


Fast Digital Orthophoto Generation: A Comparative Study of Explicit and Implicit Methods


Abstract
:1. Introduction
2. Related Work
2.1. DigitalOrthophoto Generation Methods
2.2. NeRF with Sparse Parametric Encodings
3. Method
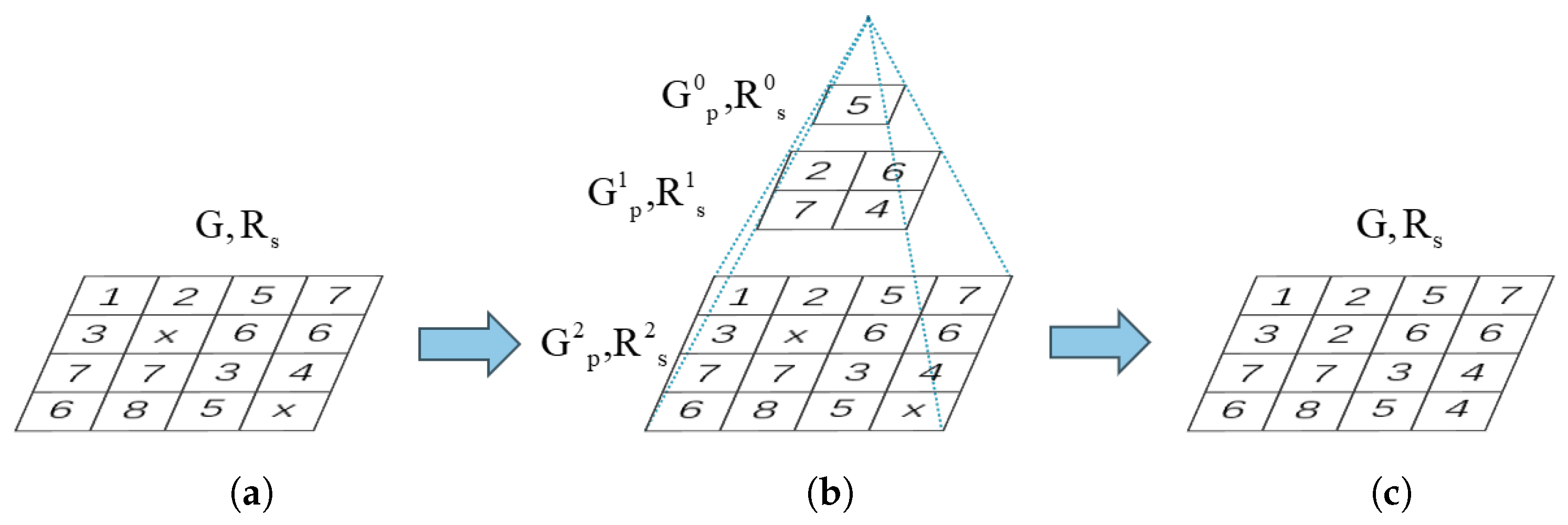
3.1. Explicit Method—TDM
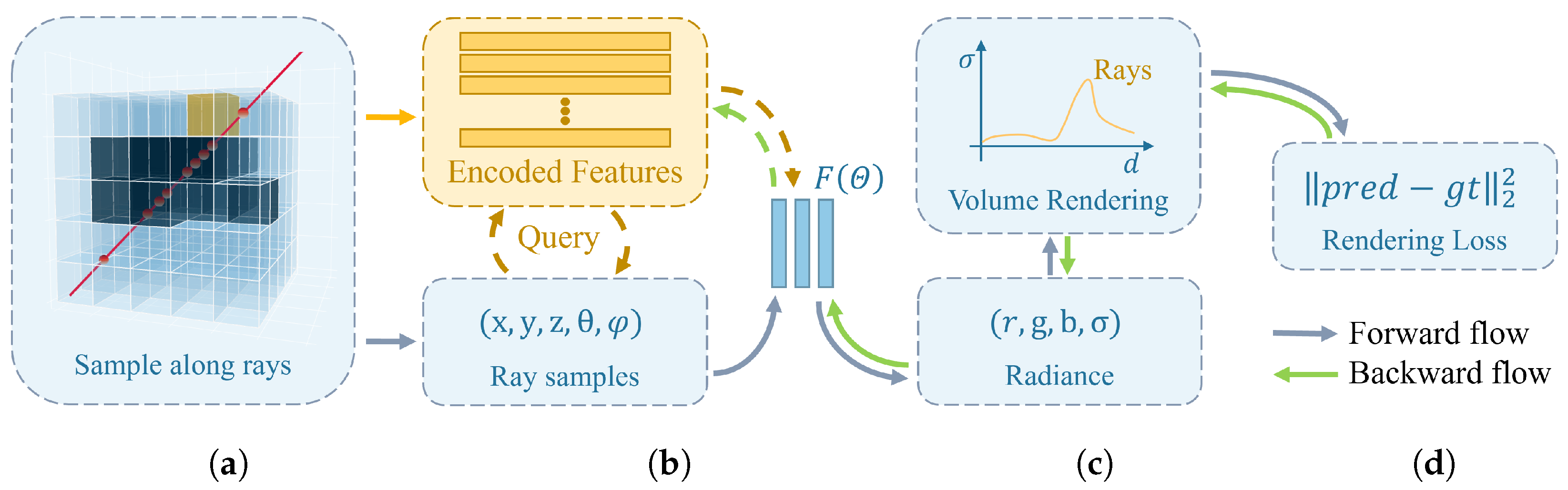
3.2. Implicit Method—Instant NGP
4. Experiments and Analysis
4.1. Test on Various Scenes
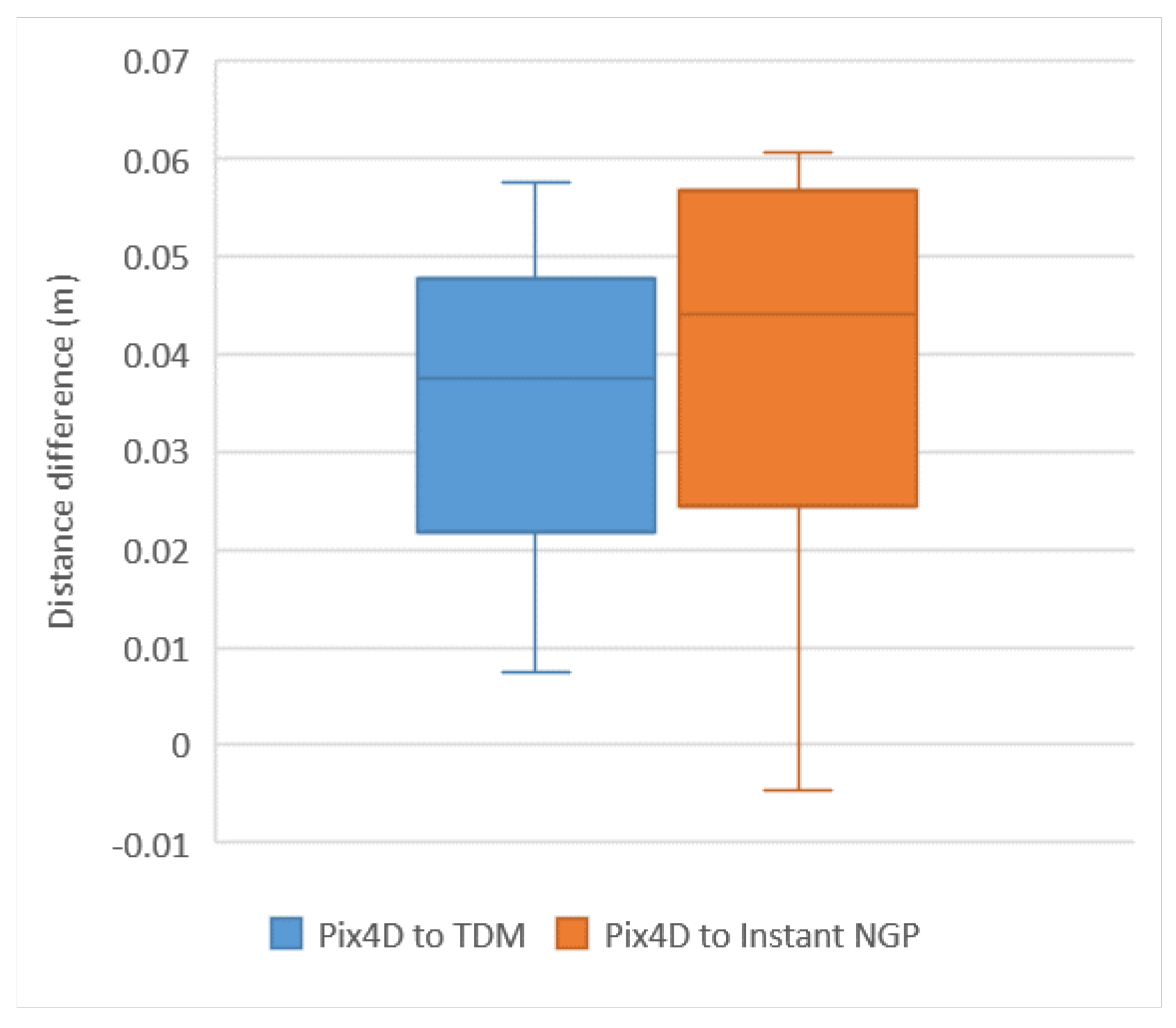
4.2. Evaluation of Accuracy
4.3. Evaluation of Efficiency
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Zheng, X.; Ai, G.; Zhang, Y.; Zuo, Y. Generating a high-precision true digital orthophoto map based on UAV images. ISPRS Int. J. Geo-Inf. 2018, 7, 333. [Google Scholar] [CrossRef]
- Lin, T.Y.; Lin, H.L.; Hou, C.W. Research on the production of 3D image cadastral map. In Proceedings of the 2018 IEEE International Conference on Applied System Invention (ICASI), Tokyo, Japan, 13–17 April 2018; pp. 259–262. [Google Scholar]
- Barazzetti, L.; Brumana, R.; Oreni, D.; Previtali, M.; Roncoroni, F. True-orthophoto generation from UAV images: Implementation of a combined photogrammetric and computer vision approach. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 2, 57–63. [Google Scholar] [CrossRef]
- Wang, Q.; Yan, L.; Sun, Y.; Cui, X.; Mortimer, H.; Li, Y. True orthophoto generation using line segment matches. Photogramm. Rec. 2018, 33, 113–130. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Zhao, Z.; Jiang, G.; Li, Y. A Novel Method for Digital Orthophoto Generation from Top View Constrained Dense Matching. Remote Sens. 2022, 15, 177. [Google Scholar] [CrossRef]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. (ToG) 2022, 41, 1–15. [Google Scholar] [CrossRef]
