


Bridging Domains and Resolutions: Deep Learning-Based Land Cover Mapping without Matched Labels


Abstract
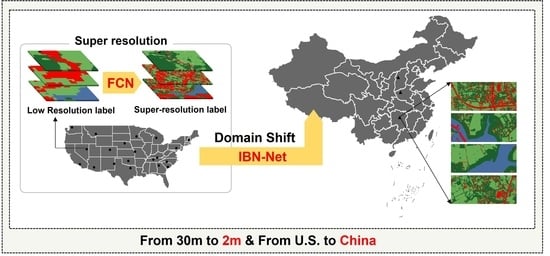
:
1. Introduction
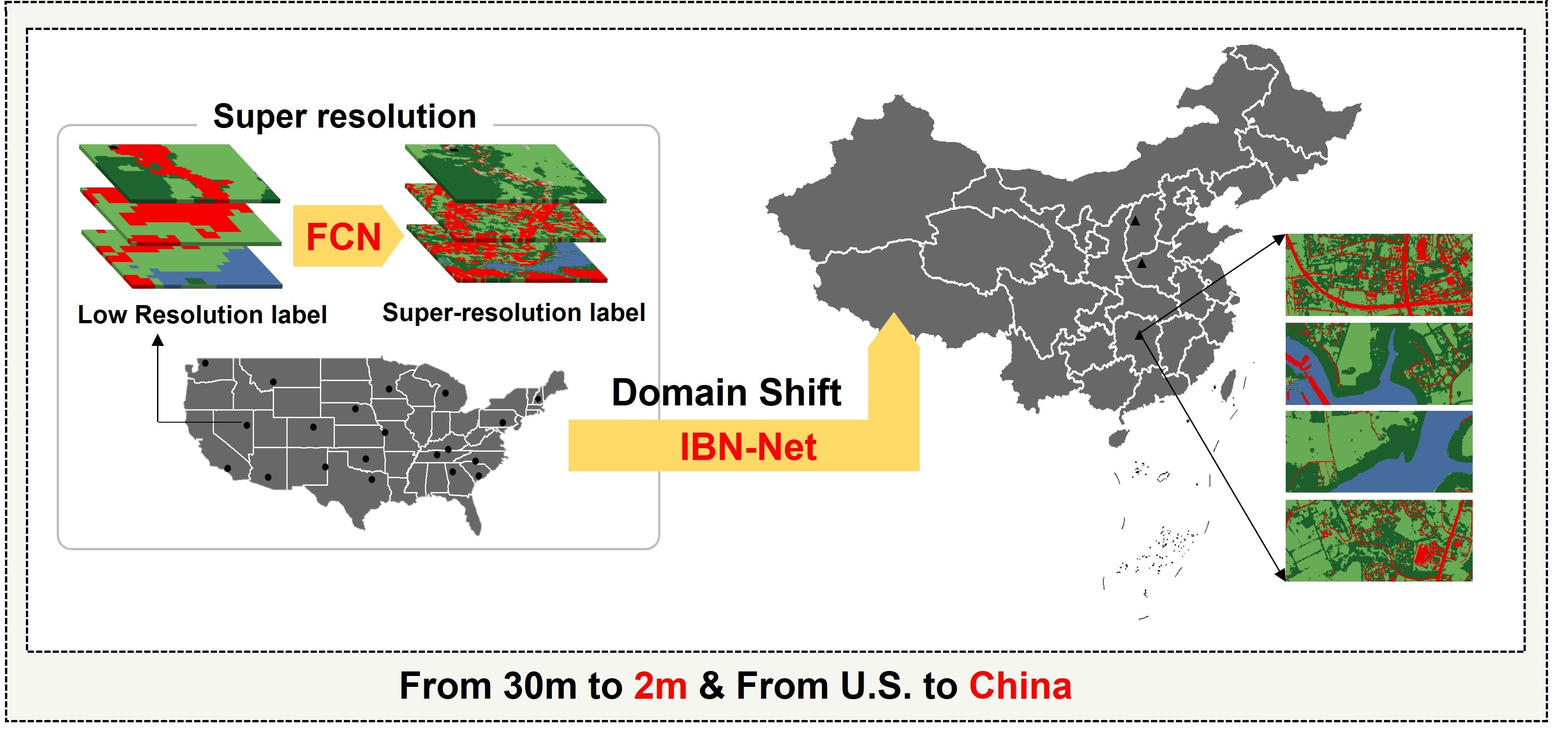
2. Materials and Methods
2.1. Study Area and Dataset
2.1.1. Data Acquisition
2.1.2. Reclassification
2.1.3. Preprocessing of Dataset
2.2. Methodology
2.2.1. Label Super-Resolution
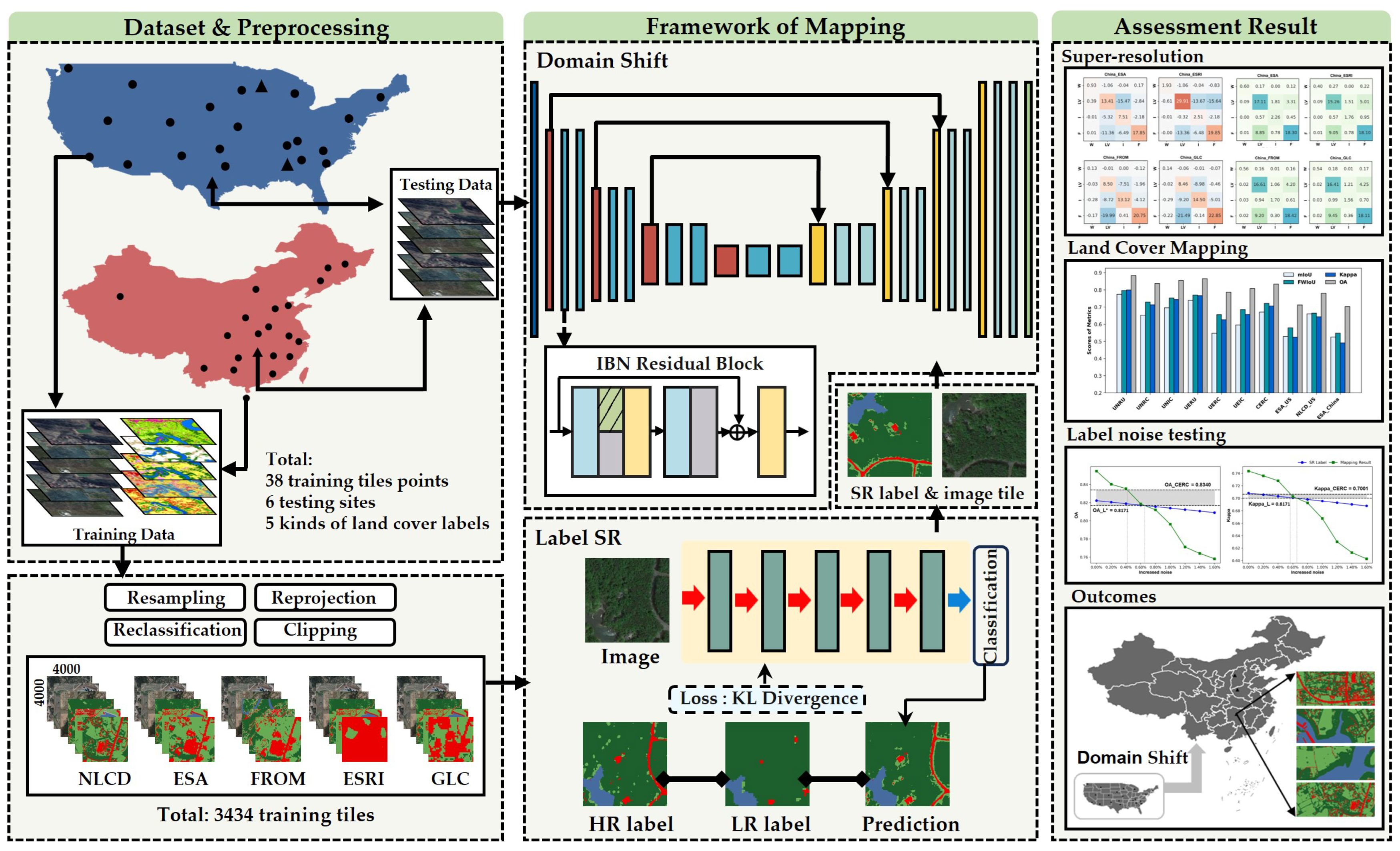
2.2.2. IBN-Net
2.3. Implementation Details
2.4. Comparison Methods
2.5. Evaluation Metrics
3. Results and Analysis
3.1. Super Resolution



3.2. Land Cover Mapping
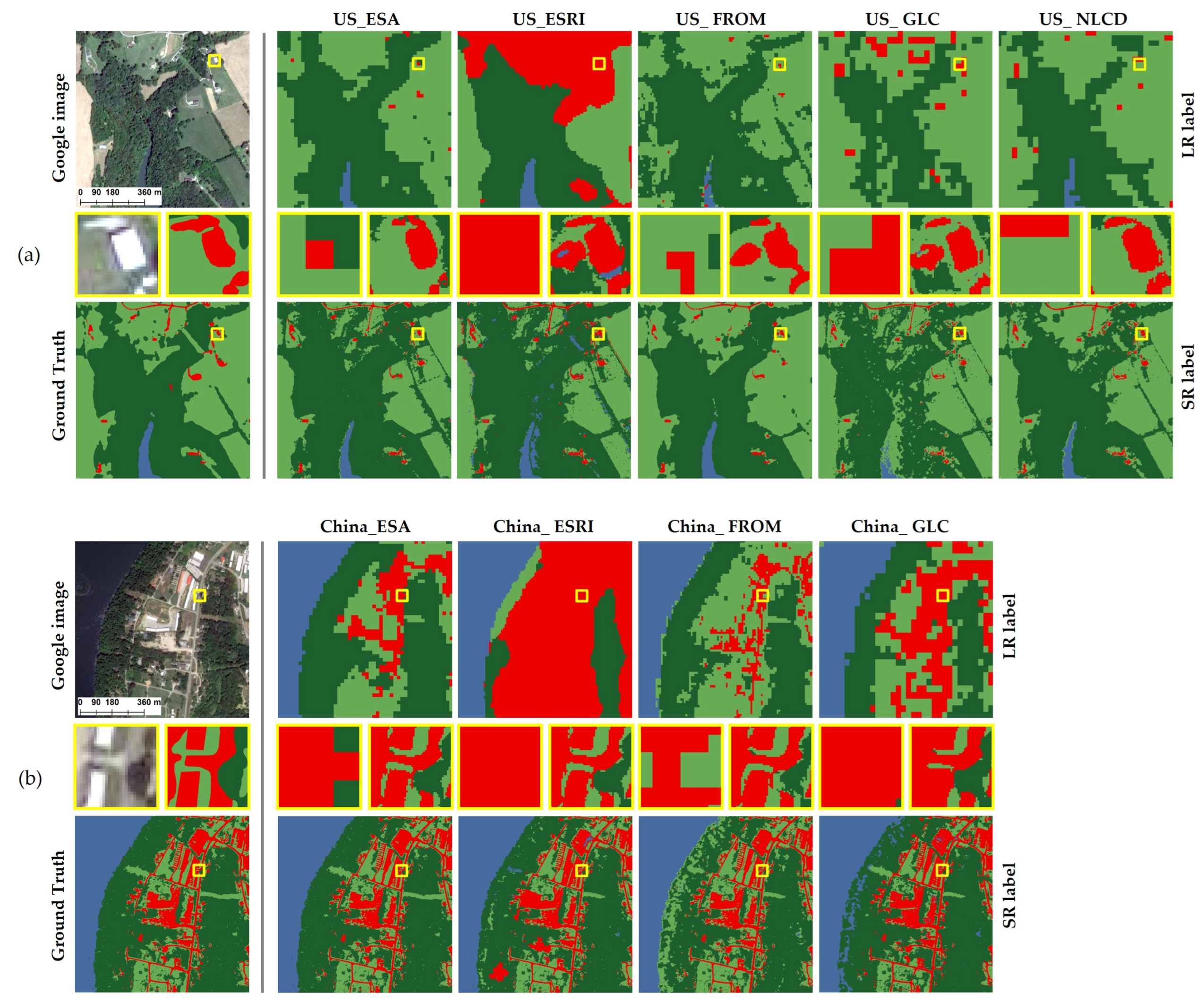
3.2.1. Visualization and Qualitative Analysis
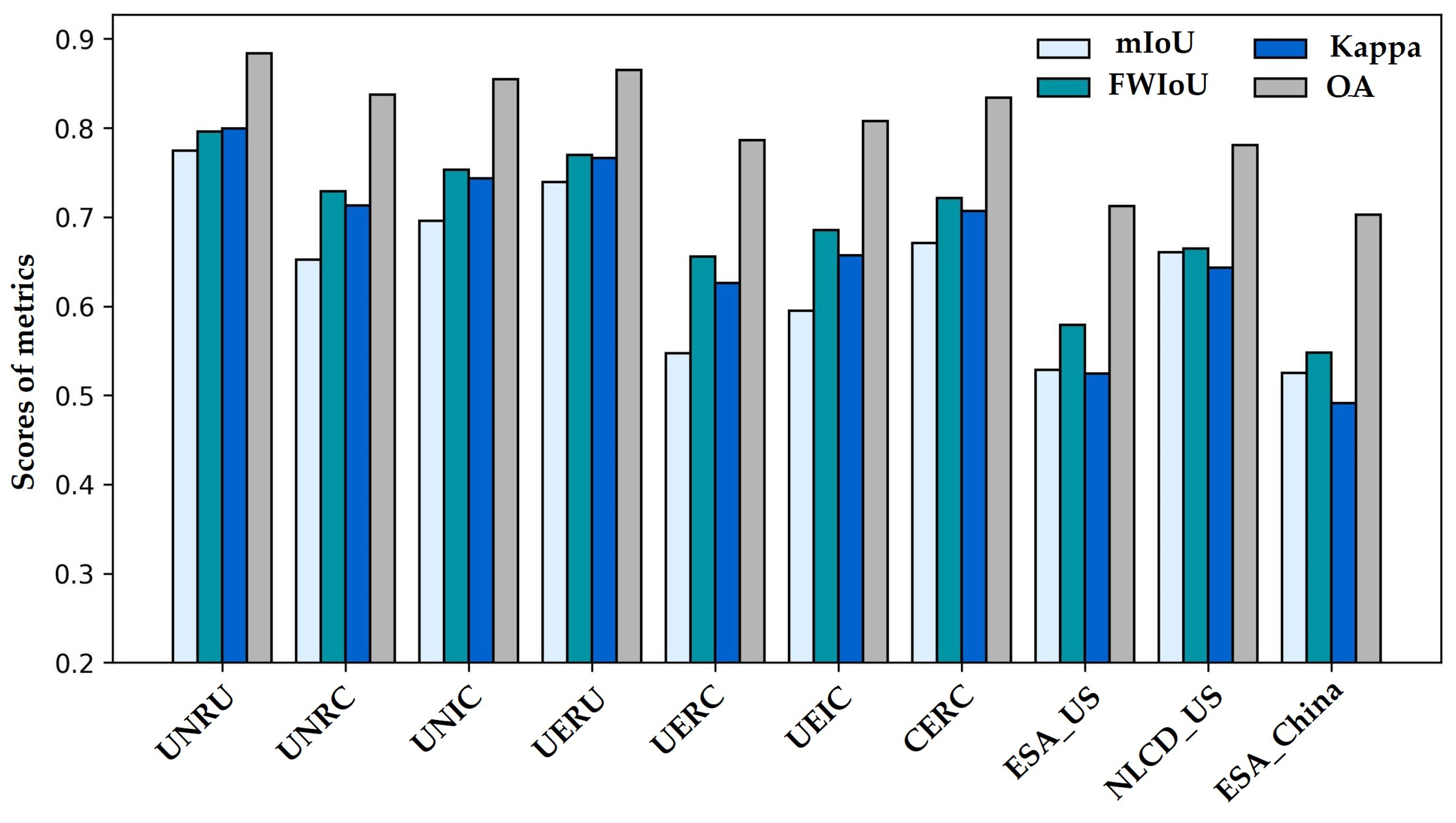
3.2.2. Quantitative Analysis
4. Discussion
4.1. Comparison of Global Products
4.2. Exogenous Label Noise Testing
4.3. Research Constraints and Opportunities
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, X.; Yang, D.; He, Y.; Nelson, P.; Low, R.; McBride, S.; Mitchell, J.; Guarraia, M. Land cover mapping via crowdsourced multi-directional views: The more directional views, the better. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103382. [Google Scholar] [CrossRef]
- Jiang, J.; Xiang, J.; Yan, E.; Song, Y.; Mo, D. Forest-CD: Forest Change Detection Network Based on VHR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Tong, X.Y.; Xia, G.S.; Zhu, X.X. Enabling country-scale land cover mapping with meter-resolution satellite imagery. ISPRS J. Photogramm. Remote. Sens. 2023, 196, 178–196. [Google Scholar] [CrossRef] [PubMed]
