
Deep Learning-Based Framework for Soil Moisture Content Retrieval of Bare Soil from Satellite Data



Abstract
:1. Introduction
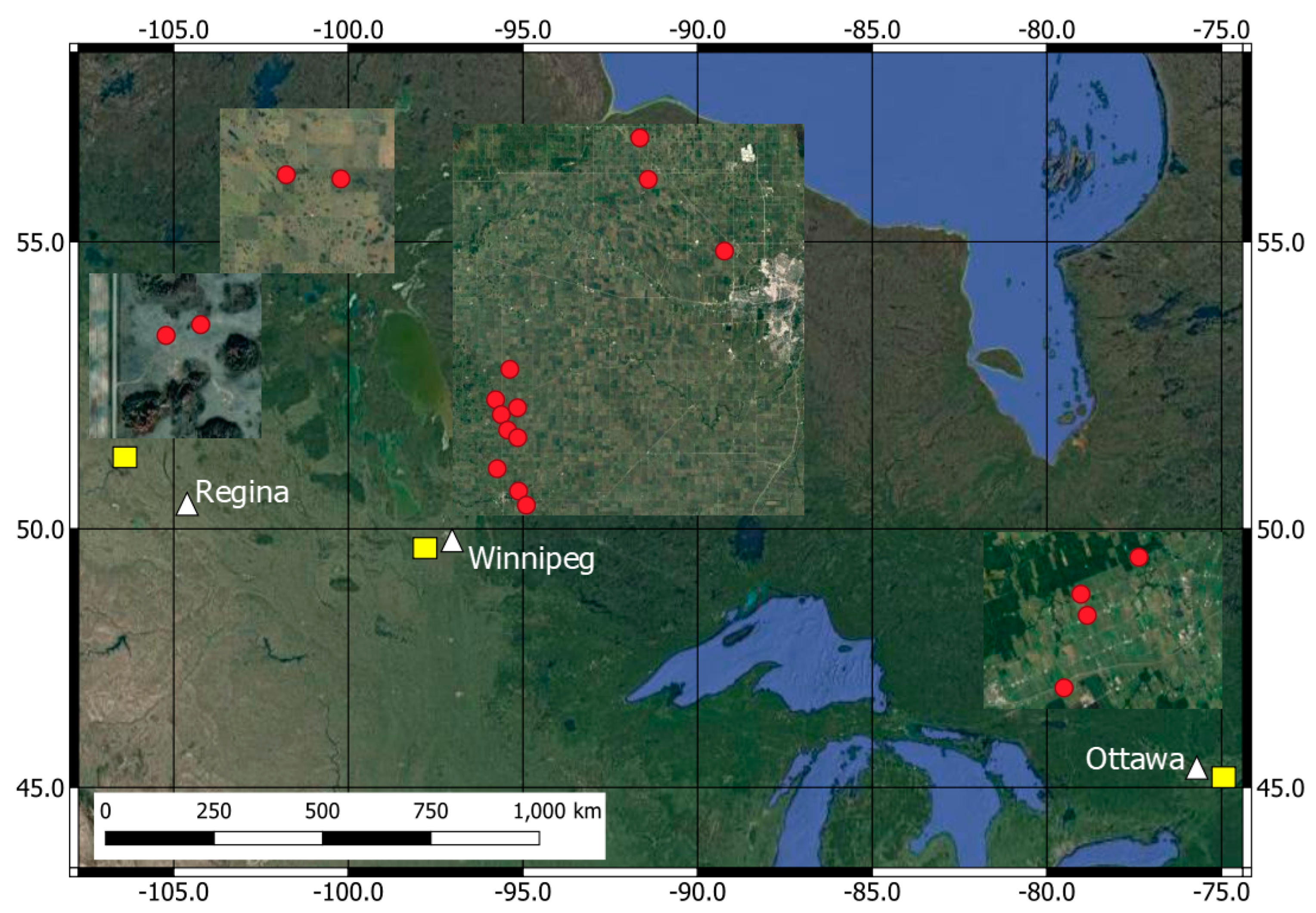
