

Ship Target Detection in Optical Remote Sensing Images Based on E2YOLOX-VFL

Abstract
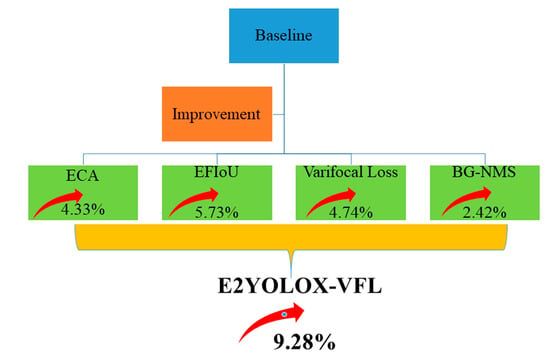
:
1. Introduction
- 1.
- Conventional detection approaches often involve multiple steps and have limited accuracy. For instance, in [5], ship detection is achieved using image edge intensity, which is effective in distinguishing between ships and nonships and obtains a 95% detection accuracy. He et al. [6] utilized texture fractal dimension and gap features for ship detection. This method effectively eliminates the impact of sea clutter on the detection results, achieving good detection results under different signal-to-noise ratios. Furthermore, it is not affected by occlusion and rotation of moving targets, demonstrating better robustness compared to traditional methods based on target shape and point-line structures. In [7], utilizing the differences in multi-scale fractal features between ship targets and background images, the interference of sea and sky backgrounds on ship detection has been effectively eliminated. The experimental results demonstrate that this method can accurately and effectively detect targets, with a 97.1% detection rate and a 9.5% false alarm rate. Li et al. [8] used an image-based maritime ship detection method based on fuzzy theory, effectively eliminating false targets and efficiently and accurately detecting ship targets in images. Its Figure of Merit (FoM) is 25% higher than the CFAR algorithm. Zhao et al. [9] proposed a ship detection method combining multi-scale visual saliency, capable of successfully detecting ships of different sizes and orientations while overcoming interference from complex backgrounds. This method achieved a detection rate of 93% and a false alarm rate of 4%. Wang et al. [10] employed maximum symmetric surround saliency detection for initial candidate region extraction and combined ship target geometric features for candidate region pre-filtering, achieving ship detection even in complex sea backgrounds. The detection accuracy is 97.2%, and the detection performance is better than most ship detection algorithms. Though these methods make use of the strong perception ability of the human visual system for nearby objects, they face challenges in selecting salient features due to factors such as atmospheric conditions, marine environments, and imaging performance.
- 2.
- In contrast, deep learning methods have gained considerable momentum due to their advantage in extracting diverse deep features containing semantic information from labeled data, thereby achieving higher accuracy compared to traditional methods. Deep learning algorithms can generally be divided into two distinct categories [11].
- 1.
- We propose the E2YOLOX-VFL algorithm for ship target detection, which combines the anchor-free YOLOX network and ECA-Net to overcome the limitations of previous methods.
- 2.
- We propose Efficient Force-IoU (EFIoU) Loss to modify Intersection over Union (IoU) Loss, which improves the regression performance of the algorithm by taking into account geometric dimensions of the predicted bounding box (B) and the ground truth box (G), suppressing the impact of low-quality samples.
- 3.
- The localization and confidence loss functions are improved in the YOLOX Head, leading to enhanced detection accuracy and robustness in complex backgrounds.
- 4.
- We propose the Balanced Gaussian NMS (BG-NMS), which is used instead of non-maximum suppression (NMS) to address the issue of missed detections caused by dense arrangements and occlusions.
- 5.
- The proposed algorithm was experimentally validated using the HRSC2016 dataset, demonstrating significant improvements in mAP and overall detection performance.
2. Related Work
2.1. Development Stages of Optical Remote Sensing Image Ship Target Detection and Recognition
- 1.
- Around 2010, the data sources for ship target detection in optical remote sensing images were mainly 5 m resolution optical images. Object analysis based on low-level features was utilized for ship target detection. Statistical and discriminatory analysis was carried out using the grayscale, texture, and shape characteristics to distinguish ship targets from the water surface. This achieved ship target detection in medium- to high-resolution and simple scenarios.
- 2.
- Around 2013, the data sources for ship target detection in optical remote sensing images were mainly 2 m resolution images. The images contained a large number of medium- and small-sized ship targets, which were abundant and easy to identify. Visual attention mechanisms and mid-level feature encoding theory were widely used for ship target localization and modeling in complex backgrounds with diverse intra-class variations. This enabled ship detection in more complex regions of high-resolution images.
