



An Improved SAR Ship Classification Method Using Text-to-Image Generation-Based Data Augmentation and Squeeze and Excitation


Abstract
:1. Introduction
- We introduce a new SAR ship image generation module based on an LDM, which generates category-specific images by taking textual descriptions as input, thereby addressing the deficiency in data samples. This novel approach prevents skewed classification and overfitting during model training. In this way, the generated images effectively capture the structure and detailed features of SAR ships, providing valuable support for the training of the classification model.
- Recognizing that the Transformer model tends to neglect local information in SAR ship images and the presence of redundancy in its backbone network, we use T2T-ViT as the model’s backbone network in order to achieve locality through the T2T module while simultaneously reducing computational complexity. It turns out that this novel approach effectively captures subtle variations and features in SAR ship images, thereby enhancing the overall performance.
- In order to further improve the performance of T2T-ViT, we introduce the SE module. The dynamic weight adjustment provided by the SE module enables the network to better focus on crucial features for the current task, facilitating the capture and utilization of relevant feature information. This mechanism strengthens the network’s performance, making it more precise and reliable in handling SAR ship images.
2. Related Work
2.1. Traditional Classification Methods
2.2. Deep Learning-Based Classification Methods
3. Preliminaries
3.1. Vision Transformer (ViT)
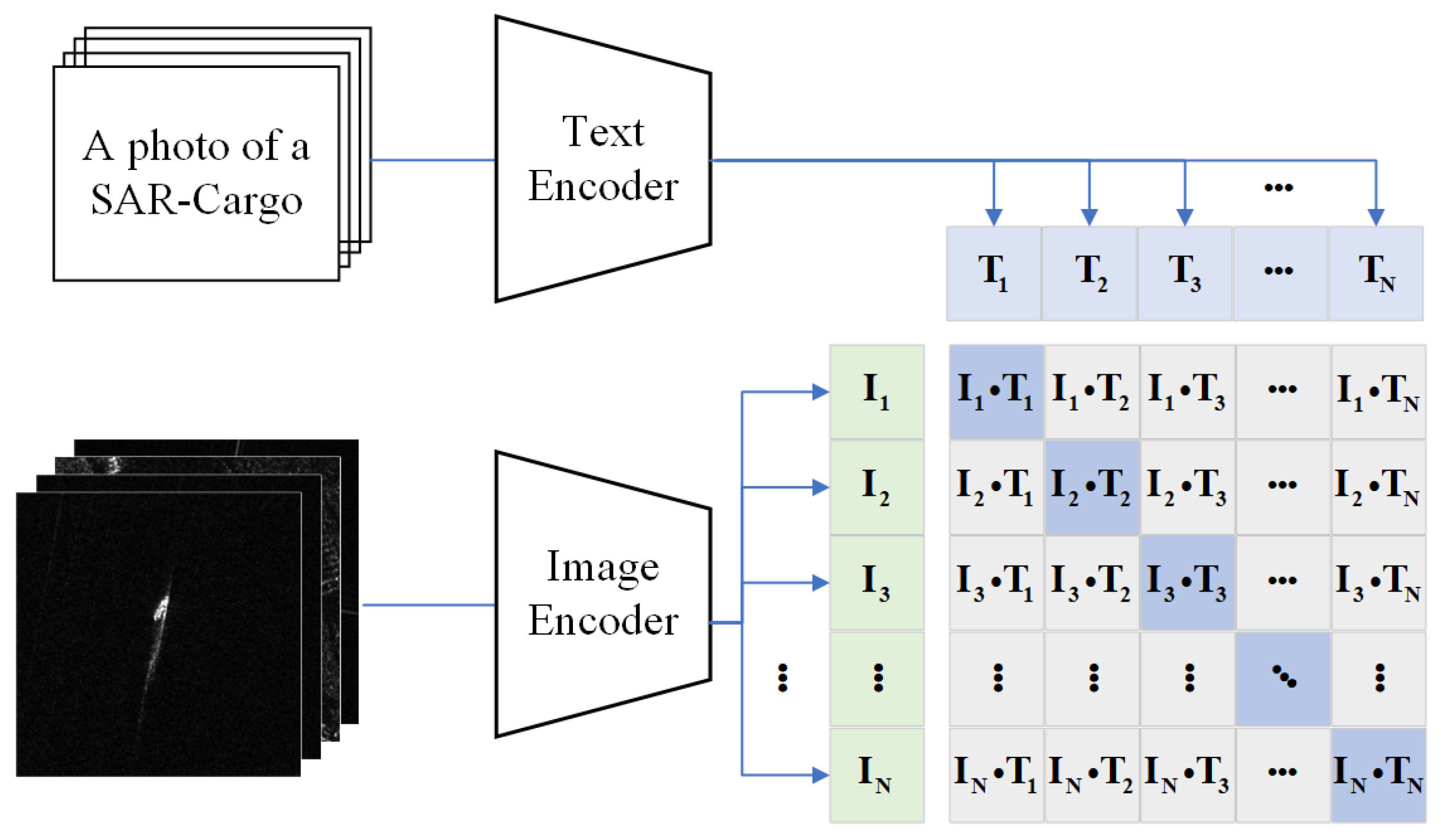
3.2. Contrastive Language–Image Pre-Training (CLIP)
4. Methods
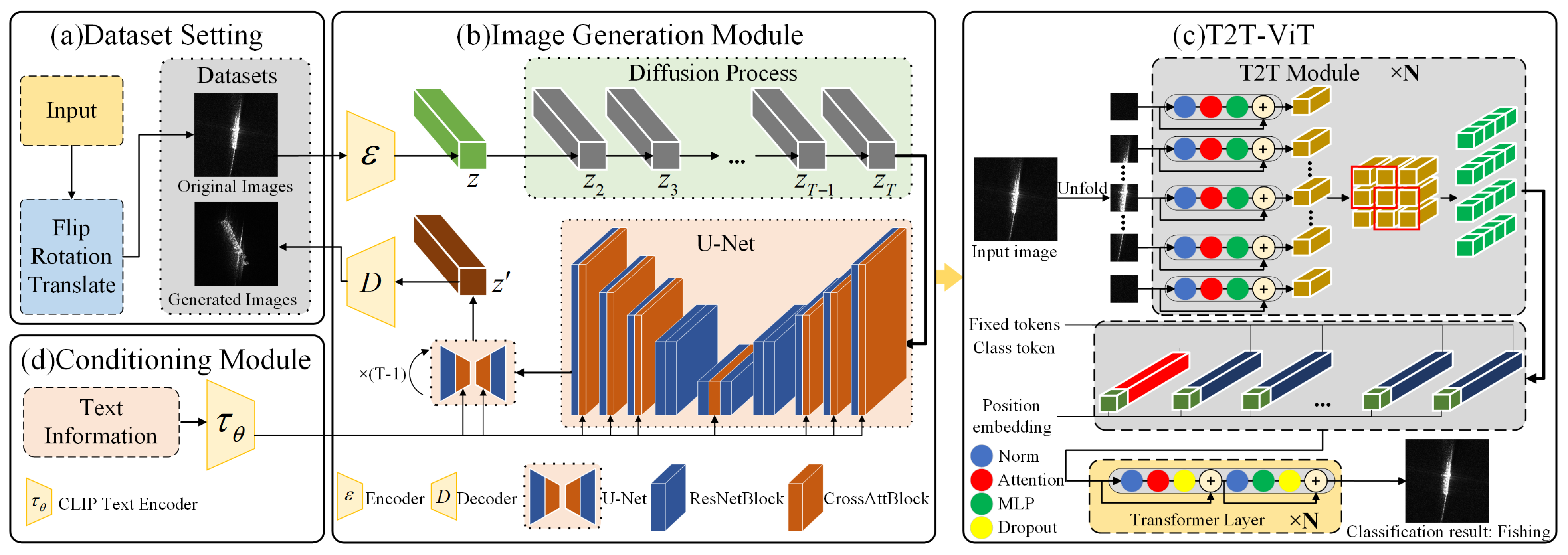
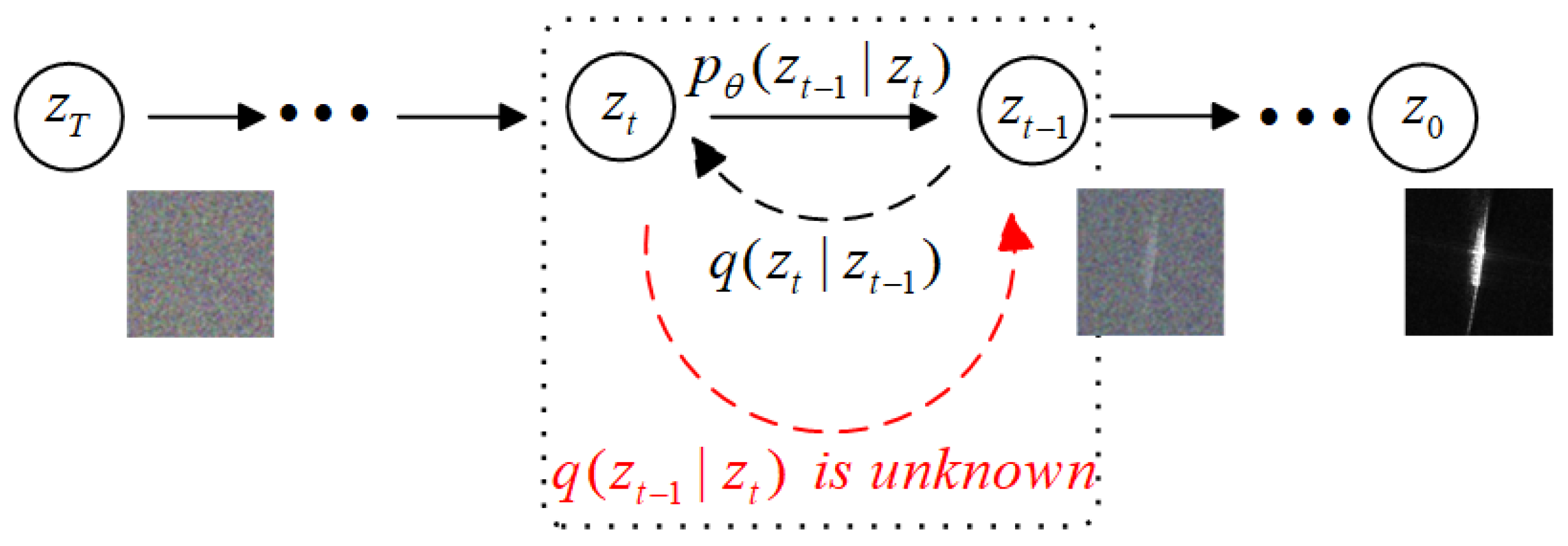
4.1. Image Generation Module
4.2. Tokens-to-Token Vision Transformers (T2T-ViT)
4.3. Squeeze-and-Excitation (SE) Module
5. Experiments and Performance Evaluation Results
5.1. Datasets and Settings
5.2. Performance Evaluation Indices
5.3. Image Generation Experiment
5.4. Performance Comparison Results
