1. Introduction
Accurate 3D object detection is a crucial task in the fields of autonomous driving and robotics, where multiple sensors are utilized to capture comprehensive spatial information. Self-driving vehicles, for instance, commonly incorporate various sensors such as the IMU, radar, LiDAR, and camera. Among these sensors, LiDAR sensors possess a distinct advantage in obtaining precise depth and shape information, resulting in previous methods relying solely on point clouds achieving competitive performance. Additionally, some recent methods have substantially improved by incorporating a two-stage refinement module. These findings have inspired researchers to explore more effective LiDAR-based two-stage detectors further.
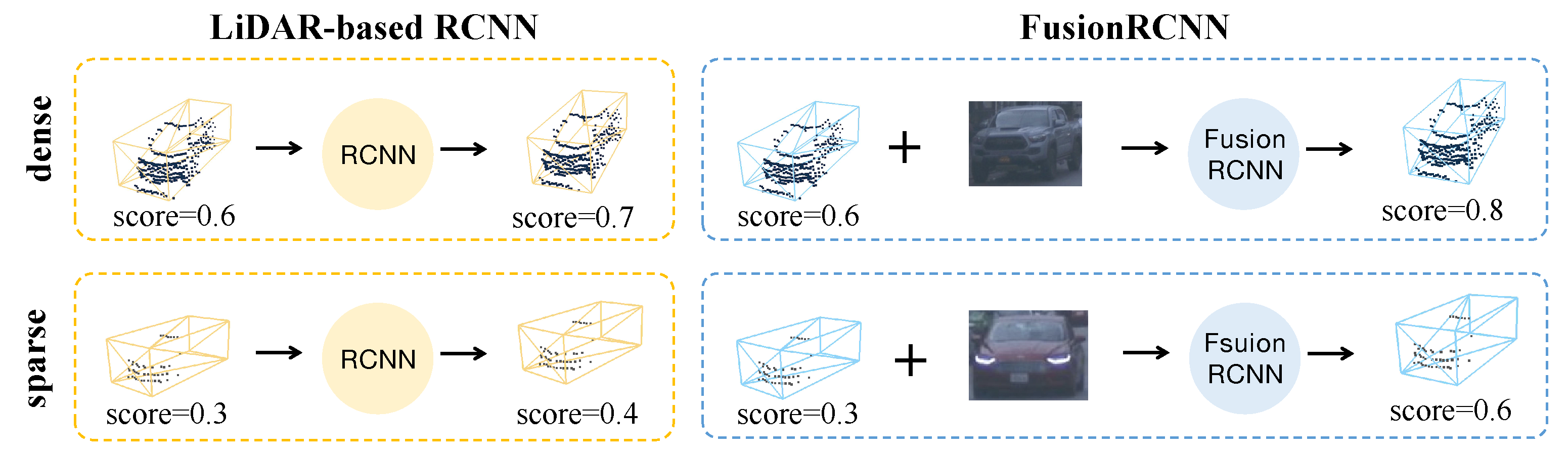
Two-stage 3D object detection methods can be classified into three primary categories based on the Point of Interest representation, namely, point-based, voxel-based, and point-voxel-based. Point-based approaches [
1,
2,
3,
4] utilize input sampling points to obtain point features for RoI refinement. Voxel-based techniques [
5,
6] rasterize point clouds into voxel-grids and extract features from 3D CNNs for refinement. Point-Voxel-based methods [
7,
8] combine both feature learning schemes to enhance detection performance. However, regardless of the representation used, the sparse and non-uniform distribution characteristics of point clouds make it challenging to distinguish and locate objects at far distances, leading to false or missed detections, as demonstrated in
Figure 1. These challenges are exacerbated when proposals contain only a few points (1–5), from which it is challenging to obtain enough semantic information. In urban scenarios, multi-sensor fusion performs better than single sensors in various tasks such as remote sensing [
9,
10]. Fortunately, cameras provide dense texture information and are complementary to LiDAR. Thus, designing a LiDAR-Camera fusion paradigm in two-stage detectors to leverage their complementary strengths effectively is of great importance.
