SVM-Based Classification of Segmented Airborne LiDAR Point Clouds in Urban Areas

Abstract
:1. Introduction
- ▪ Point-based classification methods. Point-based classification is performed by analyzing the features of one single laser point. Taking a discrete point of the surface and comparing its features to another point, the obtainable information is restricted in terms of the nature of the sampled surface. Most of the filtering algorithms belong to the point-based classifications, such as the labeling algorithm [25] and multi-scale curvature classification LiDAR algorithm [26]. Additionally, Petzold and Axelsson [27] presented a point cloud classification method in which it is found the reflectance of the laser echo is a good feature to discriminate the neighboring objects. However, the number of point features is limited, which allows only simple classifications for this kind of methods.
- ▪ Segment-based classification. Segment-based classification is to first segment the data, and then perform a classification based on those segments. A special case of segment-based classification is the segment-based filtering. The rationale behind such algorithms is that segments of objects are situated higher than the ground segments [28,29]. The segment-based filters are typically designed for urban areas where many step edges can be found in the data. In the segment-based classification, Sithole [30] designed a four step procedure to classify the ALS data, in which it detects ‘macro objects’, bridges, ‘micro objects’ and the man-made and natural objects. The segments are classified depending on their geometrical relation. Golovinskiy et al. [31] design a system for recognizing objects