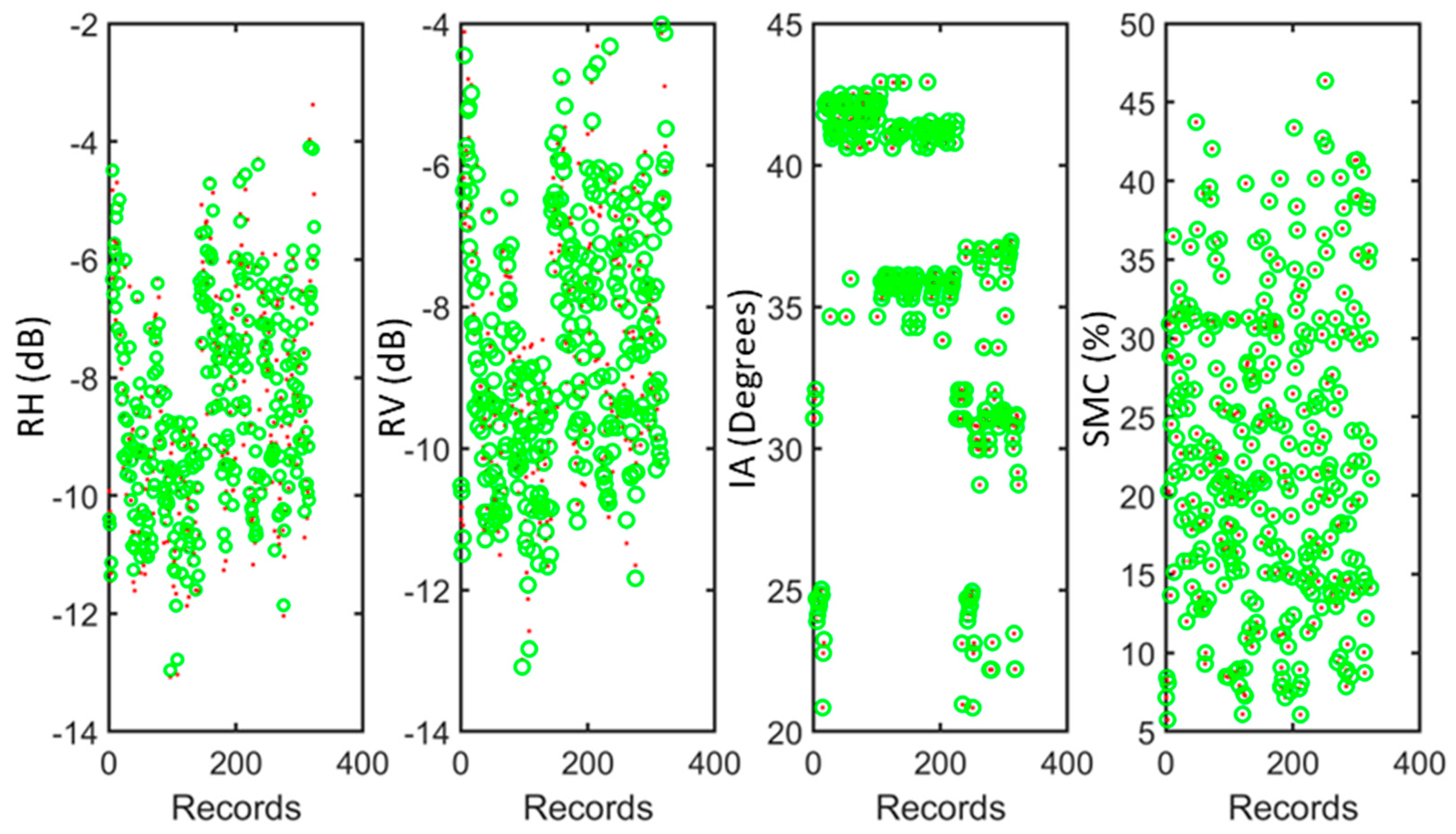
2. Data Availability
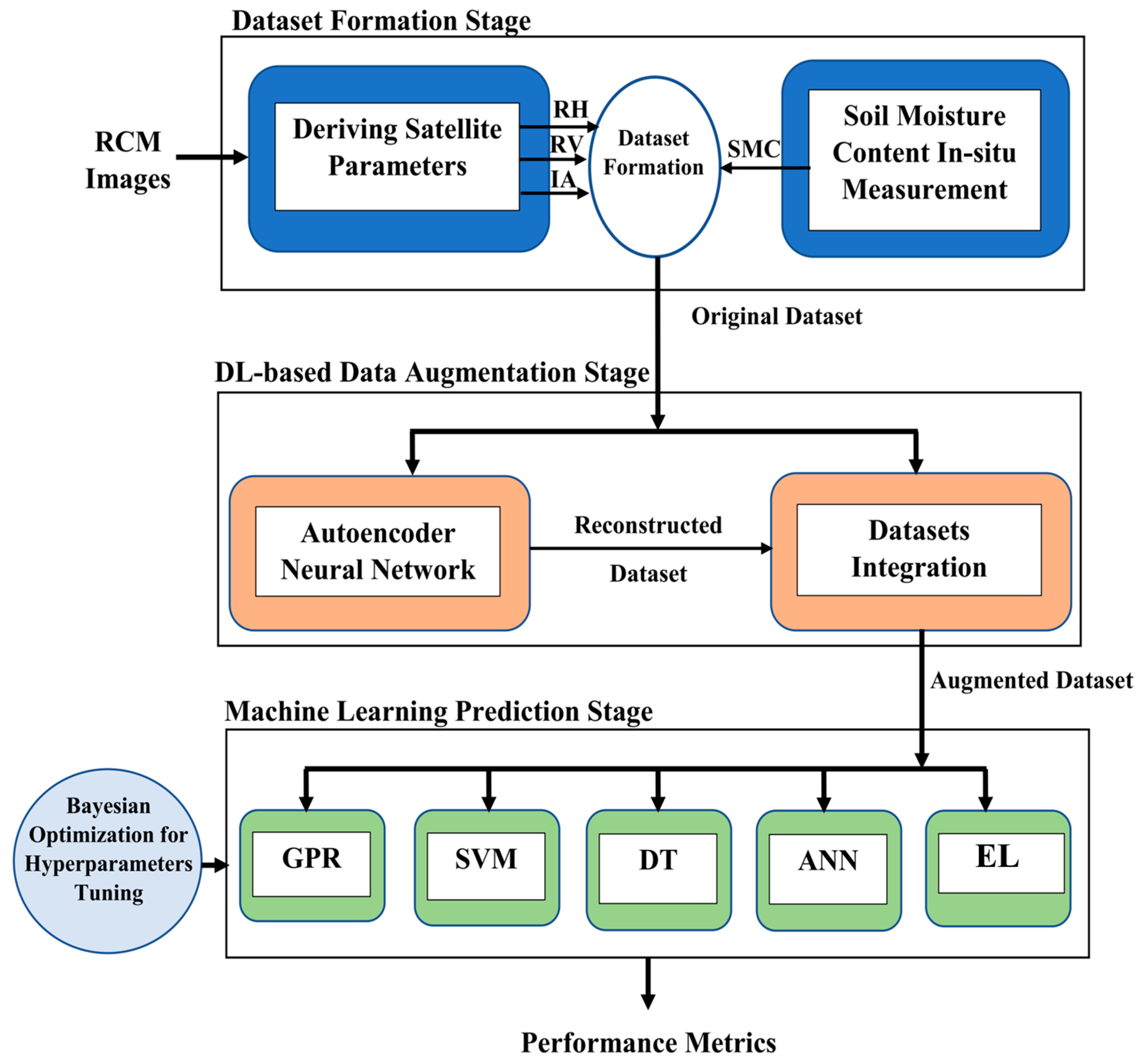
3. Methodology
3.1. ML Techniques Tuning
3.1.1. Artificial Neural Network
3.1.2. Support Vector Machine
3.1.3. Decision Trees
3.1.4. Gaussian Process Regression
- Basic function: Linear,
- Kernel function: Nonisotropic Rational Quadratic,
- σ: .