5.5. Performance Results
5.6. Expansion of Experiment to Four Categories
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Elachi, C. Spaceborne Imaging Radar: Geologic and Oceanographic Applications. Science 1980, 209, 1073–1082. [Google Scholar] [CrossRef] [PubMed]
- Petit, M.; Stretta, J.M.; Farrugio, H.; Wadsworth, A. Synthetic Aperture Radar Imaging of Sea Surface Life and Fishing Activities. IEEE Trans. Geosci. Remote Sens. 1992, 30, 1085–1089. [Google Scholar] [CrossRef]
- Born, G.H.; Dunne, J.A.; Lame, D.B. Seasat Mission Overview. Science 1979, 204, 1405–1406. [Google Scholar] [CrossRef] [PubMed]
- Iervolino, P.; Guida, R. A Novel Ship Detector Based on the Generalized-Likelihood Ratio Test for SAR Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3616–3630. [Google Scholar] [CrossRef]
- Yang, H.; Cao, Z.; Cui, Z.; Pi, Y. Saliency Detection of Targets in Polarimetric SAR Images Based on Globally Weighted Perturbation Filters. ISPRS J. Photogramm. Remote Sens. 2019, 147, 65–79. [Google Scholar] [CrossRef]
- Xie, T.; Zhang, W.; Yang, L.; Wang, Q.; Huang, J.; Yuan, N. Inshore Ship Detection Based on Level Set Method and Visual Saliency for SAR Images. Sensors 2018, 18, 3877. [Google Scholar] [CrossRef] [PubMed]
- Margarit, G.; Tabasco, A. Ship Classification in Single-Pol SAR Images Based on Fuzzy Logic. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3129–3138. [Google Scholar] [CrossRef]
- Lang, H.; Wu, S.; Xu, Y. Ship Classification in SAR Images Improved by AIS Knowledge Transfer. IEEE Geosci. Remote Sens. Lett. 2018, 15, 439–443. [Google Scholar] [CrossRef]
- Xu, Y.; Lang, H. Distribution Shift Metric Learning for Fine-Grained Ship Classification in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2276–2285. [Google Scholar] [CrossRef]
- Xuand, X.; Zhang, X.; Zhang, T. Multi-Scale SAR Ship Classification with Convolutional Neural Network. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021. [Google Scholar]
- Bentes, C.; Velotto, D.; Tings, B. Ship Classification in TerraSAR-X Images with Convolutional Neural Networks. IEEE J. Ocean. Eng. 2018, 43, 258–266. [Google Scholar] [CrossRef]