- Paris, C.; Bruzzone, L.; Fernández-Prieto, D. A novel approach to the unsupervised update of land-cover maps by classification of time series of multispectral images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4259–4277. [Google Scholar] [CrossRef]
- Gaur, S.; Singh, R. A comprehensive review on land use/land cover (LULC) change modeling for urban development: Current status and future prospects. Sustainability 2023, 15, 903. [Google Scholar] [CrossRef]
- Zhao, Z.; Islam, F.; Waseem, L.A.; Tariq, A.; Nawaz, M.; Islam, I.U.; Bibi, T.; Rehman, N.U.; Ahmad, W.; Aslam, R.W.; et al. Comparison of three machine learning algorithms using google earth engine for land use land cover classification. Rangel. Ecol. Manag. 2024, 92, 129–137. [Google Scholar] [CrossRef]
- Feizizadeh, B.; Omarzadeh, D.; Kazemi Garajeh, M.; Lakes, T.; Blaschke, T. Machine learning data-driven approaches for land use/cover mapping and trend analysis using Google Earth Engine. J. Environ. Plan. Manag. 2023, 66, 665–697. [Google Scholar] [CrossRef]
- Kakogeorgiou, I.; Karantzalos, K. Evaluating explainable artificial intelligence methods for multi-label deep learning classification tasks in remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102520. [Google Scholar] [CrossRef]
- Robinson, C.; Hou, L.; Malkin, K.; Soobitsky, R.; Czawlytko, J.; Dilkina, B.; Jojic, N. Large scale high-resolution land cover mapping with multi-resolution data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12726–12735. [Google Scholar]