in 3D point clouds obtained by mobile laser scanning in urban environments, and the system is decomposed into four steps: locating, segmenting, characterizing, and classifying clusters of 3D points. Shen et al. [29] proposed a segment-based classification method for ALS data with multiple returns, in which a rule-based classification is performed on the segmented point clouds. A special segment-based classification application can be seen in Barsi et al. [32], where vehicles on the highway are classified in ALS data by a clustering method.
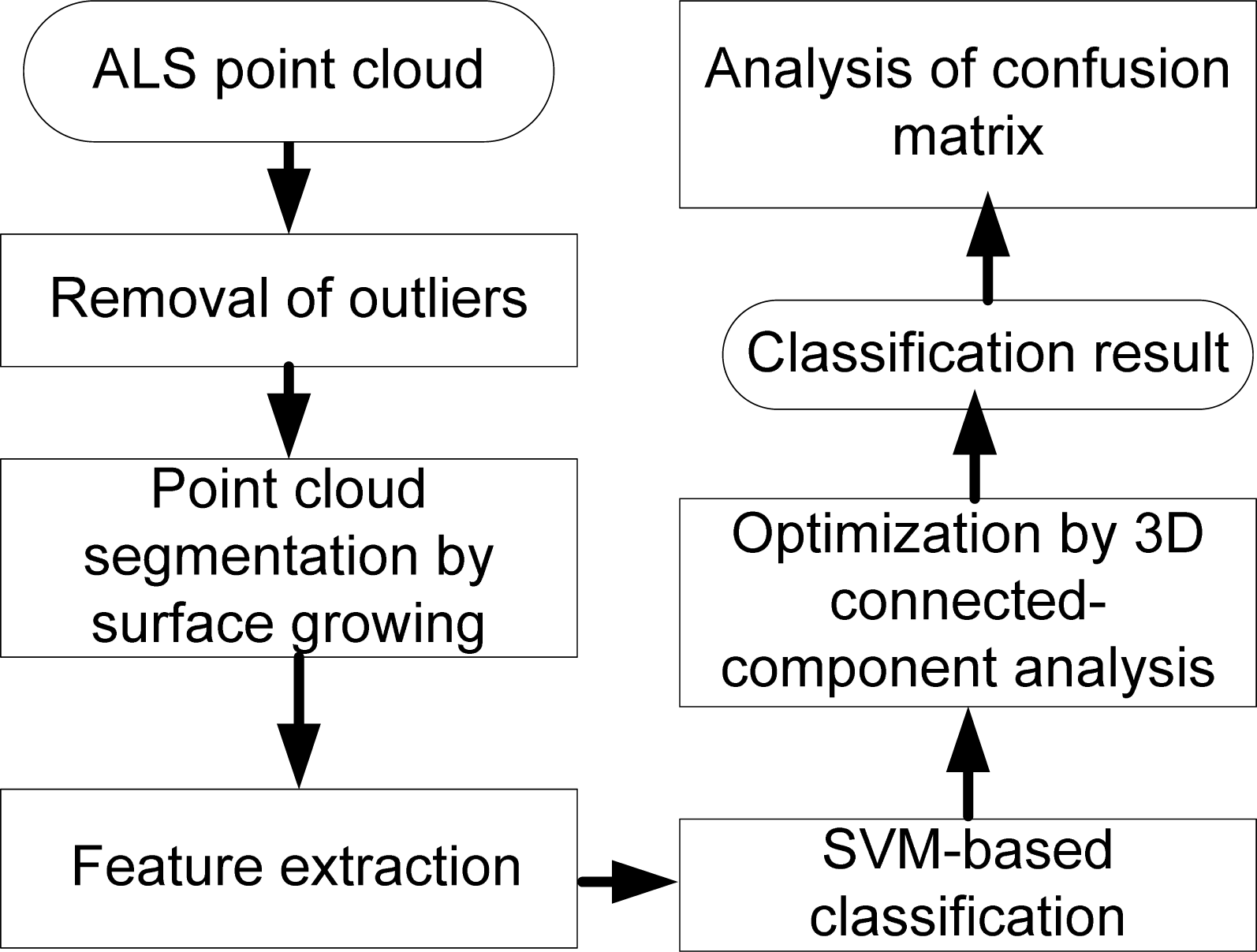
2. The Proposed Method
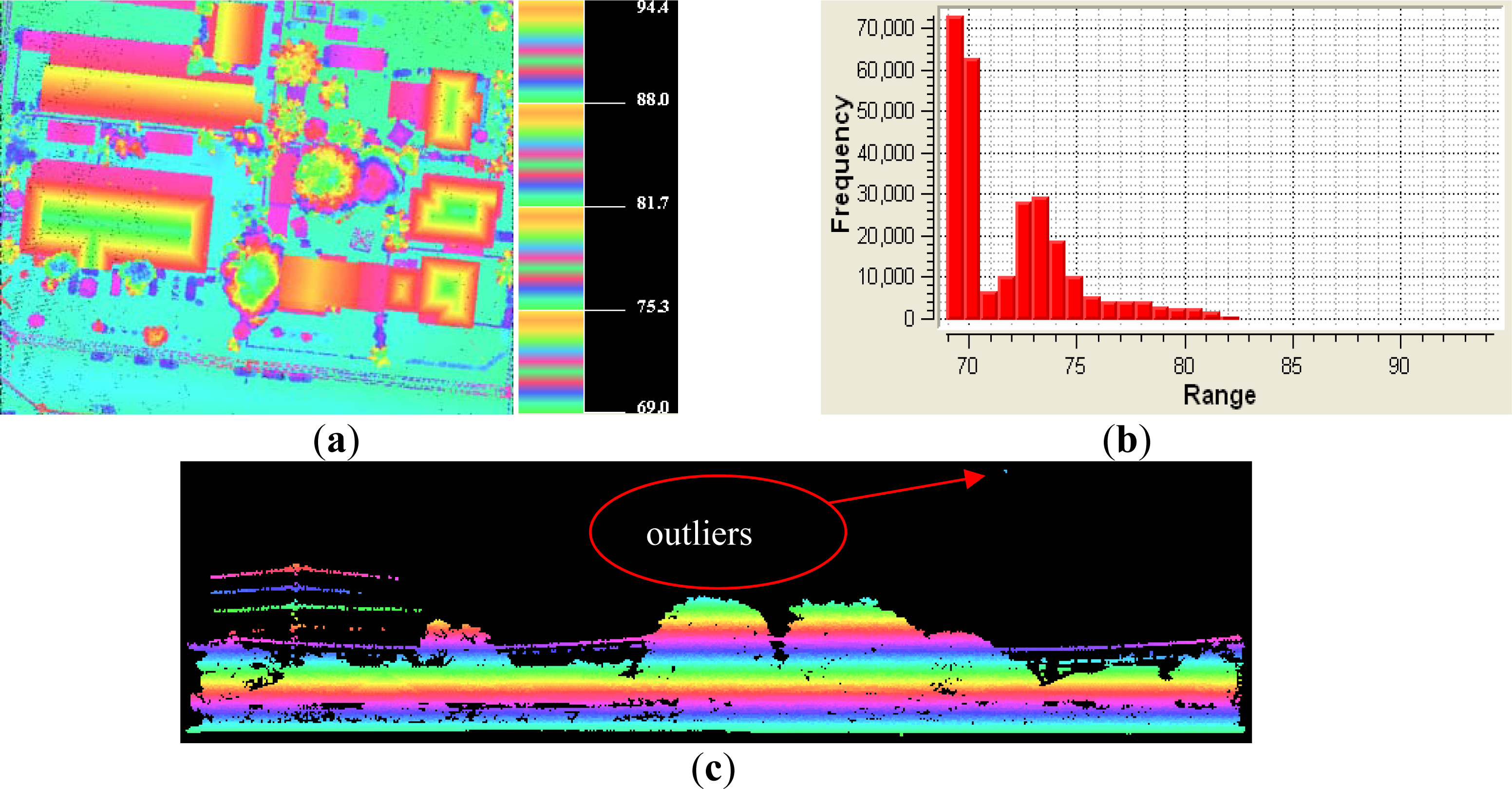
2.1. Outlier Removal
2.2. Segmentation by Surface Growing
- ▪ Proximity of points. Only points within certain distance to a seed surface, or the neighboring points of a seed surface, can be added to this seed surface.
- ▪ Globally planar. For this criterion, a plane equation is determined by fitting a plane through all surface points in this seed surface. Points can only be added if the perpendicular distance to the plane is below some a threshold.
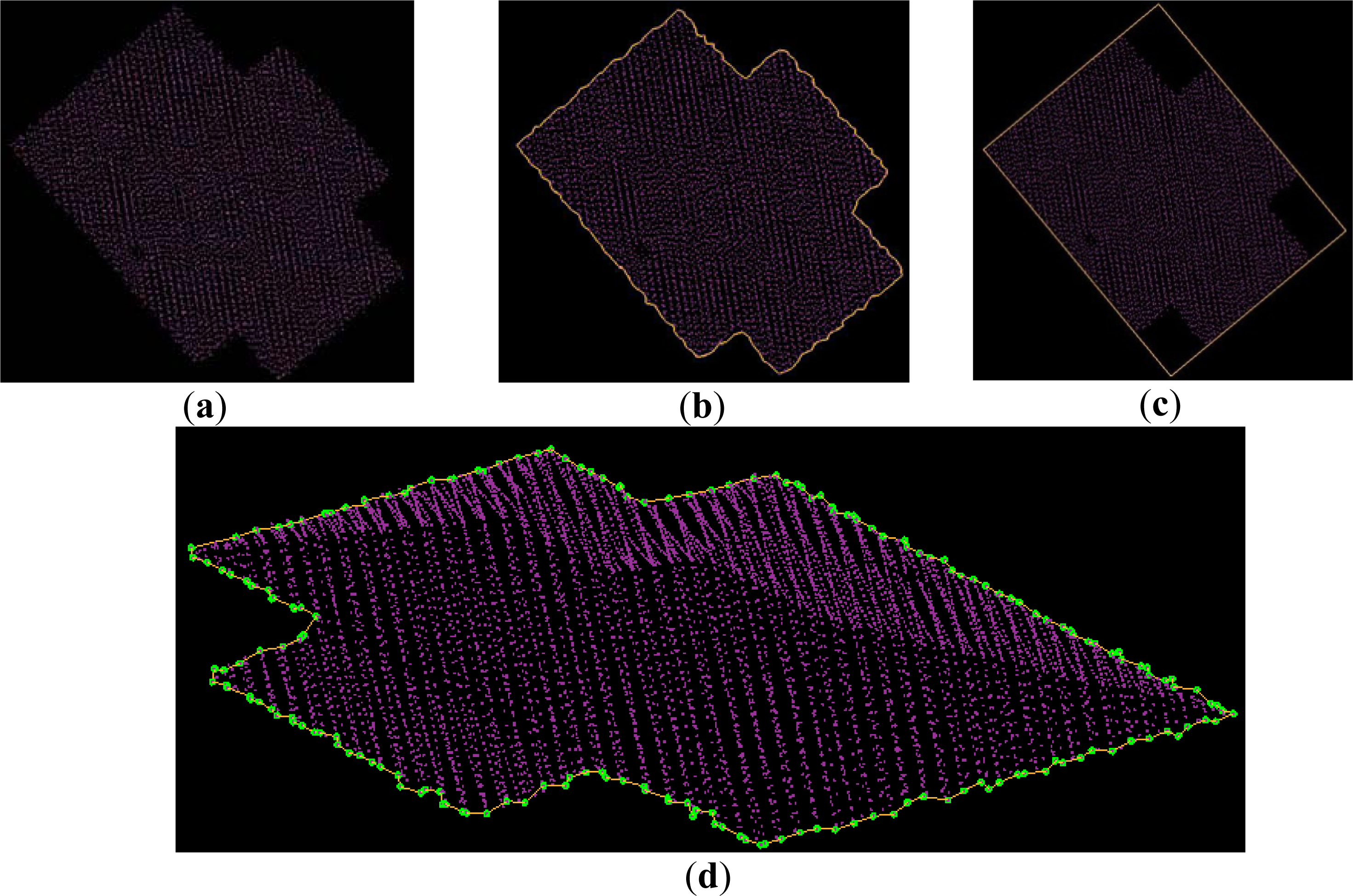
- ▪ Concave boundary: The boundary which closely encompasses the point cluster could be determined by finding the alpha shape of the points [40], as shown in Figure 6,b. Note, the points on the boundary also can derive the boundary of the segment in 3D space because each transformed point has the same point number as the original laser point, as shown in Figure 6,d. The boundaries of the segmented point clouds in Figure 4,b are displayed in Figure 4,g, which suggests that the boundaries of the segments reflect the geometric features of the segments.