- DeWitt, B.A.; Wolf, P.R. Elements of Photogrammetry (with Applications in GIS); McGraw-Hill Higher Education: New York, NY, USA, 2000. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Shen, S. Accurate multiple view 3D reconstruction using patch-based stereo for large-scale scenes. IEEE Trans. Image Process. 2013, 22, 1901–1914. [Google Scholar] [CrossRef]
- Fang, K.; Zhang, J.; Tang, H.; Hu, X.; Yuan, H.; Wang, X.; An, P.; Ding, B. A quick and low-cost smartphone photogrammetry method for obtaining 3D particle size and shape. Eng. Geol. 2023, 322, 107170. [Google Scholar] [CrossRef]
- Tavani, S.; Granado, P.; Riccardi, U.; Seers, T.; Corradetti, A. Terrestrial SfM-MVS photogrammetry from smartphone sensors. Geomorphology 2020, 367, 107318. [Google Scholar] [CrossRef]
- Li, Z.; Wegner, J.D.; Lucchi, A. Topological map extraction from overhead images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1715–1724. [Google Scholar]
- Lin, Y.C.; Zhou, T.; Wang, T.; Crawford, M.; Habib, A. New orthophoto generation strategies from UAV and ground remote sensing platforms for high-throughput phenotyping. Remote Sens. 2021, 13, 860. [Google Scholar] [CrossRef]
- Zhao, Y.; Cheng, Y.; Zhang, X.; Xu, S.; Bu, S.; Jiang, H.; Han, P.; Li, K.; Wan, G. Real-time orthophoto mosaicing on mobile devices for sequential aerial images with low overlap. Remote Sens. 2020, 12, 3739. [Google Scholar] [CrossRef]
- Hood, J.; Ladner, L.; Champion, R. Image processing techniques for digital orthophotoquad production. Photogramm. Eng. Remote Sens. 1989, 55, 1323–1329. [Google Scholar]
- Fu, J. DOM generation from aerial images based on airborne position and orientation system. In Proceedings of the 2010 6th International Conference on Wireless Communications Networking and Mobile Computing (WiCOM), Chengdu, China, 23–25 September 2010; pp. 1–4. [Google Scholar]
- Sun, C.; Sun, M.; Chen, H.T. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5459–5469. [Google Scholar]
- Fridovich-Keil, S.; Yu, A.; Tancik, M.; Chen, Q.; Recht, B.; Kanazawa, A. Plenoxels: Radiance fields without neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5501–5510. [Google Scholar]
