Machine Learning Comparison between WorldView-2 and QuickBird-2-Simulated Imagery Regarding Object-Based Urban Land Cover Classification



Abstract
:1. Introduction
2. Methodology
2.1. Study Site and Data Preparation
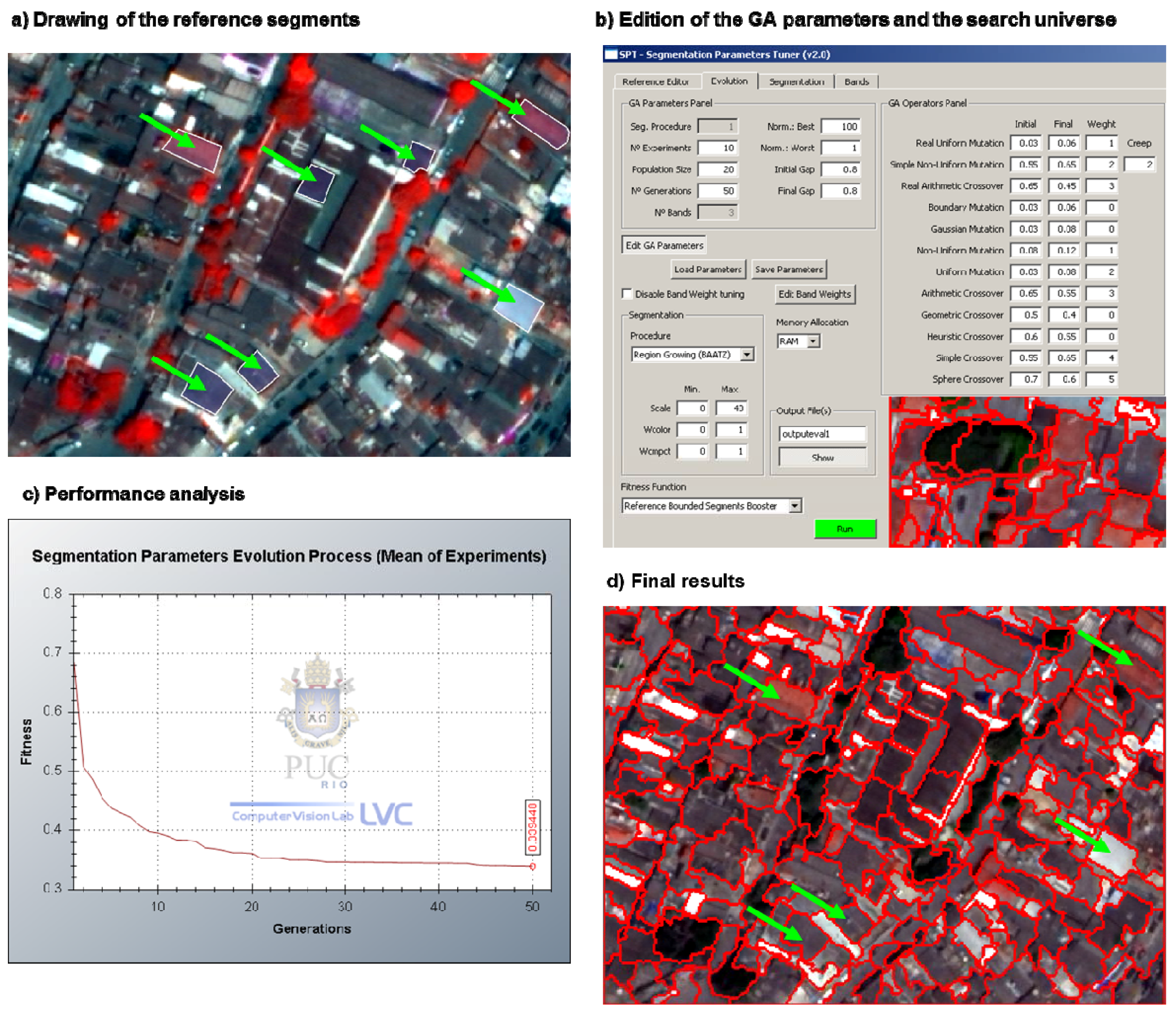
2.2. Segmentation-Based Analysis
- Image 1: Bands 2, 3 and 5;
- Image 2: Bands 2, 3 and 7;
- Image 3: Bands 1, 5 and 8;
- Image 4: Bands 2, 6 and 8;


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Correlation | Band 1 | Band 2 | Band 3 | Band 4 | Band 5 | Band 6 | Band 7 | Band 8 |
|---|---|---|---|---|---|---|---|---|
| Band 1 | 1 | |||||||
| Band 2 | 0.990286 | 1 | ||||||
| Band 3 | 0.974494 | 0.987039 | 1 | |||||
| Band 4 | 0.937438 | 0.942091 | 0.965501 | 1 | ||||
| Band 5 | 0.915844 | 0.929299 | 0.955034 | 0.984436 | 1 | |||
| Band 6 | 0.766527 | 0.779873 | 0.846188 | 0.885299 | 0.865134 | 1 | ||
