Quality Assessment of Pre-Classification Maps Generated from Spaceborne/Airborne Multi-Spectral Images by the Satellite Image Automatic Mapper™ and Atmospheric/Topographic Correction™-Spectral Classification Software Products: Part 2 — Experimental Results

Abstract
:1. Introduction
2. Test Image Set
- (1).
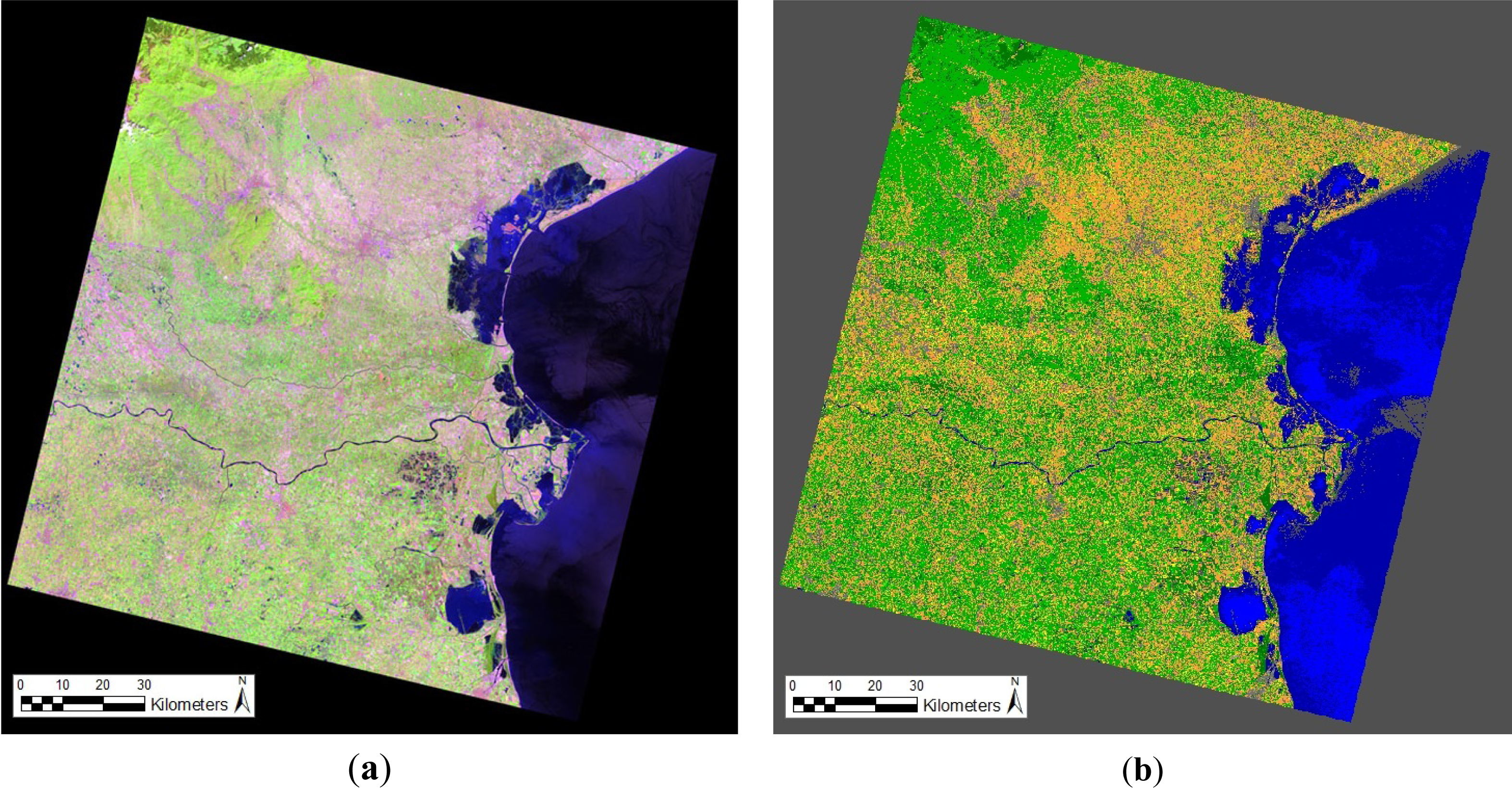
- One spaceborne 23.5 m-resolution 4-band (visible green (G), visible red (R), near infra-red (NIR), medium infra-red (MIR)) Indian Remote sensing Satellite (IRS)-P6 medium resolution Linear Imaging Self-Scanner (LISS)-3 image, acquired over the Veneto region of Italy (Venice lagoon) on 13 June 2006. The raw image is orthorectified and radiometrically calibrated into top-of-atmosphere (TOA) reflectance (TOARF) values (refer to the Part 1, Section 4.2.1 [20]), see Figure 1a. The scene is characterized by the presence of the Adriatic Sea in the east, the city of Venice in the northeast, agricultural land to the south and forested areas in the northwest. The IRS-P6 LISS-3 test image is unique in the scope of this work in that it is the only test image presenting clouds (in the top left portion of the image). This test image is input to the ATCOR™-SPECL single-granule pre-classifier (see Figure 1b, whose legend is shown in Table 2; courtesy of Daniel Schläpfer, ReSe Applications Schläpfer) and to the SPOT-like SIAM™ (S-SIAM™) three-granule pre-classification and three-scale segmentation software product (refer to the Part 1, Tables 3 and 4 [20]), see Figure 1c,d. The S-SIAM™ fine-granularity map legend is shown in Table 3.
- (2).
- One spaceborne 20 m-resolution 4-band (G, R, NIR, MIR) Satellite Pour l’Observation de la Terre (SPOT)-4 High Resolution Visible & Infrared (HRVIR) image, acquired over the Veneto region of Italy across the city area of Verona on 2006-07-21. The raw image is orthorectified and radiometrically calibrated into TOARF values, see Figure 2a. The scene is distinguished by the mountains dominating the northern part of the image, the city area of Verona to the southern portion of the image and a mixture of agricultural and built-up land to the southeast. This test image is input to the ATCOR™-SPECL single-granule pre-classifier (see Figure 2b, whose legend is shown in Table 2; courtesy of Daniel Schläpfer, ReSe Applications Schläpfer) and to the S-SIAM™ three-granule pre-classification and three-scale segmentation software product (refer to the Part 1, Tables 3 and 4 [20]), see Figure 2c,d. The S-SIAM™ fine-granularity map legend is shown in Table 3. Since the SPOT-4 HRVIR test image is similar to the IRS-P6 LISS-3 test image in terms of spectral resolution, spatial resolution and acquisition time, while the surface area depicted in the former is a subset of that of the latter, the difference between the ATCOR™-SPECL and SIAM™ mapping results collected from these two test cases are expected to be (to some degree) correlated (aligned). If verified experimentally, this conjecture would prove, first, the robustness of the two alternative MS image mapping systems to small changes in spectral resolution and image acquisition conditions and, second, the consistency of the proposed protocol for thematic map quality assessment.
- (3).
- One airborne 0.25 m-resolution 4-band (visible blue (B), G, R, NIR) Leica Airborne Digital Scanner (ADS)-80 image, acquired over an unknown location in the French Alps on 1 September 2007. The raw MS image is radiometrically calibrated into surface reflectance (SURF) values, see Figure 3a (courtesy of Daniel Schläpfer, ReSe Applications Schläpfer). Notably, SURF ⊆ TOARF, i.e., SURF values are a special case of TOARF values, where SURF ≈ TOARF in very clear sky conditions and flat terrain conditions [12,32,33] (refer to the Part 1, Section 4.2.1 [20]). In this test case, visible features include dense tree cover in the southern portion and house development in the northern portion of the image. This test image is input to the ATCOR™-SPECL single-granule pre-classifier (see Figure 3b; courtesy of Daniel Schläpfer, ReSe Applications Schläpfer) and to the QuickBird-like SIAM™ (Q-SIAM™) three-granule pre-classification and three-scale segmentation software product (refer to the Part 1, Tables 3 and 4 [20]), see Figure 3c,d. The Q-SIAM™ fine-granularity map legend is shown in Table 4.
3. Probability Sampling Protocol for Thematic Map Accuracy Assessment
- (i)
- Identification of the GEOROI, test map taxonomy, reference sample set taxonomy and “correct” entries in the contingency table (error matrix). A contingency table is the Cartesian product between two discrete and finite sorted sets of concepts, the test and the reference vocabulary, which may not coincide. Before the contingency table is instantiated with probability values, “correct” entries of the contingency table must be selected by a “knowledge engineer” (domain expert) [28]. Identified as CVPSI ∈ [0, 1] (refer to Section 1), a metrological QI of the semantic harmonization between the test and reference map taxonomies is estimated from the distribution of “correct” entries in the contingency table.
- (ii)
- Probability sampling design, where the following decisions must be taken.
- Estimation of the sample set cardinality depending on the project’s requirements specification in terms of: (i) target overall accuracy and confidence interval, (ii) target per-class accuracy and confidence interval and (iii) costs of sampling in compliance with the project budget.