- Chen, A.; Xu, Z.; Geiger, A.; Yu, J.; Su, H. Tensorf: Tensorial radiance fields. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 333–350. [Google Scholar]
- Fridovich-Keil, S.; Meanti, G.; Warburg, F.R.; Recht, B.; Kanazawa, A. K-planes: Explicit radiance fields in space, time, and appearance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12479–12488. [Google Scholar]
- Hu, W.; Wang, Y.; Ma, L.; Yang, B.; Gao, L.; Liu, X.; Ma, Y. Tri-miprf: Tri-mip representation for efficient anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 19774–19783. [Google Scholar]
- Xu, Q.; Xu, Z.; Philip, J.; Bi, S.; Shu, Z.; Sunkavalli, K.; Neumann, U. Point-nerf: Point-based neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5438–5448. [Google Scholar]
- Yu, A.; Li, R.; Tancik, M.; Li, H.; Ng, R.; Kanazawa, A. Plenoctrees for real-time rendering of neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5752–5761. [Google Scholar]
- Kulhanek, J.; Sattler, T. Tetra-NeRF: Representing Neural Radiance Fields Using Tetrahedra. arXiv 2023, arXiv:2304.09987. [Google Scholar]
- Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5855–5864. [Google Scholar]
- Barron, J.T.; Mildenhall, B.; Verbin, D.; Srinivasan, P.P.; Hedman, P. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5470–5479. [Google Scholar]
- Li, R.; Tancik, M.; Kanazawa, A. Nerfacc: A general nerf acceleration toolbox. arXiv 2022, arXiv:2210.04847. [Google Scholar]
- Zhang, K.; Riegler, G.; Snavely, N.; Koltun, V. Nerf++: Analyzing and improving neural radiance fields. arXiv 2020, arXiv:2010.07492. [Google Scholar]
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3D gaussian splatting for real-time radiance field rendering. ACM Trans. Graph. (ToG) 2023, 42, 1–14. [Google Scholar] [CrossRef]
- Laine, S.; Hellsten, J.; Karras, T.; Seol, Y.; Lehtinen, J.; Aila, T. Modular Primitives for High-Performance Differentiable Rendering. ACM Trans. Graph. 2020, 39, 1–14. [Google Scholar] [CrossRef]
