

A Reconstructing Model Based on Time–Space–Depth Partitioning for Global Ocean Dissolved Oxygen Concentration


Abstract
:1. Introduction
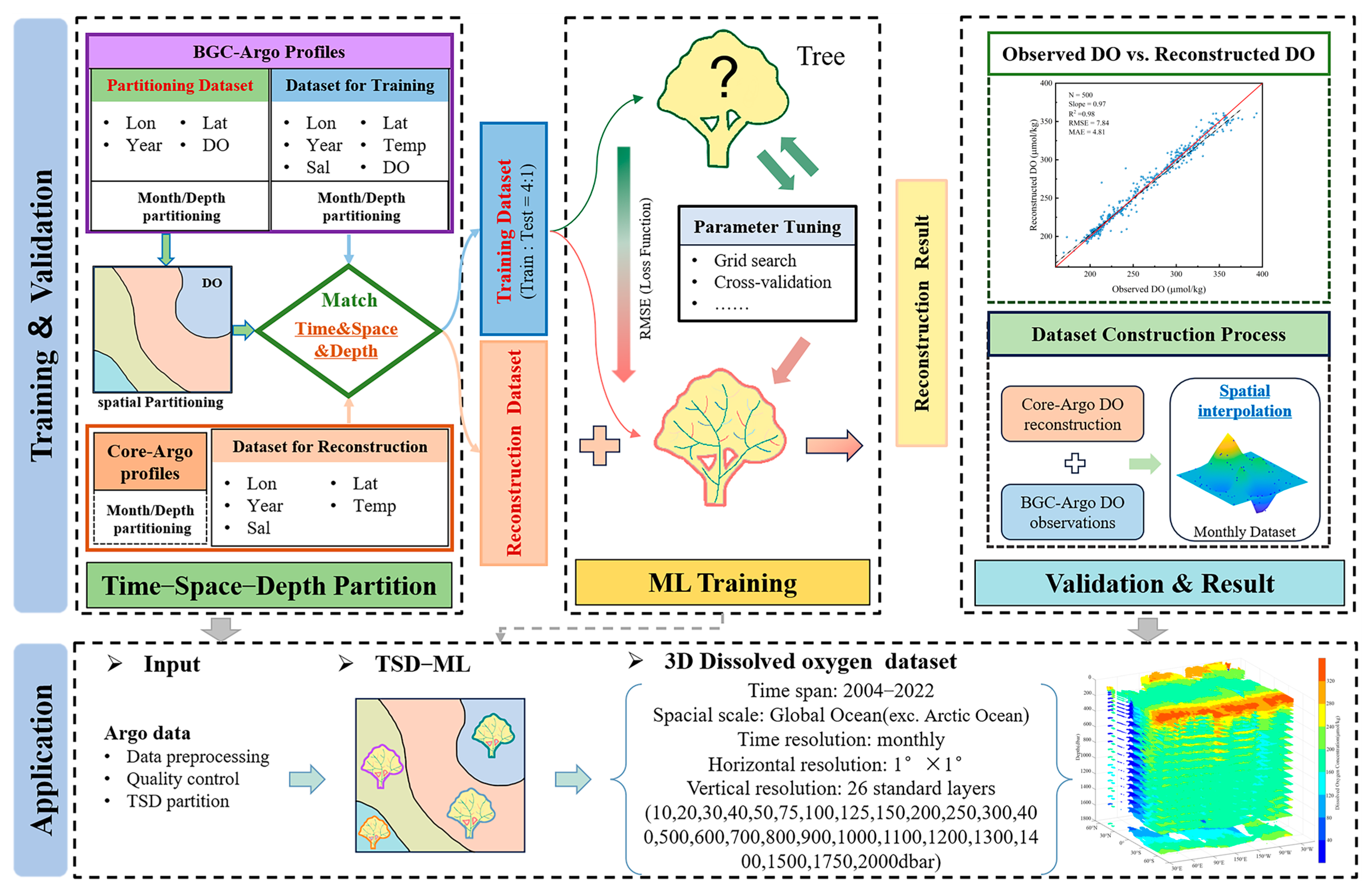
2. Materials and Methods
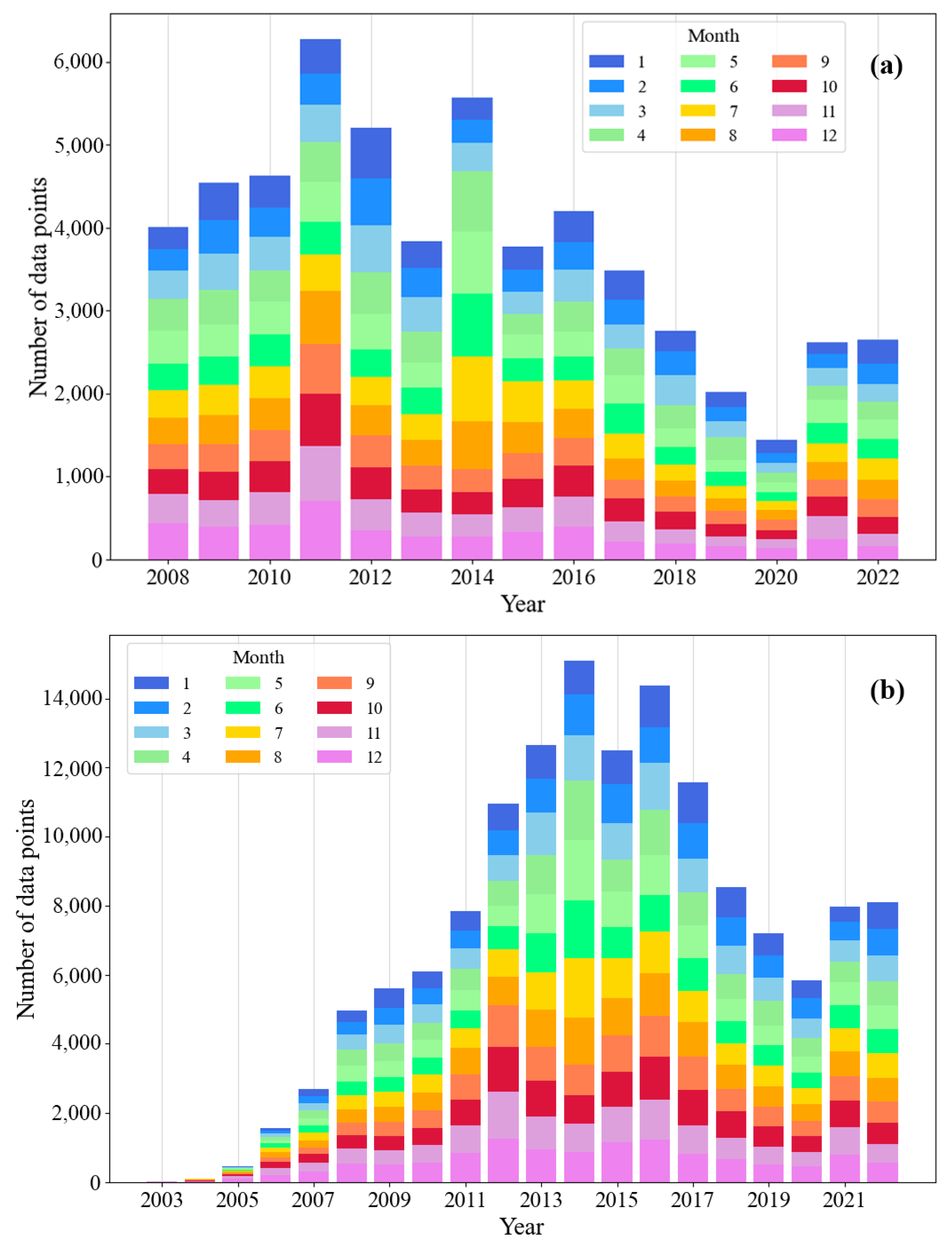
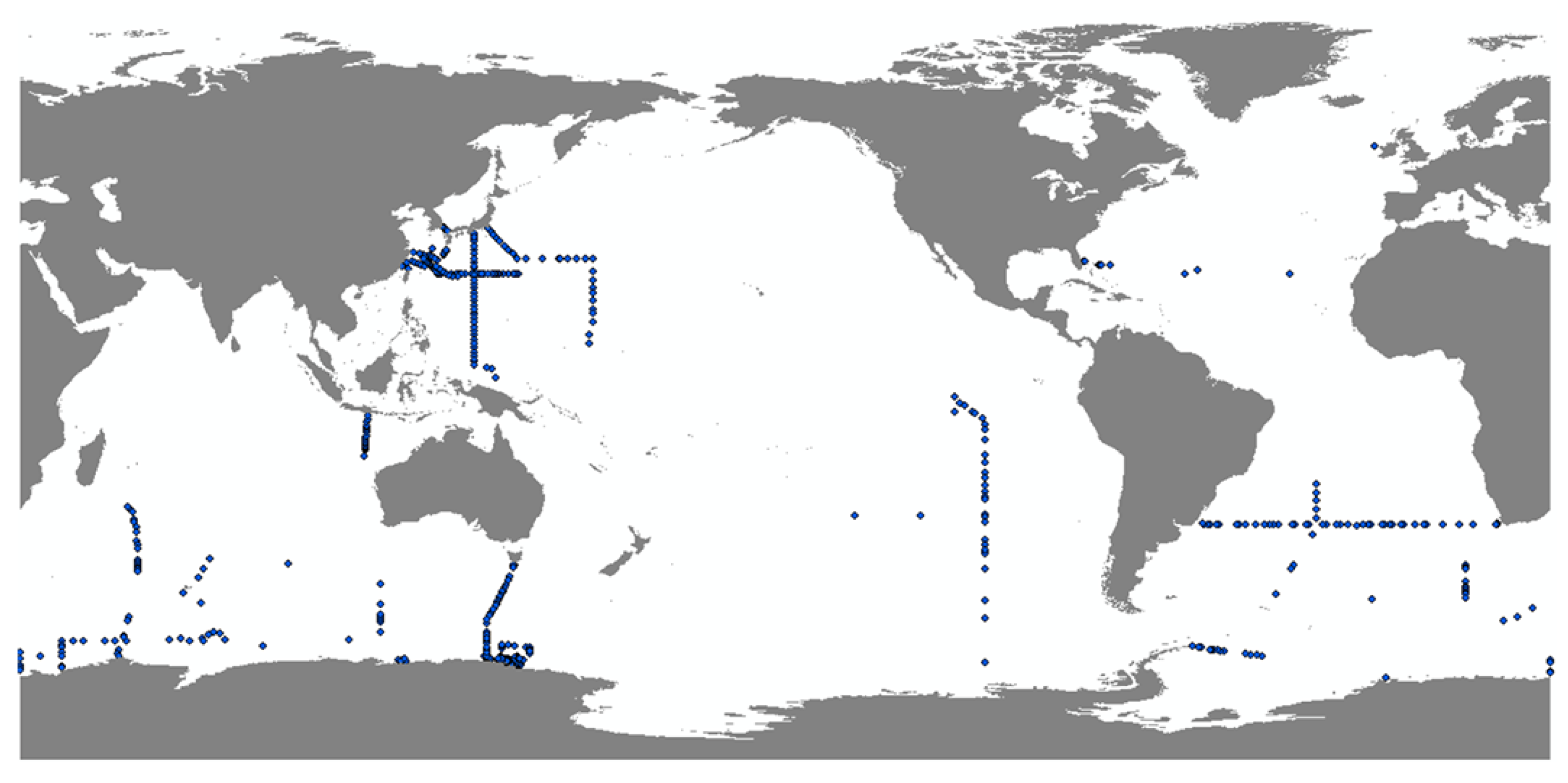
2.1. Argo Data
2.2. Model Training
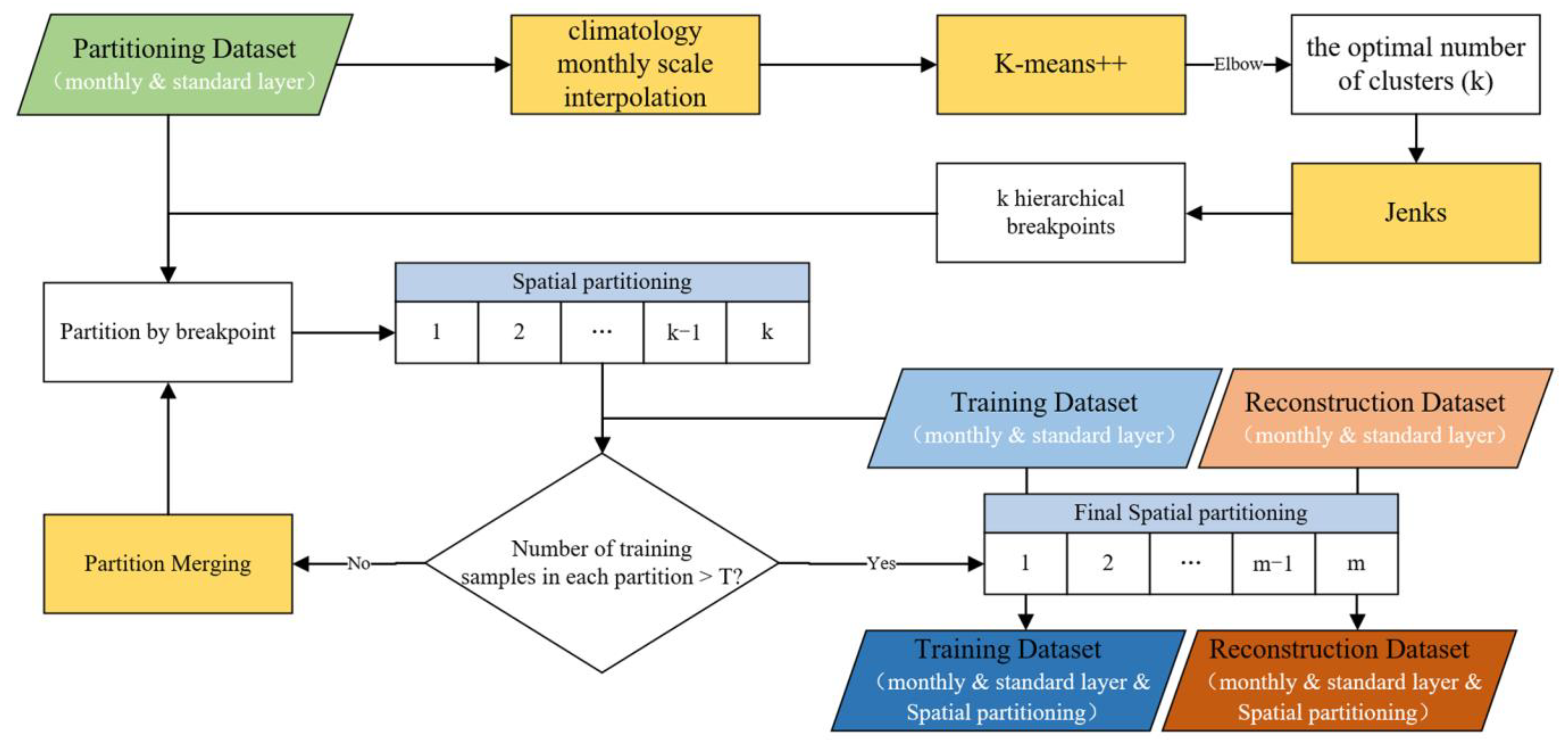
2.2.1. Time–Space–Depth Partition
- (1)
- To generate continuous, smooth DO surfaces while accounting for seafloor topography effects, spline with barriers (SWP) interpolation was applied. This interpolated the partitioned DO data from the spatial dataset into global ocean grids (85.5°S–69.5°N, 180°E–180°W) for each depth layer and month. The spline with barriers interpolation method uses the two-dimensional minimum curvature spline technique to interpolate points to a grid surface. A negative value check is also performed on the interpolated grid to ensure that all grid cell values in the final grid are greater than zero.
- (2)
- K-means++ clustering is used to classify the interpolated climatology monthly DO grids. The K-means++ algorithm is an optimization of the K-means method of randomly initializing the centroid and can select a better cluster center in the cluster center selection process. After testing various scenarios, the number of clustering clusters (k) selected in this article ranges from 2 to 12, with clustering performed sequentially for each k value. The corresponding sum of squared error (SSE) was computed to evaluate the clustering effectiveness by summing the squared distances between data points and cluster centers. SSE values were obtained for different k. The optimal k was determined using the elbow method. As k increases, the SSE decreases, but slows down after an elbow point.
- (3)
- The optimal number of clusters was entered into the Jenks natural breaks classification method to categorize the interpolated monthly DO data by minimizing intraclass differences and maximizing interclass differences, while paying more attention to the spatial correlation of partition breakpoints. Excessive data ranges for some partitions are avoided, helping to improve interpretability of results and analytical applications.
- (4)
- Partition labels were assigned to the training data based on location and month. Some partitions had insufficient samples for training, so partitions below the sample threshold (T = 300) were merged. The principle of merging is to merge only spatially adjacent partitions and to ensure the maximum number of partitions. The merging rules were as follows: (a) the partitions above the sample threshold are added directly to the subset; (b) if below the threshold, it is merged with the neighboring partition with fewer samples until the condition is met; and (c) each partition name appears only once in all subsets. These rules ensure sufficient samples for model training while maximizing spatial heterogeneity considerations.