- Liu, Y.; Zhong, Y.; Ma, A.; Zhao, J.; Zhang, L. Cross-resolution national-scale land-cover mapping based on noisy label learning: A case study of China. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103265. [Google Scholar] [CrossRef]
- Li, Z.; Lu, F.; Zhang, H.; Yang, G.; Zhang, L. Change cross-detection based on label improvements and multi-model fusion for multi-temporal remote sensing images. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 2054–2057. [Google Scholar]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Zanaga, D.; Van De Kerchove, R.; Daems, D.; De Keersmaecker, W.; Brockmann, C.; Kirches, G.; Wevers, J.; Cartus, O.; Santoro, M.; Fritz, S.; et al. ESA WorldCover 10 m 2021 v200. Zenodo 2022. [Google Scholar] [CrossRef]
- Mollick, T.; Azam, M.G.; Karim, S. Geospatial-based machine learning techniques for land use and land cover mapping using a high-resolution unmanned aerial vehicle image. Remote. Sens. Appl. Soc. Environ. 2023, 29, 100859. [Google Scholar] [CrossRef]
- Li, R.; Gao, X.; Shi, F.; Zhang, H. Scale Effect of Land Cover Classification from Multi-Resolution Satellite Remote Sensing Data. Sensors 2023, 23, 6136. [Google Scholar] [CrossRef]
- Priscila, S.S.; Rajest, S.S.; Regin, R.; Shynu, T. Classification of Satellite Photographs Utilizing the K-Nearest Neighbor Algorithm. Cent. Asian J. Math. Theory Comput. Sci. 2023, 4, 53–71. [Google Scholar]
- Song, L.; Estes, A.B.; Estes, L.D. A super-ensemble approach to map land cover types with high resolution over data-sparse African savanna landscapes. Int. J. Appl. Earth Obs. Geoinf. 2023, 116, 103152. [Google Scholar] [CrossRef]