- ▪ Area: The covered area of the point cluster can be computed using the connected concave boundary.
- ▪ MOBB: The MOBB is calculated from the concave polygon formed by the above concave boundary, as shown in Figure 6c.
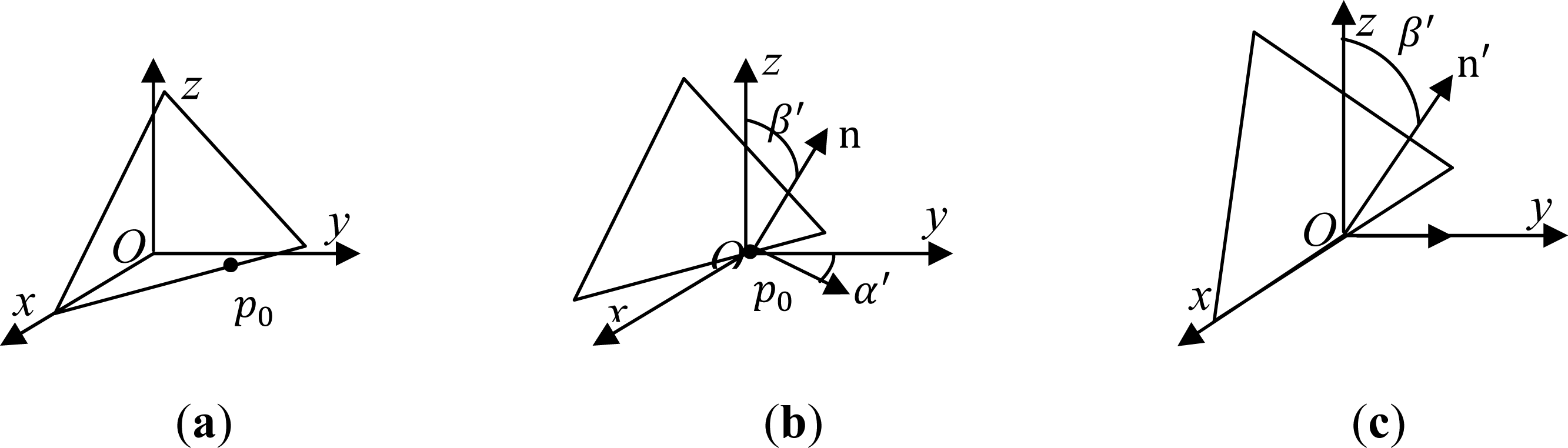
2.3. Features Calculation
2.4. SVM-Based Classification
2.5. Post-Processing
- (1)
- Specify a distance threshold, dsearch.
- (2)
- Set all 3D points as unlabeled, insert them into a stack, and building the k-d tree for the point cloud with class attribute.
- (3)
- If all the points have been already labeled go to step (7).Otherwise, select the first point without label in the stack as the current seed, build an empty list of potential seed points, and insert the current seed into the list.
- (4)
- Select the neighboring points of the current seed using FDN. The points that satisfy having the same class attribute as the current seed, add them to the list of potential seed points.
- (5)
- If the number of members in the potential seed point list is larger than one, set the current seed to the next available seed, and go to step (4). Otherwise, go to step (6).
- (6)
- Give the points in the list a new label, clear the list, and go to step (3).
- (7)
- Finish the task of labeling.
- (1)
- Specify a minimum number of points threshold, Nsearch.
- (2)
- Perform CCAPFC.
- (3)
- Calculate the number of points in each connected component, if the number of points of each component is larger than Nsearch, finish the task. Otherwise, go to next step.
- (4)
- Find a connected component without being processed, and the number of points in the component is no more than Nsearch. Select the connect component as the current region, and go the next step.
- (5)
- For each point in the current region, select the neighboring points of the current point using FDN. For each neighboring point, if the neighboring point has a different component label as the current region, add the component label of neighboring point into the region adjacency graph (RAG). Note that the component label could insert into the RAG only if it was not existed in the RAG.
- (6)
- Label the state of the current region as being processed. Find the component with maximum number of points among the components in the RAG. If the maximum number is larger than Nsearch, reclassify the points of current region into the class, which the component with maximum number belongs to, and the points of current region are relabeled as the label of the component with maximum number. Go to step (4).
- (7)
- Finish this iteration. If there is no change of reclassifying happens, finish the task. Otherwise, go to step (3).