| Band 7 | 0.518168 | 0.538644 | 0.620546 | 0.621782 | 0.608105 | 0.897162 | 1 | |
| Band 8 | 0.498322 | 0.512075 | 0.591015 | 0.606024 | 0.587367 | 0.877953 | 0.981882 | 1 |
| GA Procedure Parameters | Search Space | ||||
|---|---|---|---|---|---|
| Min. | Max. | ||||
| No of experiments | 10 | Scale parameter | 0 | 40 | |
| Population size | 20 | Weight color | 0 | 1 | |
| No of generations | 50 | Weight compactness | 0 | 1 | |
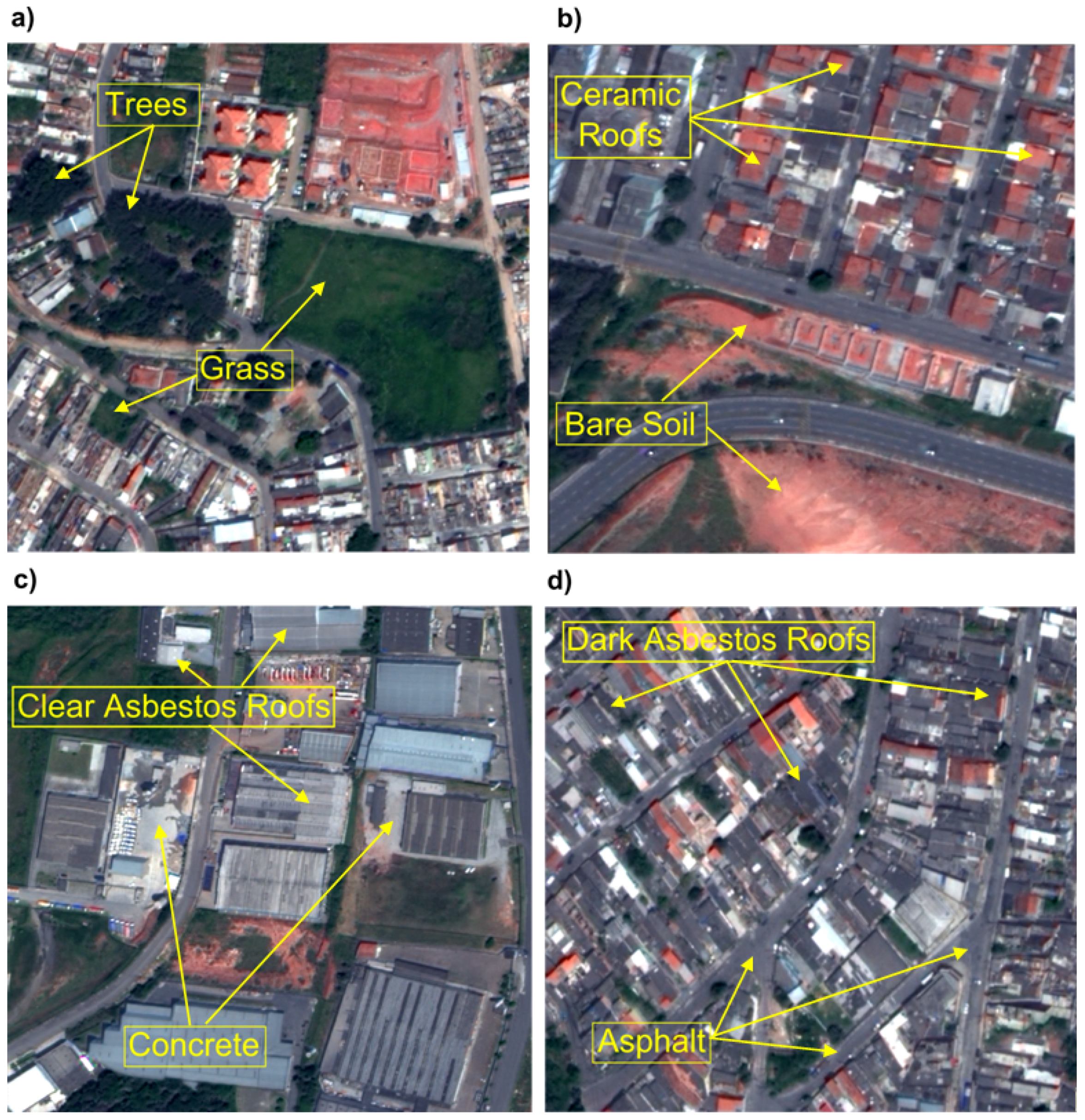
2.3. Feature Selection
- Group 1 (G1): Grass (311) and Trees (150);
- Group 2 (G2): Ceramic Tile Roofs (151) and Bare Soil (141);
- Group 3 (G3): Concrete (196) and Clear Asbestos Roofs (86);
- Group 4 (G4): Asphalt (53) and Dark Asbestos Roofs (52).

2.4. Land Cover Classification Analysis
3. Results
3.1. Segmentation Parameters-Based Analysis

3.2. Feature Selection Analysis
| Group 1 | InfoGain | Relief-F | FCBF | RF | ||||
| Ra | RVb | Ra | RVb | Ra | RVb | Ra | RVb | |