2.2.2. ML Training and Validation
3. Results
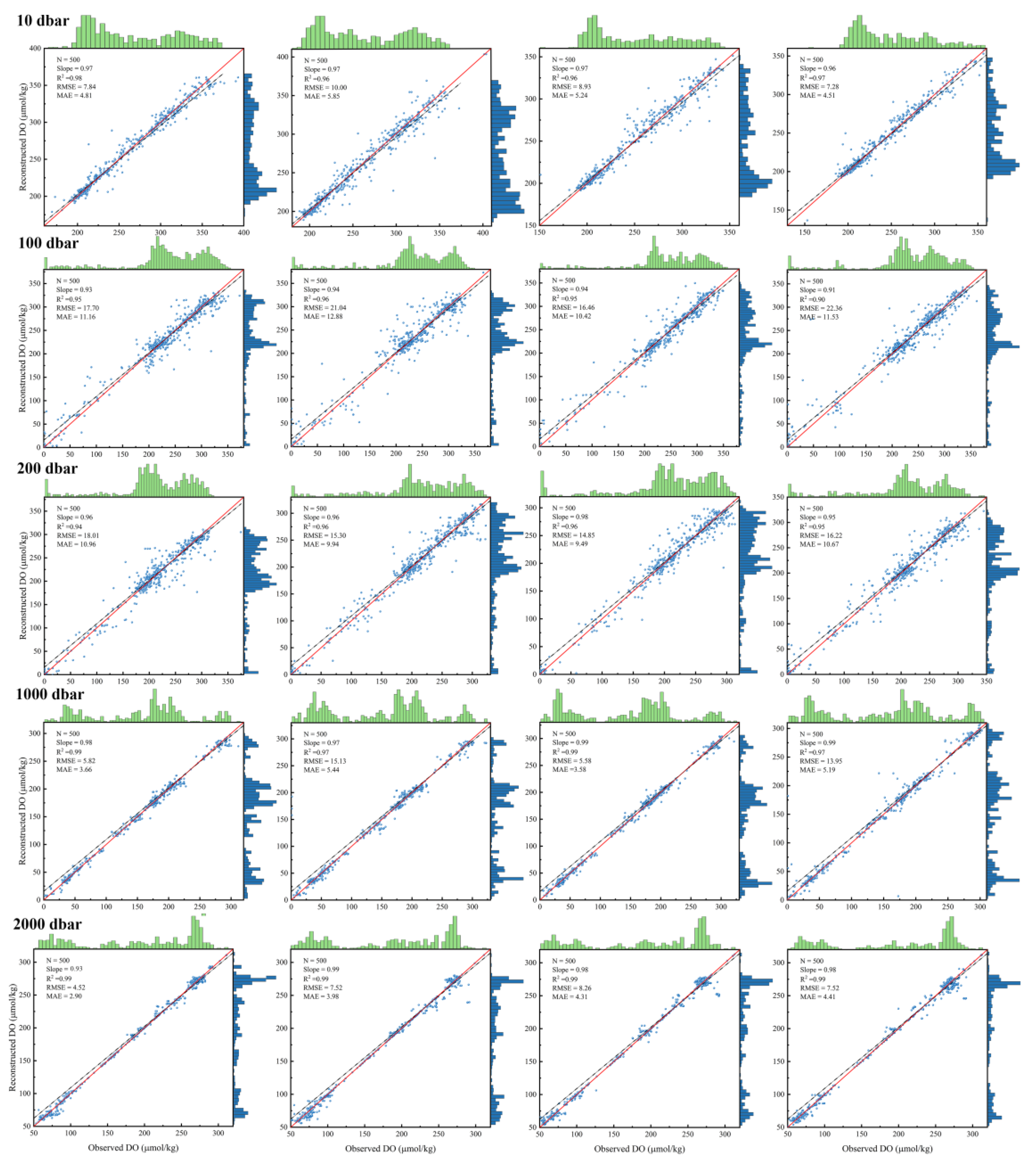
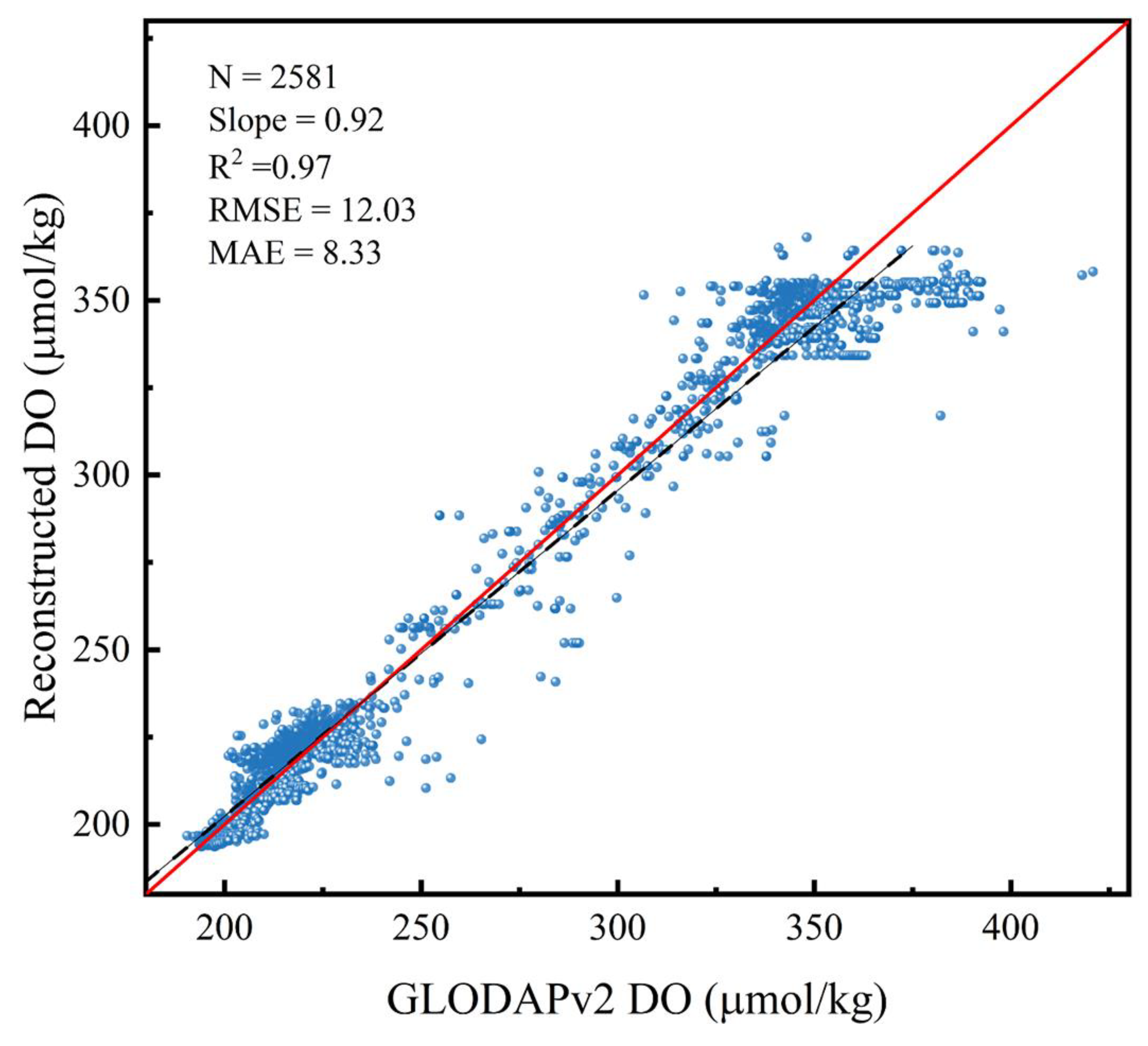
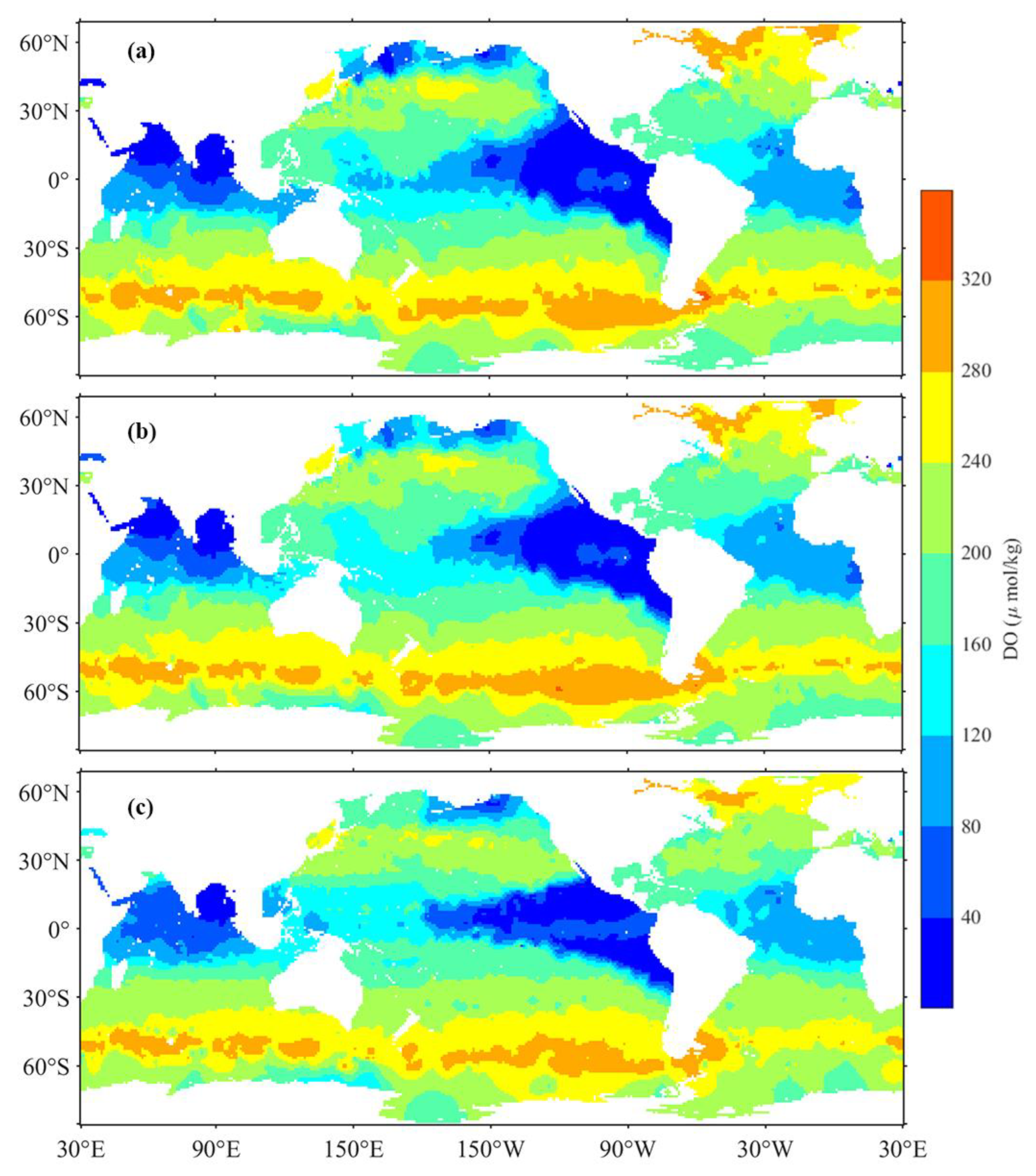
3.1. Model Performance
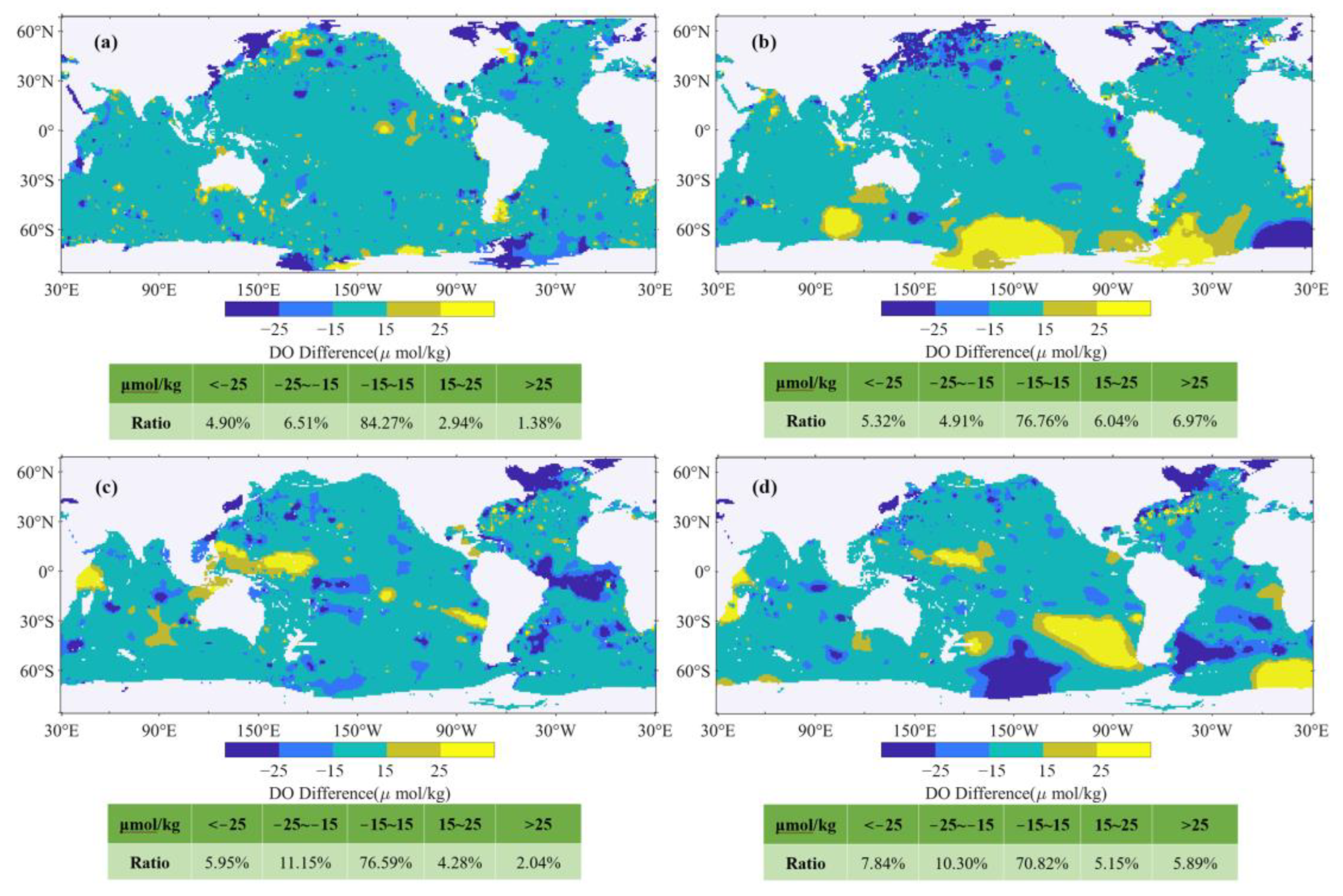
3.2. Comparative Validation
4. Discussion
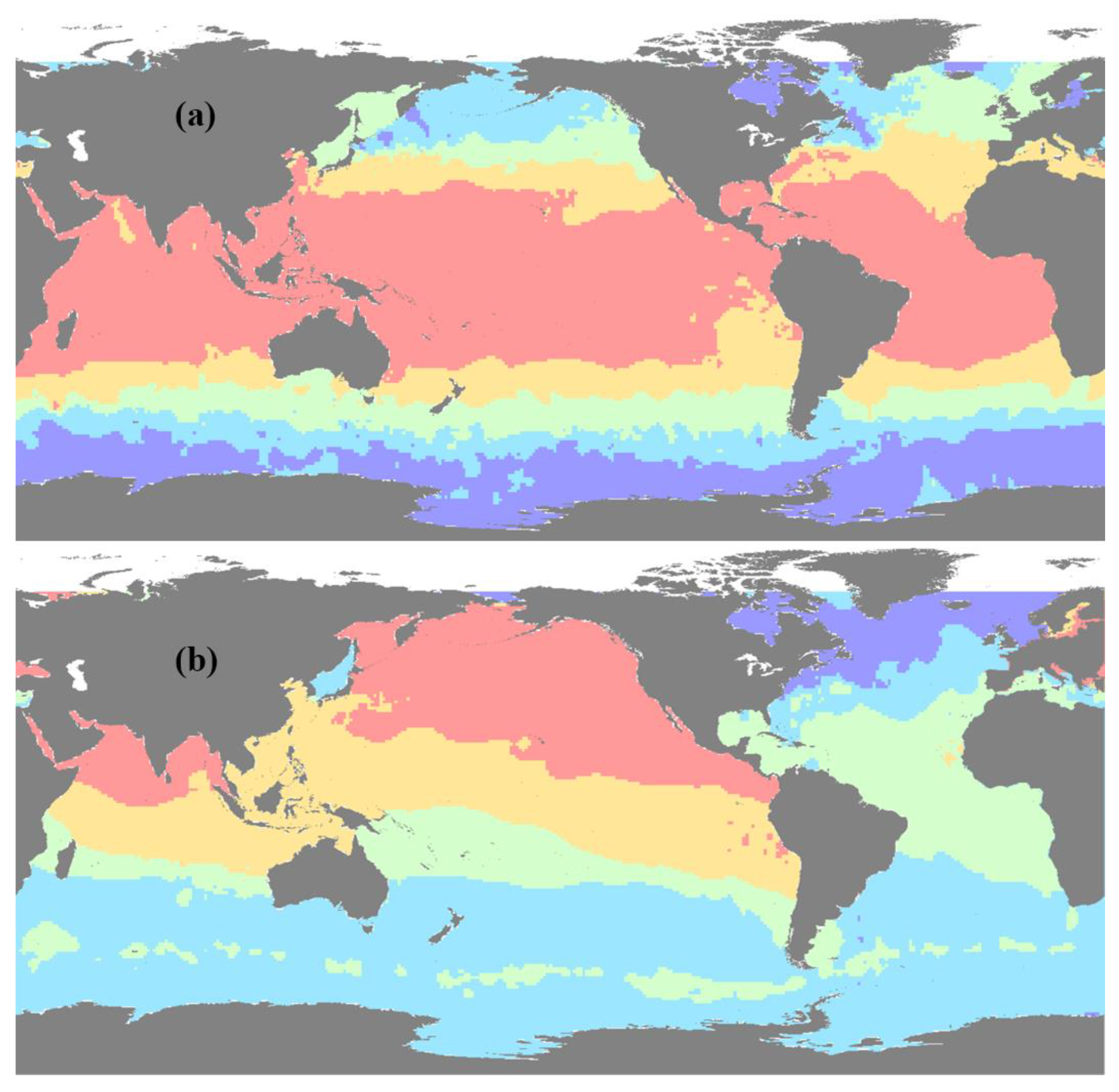
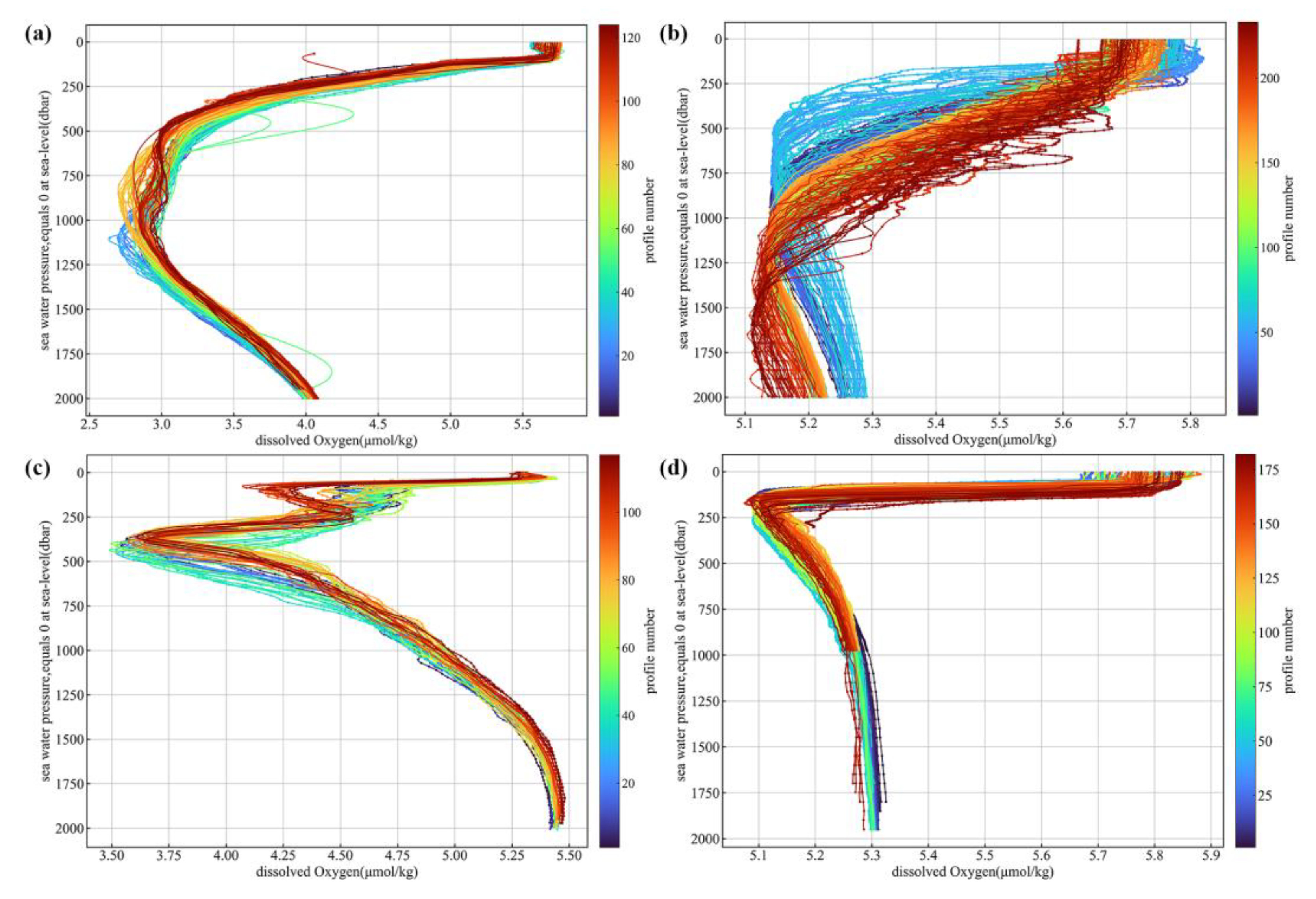
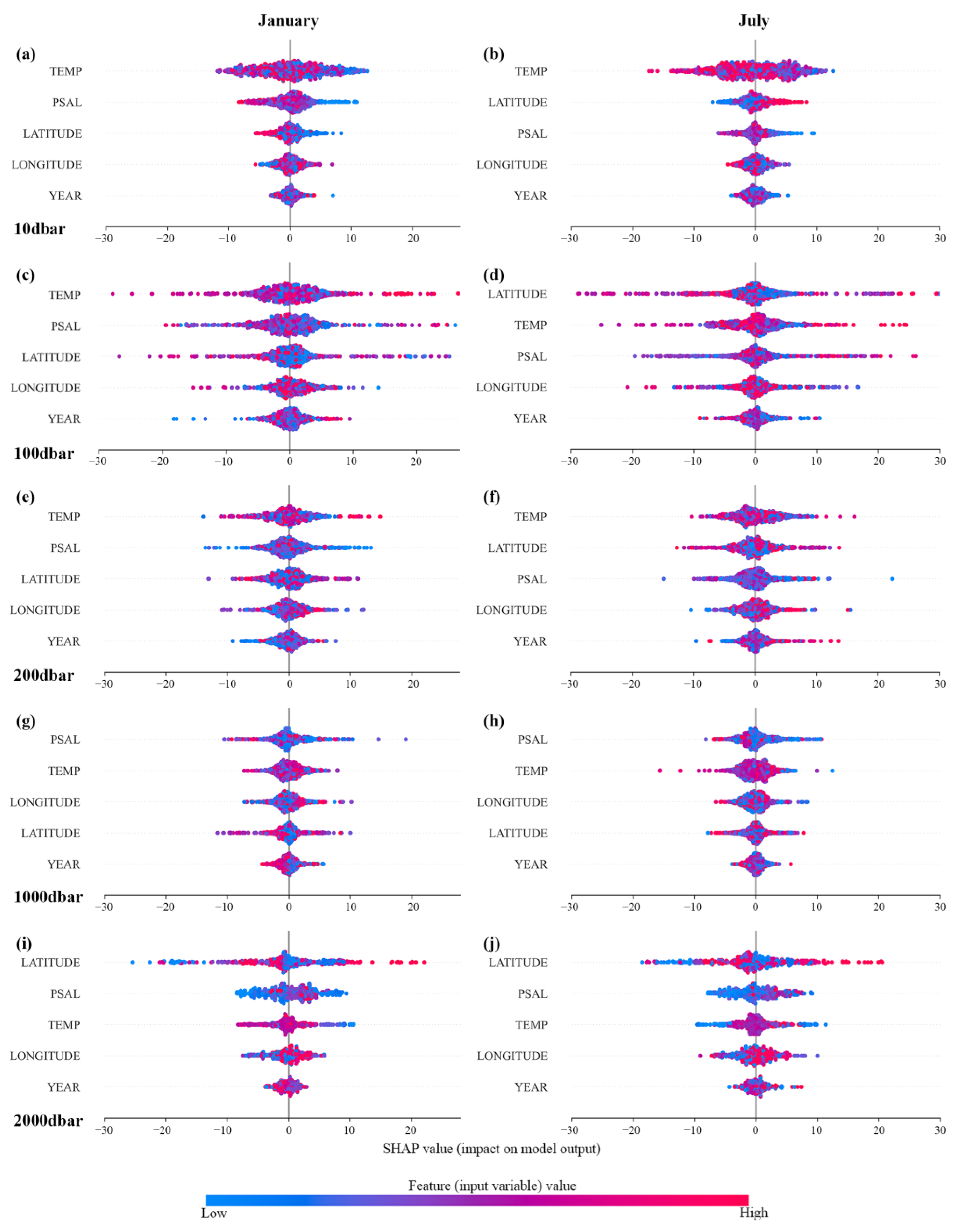
4.1. Advantage of Spatial Partition
4.2. Sensitivity Test
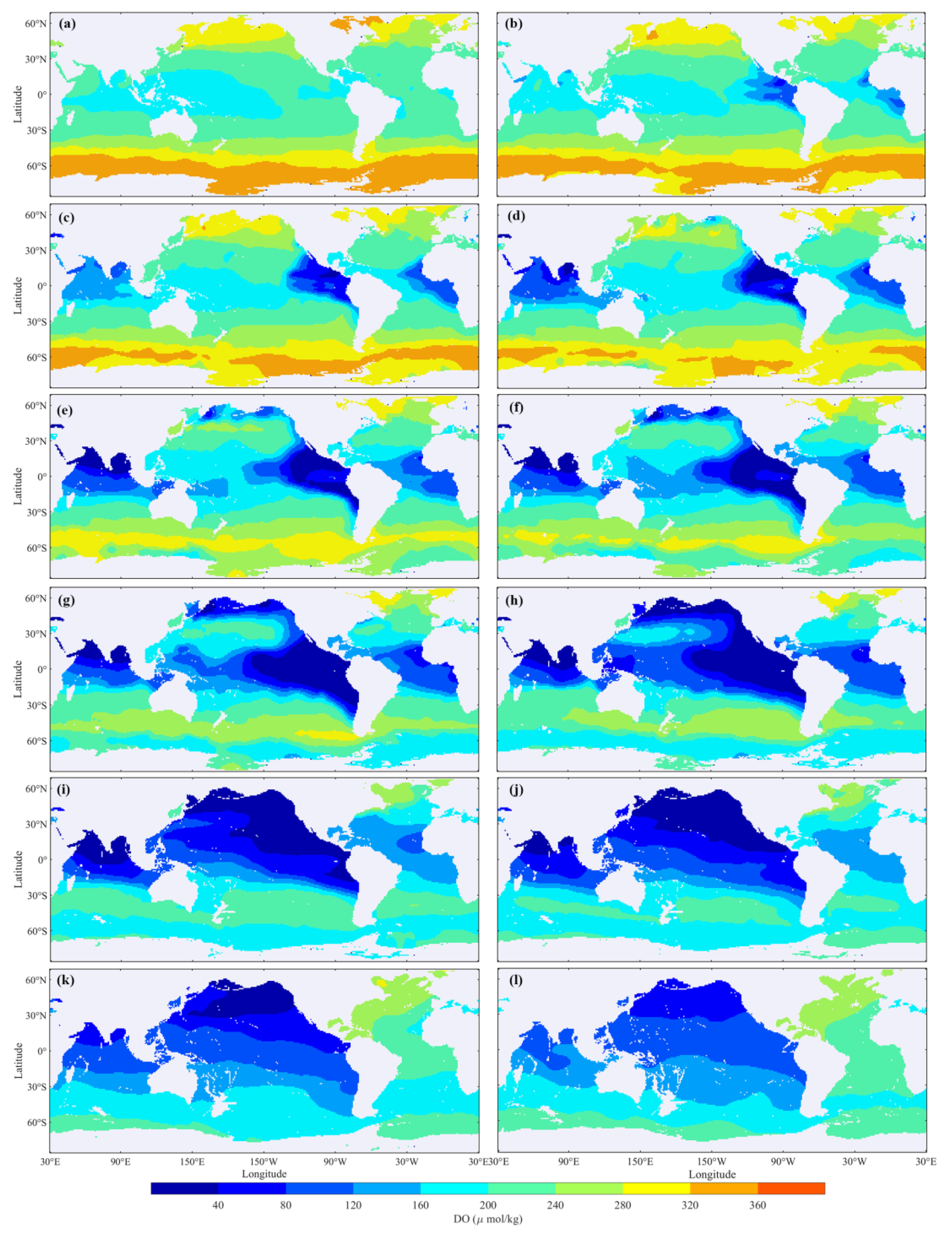
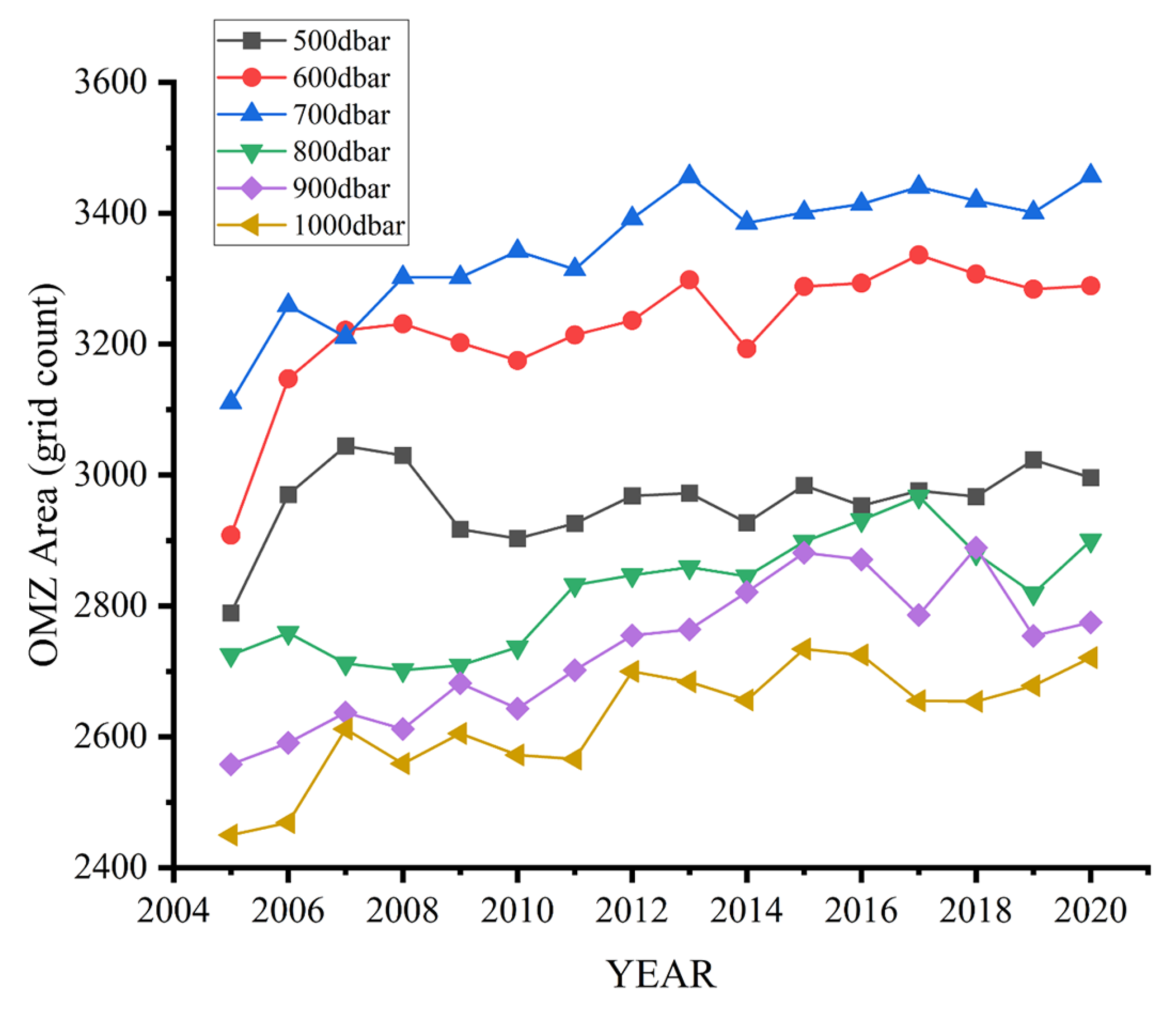
4.3. Global DO Trends
5. Conclusions
- (1)
- The TSD-ML method demonstrates commendable performance in the reconstruction of DO. The spatial heterogeneity of DO is fully considered when training ML models.
- (2)
- Partition modeling significantly improves the reconstruction accuracy of the model. Compared to the NSP and PIV approaches, the SP approach significantly improves model performance in data-sparse areas, which will promote the applications of ML in the marine domain.
- (3)
- The comparative analysis of the reconstructed DO with WOA18 and GLODAPv2 ship survey DO demonstrates a high degree of spatial consistency. This validation underscores the effectiveness of our approach in accurately depicting global ocean DO.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Depth | Month | RMSE | MAE | ||||
|---|---|---|---|---|---|---|---|
| SP | PIV | NSP | SP | PIV | NSP | ||
| 10 dbar | 1 | 4.14 | 10.43 | 11.07 | 2.87 | 3.61 | 3.88 |
| 4 | 4.87 | 5.84 | 5.88 | 3.17 | 3.6 | 3.67 | |
| 7 | 4.71 | 6.07 | 6.01 | 2.97 | 3.58 | 3.63 | |
| 10 | 4.36 | 5.81 | 6.15 | 2.88 | 3.17 | 3.27 | |
| 100 dbar | 1 | 10.26 | 14.62 | 14.08 | 6.7 | 7.72 | 8.09 |
| 4 | 8.71 | 11.18 | 13.36 | 5.42 | 6.43 | 6.85 | |
| 7 | 8.88 | 11.44 | 14.96 | 5.75 | 6.65 | 7.18 | |
| 10 | 9.47 | 15.01 | 12.33 | 5.89 | 6.91 | 7.03 | |
| 200 dbar | 1 | 7.29 | 10.67 | 15.3 | 4.99 | 6.21 | 7.34 |
| 4 | 6.98 | 11.47 | 11.94 | 4.57 | 6.31 | 6.54 | |
| 7 | 7 | 9.37 | 10.45 | 4.57 | 5.59 | 5.94 | |
| 10 | 7.37 | 11.18 | 11.54 | 4.92 | 6.47 | 6.42 | |
| 1000 dbar | 1 | 2.72 | 5.18 | 4.13 | 1.88 | 2.18 | 2.11 |
| 4 | 3.08 | 3.58 | 3.43 | 1.97 | 2.13 | 2.2 | |
| 7 | 2.95 | 3.68 | 3.65 | 1.81 | 2.21 | 2.13 | |
| 10 | 2.85 | 3.73 | 4.52 | 1.9 | 2.17 | 2.37 | |
| 2000 dbar | 1 | 3.29 | 3.81 | 6.68 | 2.17 | 2.41 | 3.26 |
| 4 | 3.4 | 4.17 | 4.09 | 2 | 2.35 | 2.42 | |
| 7 | 3.74 | 4.03 | 4.55 | 2.33 | 2.42 | 2.67 | |
| 10 | 3.81 | 4.53 | 5.32 | 2.26 | 2.45 | 2.81 | |
| Depth | Season | RMSE | MAE | ||||
|---|---|---|---|---|---|---|---|
| SP | PIV | NSP | SP | PIV | NSP | ||
| 10 dbar | 1 | 4.73 | 11.37 | 11.28 | 3.15 | 4.29 | 4.46 |
| 4 | 5.16 | 6.37 | 6.79 | 3.28 | 4.24 | 4.41 | |
| 7 | 5.31 | 6.72 | 6.65 | 3.29 | 4.36 | 4.35 | |
| 10 | 4.61 | 5.46 | 7.16 | 2.97 | 3.55 | 4.01 | |
| 100 dbar | 1 | 11.38 | 14.05 | 18.23 | 6.74 | 8.46 | 10.08 |