3. Experiments and Performance Analysis
3.1. The Testing Data
3.2. Experimental Results
3.3. Evaluation
4. Uncertainties, Errors, and Accuracies
- (1)
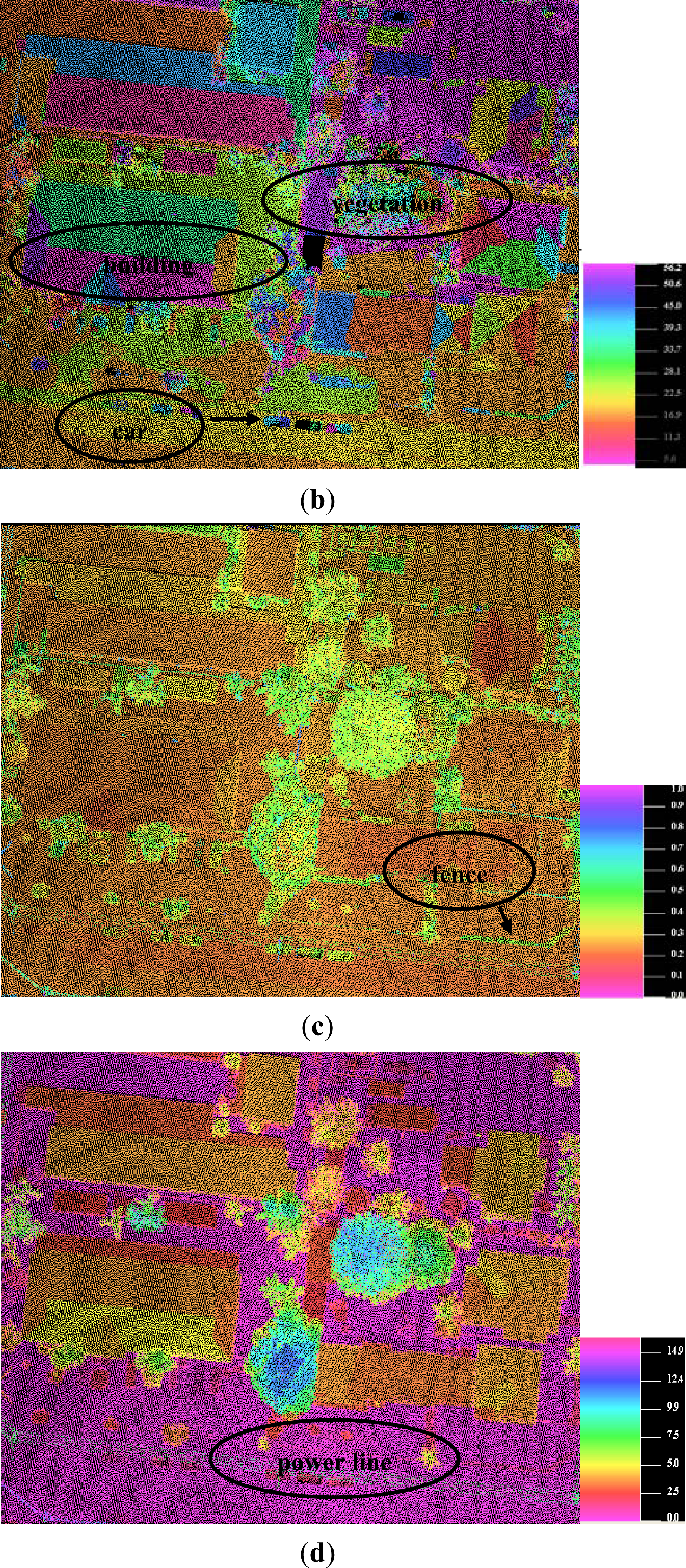
- Compared to the object points, the ground/terrain points are more likely to be correctly detected by our proposed approach, which is meaningful for the filtering and generation of DTM. Among the three scenes, the ground measurements are scarcely misclassified into other classes, and the producer accuracy and the user accuracy is higher than 96.55% and 98.85% respectively for the ground class. In all of the three tests, the ground class obtains higher classification accuracy than the vegetation and building class. On average, the producer accuracy of ground class is 6.38% higher than the vegetation class, and the user accuracy of ground class is 19.87% higher than the vegetation class. Similar statistics are 6.66% and 4.91% for the ground class compared to the building class. This should contribute to the following factors. First, the ground segments are usually larger than the other types of segments. Second, the sizes of the ground segments trend to distribute into a fixed range. Third, the ground surfaces seldom yield multiple echoes. Fourth, the ground surfaces usually are horizontal in the urban areas, and they are easy to be clustered into one same segment in point cloud segmentation. Last but not least, the ground surfaces may be the lowest part in a local neighborhood. The above factors lead the ground class having lower complexity than the other types of objects.
- (2)
- Compared to the other types of object points, the building measurements are more likely to be correctly identified by our proposed approach. Among the three tests, the building class gets higher classification accuracy than the vegetation, the vehicle and the powerline. For example, the user accuracy of building class is approximately 15% higher than the vegetation class on average. This should contribute to the following factors. First, most of the building roofs are planes, and they are often very large. Thus, the building measurements trend to be clustered into the same and large segment after point cloud segmentation. Second, a building roof trends to produce single returns rather than the multiple returns, which yields a difference from the trees. As a result, the building class is easier to be separated from the vegetation class.