| Brightness | 4 | 2.14 | ||||||
| Brightness – Quickc | 4 | 0.411 | ||||||
| GLDV Ang. 2nd moment Layer 1 (135°) | 3 | 0.473 | ||||||
| GLDV Contrast Layer 4 (135°) | 5 | 0.211 | ||||||
| Max.pixelvalueLayer3 | 5 | 2.14 | ||||||
| Mean Layer 3 | 1 | 0.824 | 1 | 0.309 | 1 | 0.906 | 2 | 2.83 |
| Mean Layer 4 | 4 | 0.728 | 3 | 0.224 | ||||
| Min. pixel value Layer 3 | 2 | 0.787 | 2 | 0.272 | 1 | 2.86 | ||
| Min. pixel value Layer 4 | 3 | 0.728 | 4 | 0.221 | 2 | 0.706 | ||
| Min. pixel value Layer 5 | 5 | 0.661 | ||||||
| Min.pixelvalueLayer2 | 3 | 2.55 | ||||||
| Ratio2 – Quickc | 5 | 0.198 | ||||||
| Group 2 | InfoGain | Relief-F | FCBF | RF | ||||
| Ra | RVb | Ra | RVb | Ra | RVb | Ra | RVb | |
| GLDV Ang. 2nd moment (0°) | 4 | 0.359 | 3 | 0.282 | ||||
| GLDV Ang. 2nd moment Layer 8 (all dir.) | 3 | 0.88 | ||||||
| GLDV Entropy (0°) | 4 | 0.73 | ||||||
| GLDV Entropy Layer 7 (90°) | 1 | 0.317 | ||||||
