


Vision through Obstacles—3D Geometric Reconstruction and Evaluation of Neural Radiance Fields (NeRFs)

Abstract
:1. Introduction
- (1)
- We introduce a new dataset named STELLA of real-world scenarios tackling transparent and non-transparent obstacles, occlusions and visibility constraints.
- (2)
- We evaluate the underlying geometry of NeRFs for reconstructing the occluded object parts behind obstacles by comparing point clouds in 3D space with respect to ground truth.
- (3)
- We propose a new approach for NeRFs geometry extraction in the form of a point cloud by voxelizing the density field and applying a 3D density-gradient based Canny edge detection filter to better constrain the geometric features.
2. Related Work
2.1. Multi-View Stereo
2.2. Neural Implicit Scene Reconstruction
2.3. Occlusion Benchmark Datasets
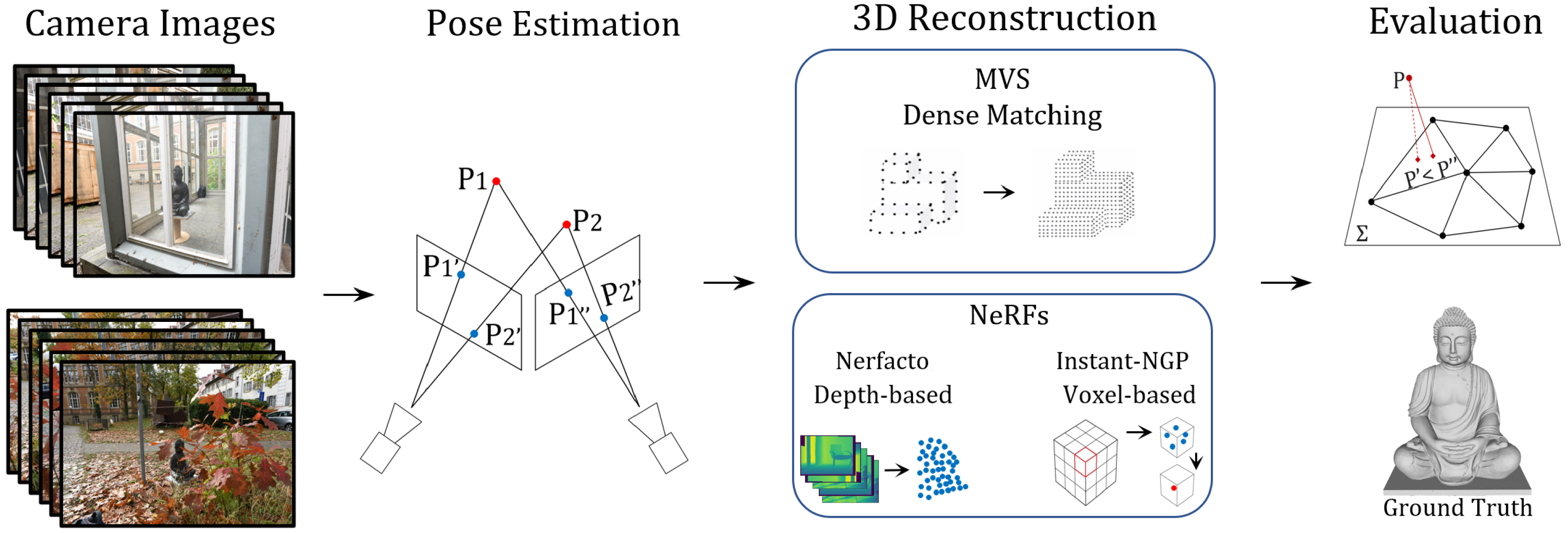
3. Methodology
3.1. Pose Estimation
3.2. Multi-View Stereo
3.3. Neural Radiance Fields
3.4. Evaluation Metrics
4. Datasets
5. Results
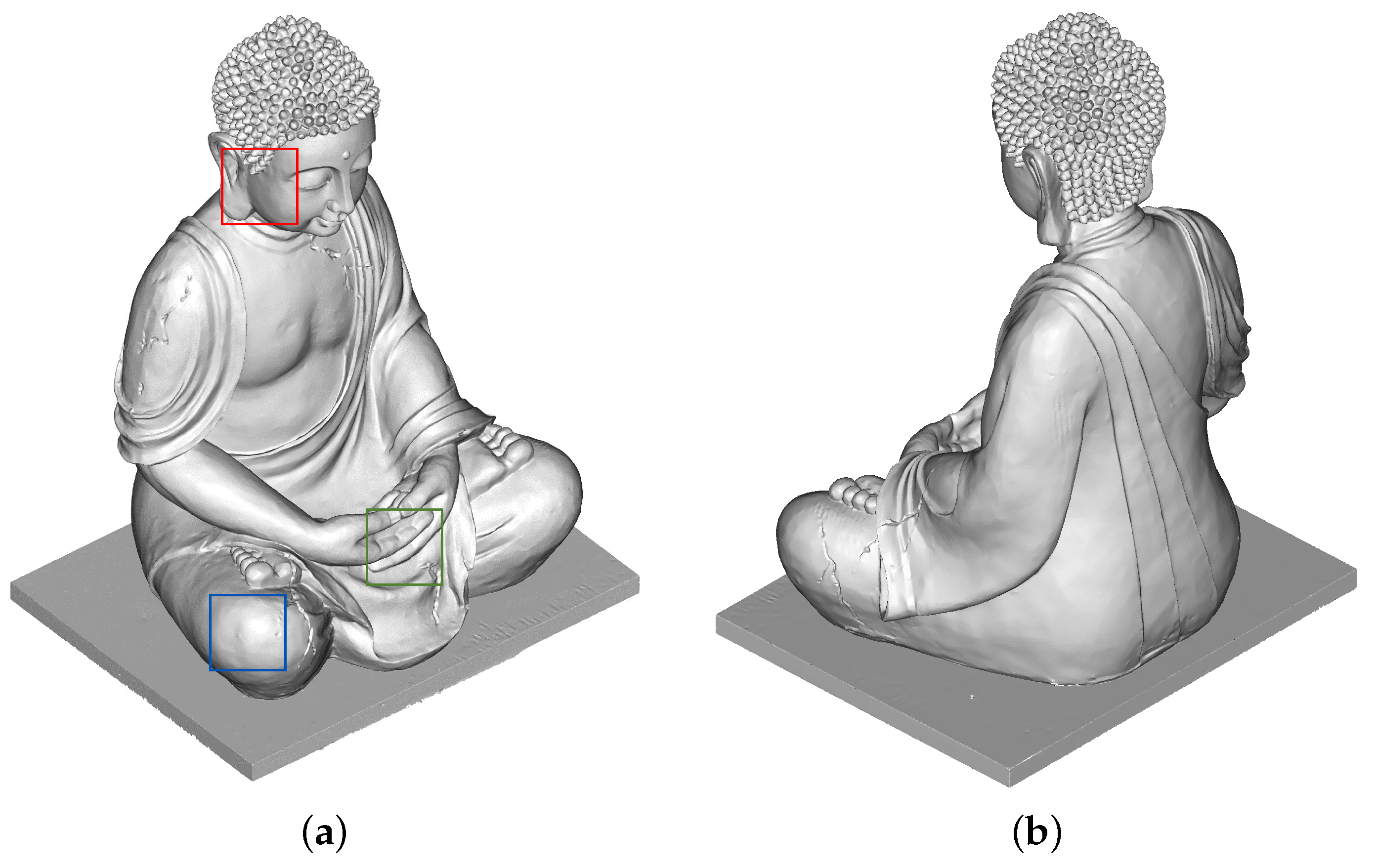
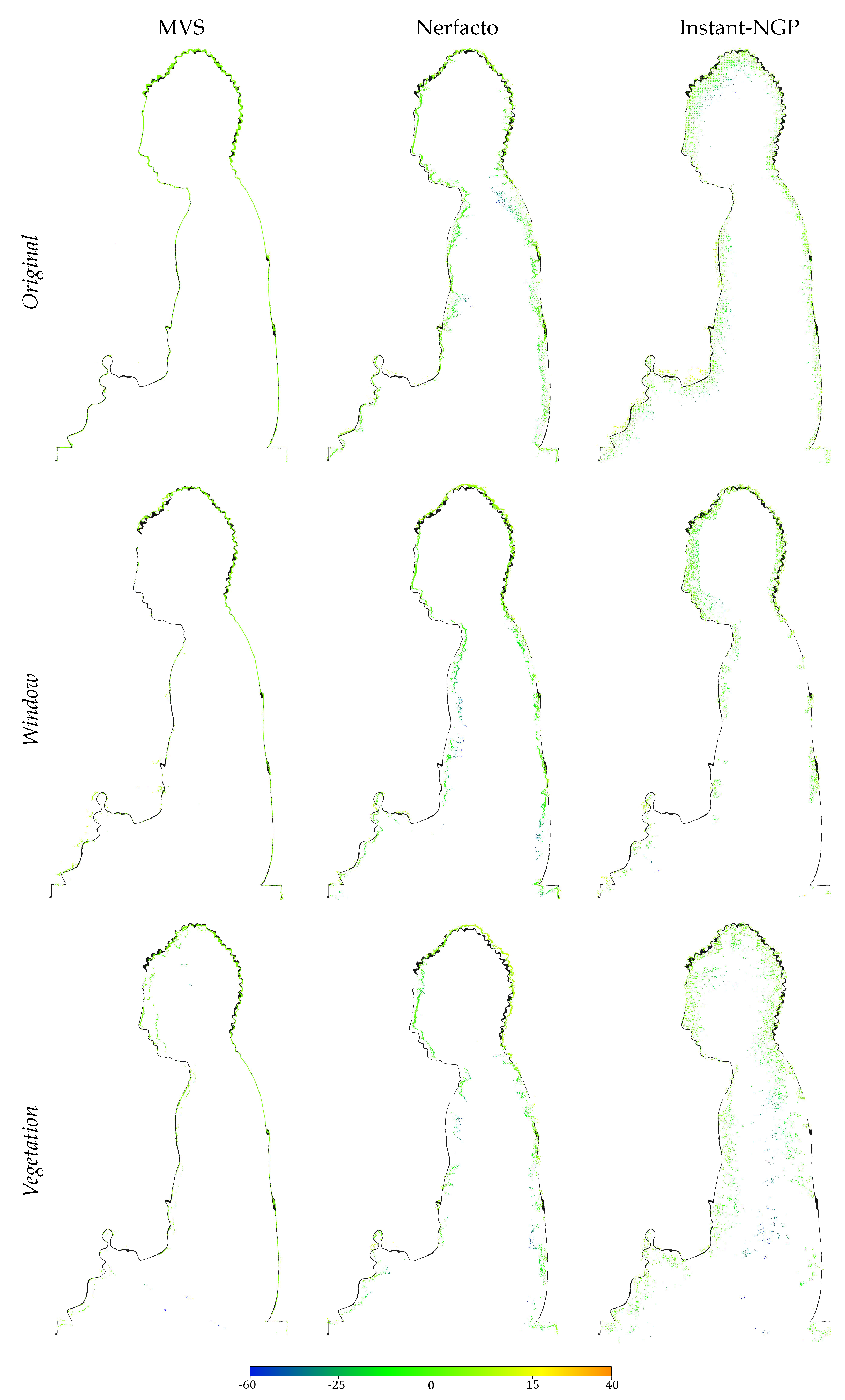
5.1. Qualitative Results


5.2. Quantitative Results
6. Discussion
6.1. Qualitative Evaluation
6.2. Quantitative Evaluation
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dumic, E.; da Silva Cruz, L.A. Subjective Quality Assessment of V-PCC-Compressed Dynamic Point Clouds Degraded by Packet Losses. Sensors 2023, 23, 5623. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Yang, Q.; Xu, Y.; Yang, L. Point cloud quality assessment: Dataset construction and learning-based no-reference metric. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–26. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Zheng, E.; Frahm, J.M.; Pollefeys, M. Pixelwise view selection for unstructured multi-view stereo. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 501–518. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Stathopoulou, E.K.; Battisti, R.; Cernea, D.; Remondino, F.; Georgopoulos, A. Semantically Derived Geometric Constraints for MVS Reconstruction of Textureless Areas. Remote Sens. 2021, 13, 1053. [Google Scholar] [CrossRef]