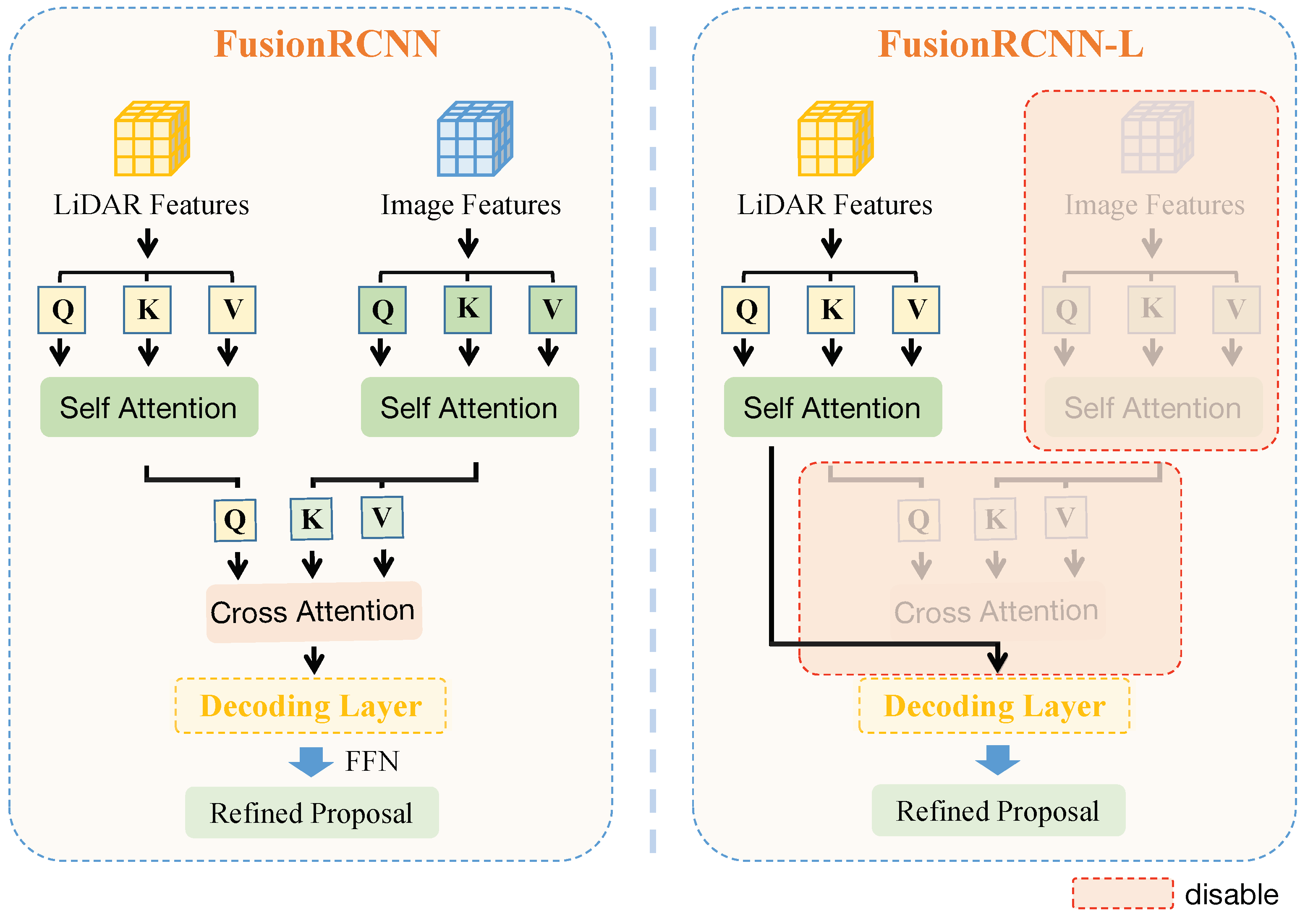
In this study, we focus on the refinement stage of fusing LiDAR point clouds and images. Previous approaches, such as those proposed by Xie et al. [
11], have used an image segmentation sub-network to extract image features, which are then attached to the raw points. However, we have found that point-based fusion methods tend to ignore the semantic density of image features and heavily rely on the image segmentation sub-network. To address these limitations, we propose a new deep fusion method called FusionRCNN, which consists of three key steps: Firstly, RoI features are extracted from both points and images corresponding to proposals generated by any one-stage detectors. Since the number of point clouds and image sizes corresponding to different proposals can vary, we sample or pad points within the corresponding box to a unified number and employ RoIPooling to obtain RoI image features with a unified size. These methods can be used to extract RoI features in parallel, significantly improving model speed. Secondly, we fuse the features of the two modalities through well-designed intra-modality self-attention and inter-modality cross-attention mechanisms. Due to the differences in visual appearance and spatial structures between LiDAR and camera images, FusionRCNN first utilizes intra-modality self-attention to enhance domain-specific features before using cross-attention to fuse information from the two modalities dynamically. This approach abandons the heavy reliance on hard associations between points and images while maintaining the semantic density of images. Finally, we feed the encoded fusion features into a transformer-based decoder to predict refined 3D bounding boxes and confidence scores.