- He, J.; Wang, Y.; Liu, H. Ship Classification in Medium-Resolution SAR Images via Densely Connected Triplet CNNs Integrating Fisher Discrimination Regularized Metric Learning. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3022–3039. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, Z.; Sun, X.; Fu, K. SPAN: Strong Scattering Point Aware Network for Ship Detection and Classification in Large-Scale SAR Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1188–1204. [Google Scholar] [CrossRef]
- Shang, Y.; Pu, W.; Wu, C.; Liao, D.; Xu, X.; Wang, C.; Huang, Y.; Zhang, Y.; Wu, J.; Yang, J.; et al. HDSS-Net: A Novel Hierarchically Designed Network with Spherical Space Classifier for Ship Recognition in SAR Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5222420. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.; Tay, F.E.H.; Feng, J.; Yan, S. Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Gouaillier, V.; Gagnon, L. Ship Silhouette Recognition Using Principal Components Analysis. In Applications of Digital Image Processing XX; Tescher, A.G., Ed.; SPIE: Bellingham, WA, USA, 1997. [Google Scholar]
- Wang, B.; Binford, T.O. Generic, Model-Based Estimation and Detection of Peaks in Image Surfaces; Association for Computing Machinery: New York, NY, USA, 1996. [Google Scholar]
- Touzi, R.; Raney, R.K.; Charbonneau, F. On the Use of Permanent Symmetric Scatterers for Ship Characterization. IEEE Trans. Geosci. Remote Sens. 2004, 42, 2039–2045. [Google Scholar] [CrossRef]
- Margarit, G.; Mallorqui, J.J.; Fabregas, X. Single-Pass Polarimetric SAR Interferometry for Vessel Classification. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3494–3502. [Google Scholar] [CrossRef]
- Wang, J.; Xu, Y.; Zhang, X. The Active Appearance Model with Applications to SAR Target Recognition; Academy Publisher: Guwahati, India, 2009. [Google Scholar]
- Knapskog, A.O. Classification of Ships in TerraSAR-X Images Based on 3D Models and Silhouette Matching. In Proceedings of the European Conference on Synthetic Aperture Radar, Aachen, Germany, 7–10 June 2010; pp. 1–4. [Google Scholar]