| 4 | 8.67 | 10.17 | 11.71 | 5.45 | 6.93 | 8.03 | |
| 7 | 8.79 | 12.99 | 13.6 | 5.51 | 7.84 | 8.36 | |
| 10 | 10.01 | 19.69 | 14.76 | 6.22 | 8.86 | 9.12 | |
| 200 dbar | 1 | 7.69 | 9.98 | 10.87 | 4.82 | 6.92 | 7.49 |
| 4 | 8.23 | 10.66 | 10.52 | 5.14 | 6.94 | 7.13 | |
| 7 | 7.77 | 9.81 | 10.48 | 4.57 | 6.81 | 7.01 | |
| 10 | 7.68 | 10.54 | 9.77 | 4.94 | 7.01 | 7.02 | |
| 1000 dbar | 1 | 3.35 | 5.81 | 5.52 | 1.90 | 4.27 | 4.41 |
| 4 | 3.05 | 5.19 | 5.25 | 1.86 | 4.09 | 4.05 | |
| 7 | 2.92 | 5.25 | 5.5 | 1.78 | 4.05 | 4.35 | |
| 10 | 2.95 | 4.88 | 5.85 | 1.80 | 3.85 | 4.47 | |
| 2000 dbar | 1 | 3.38 | 5.83 | 5.37 | 2.22 | 4.16 | 4.24 |
| 4 | 3.32 | 4.85 | 5.72 | 2.10 | 3.54 | 4.26 | |
| 7 | 4.21 | 5.19 | 5.84 | 2.54 | 3.91 | 4.27 | |
| 10 | 4.69 | 5.71 | 5.99 | 2.43 | 3.79 | 3.87 | |
References
- Varol, M. Use of water quality index and multivariate statistical methods for the evaluation of water quality of a stream affected by multiple stressors: A case study. Environ. Pollut. 2020, 266, 115417. [Google Scholar] [CrossRef] [PubMed]
- Song, H.J.; Wignall, P.B.; Song, H.Y.; Dai, X.; Chu, D.L. Seawater Temperature and Dissolved Oxygen over the Past 500 Million Years. J. Earth Sci. 2019, 30, 236–243. [Google Scholar] [CrossRef]
- Chi, L.B.; Song, X.X.; Yuan, Y.Q.; Wang, W.T.; Cao, X.H.; Wu, Z.X.; Yu, Z.M. Main factors dominating the development, formation and dissipation of hypoxia off the Changjiang Estuary (CE) and its adjacent waters, China. Environ. Pollut. 2020, 265, 115066. [Google Scholar] [CrossRef] [PubMed]
- Diaz, R.J.; Rosenberg, R. Spreading dead zones and consequences for marine ecosystems. Science 2008, 321, 926–929. [Google Scholar] [CrossRef] [PubMed]
- Vaquer-Sunyer, R.; Duarte, C.M. Thresholds of hypoxia for marine biodiversity. Proc. Natl. Acad. Sci. USA 2008, 105, 15452–15457. [Google Scholar] [CrossRef] [PubMed]
- Morée, A.L.; Clarke, T.M.; Cheung, W.W.L.; Frölicher, T.L. Impact of deoxygenation and warming on global marine species in the 21 stcentury. Biogeosciences 2023, 20, 2425–2454. [Google Scholar] [CrossRef]
- Kim, H.; Franco, A.C.; Sumaila, U.R. A Selected Review of Impacts of Ocean Deoxygenation on Fish and Fisheries. Fishes 2023, 8, 316. [Google Scholar] [CrossRef]
- Breitburg, D.; Levin, L.A.; Oschlies, A.; Gregoire, M.; Chavez, F.P.; Conley, D.J.; Garcon, V.; Gilbert, D.; Gutierrez, D.; Isensee, K.; et al. Declining oxygen in the global ocean and coastal waters. Science 2018, 359, eaam7240. [Google Scholar] [CrossRef]
- Zhang, X.D.; Wang, Z.L.; Cai, H.W.; Chai, X.P.; Tang, J.L.; Zhuo, L.F.; Jia, H.B. Summertime dissolved oxygen concentration and hypoxia in the Zhejiang coastal area. Front. Mar. Sci. 2022, 9, 1051549. [Google Scholar] [CrossRef]
- Kim, H.; Hirose, N.; Takayama, K. Physical and Biological Factors Underlying Long-Term Decline of Dissolved Oxygen Concentrationin the East/Japan Sea. Front. Mar. Sci. 2022, 9, 851598. [Google Scholar] [CrossRef]
