer where proposals come from. Proposals from the deeper FPN layer will pass through a more strict NMS. As a result, more proposals of small sizes in dense areas from large feature maps are kept for use in the following R-CNN stage.
After distinguishing those proposals from their FPN output layers, different NMS thresholds are applied according to the layers, respectively. Generally, the deeper the FPN layer is, the larger the average size of proposals generated. To set the NMS threshold by increasing the deepening of FPN layers, we are able to keep more proposals for dense and small sizes.
Generally, vehicles are most commonly seen along roads, in parking lots, or in individual residential areas. Due to a large number of vehicles, they often cause severe traffic jams or crowded parking lots. Therefore, the distribution of vehicle objects tends to be dense in a certain area. Considering that most vehicle detection datasets adopt horizontal bounding boxes as their labeling mode, an overlapping box in dense traffic regions is a nonnegligible issue. The overlapping boxes of vehicles are shown in
Figure 3. To improve the detection performance on these densely arranged objects, we propose to take the prior information into consideration to assist network learning. In other words, we propose to use the vehicles’ density information to assist the label assignment and design a Density-assigner, as shown in
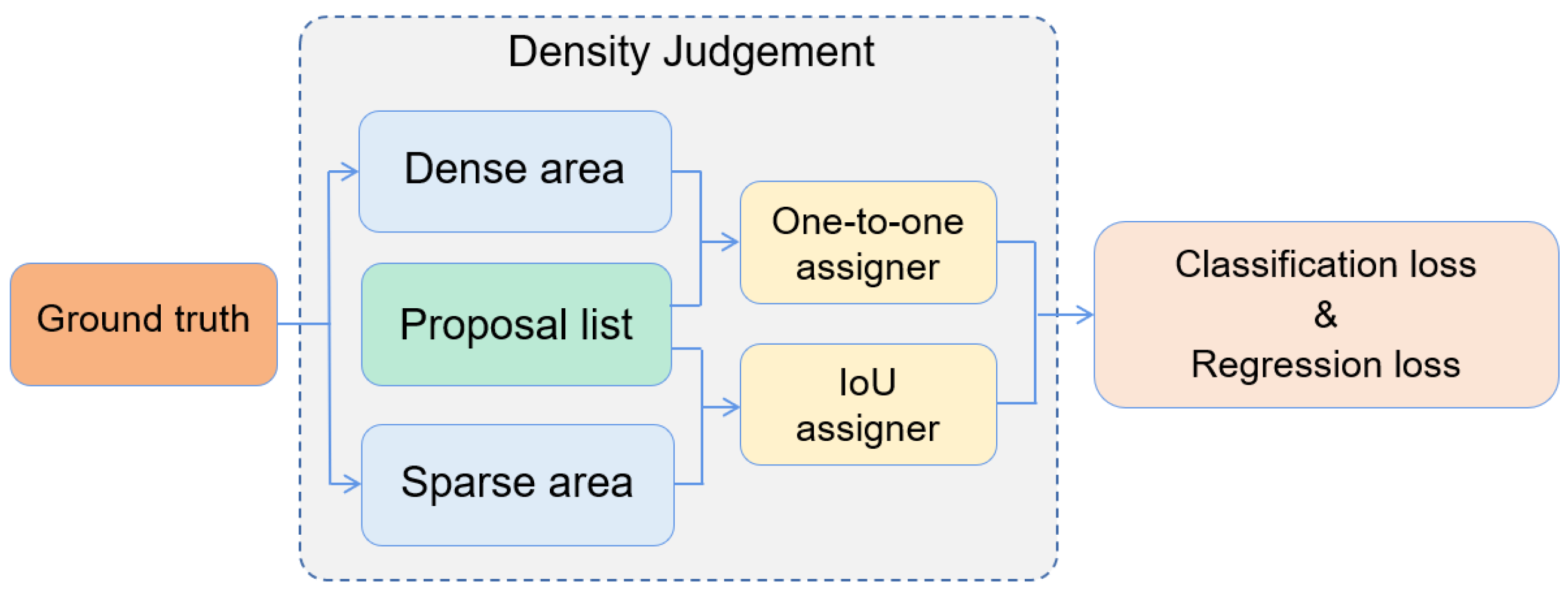
Figure 4.
For a vehicle that parks in the open countryside, proposals overlapping within a proper IoU threshold around it can all be used as a positive guide to supervising the bounding box regression training process. However, when the vehicle ground truths are dense in a region, not all proposals around the vehicle object with corresponding IoU are suitable for the bounding box regression training process. Those proposals between two ground truths are more likely to be assigned as positive samples to both two ground truths. Under this circumstance, the selected positive samples are of poor quality, and they may cause confusion in the bounding box regression training process. The visualization of easily-confused proposals is shown in
Figure 5.
Inspired by the ideology of one-to-one detection in the transformer-based method DETR [
35], we proposed a density-based assigner. This assigner will first judge whether the ground truths are in a dense area, and then conduct a one-to-one positive sample assignment. Since many proposals in dense areas were obtained, it is necessary to assign positive samples in a more strict way, eliminating redundant false predictions that cannot be deleted by NMS. The function of RPN is to give rough proposals for all the foreground objects, while that of R-CNN predicts the finally precise classes and locations. For those objects in dense areas, more proposals from RPN are reserved. As a result, any ground truth in these areas will be assigned to only a single proposal that has accordingly maximum IoU in the R-CNN stage.
Now that we choose the one-to-one assigning strategy in vehicle-dense areas, the definition of dense area is also a critical point worth studying. Firstly, and intuitively, any vehicle object ground truth which has IoU with another vehicle object ground truth belongs to the dense area, obviously. However, if vehicles lie orderly along a road or in a parking lot by coincidence, the ground truths of these vehicle objects may have no overlaps. Under this circumstance, to group the ground truths of vehicle objects together with dense vehicle objects, we design a new formula to measure whether a vehicle object belongs to objects in a dense area, as is shown in the following equations.
where
represents the width of ground truth bounding box A, and
represents the width of ground truth bounding box B. Similarly,
represents the height of ground truth bounding box A, and
represents the height of ground truth bounding box B. In this equation,
is used to measure the difference of bounding box outlines. If the outlines of two bounding boxes are obviously different, they will be less likely to cause confusion in label assignments. In this situation, the low value of IoU is able to eliminate samples of poor quality.
where
represents the center point’s x-coordinate of ground truth bounding box A, and
represents the center point’s x-coordinate of ground truth bounding box B. Similarly,
represents the center point’s y-coordinate of ground truth bounding box A, and
represents the center point’s y-coordinate of ground truth bounding box B.
here measures the adjacent level of two ground truth center points. The closer they are to each other, the more likely it is that they will cause confusion in label assignments.
where
C is a constant that is closely related to the dataset to constrain the range. With the help of hyperparameter
C, we can control the sensitivity, which makes it more convenient to distinguish the dense area and the sparse area. In this equation, the final value is mapped to the range of 0 to 1 by exponential form. In our definition, the value
can measure the dense level of every two ground truth bounding boxes. If the value
of two ground truth bounding boxes exceeds the density threshold, these two ground truth bounding boxes are judged to be in the dense area.
Placing the Density-assigner together with Scale-NMS, they form a structure that first releases and then contracts. Only when Scale-NMS provides a sufficient quantity of proposals can the Density-assigner then carry out the one-to-one assignment in a dense area. The Density-assigner makes sure that every ground truth is assigned to the optimal positive sample as far as possible and eliminates the phenomenon of missing assignment.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}