- 3.
- Around 2016, a large number of high-resolution optical remote sensing images facilitated ship target detection based on deep learning. Convolutional neural networks (CNNs) were widely applied, mainly in two detection frameworks—classification-based and regression-based approaches—corresponding to step-by-step detection and integrated localization detection, respectively.
2.2. Ship Target Classification
2.2.1. Coarse-Grained Ship Recognition
2.2.2. Fine-Grained Ship Recognition
2.3. Loss Functions
- 1.
- Lack of distance information: When B and G do not have any intersection, the IoU calculation results in 0, which fails to reflect the true distance between the two boxes. Additionally, since the loss value is 0, the gradient cannot be backpropagated, preventing the network from updating its parameters.
- 2.
- Insufficient differentiation between regression outcomes: In cases where multiple regression outcomes yield the same IoU value, the quality of regression differs among these outcomes. In such cases, IoU fails to reflect the regression performance.
2.4. NMS Strategy
3. Methodology
3.1. Adding ECA Attention Mechanism to Backbone
3.2. Proposing EFIoU Loss as the Localization Loss Function
3.3. Adopting Varifocal Loss as the Confidence Loss Function
3.4. Proposing BG-NMS to Replace NMS
4. Results
4.1. HRSC2016 Dataset
- 1.
- Removing unannotated data from the dataset to exclude it from training.
- 2.
- Converting BMP format images in the dataset to JPG format to align with the model used in this research.
- 3.
- Enhancing low-contrast images to highlight ship targets.
4.2. Evaluation Metrics
4.3. Experimental Conditions
4.4. Ablation Experiments
- 1.
- YOLOX: The original YOLOX model.
- 2.
- YOLOX-BGNMS: Change NMS to BG-NMS.
- 3.
- YOLOX-ECA: An improved model in which ECA-Net is added to the Backbone network of YOLOX.
- 4.
- YOLOX-VFL: An improved model in which the confidence loss function of YOLOX is replaced with Varifocal Loss.
- 5.
- YOLOX-EFIoU: An improved model in which the localization loss function of YOLOX is replaced with EFIoU Loss.
- 6.
- E2YOLOX: An improved model in which ECA-Net is added to the Backbone network of YOLOX, and the localization loss function is replaced with EFIoU Loss.
- 7.
- E2YOLOX-VFL: An improved model in which modifications are made to the Backbone network, confidence loss function, and localization loss function of YOLOX.
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bi, F.; Zhu, B.; Gao, L.; Bian, M. A Visual Search Inspired Computational Model for Ship Detection in Optical Satellite Images. IEEE Geosci. Remote Sens. Lett. 2012, 9, 749–753. [Google Scholar]
- Zhao, M.; Zhang, X.; Kaup, A. Multitask Learning for SAR Ship Detection with Gaussian-Mask Joint Segmentation. IEEE Trans. Geosci. Remote Sens. 2021, 14, 5214516. [Google Scholar] [CrossRef]
- Wan, H.; Huang, Z.; Xia, R.; Wu, B.; Sun, L.; Yao, B.; Liu, X.; Xing, M. AFSar: An Anchor-free SAR Target Detection Algorithm Based on Multiscale Enhancement Representation Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5219514. [Google Scholar] [CrossRef]
- Tang, J.; Deng, C.; Huang, G.; Zhao, B. Compressed-Domain Ship Detection on Spaceborne Optical Image Using Deep Neural Network and Extreme Learning Machine. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1174–1185. [Google Scholar] [CrossRef]
- Zhu, C.; Zhou, H.; Wang, R.; Wang, R.; Guo, J. A Novel Hierarchical Method of Ship Detection from Spaceborne Optical Image Based on Shape and Texture Features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- He, S.; Yang, S.; Shi, A.; Li, T. Application of Texture Higher-Order Classification Feature in Ship Target Detection on The Sea. Opt. Electron. Technol. 2008, 6, 79–82. [Google Scholar]
- Zhang, D.; He, S.; Yang, S. A Multi-Scale Fractal Method for Ship Target Detection. Laser. Infrared. 2009, 39, 315–318. [Google Scholar]