- Roessle, B.; Barron, J.T.; Mildenhall, B.; Srinivasan, P.P.; Nießner, M. Dense depth priors for neural radiance fields from sparse input views. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12892–12901. [Google Scholar]
- Deng, K.; Liu, A.; Zhu, J.Y.; Ramanan, D. Depth-supervised nerf: Fewer views and faster training for free. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12882–12891. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenes Method|Metric | Houses | Bridges | River | |||
|---|---|---|---|---|---|---|
| Brisque↓ | NIQE↓ | Brisque↓ | NIQE↓ | Brisque↓ | NIQE↓ | |
| TDM (cuda) | 12.96 | 2.77 | 7.88 | 2.33 | 12.90 | 5.01 |
| Instant NGP | 50.93 | 5.47 | 60.26 | 7.43 | 23.66 | 3.99 |
| Real Images | 6.72 | 1.67 | 5.91 | 1.72 | 7.74 | 1.74 |
| Scene Size (m) @Images | Method | |
|---|---|---|
| TDM | Instant NGP | |
| @ 78 | 36 s | 10,243 s |
| @ 130 | 60 s | 16,931 s |
| @ 256 | 88 s | 33,210 s |
| @ 281 | 103 s | 36,454 s |
| @ 333 | 129 s | 43,576 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, J.; Jiang, G.; Ding, W.; Zhao, Z. Fast Digital Orthophoto Generation: A Comparative Study of Explicit and Implicit Methods. Remote Sens. 2024, 16, 786. https://doi.org/10.3390/rs16050786
Lv J, Jiang G, Ding W, Zhao Z. Fast Digital Orthophoto Generation: A Comparative Study of Explicit and Implicit Methods. Remote Sensing. 2024; 16(5):786. https://doi.org/10.3390/rs16050786
Chicago/Turabian StyleLv, Jianlin, Guang Jiang, Wei Ding, and Zhihao Zhao. 2024. "Fast Digital Orthophoto Generation: A Comparative Study of Explicit and Implicit Methods" Remote Sensing 16, no. 5: 786. https://doi.org/10.3390/rs16050786
APA StyleLv, J., Jiang, G., Ding, W., & Zhao, Z. (2024). Fast Digital Orthophoto Generation: A Comparative Study of Explicit and Implicit Methods. Remote Sensing, 16(5), 786. https://doi.org/10.3390/rs16050786