1. Introduction
In contemporary warfare, electronic countermeasure technology has emerged as the primary defense against information warfare. The electromagnetic environment of the battlefield has become increasingly complex due to the continuous development and widespread use of new radar systems [
1]. As a crucial aspect of electronic reconnaissance, radar individual identification has garnered significant attention from scholars [
1,
2,
3,
4,
5,
6]. This technology relies on the distinctive individual features of radar signals to accurately identify different radar transmitters in complex environments [
7].
Radar emitter individual identification is known as specific emitter identification (SEI) or fingerprint identification [
8], which is an advanced task in radar signal identification in addition to radar signal model identification, type identification, and waveform identification [
9,
10]. Specifically, it refers to analyzing and processing the radar signals received by the receiver; extracting the unique fingerprint features in the signal due to personal reasons such as the equipment platform, etc.; and using it to distinguish and judge which radar individual the received signal belongs to [
11]. Unlike radar signal type and model identification, the great difficulty and challenge in SEI is that radars of the same model can still be correctly distinguished when they emit the same type of radar signal with the same parameters [
12], which relies on the following characteristics of the fingerprint features: (1) uniqueness—the fingerprint features must be unique for each radar individual; (2) stability—each radar’s fingerprint features must be invariable and in a period of observation without significant changes and fluctuations; and (3) extractability—the fingerprint feature extraction method should be able to use the existing technical means from the limited reception signal detection and extraction. Therefore, the key to radar emitter individual identification can be summarized as the individual feature generation principle, feature extraction method, and identification algorithm [
13,
14].
Fingerprint features can reflect the characteristics of different radars extracted from multiple dimensions such as time, frequency, spatial, energy, and transform domain. These features mainly arise from the Unintentional Modulation on Pulse (UMOP) caused by the nonlinear components, such as transmitter tubes, crystal oscillators, and power amplifiers, in the radar transmitter equipment during transmission, their device aging and tendency to be influenced by noise, temperature, and humidity in the environment [
15,
16]. UMOP is the inherent property of radar individuals, and it cannot be prevented and eliminated, so in recent years, many researchers have investigated various characteristics of UMOP. Carroll T L [
17] established a radar power amplifier model, constructed a nonlinear mechanical system, and used spatial analysis to distinguish radar individuals. D. Xu [
18] studied the working principle of a self-excited oscillation-type transmitter, constructed a radar RF oscillator model, simulated the physical processes of free oscillation and controlled oscillation, extracted the middle pulse envelope feature quantity, and designed a fingerprint feature identification method to address the shortcomings of envelope rising edge and envelope trailing edge delay measurement methods in traditional individual features. S. Yu [
1] introduced a method for radar emitter individual identification that combines variational mode decomposition (VMD) with multiple image features. The process involves decomposing the radar signal using VMD, extracting features from the modal components to create VMD–Hilbert and VMD–envelope spectra, and then employing a SEResNet50-based network for feature fusion and recognition. L. Ding [
19] developed a deep-learning-based SEI method that leverages the bispectrum of steady-state signals for feature extraction by applying supervised dimensionality reduction on the bispectrum followed by a Convolutional Neural Network (CNN) which can efficiently identify specific emitters, enhancing identification performance through comprehensive feature analysis. Chen Taowei et al. [
20] established a phase noise model for radar transmitters based on sinusoidal signals and then used bispectral analysis to distinguish the differences between different radar individuals. Based on this, Wang Lei [
21] used fuzzy functions to analyze the phase noise and various unique parasitic signals generated during transmitter emission and use it as a feature to aid recognition. M. Hua [
6] proposed an improved deep learning-based SEI method using a signal feature embedded knowledge graph composed of universal features. Kawalec [
22] et al., systematically analyzed the time domain waveforms of radar signals and obtained the fine fingerprint features of pulse envelopes by demodulating them, including pulse width, envelope rising edge, trailing edge, envelope top drop, etc. The research on fingerprint features and their extraction methods is very developed; however, the design of classification algorithms for different scenarios and problems, which is the focus of this paper, still deserves extensive research.