- Li, C.; Hu, Y.; Chen, X. Research on Marine Ship Detection Method of SAR Image Based on Fuzzy Theory. Comput. App. 2005, 25, 1954–1956. [Google Scholar]
- Zhao, H.; Wang, P.; Dong, C.; Shang, Y. Ship Target Detection Using Multi-scale Visual Saliency. Optisc. Precis. Eng. 2020, 28, 1395–1403. [Google Scholar] [CrossRef]
- Wang, H.; Zhu, M.; Lin, C.; Chen, D.; Yang, H. Ship Detection in Complex Sea Background in Optical Remote Sensing Images. Optisc. Precis. Eng. 2018, 26, 723–732. [Google Scholar] [CrossRef]
- Zhang, C.; Xiong, B.; Kuang, G. Overview of Ship Target Detection in Optical Satellite Remote Sensing Images. J. Rad. Sci. 2020, 35, 637–647. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intel. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Su, J.; Huang, H.; Li, X. A Ship Target Detection Algorithm for SAR Images Based on Deep Multi-scale Feature Fusion CNN. J. Opt. 2020, 40, 0215002. [Google Scholar]
- Zhang, R.; Yao, J.; Zhang, K.; Chen, F.; Zhang, J. S-CNN-Based Ship Detection from High-Resolution Remote Sensing Images. In Proceedings of the International Archives of the Photogrammetry Remote Sensing and Spatial Information Sciences, Prague, Czech Republic, 12–19 July 2016. [Google Scholar]
- Ma, X.; Shao, L.; Jin, X. Ship Ttarget Detection Method in Visual Images Based on Improved Mask R-CNN. J. B. Univ. Technol. 2021, 41, 734–744. [Google Scholar]
- Han, X.; Zhong, Y.; Zhang, L. An Efficient and Robust Integrated Geospatial Object Detection Framework for High Spatial Resolution Remote Sensing Imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef]
- Li, Q.; Mou, L.; Liu, Q.; Wang, Y.; Zhu, X. HSF-Net: Multiscale Deep Feature Embedding for Ship Detection in Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7147–7161. [Google Scholar] [CrossRef]
- Yao, Y.; Jiang, Z.; Zhang, H.; Zhao, D.; Cai, B. Ship Detection in Optical Remote Sensing Images Based on Convolutional Neural Networks. J. App. Remote Sens. 2017, 11, 042611. [Google Scholar] [CrossRef]
- Yang, F.; Xu, Q.; Li, B.; Ji, Y. Ship Detection from Thermal Remote Sensing Imagery through Region Based on Deep Forest. IEEE Geosci. Remote Sens. Lett. 2018, 15, 449–453. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Zhang, W. Ship Extraction Using Post CNN from High Resolution Optical Remotely Sensed Images. In Proceedings of the 3rd Information Networking, Electronics and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019. [Google Scholar]
- Redmon, J.; Redmon, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, D.; Shao, H.; Zhang, J. Research on Improving YOLOv3′s Ship Detection Algorithm. Mod. Electron. Technol. 2023, 46, 101–106. [Google Scholar]
- Xu, Y.; Gu, Y.; Peng, D.; Liu, J.; Chen, H. An Improved YOLOv3 Model for Arbitrary Direction Ship Detection in Synthetic Aperture Radar Images. J. Mil. Eng. 2021, 42, 1698–1707. [Google Scholar]
- Zou, Z.; Shi, Z. Ship Detection in Spaceborne Optical Image with SVD Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5832–5845. [Google Scholar] [CrossRef]
- Wang, R.; Li, J.; Duan, Y.; Cao, H.; Zhao, Y. Study on the Combined Application of CFAR and Deep Learning in Ship Detection. J. Indian Soc. Remote Sens. 2018, 46, 1413–1421. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the IEEE International Conference on Computer Vision Workshops(ICCVW), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Wang, X.; Jiang, H.; Lin, K. Ship Detection in Remote Sensing Images Based on Improved YOLO Algorithm. J. B. Univ. Aeronaut. Astronaut. 2020, 46, 1184–1191. [Google Scholar]
- Zhang, D.; Wang, C.; Fu, Q. A Ship Critical Position Detection Algorithm Based on Improved YOLOv4 Tiny. Radio Eng. 2023, 53, 628–635. [Google Scholar]