| Mean Layer 3 | 4 | 0.102 | 2 | 1.01 | ||||
| Min. pixel value Layer 1 | 5 | 0.354 | 5 | 0.71 | ||||
| Min. pixel value Layer 2 | 1 | 0.401 | 2 | 0.104 | 4 | 0.272 | ||
| Min. pixel value Layer 3 | 3 | 0.379 | 3 | 0.103 | 1 | 1.24 | ||
| Ratio Layer 3 | 5 | 0.228 | ||||||
| Standard deviation Layer 6 | 5 | 0.099 | ||||||
| Standard deviation Layer 7 | 2 | 0.384 | 1 | 0.106 | 2 | 0.302 | ||
| Group 3 | InfoGain | Relief-F | FCBF | RF | ||||
| Ra | RVb | Ra | RVb | Ra | RVb | Ra | RVb | |
| GLCM Correlation Layer 7 (135°) | 4 | 0.118 | ||||||
| GLCM StdDev Layer 6 (135°) | 3 | 0.128 | ||||||
| GLDV Entropy Layer 4 (45°) | 5 | 0.082 | ||||||
| Mean Layer 1 | 2 | 0.159 | ||||||
| Ratio Layer 1 – Quickc | 5 | 0.124 | ||||||
| Ratio Layer 2 | 2 | 0.132 | 3 | 1.29 | ||||
| Ratio Layer 2 – Quickc | 2 | 0.302 | ||||||
| Ratio Layer 3 | 1 | 0.311 | 1 | 0.413 | 2 | 1.32 | ||