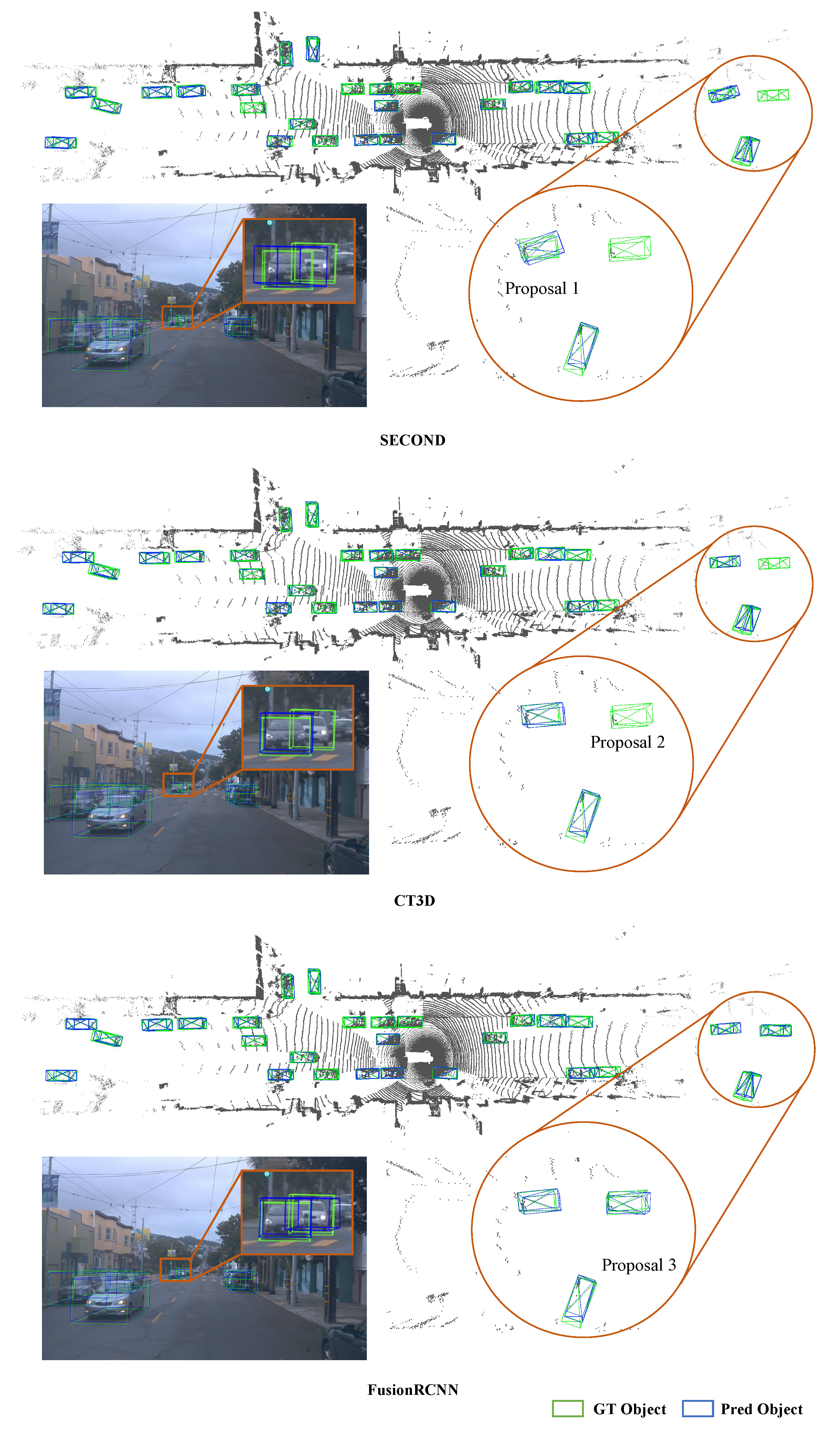
According to our observation, fully trained one-stage point cloud detectors have high bounding box recall rates (IoU(Intersection over Union) > 0.3) even in cases where the faraway point clouds are sparse. However, the real challenge is that the lack of structural information in sparse point clouds leads to low confidence, poor localization, and incorrect classification of these proposal boxes; for example, a car is misclassified as a bicycle with only several points within the proposal. Our novel two-stage fusion approach improves the precision of proposal boxes more accurately. Although some well-designed one-stage fusion methods [
12,
13] have achieved good performance, our method provides a new perspective for multi-modality fusion detection. We propose a two-stage plug-and-play refinement approach that can be attached as an additional enhancement module after any conventional detector without redesigning a highly coupled and heavy network for each specific point cloud detector, bringing more flexibility.