- Li, J.; Zhang, D.; Fan, Y.; Yang, J. Lightweight Ship Target Detection Algorithm Based on Improved YOLOv5. Comput. App. 2023, 43, 923–929. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Ge, L. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Liu, F.; Chen, R.; Zhang, J.; Xing, K.; Liu, H.; Qin, J. R2YOLOX: A Lightweight Refined Anchor-Free Rotated Detector for Object Detection in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5632715. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A High Resolution Optical Satellite Image Dataset for Ship Recognition and Some New Baselines. In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods (ICPRAM), Porto, Portugal, 24–26 February 2017. [Google Scholar]
- Howard, D.; Roberts, S.; Brankin, R. Target Detection in SAR Imagery by Genetic Programming. Adv. Eng. Softw. 1999, 5, 303–311. [Google Scholar] [CrossRef]
- Marre, F. Automatic vessel detection system on SPOT-5 optical imagery: A neuro-genetic approach. In Proceedings of the Fourth Meeting of the DECLIMS Project, Toulouse, France, 10–12 June 2004. [Google Scholar]
- Bentes, C.; Velotto, D.; Lehner, S. Target Classification in Oceanographic SAR Images with Dep Neural Networks: Architecture and Initial Results. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015. [Google Scholar]
- Bentes, C.; Frost, A.; Velotto, D.; Tings, B. Ship-Iceberg Discrimination with Convolutional Neural Networks in High Resolution SAR Images. In Proceedings of the 11th European Conference on Synthetic Aperture Radar Electronic Proceedings, Hamburg, Germany, 6–9 June 2016. [Google Scholar]
- Fernandez, V.; Velotto, D.; Tings, B.; Van, H.; Bentes, C. Ship Classification in High and Very High Resolution Satellite SAR Imagery. In Proceedings of the Future Security 2016, Stuttgart, Germany, 29–30 September 2016. [Google Scholar]
- Liu, G.; Zhang, Y.; Zheng, X.; Sun, X. A New Method on Inshore Ship Detection in High-Resolution Satellite Images Using Shape and Context Information. IEEE Geosci. Remote Sens. Lett. 2013, 11, 617–621. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Zhang, X. TensorFlow: A System for Large-Scale Machine Learning. arXiv 2016, arXiv:1605.08695. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection of Remote Sensing Images from Google Earth in Complex Scenes Based on Multi-Scale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, J.; Weng, L.; Yang, Y. Rotated region based CNN for ship detection. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Liu, W.; Ma, L.; Chen, H. Arbitrary-Oriented Ship Detection Framework in Optical Remote-Sensing Images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 937–941. [Google Scholar] [CrossRef]
- Nie, M.; Zhang, J.; Zhang, X. Ship Segmentation and Orientation Estimation Using Keypoints Detection and Voting Mechanism in Remote Sensing Images. In Proceedings of the 16th International Symposium on Neural Networks (ISNN 2019), Moscow, Russia, 10–12 July 2019. [Google Scholar]
- Feng, Y.; Diao, W.; Sun, X.; Yan, M. Towards Automated Ship Detection and Category Recognition from High-Resolution Aerial Images. Remote Sens. 2019, 11, 1901. [Google Scholar] [CrossRef]
- Sun, J.; Zou, H.; Deng, Z.; Cao, X.; Li, M.; Ma, Q. Multiclass Oriented Ship Localization and Recognition in High Resolution Remote Sensing Images. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, C.; Tian, J. Precise Recognition of Ship Target Based on Generative Adversarial Network Assisted Learning. J. Intell. Syst. 2020, 15, 296–301. [Google Scholar]
- Li, M.; Sun, W.; Zhang, X.; Yao, L. Fine Grained Recognition of Ship Targets in Optical Satellite Remote Sensing Images Based on Global Local Feature Combination. Spacecraft Rec. Remote Sens. 2021, 42, 138–147. [Google Scholar]
- Zhou, Q. Research on Ship Detection Technology in Ocean Optical Remote Sensing Images. Master’s Thesis, Institute of Optoelectronics Technology, Chinese Academy of Sciences, Chengdu, China, 2021. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Huang, T. Unitbox: An Advanced Object Detection Network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 1 October 2016. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. [Google Scholar] [CrossRef]