- Malkin, K.; Robinson, C.; Hou, L.; Soobitsky, R.; Czawlytko, J.; Samaras, D.; Saltz, J.; Joppa, L.; Jojic, N. Label super-resolution networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Li, Z.; Zhang, H.; Lu, F.; Xue, R.; Yang, G.; Zhang, L. Breaking the resolution barrier: A low-to-high network for large-scale high-resolution land-cover mapping using low-resolution labels. ISPRS J. Photogramm. Remote Sens. 2022, 192, 244–267. [Google Scholar] [CrossRef]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with Sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4704–4707. [Google Scholar]
- Kang, J.; Sui, L.; Yang, X.; Wang, Z.; Huang, C.; Wang, J. Spatial pattern consistency among different remote-sensing land cover datasets: A case study in Northern Laos. ISPRS Int. J. Geoinf. 2019, 8, 201. [Google Scholar] [CrossRef]
- Wickham, J.; Stehman, S.V.; Sorenson, D.G.; Gass, L.; Dewitz, J.A. Thematic accuracy assessment of the NLCD 2019 land cover for the conterminous United States. GIsci. Remote Sens. 2023, 60, 2181143. [Google Scholar] [CrossRef]
- Shinskie, J.L.; Delahunty, T.; Pitt, A.L. Fine-scale accuracy assessment of the 2016 National Land Cover Dataset for stream-based wildlife habitat. J. Wildl. Manag. 2023, 87, e22402. [Google Scholar] [CrossRef]