- Sitzmann, V.; Zollhöfer, M.; Wetzstein, G. Scene representation networks: Continuous 3D-structure-aware neural scene representations. In Proceedings of the Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Yan, Z.; Li, C.; Lee, G.H. Nerf-ds: Neural radiance fields for dynamic specular objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8285–8295. [Google Scholar]
- Zhang, X.; Yang, F.; Chang, M.; Qin, X. MG-MVSNet: Multiple granularities feature fusion network for multi-view stereo. Neurocomputing 2023, 528, 35–47. [Google Scholar] [CrossRef]
- Stathopoulou, E.K.; Rigon, S.; Battisti, R.; Remondino, F. Enhancing Geometric Edge Details in MVS Reconstruction. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2021, 43, 391–398. [Google Scholar] [CrossRef]
- Zhu, Q.; Min, C.; Wei, Z.; Chen, Y.; Wang, G. Deep learning for multi-view stereo via plane sweep: A survey. arXiv 2021, arXiv:2106.15328. [Google Scholar]
- Zhang, Y.; Zhu, J.; Lin, L. Multi-View Stereo Representation Revist: Region-Aware MVSNet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 17376–17385. [Google Scholar]
- Zhang, Z.; Peng, R.; Hu, Y.; Wang, R. GeoMVSNet: Learning Multi-View Stereo With Geometry Perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 21508–21518. [Google Scholar]
- Yamashita, K.; Enyo, Y.; Nobuhara, S.; Nishino, K. nLMVS-Net: Deep Non-Lambertian Multi-View Stereo. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 3037–3046. [Google Scholar]
- Ito, K.; Ito, T.; Aoki, T. PM-MVS: PatchMatch multi-view stereo. Mach. Vis. Appl. 2023, 34, 32. [Google Scholar] [CrossRef]
- Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5855–5864. [Google Scholar]
- Barron, J.T.; Mildenhall, B.; Verbin, D.; Srinivasan, P.P.; Hedman, P. Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5470–5479. [Google Scholar]
- Martin-Brualla, R.; Radwan, N.; Sajjadi, M.S.; Barron, J.T.; Dosovitskiy, A.; Duckworth, D. Nerf in the wild: Neural radiance fields for unconstrained photo collections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7210–7219. [Google Scholar]