- Simonovic, N.; Dominovic, I.; Margus, M.; Matek, A.; Ljubesic, Z.; Ciglenecki, I. Dynamics of organic matter in the changing environment of a stratified marine lake over two decades. Sci. Total Environ. 2023, 865, 161076. [Google Scholar] [CrossRef] [PubMed]
- Dimarco, S.F.; Wang, Z.K.; Chapman, P.; al-Kharusi, L.; Belabbassi, L.; al-Shaqsi, H.; Stoessel, M.; Ingle, S.; Jochens, A.E.; Howard, M.K. Monsoon-driven seasonal hypoxia along the northern coast of Oman. Front. Mar. Sci. 2023, 10, 1248005. [Google Scholar] [CrossRef]
- Eyring, V.; Bony, S.; Meehl, G.A.; Senior, C.A.; Stevens, B.; Stouffer, R.J.; Taylor, K.E. Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization. Geosci. Model Dev. 2016, 9, 1937–1958. [Google Scholar] [CrossRef]
- Kwiatkowski, L.; Torres, O.; Bopp, L.; Aumont, O.; Chamberlain, M.; Christian, J.R.; Dunne, J.P.; Gehlen, M.; Ilyina, T.; John, J.G.; et al. Twenty-first century ocean warming, acidification, deoxygenation, and upper-ocean nutrient and primary production decline from CMIP6 model projections. Biogeosciences 2020, 17, 3439–3470. [Google Scholar] [CrossRef]
- Ito, T. Optimal interpolation of global dissolved oxygen: 1965–2015. Geosci. Data J. 2022, 9, 167–176. [Google Scholar] [CrossRef]
- Schmidtko, S.; Stramma, L.; Visbeck, M. Decline in global oceanic oxygen content during the past five decades. Nature 2017, 542, 335–339. [Google Scholar] [CrossRef]
- Garcia, H.E.; Locarnini, R.A.; Boyer, T.P.; Antonov, J.I.; Johnson, D.R. Dissolved Oxygen, Apparent Oxygen Utilization, and Oxygen Saturation; NOAA Atlas NESDIS 70 Series; National Oceanic and and Atmospheric Administration: Silver Spring, MA, USA, 2013. [Google Scholar]
- Olsen, A.; Key, R.M.; van Heuven, S.; Lauvset, S.K.; Velo, A.; Lin, X.H.; Schirnick, C.; Kozyr, A.; Tanhua, T.; Hoppema, M.; et al. The Global Ocean Data Analysis Project version 2 (GLODAPv2)—An internally consistent data product for the world ocean. Earth Syst. Sci. Data 2016, 8, 297–323. [Google Scholar] [CrossRef]
- Lauvset, S.K.; Key, R.M.; Olsen, A.; van Heuven, S.; Velo, A.; Lin, X.H.; Schirnick, C.; Kozyr, A.; Tanhua, T.; Hoppema, M.; et al. A new global interior ocean mapped climatology: The 1° × 1° GLODAP version 2. Earth Syst. Sci. Data 2016, 8, 325–340. [Google Scholar] [CrossRef]
- Key, R.M.; Olsen, A.; Heuven, S.v.; Lauvset, S.K.; Velo, A.; Lin, X.; Schirnick, C.; Kozyr, A.; Tanhua, T.; Hoppema, M.; et al. Global Ocean Data Analysis Project, Version 2 (GLODAPv2); Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory, US Department of Energy: Oak Ridge, TN, USA, 2015. [Google Scholar]
- Karakaya, N.; Evrendilek, F. Monitoring and validating spatio-temporal dynamics of biogeochemical properties in Mersin Bay (Turkey) using Landsat ETM+. Environ. Monit. Assess. 2011, 181, 457–464. [Google Scholar] [CrossRef]