- Bruzzone, L.; Carlin, L. A multilevel context-based system for classification of very high spatial resolution images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2587–2600. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Pan, Z.; Yu, W.; Wang, B.; Xie, H.; Sheng, V.S.; Lei, J.; Kwong, S. Loss functions of generative adversarial networks (GANs): Opportunities and challenges. IEEE Trans. Emerg Top. Comput Intell. 2020, 4, 500–522. [Google Scholar] [CrossRef]
- Pan, X.; Luo, P.; Shi, J.; Tang, X. Two at once: Enhancing learning and generalization capacities via ibn-net. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 464–479. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. Proc. AAAI Conf. Artif. Intell. 2018, 32, 1. [Google Scholar] [CrossRef]
- Malkin, N.; Ortiz, A.; Jojic, N. Mining self-similarity: Label super-resolution with epitomic representations. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 531–547. [Google Scholar]
- Smith, P. Bilinear interpolation of digital images. Ultramicroscopy 1981, 6, 201–204. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. NeurIPS 2018, 31, 8778–8788. [Google Scholar]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Xian, G.; Homer, C. Updating the 2001 National Land Cover Database impervious surface products to 2006 using Landsat imagery change detection methods. Remote Sens. Environ. 2010, 114, 1676–1686. [Google Scholar] [CrossRef]
- Aryal, K.; Apan, A.; Maraseni, T. Comparing global and local land cover maps for ecosystem management in the Himalayas. Remote Sens. Appl. 2023, 30, 100952. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Year | Scale | URLs |
|---|---|---|---|
