



A Lightweight Building Extraction Approach for Contour Recovery in Complex Urban Environments




Abstract
:1. Introduction
- (1)
- We propose an advanced deep learning-based method for extracting urban buildings from high-resolution remote sensing images. In this study, we replaced the backbone network by adopting a lightweight model to address the issue of low computational efficiency in existing models. Additionally, we introduced an attention mechanism to enhance the focus on the spatial coordinate information of building contours at different locations in the image, aiming to alleviate the problem of missing architectural outlines.
- (2)
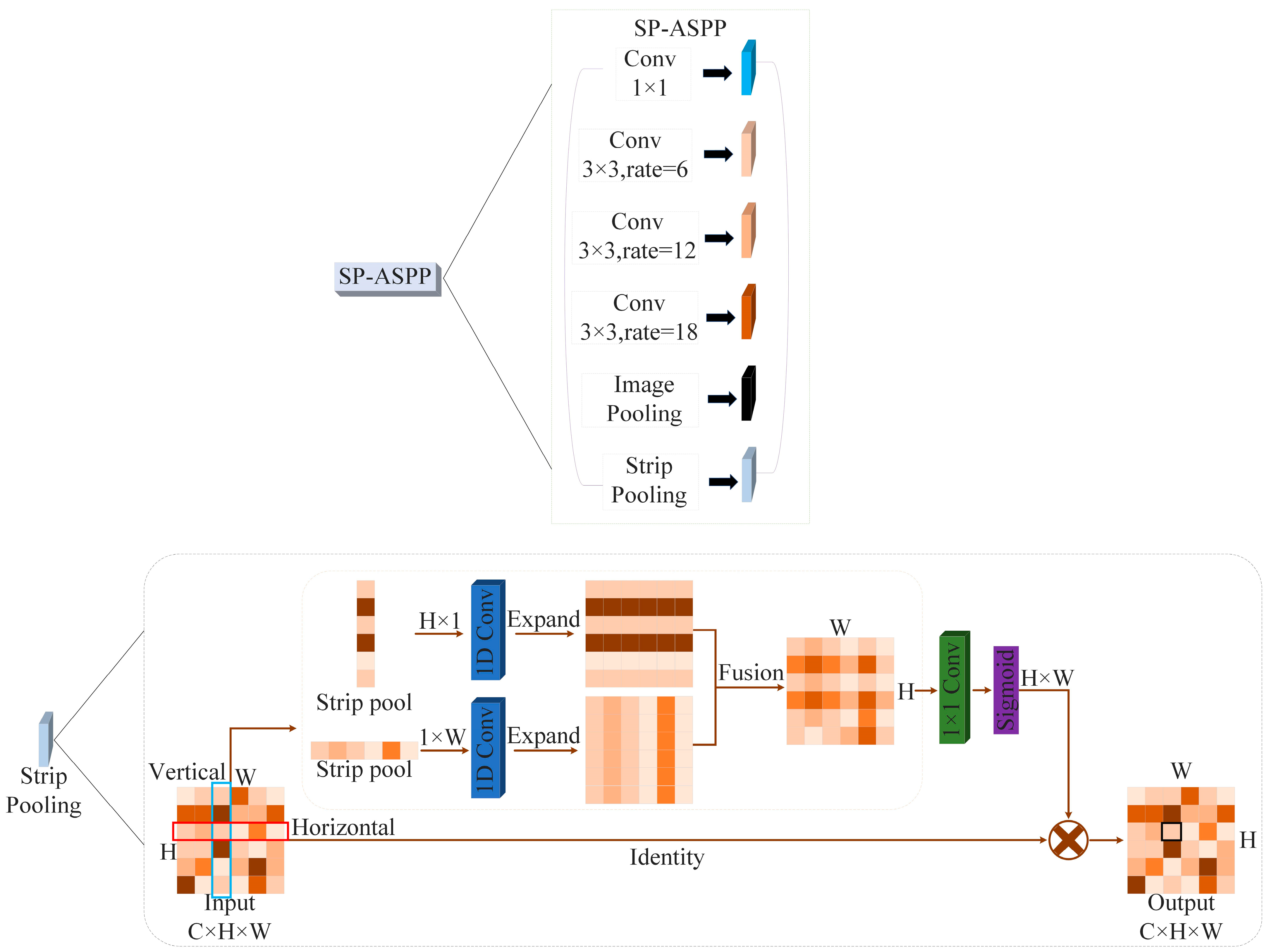
- Our improved network incorporates a fusion module that combines strip pooling with Atrous spatial pyramid pooling to introduce lateral context information to further recover building contour profiles by enhancing the network’s representation of building edge features. We validate the significant role of strip pooling in enhancing the feature extraction of urban buildings.