Research on classification algorithms for SEI is mainly divided into two types: (1) designing classifiers based on extracted fingerprint features, including machine learning methods such as clustering, K-nearest neighbor (KNN), Support Vector Machines (SVMs), and decision trees, among others, and (2) deep learning-based recognition methods, including deep self-encoders and CNNs. Y. Zhong [
14] introduced a novel multimodal deep learning model that leverages diverse signal feature extraction techniques and deep network branches for independent processing. The model integrates these branches’ outputs through a fully connected layer, enhancing its analytical capabilities. Wu, LW, and colleagues [
23] investigated individual differences in pulse envelopes, modeling four types of pulse envelopes. They proposed an intrinsic mode function distinct native attribute feature extraction algorithm and a joint feature selection algorithm as the final SEI technique to identify specific emitters by leveraging individual features alongside the pulse envelope. Shieh C S [
24] used pulse repetition period (PRI), carrier frequency information, and pulse width as inputs to build a vector neural network structure to classify a radar individual. Kong M, Zhang J, Liu W et al. [
25] relied on deep neural networks to extract deep features in the signal, ensuring the integrity of feature information, solving the problem of subjectivity when manually extracting features, and taking the bispectral features of radar signals as the input. Jialiang Gong [
26] introduced an unsupervised SEI framework utilizing information-maximized generative adversarial networks combined with radio frequency fingerprint embedding. The framework was enhanced by embedding a gray histogram derived from the signal’s bispectrum and incorporating a priori statistical characteristics of wireless channels into a structured multimodal latent vector to improve GAN quality. However, all these classification methods have common drawbacks: the learning of fingerprint