- Selection of the sampling frame. A sampling frame provides a complete partition of a GEOROI into sampling units and allows access to the elements of the target population spread across the GEOROI [35]. There are two types of sampling frames: (one-dimensional) list frames and (two-dimensional) area frames [24].
- Selection of the spatial type(s) of sampling units, e.g., pixel, polygon or block of pixels [35]. For example, these three spatial types of sampling units are appropriate for TQI assessment, but the polygon sampling unit type is necessary for SQI assessment (refer to Section 1).
- Selection of the sampling strategy, e.g., simple random sampling, systematic sampling, stratified random sampling, etc.
- (iii)
- Evaluation protocol. This procedure collects information pertaining to the thematic determination of both reference and test sampling units. Typically, information pertaining to the thematic determination of the reference sampling units is collected by means of field campaigns, photointerpretation of EO images “one step closer to the ground” than the RS data used to make up the test map [36], i.e., EO images whose spatial and/or spectral quality is higher than that of the RS images employed for the generation of the test map, or a combination of these two information sources.
- (iv)
- Labeling protocol, consisting of rules to assign one or more class indexes to each reference sampling unit and each test sampling unit, based on the information collected in the evaluation protocol.
- (v)
- Analysis protocol, where a contingency table, whose “correct” entries are selected in step (i), is instantiated with occurrence or probability values.
- (vi)
- Estimation protocol, where an optimized set of mutually independent summary statistics, e.g., TQIs and SQIs (see Section 1), provided with their confidence interval, are estimated from the contingency table(s) and assessed in comparison with reference standards [2].
3.1. Identification of the GEOROI, Reference Class Taxonomy, Test Map Taxonomy and “Correct” Entries in the Contingency Table
- Two thematic maps of the same GEOROI and featuring the same thematic map’s legend are compared.
- Two thematic maps of the same GEOROI, but featuring two different thematic map’s legends are compared. This second type of thematic map comparison includes the first type as a special case.
3.1.1. Selection of “Correct” Entries in a Contingency Table
3.1.2. Alternative CVPSI Formulations
- Suppose that all elements of the OAMTRX instance of size TC × RC = 14 × 6 = 64 are “correct” entries, such that CE = 64, equivalent to a dumb (non-informative) mapping case. In accordance with condition (A1.c) in the Appendix, it is expected that CVPSI → 0. Based on Equation (A3) to Equation (A5) in the Appendix:This result proves that Equation (A3) to Equation (A5) satisfy constraint (A1.c) when all inter-vocabulary semantic relationships are allowed.
- Suppose CE is defined as the total number of elements identified by yellow checkmarks in Table 8, then CE = 29 ≤ TC × RC = 14 × 6 = 64. In accordance with condition (A1.e) in the Appendix, it is expected that CVPSI1 ∈ (0, 1]. Based on Equation (A3) to Equation (A5) in the Appendix:
- Across image-specific reference vocabularies, the CVPSI values estimated from the SIAM™ three-granule legend increase monotonically with the cardinality of the test set of spectral categories. This evidence proves that the “subjective” work performed by the knowledge engineer, who selected the “correct” entries in the OAMTRX instances, can be considered consistent overall, because it does not hinder an existing correlation among sets of SIAM™’s maps featuring a parent-child relationship (refer to the Part 1, Figure 4 [20]).
- With only one exception in 12 experiments involving both the ATCOR™-SPECL and SIAM™ pre-classifiers, estimated CVPSI values increase with the cardinality of the test set of spectral categories. It means that, in these experiments, the ATCOR™-SPECL semantic vocabulary is correlated with the fine, intermediate and coarse hierarchical levels of the SIAM™ taxonomy (refer to the Part 1, Table 4 [20]). In practice, the ATCOR™-SPECL’s set of spectral categories (refer to Table 2) can be considered as yet-another aggregation of the SIAM™’s set of primitive concepts at fine semantic granularity.
- For the S-SIAM™ and Q-SIAM™ maps at coarse semantic granularity, the CVPSI values are inferior to those of the ATCOR™-SPECL in two out of three cases, where the semantic cardinality of the latter (equal to 19, see Table 2) is greater than those of the former (equal to 15 and 12 respectively, refer to Table 4 in Part 1 [20]).
- Overall, across all test images, both the ATCOR™-SPECL and SIAM™ pre-classifiers accomplish a CVPSI value higher than 50%, which means they both fill at least 50% of the information gap from sensory data to LC classes (refer to the Part 1, Figure 1c [20]), right at the pre-attentive vision first stage, without user interactions and in near real-time, which means at no cost in manpower and computer power.
- Approximately 50% of the information gap from sensory data to LC classes is filled by the SIAM™ pre-classification first stage and accomplished without user’s supervision and in near real-time. To be considered of potential interest, in addition to being informative because its CVPSI value scores high, the SIAM™ pre-classification first stage must also be accurate, i.e., its TQIs and SQIs must score high simultaneously with the CVPSI.
3.2. Probability Sampling Design
3.2.1. Reference Sample Set Cardinality and Degree of Uncertainty in Measurement
Statistical Level of Confidence and Level of Significance of a Sample overall Accuracy
- In the case where two confidence intervals do not overlap at all, it is possible to draw the conclusion that there is a statistically significant difference (at the confidence level (1−∝) or significance level ∝) between the two accuracy estimates.
- If two confidence intervals overlap such that the central point of one or other interval falls within the second interval, then there is no statistically significant difference (at the confidence level (1−∝) or significance level ∝) between the two estimates.
- In the third case, where the intervals overlap but the central point of neither interval lies within the second interval, “we cannot draw a conclusion about the significance of the relative algorithm performance and we must resort to different methods to formally determine the statistical significance of the differences between two algorithms, such as non-parametric tests independent of the underlying distribution, like the Sign test, suitable to determine the significance of the difference between a summary statistic of two different distributions, and the Kolmogorov-Smirnov test, used to investigate the statistical significance of the differences between the distributions themselves” [37].
- In accordance with the U.S. Geological Survey (USGS) standards, the target probability estimate, pOA, and associated confidence interval, ± δ, is fixed at 0.85 ± 2% [13]. The significance level, ∝, is fixed at 0.05, thus = ≈ 3.84.
- Per-class accuracy estimates, pOA,c, and associated confidence intervals, ± δ, should be consistent and greater than or equal to 0.70% ± 5% [13,53]. In this work, the reference per-class accuracy, pOA,c, is considered equal to 0.85% ± 5%. Additionally, the per-class significance level, ∝/C, is fixed at 0.01, thus = ≈ 6.63.
- According to Equation (4), the minimum sample set size, independent of the test image and sampling costs, necessary to assess the overall accuracy assuming USGS parameters is
- ○
- According to Equation (6), the minimum sample set size (dependent upon the test image reference class set, RC) necessary to assess the per-class accuracy assuming the previously defined parameters is
- ○
- ○ The number of samples per image is the product of the number of reference classes, RC, and the per-class sample set size, SSSc. For example,
- ▪ The minimum total number of samples necessary for the IRS test image is RC × 340 = 6 × 340 = 2,040.
- ▪ The minimum total number of samples necessary for the SPOT test image is RC × 340 = 5 × 340 = 1,700.
- ▪ The minimum total number of samples necessary for the Leica test image is RC × 340 = 6 × 340 = 2,040, plus “Outliers”.
3.2.2. Selection of the Sampling Frame
3.2.3. Selection of the Spatial Types of Sampling Units
- Pixels, representing small areas (e.g., 30 m pixel), are related to the dimensionless sample location described in Section 3.2.2, but because pixels still possess some areal extent, they partition the mapped population into a finite, though large, number of sampling units.
- Polygons, typically irregular in shape and differing in size to approximate the shape and size of a target 3-D object, e.g., a target building.
- Fixed-area plots, generally regular in shape and area which cover a chosen areal extent (typically a 3 × 3 or 5 × 5 pixel plot).
3.2.4. Selection of the Sampling Strategy
3.3. Response Design: Evaluation and Labeling Protocol
3.4. Analysis and Estimation Protocol
3.4.1. Thematic Accuracy Assessment of a Classification Map
TQI Formulations
Overall Accuracy Estimation
Producer’s Accuracy Estimation
User’s Accuracy Estimation
3.4.2. Spatial Accuracy Assessment of a Classification Map
SQI Formulations
SQI Estimation
3.4.3. Remarks
4. QIOs Assessment
- (i)
- Degree of automation. It is estimated as the inverse of the number of system free-parameters to be user-defined, which is null, hence degree of automation is maximum, i.e., it cannot be surpassed by alternative approaches. Both preliminary classifiers are termed “fully automatic” [21], i.e., they require neither input parameters to be user-defined nor training data to run (refer to the Part 1, Section 4.1 [20]).
- (ii)
- Effectiveness, intended as accuracy of the pre-classification map. Map accuracy measures are split into independent QIs, namely, TQIs, SQIs and the CVSPI, see Section 3. The TQI values of the SIAM™ tend to be significantly higher (in statistical terms) than the ATCOR™-SPECL’s. Also the CVPSI values of the SIAM™ at the intermediate and fine semantic granularities are higher than those of the ATCOR™-SPECL single-granule maps. Estimated for the SIAM™ exclusively, SQIs tend to be lower than their corresponding TQIs (refer to Section 3.4.2).