2. Methods
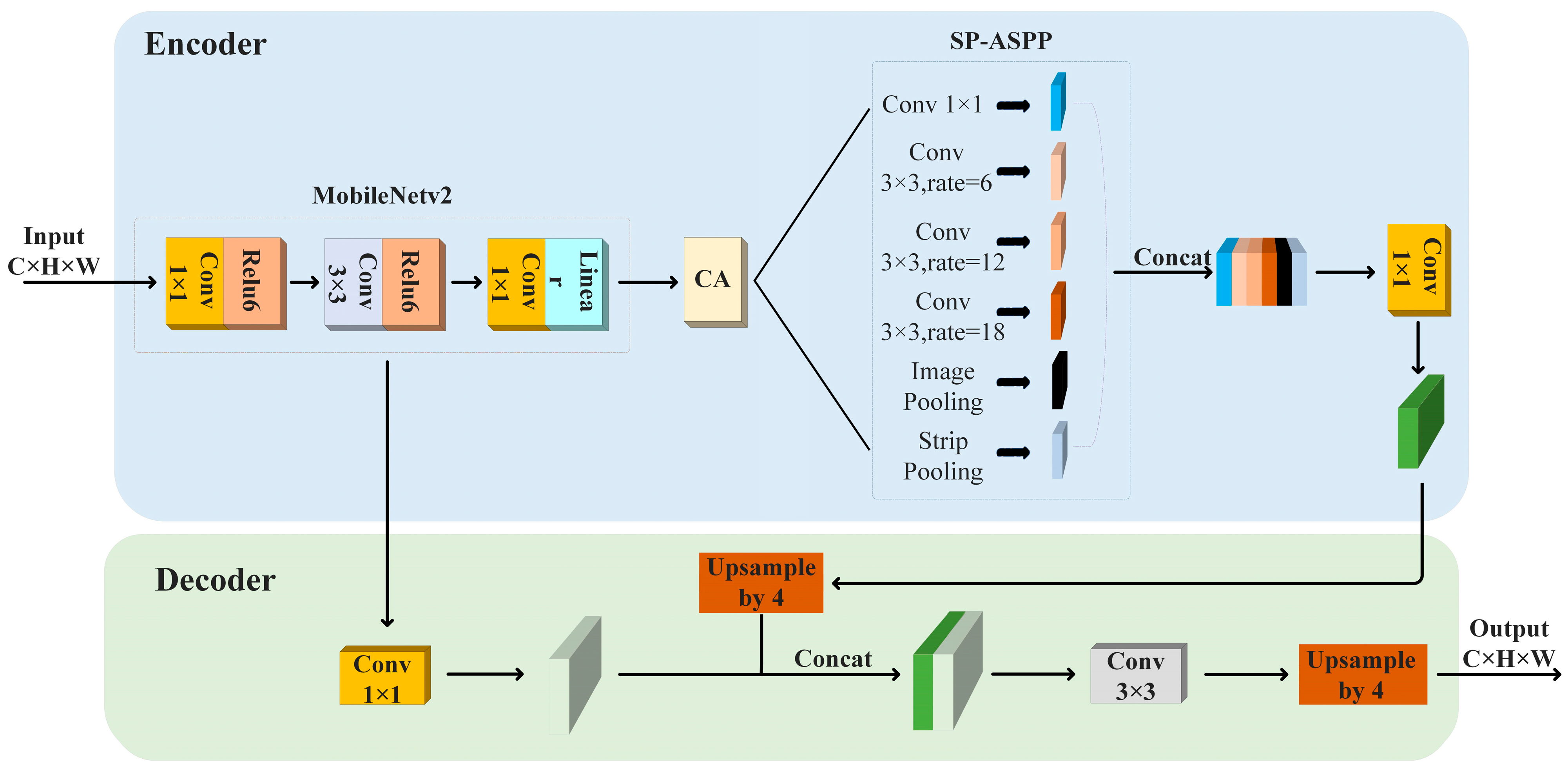
2.1. The Structure of the Network
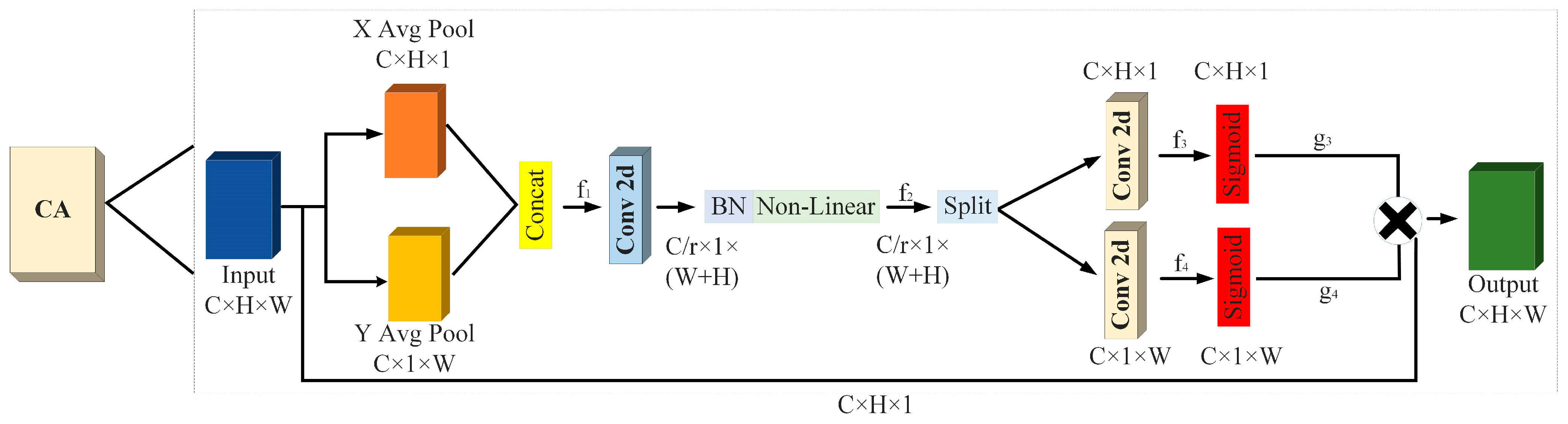
2.2. Coordinate Attention Mechanism
2.3. SP-ASPP Module
3. Experiment
3.1. Experimental Environment
3.2. Dataset
- (1)
- The primary dataset employed in this study is the publicly available Remote Sensing Image Dataset of Typical Urban Buildings in China [41], which was curated by China University of Geosciences. The dataset contains 7260 image area samples and a total of 63,886 buildings; four representative urban centers, Beijing, Shanghai, Shenzhen, and Wuhan, were selected as the data collection target areas. The original data were sourced from 19th-level satellite imagery provided by Google, with a ground resolution of 0.29 m. To ensure the dataset’s versatility, the selection of data regions considered diverse factors such as the inclusion of orthorectified and non-orthorectified image regions, areas with both sparse and dense distributions of buildings, and the incorporation of various building contour shapes. The dataset was partitioned into training, validation, and testing sets, following an 8:1:1 ratio, and the image dimensions were standardized to 500 × 500 pixels. The dataset was exported in the Pascal VOC data format. Sample images from the dataset are depicted in Figure 4.
- (2)
- The second dataset employed in this study is the Map Challenge Building Dataset [42]. The images within this dataset have dimensions of 300 × 300 pixels. It encompasses a total of 280,741 training samples, 60,697 testing samples, and 60,317 validation samples. For the purpose of this study, 6028 images were selected from this dataset. These images were divided into training, validation, and testing sets following an 8:1:1 ratio, and the data were exported in the Pascal VOC data format. Sample images from the dataset are depicted in Figure 5.