3.1.5. Ensemble Learning
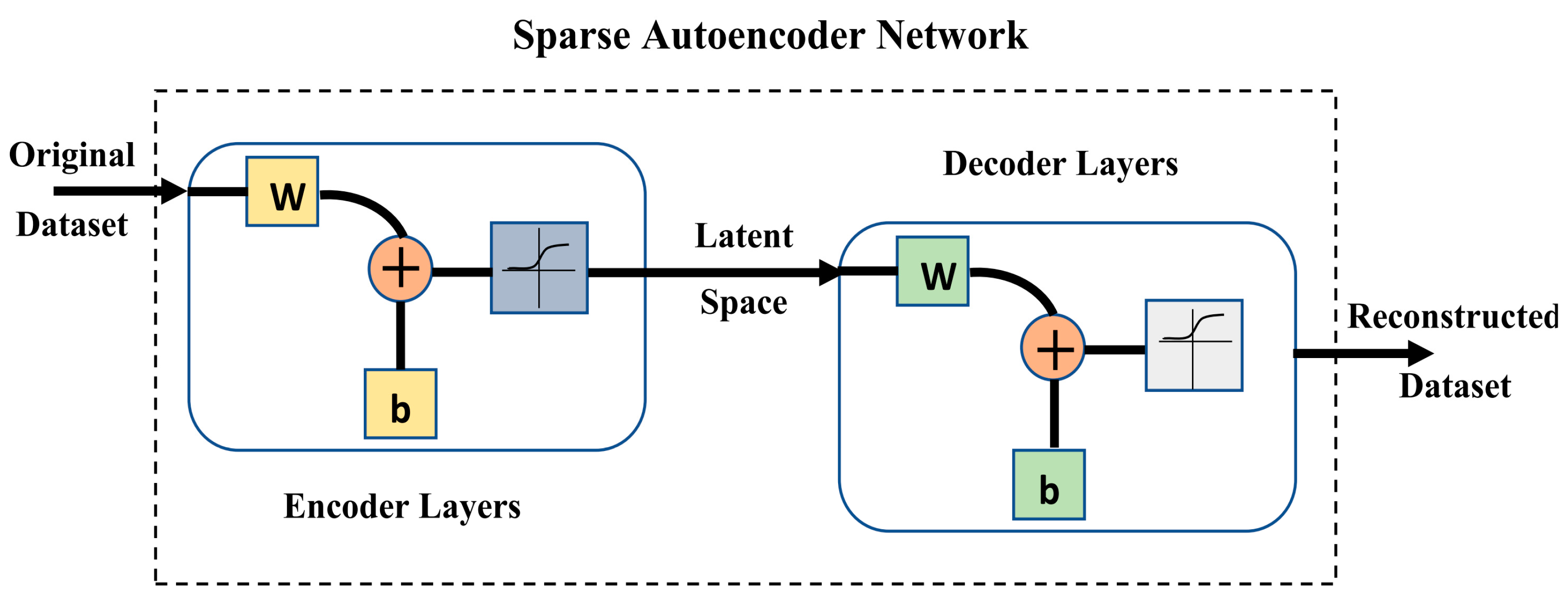
3.2. Autoencoder Deep Learning Neural Networks
4. Results and Discussion
- Experiment 1:
- Experiment 2:
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lary, D.; Alavi, A.; Gandomi, A.; Walker, A. Machine learning in geosciences and remote sensing. Geosci. Front. 2015, 7, 3–10. [Google Scholar] [CrossRef] [Green Version]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- Shirmard, H.; Farahbakhsh, E.; Müller, R.D.; Chandra, R. A review of machine learning in processing remote sensing data for mineral exploration. Remote Sens. Environ. 2022, 268, 112750. [Google Scholar] [CrossRef]
- Dawson, H.L.; Dubrule, O.; John, C.M. Impact of dataset size and convolutional neural network architecture on transfer learning for carbonate rock classification. Comput. Geosci. 2023, 171, 105284. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Liu, L.; Davedu, S.; Fujisaki-Manome, A.; Hu, H.; Jablonowski, C.; Chu, P.Y. Machine learning model-based ice cover forecasting for a vital waterway in large lakes. J. Mar. Sci. Eng. 2022, 10, 1022. [Google Scholar] [CrossRef]
- De Kerf, T.; Gladines, J.; Sels, S.; Vanlanduit, S. Oil spill detection using machine learning and infrared images. Remote Sens. 2020, 12, 4090. [Google Scholar] [CrossRef]
- Wu, Y.; Duguay, C.; Xu, L. Assessment of machine learning classifiers for global lake ice cover mapping from MODIS TOA reflectance data. Remote Sens. Environ. 2020, 253, 112206. [Google Scholar] [CrossRef]
- López-Tapia, S.; Ruiz, P.; Smith, M.; Matthews, J.; Zercher, B.; Sydorenko, L.; Varia, N.; Jin, Y.; Wang, M.; Dunn, J.; et al. Machine learning with high-resolution aerial imagery and data fusion to improve and automate the detection of wetlands. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102581. [Google Scholar] [CrossRef]
- Shahhosseini, M.; Hu, G.; Huber, I.; Archontoulis, S.V. Coupling machine learning and crop modeling improves crop yield prediction in the US Corn Belt. Sci. Rep. 2021, 11, 1606. [Google Scholar] [CrossRef]
- Santi, E.; Dabboor, M.; Pettinato, S.; Paloscia, S. Combining machine learning and compact polarimetry for estimating soil moisture from C-band SAR data. Remote Sens. 2019, 11, 2451. [Google Scholar] [CrossRef] [Green Version]
- Ghasemloo, N.; Matkan, A.; Alimohammadi, A.; Aghighi, H.; Mirbagheri, B. Estimating the agricultural farm soil moisture using spectral indices of Landsat 8, and Sentinel-1, and artificial neural networks. J. Geovis. Spat. Anal. 2022, 6, 19. [Google Scholar] [CrossRef]
- Kolassa, J.; Reichle, R.H.; Liu, Q.; Alemohammad, H.; Gentine, P.; Aida, K.; Asanuma, J.; Bircher, S.; Caldwell, T.; Colliander, A.; et al. Estimating surface soil moisture from SMAP observations using a neural network technique. Remote Sens. Environ. 2017, 204, 43–59. [Google Scholar] [CrossRef]
- Pekel, E. Estimation of soil moisture using decision tree regression. Theor. Appl. Climatol. 2020, 139, 1111–1119. [Google Scholar] [CrossRef]