| NLCD (level II) | 2019 | National (U.S.) | https://www.mrlc.gov/data/nlcd-2019-land-cover-conus |
| ESA WorldCover v100 | 2020 | Global | https://esa-worldcover.org |
| FROM-GLC10 | 2017 | Global | https://data-starcloud.pcl.ac.cn/zh |
| ESRI-LULC | 2020 | Global | https://livingatlas.arcgis.com/landcover/ |
| GLC_FCS30 | 2015 | Global | https://doi.org/10.5281/zenodo.3986872 |
| NLCD | ESA | FROM | ESRI | GLC | Target Classes | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
 | 11 |  | 80 |  | 60 |  | 1 |  | 210 |  | W |
 | 23 |  | 50 |  | 80 |  | 7 |  | 190 |  | I |
 | 24 | ||||||||||
 | 62 | ||||||||||
 | 60 | ||||||||||
 | 61 | ||||||||||
 | 80 | ||||||||||
 | 41 |  | 81 | ||||||||
 | 42 |  | 10 |  | 20 |  | 2 |  | 82 |  | F |
 | 43 |  | 50 | ||||||||
 | 71 | ||||||||||
 | 70 | ||||||||||
 | 72 | ||||||||||
 | 90 | ||||||||||
 | 11 | ||||||||||
 | 51 |  | 10 | ||||||||
 | 52 |  | 202 | ||||||||
 | 72 |  | 200 | ||||||||
 | 71 |  | 30 |  | 153 | ||||||
 | 22 |  | 20 |  | 40 |  | 4 |  | 152 | ||
 | 21 |  | 100 |  | 30 |  | 11 |  | 130 | ||
 | 73 |  | 90 |  | 10 |  | 5 |  | 150 |  | LV |
 | 74 |  | 95 |  | 90 |  | 8 |  | 140 | ||
 | 95 |  | 40 |  | 180 | ||||||
 | 90 |  | 60 |  | 20 | ||||||
 | 81 |  | 121 | ||||||||
 | 82 |  | 122 | ||||||||
 | 31 |  | 120 | ||||||||
 | 201 | ||||||||||
| Source Domains | Target Domains | |||
|---|---|---|---|---|
| Training | Testing | Training | Testing | |
| Size | 4000 × 4000 | 256 × 256 | 4000 × 4000 | 256 × 256 |
| Quantity | 1994 | 8020 | 1442 | 8308 |
| Dataset * | NLCD, ESA, FROM, ESRI, GLC | ESA, FROM, ESRI, GLC | ||