- (3)
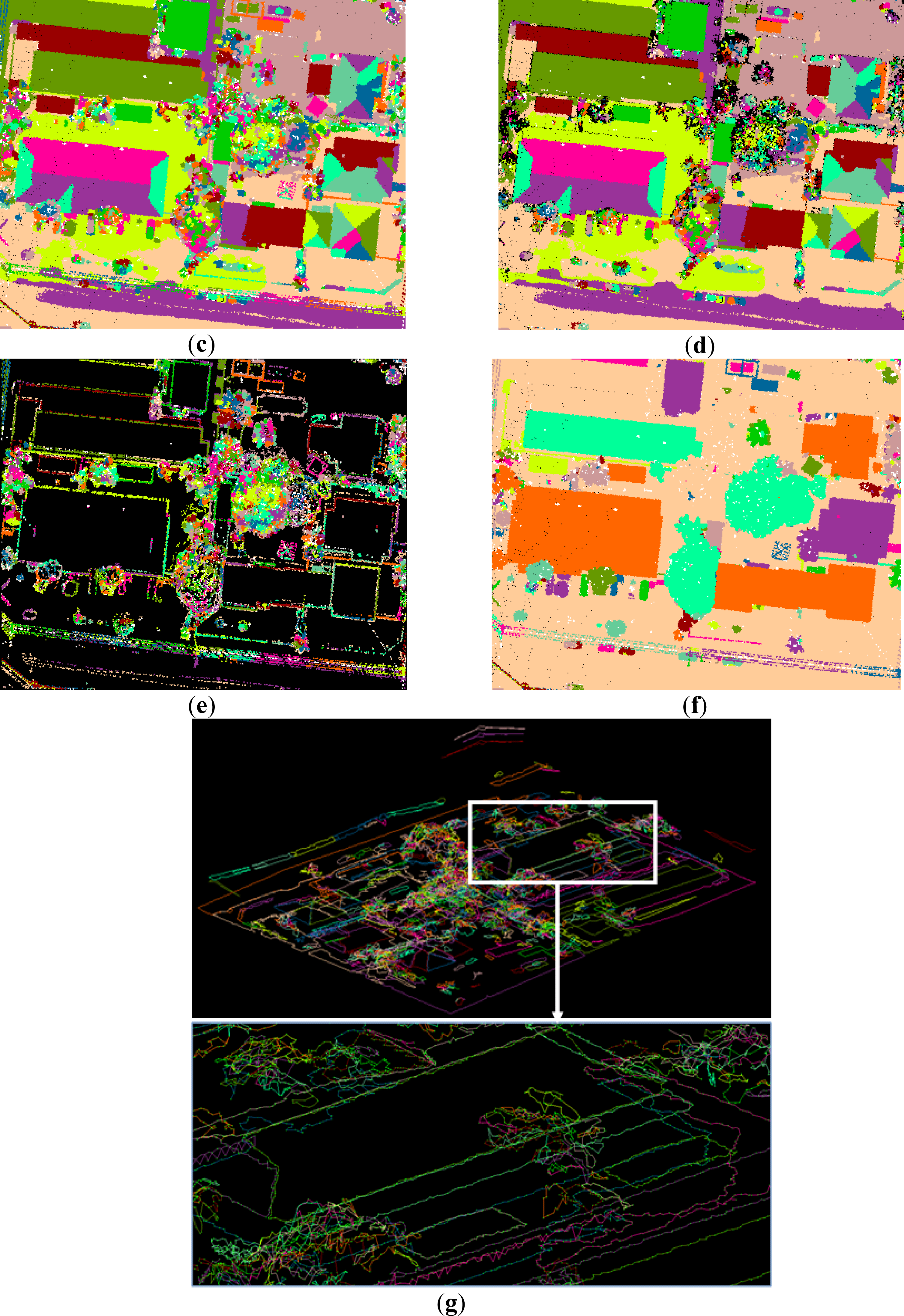
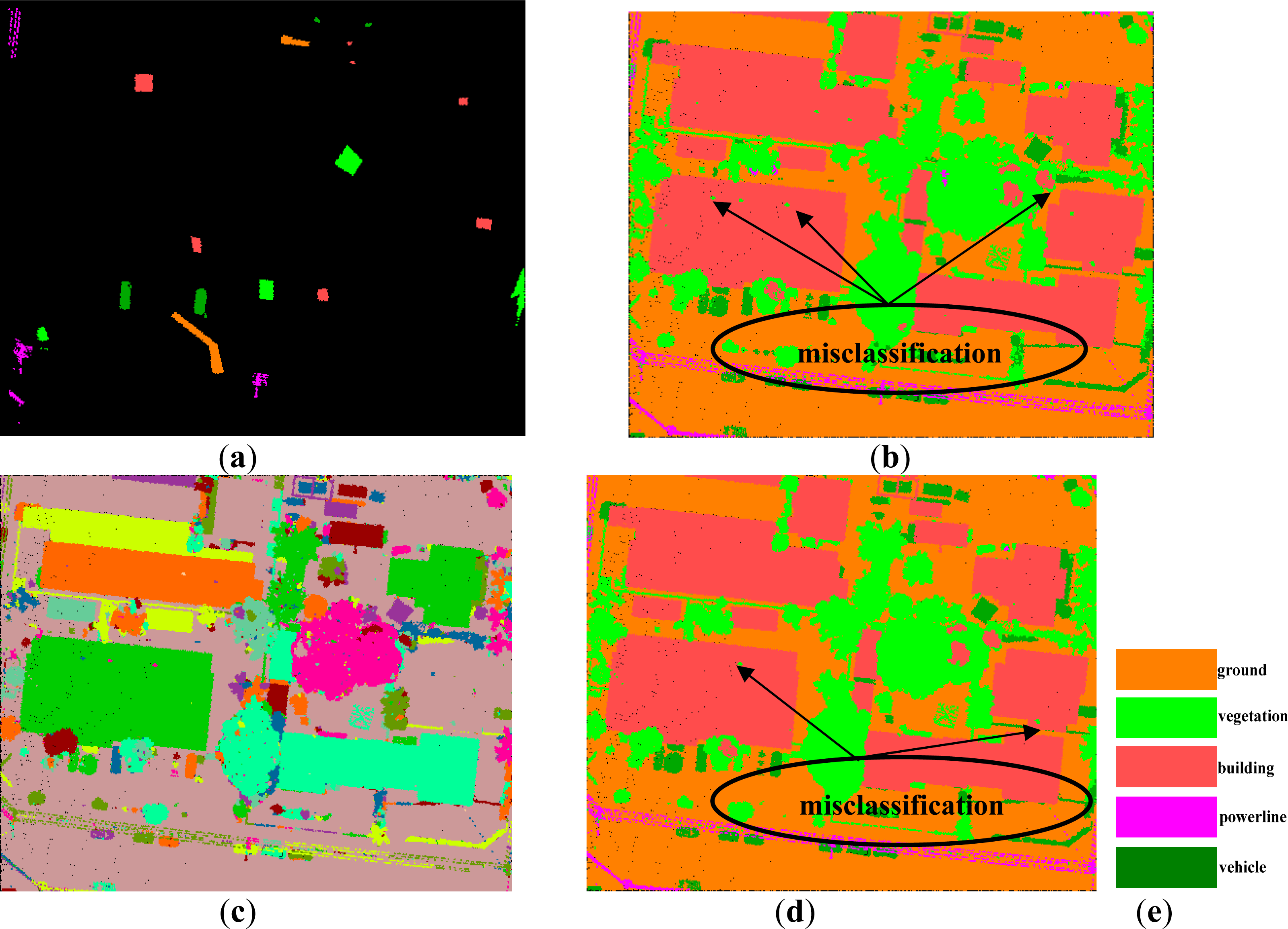
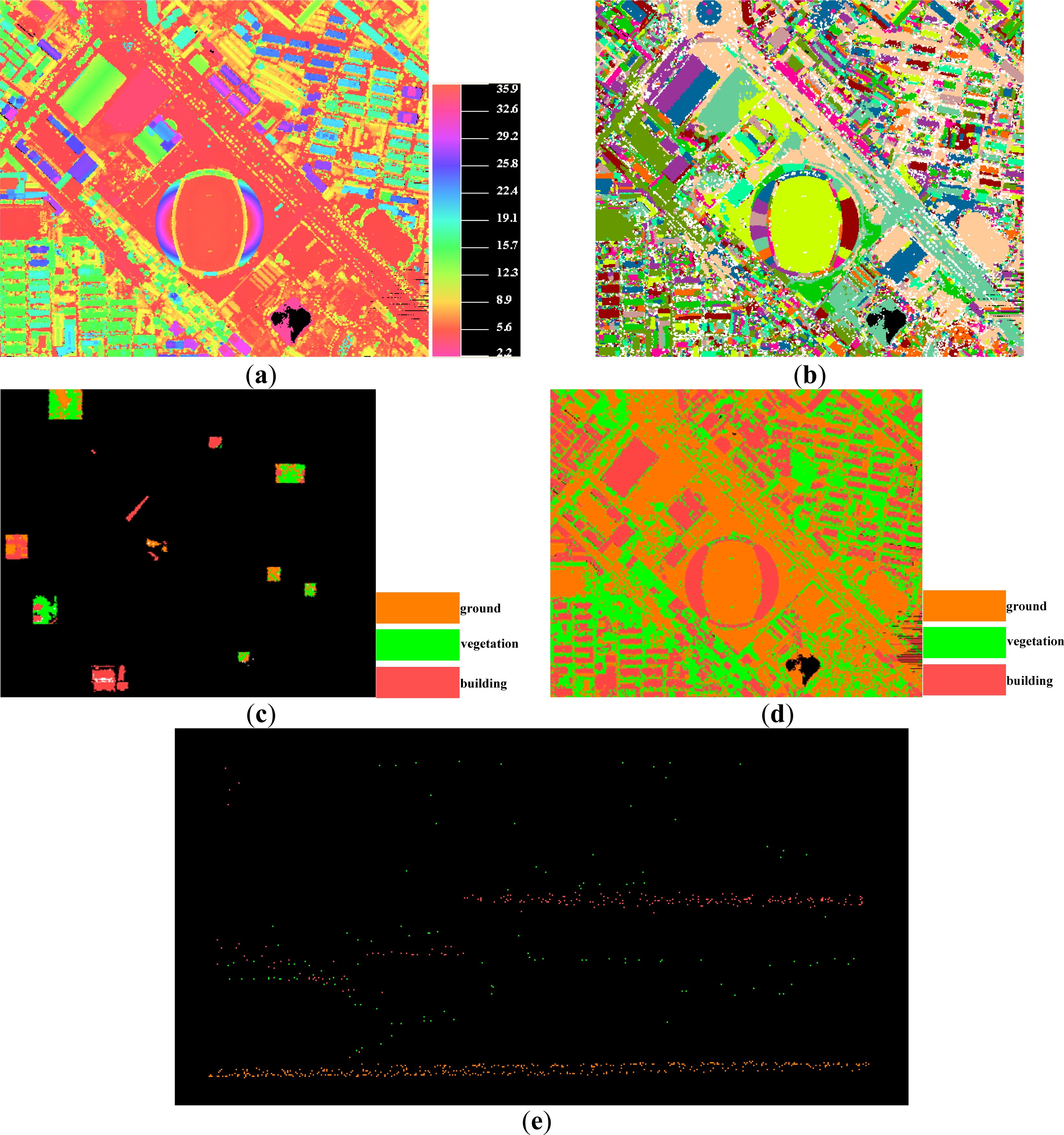
- The wall points and the points, belonging to the small objects on the building roofs, are more likely to be wrongly regarded as vegetation points, as shown in Figure 9e and Figure 11f. The misclassification comes from that the wall points and the mini-structures on the building roofs often have similar features as the trees. Both of them are small in size, and the mini-structures also produce multiple echoes if they are high enough. The above reasons lead to the low classification accuracy for the vegetation class, as low as approximate 66% for the producer accuracy in the second scene. Fortunately, once misclassification occurs, some of the errors may be removed by our post-processing method, because these kinds segments sometimes are far away from the building segments, as shown in Figure 9e.
- (4)
- The powerline may be not suitable to be recognized by our proposed method, as shown in Figure 11. In the third scene, the powerline class has low classification accuracy. The user accuracy and the producer accuracy is 84.24% and 76.97%, respectively. The low classification accuracy is derived from the following factors. Generally, the powerline in the urban areas is not far away enough from the adjacent trees. Moreover, the power line also trends to produce multiple echoes same as the trees. As a result, a lot of powerline measurements are subjective to be misclassified as vegetations in the urban areas.
- (5)
- Errors also trend to occur where there is a mixture of different classes of points. As shown in Figure 10e, the small and low building measurements around the trees are misclassified as vegetations. Other similar errors often occur. The mixture could produce similar features such as same height, similar proportion of multiple echoes etc. Mixture increases the complexity of a landscape, which is a difficult problem to be solved.
- (6)
- Point density of a point cloud has a significant influence on the classification accuracy. As illustrated above, our proposed classification method trend to correctly detect the objects with a larger size if the point density is fixed. On contrary, if the point density of a point cloud is increased, the classification accuracy is also promoted. In the three test dataset, the point cloud density is getting larger and larger. Correspondingly, the overall classification accuracy and the kappa coefficient are also getting higher and higher. Moreover, in the former two scenes, only three classes of points, including ground, building and vegetation, are obviously distinguished, because the point density is low for the two data, and it is insufficient for detecting small objects. However, in the third scene, five classes of points, including vehicle and powerline plus the former three classes are capable of being detected. Furthermore, most of the vehicles are corrected recognized, but the vehicles can’t be recognized by the human beings in the former two data. With the increasing of the point density, the number of points in each face is also increased, which leads to a larger segment in point cloud segmentation. Thus, the classification accuracy is increased for the whole dataset.