- (iii)
- Efficiency is estimated as the inverse of computation time, because memory occupation is negligible, both algorithms being pixel-based. The two deductive pre-classifiers are context-insensitive (pixel-based), non-iterative (one-pass) and non-adaptive to input data (prior knowledge-based), hence they are computationally efficient. For example, in a laptop computer provided with a Windows operating system, SIAM™ requires three minutes to generate as output three pre-classification maps from a 7-band Landsat full scene, approximately 7,000 × 7,000 pixels in size. In practice, both pre-classifiers can be considered near real-time.
- (iv)
- Robustness to changes in input parameters cannot be surpassed by alternative approaches, because no system free-parameter exists.
- (v)
- Robustness to changes in input data acquired across time, space and sensors is investigated in Section 3, in addition to the existing literature [6–19]. It can be considered (qualitatively) “high”. This is due to a combination of effects. First, the required radiometric calibration constraint guarantees harmonization of MS data acquired across time, space and sensors (refer to the Part 1, Section 4.2.1 [20]). Second, the two pre-classifiers are pixel-based, i.e., both systems work at the spatial resolution of the imaging sensor whatever it is, i.e., they are spatial resolution-independent. Third, the two rule-based mapping system implementations pursue redundancy of the rule set. Actually, redundancy of the SIAM™ rule set appears far superior to that of the ATCOR™-SPECL rule set at the expense of a higher level of software complexity of the former. In practice, both systems are eligible for use with any existing or future planned spaceborne/airborne optical mission whose spectral resolution overlaps with Landsat’s, irrespective of spatial resolution (e.g., refer to the Part 1, Table 3 and the Part 1, Table 4 [20]). For example, starting from a Landsat spectral resolution of seven bands, ranging from visible to thermal electromagnetic wavelengths (refer to the Part 1, Tables 3 and 4 [20]), the SIAM™ decision tree can work with as low as two input bands, namely, one visible and one NIR channel [12–14].
- (vi)
- (vii)
- Timeliness, from data acquisition to data-derived high-level product generation, is equivalent to computation time, because user interactions are zero. Since their computation time is low then their timeliness is extremely favorable (“low”).
- (viii)
- Costs. The combination of high computation efficiency with no user interactions implies that costs in computer power and manpower are “low”.
5. Conclusions
- ➢ A Categorical Variable Pair Similarity Index (CVPSI) ∈ [0, 1]. The CVPSI is a normalized estimate of the degree of semantic harmonization (reconciliation) between the test and reference class taxonomies which, in general, may not coincide. Vice versa, (1 − CVPSI) ∈ [0, 1] is a normalized estimate of the residual of the semantic gap from sub-symbolic data to symbolic reference classes filled up, totally or in part, by the intermediate vocabulary of test classes. In the present Part 2 of this paper, a novel CVPSI2 formulation is proposed (refer to the Appendix).
- ➢ A set of symbolic pixel-based thematic quality indicators (TQIs), independent of a set of sub-symbolic polygon-based Spatial Quality Indicators (SQIs). These two sets of QIs are eligible for coping with the well-known non-injective property of any QI (refer to the Part 1, Section 2.5 [20]). Selected symbolic pixel-based TQIs are the overall accuracy, user's and producer's accuracies. Selected sub-symbolic object-based SQIs assess oversegmentation, undersegmentation and fuzzy edge overlap phenomena. In accordance with the Part 1, Section 3 [20], these TQIs and SQIs feature:
- Statistical significance, i.e., TQIs and SQIs are provided with a degree of uncertainty in measurement at a known level of statistical significance, in compliance with the principles of statistics and the QA4EO requirements [2].
- (1)
- Degree of semantic harmonization between output spectral categories (e.g., “vegetation”) and target land cover (LC) classes (e.g., “deciduous forest”). In all test images, the CVPSI values of the SIAM™ maps at fine and intermediate granularity are superior to those of the ATCOR™-SPECL single-granule maps, whose semantic cardinality is smaller (vice versa, whose semantic granularity is coarser). Notably, in both the ATCOR™-SPECL and the SIAM™ deductive pre-classification first stage, more than 50% of the information gap from sensory data to LC classes (see Table 14) is filled up automatically and in near real-time by spectral categories (refer to the Part 1, Figure 1c [20]), irrespective of the mapping accuracy estimated via TQIs and SQIs.
- (2)
- Pre-classification map’s semantic accuracy. Across the three test images and the SIAM™’s three semantic granularities, symbolic pixel-based TQIs of the SIAM™ tend to be significantly higher (in statistical terms) than the ATCOR™-SPECL’s. In the only image of the test set where clouds are present, the ATCOR™-SPECL pre-classifier scores extremely low (16.47% ± 5.18%) in the detection of the reference LC class “Cloud/Shadow” (“Cl/Sh”). This indicates that the ATCOR™-SPECL implementation of spectral-based decision rules capable of mapping clouds and cloud-shadows requires a significant improvement.
- (3)
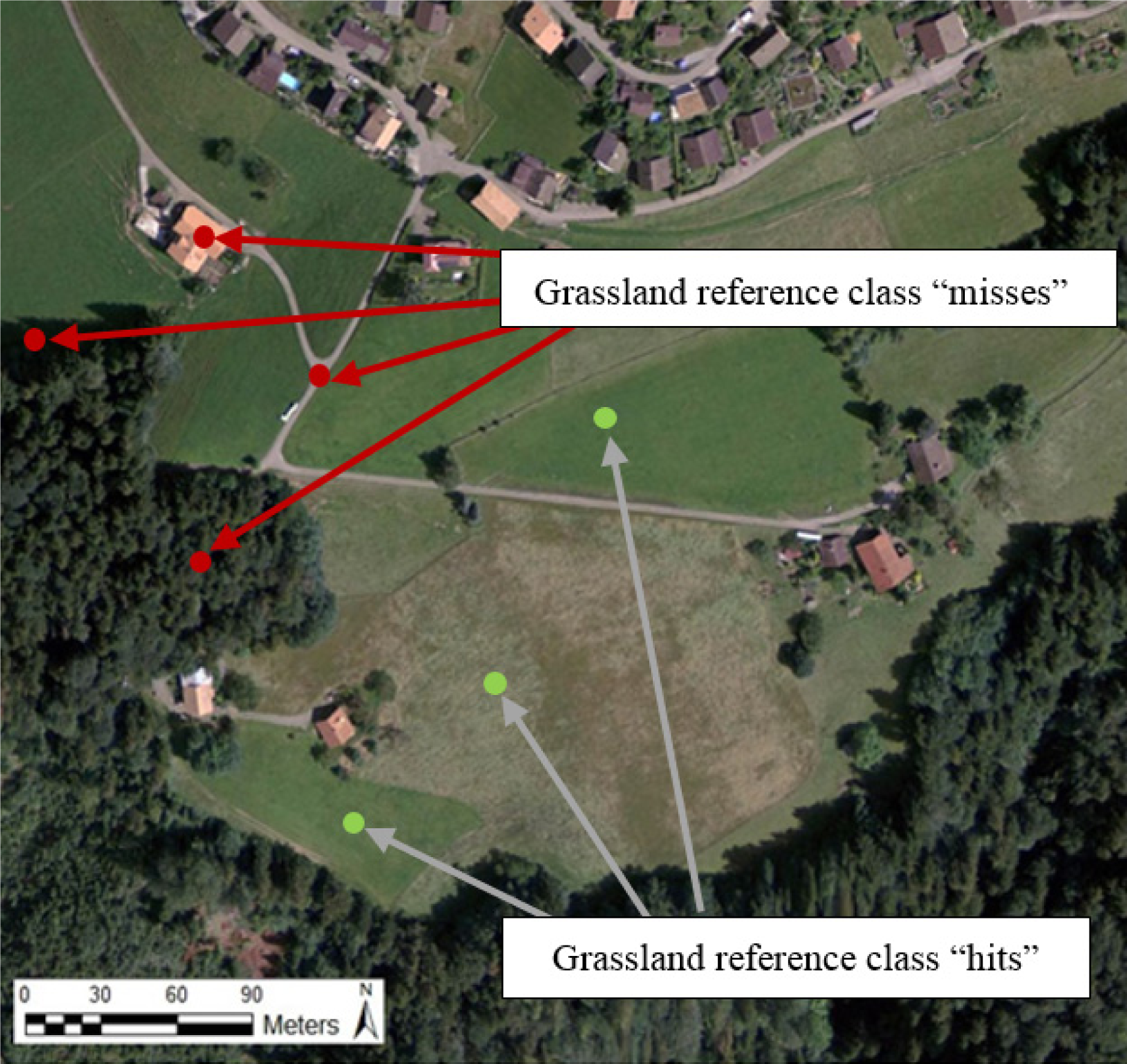
- Pre-classification map’s spatial accuracy. In a three-scale segmentation map automatically generated from the SIAM™’s three-granule pre-classification map of the very high resolution airborne Leica test image, SQI values tend to increase (respectively, decrease) with the SIAM™’s semantic cardinality (respectively, semantic granularity). These SQI estimates are negatively biased (underestimated) compared to TQI values due to: (i) their inability to model many-to-many associations between reference and test classes and (ii) undesired neighboring effects pointed out in this work (see Figures 6 and 7).