Our FusionRCNN method is a versatile approach that can greatly enhance the accuracy of 3D object detection. Through extensive experiments on two widely used autonomous driving datasets, KITTI [
14] and Waymo [
15], we have shown that our method outperforms LiDAR-only methods, especially for challenging samples with sparse point clouds (such as samples in the Hard level on KITTI and samples in the 50 m
range on Waymo). Notably, when our two-stage refinement network is applied to the baseline model SECOND [
16], it improves the detection performance by a remarkable
11.88 mAP(mean Average Precision) in the range of ≥50 m (from 46.93 mAP to 58.81 mAP for vehicle detection) on the Waymo dataset.
To sum up, this work makes the following contributions:
We propose a versatile and efficient two-stage multi-modality 3D detector, FusionRCNN. The detector combines image and point clouds within regions of interest and can enhance existing one-stage detectors with minor modifications.
We introduce a novel transformer-based mechanism that enables the simultaneous achievement of attentive fusion between pixel and point sets, providing rich context and structural information.
Our method demonstrates superior performance when compared to two-stage approaches on challenging samples that have sparse points in both the KITTI and Waymo Open Dataset.
3. Method
Given
M predicted proposals containing 3D bounding boxes
, where
denote the center position, size, and heading angle of the box, respectively, and confidence scores
obtained from any one-stage detectors, we aim to enhance the detection results by leveraging point clouds
P and camera images
from
T different views, i.e.,
where
and
denote the corrected bounding boxes and confidence scores, respectively, and
represents the proposed network.
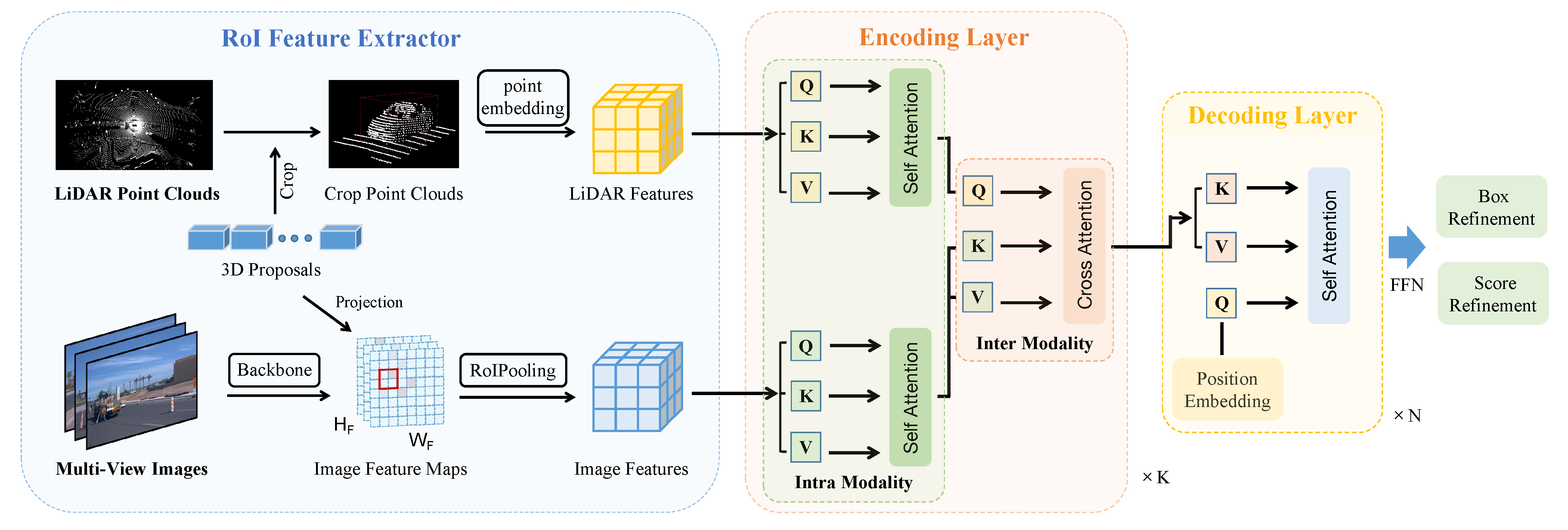
Figure 2 depicts the overall architecture of the proposed FusionRCNN. We employ the RoI Feature Extractor (
Section 3.1) to extract the RoI features from the points and images corresponding to
B, and then fuse the features of these two modalities via the Fusion Encoder (
Section 3.2). The encoding fusion features are then fed into the Decoder (
Section 3.3) to predict the refined 3D bounding boxes and confidence scores.