- Kaur, A.; Neeru, N. Machine learning-based predictions for the estimation of soil moisture content. Comput. Integr. Manuf. Syst. 2022, 28, 265–281. [Google Scholar]
- Araya, S.N.; Fryjoff-Hung, A.; Anderson, A.; Viers, J.H.; Ghezzehei, T.A. Advances in soil moisture retrieval from multispectral remote sensing using unoccupied aircraft systems and machine learning techniques. Hydrol. Earth Syst. Sci. 2021, 25, 2739–2758. [Google Scholar] [CrossRef]
- He, B.; Jia, B.; Zhao, Y.; Wang, X.; Wei, M.; Dietzel, R. Estimate soil moisture of maize by combining support vector machine and chaotic whale optimization algorithm. Agric. Water Manag. 2022, 267, 107618. [Google Scholar] [CrossRef]
- Gill, M.; Asefa, T.; Kemblowski, M.; McKee, M. Soil moisture prediction using support vector machines. J. Am. Water Resour. Assoc. 2007, 42, 1033–1046. [Google Scholar] [CrossRef]
- Stamenkovic, J.; Guerriero, L.; Ferrazzoli, P.; Notarnicola, C.; Greifeneder, F.; Thiran, J.P. Soil moisture estimation by SAR in alpine fields using gaussian process regressor trained by model simulations. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4899–4912. [Google Scholar] [CrossRef]
- Liu, M.; Huang, C.; Wang, L.; Zhang, Y.; Luo, X. Short-term soil moisture forecasting via gaussian process regression with sample selection. Water 2020, 12, 3085. [Google Scholar] [CrossRef]
- Taneja, P.; Vasava, H.B.; Fathololoumi, S.; Daggupati, P.; Biswas, A. Predicting soil organic matter and soil moisture content from digital camera images: Comparison of regression and machine learning approaches. Can. J. Soil Sci. 2022, 102, 767–784. [Google Scholar] [CrossRef]
- Carranza, C.; Nolet, C.; Pezij, M.; Ploeg, M. Root zone soil moisture estimation with Random Forest. J. Hydrol. 2020, 593, 125840. [Google Scholar] [CrossRef]
- Tramblay, Y.; Quintana Seguí, P. Estimating soil moisture conditions for drought monitoring with random forests and a simple soil moisture accounting scheme. Nat. Hazards Earth Syst. Sci. 2022, 22, 1325–1334. [Google Scholar] [CrossRef]
- Senyurek, V.; Farhad, M.M.; Gurbuz, A.C.; Kurum, M.; Adeli, A. Fusion of reflected GPS signals with multispectral imagery to estimate soil moisture at subfield scale from small UAS platforms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6843–6855. [Google Scholar] [CrossRef]
- Dindaroğlu, T.; Kılıç, M.; Günal, E.; Gundogan, R.; Akay, A.; Seleiman, M. Multispectral UAV and satellite images for digital soil modeling with gradient descent boosting and artificial neural network. Earth Sci. Inform. 2022, 25, 2239–2263. [Google Scholar] [CrossRef]
- Pacheco, A.; L’Heureux, J.; McNairn, H.; Powers, J.; Howard, A.; Geng, X.; Rollin, P.; Gottfried, K.; Freeman, J.; Ojo, R.; et al. Real-Time In-Situ Soil Monitoring for Agriculture (RISMA) Network Metadata; Agriculture and Agri-Food Canada: Edmonton, AB, Canada. Available online: https://agriculture.canada.ca/SoilMonitoringStations/files/RISMA_Network_Metadata.pdf (accessed on 5 April 2022).