3.3. Evaluation Index
3.4. Ablation Experiment
3.5. Comparison with Other Algorithms
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rahmayanti, H.; Maulida, E.; Kamayana, E. The role of sustainable urban building in industry 4.0. J. Phys. Conf. Ser. 2019, 1387, 012050. [Google Scholar] [CrossRef]
- Huo, T.; Li, X.; Cai, W.; Zuo, J.; Jia, F.; Wei, H. Exploring the impact of urbanization on urban building carbon emissions in China: Evidence from a provincial panel data model. Sustain. Cities Soc. 2020, 56, 102068. [Google Scholar] [CrossRef]
- Lenjani, A.; Yeum, C.M.; Dyke, S.; Bilionis, I.A. Automated building image extraction from 360 panoramas for postdisaster evaluation. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 241–257. [Google Scholar] [CrossRef]
- Nop, S.; Thornton, A. Urban resilience building in modern development. Ecol. Soc. 2019, 24, 23. [Google Scholar] [CrossRef]
- Gao, X.; Nakatani, J.; Zhang, Q.; Huang, B.; Wang, T.; Moriguchi, Y. Dynamic material flow and stock analysis of residential buildings by integrating rural–urban land transition: A case of Shanghai. J. Clean. Prod. 2020, 253, 119941. [Google Scholar] [CrossRef]
- Li, W.; He, C.; Fang, J.; Zheng, J.; Fu, H.; Yu, L. Semantic segmentation-based building footprint extraction using very high-resolution satellite images and multi-source GIS data. Remote Sens. 2019, 11, 403. [Google Scholar] [CrossRef]
- Hazaymeh, K.; Almagbile, A. A cascaded data fusion approach for extracting the rooftops of buildings in heterogeneous urban fabric using high spatial resolution satellite imagery and elevation data. Egypt. J. Remote Sens. Space Sci. 2023, 26, 245–252. [Google Scholar] [CrossRef]
- Jiang, H.; Peng, M.; Zhong, Y.; Xie, H.; Hao, Z.; Lin, J.; Ma, X.; Hu, X. A survey on deep learning-based change detection from high-resolution remote sensing images. Remote Sens. 2022, 14, 1552. [Google Scholar] [CrossRef]
- Boonpook, W.; Tan, Y.; Xu, B. Deep learning-based multi-feature semantic segmentation in building extraction from images of UAV photogrammetry. Int. J. Remote Sens. 2021, 42, 1–19. [Google Scholar] [CrossRef]
- Liu, X.; Chen, Y.; Wang, C.; Tan, K.; Li, J. A lightweight building instance extraction method based on adaptive optimization of mask contour. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103420. [Google Scholar] [CrossRef]
- Chen, Z.; Luo, Y.; Wang, J.; Li, J.; Wang, C.; Li, D. DPENet: Dual-path extraction network based on CNN and transformer for accurate building and road extraction. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103510. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, Z.; Wang, B.; Li, S.; Liu, H.; Xu, D.; Ma, C. BOMSC-Net: Boundary optimization and multi-scale context awareness based building extraction from high-resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Ezugwu, A.E.; Abualigah, L.; Abuhaija, B.; Heming, J. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data. Inf. Sci. 2023, 622, 178–210. [Google Scholar] [CrossRef]
- Chandra, M.A.; Bedi, S.S. Survey on SVM and their application in image classification. Int. J. Inf. Technol. 2022, 13, 1–11. [Google Scholar] [CrossRef]
- Parmar, A.; Katariya, R.; Patel, V. A review on random forest: An ensemble classifier. In Proceedings of the International Conference on Intelligent Data Communication Technologies and Internet of Things (ICICI), Coimbatore, India, 7–8 August 2018; Springer: Cham, Switzerland, 2018; pp. 758–763. [Google Scholar]