- (4)
- Collected QIO values, including the aforementioned CVPSI, TQI and SQI values, reveal that the peculiar capability of the two alternative ATCOR™-SPECL and SIAM™ deductive pre-classifiers, which is to infer automatically and in near real-time output spectral categories from an input single-date MS imagery, does not come at the expense of accuracy, robustness to changes in the input data set or scalability, but at the expense of the informative content of the output spectral-based semi-concepts, whose semantic meaning is “low”, namely, equal or inferior to that of target 4-D LC classes-through-time.
Acronyms and Abbreviations
| ADS | Airborne Digital Scanner |
| ATCOR™ | Atmospheric/Topographic Correction™ |
| ASQI | Average Spatial Quality Indicator |
| B | (Visible) Blue |
| CEOS | Committee on Earth Observation Satellites |
| CMTRX | (Square and sorted) Confusion Matrix |
| CVPSI | Categorical Variable Pair Similarity Index |
| EO | Earth Observation |
| FEOQI | Fuzzy Edge Overlap Spatial Quality Indicator |
| G | (Visible) Green |
| GEOBIA | Geographic Object-Based Image Analysis |
| GEOOIA | Geographic Object-Observation Image Analysis |
| GEOROI | Geographic Region Of Interest |
| GIS | Geographic Information System |
| HR | High Resolution |
| HRVIR | High Resolution Visible & Infrared |
| IR | Infra-Red |
| IRS | Indian Remote sensing Satellite |
| LAI | Leaf Area Index |
| LC | Land Cover |
| LCC | Land Cover Change |
| LISS | medium resolution Linear Imaging Self-Scanner |
| MIR | Medium infra-red |
| MODIS | Moderate Resolution Imaging Spectroradiometer |
| MS | Multi-Spectral |
| OAMTRX | Overlapping Area Matrix |
| OSQI | Oversegmentation Spatial Quality Indicator |
| QA4EO | Quality Accuracy Framework for Earth Observation |
| QI | Quality Indicator |
| QIO | Quality Indicator of Operativeness |
| Q-SIAM™ | QuickBird-like Satellite Image Automatic Mapper™ |
| R | (visible) Red |
| RS | Remote Sensing |
| RS-IUS | Remote Sensing Image Understanding System |
| SIAM™ | Satellite Image Automatic Mapper™ |
| SIRS | Simple random sampling |
| SPECL | Spectral Classification of surface reflectance signatures |
| SPOT | Satellite Pour l’Observation de la Terre |
| SQI | Spatial Quality Indicator |
| S-SIAM™ | SPOT-like Satellite Image Automatic Mapper™ |
| SURF | Surface Reflectance |
| TIR | Thermal Infra-Red |
| TM | Trademark |
| TO | Target image-Object |
| TOA | Top-Of-Atmosphere |
| TOARF | Top-Of-Atmosphere Reflectance |
| TQI | Thematic Quality Indicator |
| USGS | US Geological Survey |
| USQI | Undersegmentation Spatial Quality Indicator |
| VHR | Very High Resolution |
Acknowledgments
Conflict of Interest
References
- Global Earth Observation (GEO). The Global Earth Observation System of Systems (GEOSS) 10-Year Implementation Plan, 16 February 2005. Available online: http://www.earthobservations.org/docs/10-Year%20Implementation%20Plan.pdf (accessed on 15 November 2012).
- Global Earth Observation (GEO)/Committee on Earth Observation Satellites (CEOSS). A Quality Assurance Framework for Earth Observation, Version 4.0;; 2010. Available online: http://qa4eo.org/docs/QA4EO_Principles_v4.0.pdf (accessed on 15 November 2012).
- Committee on Earth Observation Satellites (CEOS). CEOS Working Group on Calibration and Validation—Land Product Validation Subgroup. Available online: http://lpvs.gsfc.nasa.gov/ (accessed on 10 January 2012).
- Gutman, G.; Janetos, A.C.; Justice, C.O.; Moran, E.F.; Mustard, J.F.; Rindfuss, R.R.; Skole, D.; Turner, B.L.; Cochrane, M.A. Land Change Science; Kluwer: Dordrecht, The Netherlands, 2004. [Google Scholar]
- Marr, D. Vision; W.H. Freeman and Company: San Francisco, CA, USA, 1982. [Google Scholar]
- Dorigo, W.; Richter, R.; Baret, F.; Bamler, R.; Wagner, W. Enhanced automated canopy characterization from hyperspectral data by a novel two step radiative transfer model inversion approach. Remote Sens 2009, 1, 1139–1170. [Google Scholar]
- Richter, R.; Schläpfer, D. “Atmospheric/Topographic Correction for Satellite Imagery,” ATCOR-2/3 User Guide, Version 8.2.1; DLR/ReSe, DLR-IB 565-01/13;; DLR: Wessling, Germany, 2013. Available online: http://www.rese.ch/pdf/atcor3_manual.pdf (accessed on 28 May 2013).
- Richter, R.; Schläpfer, D. “Atmospheric/Topographic Correction for Airborne Imagery,” ATCOR-4 User Guide, Version 6.2.1; DLR-IB 565-02/13;; DLR: Wessling, Germany, 2013. Available online: http://www.rese.ch/pdf/atcor4_manual.pdf (accessed on 28 May 2013).
- Schläpfer, D.; Richter, R.; Hueni, A. Recent Developments in Operational Atmospheric and Radiometric Correction of Hyperspectral Imagery. Proceeding of the 6th EARSeL SIG IS Workshop, Tel-Aviv, Israel, 16–19 March 2009.
- Baraldi, A. Impact of radiometric calibration and specifications of spaceborne optical imaging sensors on the development of operational automatic remote sensing image understanding systems. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens 2009, 2, 104–134. [Google Scholar]
- Baraldi, A.; Puzzolo, V.; Blonda, P.; Bruzzone, L.; Tarantino, C. Automatic spectral rule-based preliminary mapping of calibrated Landsat TM and ETM+ images. IEEE Trans. Geosci. Remote Sens 2006, 44, 2563–2586. [Google Scholar]
- Baraldi, A.; Durieux, L.; Simonetti, D.; Conchedda, G.; Holecz, F.; Blonda, P. Automatic spectral rule-based preliminary classification of radiometrically calibrated SPOT-4/-5/IRS, AVHRR/MSG, AATSR, IKONOS/QuickBird/OrbView/GeoEye and DMC/SPOT-1/-2 imagery—Part I: System design and implementation. IEEE Trans. Geosci. Remote Sens 2010, 48, 1299–1325. [Google Scholar]
- Baraldi, A.; Durieux, L.; Simonetti, D.; Conchedda, G.; Holecz, F.; Blonda, P. Automatic spectral rule-based preliminary classification of radiometrically calibrated SPOT-4/-5/IRS, AVHRR/MSG, AATSR, IKONOS/QuickBird/OrbView/GeoEye and DMC/SPOT-1/-2 imagery—Part II: Classification accuracy assessment. IEEE Trans. Geosci. Remote Sens 2010, 48, 1326–1354. [Google Scholar]
- Baraldi, A.; Durieux, L.; Simonetti, D.; Conchedda, G.; Holecz, F.; Blonda, P. Corrections to Automatic spectral rule-based preliminary classification of radiometrically calibrated SPOT-4/-5/IRS, AVHRR/MSG, AATSR, IKONOS/QuickBird/OrbView/GeoEye and DMC/SPOT-1/-2 Imagery. IEEE Trans. Geosci. Remote Sens 2010, 48, 1635. [Google Scholar]
- Baraldi, A.; Simonetti, D.; Gironda, M. Operational two-stage stratified topographic correction of spaceborne multi-spectral imagery employing an automatic spectral rule-based decision-tree preliminary classifier. IEEE Trans. Geosci. Remote Sens 2010, 48, 112–146. [Google Scholar]
- Baraldi, A.; Wassenaar, T.; Kay, S. Operational performance of an automatic preliminary spectral rule-based decision-tree classifier of spaceborne very high resolution optical images. IEEE Trans. Geosci. Remote Sens 2010, 48, 3482–3502. [Google Scholar]
- Baraldi, A. Fuzzification of a crisp near-real-time operational automatic spectral-rule-based decision-tree preliminary classifier of multisource multispectral remotely sensed images. IEEE Trans. Geosci. Remote Sens 2011, 49, 2113–2134. [Google Scholar]
- Baraldi, A.; Boschetti, L. Operational automatic remote sensing image understanding systems: Beyond Geographic Object-Based and Object-Oriented Image Analysis (GEOBIA/GEOOIA)—Part 1: Introduction. Remote Sens 2012, 4, 2694–2735. [Google Scholar]
- Baraldi, A.; Boschetti, L. Operational automatic remote sensing image understanding systems: Beyond Geographic Object-Based and Object-Oriented Image Analysis (GEOBIA/GEOOIA)—Part 2: Novel system architecture, information/knowledge representation, algorithm design and implementation. Remote Sens 2012, 4, 2768–2817. [Google Scholar]
- Baraldi, A.; Humber, M.; Boschetti, L. Quality assessment of pre-classification maps generated from spaceborne/airborne multi-spectral images by the Satellite Image Automatic Mapper™ and Atmospheric/Topographic Correction-Spectral Classification software products: Part 1—Theory, submitted for consideration for publication. Remote Sens, 2013; submitted. [Google Scholar]