| Ratio Layer 4 – Quickc | 3 | 0.293 | 4 | 0.125 | ||||
| Ratio Layer 6 | 1 | 1.76 | ||||||
| Ratio Layer 7 | 5 | 0.293 | 3 | 0.126 | 4 | 1.27 | ||
| Ratio Layer 8 | 4 | 0.293 | 1 | 0.136 | 5 | 1.25 | ||
| Group 4 | InfoGain | Relief-F | FCBF | RF | ||||
| Ra | RVb | Ra | RVb | Ra | RVb | Ra | RVb | |
| GLCM Dissimilarity (90°) | 4 | 0.223 | ||||||
| GLCM Dissimilarity Layer 8 (0°) | 5 | 0.155 | ||||||
| Max. Diff. | 4 | 0.385 | 2 | 0.223 | 5 | 0.29 | ||
| Max. pixel value Layer 8 | 3 | 0.289 | ||||||
| Ratio Layer 2 – Quickc | 2 | 0.514 | 3 | 0.181 | 1 | 0.48 | ||
| Ratio Layer 3 | 1 | 0.536 | 2 | 0.209 | 1 | 0.155 | ||
| Ratio Layer 4 | 5 | 0.132 | 4 | 0.31 | ||||
| Ratio Layer 4 – Quickc | 5 | 0.358 | 4 | 0.137 | 3 | 0.35 | ||
| Ratio Layer 8 | 3 | 0.503 | 1 | 0.269 | 2 | 0.47 | ||
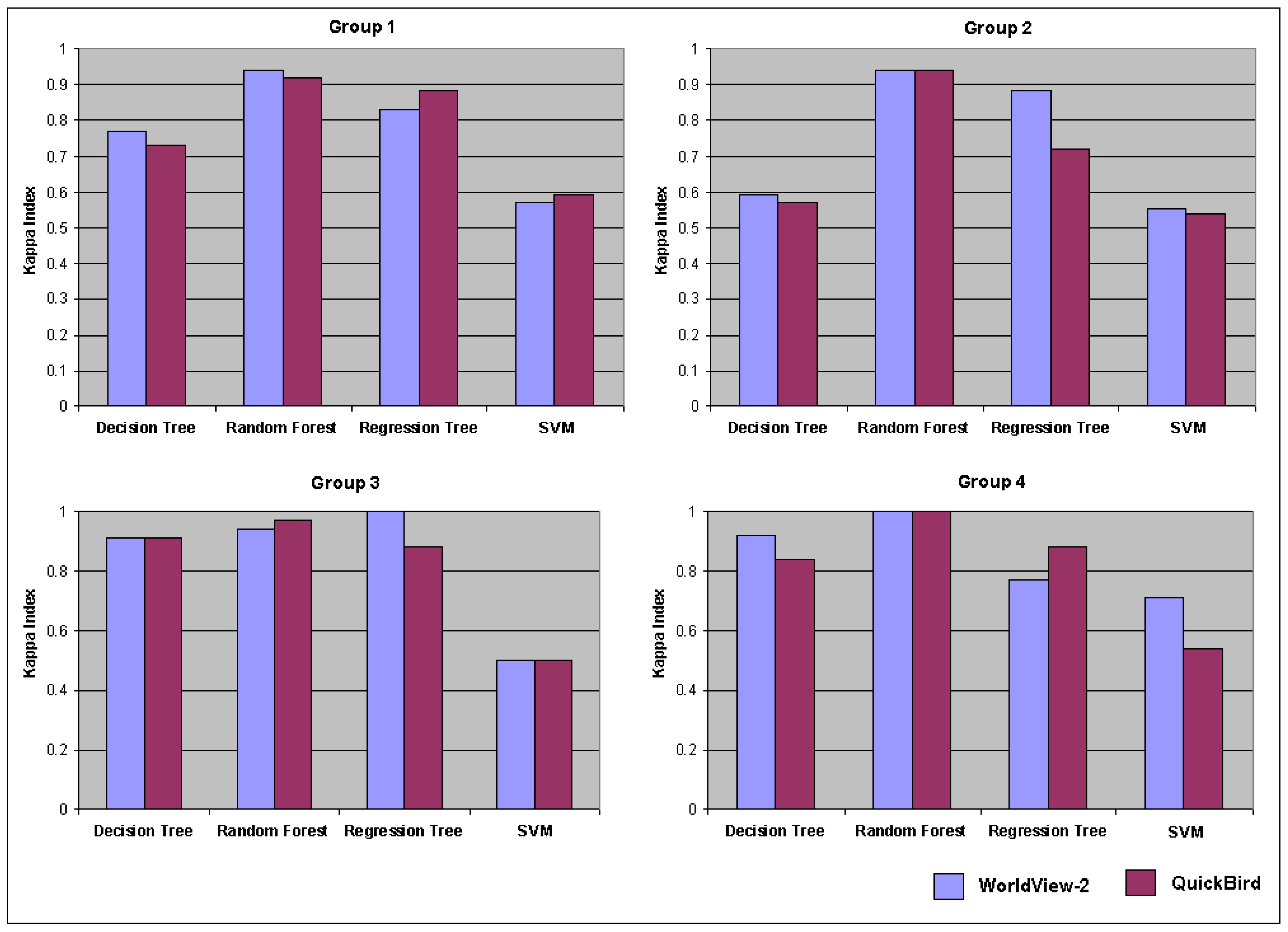
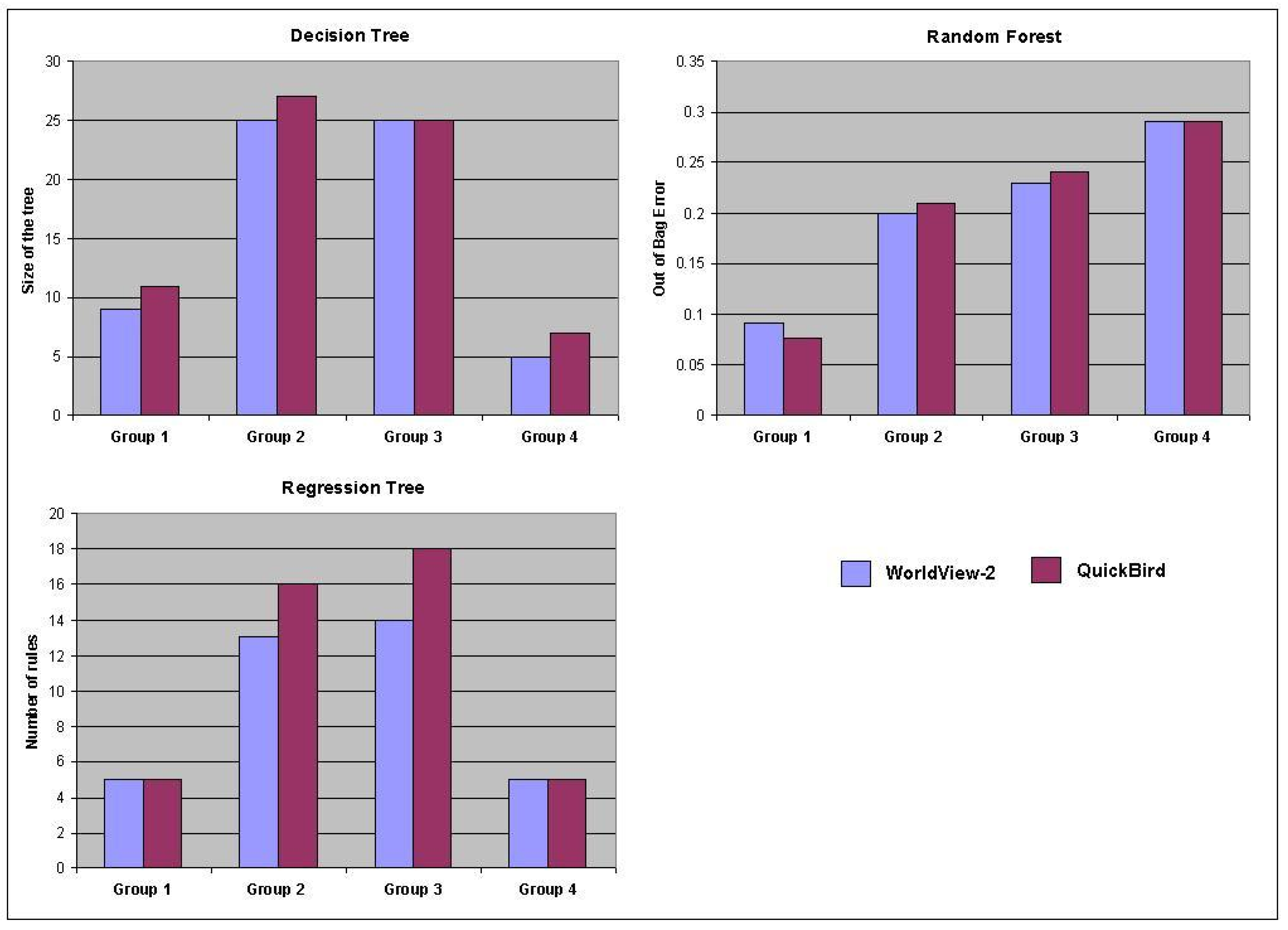
3.3. Classification-Based Analysis


4. Conclusions and Suggestions
Acknowledgments
References
- Grimm, N.B.; Faeth, S.H.; Golubiewski, N.E.; Redman, C.L.; Wu, J.G.; Bai, X.M.; Briggs, J.M. Global change and the ecology of cities. Science 2008, 319, 756–760. [Google Scholar] [CrossRef] [PubMed]
- Rogan, J.; Chen, D. Remote sensing technology for mapping and monitoring land-cover and land-use change. Progr. Plan. 2004, 61, 301–325. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. Extraction of urban impervious surfaces from IKONOS imagery. Int. J. Remote Sens. 2009, 30, 1297–1311. [Google Scholar] [CrossRef]
- Lu, D.; Hetrick, S.; Moran, E. Impervious surface mapping with QuickBird imagery. Int. J. Remote Sens. 2011, 32, 2519–2533. [Google Scholar] [CrossRef] [PubMed]
- DigitalGlobe®. The Benefits of the 8 Spectral Bands of WorldView-2. 2010. Available online: http://www.digitalglobe.com/index.php/88/WorldView-2 (accessed on 3 July 2011).