features by the classifier relies on a single pattern of data input, which is highly susceptible to noise. Both manual extractions of fingerprint features and deep learning algorithms that learn individual information from emitter signals rely on high-quality data with a high SNR. In practical applications, when reconnaissance data becomes heavily contaminated, fingerprint features may be obscured by noise at low SNRs. Relying solely on data input from a single modality can result in a sudden drop in classifier recognition accuracy. Moreover, high-quality signals are often scarce, requiring high-precision reconnaissance equipment for extended periods of measurement and accumulation, which can be costly.
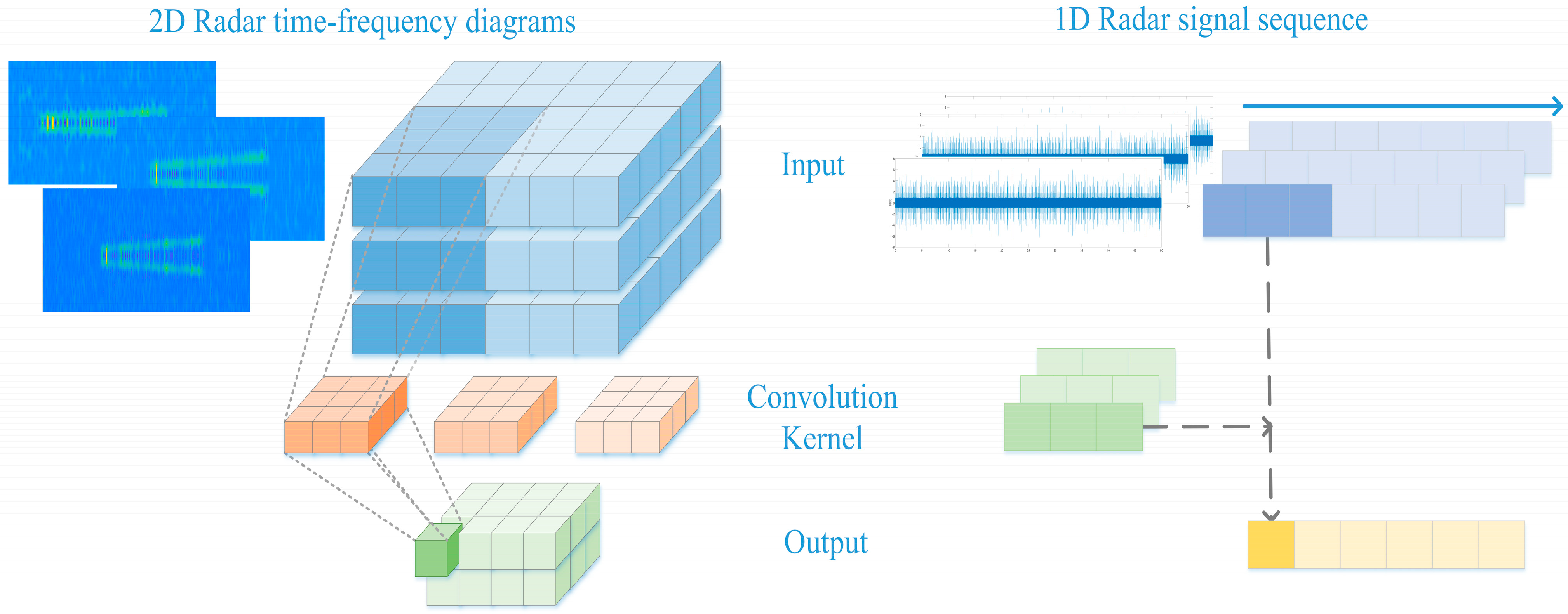
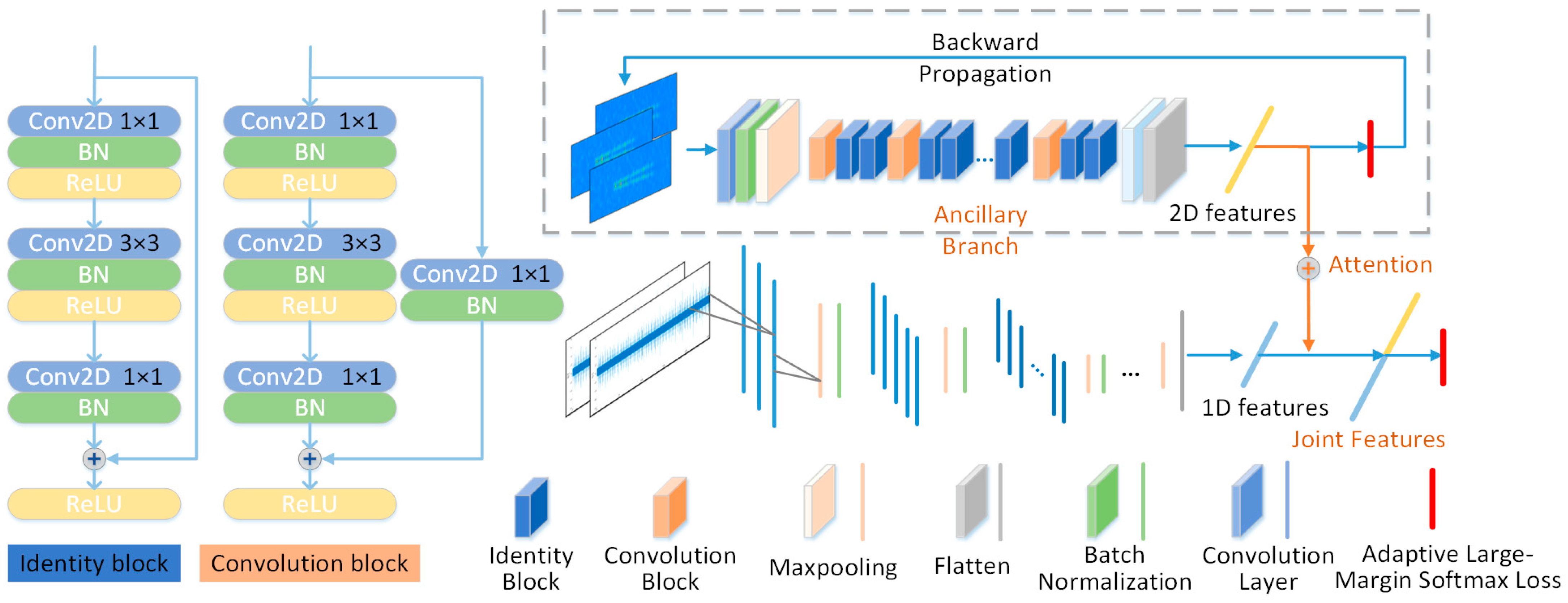
Therefore, to address the issue of low accuracy in SEI under low-SNR conditions, we have introduced an attention-enhanced dual-branch residual network that utilizes ALS. This network extracts features from one-dimensional intermediate frequency data and two-dimensional time–frequency images, fusing them with varying attention weights to form an enhanced joint feature for advanced training. This method allows for the extraction of distinctive features across dimensions, ensuring robust recognition performance amidst noise. Additionally, we replace the original Softmax with L-Softmax and further develop ALS, which adaptively calculates and adjusts the classification margin decision parameter, effectively reducing intra-class distances while increasing inter-class separations without extensive experimental tuning. Our experimental results show that this approach significantly outperforms existing methods in low-SNR scenarios, achieving an average recognition rate improvement of 4.8%.
The remainder of the paper proceeds as follows:
Section 2 is concerned with the methodology used for this study. Detailed experimental procedures are given in
Section 3. In
Section 4, we discuss the results and analyze the factors influencing the results.