- Yu, Q.; Clausi, D.A. SAR sea-ice image analysis based on iterative region growing using semantics. IEEE Trans. Geosci. Remote Sens 2007, 45, 3919–3931. [Google Scholar]
- Cherkassky, V.; Mulier, F. Learning from Data: Concepts, Theory, and Methods; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Clarendon Press: Oxford, UK, 1995. [Google Scholar]
- Stehman, S.V.; Czaplewski, R.L. Design and analysis for thematic map accuracy assessment: Fundamental principles. Remote Sens. Environ 1998, 64, 331–344. [Google Scholar]
- Overton, W.S.; Stehman, S.V. The Horvitz-Thompson theorem as a unifying perspective for probability sampling: With examples from natural resource sampling. Am. Stat 1995, 49, 261–268. [Google Scholar]
- Capurro, R.; Hjørland, B. The concept of information. Annu. Rev. Inform. Sci. Technol 2003, 37, 343–411. [Google Scholar]
- Capurro, R. Hermeneutics and the Phenomenon of Information. In Metaphysics, Epistemology, and Technology: Research in Philosophy and Technology; JAI/Elsevier: Amsterdam, The Netherlands, 2000; Volume 19, pp. 79–85. [Google Scholar]
- Laurini, R.; Thompson, D. Fundamentals of Spatial Information Systems; Academic Press: London, UK, 1992. [Google Scholar]
- Mather, P. Computer Processing of Remotely-Sensed Images—An Introduction; John Wiley & Sons: Chichester, UK, 1994. [Google Scholar]
- Matsuyama, T.; Hwang, V.S. SIGMA: A Knowledge-Based Aerial Image Understanding System; Plenum Press: New York, NY, USA, 1990. [Google Scholar]
- Sonka, M.; Hlavac, V.; Boyle, R. Image Processing and Machine Vision; Thompson Learning: Toronto, ON, Canada, 2008. [Google Scholar]
- Baraldi, A.; Boschetti, L.; Humber, M. Probability sampling protocol for thematic and spatial quality assessments of classification maps generated from spaceborne/airborne very high resolution images. In IEEE Trans. Geosci. Remote Sens.; 2014; in press. [Google Scholar]
- Chavez, P.S. An improved dark-object subtraction technique for atmospheric scattering correction of multispectral data. Remote Sens. Environ 1988, 24, 459–479. [Google Scholar]
- Kuzera, K.; Pontius, R.G. Importance of matrix construction for multiple-resolution categorical map comparison. GIScience Remote Sens 2008, 45, 249–274. [Google Scholar]
- Stehman, S.V.; Wickham, J.D. Pixels, blocks of pixels, and polygons: Choosing a spatial unit for thematic accuracy assessment. Remote Sens. Environ 2011, 115, 3044–3055. [Google Scholar]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data; Lewis Publishers: Boca Raton, FL, USA, 1999. [Google Scholar]
- Stehman, S.V. Comparing thematic maps based on map value. Int. J. Remote Sens 1999, 20, 2347–2366. [Google Scholar]
- Ahlqvist, O. Extending post-classification change detection using semantic similarity metrics to overcome class heterogeneity: A study of 1992 and 2001 US National Land Cover Database changes. Remote Sens. Environ 2008, 112, 1226–1241. [Google Scholar]
- Herold, M.; Woodcock, C.; di Gregorio, A.; Mayaux, P.; Belward, A.S.; Latham, J.; Schmullius, C. A joint initiative for harmonization and validation of land cover datasets. IEEE Trans. Geosci. Remote Sens 2006, 44, 1719–1727. [Google Scholar]
- Feng, C.C.; Flewelling, D.M. Assessment of semantic similarity between land use/land cover classification systems. Comput. Environ. Urban Syst 2004, 28, 229–246. [Google Scholar]
- Kavouras, M.; Kokla, M. A method for the formalization and integration of geographical categorizations. Int. J. Geogr. Inf. Sci 2002, 16, 439. [Google Scholar]
- Fonseca, F.; Egenhofer, M.; Agouris, P.; Câmara, G. Using ontologies for integrated geographic information systems. Trans. GIS 2002, 6, 231–257. [Google Scholar]
- Fonseca, F.; Egenhofer, M.; Davis, C.; Câmara, G. Semantic granularity in ontology-driven geographic information systems. AMAI Ann. Math. Artif. Intell 2002, 36, 121–151. [Google Scholar]
- Cerba, O.; Charvat, K.; Jezek, J. Data Harmonization towards CORINE Land Cover. Available online: www.efita.net/apps/accesbase/bindocload.asp (accessed on 6 November 2012).
- Goodchild, M.F.; Yuan, M.; Cova, T.J. Towards a general theory of geographic representation in GIS. Int. J. Geogr. Inf. Sci 2007, 21, 239–260. [Google Scholar]
- Adams, J.B.; Donald, E.S.; Kapos, V.; Almeida Filho, R.; Roberts, D.A.; Smith, M.O.; Gillespie, A.R. Classification of multispectral images based on fractions of endmembers: Application to land-cover change in the Brazilian Amazon. Remote Sens. Environ 1995, 52, 137–154. [Google Scholar]
- Ahlqvist, O. Using uncertain conceptual spaces to translate between land cover categories. Int. J. Geogr. Inf. Sci 2005, 19, 831–857. [Google Scholar]
- Beauchemin, M.; Thomson, K.P.B. The evaluation of segmentation results and the overlapping area matrix. Int. J. Remote Sens 2010, 18, 3895–3899. [Google Scholar]
- Baraldi, A.; Bruzzone, L.; Blonda, P. Quality assessment of classification and cluster maps without ground truth knowledge. IEEE Trans. Geosci. Remote Sens 2005, 43, 857–873. [Google Scholar]
- Lunetta, R.S.; Elvidge, C.D. Remote Sensing Change Detection: Environmental Monitoring Methods and Applications; Taylor & Francis: London, UK, 1999; pp. 288–300. [Google Scholar]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ 1997, 62, 77–89. [Google Scholar]
- Anonymous FTP. Available online: ftp://ftp.iluci.org/Paper/remotesensing-29006_2013 (accessed on 15 October 2013).
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ 2002, 80, 185–201. [Google Scholar]
- Pontius, R.G. Quantification error versus location error in comparison of categorical maps. Photogramm. Eng. Remote Sens 2000, 66, 1011–1016. [Google Scholar]
- Persello, C.; Bruzzone, L. A novel protocol for accuracy assessment in classification of very high resolution images. IEEE Trans. Geosci. Remote Sens 2010, 48, 1232–1244. [Google Scholar]
- Pontius, R.G.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens 2011, 32, 4407–4429. [Google Scholar]
- Pontius, R.G.; Connors, J. Expanding the Conceptual, Mathematical and Practical Methods for Map Comparison. Proceedings of the Meeting on Spatial Accuracy, Lisbon, Portugal, 5–7 July 2006; pp. 64–79.
- Nishii, R.; Tanaka, S. Accuracy and inaccuracy assessments in landcover classification. IEEE Trans. Geosci. Remote Sens 1999, 37, 491–498. [Google Scholar]
- Lang, S. Chapter 1.1. Object-Based Image Analysis for Remote Sesning Applications: Modeling Reality-Dealing with Complexity. In Object-Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications; Blaschke, T., Lang, S., Hay, G.J., Eds.; Springer-Verlag: New York, NY, USA, 2008; pp. 3–27. [Google Scholar]
- Definiens Imaging GmbH. eCognition Elements User Guide 4; Definiens Imaging GmbH: Munich, Germany, 2004. [Google Scholar]
- Definiens, A.G. Developer 8 Reference Book; Definiens AG: Munich, Germany, 2011. [Google Scholar]
- Esch, T.; Thiel, M.; Bock, M.; Roth, A.; Dech, S. Improvement of image segmentation accuracy based on multiscale optimization procedure. IEEE Geosci. Remote Sens. Lett 2008, 5, 463–467. [Google Scholar]
- Baatz, M.; Schäpe, A. Multiresolution Segmentation: An Optimization Approach for High Quality Multi-Scale Image Segmentation. In Angewandte Geographische Informationsverarbeitung XII; Strobl, J., Ed.; Herbert Wichmann Verlag: Berlin, Germany, 2000; Volume 58, pp. 12–23. [Google Scholar]
- Baatz, M.; Hoffmann, C.; Willhauck, G. Chapter 1.4. Progressing from Object-Based to Object-Oriented Image Analysis. In Object-Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications; Blaschke, T., Lang, S., Hay, G.J., Eds.; Springer-Verlag: New York, NY, USA, 2008; pp. 29–42. [Google Scholar]
- Trimble eCognition Developer. Available online: http://www.ecognition.com/products/ecognition-developer (accessed on 15 November 2012).
- Hay, G.J.; Castilla, G. Object-Based Image Analysis: Strengths, Weaknesses, Opportunities and Threats (SWOT). Proceedings of the 1st International Conference on Object-Based Image Analysis (OBIA), Salzburg, Austria, 4–5 July 2006.