- Jiang, Y.; Hedman, P.; Mildenhall, B.; Xu, D.; Barron, J.T.; Wang, Z.; Xue, T. AligNeRF: High-Fidelity Neural Radiance Fields via Alignment-Aware Training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 46–55. [Google Scholar]
- Zhang, X.; Kundu, A.; Funkhouser, T.; Guibas, L.; Su, H.; Genova, K. Nerflets: Local radiance fields for efficient structure-aware 3d scene representation from 2d supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8274–8284. [Google Scholar]
- Li, Z.; Müller, T.; Evans, A.; Taylor, R.H.; Unberath, M.; Liu, M.Y.; Lin, C.H. Neuralangelo: High-Fidelity Neural Surface Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8456–8465. [Google Scholar]
- Hu, B.; Huang, J.; Liu, Y.; Tai, Y.W.; Tang, C.K. NeRF-RPN: A general framework for object detection in NeRFs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 23528–23538. [Google Scholar]
- Xu, Q.; Xu, Z.; Philip, J.; Bi, S.; Shu, Z.; Sunkavalli, K.; Neumann, U. Point-nerf: Point-based neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5438–5448. [Google Scholar]
- Zimny, D.; Trzciński, T.; Spurek, P. Points2nerf: Generating neural radiance fields from 3D point cloud. arXiv 2022, arXiv:2206.01290. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. (ToG) 2022, 41, 1–15. [Google Scholar] [CrossRef]
- Guo, Y.C.; Kang, D.; Bao, L.; He, Y.; Zhang, S.H. NeRFReN: Neural Radiance Fields with Reflections. arXiv 2022, arXiv:cs.CV/2111.15234. [Google Scholar]
- Tong, J.; Muthu, S.; Maken, F.A.; Nguyen, C.; Li, H. Seeing Through the Glass: Neural 3D Reconstruction of Object Inside a Transparent Container. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12555–12564. [Google Scholar]
- Wang, D.; Zhang, T.; Süsstrunk, S. NEMTO: Neural Environment Matting for Novel View and Relighting Synthesis of Transparent Objects. arXiv 2023, arXiv:cs.CV/2303.11963. [Google Scholar]
- Li, Z.; Long, X.; Wang, Y.; Cao, T.; Wang, W.; Luo, F.; Xiao, C. NeTO:Neural Reconstruction of Transparent Objects with Self-Occlusion Aware Refraction-Tracing. arXiv 2023, arXiv:cs.CV/2303.11219. [Google Scholar]