- Chen, W.; Ji, K.; Xing, X.; Zou, H.; Sun, H. Ship Recognition in High Resolution SAR Imagery Based on Feature Selection. In Proceedings of the International Conference on Computer Vision in Remote Sensing, Xiamen, China, 16–18 December 2012. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-HRNet: A Lightweight High-Resolution Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 27 January 2024).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Houlsby, N. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Mozhdeh, G.; Xiang, R.; Jonathan, M. Cross-Attention is All You Need: Adapting Pretrained Transformers for Machine Translation. arXiv 2021, arXiv:2104.08771. [Google Scholar]
- Li, B.; Liu, B.; Huang, L.; Guo, W.; Zhang, Z.; Yu, W. OpenSARShip 2.0: A Large-Volume Dataset for Deeper Interpretation of Ship Targets in Sentinel-1 Imagery. In Proceedings of the SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017. [Google Scholar]
- Hou, X.; Ao, W.; Song, Q.; Lai, J.; Wang, H.; Xu, F. FUSAR-Ship: Building A High-Resolution SAR-AIS Matchup Dataset of Gaofen-3 for Ship Detection and Recognition. Sci. China Inf. Sci. 2020, 63, 140303. [Google Scholar] [CrossRef]
- Theodoridis, S. Stochastic Gradient Descent; Elsevier: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Zheng, H.; Hu, Z.; Yang, L.; Xu, A.; Zheng, M.; Zhang, C.; Li, K. Multifeature Collaborative Fusion Network with Deep Supervision for SAR Ship Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5212614. [Google Scholar] [CrossRef]
- Xu, Y.; Lang, H. Ship Classification in SAR Images with Geometric Transfer Metric Learning. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6799–6813. [Google Scholar] [CrossRef]
- Lang, H.; Wu, S. Ship Classification in Moderate-Resolution SAR Image by Naive Geometric Features-Combined Multiple Kernel Learning. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1765–1769. [Google Scholar] [CrossRef]
- Salerno, E. Using Low-Resolution SAR Scattering Features for Ship Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4509504. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support Vector Machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Desicion-Theoretic Generalization of on-Line Learning and an Application to Boosting. In Proceedings of the Computational Learning Theory, Santa Cruz, CA, USA, 5–8 July 1995. [Google Scholar]