- McGlone, J.C.; Shufelt, J.A. Projective and Object Space Geometry for Monocular Building Extraction. Proceedings of the 1994 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 54–61.
- Hermosilla, T.; Ruiz, L.; Recio, J.; Estornell, J. Evaluation of automatic building detection approaches combining high resolution images and LiDAR data. Remote Sens 2011, 3, 1188–1210. [Google Scholar]
- Hadamard, J. Sur les problemes aux derivees partielles et leur signification physique. Princet. Univ. Bull 1902, 13, 49–52. [Google Scholar]
Appendix: Alternative Formulations of the CVPSI Estimated from an OAMTRX Instance
A1. Categorical Variable Pair Similarity Index, Version 1, CVPSI1, Where “correct” Inter-Vocabulary Reference-Test Class Relations are One-to-One
- (A1.a)
- (A1.b)
- If (CE == 0) then CVPSI1 = 0. It means that, when no “correct” entry exists, then the degree of match between the two categorical variables is zero.
- (A1.c)
- If (CE == RC×TC) then CVPSI1 → 0. It means that when all table entries are considered “correct”, then nothing is meaningful or makes the difference between the two categorical variables.
- (A1.d)
- Ifi.e., if [(CERC = RC) AND (CETC = TC)], then CVPSI1 = 1. It means that when the reference and test map legends “match” each other by means of one-to-one relations exclusively, then the OAMTRX is equivalent to a (square and sorted) CMTRX and CVPSI1 is maximum.
- (A1.e)
- If [not condition(A1.b) AND not condition(A1.c) AND not condition(A1.d)] then CVPSI1 ∈ (0,1).
A2. Categorical Variable Pair Similarity Index, Version 2, CVPSI2, Where “correct” Test-to-Reference Class Relations are Considered One-to-One, While “correct” Reference-to-Test Class Relations Can be One-to-Many

- (A2.a)
- Same as in CVPSI1.
- (A2.b)
- Same as in CVPSI1. If (CE == 0) then CVPSI2 = 0. It means that, when no “correct” entry exists, then the degree of match between the two categorical variables is zero.
- (A2.c)
- Same as in CVPSI1. If (CE == RC×TC) then CVPSI2 → 0. It means that when all table entries are considered “correct”, then nothing is meaningful or makes the difference between the two categorical variables.
- (A2.d)
- Ifthen CVPSI2 is maximum, i.e., CVPSI2 = 1.
- (A2.e)
- If [not condition(A2.b) AND not condition(A2.c) AND not condition(A2.d)] then CVPSI2 ∈ (0,1).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test image | Sensor | Radiometric Calibration | Acquisition Date and Time | Central Image, Geographic Coordinates | Spatial Resolution (m) | Swath Width | Spectral Resolution (μm) per Band |
|---|---|---|---|---|---|---|---|
| Spaceborne IRS-P6 | LISS-3 | TOARF | 2006-06-13, 10:15:05.83 | 11°53′E, 45°8′N (Northern Italy) | 23.5 | 141 × 141 km | 1-G: 0.52–0.59, 2-R: 0.62–0.68, 3-NIR: 0.77–0.86, 4-MIR: 1.55–1.70 |
| Spaceborne SPOT-4 | HRVIR | TOARF | 2006-07-21, 10:34:42 | 10°10′E, 45°36′N (Veneto region, Italy) | 20 | 60 × 60 km | 1-G: 0.50–0.59, 2-R: 0.61–0.68, 3-NIR: 0.78–0.89, 4-MIR: 1.58–1.75 |
| Airborne | ADS-80 | SURF | 2007-09-01 | 6°37′E, 46°06′N (East France) | 0.25 | 64 (degrees) | 1-B: 0.420–0.492, 2-G: 0.533–0.587, 3-R: 0.604–0.664, 4-NIR: 0.833–0.920 |
| Index | Spectral Category | Pseudo-Color |
|---|---|---|
| 1 | Snow/ice |  |
| 2 | Cloud |  |
| 3 | Bright bare soil/sand/cloud |  |
| 4 | Dark bare soil |  |
| 5 | Average vegetation |  |
| 6 | Bright vegetation |  |
| 7 | Dark vegetation |  |
| 8 | Yellow vegetation |  |
| 9 | Mix of vegetation/soil |  |
| 10 | Asphalt/dark sand |  |
| 11 | Sand/bare soil/cloud |  |
| 12 | Bright sand/bare soil/cloud |  |
| 13 | Dry vegetation/soil |  |
| 14 | Sparse veg./soil |  |
| 15 | Turbid water |  |
| 16 | Clear water |  |
| 17 | Clear water over sand |  |
| 18 | Shadow |  |
| 19 | Not classified (outliers) |  |
| Spectral Category | Pseudo-Color |
|---|---|
| “High” leaf area index (LAI) vegetation types (LAI values decreasing left to right) |  |
| “Medium” LAI vegetation types (LAI values decreasing left to right) |  |
| Shrub or herbaceous rangeland |  |
| Other types of vegetation (e.g., vegetation in shadow, dark vegetation, wetland) |  |
| Bare soil or built-up |  |
| Deep water, shallow water, turbid water or shadow |  |
| Thick cloud and thin cloud over vegetation, or water, or bare soil |  |
| Thick smoke plume and thin smoke plume over vegetation, or water, or bare soil |  |
| Snow and shadows snow |  |
| Unknowns |  |
| Spectral Category | Pseudo-Color |
|---|---|
| “High” leaf area index (LAI) vegetation types (LAI values decreasing left to right) |  |
| “Medium” LAI vegetation types (LAI values decreasing left to right) |  |
| Shrub or herbaceous rangeland |  |
| Other types of vegetation (e.g., vegetation in shadow, dark vegetation, wetland) |  |
| Bare soil or built-up |  |
| Deep water, shallow water, turbid water or shadow |  |
| Smoke plume over water, over vegatation or over bare soil |  |
| Snow and shadows snow |  |
| Unknowns |  |
| Reference Class Acronym | Spatial Type | Definition |
|---|---|---|
| Cl/Sh | Pixel | Clouds or cloud shadows or strong shadows over bare soil or strong shadows over vegetation |
| BBS | Pixel | Built-up or Bare Soil |
| Range/MP | Pixel | Rangeland or mixed vegetation/soil pixels |
| VL-M NIR | Pixel | Vegetation with very low to medium NIR response (TOARF values in range {0, 255} < 80) |
| H-VH NIR | Pixel | Vegetation with high to very high NIR response (TOARF values in range {0, 255} ≥ 80) |
| Water | Pixel | All bodies of water, including oceans, lagoons, rivers, lakes, etc. |
| Reference Class Acronym | Spatial Type | Definition |
|---|---|---|
| BBS | Pixel | Built-up or Bare Soil |
| Range/MP | Pixel | Rangeland or mixed vegetation/soil pixels |
| VL-M NIR | Pixel | Vegetation with very low to medium NIR response (TOARF values in range {0, 255} < 80) |
| H-VH NIR | Pixel | Vegetation with high to very high NIR response (TOARF values in range {0, 255} ≥ 80) |
| Water | Pixel | All bodies of water, including oceans, lagoons, rivers, lakes, etc. |
| Reference Class Acronym | Spatial Type | Definition |
|---|---|---|
| LtBBrS | Polygon if building, otherwise pixel | Light-tone Built-up or Bright Bare Soil distinguished by high response in visible wavelength |