- Zhan, X.; Pan, X.; Dai, B.; Liu, Z.; Lin, D.; Loy, C.C. Self-supervised scene de-occlusion. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3784–3792. [Google Scholar]
- Zhou, Q.; Wang, S.; Wang, Y.; Huang, Z.; Wang, X. Human de-occlusion: Invisible perception and recovery for humans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3691–3701. [Google Scholar]
- Zhang, S.; Xie, Y.; Wan, J.; Xia, H.; Li, S.Z.; Guo, G. Widerperson: A diverse dataset for dense pedestrian detection in the wild. IEEE Trans. Multimed. 2019, 22, 380–393. [Google Scholar] [CrossRef]
- Zhuo, J.; Chen, Z.; Lai, J.; Wang, G. Occluded person re-identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Jia, M.; Cheng, X.; Lu, S.; Zhang, J. Learning disentangled representation implicitly via transformer for occluded person re-identification. IEEE Trans. Multimed. 2022, 25, 1294–1305. [Google Scholar] [CrossRef]
- Ouyang, W.; Wang, X. A discriminative deep model for pedestrian detection with occlusion handling. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3258–3265. [Google Scholar]
- Lee, H.; Park, J. Instance-wise occlusion and depth orders in natural scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 21210–21221. [Google Scholar]
- Hodan, T.; Haluza, P.; Obdržálek, Š.; Matas, J.; Lourakis, M.; Zabulis, X. T-LESS: An RGB-D dataset for 6D pose estimation of texture-less objects. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 880–888. [Google Scholar]
- Tyree, S.; Tremblay, J.; To, T.; Cheng, J.; Mosier, T.; Smith, J.; Birchfield, S. 6-DoF pose estimation of household objects for robotic manipulation: An accessible dataset and benchmark. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 13081–13088. [Google Scholar]
- Blok, P.M.; van Henten, E.J.; van Evert, F.K.; Kootstra, G. Image-based size estimation of broccoli heads under varying degrees of occlusion. Biosyst. Eng. 2021, 208, 213–233. [Google Scholar] [CrossRef]