- Riser, S.C.; Freeland, H.J.; Roemmich, D.; Wijffels, S.; Troisi, A.; Belbeoch, M.; Gilbert, D.; Xu, J.P.; Pouliquen, S.; Thresher, A.; et al. Fifteen years of ocean observations with the global Argo array. Nat. Clim. Change 2016, 6, 145–153. [Google Scholar] [CrossRef]
- Bittig, H.C.; Maurer, T.L.; Plant, J.N.; Schmechtig, C.; Wong, A.P.S.; Claustre, H.; Trull, T.W.; Bhaskar, T.; Boss, E.; DallOlmo, G.; et al. A BGC-Argo Guide: Planning, Deployment, Data Handling and Usage. Front. Mar. Sci. 2019, 6, 502. [Google Scholar] [CrossRef]
- Matear, R.J.; Hirst, A.C. Long-term changes in dissolved oxygen concentrations in the ocean caused by protracted global warming. Global Biogeochem. Cycles 2003, 17, 35-1–35-20. [Google Scholar] [CrossRef]
- Garcia, H.E.; Keeling, R.F. On the global oxygen anomaly and air-sea flux. J. Geophys. Res.-Oceans 2001, 106, 31155–31166. [Google Scholar] [CrossRef]
- Zhao, N.; Fan, Z.M.; Zhao, M.M. A New Approach for Estimating Dissolved Oxygen Based on a High-Accuracy Surface Modeling Method. Sensors 2021, 21, 3954. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Gou, Y.; Zhang, T.; Wang, K.; Hu, C.Q. A Machine Learning Approach to Argo Data Analysis in a Thermocline. Sensors 2017, 17, 2225. [Google Scholar] [CrossRef] [PubMed]
- Sauzede, R.; Claustre, H.; Uitz, J.; Jamet, C.; Dall'Olmo, G.; D’Ortenzio, F.; Gentili, B.; Poteau, A.; Schmechtig, C. A neural network-based method for merging ocean color and Argo data to extend surface bio-optical properties to depth: Retrieval of the particulate backscattering coefficient. J. Geophys. Res.-Oceans 2016, 121, 2552–2571. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Giglio, D.; Lyubchich, V.; Mazloff, M.R. Estimating Oxygen in the Southern Ocean Using Argo Temperature and Salinity. J. Geophys. Res.-Oceans 2018, 123, 4280–4297. [Google Scholar] [CrossRef]
- Sharp, J.D.; Fassbender, A.J.; Carter, B.R.; Johnson, G.C.; Schultz, C.; Dunne, J.P. GOBAI-O2: Temporally and spatially resolved fields of ocean interior dissolved oxygen over nearly two decades. Earth Syst. Sci. Data Discuss. 2022, 15, 4481–4518. [Google Scholar] [CrossRef]
- Wang, L.H.; Jiang, Y.; Qi, H. Marine Dissolved Oxygen Prediction with Tree Tuned Deep Neural Network. IEEE Access 2020, 8, 182431–182440. [Google Scholar] [CrossRef]
- Sagan, V.; Peterson, K.T.; Maimaitijiang, M.; Sidike, P.; Sloan, J.; Greeling, B.A.; Maalouf, S.; Adams, C. Monitoring inland water quality using remote sensing: Potential and limitations of spectral indices, bio-optical simulations, machine learning, and cloud computing. Earth Sci. Rev. 2020, 205, 103187. [Google Scholar] [CrossRef]