- Zhang, Y.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IoU loss for Accurate Bounding Box Regression. arXiv 2022, arXiv:2101.08158. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Adaptive NMS: Refining Pedestrian Detection in A Crowd. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Navaneeth, B.; Bharat, S.; Rama, C.; Davis, L. Soft-NMS-Improving Object Detection with One Line of Code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 24–27 October 2017. [Google Scholar]
- Li, X.; Yu, L.; Chang, D.; Ma, Z.; Cao, J. Dual Cross-Entropy Loss for Small-Sample Fine-Grained Vehicle Classification. IEEE Trans. Vehi. Tech. 2019, 68, 4204–4212. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sünderhauf, N. VarifocalNet: An IoU-Aware Dense Object Detector. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- An, H.; Rodrigo, B.; Bernt, S. Learning Non-Maximum Suppression. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Jiang, S. Research on Ship Detection Method of Optical Remote Sensing Image Based on Deep Learning. Master’s Thesis, School of Electronic Information Engineering, Shanghai Jiao Tong University, Shanghai, China, 2019. [Google Scholar]
- Li, B.; Xie, X.; Wei, X.; Tang, W. Ship detection and classification from optical remote sensing images: A survey. Chin. J. Aeronaut. 2021, 343, 145–163. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Networks | Illustrate |
|---|---|
| YOLOX | Original network |
| YOLOX-BGNMS | Change NMS to BGNMS |
| YOLOX-ECA | Add ECA module to YOLOX Backbone |
| YOLOX-VFL | Change the confidence loss of YOLOX from CE to Varifocal Loss |
| YOLOX-EFIoU | Change the confidence loss of YOLOX from IoU Loss to EFIoU Loss |
| E2YOLOX | Add ECA module to YOLOX Backbone, and change the location loss from IoU Loss to EFIoU Loss |
| E2YOLOX-VFL | Add ECA module to YOLOX Backbone, change NMS to BG-NMS, change the confidence loss from CE to Varifocal Loss, and change the location loss from IoU Loss to EFIoU Loss |
| Module | YOLOX | BG-NMS | ECA | Varifocal Loss | EFIoU | mAP/% | |
|---|---|---|---|---|---|---|---|
| Model | |||||||
| YOLOX 1 | √ | × | × | × | × | 64.54 | |
| YOLOX 2 | √ | × | × | × | × | 64.82 | |
| YOLOX-BGNMS | √ | √ | × | × | × | 66.96 | |
| YOLOX-ECA | √ | × | √ | × | × | 68.87 | |
| YOLOX-VFL | √ | × | × | √ | × | 69.28 | |
| YOLOX-EFIoU | √ | × | × | × | √ | 70.27 | |
| E2YOLOX | √ | × | √ | × | √ | 70.64 | |
| E2YOLOX-VFL | √ | √ | √ | √ | √ | 73.82 | |
| Module | ECA | ECA | ECA | mAP/% | |
|---|---|---|---|---|---|
| Model | |||||
| YOLOX | × | × | × | 64.54 | |
| (80, 80) | √ | × | × | 66.36 | |
| (40, 40) | √ | √ | × | 67.13 | |
| (20, 20) | √ | √ | √ | 68.87 | |
| Module | EIoU | EFIoU | mAP/% | |
|---|---|---|---|---|
| Model | ||||
| YOLOX | × | × | 64.54 | |
| YOLOX-EIoU | × | √ | 67.57 | |
| YOLOX-EFIoU | × | √ | 70.27 | |
| Model | mAP/% | Parameter Quantity |
|---|---|---|
| Adding CBAM to the Backbone | 69.31 | 34.7 MB |
| Adding ECA to the Backbone | 68.87 | 34.3 MB |
| Adding ECA to the FPN | 61.75 | 55.2 MB |
| Model | mAP/% |
|---|---|
| E2YOLOX-VFL | 73.82 |
| SRBBS-Fast-RCNN | 60.77 |
| SRBBS-Fast-RCNN-R | 45.23 |
| RC1 | 51.0 |
| RC1 + Multi-NMS | 43.7 |
| Faster R-CNN | 40.5 |
| R-DFPN | 43.5 |
| R-DFPN + PSG97 | 71.0 |
| SHDRP9 | 74.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Q.; Wu, Y.; Yuan, Y. Ship Target Detection in Optical Remote Sensing Images Based on E2YOLOX-VFL. Remote Sens. 2024, 16, 340. https://doi.org/10.3390/rs16020340
Zhao Q, Wu Y, Yuan Y. Ship Target Detection in Optical Remote Sensing Images Based on E2YOLOX-VFL. Remote Sensing. 2024; 16(2):340. https://doi.org/10.3390/rs16020340
Chicago/Turabian StyleZhao, Qichang, Yiquan Wu, and Yubin Yuan. 2024. "Ship Target Detection in Optical Remote Sensing Images Based on E2YOLOX-VFL" Remote Sensing 16, no. 2: 340. https://doi.org/10.3390/rs16020340
APA StyleZhao, Q., Wu, Y., & Yuan, Y. (2024). Ship Target Detection in Optical Remote Sensing Images Based on E2YOLOX-VFL. Remote Sensing, 16(2), 340. https://doi.org/10.3390/rs16020340