5. Conclusions
Acknowledgments
Conflict of Interest
References and Notes
- Filin, S.; Pfeifer, N. Segmentation of airborne laser scanning data using a slope adaptive neighborhood. ISPRS J. Photogramm 2006, 60, 71–80. [Google Scholar]
- Sithole, G.; Vosselman, G. Experimental comparison of filter algorithms for bare earth extraction from airborne laser scanning point clouds. ISPRS J. Photogramm 2004, 59, 85–101. [Google Scholar]
- Maas, H.G.; Vosselman, G. Two algorithms for extracting building models from raw laser altimetry data. ISPRS J. Photogramm 1999, 54, 153–163. [Google Scholar]
- Oude Elberink, S.; Vosselman, G. 3D information extraction from laser point clouds covering complex road junctions. Photogramm. Rec 2009, 24, 23–36. [Google Scholar]
- Hyyppä, J.; Schardt, M.; Haggrén, H.; Koch, B.; Lohr, U.; Scherrer, H.U.; Paananen, R.; Luukkonen, H.; Ziegler, M.; Hyyppä, H.; et al. HIGH-SCAN: The first European-wide attempt to derive single tree information from laser scanner data. Photogram. J. Finl 2001, 17, 58–68. [Google Scholar]
- Ussyshkin, V.; Theriault, L. Airborne Lidar: Advances in discrete return technology for 3D vegetation mapping. Remote Sens 2011, 3, 416–434. [Google Scholar]
- Zhang, J. Multi-source remote sensing data fusion: status and trends. Int. J. Image Data Fusion 2010, 1, 5–24. [Google Scholar]
- Antonarakis, A.S.; Richards, K.S.; Brasington, J. Object-based land cover classification using airborne LiDAR. Remote. Sens. Environ 2008, 112, 2988–2998. [Google Scholar]
- Fricker, G.A.; Saatchi, S.S.; Meyer, V.; Gillespie, T.W.; Sheng, Y. Application of semi-automated filter to improve waveform LiDAR sub-canopy elevation model. Remote Sens 2012, 4, 1494–1518. [Google Scholar]
- Mallet, C.; Bretar, F.; Soergel, U. Analysis of full waveform LIDAR data for classification of urban areas. Photogramm. Fernerkun 2008, 5, 337–349. [Google Scholar]
- Rutzinger, M.; Höfle, B.; Hollaus, M.; Pfeifer, N. Object-Based point cloud analysis of full-waveform airborne laser scanning data for urban vegetation classification. Sensors 2008, 8, 4505–4528. [Google Scholar]
- Huang, X.; Zhang, L.P.; Gong, W. Information fusion of aerial images and LIDAR data in urban areas: vector-stacking, re-classification and post-processing approaches. Int. J. Remote. Sens 2011, 32, 69–84. [Google Scholar]
- Secord, J.; Zakhor, A. Tree detection in urban regions using aerial LiDAR and image data. IEEE. Geosci Remote Sens 2007, 4, 196–200. [Google Scholar]
- Rottensteiner, F.; Trinder, J.; Clode, S.; Kubik, K. Building detection by fusion of airborne laser scanner data and multi-spectral images: performance evaluation and sensitivity analysis. ISPRS J. Photogramm 2007, 62, 135–149. [Google Scholar]
- Zhu, X.K.; Toutin, T. Land cover classificationusing airborne LiDAR products in Beauport, Québec, Canada. Int. J. Image Data Fusion 2012. [Google Scholar] [CrossRef]
- Liu, X. Airborne LiDAR for DEM generation: some critical issues. Progr. Phys. Geogr 2008, 32, 31–49. [Google Scholar]
- Axelsson, P.E. DEM generation from laser scanner data using adaptive TIN models. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2000, 32, 110–117. [Google Scholar]
- Zhang, J.X.; Lin, X.G. Filtering airborne LiDAR data by embedding smoothness-constrained segmentation in progressive TIN densification. ISPRS J. Photogramm 2013, 81, 44–59. [Google Scholar]
- Kraus, K.; Pfeifer, N. Determination of terrain models in wooded areas with airborne laser scanner data. ISPRS J. Photogramm. 1998, 53, 193–203. [Google Scholar]
- Briese, C.; Pfeifer, N.; Dorninger, P. Applications of the robust interpolation for DTM determination. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2002, 34, 55–61. [Google Scholar]
- Darmawati, A.T. Utilization of Multiple Echo Information for Classification of Airborne Laser Scanning Data. International Institute for Geo-information Science and Observation, Enschede, The Netherlands, 2008. [Google Scholar]
- Meng, X.; Wang, L.; Currit, N. Morphology-based building detection from airborne Lidar data. Photogramm. Eng. Remote Sensing 2009, 75, 437–442. [Google Scholar]
- Yao, W.; Hinz, S.; Stilla, U. Extraction and motion estimation of vehicles in single-pass airborne LiDAR data towards urban traffic analysis. ISPRS J. Photogramm 2011, 66, 260–271. [Google Scholar]
- Oude Elberink, S.; Mass, H.G. The use of anisotropic height texture measurements for the segmentation of ariborne laser scanner data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2000, 33, 678–684. [Google Scholar]
- Shan, J.; Sampath, A. Urban DEM generation from raw Lidar data: a labeling algorithm and its performance. Photogramm. Eng. Remote Sensing 2005, 71, 217–226. [Google Scholar]
- Tinkham, W.T.; Huang, H.; Smith, A.M.S.; Shrestha, R.; Falkowski, M.J.; Hudak, A.T.; Link, T.E.; Glenn, N.F.; Marks, D.G. A Comparison of two open source LiDAR surface classification algorithms. Remote Sens 2011, 3, 638–649. [Google Scholar]
- Petzold, B.; Axelsson, P. Result of the OEEPE WG on Laser data acquisition. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2000, 33, 718–723. [Google Scholar]
- Brovelli, M.A.; Cannata, M.; Longoni, U.M. Managing and Processing LIDAR Data within GRASS. Proceedings of Open Source GIS: GRASS Users Conference, Trento, Italy, 11–13 September 2002.
- Shen, J.; Liu, J.P.; Lin, X.G.; Zhao, R. Object-based classification of airborne light detection and ranging point clouds in human settlements. Sensor Lett 2012, 10, 221–229. [Google Scholar]
- Sithole, G. Segmentation and Classification of Airborne Laser Scanner Data. Netherlands Commission of Geodesy, Delft, The Netherlands, 2005. [Google Scholar]
- Golovinskiy, A.; Kim, V.G.; Funkhouser, T. Shape-based Recognition of 3D Point Clouds in Urban Environments. Proceedings of the 12th International Conference on Computer Vision (ICCV09), Kyoto, Japan, 27 September–4 October 2009; pp. 2154–2161.