Section 5 presents the conclusions derived from this study.
5. Conclusions
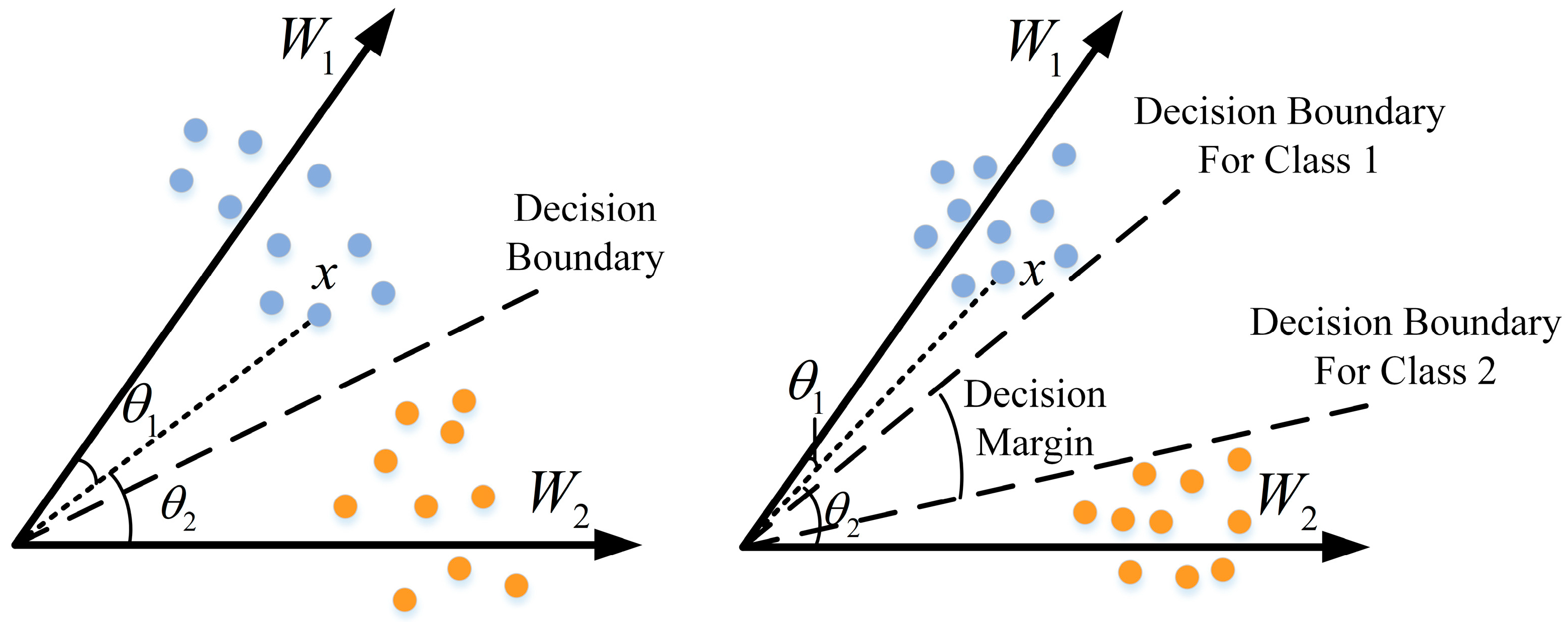
To address the problem of the poor classification accuracy of radar individual signal characteristics within low-SNR conditions, where the single-dimensional radar individual signal features are severely affected by noise, we propose the ALSDBFF for radar individual signal classification. We designed a dual-branch network structure to extract features from one-dimensional IF data and two-dimensional time–frequency images and assign the weights of the features, fusing them into an enhanced joint feature for continued training. Additionally, we introduced the Adaptive L-Softmax method (ALS) to replace the original Softmax, which adaptively calculates the classification margin decision parameter based on the angle between samples and the classification boundary and adjusts the margin values of the sample classification boundaries; it reduces the intra-class distance for the same class while increasing the inter-class distance between different classes without the need for cumbersome experiments to determine the optimal value of decision parameter.