3.1. RoI Feature Extractor
To capture enough structural and contextual information from 3D bounding boxes B, point clouds P, and camera images I, we keep the center of each bounding box fixed while expanding its length, width, and height by a ratio k. We then feed the scaled RoI to the feature extractor, using a two-branch architecture to extract the point/image RoI features individually from the point clouds P and images I.
The point branch involves sampling or padding points within the expanded box
to a fixed number
N. To enhance the point features, we follow the point embedding techniques utilized in [
3,
4] by concatenating the distances to the box’s eight corners and its center, as well as additional LiDAR point information such as reflectivity:
where
represents the distance to the
j-th corner of the box
,
denotes the center coordinates of the bounding box,
contains extra LiDAR point information, and
is a linear projection layer that maps point features into an embedding with
C channels. The resulting point RoI features are
.
In the image branch, ResNet [
62] and FPN [
63] are used to convert the original multi-view images into feature maps. Next, we project the expanded 3D bounding boxes onto the 2D feature map and extract the image embedding corresponding to the RoI by cropping the 2D feature. Specifically, we project the eight 3D corners onto the 2D feature map using the intrinsic and extrinsic of the cameras. From this projection, we calculate the minimum circumscribed rectangle and perform RoIPooling to obtain the image feature
with a unified size of
corresponding to
. Finally, another linear layer projects
into the same dimension
C as the point features. Formally, the image RoI features are
.
3.2. Fusion Encoder
Utilizing the RoI Feature Extractor described above, we can get the per-point feature and the per-pixel image feature (pixel size varies since we fix a
pooling size while the projected proposal sizes are different) inside the RoI. Instead of fusing features by painting the image features into points like previous methods [
47,
48], which prefer to utilize the direct correspondence between points and image pixels but neglects the fact that a local region of pixels can contribute to one point and vice versa, we leverage self-attention and cross-attention to achieve the Set-to-Set fusion.
3.2.1. Intra-Modality Self-Attention
To better model the inner relationships within each modality, we first feed point features and image features into the intra-modality self-attention layer. For embedded point features
, we have
where
are linear projections and
represents layernorm layer.
represents the multi-head attention, in which the results of
h-th head can be obtained as
where
d is the feature dimension.
Correspondingly, the image features are fed into another multi-head self-attention layer to enhance the context information as
3.2.2. Inter-Modality Cross-Attention
We combine the information from both domains by aligning point and image features at the feature level using inter-modality cross-attention. This is achieved as follows:
It should be noted that the cross-attention mechanism is not mandatory, and the point and image branches can operate independently. This enhances the flexibility of our model and enables us to train the network in a decoupled manner.
Finally,
are fed into FFN with two linear layers.