- McNairn, H.; Jackson, T.J.; Wiseman, G.; Belair, S.; Berg, A.; Bullock, A.; Colliander, A.; Cosh, M.H.; Kim, S.B.; Magagi, R.; et al. The soil moisture active passive validation experiment 2012 (SMAPVEX12): Prelaunch calibration and validation of the SMAP soil moisture algorithms. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2784–2801. [Google Scholar] [CrossRef]
- Ulaby, F.T.; Moore, R.K.; Fung, A.K. Microwave Remote Sensing: Active and Passive; Artech House: Boston, MA, USA, 1986. [Google Scholar]
- Astudillo, R.; Frazier, P.I. Bayesian Optimization of Function Networks. In Proceedings of the 35th Conference on Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Senyurek, V.; Lei, F.; Boyd, D.; Kurum, M.; Gurbuz, A.C.; Moorhead, R. Machine learning-based CYGNSS soil moisture estimates over ISMN sites in CONUS. Remote Sens. 2020, 12, 1168. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning—Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2017; Volume 1. [Google Scholar]
- Atteia, G.; Collins, M.J.; Algarni, A.D.; Samee, N.A. Deep-Learning-Based Feature Extraction Approach for Significant Wave Height Prediction in SAR Mode Altimeter Data. Remote Sens. 2022, 14, 5569. [Google Scholar] [CrossRef]