- Gavankar, N.L.; Ghosh, S.K. Object based building footprint detection from high resolution multispectral satellite image using K-means clustering algorithm and shape parameters. Geocarto Int. 2019, 34, 626–643. [Google Scholar] [CrossRef]
- Turker, M.; Koc-San, D. Building extraction from high-resolution optical spaceborne images using the integration of support vector machine (SVM) classification, Hough transformation and perceptual grouping. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 58–69. [Google Scholar] [CrossRef]
- Liyan, C.; Hong, L.; Jianhua, W. Building extraction based on random forest and superpixel segmentation. Bull. Surv. Mapp. 2021, 0, 49–53. [Google Scholar]
- Hou, X.; Wang, P.; An, W. Multi-scale Residual Network for Building Extraction from Satellite Remote Sensing Images. In Proceedings of the IGARSS 2022-2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malausia, 17–22 July 2022; pp. 1348–1351. [Google Scholar]
- Sun, G.; Huang, H.; Zhang, A.; Li, F.; Zhao, H.; Fu, H. Fusion of multiscale convolutional neural networks for building extraction in very high-resolution images. Remote Sens. 2019, 11, 227. [Google Scholar] [CrossRef]
- Sirko, W.; Kashubin, S.; Ritter, M.; Annkah, A.; Bouchareb, Y.S.E.; Dauphin, Y.; Keysers, D.; Neumann, M.; Cisse, M.; Quinn, J. Continental-scale building detection from high resolution satellite imagery. arXiv 2021, arXiv:2107.12283. [Google Scholar]
- Guo, H.; Shi, Q.; Du, B.; Zhang, L.; Wang, D.; Ding, H. Scene-driven multitask parallel attention network for building extraction in high-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4287–4306. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Cui, W.; Jiang, H. Fully convolutional networks for building and road extraction: Preliminary results. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1591–1594. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Lin, H.; Hao, M.; Luo, W.; Yu, H.; Zheng, N. BEARNet: A novel buildings edge-aware refined network for building extraction from high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Atik, S.O.; Atik, M.E.; Ipbuker, C. Comparative research on different backbone architectures of DeepLabV3+ for building segmentation. J. Appl. Remote Sens. 2022, 16, 024510. [Google Scholar] [CrossRef]
- Shunping, J.I.; Shiqing, W.E.I. Building extraction via convolutional neural networks from an open remote sensing building dataset. Acta Geod. Cartogr. Sin. 2019, 48, 448. [Google Scholar]
- Xu, S.J.; Ouyang, P.Y.; Guo, X.Y.; Khan, T.M.; Duan, Z.X. Building segmentation in remote sensing image based on multiscale-feature fusion dilated convolution resnet. Guangxue Jingmi Gongcheng 2020, 28, 1588–1599. [Google Scholar] [CrossRef]
- Zhang, H.; Zhao, H.; Zhang, X. High-resolution image building extraction using U-net neural network. Remote Sens. Inf. 2020, 35, 143–150. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Le, Y.; Hui, W.; Shuo, L.I.; Xiangzhou, Y.; Dachuan, S.; Miao, T. Multi-source data building extraction method combined with DeepLabv3 architecture. Geomat. Spat. Inf. Technol. 2022, 43, 62–66. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4003–4012. [Google Scholar]
- Fang, F.; Wu, K.; Liu, Y.; Li, S.; Wan, B.; Chen, Y.; Zheng, D. A Coarse-to-Fine Contour Optimization Network for Extracting Building Instances from High-Resolution Remote Sensing Imagery. Remote Sens. 2021, 13, 3814. [Google Scholar] [CrossRef]
- Mohanty, S.P. Crowdai Mapping Challenge 2018: Baseline with Mask RCNN. GitHub Repository. 2018. Available online: https://github.com/crowdai/crowdai-mapping-challenge-mask-rcnn (accessed on 26 January 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | IoU (Building)/(%) | mIOU/(%) | PA/(%) | mPA/(%) |