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Myint, S.W.; Gober, P.; Brazel, A. Per-pixel versus object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Hu, X.; Weng, Q. Impervious surface area extraction from IKONOS imagery using an object-based fuzzy method. Geocarto Int. 2011, 26, 3–20. [Google Scholar] [CrossRef]
- Navulur, K. Multiespectral Image Analysis Using the Object-Oriented Paradigm, 1st ed.; Taylor and Francis Group: Boca Raton, FL, USA, 2007; pp. 15–102. [Google Scholar]
- Benz, U.C.; Hofmann, P.; Wilhauch, G.; Lingenfelder, I.; Heynen, M. Multi-resolution, object-oriented fuzzy analysis of remote sensing data for GIS-ready information. ISPRS J. Photogramm. 2004, 58, 239–258. [Google Scholar] [CrossRef]
- Novack, T.; Kux, H.J.H.; Esch, T.; Stilla, U. Feature Selection Analysis of WorldView-2 Data for Similar Urban Objects Distinction. In Proceedings of Joint Urban Remote Sensing Event (JURSE), Munich, Germnay, 11–13 April 2011; pp. 389–392.
- Instituto Brasileiro de Geografia e Estatística (IBGE). Censo 2010; IBGE: Barreiras, BA, Brazil, 2010. Available online: http://www.ibge.gov.br/home/estatistica/populacao/censo2010/populacao_por_municipio.shtm (accessed on 10 October 2010).
- Welch, R.; Ehlers, W. Merging multiresolution SPOT HRV and Landsat TM data. Photogramm. Eng. Remote Sensing 1987, 3, 301–303. [Google Scholar]
- Computer Vision Lab. Segmentation Parameter Tuner (SPT); LVC, PUC-Rio University: Rio de Janeiro, RJ, Brazil, 2008. Available online: www.lvc.ele.puc-rio.br (accessed on 3 July 2011).
- Davis, L. Handbook of Genetic Algorithms; Van Nostrand Reinhold: New York, NY, USA, 1991; p. 385. [Google Scholar]
- Costa, G.A.O.P.; Feitosa, R.Q.; Cazes, T.B.; Feijó, B. Genetic adaptation of segmentation parameters. In Object-Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications, 1st ed.; Blaschke, T., Lang, S., Hay, G.F., Eds.; Springer Verlag: Berlin, Germany, 2008; pp. 679–695. [Google Scholar]
- Baatz, M.; Schäpe, A. Multiresolution segmentation—An optimization approach for high quality multi-scale image segmentation. In Angewandte Geographische Informationsverarbeitung XII: Beiträage zum AGIT Symposium Salzburg 2000; Strobl, J., Blaschke, T., Eds.; Herbert Wichmann: Karlsruhe, Germany, 2000; pp. 12–23. [Google Scholar]
- Trimble®. Definiens Developer Reference Book; Definiens AG: Munich, Germany, 2007. Available online: http://www.pcigeomatics.com/products/pdfs/definiens/ReferenceBook.pdf (accessed on 4 July 2011).
- Gao, Y.; Marpu, P.; Niemeyer, I.; Runfola, D. M.; Giner, N. M.; Hamill, T.; Pontius, R.G., Jr. Object-based classification with features extracted by a semi-automatic feature extraction algorithm—SeaTH. Geocarto Int. 2011, 26, 211–226. [Google Scholar] [CrossRef]
- Novack, T.; Kux, H.J.H. Urban land cover and land use classification of an informal settlement area using the open-source knowledge-based system InterIMAGE. J. Spat. Sci. 2010, 55, 23–41. [Google Scholar] [CrossRef]
- Kux, H.J.H.; Araujo, E.H.G. Object-based image analysis using QuickBird satellite image and GIS data, case study of Belo Horizonte (Brazil). In Object-based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications, 1st ed.; Blaschke, T., Lang, S., Hay, J., Eds.; Springer Verlag: Berlin, Germany, 2008; pp. 571–588. [Google Scholar]
- Tso, B.; Mather, P. Classification Methods for Remotely Sensed Data, 2nd ed.; CRC Press: London, England, 2009; p. 356. [Google Scholar]
- Kononenko, I. Estimating attributes: Analysis and extension of RELIEF. In Machine Learning: ECML-94; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, 1994; pp. 171–182. [Google Scholar]
- Yu, L.; Liu, H. Feature selection for high dimensional data: A fast correlation-based filter solution. In Proceedings of the XX International Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003; pp. 856–863.