- Olshausen, B.A.; Field, D.J. Sparse coding with an overcomplete basis set: A strategy employed by V1? Vis. Res. 1997, 37, 3311–3325. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
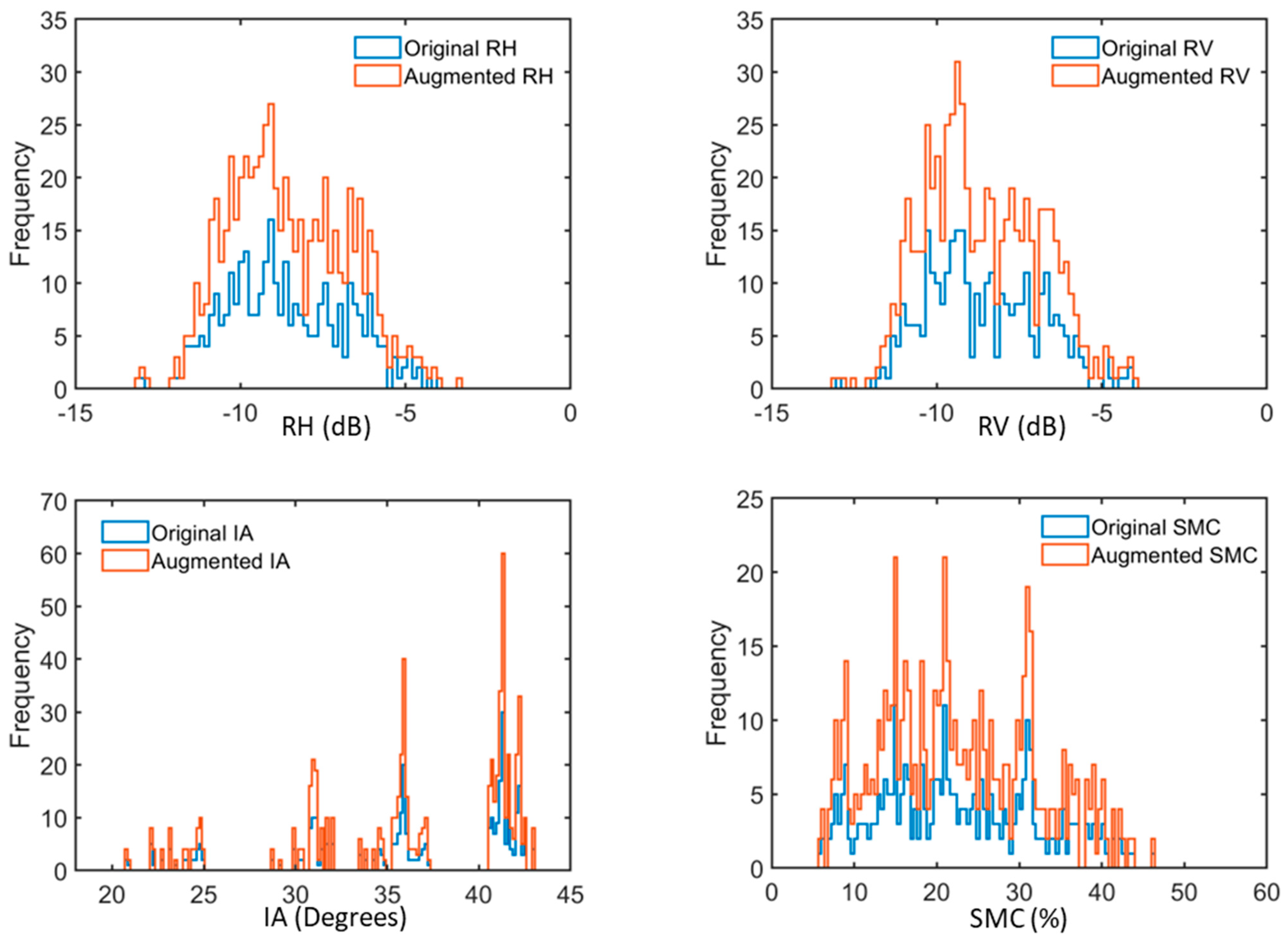{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
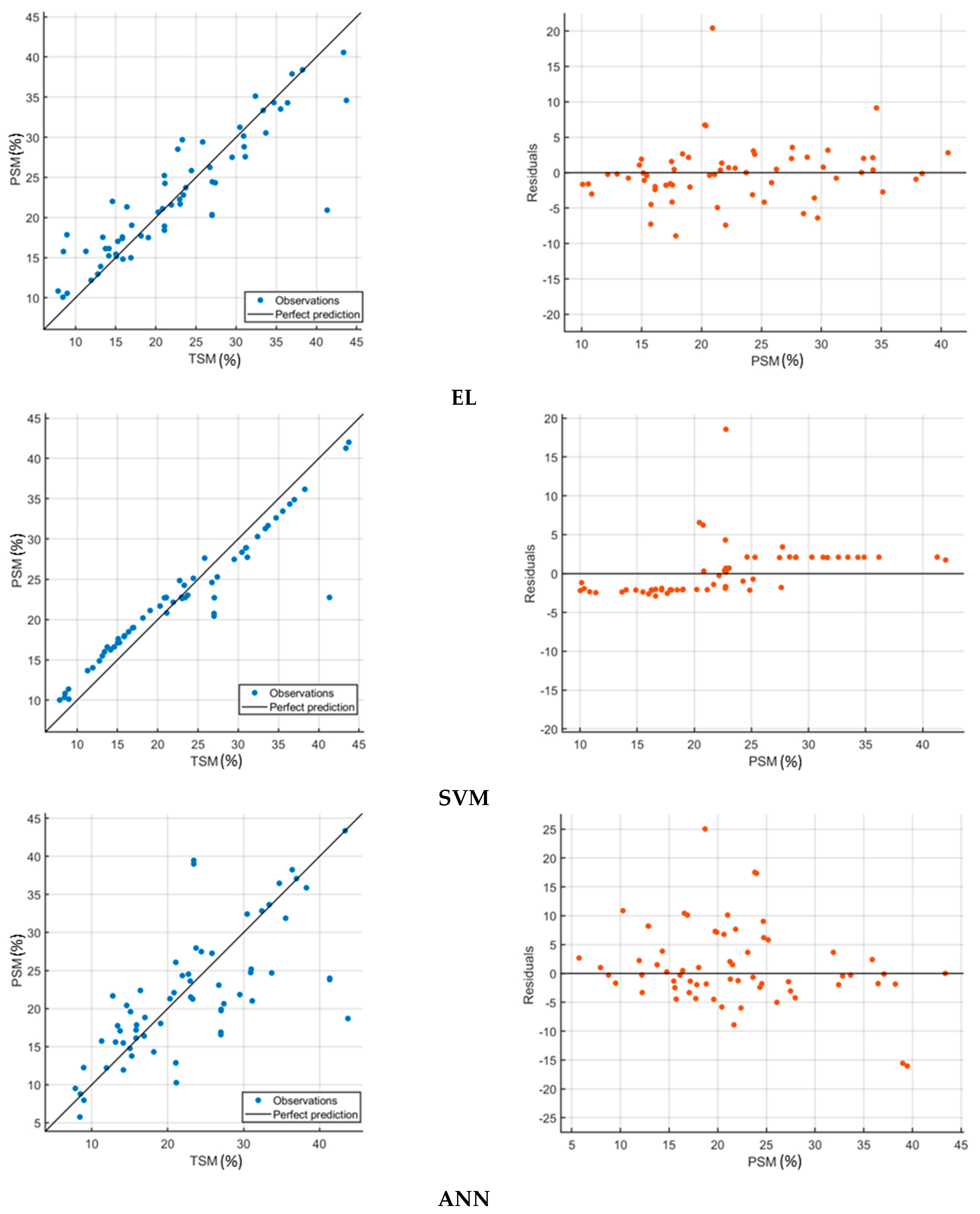{kind=link}
| Hyperparameter | Kernel Function | Kernel Scale | Box Constraint | Epsilon |
|---|---|---|---|---|
| Range | Linear Gaussian Cubic Quadratic | [0.001, 1000] | [0.001, 1000] | where is the target variable and is the Interquartile range of data. |
| Hyperparameter | Basic Function | Kernel Function | Kernel Scale | σ |
|---|---|---|---|---|
| Range | Zero Constant Linear |
| Where, Where, is the predictor. | Where is the target variable. |
| Hyperparameter | Ensemble Method | Minimum Leaf Size | Number of Learners | Learning Rate | Number of Predictors to Sample |
|---|---|---|---|---|---|
| Range | Bag/LSBoost | where, is the number of samples. | [10, 500] | [0.001, 1] | where is the number of predictors. |
| Initial Value | End Value | Threshold Value | |
|---|---|---|---|
| 426 | 0.028 | 0 | |
| Gradient | 21.9 | 0.011 |
| Optimized Model | 8-Fold Cross Validation | 10% Test Set | ||
|---|---|---|---|---|
| RMSE (%) | R2 | RMSE (%) | R2 | |
| DT | 9.31 | 0.01 | 7.90 | 0.26 |
| GPR | 7.82 | 0.30 | 7.22 | 0.38 |
| EL | 8.82 | 0.11 | 7.45 | 0.34 |