- Kaskman, R.; Zakharov, S.; Shugurov, I.; Ilic, S. Homebreweddb: RGB-D dataset for 6D pose estimation of 3D objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Koch, T.; Liebel, L.; Fraundorfer, F.; Korner, M. Evaluation of cnn-based single-image depth estimation methods. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Tancik, M.; Weber, E.; Ng, E.; Li, R.; Yi, B.; Wang, T.; Kristoffersen, A.; Austin, J.; Salahi, K.; Ahuja, A.; et al. Nerfstudio: A Modular Framework for Neural Radiance Field Development. In Proceedings of the ACM SIGGRAPH 2023 Conference Proceedings, Los Angeles, CA, USA, 6–10 August 2023. [Google Scholar] [CrossRef]
- Remondino, F.; Karami, A.; Yan, Z.; Mazzacca, G.; Rigon, S.; Qin, R. A critical analysis of nerf-based 3d reconstruction. Remote Sens. 2023, 15, 3585. [Google Scholar] [CrossRef]
- Jiang, H.; Li, R.; Sun, H.; Tai, Y.W.; Tang, C.K. Registering Neural Radiance Fields as 3D Density Images. arXiv 2023, arXiv:2305.12843. [Google Scholar]
- Petrovska, I.; Jäger, M.; Haitz, D.; Jutzi, B. Geometric Accuracy Analysis between Neural Radiance Fields (NeRFs) and Terrestrial laser scanning (TLS). Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2023, 48, 153–159. [Google Scholar] [CrossRef]
- Oechsle, M.; Peng, S.; Geiger, A. Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5589–5599. [Google Scholar]
- Jäger, M.; Jutzi, B. 3D Density-Gradient Based Edge Detection on Neural Radiance Fields (NeRFS) for Geometric Reconstruction. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2023, 48, 71–78. [Google Scholar] [CrossRef]
- Ni, H.; Lin, X.; Ning, X.; Zhang, J. Edge Detection and Feature Line Tracing in 3D-Point Clouds by Analyzing Geometric Properties of Neighborhoods. Remote Sens. 2016, 8, 710. [Google Scholar] [CrossRef]
- Mutneja, V. Methods of Image Edge Detection: A Review. J. Electr. Electron. Syst. 2015, 4, 5. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Proceedings of the Sensor Fusion IV: Control Paradigms and Data Structures; SPIE: Bellingham, WA, USA, 1992; Volume 1611, pp. 586–606. [Google Scholar]