|---|---|---|---|---|
| Deeplabv3plus | 75.61 | 84.47 | 88.11 | 91.63 |
| Deeplabv3plus + Mobilenetv2 | 74.97 | 84.13 | 86.07 | 91.25 |
| Deeplabv3plus + CA | 76.02 | 84.74 | 88.39 | 92.23 |
| Deeplabv3plus + SP-ASPP | 76.27 | 84.99 | 85.21 | 91.23 |
| All | 76.44 | 85.11 | 86.35 | 91.61 |
| Method | Gflops (GB) | Params (MB) | FPS/(f/s) |
|---|---|---|---|
| Deeplabv3plus | 166.84 | 54.71 | 40.64 |
| Deeplabv3plus + Mobilenetv2 | 6.26 | 2.06 | 137.53 |
| Deeplabv3plus + CA | 166.88 | 55.10 | 41.14 |
| Deeplabv3plus + SP-ASPP | 177.17 | 61.27 | 38.15 |
| All | 6.51 | 2.23 | 110.67 |
| Models | IoU (Building)/(%) | mIoU/(%) | PA/(%) | mPA/(%) |
|---|---|---|---|---|
| PSPNet(Mob) | 74.43 | 83.33 | 84.86 | 90.49 |
| PSPNet | 82.37 | 88.56 | 89.12 | 93.56 |
| U-Net(vgg) | 83.06 | 89.04 | 89.62 | 93.90 |
| U-Net(resnet50) | 83.48 | 89.31 | 90.61 | 94.12 |
| HRNetv2_w32 | 84.12 | 89.73 | 90.58 | 94.30 |
| Deeplabv3plus | 84.13 | 89.73 | 91.18 | 94.43 |
| HRNetv2_w48 | 84.40 | 89.93 | 90.86 | 94.37 |
| HRNetv2_w18 | 84.63 | 90.07 | 91.03 | 94.47 |
| Ours | 84.86 | 90.27 | 92.22 | 94.79 |
| Models | Gfloaps/(GB) | Params/(MB) | FPS/(Frame/s) |
|---|---|---|---|
| PSPNet(Mob) | 2.12 | 2.38 | 141.16 |
| PSPNet | 41.60 | 46.71 | 57.09 |
| U-Net(vgg) | 176.43 | 24.89 | 25.46 |
| U-Net(resnet50) | 71.31 | 43.93 | 70.97 |
| HRNetv2_w32 | 32.00 | 29.54 | 22.77 |
| Deeplabv3plus | 58.33 | 54.71 | 75.29 |
| HRNetv2_w48 | 66.17 | 65.85 | 20.10 |
| HRNetv2_w18 | 13.06 | 9.64 | 24.91 |
| Ours | 2.28 | 2.23 | 117.68 |
| Models | IoU (Building)/(%) | mIoU/(%) | PA/(%) | mPA/(%) |
|---|---|---|---|---|
| PSPNet(Mob) | 65.37 | 77.41 | 78.08 | 86.53 |
| PSPNet | 73.65 | 83.01 | 84.75 | 90.47 |
| U-Net(vgg) | 75.12 | 84.17 | 87.47 | 91.75 |
| U-Net(resnet50) | 75.38 | 84.51 | 83.86 | 90.57 |
| HRNetv2_w32 | 74.46 | 83.88 | 85.07 | 90.83 |
| Deeplabv3plus | 75.61 | 84.47 | 88.11 | 91.63 |
| HRNetv2_w48 | 76.02 | 84.86 | 85.63 | 91.29 |
| HRNetv2_w18 | 76.09 | 84.80 | 88.05 | 92.13 |
| Ours | 76.44 | 85.11 | 86.35 | 91.61 |
| Models | Gfloaps/(GB) | Params/(MB) | FPS/(Frame/s) |
|---|---|---|---|
| PSPNet(Mob) | 6.03 | 2.38 | 154.32 |
| PSPNet | 118.43 | 46.71 | 57.09 |
| U-Net(vgg) | 451.67 | 24.89 | 24.47 |
| U-Net(resnet50) | 184.10 | 43.93 | 35.25 |
| HRNetv2_w32 | 88.34 | 29.54 | 22.77 |
| Deeplabv3plus | 166.84 | 54.71 | 40.64 |
| HRNetv2_w48 | 182.61 | 65.85 | 21.01 |
| HRNetv2_w18 | 36.11 | 9.64 | 20.63 |
| Ours | 6.51 | 2.23 | 110.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Cheng, Y.; Wang, W.; Ren, Z.; Zhang, C.; Zhang, W. A Lightweight Building Extraction Approach for Contour Recovery in Complex Urban Environments. Remote Sens. 2024, 16, 740. https://doi.org/10.3390/rs16050740
He J, Cheng Y, Wang W, Ren Z, Zhang C, Zhang W. A Lightweight Building Extraction Approach for Contour Recovery in Complex Urban Environments. Remote Sensing. 2024; 16(5):740. https://doi.org/10.3390/rs16050740
Chicago/Turabian StyleHe, Jiaxin, Yong Cheng, Wei Wang, Zhoupeng Ren, Ce Zhang, and Wenjie Zhang. 2024. "A Lightweight Building Extraction Approach for Contour Recovery in Complex Urban Environments" Remote Sensing 16, no. 5: 740. https://doi.org/10.3390/rs16050740
APA StyleHe, J., Cheng, Y., Wang, W., Ren, Z., Zhang, C., & Zhang, W. (2024). A Lightweight Building Extraction Approach for Contour Recovery in Complex Urban Environments. Remote Sensing, 16(5), 740. https://doi.org/10.3390/rs16050740