| DkBDkS | Polygon if building, otherwise pixel | Dark-tone Built-up or Dark Bare Soil distinguished by low response in visible wavelength |
| NDVI1 | Pixel | Grassland with high NDVI (≥0.7) |
| NDVI2 | Pixel | Grassland with lower NDVI (<0.7) |
| TrCr | Pixel | Tree Crowns |
| SH | Pixel | Shadow over vegetation, built-up, or soil land covers |
| Outlier | Pixel | Unidentifiable objects |
| Spectral Category | Cl/Sh | BBS | Range/MP | VL-M NIR | H-VH NIR | Water |
|---|---|---|---|---|---|---|
| Bare Soil | X | ✓ | X | X | X | X |
| Average Vegetation | X | X | ✓ | ✓ | ✓ | X |
| Bright Vegetation | X | X | ✓ | ✓ | ✓ | X |
| Dark Vegetation | X | X | ✓ | ✓ | ✓ | X |
| Yellow Vegetation | X | X | ✓ | ✓ | ✓ | X |
| Mix of Vegetation/Soil | X | ✓ | ✓ | ✓ | ✓ | X |
| Asphalt/Dark Sand | X | ✓ | X | X | X | X |
| Sand/Bare Soil/Cloud | ✓ | ✓ | X | X | X | X |
| Bright Sand/Soil/Cloud | ✓ | ✓ | X | X | X | X |
| Dry Vegetation/Soil | X | ✓ | ✓ | X | X | X |
| Sparse Vegetation/Soil | X | ✓ | ✓ | X | X | X |
| Turbid Water | ✓ | X | X | X | X | ✓ |
| Clear Water Over Sand | X | X | X | X | X | ✓ |
| Not Classified | X | X | X | X | X | X |
| Spectral Category | Cl/Sh | BBS | Range/MP | VL-M NIR | H-VH NIR | Water |
|---|---|---|---|---|---|---|
| Unclassified | X | X | X | X | X | X |
| V | X | X | ✓ | ✓ | ✓ | X |
| R | X | X | ✓ | ✓ | ✓ | X |
| WR | X | ✓ | ✓ | X | X | X |
| BB | X | ✓ | X | X | X | X |
| WASH | ✓ | X | X | X | X | ✓ |
| CL | ✓ | X | X | X | X | X |
| TNCL_SHRBR_HRBCR_BB | ✓ | ✓ | ✓ | X | X | X |
| UN | X | X | X | X | X | X |
| Spectral Category | BBS | Range/MP | VL-M NIR | H-VH NIR | Water |
|---|---|---|---|---|---|
| Average Vegetation | X | ✓ | ✓ | ✓ | X |
| Bright Vegetation | X | ✓ | ✓ | ✓ | X |
| Dark Vegetation | X | ✓ | ✓ | ✓ | X |
| Yellow Vegetation | X | ✓ | ✓ | ✓ | X |
| Mix of Vegetation/Soil | ✓ | ✓ | ✓ | ✓ | X |
| Asphalt/Dark Sand | ✓ | X | X | X | X |
| Sand/Bare Soil/Cloud | ✓ | X | X | X | X |
| Dry Vegetation/Soil | ✓ | ✓ | X | X | X |
| Sparse Vegetation/Soil | ✓ | ✓ | X | X | X |
| Turbid Water | X | X | X | X | ✓ |
| Clear Water Over Sand | X | X | X | X | ✓ |
| Not Classified | X | X | X | X | X |
| Spectral Category | BBS | Range/MP | VL-M NIR | H-VH NIR | Water |
|---|---|---|---|---|---|
| Unclassified | X | X | X | X | X |
| SV | X | X | ✓ | ✓ | X |
| AV | X | ✓ | ✓ | ✓ | X |
| ASHRBR | X | ✓ | ✓ | ✓ | X |
| WEDR | ✓ | ✓ | X | X | X |
| PB | X | ✓ | ✓ | X | X |
| BBB_VBBB | ✓ | X | X | X | X |
| SBB | ✓ | X | X | X | X |
| ABB | ✓ | X | X | X | X |
| DPWASH | X | X | X | X | ✓ |
| SLWASH | X | X | X | X | ✓ |
| TWASH | X | X | X | X | ✓ |
| SASLWA | X | X | X | X | ✓ |
| TNCLV_SHRBR_HRBCR | ✓ | ✓ | ✓ | X | X |
| TNCLWA_BB | ✓ | X | X | X | ✓ |
| UN3 | X | X | X | X | X |
| Spectral Category | LtBBrs | DkBDkS | NDVI1 | NDVI2 | TrCr | SH | Outlier |
|---|---|---|---|---|---|---|---|
| Average Vegetation | X | X | ✓ | ✓ | ✓ | X | X |
| Bright Vegetation | X | X | ✓ | ✓ | ✓ | X | X |
| Dark Vegetation | X | X | ✓ | ✓ | ✓ | ✓ | X |
| Yellow Vegetation | X | X | ✓ | ✓ | X | X | X |
| Mix of Vegetation/Soil | ✓ | ✓ | ✓ | ✓ | X | X | X |
| Asphalt/Dark Sand | ✓ | ✓ | X | X | X | X | X |
| Sand/Bare Soil/Cloud | ✓ | ✓ | X | X | X | X | X |
| Bright Sand/Soil/Cloud | ✓ | ✓ | X | X | X | X | X |
| Dry Vegetation/Soil | ✓ | ✓ | X | ✓ | X | X | X |
| Sparse Vegetation/Soil | ✓ | ✓ | X | ✓ | X | X | X |
| Turbid Water | X | X | X | X | X | ✓ | X |
| Not Classified | X | X | X | X | X | X | ✓ |
| Spectral Category | LtBBrS | DkBDkS | NDVI1 | NDVI2 | TrCr | SH | Outlier |
|---|---|---|---|---|---|---|---|
| Unclassified | X | X | X | X | X | X | X |
| SVVH2NIR | X | X | ✓ | ✓ | ✓ | X | X |
| SVVH1NIR | X | X | ✓ | ✓ | ✓ | X | X |
| SVVHNIR | X | X | ✓ | ✓ | ✓ | X | X |
| SVHNIR | X | X | ✓ | ✓ | ✓ | ✓ | X |
| SVMNIR | X | X | ✓ | ✓ | ✓ | ✓ | X |
| SVLNIR | X | X | X | ✓ | ✓ | ✓ | X |
| SVVLNIR | X | X | X | ✓ | ✓ | ✓ | X |
| AVVH1NIR | X | X | X | ✓ | ✓ | ✓ | X |
| AVVHNIR | X | X | X | ✓ | ✓ | ✓ | X |
| ASHRBRHNIR | ✓ | ✓ | ✓ | ✓ | ✓ | X | X |
| ASHRBRMNIR | ✓ | ✓ | ✓ | ✓ | ✓ | X | X |
| ASHRBRLNIR | ✓ | ✓ | ✓ | ✓ | ✓ | X | X |
| ASHRBRVLNIR | ✓ | ✓ | ✓ | ✓ | ✓ | X | X |
| BBB_TNCL | ✓ | ✓ | X | X | X | X | X |
| SBBNF | ✓ | ✓ | X | X | X | X | X |
| ABBVF | ✓ | ✓ | X | X | X | X | X |
| ABBNF | ✓ | ✓ | X | X | X | X | X |
| DBBVF | ✓ | ✓ | X | X | X | ✓ | X |
| DBBF | ✓ | ✓ | X | X | X | ✓ | X |
| DBBNF | ✓ | ✓ | X | X | X | ✓ | X |
| TWASH | X | ✓ | X | X | X | ✓ | X |
| SN_CL_BBB | ✓ | X | X | X | X | X | X |
| UN3 | X | X | X | X | X | X | ✓ |
| Test Data Set | ATCOR™ SPECL (19 sp. cat.) CVPSI1 | ATCOR™ SPECL (19 sp. cat.) CVPSI2 | S-SIAM™ (Coarse = 15 sp. cat.) CVPSI1 | S-SIAM™ (Coarse = 15 sp. cat.) CVPSI2 | S-SIAM™ (Interm. = 40 sp. cat.) CVPSI1 | S-SIAM™ (Interm. = 40 sp. cat.) CVPSI2 | S-SIAM™ (Fine = 68 sp. cat.) CVPSI1 | S-SIAM™ (Fine = 68 sp. cat.) CVPSI2 |
|---|---|---|---|---|---|---|---|---|
| IRS-P6 LISS-3, 23.5 m-resolution, 4-band (G, R, NIR, MIR) | 0.6631 | 0.7696 | 0.4855 | 0.6480 | 0.7110 | 0.7755 | 0.7653 | 0.8034 |
| SPOT-4 HRVIR, 20 m-resolution, 4-band (G, R, NIR, MIR) | 0. 5732 | 0.6688 | 0.4746 | 0.6135 | 0.6659 | 0.7208 | 0.7449 | 0.7796 |
| ATCOR™ SPECL (19 sp. cat.) CVPSI1 | ATCOR™ SPECL (19 sp. cat.) CVPSI2 | Q-SIAM™ (Coarse = 12 sp. cat.) CVPSI1 | Q-SIAM™ (Coarse = 12 sp. cat.) CVPSI2 | Q-SIAM™ (Interm. = 28 sp. cat.) CVPSI1 | Q-SIAM™ (Interm. = 28 sp. cat.) CVPSI2 | Q-SIAM™ (Fine = 52 sp. cat.) CVPSI1 | Q-SIAM™ (Fine = 52 sp. cat.) CVPSI2 | |
| Leica ADS-40, 0.25 m-resolution, 4-band (B, G, R, NIR) | 0.5000 | 0.6073 | 0.4249 | 0.6337 | 0.5642 | 0.6664 | 0.6310 | 0.6911 |
| Test Data Set | ATCOR™-SPECL (19 sp.cat.), POA = Eq. (9) | +/− δEq. (3) | S-SIAM™ (Coarse = 15 sp.cat.), POA = Eq. (9) | +/−δ=Eq. (3) | S-SIAM™ (Interm. = 40 sp.cat.), POA = Eq. (9) | +/−δ= Eq. (3) | S-SIAM™ (Fine = 68 sp.cat.), POA = Eq. (9) | +/−δ= Eq. (3) | Number of Randomly Selected Reference Samples (Spatial Type: Pixel) |
|---|---|---|---|---|---|---|---|---|---|
| IRS-P6 LISS-3, 23.5 m-resolution, 4-band (G, R, NIR, MIR) | 84.26% | 2.08% | 90.49% | 1.67% | 91.47% | 1.59% | 96.81% | 1.00% | 2040 |