- Cover, T.; Hart, P. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training Data-Efficient Image Transformers Distillation through Attention. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, C.; Liao, H.M.; Wu, Y.; Chen, P.; Hsieh, J.; Yeh, I. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Training | Testing | Total |
|---|---|---|---|
| Cargo | 558 | 178 | 736 |
| Fishing | 514 | 178 | 692 |
| Tug | 486 | 178 | 664 |
| Category | Training | Testing | Total |
|---|---|---|---|
| Bulk Carrier | 722 | 481 | 1203 |
| Cargo | 729 | 486 | 1215 |
| Fishing | 726 | 484 | 1210 |
| Tanker | 726 | 483 | 1209 |
| Other Ship | 784 | 522 | 1306 |
| Methods | OpenSARShip2.0 Dataset | FUSAR-Ship Dataset | Speed | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 Score (%) | Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) | Accuracy (%) | Train Time (s) | Test Time (ms) | |
| SVM [50] | 58.02 | 57.89 | 58.47 | 58.24 | 56.12 | 56.45 | 56.73 | 56.36 | - | 29.45 |
| Adaboost [51] | 49.73 | 49.52 | 49.27 | 49.64 | 39.92 | 40.27 | 40.31 | 40.28 | - | 21.57 |
| KNN [52] | 63.01 | 62.86 | 63.32 | 63.05 | 52.95 | 52.62 | 52.71 | 52.87 | - | 14.82 |
| LeNet [25] | 68.72 | 67.85 | 66.84 | 68.09 | 60.87 | 60.23 | 60.41 | 60.21 | 7 | 16.29 |
| AlexNet [26] | 67.12 | 66.63 | 66.41 | 66.49 | 61.65 | 62.03 | 61.22 | 62.18 | 22 | 39.08 |
| ResNet [30] | 59.21 | 58.40 | 58.09 | 59.04 | 60.41 | 61.27 | 60.80 | 61.41 | 60 | 127.03 |
| MobileNet [31] | 67.11 | 67.57 | 66.43 | 67.55 | 67.41 | 67.05 | 67.27 | 67.13 | 25 | 42.35 |
| DeiT [53] | 57.65 | 56.94 | 55.92 | 57.09 | 52.97 | 53.04 | 51.89 | 53.01 | 68 | 61.89 |
| DenseNet [54] | 67.17 | 66.49 | 66.54 | 66.48 | 67.81 | 68.96 | 68.05 | 69.22 | 74 | 48.56 |
| EfficientNet [55] | 71.52 | 71.73 | 71.32 | 72.16 | 70.59 | 70.43 | 70.27 | 70.69 | 37 | 29.32 |
| Shufflenet [56] | 73.58 | 73.41 | 73.12 | 73.41 | 71.29 | 71.21 | 71.34 | 71.36 | 26 | 45.60 |