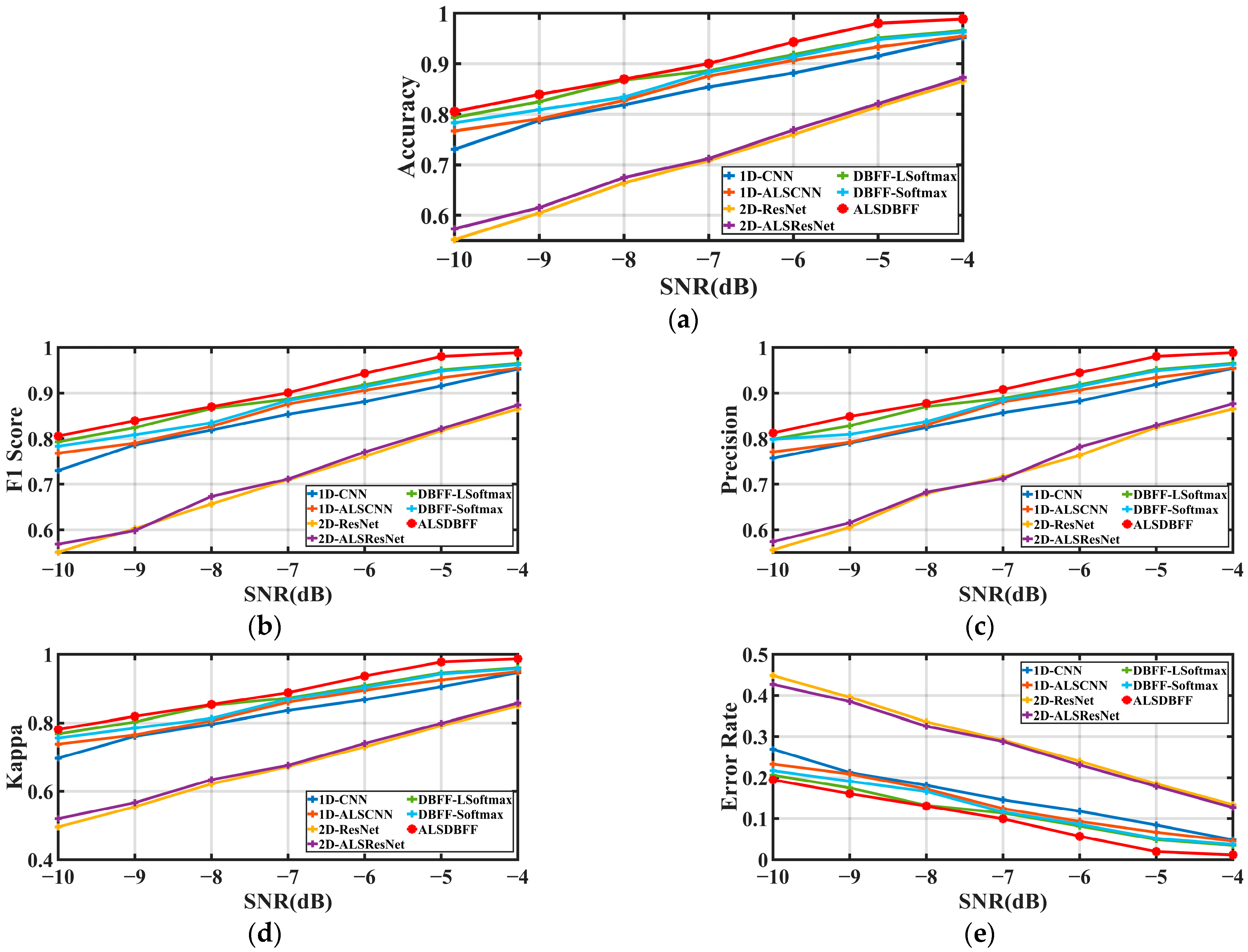
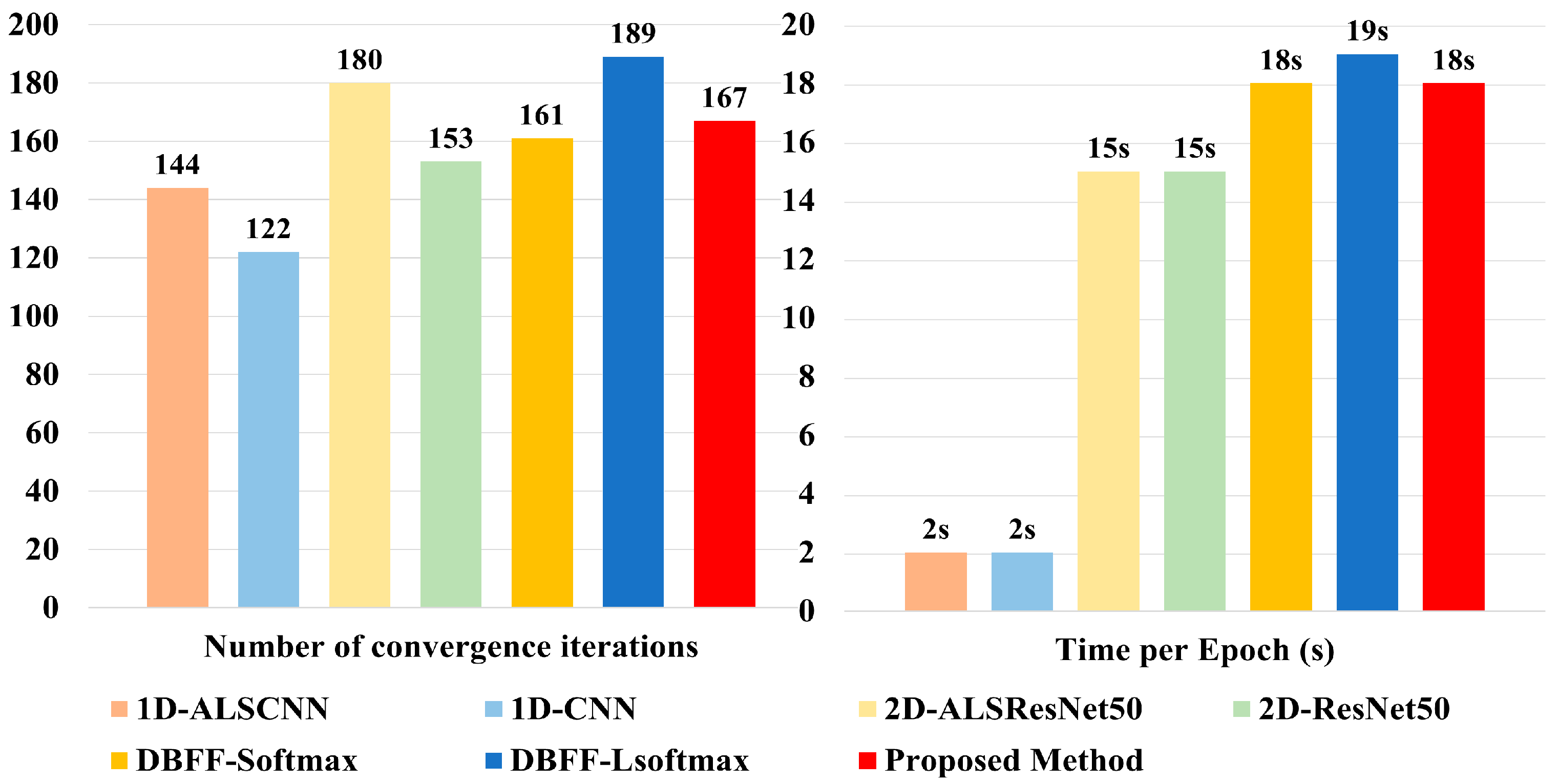
The experimental results demonstrate that relative to other baseline approaches, the proposed method significantly improves the model’s ability to extract features and classify data under low-SNR conditions, effectively mitigating the influence of noise. Compared to models using only single-dimensional features (1D-CNN, 2D-ResNet), the network structure utilizing dual-branch feature fusion achieves an average classification accuracy rate improvement of 9.7%. Further experimental investigation into the effects of ALS indicates that employing L-Softmax aids the model in enlarging the distance between different classes, thus diminishing the likelihood of misclassification among similar categories. Compared to Softmax, the average classification accuracy rate improved by 1.04%, and the accuracy rate was further enhanced by 1.84% when using the attention mechanism with L-Softmax compared to L-Softmax alone. However, we also recognize the shortcomings of our method. Firstly, although the dual-branch network structure improves the network’s classification accuracy rate and stability, it somewhat sacrifices training speed. Meanwhile, the L-Softmax makes the model more difficult to converge during training, requiring a greater time investment. Secondly, the auxiliary branch’s ResNet network structure is prone to overfitting, posing challenges in enhancing the model’s validation set accuracy throughout the training process.
In future work, we hope to continue improving this method, enhancing network training efficiency, reducing training time costs, and reducing overfitting through designing or improving loss function methods. Meanwhile, we plan to collect real-world data to further refine our model to ensure its robustness and reliability in real-world applications.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}