- Hodson, T.O. Root-mean-square error (RMSE) or mean absolute error (MAE): When to use them or not. Geosci. Model Dev. 2022, 15, 5481–5487. [Google Scholar] [CrossRef]
- Püschel, J. Vergleich eines 3D-Modells zwischen Bundler und Breuckmann. Bachelor’s Thesis, Institute for Photogrammetry and Remote Sensing, Karlsruhe Institute of Technology—KIT, Karlsruhe, Germany, 2011. [Google Scholar]
- Jäger, M.; Landgraf, S.; Jutzi, B. Density Uncertainty Quantification with NeRF-Ensembles: Impact of Data and Scene Constraints. arXiv 2023, arXiv:2312.14664. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Method | Number of Points (Million) | Accuracy (mm) | Completeness (%) ↑ | ||
|---|---|---|---|---|---|---|
| Mean ↓ | SD ↓ | RMSE ↓ | ||||
| MVS | 16.48 | 0.02 | 0.40 | 0.41 | 88.96 | |
| Original | Nerfacto | 2.65 | 3.78 | 5.29 | 6.50 | 90.12 |
| Instant-NGP | 2.53 | 3.51 | 6.61 | 7.48 | 93.65 | |
| MVS | 2.66 | 0.19 | 2.26 | 2.27 | 65.26 | |
| Window | Nerfacto | 3.11 | −3.9 | 7.58 | 8.52 | 83.38 |
| Instant-NGP | 2.98 | −10.10 | 15.69 | 18.66 | 80.92 | |
| MVS | 1.92 | −0.95 | 3.36 | 3.49 | 76.94 | |
| Vegetation | Nerfacto | 1.72 | −3.43 | 7.76 | 8.49 | 69.59 |
| Instant-NGP | 2.16 | −7.82 | 14.89 | 16.82 | 83.99 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petrovska, I.; Jutzi, B. Vision through Obstacles—3D Geometric Reconstruction and Evaluation of Neural Radiance Fields (NeRFs). Remote Sens. 2024, 16, 1188. https://doi.org/10.3390/rs16071188
Petrovska I, Jutzi B. Vision through Obstacles—3D Geometric Reconstruction and Evaluation of Neural Radiance Fields (NeRFs). Remote Sensing. 2024; 16(7):1188. https://doi.org/10.3390/rs16071188
Chicago/Turabian StylePetrovska, Ivana, and Boris Jutzi. 2024. "Vision through Obstacles—3D Geometric Reconstruction and Evaluation of Neural Radiance Fields (NeRFs)" Remote Sensing 16, no. 7: 1188. https://doi.org/10.3390/rs16071188
APA StylePetrovska, I., & Jutzi, B. (2024). Vision through Obstacles—3D Geometric Reconstruction and Evaluation of Neural Radiance Fields (NeRFs). Remote Sensing, 16(7), 1188. https://doi.org/10.3390/rs16071188