| Parameters | Label SR | Land Cover Mapping |
|---|---|---|
| Input Size | 4000 × 4000 | 256 × 256 |
| Batch Size | 16 | 8 |
| Weight Decay | 0.005 | 0.005 |
| Iteration Number | 10 | 20 |
| Initial Learning Rate | 1 × 10−3 | 1 × 10−4 |
| Experiment | Training Pairs | Framework | Predicted Site |
|---|---|---|---|
| UNRU | Resnet18-Unet | US | |
| UNRC | US_NLCD (data from US) | Resnet18-Unet | China |
| UNIC | IBN-Resnet18-Unet | China | |
| UERU | Resnet18-Unet | US | |
| UERC | US_SR-B (data from US) | Resnet18-Unet | China |
| UEIC | IBN-Resnet18-Unet | China | |
| CEIC | China_SR-B (training data from China) | IBN-Resnet18-Unet | China |
| Metric | Site | Experiment | LR Label | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| UNRU | UNRC | UNIC | UERU | UERC | UEIC | CEIC | ESA_US | NLCD_US | ESA_China | ||
| MIoU | 1 | 0.7507 | 0.6512 | 0.6862 | 0.7313 | 0.5780 | 0.5977 | 0.6680 | 0.5286 | 0.6606 | 0.5250 |
| 2 | 0.7568 | 0.6479 | 0.6979 | 0.7288 | 0.5616 | 0.6257 | 0.6801 | ||||
| 3 | 0.8149 | 0.6573 | 0.7043 | 0.7571 | 0.5012 | 0.5607 | 0.6642 | ||||
| Avg. | 0.7742 | 0.6522 | 0.6961 | 0.7391 | 0.5469 | 0.5947 | 0.6707 | ||||
| FWIoU | 1 | 0.7797 | 0.7278 | 0.7501 | 0.7643 | 0.6644 | 0.6889 | 0.7219 | 0.5791 | 0.6645 | 0.5480 |
| 2 | 0.7974 | 0.7280 | 0.7544 | 0.7601 | 0.6639 | 0.6955 | 0.7249 | ||||
| 3 | 0.8106 | 0.7310 | 0.7553 | 0.7856 | 0.6383 | 0.6727 | 0.7181 | ||||
| Avg. | 0.7959 | 0.7289 | 0.7533 | 0.7700 | 0.6555 | 0.6857 | 0.7216 | ||||