- Breiman, L. Random forests. Machine Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ghimere, B.; Rogan, J.; Miller, J. Contextual land-cover classification: Incorporating spatial dependence in land-cover classification models using random forests and the Getis statistic. Remote Sens. Lett. 2010, 1, 45–54. [Google Scholar] [CrossRef]
- Machine Learning Group. Weka: Data Mining Software in Java; Version 3; University of Waikato: Hamilton, New Zealand, 2011; Available online: http://www.cs.waikato.ac.nz/ml/weka/ (accessed on 20 October 2011).
- Livingston, F. Implementation of Breiman’s Random Forest Machine Learning Algorithm. Machine Learning Journal Paper. 2005. Available online: http://gogoshen.org/ml2005/Journal%20Paper/JournalPaper_Livingston.pdf (accessed on 20 October 2011).
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; Lewis Publishers: Boca Raton, FL, USA, 1999; p. 137. [Google Scholar]
- Quinlan, R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers: San Mateo, CA, USA, 1993; p. 302. [Google Scholar]
- Keerthi, S.S.; Shevade, S.K.; Bhattacharyya, C.; Murthy, K.R.K. Improvements to Platt’s SMO algorithm for SVM classifier design. Neural Comput. 2001, 13, 637–649. [Google Scholar] [CrossRef]
- Frank, E.; Wang, Y.; Inglis, S.; Homes, G.; Witten, I.H. Using model trees for classification. Machine Learn. 1998, 32, 63–76. [Google Scholar] [CrossRef]
- Xian, G. Mapping impervious surface using classification and regression tree algorithm. In Remote Sensing of Impervious Surfaces, 2nd ed.; Weng, Q., Ed.; CRC Press: Boca Raton, FL, USA, 2008; pp. 39–58. [Google Scholar]
- Haralick, R.M.; Shanmugan, M.; Dinstein, I. Texture feature for image classification. IEEE Trans. Syst. Man Cyber. 1973, 3, 610–621. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Fortier, J.; Rogan, J.; Woodcock, C.; Runfola, D.M. Utilizing temporally invariant calibration sites to classify multiple dates of satellite imagery. Photogramm. Eng. Remote Sensing 2011, 77, 181–189. [Google Scholar] [CrossRef]
- InterIMAGE. InterIMAGE: Interpreting Images Freely; LVC: Rio de Janeiro, RJ, Brasil, 2011; Available online: http://www.lvc.ele.puc-rio.br/projects/interimage/ (accessed on 10 August 2011).
© 2011 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Novack, T.; Esch, T.; Kux, H.; Stilla, U. Machine Learning Comparison between WorldView-2 and QuickBird-2-Simulated Imagery Regarding Object-Based Urban Land Cover Classification . Remote Sens. 2011, 3, 2263-2282. https://doi.org/10.3390/rs3102263
Novack T, Esch T, Kux H, Stilla U. Machine Learning Comparison between WorldView-2 and QuickBird-2-Simulated Imagery Regarding Object-Based Urban Land Cover Classification . Remote Sensing. 2011; 3(10):2263-2282. https://doi.org/10.3390/rs3102263
Chicago/Turabian StyleNovack, Tessio, Thomas Esch, Hermann Kux, and Uwe Stilla. 2011. "Machine Learning Comparison between WorldView-2 and QuickBird-2-Simulated Imagery Regarding Object-Based Urban Land Cover Classification " Remote Sensing 3, no. 10: 2263-2282. https://doi.org/10.3390/rs3102263
APA StyleNovack, T., Esch, T., Kux, H., & Stilla, U. (2011). Machine Learning Comparison between WorldView-2 and QuickBird-2-Simulated Imagery Regarding Object-Based Urban Land Cover Classification . Remote Sensing, 3(10), 2263-2282. https://doi.org/10.3390/rs3102263