| SVM | 8.82 | 0.11 | 8.49 | 0.14 |
| ANN | 8.90 | 0.10 | 8.39 | 0.16 |
| Optimized Model | 8-Fold Cross Validation | 10% Test Set | ||
|---|---|---|---|---|
| RMSE (%) | R2 | RMSE (%) | R2 | |
| DT | 6.83 | 0.46 | 7.34 | 0.38 |
| GPR | 3.67 | 0.85 | 4.05 | 0.81 |
| EL | 4.51 | 0.77 | 4.86 | 0.73 |
| SVM | 4.01 | 0.81 | 4.72 | 0.74 |
| ANN | 8.15 | 0.24 | 6.92 | 0.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dabboor, M.; Atteia, G.; Meshoul, S.; Alayed, W. Deep Learning-Based Framework for Soil Moisture Content Retrieval of Bare Soil from Satellite Data. Remote Sens. 2023, 15, 1916. https://doi.org/10.3390/rs15071916
Dabboor M, Atteia G, Meshoul S, Alayed W. Deep Learning-Based Framework for Soil Moisture Content Retrieval of Bare Soil from Satellite Data. Remote Sensing. 2023; 15(7):1916. https://doi.org/10.3390/rs15071916
Chicago/Turabian StyleDabboor, Mohammed, Ghada Atteia, Souham Meshoul, and Walaa Alayed. 2023. "Deep Learning-Based Framework for Soil Moisture Content Retrieval of Bare Soil from Satellite Data" Remote Sensing 15, no. 7: 1916. https://doi.org/10.3390/rs15071916
APA StyleDabboor, M., Atteia, G., Meshoul, S., & Alayed, W. (2023). Deep Learning-Based Framework for Soil Moisture Content Retrieval of Bare Soil from Satellite Data. Remote Sensing, 15(7), 1916. https://doi.org/10.3390/rs15071916