- Xiong, Y.J.; Ran, Y.L.; Zhao, S.H.; Zhao, H.; Tian, Q.X. Remotely assessing and monitoring coastal and inland water quality in China: Progress, challenges and outlook. Crit. Rev. Environ. Sci. Technol. 2020, 50, 1266–1302. [Google Scholar] [CrossRef]
- Palmer, S.C.J.; Kutser, T.; Hunter, P.D. Remote sensing of inland waters: Challenges, progress and future directions. Remote Sens. Environ. 2015, 157, 1–8. [Google Scholar] [CrossRef]
- Yu, X.; Shen, J.; Du, J.B. A Machine-Learning-Based Model for Water Quality in Coastal Waters, Taking Dissolved Oxygen and Hypoxia in Chesapeake Bay as an Example. Water Resour. Res. 2020, 56, e2020WR027227. [Google Scholar] [CrossRef]
- Ross, A.C.; Stock, C.A. An assessment of the predictability of column minimum dissolved oxygen concentrations in Chesapeake Bay using a machine learning model. Estuar. Coast. Shelf S 2019, 221, 53–65. [Google Scholar] [CrossRef]
- Heddam, S.; Kim, S.; Mehr, A.D.; Kermani, Z.; Malik, A.; Elbeltagi, A.; Kisi, O. Predicting dissolved oxygen concentration in river using new advanced machines learning: Long-short term memory (LSTM) deep learning. In Computers in Earth and Environmental Sciences; Elsevier: Amsterdam, The Netherlands, 2022; pp. 1–20. [Google Scholar]
- Moghadam, S.V.; Sharafati, A.; Feizi, H.; Marjaie, S.M.S.; Asadollah, S.; Motta, D. An efficient strategy for predicting river dissolved oxygen concentration: Application of deep recurrent neural network model. Environ. Monit. Assess. 2021, 193, 798. [Google Scholar] [CrossRef]
- Sun, J.; Li, D.; Fan, D. A novel dissolved oxygen prediction model based on enhanced semi-naive Bayes for ocean ranches in northeast China. PeerJ Comput. Sci. 2021, 7, e591. [Google Scholar] [CrossRef]
- Li, H.; Xu, J.P.; Liu, Z.H.; Sun, Z.H. Study on the establishment of gridded Argo data by successive orrection. Marin. Sci. Bull. 2012, 31, 502–514. [Google Scholar] [CrossRef]
- Cao, Z.G.; Ma, R.H.; Duan, H.T.; Pahlevan, N.; Melack, J.; Shen, M.; Xue, K. A machine learning approach to estimate chlorophyll-a from Landsat-8 measurements in inland lakes. Remote Sens. Environ. 2020, 248, 111974. [Google Scholar] [CrossRef]
- Pahlevan, N.; Smith, B.; Schalles, J.; Binding, C.; Cao, Z.G.; Ma, R.H.; Alikas, K.; Kangro, K.; Gurlin, D.; Ha, N.; et al. Seamless retrievals of chlorophyll-a from Sentinel-2 (MSI) and Sentinel-3 (OLCI) in inland and coastal waters: A machine-learning approach. Remote Sens. Environ. 2020, 240, 111604. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Red Hook, NY, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]
- Karstensen, J.; Stramma, L.; Visbeck, M. Oxygen minimum zones in the eastern tropical Atlantic and Pacific oceans. Prog. Oceanogr. 2008, 77, 331–350. [Google Scholar] [CrossRef]














| Depth | Month | <1% | 1–5% | 5–10% | >10% |
|---|---|---|---|---|---|
| 10 dbar | 1 | 48.4 | 44.2 | 6.4 | 1 |
| 4 | 44.2 | 44.4 | 9.2 | 2.2 | |
| 7 | 44.4 | 46 | 7.4 | 2.2 | |
| 10 | 45.8 | 47.2 | 5.6 | 1.4 | |