| Kappa | 1 | 0.7780 | 0.7117 | 0.7395 | 0.7071 | 0.6404 | 0.6610 | 0.7071 | 0.5244 | 0.6431 | 0.4915 |
| 2 | 0.7967 | 0.7120 | 0.7450 | 0.7553 | 0.6374 | 0.6730 | 0.7102 | ||||
| 3 | 0.8230 | 0.7158 | 0.7463 | 0.8368 | 0.6001 | 0.6371 | 0.7023 | ||||
| Avg. | 0.7992 | 0.7131 | 0.7436 | 0.7664 | 0.6260 | 0.6570 | 0.7065 | ||||
| OA | 1 | 0.8722 | 0.8369 | 0.8527 | 0.8619 | 0.7937 | 0.8101 | 0.8343 | 0.7123 | 0.7810 | 0.7029 |
| 2 | 0.8843 | 0.8372 | 0.8556 | 0.8585 | 0.7926 | 0.8158 | 0.8361 | ||||
| 3 | 0.8938 | 0.8391 | 0.8560 | 0.8757 | 0.7719 | 0.7972 | 0.8316 | ||||
| Avg. | 0.8834 | 0.8377 | 0.8548 | 0.8654 | 0.7861 | 0.8077 | 0.8340 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, S.; Tang, Y.; Yan, E.; Jiang, J.; Mo, D. Bridging Domains and Resolutions: Deep Learning-Based Land Cover Mapping without Matched Labels. Remote Sens. 2024, 16, 1449. https://doi.org/10.3390/rs16081449
Cao S, Tang Y, Yan E, Jiang J, Mo D. Bridging Domains and Resolutions: Deep Learning-Based Land Cover Mapping without Matched Labels. Remote Sensing. 2024; 16(8):1449. https://doi.org/10.3390/rs16081449
Chicago/Turabian StyleCao, Shuyi, Yubin Tang, Enping Yan, Jiawei Jiang, and Dengkui Mo. 2024. "Bridging Domains and Resolutions: Deep Learning-Based Land Cover Mapping without Matched Labels" Remote Sensing 16, no. 8: 1449. https://doi.org/10.3390/rs16081449
APA StyleCao, S., Tang, Y., Yan, E., Jiang, J., & Mo, D. (2024). Bridging Domains and Resolutions: Deep Learning-Based Land Cover Mapping without Matched Labels. Remote Sensing, 16(8), 1449. https://doi.org/10.3390/rs16081449