| SPOT-4 HRVIR, 20 m-resolution, 4-band (G, R, NIR, MIR) | 92.00% | 1.69% | 95.47% | 1.30% | 98.71% | 0.70% | 99.35% | 0.50% | 1700 |
| ATCOR™-SPECL (19 sp.cat.), POA = Eq. (9) | Q-SIAM™ (Coarse = 12 sp.cat.), POA = Eq. (9) | Q-SIAM™ (Interm. = 28 sp.cat.), POA = Eq. (9) | Q-SIAM™ (Fine = 52 sp.cat.), POA = Eq. (9) | ||||||
| Leica ADS-80, 0.25 m-resolution, 4-band (B, G, R, NIR) | 96.18% | 1.09% | 97.55% | 0.88% | 99.17% | 0.52% | 99.22% | 0.50% | 2045 |
| IRS-P6 LISS-3, 23.5 m-Resolution, 4-Band (G, R, NIR, MIR), Reference LC Classes (Refer to Table 5) | ATCOR™- SPECL (19 sp. cat.), PPA = Eq. (11) | +/− δ = Eq. (5) | S-SIAM™ (Coarse = 15 sp. cat.), PPA = Eq. (11) | +/− δ = Eq. (5) | S-SIAM™ (Interm. = 40 sp. cat.), PPA = Eq. (11) | +/− δ = Eq. (5) | S-SIAM™ (Fine = 68 sp. cat.), PPA = Eq. (11) | +/− δ = Eq. (5) | Number of Randomly Selected Reference Samples (Spatial Type: Pixel) |
|---|---|---|---|---|---|---|---|---|---|
| Cl/Sh | 16.47% | 5.18% | 55.88% | 6.93% | 55.88% | 6.93% | 83.53% | 5.18% | 340 |
| BBS | 99.41% | 1.07% | 94.12% | 3.29% | 94.12% | 3.29% | 98.24% | 1.84% | 340 |
| Range/MP | 97.94% | 1.98% | 99.71% | 0.76% | 99.71% | 0.76% | 99.71% | 0.76% | 340 |
| VL-M NIR | 98.53% | 1.68% | 98.53% | 1.68% | 99.71% | 0.76% | 100.00% | 0.00% | 340 |
| H-VH NIR | 100.00% | 0.00% | 99.71% | 0.76% | 100.00% | 0.00% | 100.00% | 0.00% | 340 |
| Water | 93.24% | 3.51% | 95.00% | 3.04% | 99.41% | 1.07% | 99.41% | 1.07% | 340 |
| SPOT-4 HRVIR, 20 m-Resolution, 4-Band (G, R, NIR, MIR), Reference LC Classes (Refer to Table 6) | ATCOR™- SPECL (19 sp. cat.), PPA = Eq. (11) | +/− δ = Eq. (5) | S-SIAM™ (Coarse = 15 sp. cat.), PPA = Eq. (11) | +/− δ = Eq. (5) | S-SIAM™ (Interm. = 40 sp. cat.), PPA = Eq. (11) | +/− δ = Eq. (5) | S-SIAM™ (Fine = 68 sp. cat.), PPA = Eq. (11) | +/− δ = Eq. (5) | Number of Randomly Selected Reference Samples (Spatial Type: Pixel) |
| BBS | 98.82% | 1.51% | 94.41% | 3.21% | 94.41% | 3.21% | 97.65% | 2.12% | 340 |
| Range/MP | 97.65% | 2.12% | 100.00% | 0.00% | 100.00% | 0.00% | 100.00% | 0.00% | 340 |
| VL-M NIR | 99.71% | 0.76% | 100.00% | 0.00% | 100.00% | 0.00% | 100.00% | 0.00% | 340 |
| H-VH NIR | 100.00% | 0.00% | 100.00% | 0.00% | 100.00% | 0.00% | 100.00% | 0.00% | 340 |
| Water | 63.82% | 6.71% | 82.94% | 5.25% | 99.12% | 1.31% | 99.12% | 1.31% | 340 |
| Leica ADS-80, 0.25 m-Resolution, 4-Band (B, G, R, NIR), Reference LC Classes (Refer to Table 7) | ATCOR™- SPECL (19 sp. cat.), PPA = Eq. (11) | +/− δ = Eq. (5) | Q-SIAM™ (Coarse = 12 sp. cat.), PPA = Eq. (11) | +/− δ = Eq. (5) | Q-SIAM™ (Interm. = 28 sp. cat.), PPA = Eq. (11) | +/− δ = Eq. (5) | Q-SIAM™ (Fine = 52 sp. cat.), PPA = Eq. (11) | +/− δ = Eq. (5) | Number of Randomly Selected Reference Samples (Spatial Type: Pixel) |
| LtBBrS | 99.71% | 0.76% | 97.94% | 1.98% | 97.94% | 1.98% | 97.94% | 1.98% | 340 |
| DkBDkS | 79.71% | 5.62% | 97.65% | 2.12% | 97.35% | 2.24% | 97.35% | 2.24% | 340 |
| NDVI1 | 100.00% | 0.00% | 100.00% | 0.00% | 100.00% | 0.00% | 100.00% | 0.00% | 340 |
| NDVI2 | 98.82% | 1.51% | 100.00% | 0.00% | 100.00% | 0.00% | 100.00% | 0.00% | 340 |
| TrCr | 100.00% | 0.00% | 100.00% | 0.00% | 100.00% | 0.00% | 100.00% | 0.00% | 340 |
| SH | 98.53% | 1.68% | 99.41% | 1.07% | 99.41% | 1.07% | 89.71% | 4.24% | 340 |
| Outlier | -- | -- | -- | -- | 5 | ||||
| Pre-Classifier | Test Image | Number of Test Classes = TC | Test Spectral Category* | pUA = Eq. (10) ± δ = Eq. (5). | Source of Error |
|---|---|---|---|---|---|
| ATCOR™-SPECL | IRS, 23.5 m-resolution, 4-band (G, R, NIR, MIR) | 19 sp. cat. | Dry Vegetation/Soil | 55.86% ± 12.12% | Clouds/Shadows |
| Sparse Vegetation/Soil | 21.83% ± 7.58% | Clouds/Shadows | |||
| SPOT, 20 m-resolution, 4-band (G, R, NIR, MIR) | 19 sp. cat. | Asphalt/Dark Sand | 17.27% ± 8.26% | Water | |
| S-SIAM™ | IRS | Coarse = 15 sp. cat. | BB (Bare soil or Built-up) | 50.49% ± 8.97% | Clouds |
| SPOT | Coarse = 15 sp. cat. | TNCL_SHRBR_HRBCR_BB | 66.26% ± 9.54% | Water | |
| Q-SIAM™ Semantic Granularity | Number of Randomly Selected Reference Samples (Spatial Type: Polygon) | OSQI × 100% = Eq. (14) | +/− δ = Eq. (3) | USQI × 100% = Eq. (15) | +/− δ = Eq. (3) | FEOQI-R × 100% = Eq. (16) | +/− δ = Eq. (3) | FEOQI-T × 100 = Eq.(17) | +/− δ = Eq. (3) | Percent Average SQI (ASQI) |
|---|---|---|---|---|---|---|---|---|---|---|
| Coarse = 12 | 109 | 88.76% | 5.92% | 31.88% | 8.74% | 78.18% | 7.75% | 26.28% | 8.26% | 56.28% |
| Intermediate = 28 | 109 | 81.73% | 7.25% | 50.07% | 9.38% | 82.09% | 7.19% | 38.50% | 9.13% | 63.10% |
| Fine = 52 | 109 | 75.62% | 8.05% | 77.78% | 7.8% | 77.75% | 7.8% | 56.92% | 9.29% | 72.02% |
© 2013 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Baraldi, A.; Humber, M.; Boschetti, L. Quality Assessment of Pre-Classification Maps Generated from Spaceborne/Airborne Multi-Spectral Images by the Satellite Image Automatic Mapper™ and Atmospheric/Topographic Correction™-Spectral Classification Software Products: Part 2 — Experimental Results. Remote Sens. 2013, 5, 5209-5264. https://doi.org/10.3390/rs5105209
Baraldi A, Humber M, Boschetti L. Quality Assessment of Pre-Classification Maps Generated from Spaceborne/Airborne Multi-Spectral Images by the Satellite Image Automatic Mapper™ and Atmospheric/Topographic Correction™-Spectral Classification Software Products: Part 2 — Experimental Results. Remote Sensing. 2013; 5(10):5209-5264. https://doi.org/10.3390/rs5105209
Chicago/Turabian StyleBaraldi, Andrea, Michael Humber, and Luigi Boschetti. 2013. "Quality Assessment of Pre-Classification Maps Generated from Spaceborne/Airborne Multi-Spectral Images by the Satellite Image Automatic Mapper™ and Atmospheric/Topographic Correction™-Spectral Classification Software Products: Part 2 — Experimental Results" Remote Sensing 5, no. 10: 5209-5264. https://doi.org/10.3390/rs5105209
APA StyleBaraldi, A., Humber, M., & Boschetti, L. (2013). Quality Assessment of Pre-Classification Maps Generated from Spaceborne/Airborne Multi-Spectral Images by the Satellite Image Automatic Mapper™ and Atmospheric/Topographic Correction™-Spectral Classification Software Products: Part 2 — Experimental Results. Remote Sensing, 5(10), 5209-5264. https://doi.org/10.3390/rs5105209