| 100 dbar | 1 | 23.8 | 42 | 17.2 | 17 |
| 4 | 24.4 | 38.6 | 14.8 | 22.2 | |
| 7 | 24 | 47.4 | 16.4 | 12.2 | |
| 10 | 26.6 | 41.6 | 18 | 13.8 | |
| 200 dbar | 1 | 25.4 | 38.8 | 17 | 18.8 |
| 4 | 21.8 | 43.8 | 17 | 17.4 | |
| 7 | 26.2 | 36.8 | 18.4 | 18.6 | |
| 10 | 21.8 | 40.4 | 17.2 | 20.6 | |
| 1000 dbar | 1 | 42.2 | 37.2 | 13 | 7.6 |
| 4 | 35 | 37.4 | 11.4 | 16.2 | |
| 7 | 36 | 40.2 | 13.4 | 10.4 | |
| 10 | 36.2 | 35 | 15 | 13.8 | |
| 2000 dbar | 1 | 51.4 | 39.6 | 6 | 3 |
| 4 | 48.6 | 36.2 | 8.2 | 7 | |
| 7 | 48.6 | 37.2 | 8 | 6.2 | |
| 10 | 41.6 | 41.2 | 11.6 | 5.6 |
| Year | <1% | 1–5% | 5–10% | >10% |
|---|---|---|---|---|
| 2005 | 45.2 | 46.9 | 7.3 | 0.6 |
| 2010 | 35.2 | 57.1 | 7.7 | 0 |
| 2015 | 20.1 | 57.6 | 22.3 | 0 |
| 2020 | 18.7 | 58.2 | 14.3 | 8.8 |
| Depth | Month | RMSE | MAE | ||||
|---|---|---|---|---|---|---|---|
| SP | PIV | NSP | SP | PIV | NSP | ||
| 10 dbar | 1 | 3.95 | 10.83 | 10.57 | 2.67 | 3.4 | 3.29 |
| 4 | 4.51 | 5.64 | 5.71 | 2.86 | 3.47 | 3.5 | |
| 7 | 4.59 | 6.04 | 5.56 | 2.79 | 3.6 | 3.35 | |
| 10 | 4.05 | 4.96 | 5.45 | 2.6 | 2.86 | 2.91 | |
| 100 dbar | 1 | 9.65 | 13.36 | 12.45 | 6.13 | 7.41 | 7.11 |
| 4 | 9.06 | 10.88 | 11.88 | 5.5 | 6.15 | 6.67 | |
| 7 | 8.8 | 10.96 | 12.72 | 5.27 | 6.29 | 6.61 | |
| 10 | 9.16 | 18.57 | 15.95 | 5.63 | 7.36 | 7.15 | |
| 200 dbar | 1 | 7.17 | 10.09 | 9.55 | 4.79 | 6.23 | 6 |
| 4 | 6.56 | 9.87 | 9.48 | 4.19 | 5.81 | 5.6 | |
| 7 | 6.73 | 8.66 | 8.81 | 4.3 | 5.53 | 5.49 | |
| 10 | 6.96 | 9.91 | 9.81 | 4.47 | 5.93 | 5.72 | |
| 1000 dbar | 1 | 2.5 | 6.21 | 5.08 | 1.58 | 2.31 | 2.1 |
| 4 | 2.8 | 4.03 | 4.75 | 1.66 | 2.24 | 2.12 | |
| 7 | 2.31 | 3.46 | 2.96 | 1.4 | 2.19 | 1.92 | |
| 10 | 2.44 | 3.64 | 3.6 | 1.54 | 2.22 | 2.2 | |
| 2000 dbar | 1 | 2.82 | 3.87 | 4.26 | 1.86 | 2.27 | 2.42 |
| 4 | 3.12 | 3.79 | 4.14 | 1.91 | 2.16 | 2.4 | |
| 7 | 3.47 | 3.77 | 4.2 | 2.1 | 2.31 | 2.61 | |
| 10 | 3.91 | 4.41 | 4.72 | 1.98 | 2.3 | 2.53 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Xue, C.; Ping, B. A Reconstructing Model Based on Time–Space–Depth Partitioning for Global Ocean Dissolved Oxygen Concentration. Remote Sens. 2024, 16, 228. https://doi.org/10.3390/rs16020228
Wang Z, Xue C, Ping B. A Reconstructing Model Based on Time–Space–Depth Partitioning for Global Ocean Dissolved Oxygen Concentration. Remote Sensing. 2024; 16(2):228. https://doi.org/10.3390/rs16020228
Chicago/Turabian StyleWang, Zhenguo, Cunjin Xue, and Bo Ping. 2024. "A Reconstructing Model Based on Time–Space–Depth Partitioning for Global Ocean Dissolved Oxygen Concentration" Remote Sensing 16, no. 2: 228. https://doi.org/10.3390/rs16020228
APA StyleWang, Z., Xue, C., & Ping, B. (2024). A Reconstructing Model Based on Time–Space–Depth Partitioning for Global Ocean Dissolved Oxygen Concentration. Remote Sensing, 16(2), 228. https://doi.org/10.3390/rs16020228