| CSPNet [57] | 70.08 | 70.49 | 69.40 | 69.88 | 70.40 | 70.23 | 70.28 | 70.58 | 94 | 42.34 |
| Proposed method | 53 | 51.37 | ||||||||
| Backbone | Image Generation Module | SE Module | Accuracy (%) |
|---|---|---|---|
| ViT | 64.89 | ||
| T2T-ViT | 72.13 | ||
| T2T-ViT | ✓ | 74.02 | |
| T2T-ViT | ✓ | 73.59 | |
| T2T-ViT | ✓ | ✓ | 74.46 |
| Image Generation Module | Category | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| × | Cargo | 79.54 | 79.81 | 79.67 |
| Fishing | 68.42 | 60.94 | 64.46 | |
| Tug | 66.18 | 72.58 | 69.23 | |
| ✓ | Cargo | 79.79 | 82.25 | 81.01 |
| Fishing | 72.94 | 65.42 | 68.98 | |
| Tug | 69.66 | 74.19 | 71.85 |
| Method | Category | Precision (%) | Recall (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| T2T-ViT | Cargo | 67.18 | 60.79 | 63.83 | 59.03 |
| Fishing | 56.83 | 63.92 | 60.17 | ||
| Tug | 58.32 | 50.32 | 54.03 | ||
| Tanker | 54.46 | 57.52 | 55.95 | ||
| Proposed method | Cargo | 68.06 | 61.25 | 64.47 | 60.26 |
| Fishing | 57.14 | 65.03 | 60.82 | ||
| Tug | 59.26 | 51.61 | 55.17 | ||
| Tanker | 57.65 | 61.25 | 59.39 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Qi, Y.; Mathiopoulos, P.T.; Zhao, C.; Mazhar, S. An Improved SAR Ship Classification Method Using Text-to-Image Generation-Based Data Augmentation and Squeeze and Excitation. Remote Sens. 2024, 16, 1299. https://doi.org/10.3390/rs16071299
Wang L, Qi Y, Mathiopoulos PT, Zhao C, Mazhar S. An Improved SAR Ship Classification Method Using Text-to-Image Generation-Based Data Augmentation and Squeeze and Excitation. Remote Sensing. 2024; 16(7):1299. https://doi.org/10.3390/rs16071299
Chicago/Turabian StyleWang, Lu, Yuhang Qi, P. Takis Mathiopoulos, Chunhui Zhao, and Suleman Mazhar. 2024. "An Improved SAR Ship Classification Method Using Text-to-Image Generation-Based Data Augmentation and Squeeze and Excitation" Remote Sensing 16, no. 7: 1299. https://doi.org/10.3390/rs16071299
APA StyleWang, L., Qi, Y., Mathiopoulos, P. T., Zhao, C., & Mazhar, S. (2024). An Improved SAR Ship Classification Method Using Text-to-Image Generation-Based Data Augmentation and Squeeze and Excitation. Remote Sensing, 16(7), 1299. https://doi.org/10.3390/rs16071299