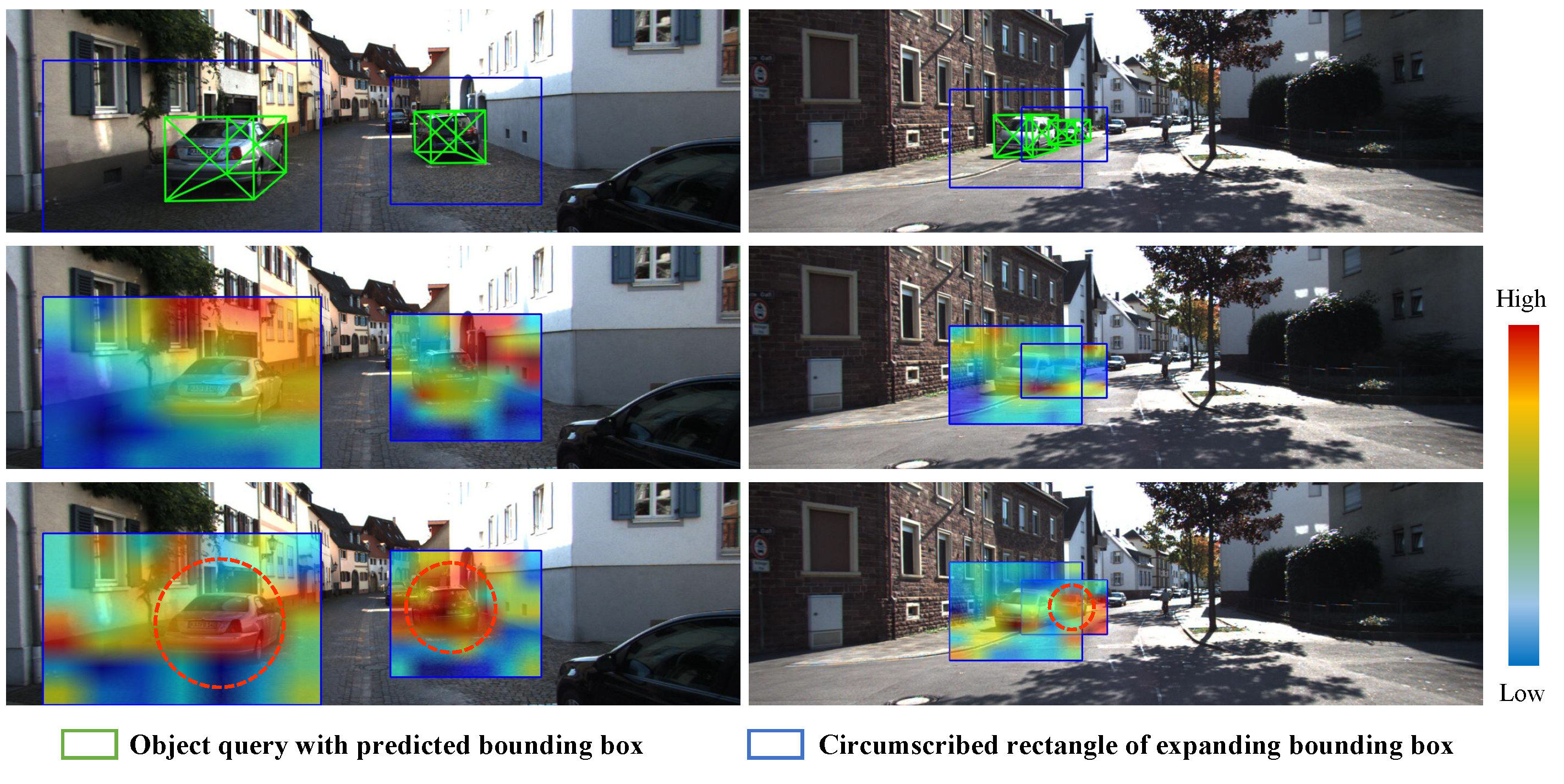
To enhance the complementary nature of the two modalities in the encoding layer, we employ a novel fusion strategy. This strategy involves integrating the rich semantic information of the image into the point features. Additionally, the object structure information extracted from the point branches is utilized to guide the aggregation of image features, which reduces the impact of occlusion and other situations. Our fusion encoder consists of multiple encoding layers to ensure complete feature fusion. The attention map visualization is presented in
Figure 3.
3.3. Decoder
The encoded fusion features are then passed to the decoding layers to obtain the final box features. To achieve this, we start by initializing a learnable query embedding
E with
d channels as a query. The encoded features are then used as keys and values, as shown below:
Next, we perform layer normalization on the output of the attention mechanism added to the query embedding
E, resulting in
:
Finally, we apply a feedforward neural network to
, resulting in
:
Here,
represents the output fusion features from the fusion encoding layers. The decoder module comprises multiple decoding layers.
3.4. Learning Objectives
To train our model, we adopt an end-to-end strategy. The overall loss function is the sum of the region proposal network (RPN) loss and the second stage network loss. The RPN loss is taken from the original network (SECOND [
16]). The newly introduced second stage loss comprises the confidence loss
and the regression loss
, as shown below:
To guide the prediction of positive and negative samples, we employ the binary cross-entropy loss, which is defined as follows:
The division of positive and negative samples is based on the intersection over union (IoU) threshold as follows:
where
t is a threshold of IoU.
For positive samples, the regression loss
is composed of the smooth L1 loss of all parameters of the bounding box, as shown below:
where
represent the predicted and ground truth parameters of the bounding box, respectively.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}