- Barsi, Á. Object detection using neural self-organization. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2004, 35, 366–371. [Google Scholar]
- Benz, U.C.; Peter, H.; Gregor, W.; Lingenfelder, I.; Heynen, M. Multi-resolution, object-oriented fuzzy analysis of remote sensing data for GIS-ready information. ISPRS J. Photogramm 2004, 58, 239–258. [Google Scholar]
- Silván-Cárdenas, J.L.; Wang, L. A multi-resolution approach for filtering LiDAR altimetry data. ISPRS J. Photogramm. 2006, 61, 11–22. [Google Scholar]
- Vosselman, G.; Klein, R. Visualization and Structuring of Point Clouds. In Airborne and Terrestrial Laser Scanning, 1st ed; Vosselman, G., Maas, H.G., Eds.; Whittles Publising: Dunbeath, UK, 2010; pp. 43–79. [Google Scholar]
- Melzer, T. Non-parametric segmentation of ALS point clouds using mean shift. J. Appl. Geod 2007, 1, 159–170. [Google Scholar]
- Wang, M.; Tseng, Y.H. Automatic segmentation of LiDAR data into coplanar point clusters using an octree-based split-and-merge algorithm. Photogramm. Eng. Remote Sensing 2010, 76, 407–420. [Google Scholar]
- Vosselman, G.; Gorte, B.G.H.; Sithole, G.; Rabbani, T. Recognizing structure in laser scanner point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2004, 36, 33–38. [Google Scholar]
- Rabbani, T. Automatic Reconstruction of Industrial Installations Using Point Clouds and Iimages. Netherlands Commission of Geodesy, Delft, The Netherlands, 2006. [Google Scholar]
- Edelsbrunner, H.; Kirkpatrick, D.; Seidel, R. On the shape of a set of points in the plane. IEEE T. Inform. Theory 1983, 29, 551–559. [Google Scholar]
- Arya, S.; Mount, D.M.; Netanyahu, N.S.; Silverman, R.; Wu, A.Y. An optimal algorithm for approximate nearest neighbor searching in fixed dimensions. J. ACM 1998, 45, 891–923. [Google Scholar]
- Lalonde, J.-F.; Vandapel, N.; Huber, D.; Hebert, M. Natural terrain classification using three-dimensional ladar data for ground robot mobility. J. Field. Robot 2006, 23, 839–861. [Google Scholar]
- Hug, C.; Wehr, A. Detecting and identifying topographic objects in imaging laser altimeter data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 1997, 32, 19–26. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer-Verlag: New York, NY, USA, 1995. [Google Scholar]
- Samet, H.; Tamminen, M. Efficient component labeling of images of arbitrary dimension represented by linear bintrees. IEEE T. Pattern Anal 1988, 10, 579–586. [Google Scholar]
- A Two-Dimensional Quality Mesh Generator and Delaunay Triangulator. Available online: http://www.cs.cmu.edu/~quake/triangle.html (accessed on 11 October, 2011).
- Chang, C.C.; Lin, C.J. LIBSVM: A Library for Support Vector Machines. 2001. http://www.csie.ntu.edu.tw/~cjlin/libsvm (accessed on 15 March 2010).
- ANN: A Library for Approximate Nearest Neighbor Searching. Available online: http://www.cs.umd.edu/~mount/ANN/ (accessed on 15 March 2010).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Ground (Points) | Vegetation (Points) | Building (Points) | Vehicle (Points) | Powerline (Points) | Total (Points) | User Accuracy (%) | |
|---|---|---|---|---|---|---|---|---|
| Ground (points) | Scene1 | 315,256 | 1,549 | 5,042 | - | - | 321,847 | 97.95 |
| Scene2 | 684,904 | 15,495 | 8,985 | - | - | 709,384 | 96.55 | |
| Scene3 | 1,152,469 | 752 | 463 | 1 | 0 | 1,153,685 | 99.89 | |
| Vegetation (points) | Scene1 | 2,871 | 65,211 | 8,770 | - | - | 76,852 | 84.85 |
| Scene2 | 1,934 | 62,423 | 3,050 | - | - | 67,407 | 92.61 | |
| Scene3 | 1,642 | 343,751 | 2,596 | 1,474 | 2057 | 351,520 | 97.79 | |
| Building (points) | Scene1 | 807 | 22,583 | 120,993 | - | - | 144,383 | 83.80 |
| Scene2 | 4,841 | 16,250 | 236,435 | - | - | 257,526 | 91.81 | |
| Scene3 | 37 | 1,569 | 172,088 | 522 | 0 | 174,216 | 98.78 | |
| Vehicle (points) | Scene3 | 319 | 507 | 317 | 13,225 | 0 | 14,368 | 92.04 |
| Powerline (points) | Scene3 | 0 | 1,268 | 0 | 0 | 6874 | 8,142 | 84.24 |
| Total (points) | Scene1 | 318,934 | 89,343 | 134,805 | - | - | 543,082 | |
| Scene2 | 691,679 | 94,168 | 248,470 | - | - | 1,034,317 | - | |
| Scene3 | 1,154,467 | 347,865 | 175,464 | 15,222 | 8931 | 1,701,949 | ||
| Producer accuracy (%) | Scene1 | 98.85 | 72.99 | 89.75 | - | - | ||
| Scene2 | 99.02 | 66.28 | 95.15 | - | - | - | ||
| Scene3 | 99.83 | 98.82 | 98.08 | 86.88 | 76.97 | |||
| Overall accuracy (%) | Scene1 | 92.34 | ||||||
| Scene2 | 95.11 | |||||||
| Scene3 | 99.20 | |||||||
| Kappa | Scene1 | 0.8638 | ||||||
| Scene2 | 0.8972 | |||||||
| Scene3 | 0.9837 | |||||||
© 2013 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Zhang, J.; Lin, X.; Ning, X. SVM-Based Classification of Segmented Airborne LiDAR Point Clouds in Urban Areas. Remote Sens. 2013, 5, 3749-3775. https://doi.org/10.3390/rs5083749
Zhang J, Lin X, Ning X. SVM-Based Classification of Segmented Airborne LiDAR Point Clouds in Urban Areas. Remote Sensing. 2013; 5(8):3749-3775. https://doi.org/10.3390/rs5083749
Chicago/Turabian StyleZhang, Jixian, Xiangguo Lin, and Xiaogang Ning. 2013. "SVM-Based Classification of Segmented Airborne LiDAR Point Clouds in Urban Areas" Remote Sensing 5, no. 8: 3749-3775. https://doi.org/10.3390/rs5083749
APA StyleZhang, J., Lin, X., & Ning, X. (2013). SVM-Based Classification of Segmented Airborne LiDAR Point Clouds in Urban Areas. Remote Sensing, 5(8), 3749-3775. https://doi.org/10.3390/rs5083749